一文揭秘AI智算中心网络流量 – AI推理篇
本篇为“揭秘AI智算中心网络流量“系列的第二篇,前篇请参阅:一文揭秘AI智算中心网络流量 – 大模型训练篇 。有关数据存储流量的分析将于下篇呈现,敬请关注。
AI推理是指从经过训练的大模型中获取用户查询或提示的响应的过程。
为了生成对用户查询的完整响应,AI推理服务器从一次推理迭代中获取输出token,将其连接到用户输入序列,并将其作为新的输入序列反馈到模型中以预测下一个token。这个过程被称为“自回归”计算,此过程重复进行,直到达到预定义的停止标准。
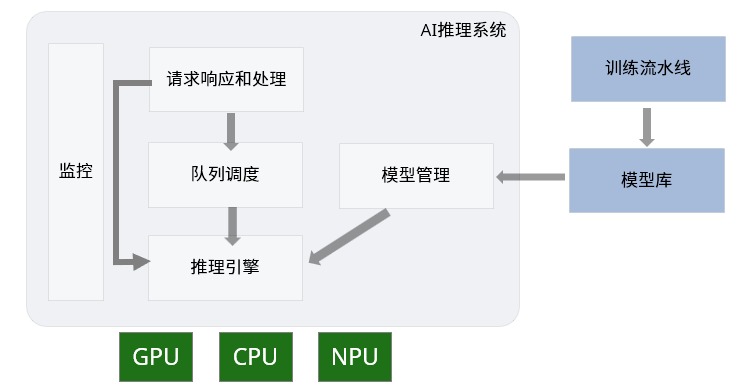
AI推理系统如何生成一次完整的响应?
⑴ 预填充/提示(Prefill):模型从用户那里获得输入序列。基于此输入,模型预测第一个输出token。
⑵ 解码(Decode):将生成的输出token连接到输入序列。更新后的输入序列被反馈到经过训练的模型中,然后生成下一个token。
⑶ 循环:解码继续进行,每个新token都是基于所有先前token的累积序列生成的。这种将输出token自回归地馈送到输入的过程确保模型在每个步骤的输出都受到所有先前token的影响,从而使其能够保持上下文和连贯性。
⑷ 终止:当模型达到停止标准时,它会终止该过程。停止标准可以是以下之一。
- 最大序列长度:一旦达到总token(输入和输出)数量的定义限制
- 序列结束 (EOS) :模型生成一个特殊token,表示文本生成的结束。
- 上下文完成:当模型确定生成的文本已根据提供的上下文得出自然且合乎逻辑的结论
AI并行推理网络流量分析
由于在预填充阶段已知整个token输入序列,因此推理加速器可以并行计算所有输入token的信息,并执行模型来预测下一个输出token。
在大模型推理时,虽然模型经过了压缩(比如4bit量化),但模型尺寸仍可能超过单个GPU的内存,这时候就需要张量并行,即使单个GPU可以容纳整个模型,张量并行可以加速推理过程。如果并发用户数较大,单个GPU来不及及时响应,就需要数据并行。
让我们再次回顾AI推理的两个关键阶段:
- 预填充(Prefill)阶段根据用户输入的prompt,生成输入token序列,并进行批处理,计算KV(Key, Value)缓存,并生成第一个输出token。这个阶段可以认为是大模型在理解用户输入,KV缓存存储了输入序列的上下文信息(为下面的Decode阶段缓存),其特点是需要大量的计算。
- 解码(Decode)阶段是一个循环过程,根据之前生成的token序列和KV缓存,计算下一个token,直到生成完整的输出。这个阶段可以认为是大模型在一个字一个字的说话。由于KV缓存的密集型计算已在 Prefill 阶段完成,因此此阶段仅处理上一阶段新生成的 token。因此,计算密集程度较低;但这一步需要从 KV缓存中读取前面所有token的Key,Value,所以需要高速的内存访问。
由于以上两个阶段对GPU的需求不同,我们可以采用Prefill-Decode解耦的方式,由2个不同类型的GPU分别承担Prefill和Decode阶段的计算任务,顺序执行。这时候就需要在两个阶段间传输KV缓存。
在生产部署时,通常结合上述几种方式。相比AI训练,AI推理只有前向传播过程,计算量相对较低,但需要快速的生成下一个token。流量产生有两个来源:
- 每次推理在Prefill GPU和Decode GPU之间传递KV缓存;
- Prefill GPU集群和Decode GPU集群分别实施张量并行,产生的中间激活的传递。不会有巨量的梯度同步流量。

假设并发用户数为U,数据并行维度为G(dp),张量并行维度为G(tp),用户输入序列的平均长度为S(in)个token,模型产生输出的平均长度为S(out)个token。
在张量并行时,前向传播产生了GPU间的网络流量,各个GPU计算出的中间激活值需要合并,由all-reduce操作进行求和。
假设模型有L层,在一次推理过程中,S(in)个输入token在模型的每一layer进行2次批量合并,共2L次,而对于每个输出Token,在模型的每个layer的中均进行2次合并,共 2xS(out) x L 次。此外,在Prefill阶段和Decode阶段之间有一次KV缓存的传递。AI并行推理网络流量如下图所示:

假设模型的隐藏状态大小为H,GPU数量为G,计算激活使用的数据格式为FLOAT16(2个字节表示一个数),每次all-reduce操作的通信量为
2 x H x (Gtp-1)x Gtp
在Prefill阶段,所有输入Token,在模型的每个layer的中均进行2次批量合并,共2xS(in)xL次。在Decode阶段,对于每个Token,在模型的每个layer的中均进行2次合并,共2xS(out)xL次。因此,U个用户的并发推理,中间激活值的总网络流量为
4 x U x(Sin+Sout)x L x H x (Gtp-1)x Gtp
另外,在一次推理中,KV缓存的大小为
4 x Sin x L x H
因此,U个用户的并发推理,KV缓存传递的网络流量为
4 x U x Sin x L x H
以Llama3-120B模型为例,模型层数140, 隐藏状态大小8192,张量并行度为4,用户prompt的平均长度S(in)为256个token,产生的输出的平均长度S(out)为4096个token。则要支持100个并发用户请求所需要的推理流量为:
4 x 100 x (256 + 4096)x 140 x 8192 x (4-1)x 4 + 4 x 100 x 256 x 140 x 8192 = 21.896TB
其中,KV缓存传递的流量虽然不大,每个用户约1.17GB,但需要在10ms左右的时间内一次传递完成。如果用1个800G端口传递,最快需要11.7ms。
AI推理对网络的需求
超高频率
AI推理流量虽然远小于训练时的网络流量,但值得注意的是,推理需要在很短的时间内完成,每个token在每一层产生2次流量,并要求在极短时间内传输完毕。假设至少要达到100token/s的推理速度,并行加速比为90%,那么每个token的推理速度要小于1ms,KV缓存需要在10ms左右完成。整个网络吞吐量应大于
4 x 100 x 140 x 8192 x (4-1)x 4/0.001 + 4 x 100 x 140 x 8192/0.01 = 5551GB/s ≈ 44.4Tbps
严格时间同步
无论是训练还是推理流量,都具有非常严格的周期性规律。基于木桶原理,如果GPU的时钟不同步,将造成同样的计算量花费不同的时间,计算快的GPU不得不等待计算慢的GPU。
开放与兼容性
AI推理进程涉及应用已训练好的AI模型进行决策或识别。对比AI训练,AI推理芯片门槛相对更低,我们的确也看到推理领域萌生出了开放生态的雏形,不少新兴初创企业加入竞争,涌现出基于不同算力架构的技术方案。
另一方面,在实际生产部署中的AI推理业务往往会与前端的业务/应用网络形成紧密配合,经由现有数据中心和云网络基础设施对外提供服务。
这便要求基础设施具备相当的开放性——网络不但要连接底层的异构算力(GPU、CPU、NPU)系统,还需要实现与上层管理系统的对接集成,例如与基于K8s的算力调度平台、已有的云管平台等等。
随着大模型的应用不断深化,AI算力部署将从训练场景逐步转向推理,推理需求也逐渐从云端迁移至边缘/终端,并呈现出垂直行业定制化的趋势。在云-边-端之间,我们需要构建一个更为均衡、通用化的网络基础设施体系。
在已被用户场景充分验证的数据中心开放云网能力之上(BGP、VXLAN、Calico容器路由、RoCE、NVMe-oF等),星融元推出的 星智AI 网络解决方案基于通用、解耦、高性能的以太网硬件和开放的SONiC软件框架,为AI智算中心提供10G-800G速率的以太网交换机,灵活支持单一速率或混合速率交换机组网,在保持极致性能的同时可编程、可升级,帮助客户构建高性能的AI智算中心网络,提供用于AI训练、推理、分布式存储、带内外管理等场景的互联能力。


- 最大支持64个800G以太网接口,共51.2T交换容量
- 超低时延,在800G端口上实现业界最强的560ns cut-through时延
- 全端口标配支持RoCEv2
200+MB大容量高速片上包缓存,显著减小集体通信时RoCE流量的存储转发时延 - Intel至强CPU + 大容量可扩展内存,运行持续进化的企业级SONiC——AsterNOS网络操作系统,并通过DMA直接访问包缓存,对网络流量进行实时加工
- INNOFLEX可编程转发引擎:可以根据业务需求和网络状态实时调整转发流程,最大程度避免网络拥塞和故障而造成的丢包
- FLASHLIGHT精细化流量分析引擎:实时测量每个包的延迟和往返时间等,经过CPU的智能分析,实现自适应路由和拥塞控制
- 10纳秒级别的PTP/SyncE时间同步,保证所有GPU同步计算
- 开放的软件架构(生产就绪的SONiC,AsterNOS)通过REST API开放全部网络功能给AI智算中心管理系统,与计算设备相互协同,实现AI算力集群的自动化部署