
520 P4可编程表白SDN交换机:我能给你的,比你想象得多!
P4可编程芯片概述
本文中我们以Tofino可编程芯片为例,Tofino芯片包含多个Pipeline,每个Pipeline可以运行不同的查表逻辑(即不同的P4程序),每个Pipeline含12个MAU(Match-Action Unit),出/入Pipeline共享这些MAU。
每一个MAU对应Pipeline流水线中一个Stage阶段,每个Stage支持若干次并发查找,从而可以提升并发查找性能。MAU与MAU之间顺序查找,多级查表或处理可以分布到不同的MAU上,从而可以丰富业务处理逻辑。
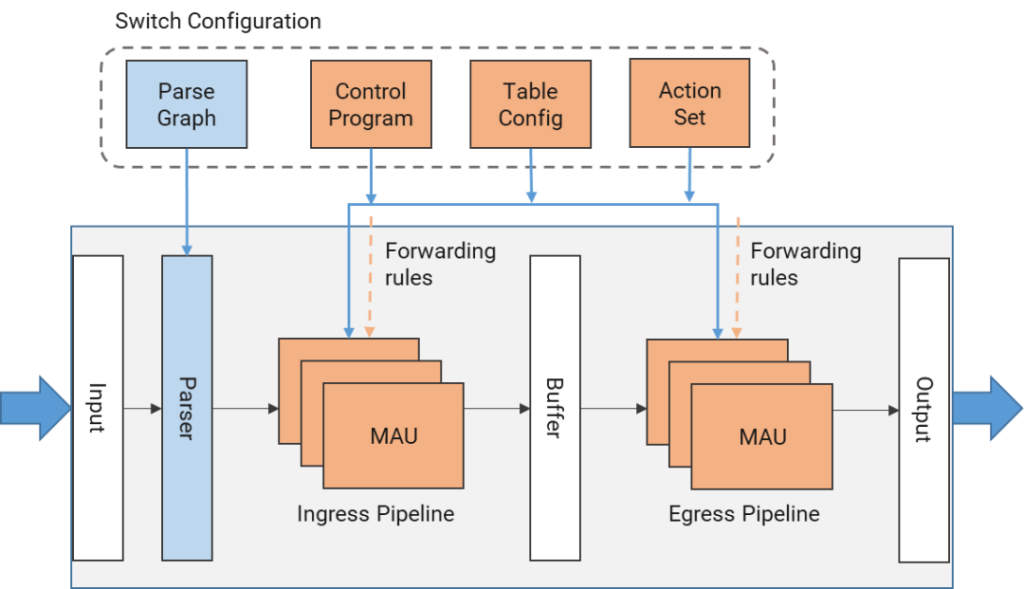 图1, P4抽象转发模型
图1, P4抽象转发模型
整体设计背景及面临的问题
为了满足交换机高性能处理的需要,设计时,我们采用多个Pipeline同构设计,即所有Pipeline部署相同P4程序,使用相同的处理转发逻辑。
考虑到业务逻辑的复杂性,数据面通常需要定义多个表才可以完成整个业务逻辑,并且流表与流表之间存在依赖关系,有依赖关系的流表会被P4编译器分配到不同的Stage。每个Stage只能访问自己的本地内存,当一张流表没有在运行时使用的时候,它的资源也就白白浪费了。
以下图为例,表21~23依赖于表11的匹配处理结果,如果表11没有处理完,表21~23也无法运行,同理,表31依赖于表21~23的匹配处理结果。
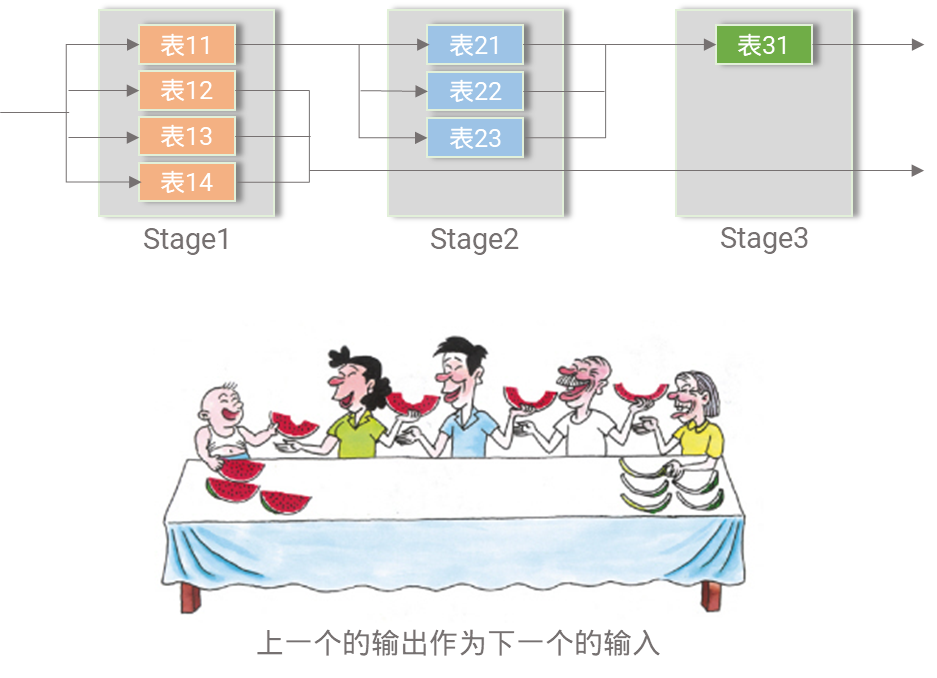 图2,表间依赖导致Stage资源利用率低
图2,表间依赖导致Stage资源利用率低
因此,在实际编码时,我们会发现虽然用光了所有的Stage资源,但每个Stage资源利用率却很低,极端时,资源利用率甚至不到10%。
优化设计方法
Stage资源利用率低的直接体现就是交换机相应的流表空间的不足。
为了实现交换机流表空间扩充,需要寻找可以提高Stage资源利用率的方法。
通常的调优方法主要包括以下几种:
- 优化表配置,降低表间耦合度,提升Stage资源利用率。
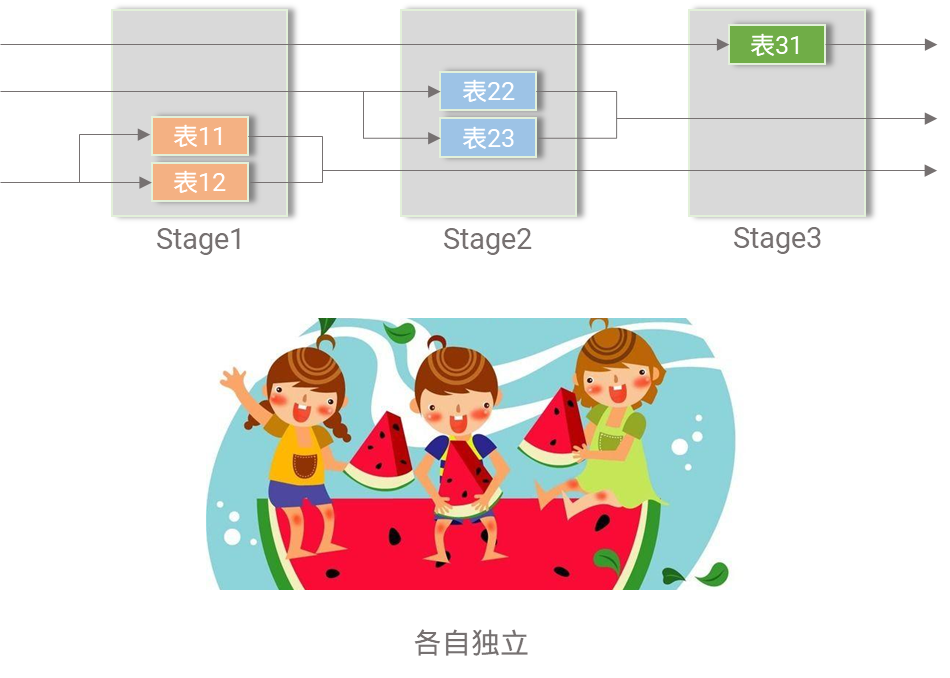 图3,降低表间耦合提升Stage资源利用率
图3,降低表间耦合提升Stage资源利用率 - 如果实在不能通过流表的设计降低耦合度,就需要深刻理解和调整业务逻辑,一般地做法是将Key或Action依赖改为后继依赖,必要时可以通过牺牲SRAM/TCAM确保低耦合。
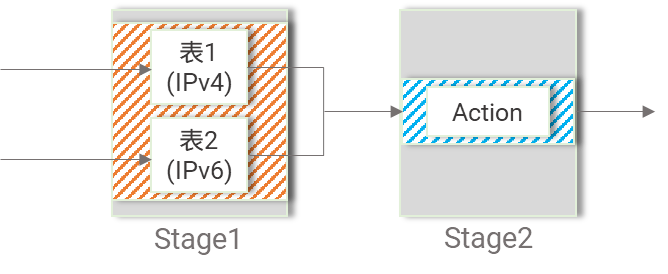 图4,后继依赖示例
图4,后继依赖示例 - 业务逻辑拆分部署。例如,在实际业务场景中,对特定报文执行隧道解封装是常见的需求,如果把整个功能单独放在Ingress Pipeline或单独放在Egress Pipeline,就会增加表间依赖,导致Stage资源利用率低,但是,如果将特定报文的筛选(查表)和处理(修)分别放在Ingress Pipeline和Egress Pipeline,则既能兼顾PHV(PacketHeader Vector)生存周期这一约束性资源的限制,又能提高Stage资源利用率。
- 巨型表拆解成小表。巨型表会被P4编译器分配到不同的Stage,如下图中的表2和表3是一个巨型表编译后的情况,对于Stage3而言,剩余的资源还可以部署其它拆解后小表,达到资源充分利用的效果。
 图5,巨型表拆解成小表[/caption]
图5,巨型表拆解成小表[/caption]
经过我们大量的实验和调优设计,基于P4可编程的SDN交换机片上SRAM利用率达到74%,片上TCAM利用率达到81%。
下图是优化后Stage资源利用图:
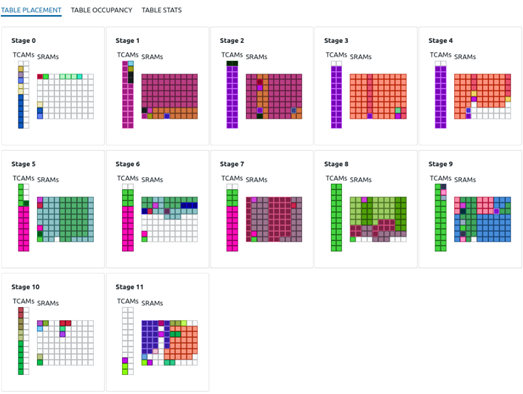
交换机流表扩充
SDN交换机需要根据L2-L4协议头识别所关心的流量,并对这部分流量做过滤和处理。
如下图所示,当收到报文后,适配不同的流表,并根据预定义的匹配动作处理报文。
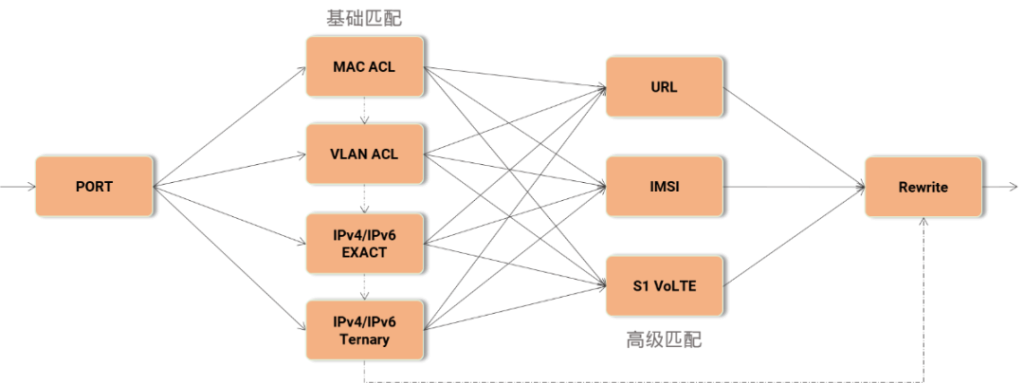 图7,流表匹配图
图7,流表匹配图
其中,报文五元组流表匹配是较为常见的匹配模式,又分为:
- 五元组精确流表
- 五元组掩码流表
常规的实现方法是,将报文的五元组定义到同一张流表里来满足基于五元组识别流量的需求。
但SDN交换机对流表规格要求很高,同时也需要不同元组组合。如,
- 一元组(源IP或目的IP)
- 二元组(源目的IP)
- 三元组(源目的IP及协议号)
- 四元组(源目的IP及源目的端口)
- 五元组(源目的IP及源目的端口及协议号)等。
基于TCAM可以实现通配五元组规则,就可以通过使用掩码方法忽略部分元组实现不同元组组合的流表,因此,将五元组放在一张流表里是没有问题的。
然而,基于SRAM实现的精确五元组流表受其查表机制(不支持掩码方式)影响,故天然不能满足需要不同元组组合查表的场景。
解决精确五元组流表扩充的方式有两种:
在SRAM上定义不同元组组合的流表:
优点在于编程模型及查找逻辑简单,管理面适配简单。
缺点是固定了6种元组,实际场景中存在6种以外的其他组合规则,灵活性较差。同时,由于不同元组组合的规则共享IP字段,尤其当IPv6时,这导致片上SRAM资源利用率极低,且不能保证规格。
压缩查表的Key:
Tofino芯片提供了Key压缩机制,但这个机制存在误匹配风险。误匹配的概率与流表Key的分布(或哈希后的离散程度)有关,随着已配表项数目的增加尤其在临近满配时,误匹配的概率将急剧提高。
我们在进行精确五元组流表扩充优化设计时,充分结合上述两种方式的优势,同时规避相应的不足,解决思路如下:
将较长Key映射成一个低位宽的Key(防止被编译器优化到不同的MAU),然后用低位宽Key替换IP,并对这些Key做精确(掩码)查找。
这种方法虽然牺牲了一部分SRAM,增加了数据面逻辑的复杂度和管理面适配的复杂度,但优化查表逻辑后可以在保证无误匹配的前提下支持不同五元组组合,使得整体规格在原有数万级别的基础上提升了250%,而不同元组组合规格(中值)提升了200%。
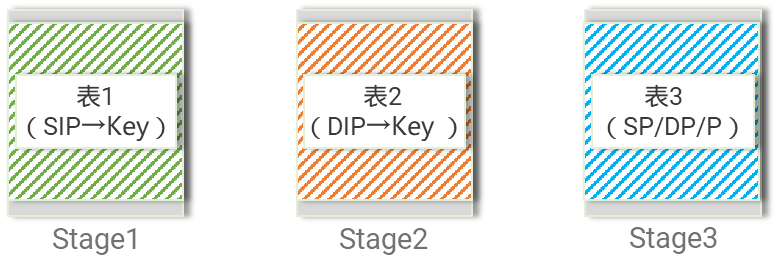 图8,低位宽Key拆解应用
图8,低位宽Key拆解应用
网络加速和业务卸载
“云化”大背景下,处理以隧道为代表的新应用新特性正在变成或已经变成基本需求,这些处理包括隧道封装、解封装、根据隧道内层IP信息进行流量识别和过滤等。
传统处理方式是将这部分流量提交到计算卡(业务卡)上处理,伴随着“云化”流量占比越来越大,本就昂贵的计算资源更加不堪重负。
……
P4可编程的SDN交换机为隧道流量的处理和卸载提供了契机,经过Parser调优设计,可以广泛支持各种隧道和封装协议的识别,如GTP、GRE、MPLS、ERSPAN、VXLAN、IP over IP等,并且可以根据隧道内层IP信息识别和过滤流量。
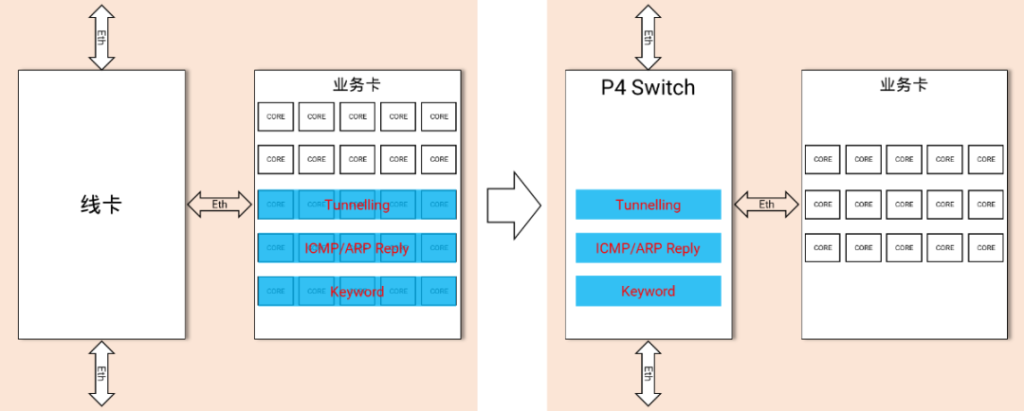 图9,基于P4可编程交换机实现网络加速和业务卸载
图9,基于P4可编程交换机实现网络加速和业务卸载
鉴于P4可编程交换机在处理隧道化流量方面有先天优势,这种优势可以转化为解决方案的成本优势;另一方面,如果将释放出计算能力运用到增值业务处理上,这一优势也可以转化为解决方案的增值优势。
除了隧道卸载外,我们还在基于P4的SDN交换机上卸载了诸如关键字匹配过滤、ICMP/ARP代答、报文截短等功能,以实现最大化地释放算力资源的目的。

