
星融元发布基于超低时延交换机的全以太HPC网络解决方案
随着云计算、大数据、物联网、人工智能等新技术融入人类社会的方方面面,可以预见,在未来二三十年间我们将迈入基于数字世界的万物感知、万物互联、万物智能的智能社会。数据中心的算力成为新的生产力,数据中心也从原有的资源规模向算力规模转变。
以下是三类典型的高性能计算(HPC)业务场景:
- 松耦合计算:计算节点之间对于彼此信息的相互依赖程度较低,网络性能要求相对较低。如:金融风险评估、遥感与测绘、分子动力学
- 紧耦合计算:各计算节点间彼此工作的协调、计算的同步以及信息的高速传输有很强的依赖性,对网络时延要求极高。如:电磁仿真、流体动力学和汽车碰撞
- 数据密集型计算:计算节点需要处理大量的数据,并在计算过程中产生大量的中间数据。要求提供高吞吐的网络,同时对于网络时延也有一定要求。如:气象预报、基因测序、图形渲染和能源勘探
显而易见,高吞吐和低时延成为HPC场景下重要的关键词。为此,业界一般采用RDMA替代TCP协议,来降低传输时延和服务器CPU的占用率。
RDMA(remote direct memory access,远程直接内存访问)是一种绕过远程主机操作系统内核访问其内存中数据的技术。目前RDMA的网络层协议主要有三种选择,分别是InfiniBand、iWarp和RoCE。
- InfiniBand 是一种专为 RDMA 设计的网络协议,从硬件级别保证了网络无损,具有极高的吞吐量和极低的延迟。但是 InfiniBand 交换机是特定厂家提供的专用产品,采用私有协议,而绝大多数现网都采用IP以太网络,采用 InfiniBand 无法满足互通性需求。同时,封闭架构也存在厂商锁定的问题,对于未来需要大规模弹性扩展的业务系统,风险尤甚。
- iWarp协议,允许在TCP上执行 RDMA ,需要支持iWarp的特殊网卡,支持在标准以太网交换机上使用RDMA。但是由于TCP协议的限制,其性能上丢失了绝大部分RDMA协议的优势。
与以上两种相比,RoCE(RDMA over Converged Ethernet)允许应用通过以太网实现远程内存访问,支持在标准以太网交换机上使用RDMA,只需要支持RoCE的特殊网卡,对网络硬件侧无特殊要求,是目前较为流行的一种。
但RDMA协议对于网络丢包非常敏感,所以问题最终还是回归到了这里:
如何来构建一张承载RDMA应用的无损以太网?
星融元全以太HPC网络解决方案
基于对高性能计算的网络需求和RDMA技术的分析和理解,星融元Asterfusion推出了CX-N系列超低时延云交换机(点击文末”阅读原文”链接了解详情),使用全开放、高性能的网络硬件平台+完全透明的开放系统,为HPC业务场景打造一张低时延、零丢包、高性能的以太网络,不被任何厂商绑定。
- 超高性价比,CX-N系列交换机具备Port to Port最低400ns的转发时延,全速率下(10G~400G)转发时延相同;
- 支持RoCEv2,降低传输协议时延;
- 支持各类数据中心高级特性(PFC、ECN等)在以太网上实现超低时延、零丢包网络传输;
- AFC SDN云网控制器提供网络管理可视化能力,实现多网合一,智能运维。
01、超低时延交换芯片,降低网络转发时延
星融元Asterfusion CX-N系列云交换机,从底层芯片到上层协议栈均面向低时延场景设计并调优,具备业界领先的低时延特性。使用 CX-N系列云交换机搭建高性能计算网络,可以大幅降低业务处理时延,提升高性能计算性能。

图1:超低时延的CX-N系列云交换机
02、使用PFC高优先级队列,提供无损网络
高性能计算场景中产生拥塞的原因有很多,比较关键也是比较常见的原因有三点:
- 进行数据中心网络架构设计时,如果采取非对称带宽设计,即上下行链路带宽不一致。也就是说当下联服务器上行发包总速率超过上行链路总带宽时,就会在上行口出现拥塞。
- 当前数据中心网络多采用Fabric架构,采用ECMP来构建多条等价负载的链路,并HASH选择一条链路来转发,是简单的。但这个过程没有考虑到所选链路本身是否已经拥塞,对于已经产生拥塞的链路来说,则会加剧拥塞。
- TCP Incast的通信模式,多对一的流量交互模式。当一个Parent Server向一组节点发起请求时,集群中的节点会同时收到请求,并且几乎同时响应。所有节点同时向 Server发送TCP数据流,使得交换机上联Server的出端口缓存不足,造成拥塞。
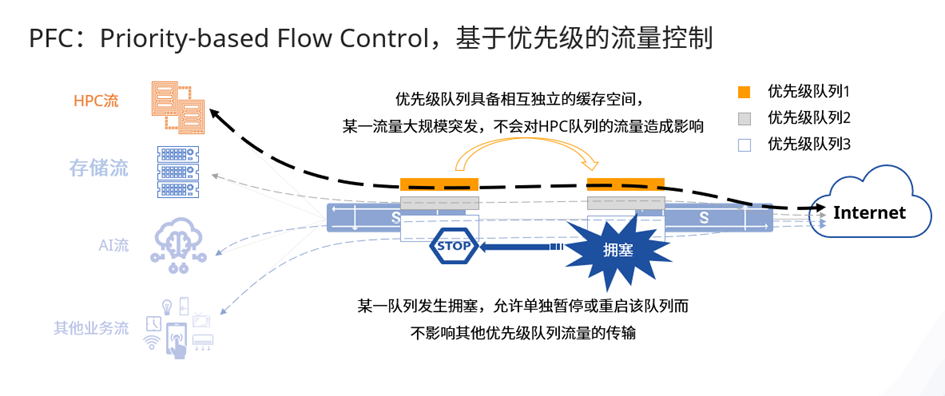
图2:PFC的工作机制
PFC是暂停机制的一种增强,PFC允许在一条以太网链路上创建8个虚拟通道,为每条虚拟通道指定一个优先等级并分配专用的资源(如缓存区、队列等等),允许单独暂停和重启其中任意一条虚拟通道而不影响其他虚拟通道流量的传输,保证其它虚拟通道的流量无中断通过。这一方法使网络能够为单个虚拟链路创建无丢包的服务,并且使其能够与同一接口上的其它流量类型共存。
03、使用ECN拥塞控制算法,消除网络拥塞
ECN(Explicit Congestion Notification,显式拥塞通知)是构建无损以太网的重要手段,能够提供端到端的流量控制。通过使用ECN功能,网络设备一旦检测到出现了拥塞,会在数据包的IP头部ECN域进行标记。被ECN标记过的数据包到达它们原本要到达的目的地时,拥塞通知就会被反馈给流量发送端,流量发送端再通过对有问题的网络数据包进行限速来回应拥塞通知,从而降低网络延迟与抖动,进而提升高性能计算集群的性能。

图3:ECN的工作机制
04、配合AFC SDN云网控制器,保证网络万无一失
星融元Asterfusion遵循SDN的设计理念、全面拥抱全开放式网络以及高性能云数据中心的策略,推出了AFC SDN云网控制器,实现了网络管理的可视化。AFC将网络中的设备状态,链路情况,以及告警信息等数据按照时间、资源、性能类型分类以图表的形式展现出来,并支持多项数据的统计功能,使客户对整体网络有一个全面直观的了解,全面把控网络状况。
同时AFC还提供灵活易用的管理界面以及界面自定义功能,客户可根据自己需求,对页面显示进行调整,方便客户一目了然地查看到所需的网络信息。平台界面友好,功能操作简单,用户可以方便、直观地对设备、资源、链路、网络拓扑图、告警等信息进行查询和操作,降低了运维操作难度。
CX-N超低时延交换机 vs. InfiniBand交换机
01、实验室测试
本次测试是在 CX-N超低时延云交换机(以下简称CX-N)和Mellanox MSB7800(以下简称IB)交换机搭建的网络上进行的。详细测试步骤请查看《解决方案-HPC高性能计算测试方案》。
HPC场景下,星融元和网络设备大厂的博弈(附对比测试方案全过程)
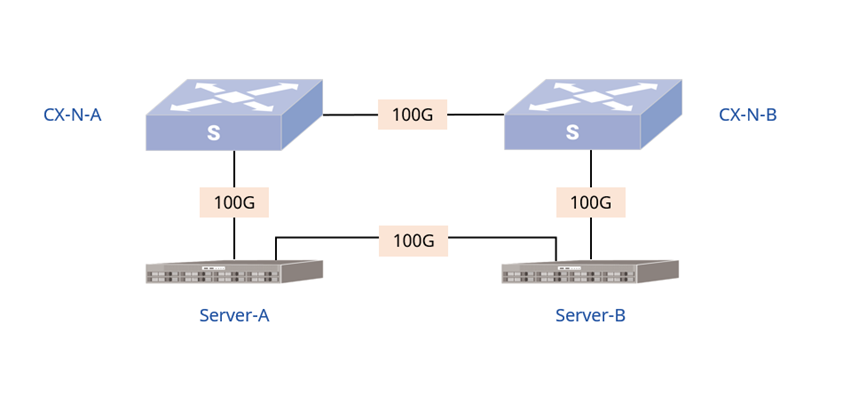
图4:对比测试环境下的物理网络拓扑一致:左边为IB交换机,右为CX-N
测试一:E2E转发
测试两款交换机在相同拓扑下E2E(End to End)的转发时延和带宽,本次方案测试点采用Mellanox IB发包工具进行发包,测试过程遍历2~8388608字节。
- CX-N交换机带宽92.25Gb/s,单台时延480ns。
- IB交换机带宽96.58Gb/s,单台时延150ns。
比较两款交换机,CX-N交换机性价比更高,并且遍历全部字节时延波动较小,多次测试数据稳定在0.1us左右。
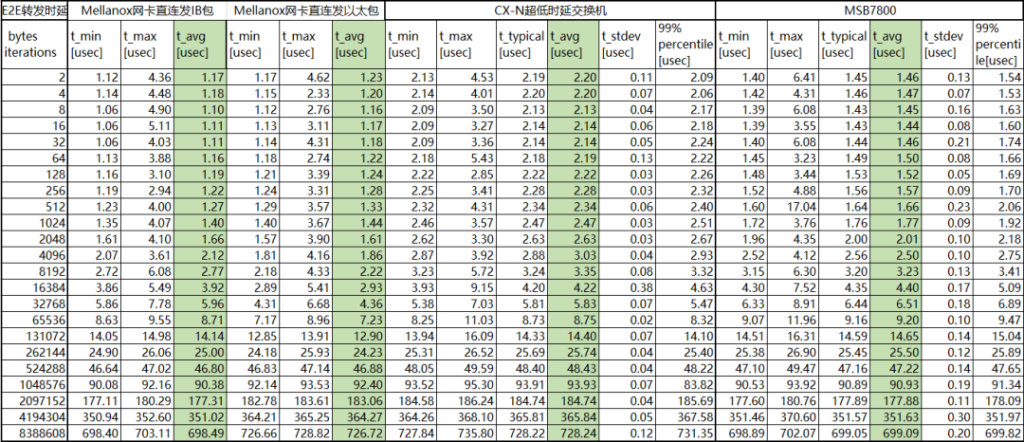
表1:CX-N vs IB 转发时延数据对比
测试二(MPI基准)
MPI基准测试常用于评估高性能计算性能。本次方案测试点采用OSU Micro-Benchmarks来评估CX-N和IB两款交换机的性能。
- CX-N交换机带宽92.63Gb/s,单台时延480ns。
- IB交换机带宽96.84Gb/s,单台时延150ns。
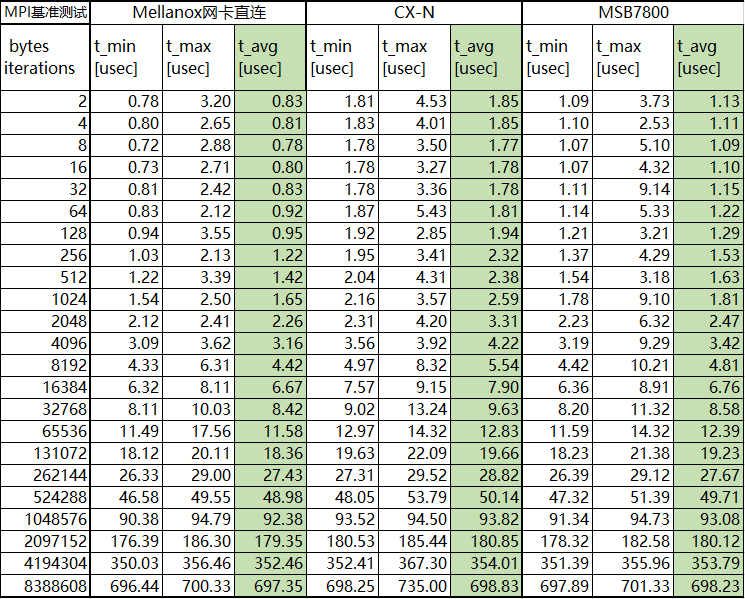
表2:CX-N vs IB MPI测试数据对比
测试三:HPC应用
在每个HPC应用中运行相同任务,并比较CX-N和IB两款交换机的运行速度。
结论:CX-N交换机运行速率较IB交换机仅低3%左右。

表3:CX-N vs IB HPC应用测试数据对比
02、客户现场测试数据对比
结论:与实验室测得结果基本一致,甚至更优。
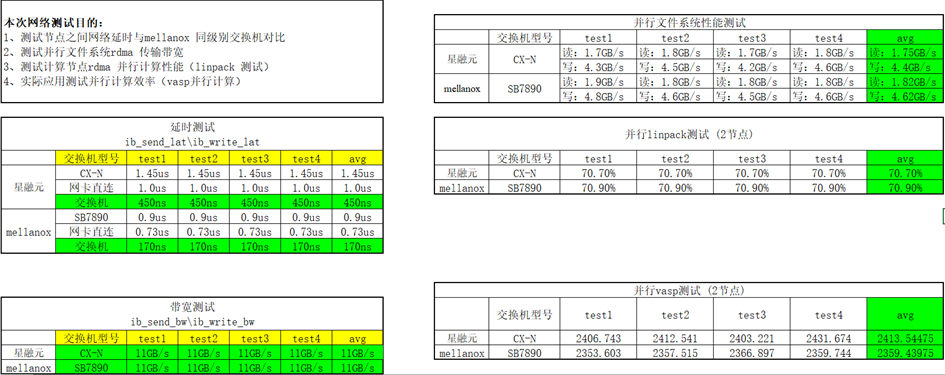
表4:某客户现场CX-N vs IB测试数据对比
星融元CX-N系列超低时延云交换机构建的超低时延无损以太网,在传统以太网上实现了原本采用昂贵的InfiniBand专用交换机的性能,帮助高性能计算方案突破网络瓶颈,为高性能计算集群提供了真正意义上的低时延、零丢包、高性能的网络。


