一文看懂ARS(自适应路由切换):基于 Flowlet 的动态负载均衡技术
智算网络高带宽利用率利器:基于 Flowlet 的自适应动态负载均衡技术

不同负载均衡技术对比
现有主流负载均衡技术大体分为三种,逐流的 ECMP 负载均衡、逐包负载均衡和基于子流(Flowlet)的负载均衡。
逐流负载均衡
传统的 ECMP 路由通常采用逐流负载分担机制,其核心是基于数据包的特征字段(例如 IP 五元组等信息)作为计算因子去进行哈希运算,根据哈希值选择转发链路。
- 不同的流由于特征字段不同,会生成不同的哈希值,从而分散到不同的链路完成转发,在整网实现一定的负载均衡;
- 具有相同特征字段的流,经过哈希运算后会分配到同一条转发路径,由此保证了同一条数据流会按序依次到达对端。
随着云计算的发展和智算业务兴起,逐流负载均衡的缺陷愈加凸显。
首先,逐流的负载均衡无法解决流大小不均的问题,当大小流平等、粗放地进行负载均衡的精细度有限,带宽利用率也有所损耗;
其次,它是一种静态的负载均衡机制,无法实时感知链路的负载情况。当网络出现大象流,静态负载均衡机制依旧会按照既定的路由算法去选路,容易进一步加剧拥塞,造成丢包;
尤其是智算集合通信场景下,该机制还极易在 Clos 组网的 Leaf 上行链路出现哈希极化现象,造成网络拥塞。(btw,我们提供一个静态方式来解决这个问题,感兴趣可以参考👉 主动规划+自动化配置工具,简单应对AI智算网络 ECMP 负载不均)
逐包负载均衡
逐包的负载均衡技术则是将数据包均匀地负载到各条链路上,又被形象地称为“数据包喷洒”(Packet Spray)。
逐包负载均衡通常提供 Random 和 Round Robin 两种算法,Random 算法将数据包随机分散到各条链路上;Round Robin 算法能够将数据包逐一等量的分散到各条链路,理论上均衡度最好。
但由于实际组网中不同链路的负载情况和转发时延不一样,逐包负载均衡无法保证报文依照原有时序到达接收端,故其整体性能依赖于端侧的缓存容量和乱序重组能力。
基于子流(Flowlet)的负载均衡
不同于传统负载均衡的逐流负载分担或逐包负载分担,基于子流的负载均衡不光是对数据流进行分割以实现更精细均匀的负载分担,而且保持了报文到达的时序性。
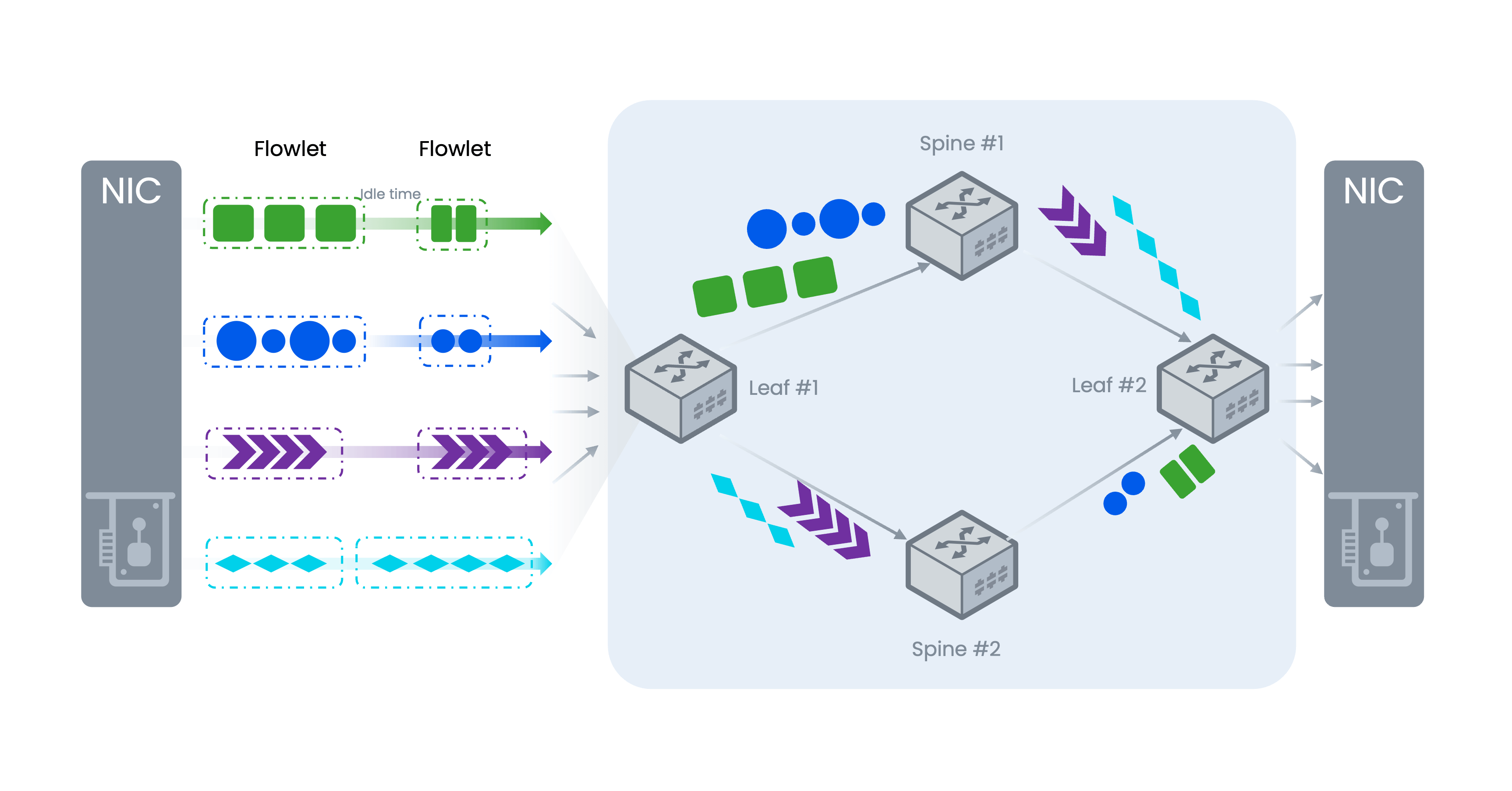
当前星融元 RoCE 交换机所支持的 ARS(Adaptive Routing and Switching,自适应路由切换)即是一种基于子流的负载均衡技术;同时这也是一种动态的负载均衡,其利用了 ASIC 提供的硬件 ALB(Auto-Load-Balancing)能力通过实时感知链路状态,主动调整选路改善拥塞状况,并提高整体的带宽利用率。
接下来我们将从下面三个问题出发,帮助读者理解该机制的运行原理。
- 如何分割大流?
- 动态选路机制和链路的测量指标是什么?
- 何时触发路径的主动分配/重分配?
术语解释
ARS技术中有以下几个关键概念:
- 微观流(Micro Flow):五元组相同的一组数据
- 宏观流(Macro Flow):哈希值相同的微观流的集合
- 空闲时间(Idle Time):宏观流中一段没有流量的时间(可配置的参数)
- 子流(Flowlet):指宏观流中被空闲时间分割的一组连续数据包
流分割:从 Flow 到 Flowlet
Flowlet(子流)是 ARS 技术对流进行负载均衡的基本单位。
如上图所示,一系列拥有相同五元组微观流(Micro Flow 1/2/3…)会进入到网络中,我们采用 IP 五元组作为哈希因子对所有微观流进行哈希计算,哈希值相同的一系列微观流组成一条宏观流。
宏观流中,当两条微观流之间相隔的时间T大于配置的空闲时间(Idle Time)会触发流分割,将宏观流分割为子流(Flowlet):以时间 T 为界,前后两个微观流从属于两个不同的子流。
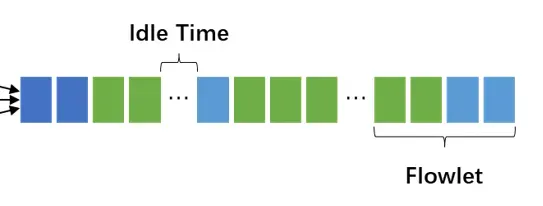
显然,Flowlet 会包含拥有不同 IP 五元组信息的数据包(不同的微观流),从业务层面来看,传统意义上的“大象流”会被打散,而小流则有可能合并到一个 Flowlet 里传输。
动态选路机制和测量指标?
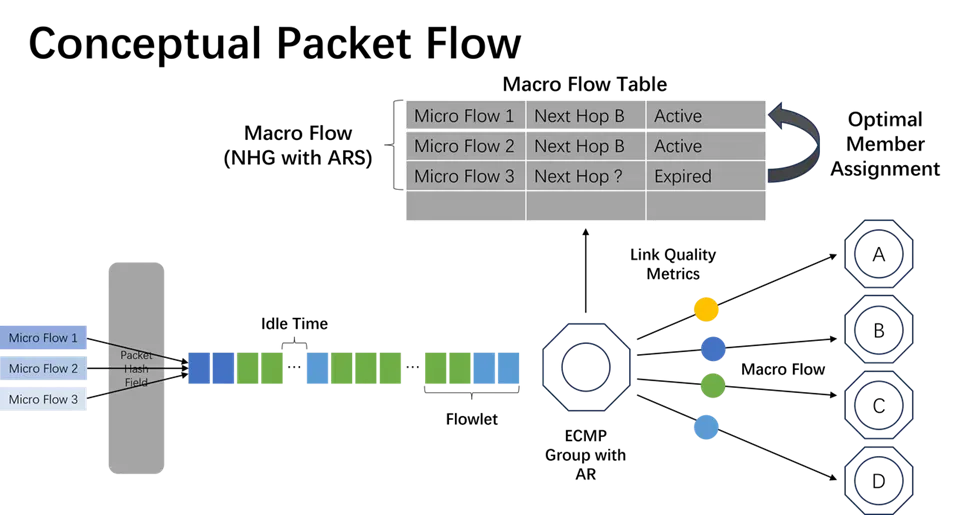
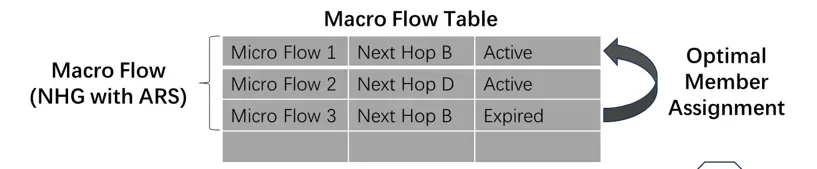
ASIC 负责维护一个宏观流表 (Macro Flow Table),其中记录了各宏观流和其对应的出接口(或 ECMP 链路成员)信息。
通过实时测量不同端口上负载和时延,ARS 技术可以将宏观流以 Flowlet 的颗粒度路由到当前更优的链路上。
至于我们如何得知当前哪条链路更优呢?这里就涉及到链路质量指标的测量问题。
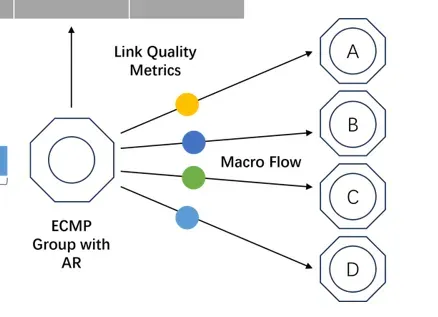
链路指标的测量由控制平面和ASIC共同完成,在星融元的方案中,我们关心的指标有端口带宽、端口利用率、转发时延,上述三个指标共同决定了端口所在链路于t时刻的质量情况。
端口带宽
对于启用了 ARS 功能的端口,控制平面会对其线速速率进行归一化,并将配置下发给 ASIC 备用,基础速率为10G。
端口利用率
端口带宽利用率通过端口实时流量速率反映。ASIC 对端口上的流量速率进行采样后,通过与端口线速速率进行比较得出端口带宽利用率,并计算端口平均负载。
转发时延
端口所在链路转发时延通过该端口的队列深度反映,ASIC 对端口队列深度进行采样后计算其历史负载情况。
对于参与了 ARS 的端口,ECMP 组会实时计算更新各出接口的链路质量情况,并在路径动态分配时根据最近一次的结果择优转发流量。
何时进行路径主动分配?
路径主动分配发生在流分割过程中的末尾,结合上述的路径指标完成最终路由决策。
我们可以假设这样一个场景:当 Flowlet 1 的最后一条微观流 Micro Flow 2 被分配到路径 D 并间隔时间 T(T>Idle Time)后,另一条微观流 Micro Flow 3 此时待处理。
由于 T>Idle Time,此时 ASIC 认为 Flowlet 1 已结束,到路径D的映射到期。
此后的微观流 Micro Flow 3 从属于一条新的子流,且处于非活跃状态,于是触发一次主动路径分配。
流分割的关键参数 Idle Time 的合理配置值跟全局路径级时延信息高度相关,通常会配置为不小于 1/2 RTT。
这是因为转发设备的接收队列缓冲区会实时变化,即使发送端的报文发送间隔恒定,转发设备上处理报文并进行转发时,间隔也会发生变化。配置过小会导致分割出来的 Flowlet 粒度过细从而引发乱序,过大则无法将宏观流进行有效分割,引发拥塞。
典型应用举例
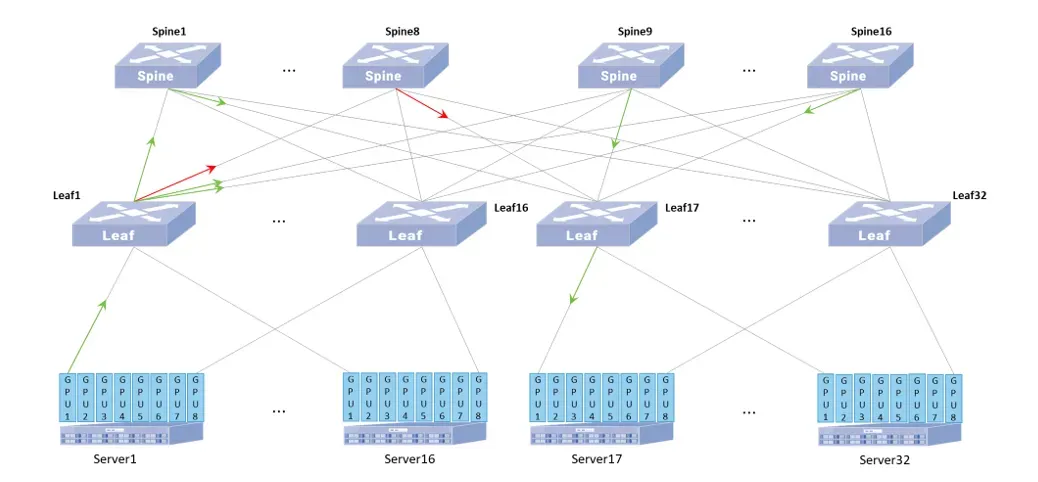
如上图,以 128 台 8 卡 GPU 服务器(共计 1024 个 400G 网卡)规模为例,AIDC 承载网采用两层 Clos 网络架构。Spine 和 Leaf 设备均选择星融元 CX864E-N 交换机,并按照下行端口与上行端口1:1的收敛比设计组网。在保证网络高吞吐、高带宽的基础上,1:1 的带宽收敛比能够避免因为带宽不对称导致的性能问题。
点击链接 ➡️ 64 x 800G 51.2T RoCE交换机
假设 Server1 的 GPU1 要与 Server65 的 GPU1 通信,按照传统负载均衡的逻辑,流量会选择 Spine 中的一个然后到达 Leaf9。由于传统负载均衡不会感知路径实时状态,所以 AI 场景下的少量大象流极易被均衡到同一 Spine 上从而导致 Leaf1 上行端口拥塞甚至出现丢包。
当在星融元 CX864E-N 交换机启用 ARS 技术,则 ASIC 将能根据转发时延和端口实时负载对流量出接口进行调整。
假设 Leaf1 通往 Spine4 的链路上发生拥塞,则 Leaf1 的 ASIC 会将更少的 Flowlet 路由到 Spine4 或跳过 Spine4,直至该链路上的拥塞情况缓解后,才会恢复选中该链路进行流量转发。
由此各设备通过完成自治达到降低整网链路拥塞情况并提高带宽利用率。
参考文档
[1] OCPSummit2022- Adaptive Routing in AI/ML Workloads https://www.youtube.com/watch?v=cgYOpp4xwQ8
[2] https://infohub.delltechnologies.com/zh-cn/l/dell-enterprise-sonic-quality-of-service-qos/adaptive-routing-and-switching/
[3] https://asterfusion.com/a20250528-flowlet-alb/
产品型号: 星融元(Asterfusion)CX864E-N (64 x 800G OSFP)
功能特性:RoCEv2, PFC, ECN, DCBX ……
应用场景:GPU算力集群,分布式存储
最后更新:2026-05-18




