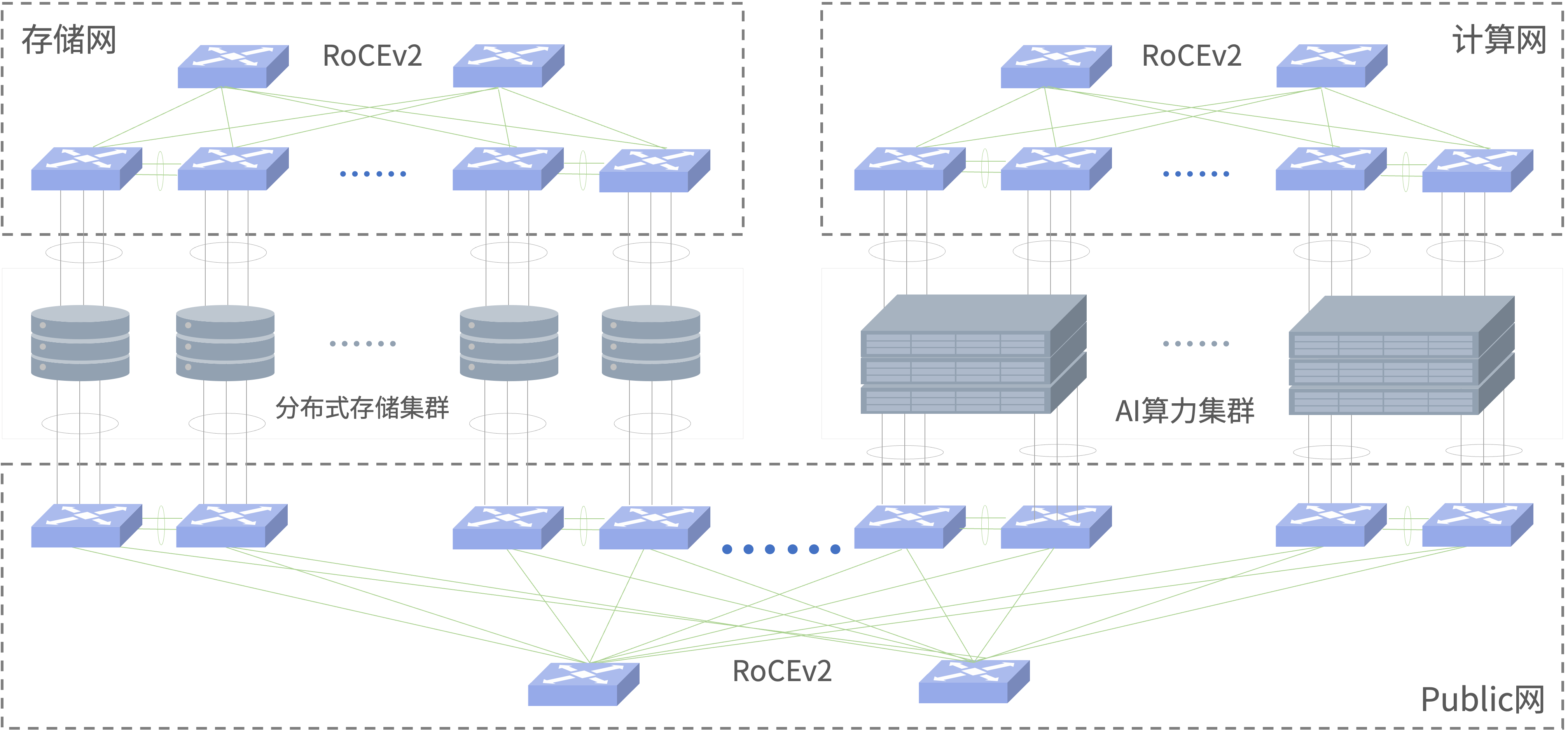
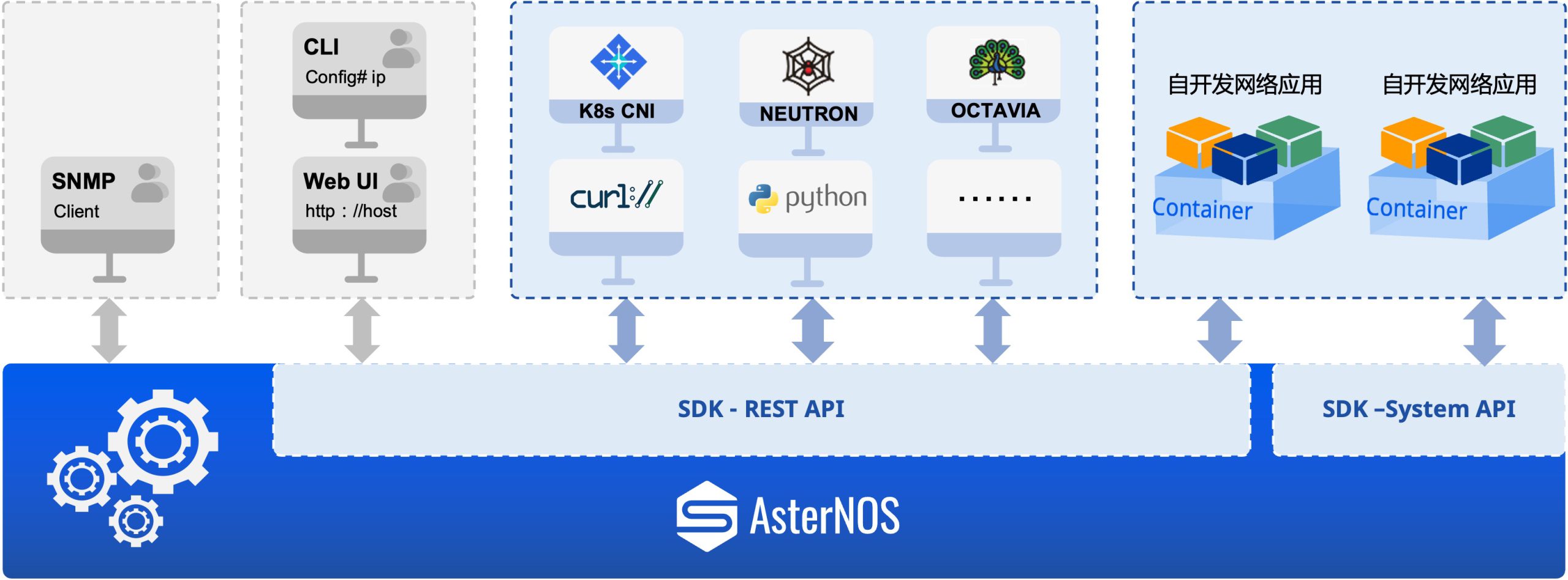
星智AI网络—基于LLM大模型的Rail Only网络
星智AI网络—基于LLM大模型的Rail Only网络
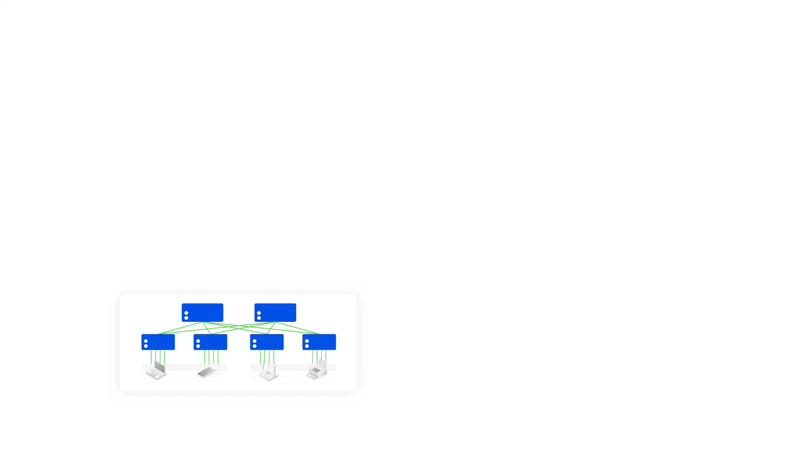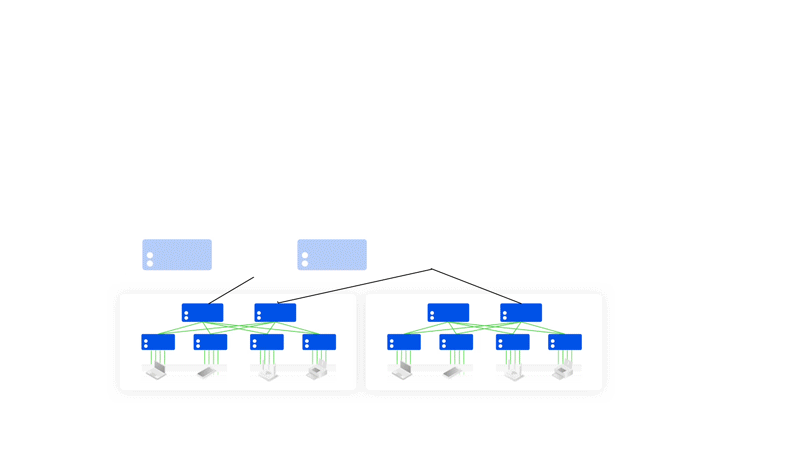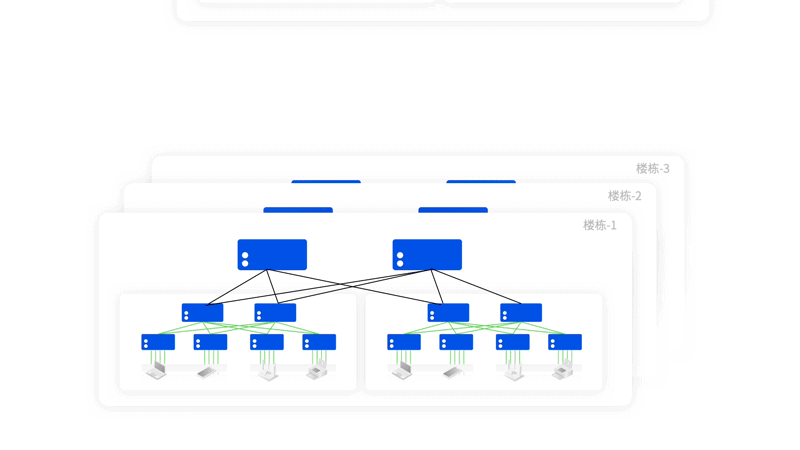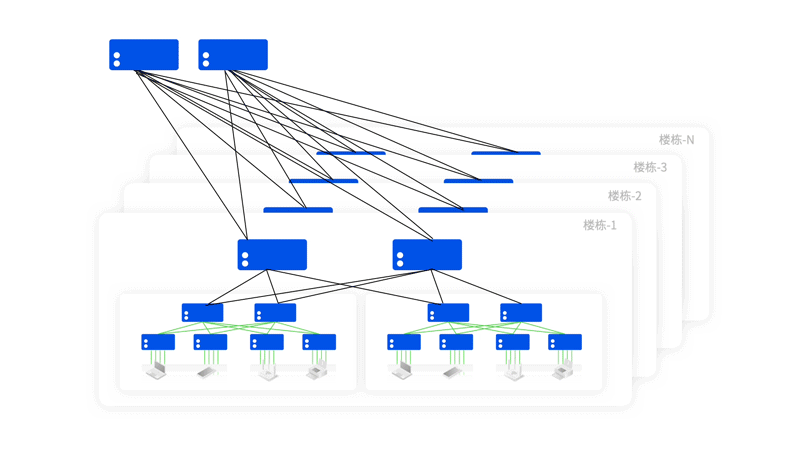
Asterfusion星智AI网络解决方案
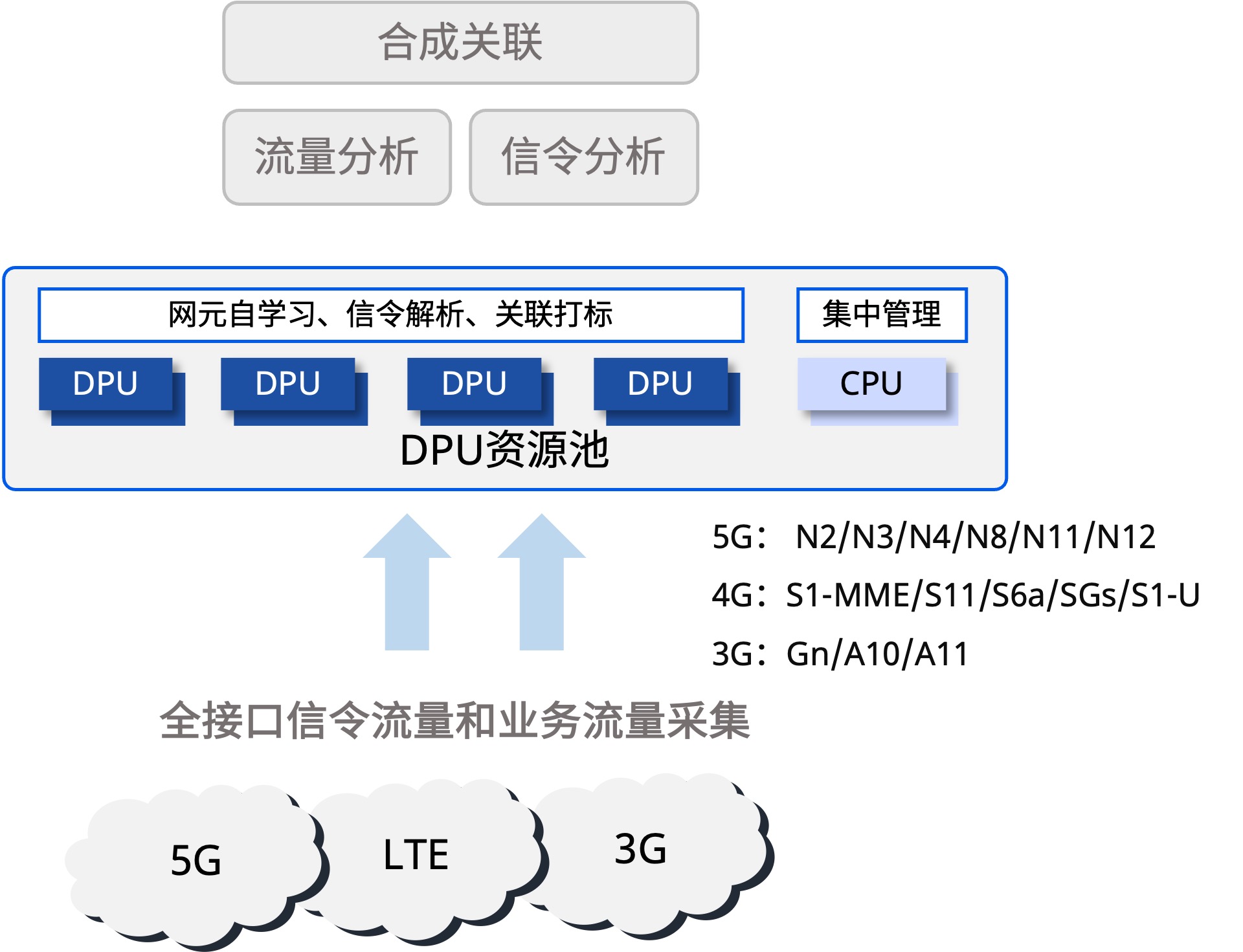
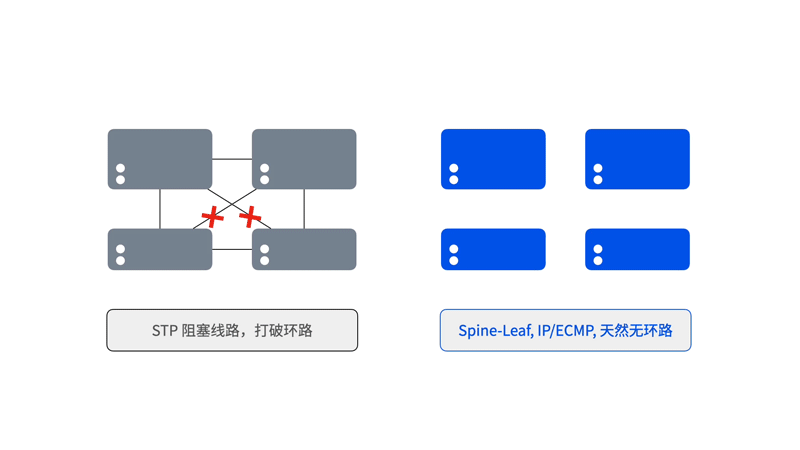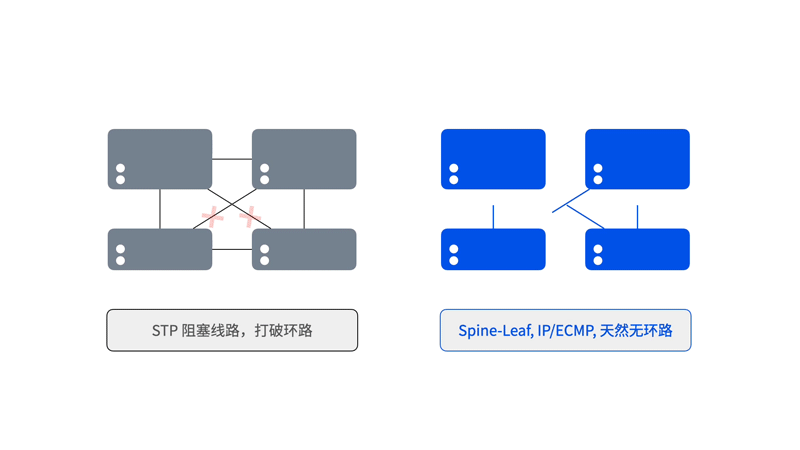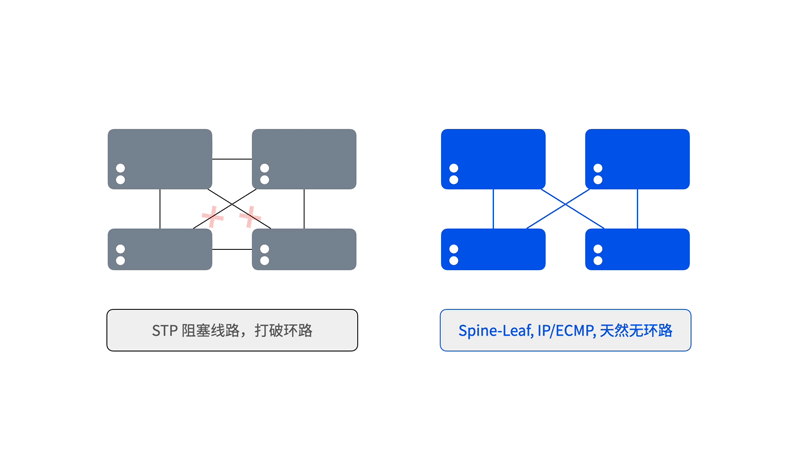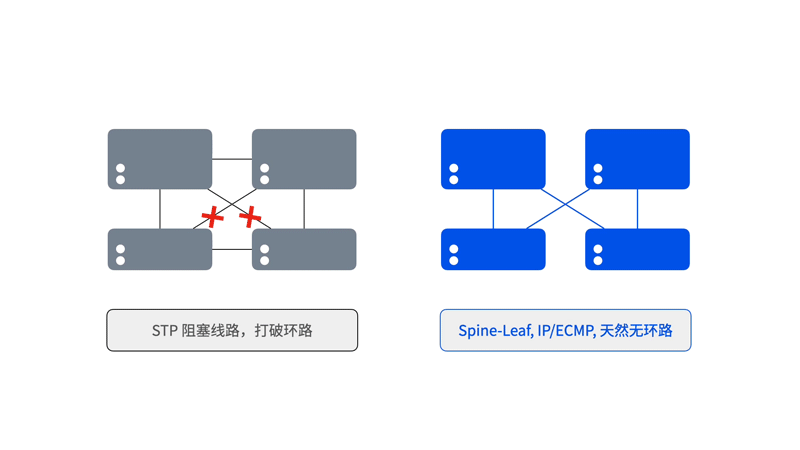
与传统方案相比,星智AI网络消除了跨GPU服务器不同GPU卡号之间的连接,只保留了与GPU相连的Leaf层交换机,将原本用于上连Spine的端口全部用于下连GPU,进一步提高Leaf交换机连接效率,并且这种网络架构仍然可以通过转发实现不同HB域之间的通信。
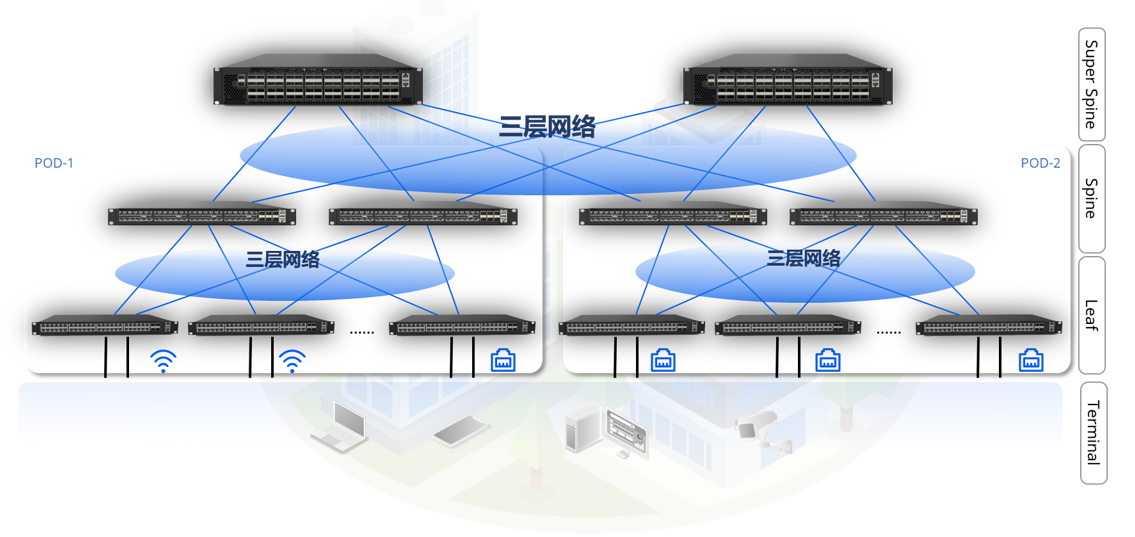
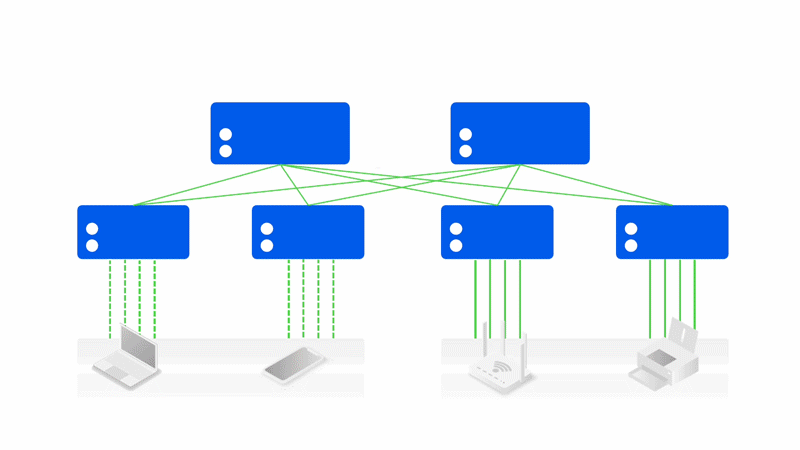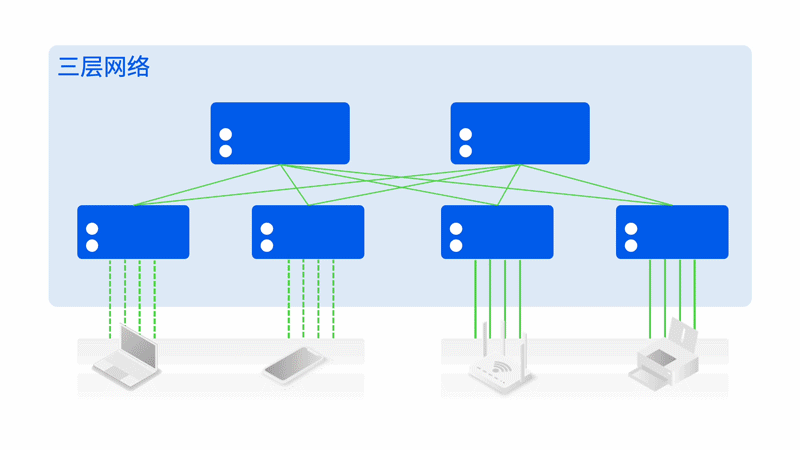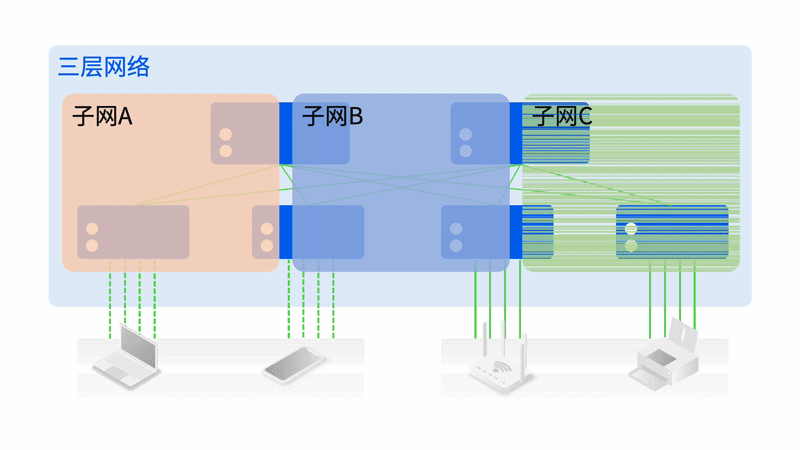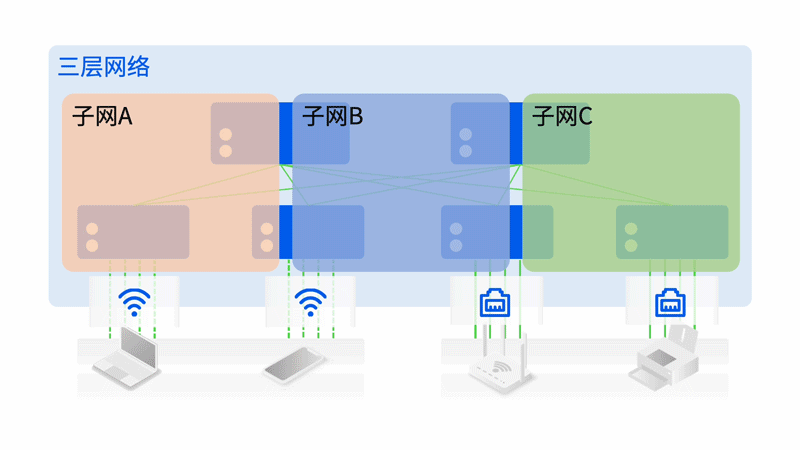
轻松组建智算中心万卡网络
-
在不影响数据传输性能的情况下,精简网络架构,极大降低用户网络建设成本;
-
将网络转发路径跳数降低至1跳,大大减少业务时延;
-
简化网络结构,降低运维以及故障排查难度。
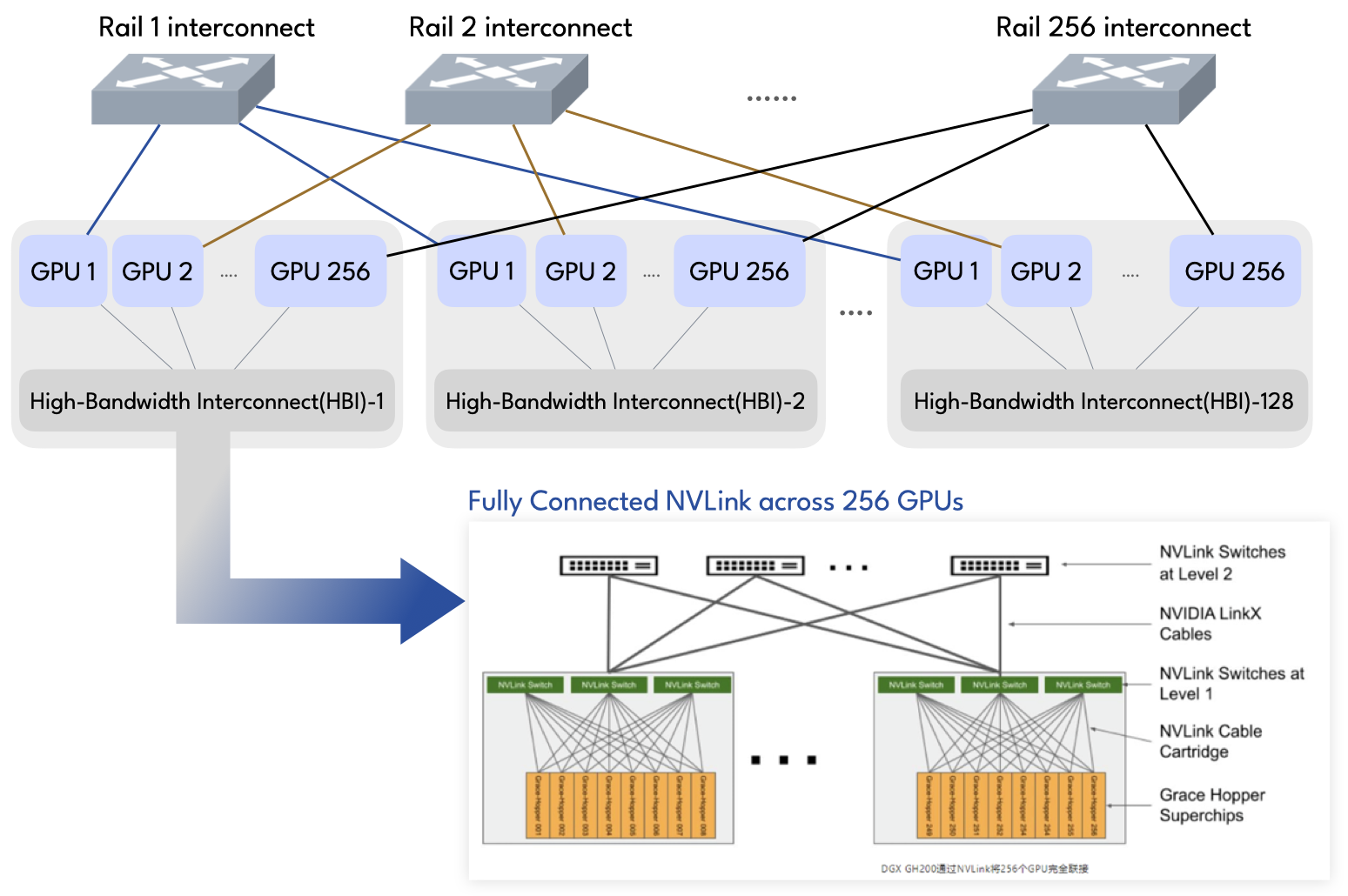
以32768个GPU,128端口交换机组网为例:
- CLOS层数:1层(Rail Only)
- 交换机需要:256台
- 光发射器数量:65536
- 网络成本最大可降低:75%
方案优势
-
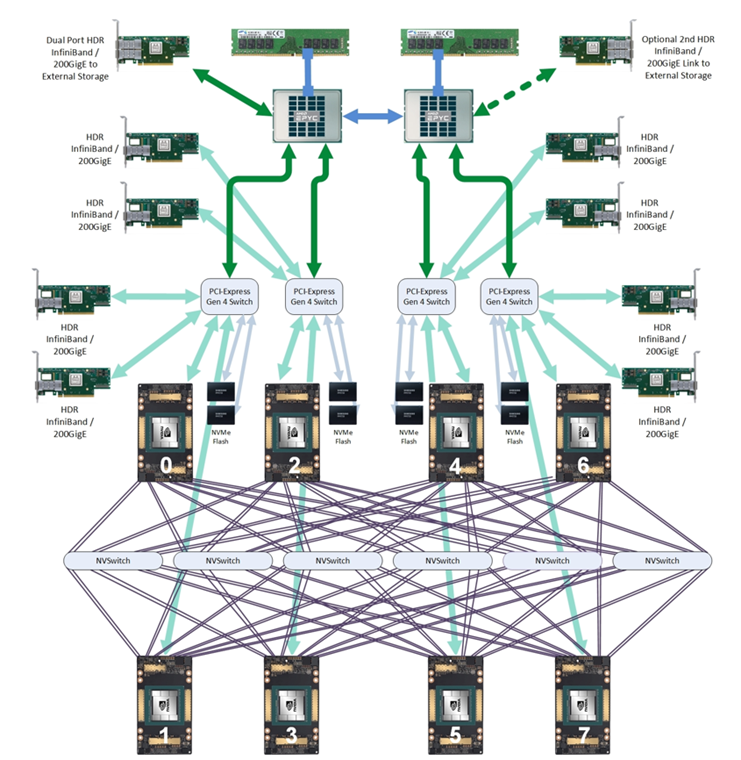
提升单机网络带宽
- 增加网卡的数量,初期业务量少,可以考虑CPU和GPU共用,后期给CPU准备单独的1到2张网卡,给GPU准备4或8张网卡;
- 提升单机网卡带宽,同时需要匹配主机PCle带宽和网络交换机带宽,星融元200G、400G以太网交换机将配合网卡确保数据传输高带宽。
网卡速率 40G 100G 200G 400G PCIe 3.0*8 3.0*16 4.0*16 4.0或5.0*16 交换机Serdes 4*10G 4*25G 4*50G 8*50G -
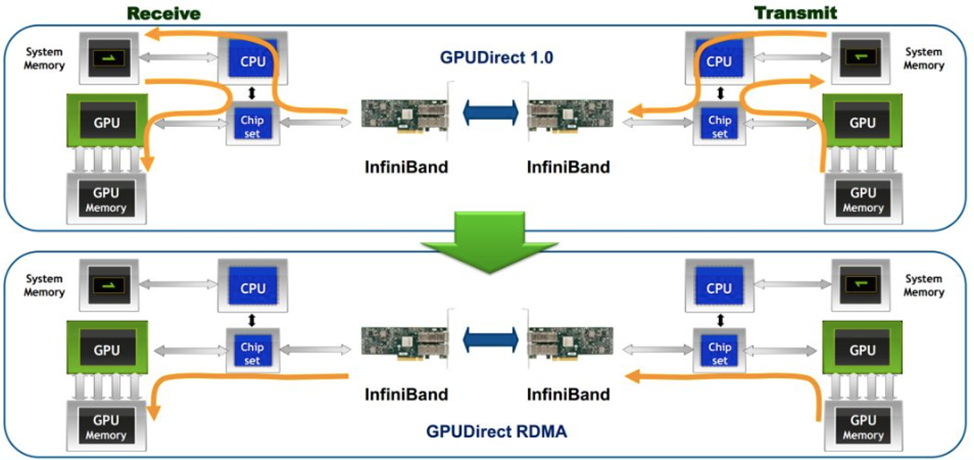
应用RDMA网络(RoCE)
- 借助RDMA技术减少GPU通信过程中的数据复制次数,优化通信路径,降低通信时延。
- 通过Easy RoCE一件下发复杂的RoCE相关配置(PFC、ECN等),帮助用户降低运维复杂度。
-
减少网络拥塞
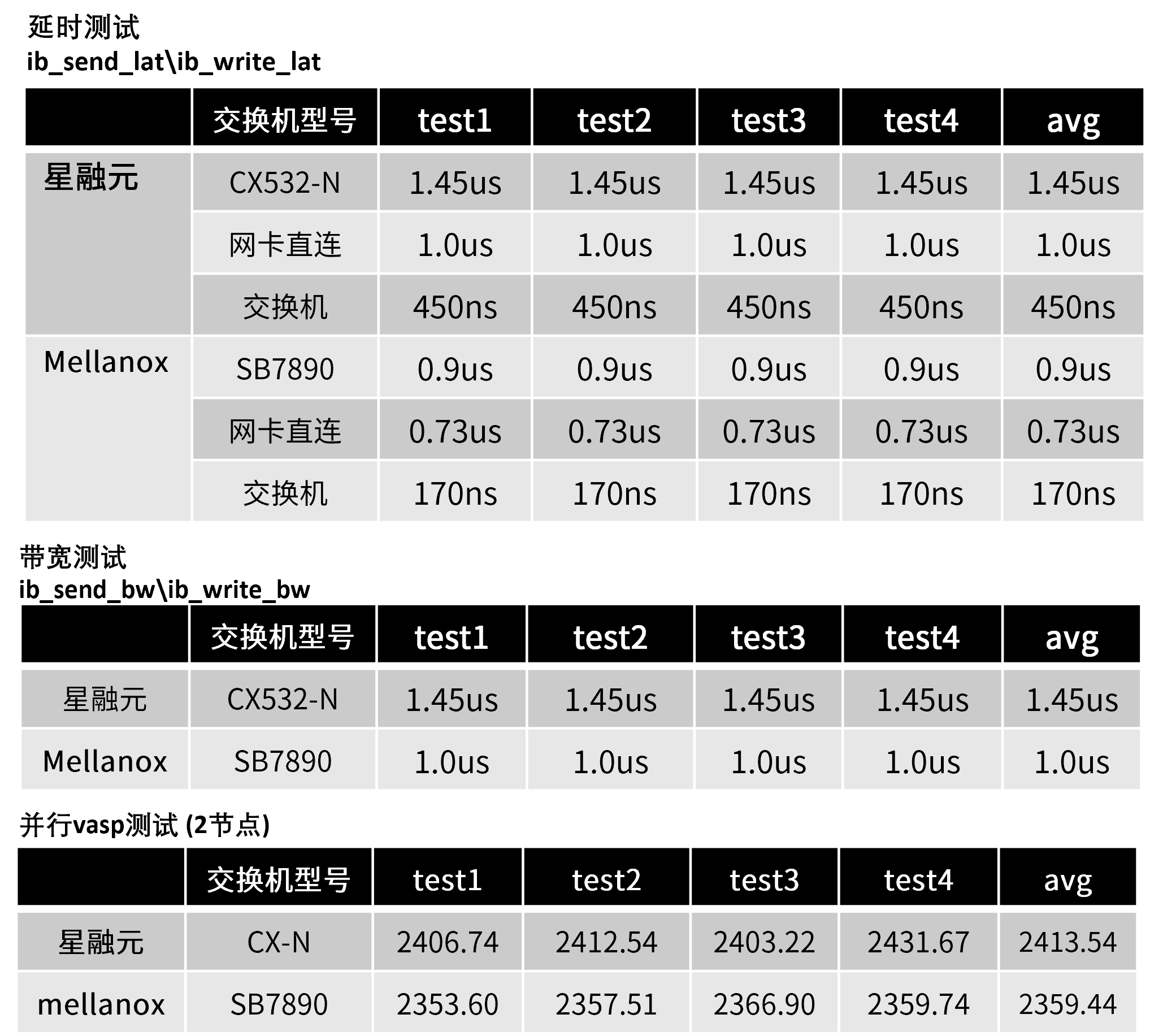
- 减少网络侧时延提高GPU使用效率:超低时延~400ns;
- 通过DCB协议组减少网络拥塞:PFC、PFC WatchDog、ECN构建全以太网零丢包低时延网络;
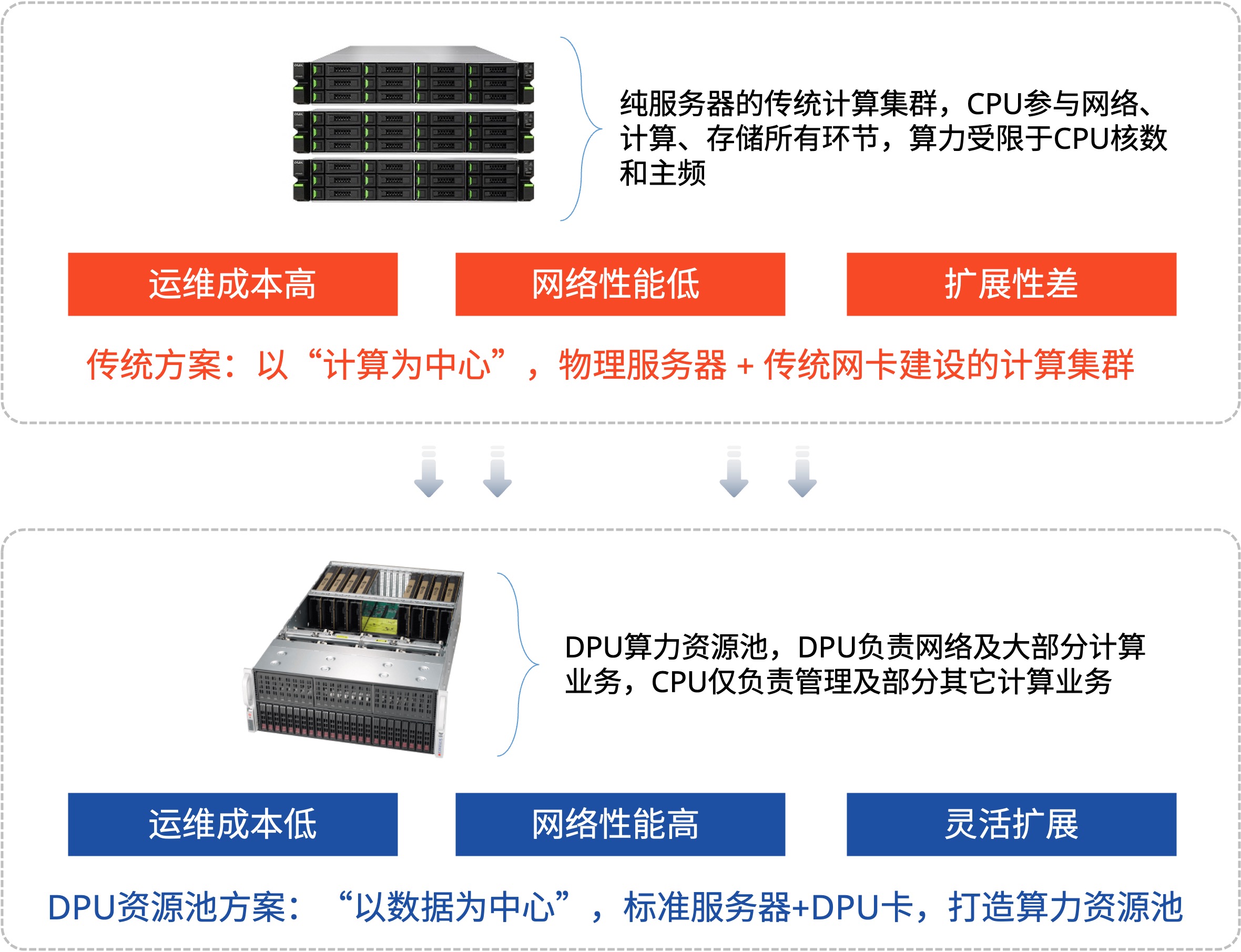
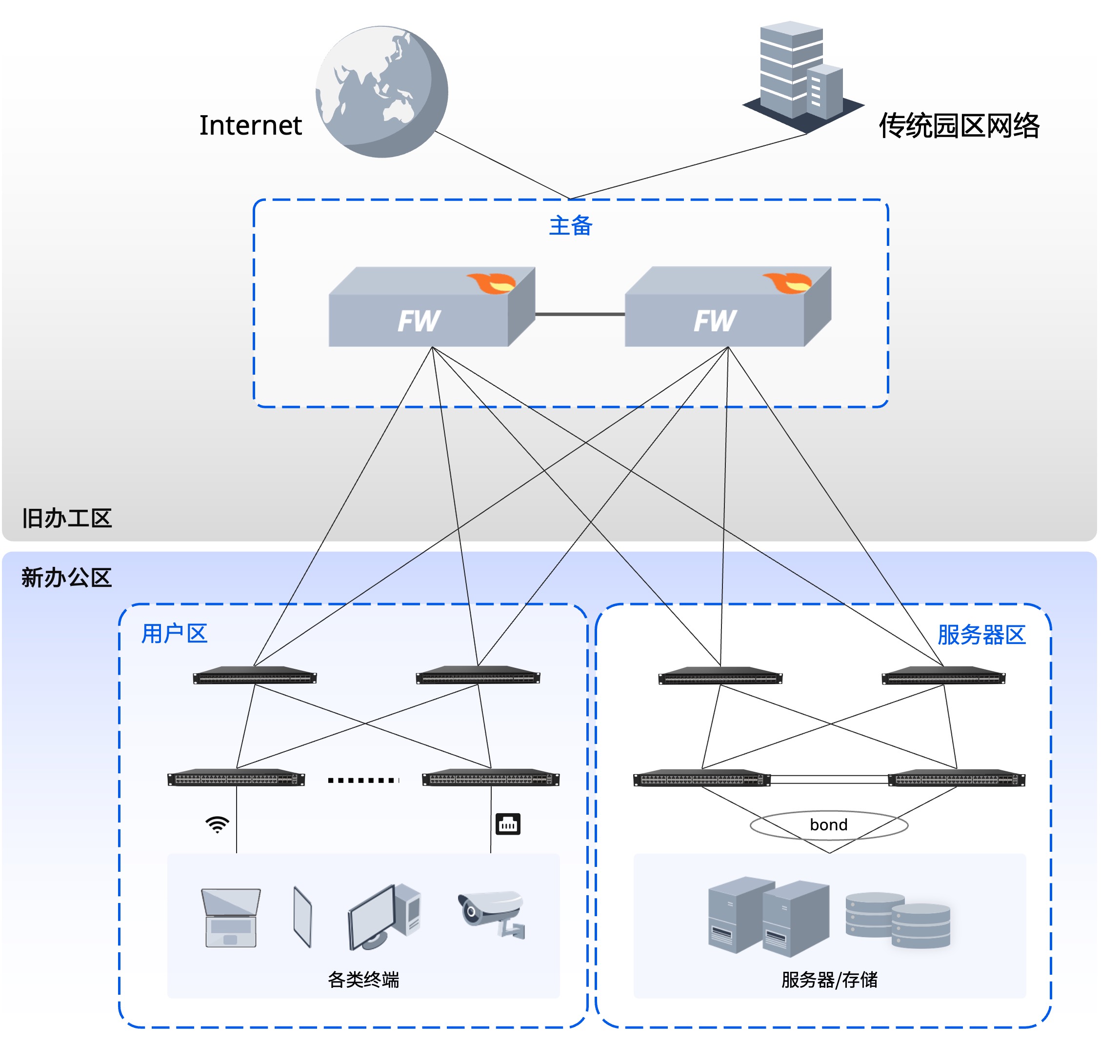
- 双网分流: CPU的流量与GPU流量彻底分离开,减少不同网络流量的占用和干扰;



-20230227-1024x467.jpg)