一文梳理:如何构建并优化GPU云算力中心?
从计算、网络到运维的全流程AI集群建设与降本工程指南

目前最常见的AI算力中心部署的GPU集群大小为 2048、1024、512 和 256,且部署成本随 GPU 数量线性增长。本文将以相对折中的1024 GPU卡(H100)的规模为例展开分析。
01 计算节点的选型
计算节点是AI算力中心的建设报价中最昂贵的部分,一开始拿到的 HGX H100 默认物料清单(BoM)往往使用的是顶级配置。不同于 DGX 是 NVIDIA 的系统品牌,HGX 作为 NVIDIA 授权平台允许合作伙伴构建定制的GPU系统。那么,根据业务实际所需,我们可从以下几个方面尝试优化成本。
| 默认 HGX H100 机箱物料报价单 | |
| 组件和服务 | 数量 |
| 接近顶级性能的英特尔 Emerald Rapids 处理器 | 2 |
| 8 H100 +4 NVSwitch HGX Baseboard + 8 SXM5 Heatsinks | 1 |
| CPU RAM (per Gbyte) | 2048 |
| Storage (per TByte) | 30 |
| 后端 ConnectX-7 NIC | 80 |
| Bluefield-3 DPU | 2 |
| 主板 | 1 |
| 机箱(机箱、布线等) | 1 |
| 冷却(CPU 散热器 + 风扇) | 1 |
| 电源 | 1 |
| 组装 & 测试 | 1 |
| OEM 增值/附加服用 | 1 |
| 合计($):270000+ | |
来源:SemiAnalysis
1、选择中端CPU
LLM 训练是一项 GPU 高度密集型工作负载,对 CPU 工作负载要求低。CPU 运行是一些简单任务,例如 PyTorch ,控制 GPU 的其他进程、初始化网络和存储调用,或者运行虚拟机管理程序等。Intel CPU 相对更容易实现正确的 NCCL 性能和虚拟化,而且整体错误更少。如果是采用AMD CPU ,则要用 NCCL_IB_PCI_RELAXED_ORDERING 并尝试不同的 NUMA NPS 设置来调优。
2、 RAM 降级到 1 TB
RAM 同样是计算节点中相对昂贵的部分。许多标准产品都具有 2TB 的 CPU DDR 5 RAM,但常规的AI工作负载根本不受 CPU RAM 限制,可以考虑减配。
3、删除 Bluefield-3 或选择平替
Bluefield-3 DPU最初是为传统 CPU 云开发的,卖点在于卸载CPU负载,让CPU用于业务出租,而不是运行网络虚拟化。结合实际,奔着GPU算力而来的客户无论如何都不会需要太多 CPU 算力,使用部分 CPU 核心进行网络虚拟化是可以接受的。此外Bluefield-3 DPU 相当昂贵,使用标准 ConnectX 作为前端或采用平替的DPU智能网卡完全可满足所需。
综合考虑前述几项成本优化,我们已经可为单个服务器降低约5%的成本。在拥有 128 个计算节点的 1024 H100 集群中,这个比率背后的金额已经相当可观。
4、减少单节点网卡数量(谨慎选择)
标准物料清单中,每台 H100 计算服务器配备八个 400G CX-7 NIC,单服务器的总带宽达到 3,200Gb/s。如果只使用四块网卡,后端计算网的带宽将会减少 50%。 这种调整显而易见可以节约资金,但多少会也对部分AI工作负载性能造成不利影响。
02 集群网络的选型
集群网络是继计算节点之后的第二大成本来源。本文举例的 NVIDIA H100 集群有三种不同的网络:
- 后端网络(计算网,InfiniBand 或 RoCEv2) 用于将 GPU 之间的通信从数十个机架扩展到数千个机架。该网络可以使 InfiniBand 或 Spectrum-X 以太网,也可以使用其他供应商的以太网。
- 前端网络(业务管理和存储网络) 用于连接互联网、SLURM/Kubernetes 和网络存储以加载训练数据和Checkpoint。该网络通常以每 GPU 25-50Gb/s 的速度运行,满配八卡的情况每台GPU服务器的带宽将达到 200-400Gb/s。
- 带外管理网络 用于重新映像操作系统、监控节点健康状况(如风扇速度、温度、功耗等)。服务器上的BMC、机柜电源、交换机、液冷装置等通常连接到此网络以监控和控制服务器和各种其他 IT 设备。
| 默认 HGX H100 集群网络 箱物料报价清单 | |
| 组件和服务 | 数量 |
| InfiniBand 计算网 | |
| Quantum-2 IB 交换机(MQM9700) | 48 |
| Nvidia LinkX IB 400G 单端口 SR4 收发器 (MMA4Z00-NS4400) | 1024 |
| Nvidia LinkX 800G 双端口 SR8 收发器 (MMA4Z00-NS) | 1536 |
| Nvidia LinkX 400G 多模光纤C | 3072 |
| 前端光纤架构成本 | |
| 主板 | 1 |
| Spectrum Ethernet Switch (SN4600) | 6 |
| Nvidia LinkX 200G QSFP56 AOC 收发器 | 384 |
| Nvidia LinkX 200G 收发器 | 256 |
| Nvidia LinkX 100G 多模光纤 | 512 |
| 带外管理网 | |
| 1GbE Spectrum Ethernet Switch (SN2201) | 4 |
| RJ45 Cables | 232 |
| 合计($):490000+ | |
来源:SemiAnalysis
1、计算网络:RoCEv2替代IB
与量大管饱的以太网解决方案相比,NVIDIA 提供的InfiniBand无疑更昂贵,但一些客户依旧笃定认为以太网性能要低得多,这主要是因为以太网需要进行必要的无损网络参数配置并且针对性调优才能发挥集合通信库的性能。
不过从对业务性能的影响角度看,目前技术背景下使用IB或是RoCEv2作为后端计算网没有并太多差异。毕竟 RoCE 实际上只是将成熟的IB传输层和RDMA移植到了同样成熟的以太网和IP网络上,这一点我们将在往后的另一篇文章来分析阐述。

大规模算力场景中用以太网替代IB组成高性能无损网络已形成业内共识,行业热点早已转向了如何更好地薅“以太网羊毛”:例如从以太网标准入手,推出下一代面向AI场景的新协议,以及一些厂商立足于现有协议标准在简化RoCE网络配置和提高可视化能力上做的创新尝试。
参阅:Easy RoCE:在SONiC交换机上一键启用无损以太网
无论是在AI训推的测试场景,还是头部云厂商已有的工程实践里,AI以太网都有了大量案例可供参考。
据统计,在全球 TOP500 的超级计算机中,RoCE和IB的占比相当。以计算机数量计算,IB 占比为 47.8%, RoCE 占比为 39%; 而以端口带宽总量计算,IB占比为 39.2%,RoCE 为 48.5%。与IB相比,我们相信有着开放生态的以太网将会得到加速发展。
目前市场上提供适用于AI场景的高性能以太网交换芯片平台主要有Broadcom Tomahawk、Marvell Teralynx和Cisco Silicon One 等,NVIDIA Spectrum 芯片仅用于Spectrum-X平台,不单独销售。以上平台都推出了51.2T,800GbE/s的尖端型号,综合来看部署数量上 Tomahawk 明显占优,转发时延性能表现 Teralynx 更胜一筹。
| 厂商 | Broadcom | Marvell | NVIDIA | Cisco |
| 芯片名称 | Tomahawk5 | Teralynx10 | Spectrum-4 | Sillcon One G200 |
| 制程工艺 | 5nm | 5nm | 定制4N工艺 | 5nm |
| 吞吐量 | 51.2Tb/s | 51.2Tb/s | 51.2Tb/s | 51.2Tb/s |
| 端口速率及配置 | 64*800Gb/s,128*400Gb/s,256*200Gb/s | 32*1.6Tb/s,64*800Gb/s,128*400Gb/s | 64*800Gb/s | 64*800Gb/s,128*400Gb/s,256*200Gb/s |
| 特色功能 | 高效SerDes设计(借助64*[PM8x100]SerDes灵活配置端口) | 延迟表现低至500纳秒 | 显著提升AI云网性能 | 采用P4可编程并行分组处理器,高度灵活可定制 |
2、前端网络:合理降低带宽速率
NVIDIA 和一些OEM/系统集成商通常会在服务器提供 2x200GbE 前端网络连接,并使用 Spectrum Ethernet SN4600 交换机部署网络。
我们知道,这张网络仅用于进行存储和互联网调用以及传输基于 SLURM,Kubernetes 等管理调度平台的带内管理流量,并不会用于时延敏感和带宽密集型的梯度同步。每台服务器 400G 的网络连接在常规情况下将远超实际所需,其中存在一些成本压缩空间。
3、带外管理网络:选用通用的以太网交换机
NVIDIA 默认物料清单一般包括 Spectrum 1GbE 交换机,价格昂贵。带外管理网络用到的技术比较通用,选择市场上成本更优的 1G 以太网交换机完全够用。
03 计算网络的架构优化
GPU集群计算网将承载并行计算过程中产生的各类集合通信(all-reduce,all-gather 等),流量规模和性能要求与传统云网络完全不同。
NVIDIA 推荐的网络拓扑是一个具有无阻塞连接的两层胖树网络,理论上任意节点对都应该能同时进行线速通信。但由于存在链路拥塞、不完善的自适应路由和额外跳数的带来的通信延迟,真实场景中无法达到理论最优状态,需要对其进行性能优化。
轨道优化(Rail-optimized)架构
轨道优化架构下,4台服务器的32张 GPU 卡不再是连接到 TOR 交换机,而是来自32台服务器的同卡号 GPU 连接各自的轨道交换机——即32台服务器的所有 GPU#0 都连接到 Leaf 交换机#0,所有 GPU#1 都连接到 Leaf 交换机#1,依此类推。
架构.png)
轨道优化网络的主要优势是减少网络拥塞。因为用于 AI 训练的 GPU 会定期并行底发送数据,通过集合通信来在不同GPU之间交换梯度并更新参数。如果来自同一服务器的所有 GPU 都连接到同一个 ToR 交换机,当它们将并行流量发送到网络,使用相同链路造成拥塞的可能性会非常高。星融元(Asterfusion)给出的1024卡,128计算节点 Scale-out 网络方案正是基于轨道优化后的架构,其中采用了24台 CX864E-N(51.2T的单芯片盒式交换机,8台作为Spine,16台作为Leaf),产生跨节点通信的同卡号GPU之间只会相距一跳。
参阅:星融元发布 51.2T 800G 以太网交换机,赋能AI开放生态
CX864E-N交换机1.png)
CX864E-N交换机2.png)
如果追求极致的成本优化,对于一个32到128个节点的计算集群甚至可以设计只有单层轨道交换机的Rail-only网络,理论上建网成本可以节约高达75%。
星智AI网络解决方案.png)
确定合适的超额订阅率
轨道优化拓扑的另一个好处可以超额订阅(Oversubscription)。在网络架构设计的语境下,超额订阅指的是提供更多的下行容量;超额订阅率即下行容量(到服务器/存储)和上行带宽(到上层Spine交换机)的比值,在 Meta 的 24k H100 集群里这个比率甚至已经来到夸张的7:1。
通过设计超额订阅,我们可以通过突破无阻塞网络的限制进一步优化成本。这点之所以可行是因为 8 轨的轨道优化拓扑里,大多数流量传输发生在 pod 内部,跨 pod 流量的带宽要求相对较低。结合足够好的自适应路由能力和具备较大缓冲空间的交换机,我们可以规划一个合适的超额订阅率以减少上层Spine交换机的数量。
但值得注意的是,无论是IB还是RoCEv2,当前还没有一个完美的方案规避拥塞风险,两者应对大规模集合通信流量时均有所不足,故超额订阅不宜过于激进。(而且最好给Leaf交换机留有足够端口,以便未来 pod 间流量较大时增加spine交换机)
现阶段如果是选用基于以太网的AI网络方案我们仍推荐1:1的无阻塞网络设计。
04 NVMe 存储
物理服务器数量
为了实现高可用性,大多数存储厂商都会建议部署至少 8 台存储服务器。8 台存储服务器每台可提供 250GB/s 到 400GB/s 的存储带宽,足以满足在 1024 台 H100 上运行的 AI 工作负载。我们可以从最小可用数量开始,但需要注意在存储系统上留出足够的端口、NVMe 驱动器托架、电源和机架空间,以便后续按需扩展。
存储网络
常见的方案是构建专门的200G无损以太网作为存储网络以确保性能,存储前后端网络在物理上合一。

2.png)
存储服务器也可以在后端计算网上运行——通常是将IB网卡绑定到 GPU 0来充当存储网卡。虽然存储基准测试的延迟和带宽表现很好,但在实际AI工作负载中将影响 GPU 0 的性能(IB网卡同时作为存储网卡会有流量冲突)。当存储集群中的磁盘发生故障将触发重建,会在计算网上造成大量的流量,形成更严重的拥塞。
05 带内管理
为了运行高可用的 UFM 和 CPU 管理节点,我们建议部署至少两个通用 x86 服务器,使用25GE/10GE以太网链路连接所有计算节点和管理节点,并接入外部网络。
1.png)
2.png)
默认的NVIDIA Superpod 架构中包含了“NVIDIA AI Enterprise”或“Base Command Manager (BCM)”,其建议零售价为4,500 美元/GPU。BCM 是一个提供 AI 工作流和集群管理的软件包,这一部分软件费用可以考虑剔除后选择其他平替方案,或交由用户自定义。
此外带内管理系统还涉及到其他 IT 设备,例如防火墙、机架、PDU 等,这部分价格不会显著增加集群建设支出。
06 带外管理
带外管理系统主要是通过智慧平台管理接口(IPMI)去监视、控制和自动回报大量服务器的运作状况。IPMI可独立于操作系统外自行运作,并允许管理者在受监控的系统未开机但有接电源的情况下进行远程管理,但这种监控功能主要集中在硬件级别。
不同于带内管理,带外管理构建了单独的网络承载物理设备管理流量,不会承载业务流量。我们一般是每GPU计算节点和存储节点配置1条1 GE 链路连接IPMI和后端管理平台。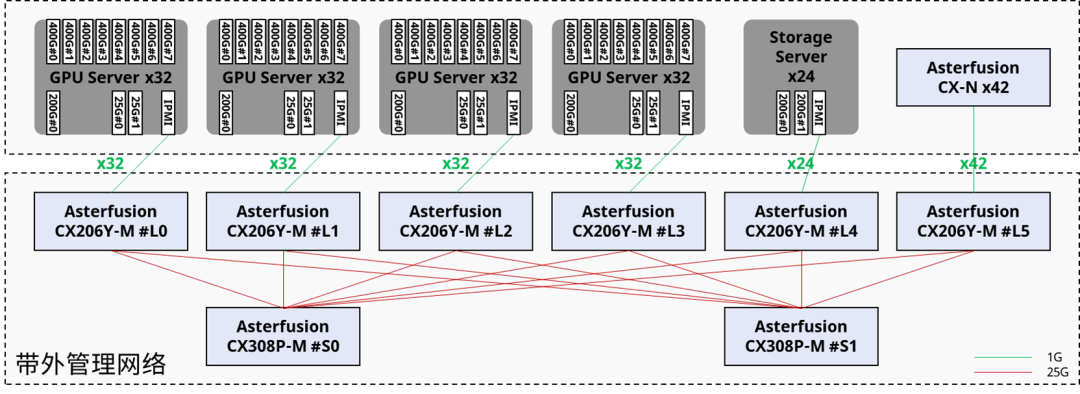
07 驱动和业务调度程序
GPU驱动程序
必要的 GPU 驱动程序有 cuda-drivers-5xx 和 fabricmanager-5xx 以及 cuda-toolkit-12-x。
- Cuda-drivers-5xx 是 ubuntu/Linux 与 GPU 交互所需的内核空间驱动程序
- fabricmanager-5xx 是一个负责配置节点内 NV 链路结构
- Cuda-toolkit-12-x 包含所有用户空间工具和 API
网络驱动程序
MLNX_OFED
每个 GPU 服务器上都需要安装 Mellanox OpenFabrics Enterprise Distribution (MLNX_OFED) 驱动程序。此软件包是 ConnectX-7 InfiniBand NIC 的驱动程序,用于执行 RDMA(远程直接内存访问)和 OS 内核旁路。
GPU Direct RDMA
这是一个包含在 cuda-drivers-5xx 中的附加内核驱动程序,默认情况下未启用。如果没有此驱动程序,GPU 将需要先在 CPU RAM 中缓冲消息后才能发送到 NIC。
启用 GPUDirect RDMA 的命令是 sudo modprobe nvidia-peermem。
NVIDIA HPC-X
主要用于进一步优化 GPU 与 NIC 的通信。
如果没有上述软件包,GPU 只能以 80Gbit/s 的速度收发流量,启用这些软件包后点对点收发速率应可达到 391Gb/s左右。
业务调度和启动程序
绝大部分的最终用户会希望拥有一个开箱即用的调度程序,可以基于SLURM 、K8s 或者其他供应商的软件平台。从0到1手动安装并调试以上平台,对于不是专精于此的工程师至少需要花费1-2天时间,因此闲置的 GPU 资源对于客户都是实打实的支出。
08 多租户隔离
参考传统CPU云的经验,除非客户长期租用整个GPU集群,否则每个物理集群可能都会有多个并发用户,所以GPU云算力中心同样需要隔离前端以太网和计算网络,并在客户之间隔离存储。
基于以太网实现的多租户隔离和借助云管平台的自动化部署已经有大量成熟的方案。如采用InfiniBand方案,多租户网络隔离是使用分区密钥 (pKeys) 实现的:客户通过 pKeys 来获得独立的网络,相同 pKeys 的节点才能相互通信。
09 GPU的虚拟化
与传统CPU云不同的是,AI用途的GPU云租户通常会将每个 GPU 计算节点作为一个整体来租用,深入到节点内部的更细粒度的虚拟化并无绝对必要。但为了进一步提高GPU资源利用率,很多人还是会选择GPU虚拟化,目前,GPU虚拟化技术一般分为三种:软件模拟、直通独占(pGPU)、直通共享(如vGPU、MIG)。
AI算力租赁场景的虚拟化程度一般是到单卡层次,即直通独占(pGPU)——利用 PCIe 直通技术,将物理主机上的整块GPU显卡直通挂载到虚拟机上使用,原理与网卡直通类似,但这种方式需要主机支持IOMMU。(一种内存管理单元,它将具有直接存储器访问能力的I/O总线连接至主内存。如传统的MMU一样,IOMMU将设备可见的虚拟地址映射到物理地址)
pGPU直通方式相当于虚拟机独享GPU,硬件驱动无需修改。因为没有对可支持的GPU数量做限制,也没有阉割GPU功能性,大多数功能可以在该直通模式下无修改支持。
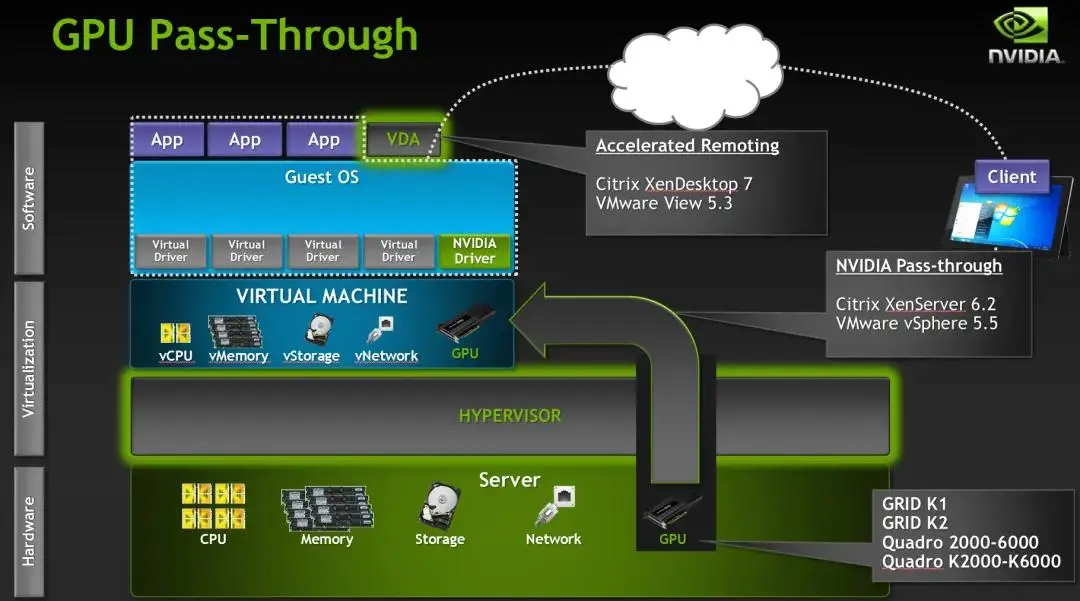
值得一提的是,NCCL 和 NVIDIA 驱动程序在 GPU 虚拟机内运行时无法自动检测 NUMA 区域和 PCIe 拓扑,需要通过 NCCL_TOPO_FILE 变量手动传递 /etc/nccl.conf中的 NUMA 区域和 PCIe 拓扑文件,否则 NCCL 性能将仅以应有带宽的 50% 运行。
10 监控方案
监控面板
在监控方面,我们至少建议通过 Prometheus + Grafana 构建一个集中的监控面板,以便用户跟踪 GPU 温度、电源使用情况等BMC指标,XID错误,甚至将业务和网络统一监测。
计算节点的监控包括在每个 GPU 节点上安装一个 IPMI 和 DCGM Exporter,然后在管理节点上部署 Prometheus 与 GPU 上的 Exporter 通信,并将数据存储在数据库中。Grafana 连接到 Prometheus 对收集来的数据进行可视化呈现。
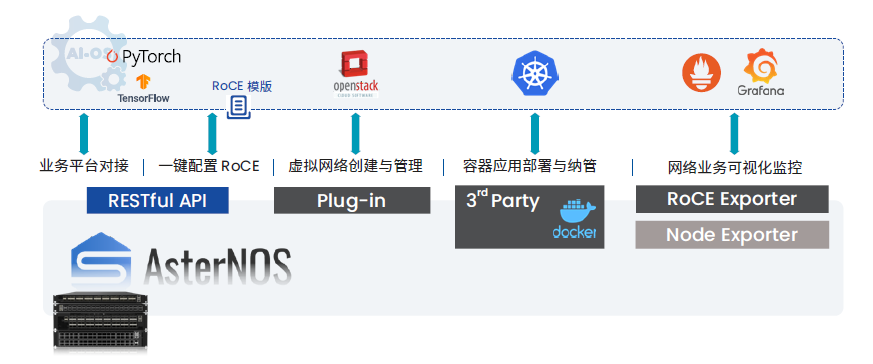
网络侧的监控类似,在这种场景下采用SONiC交换机的优势明显,因其软件环境本身就是开放的容器化架构,我们能以 docker 形式在交换机运行 exporter 取得所需设备状态数据,还可借助RESTful API调用网络能力集成进上层管理平台。
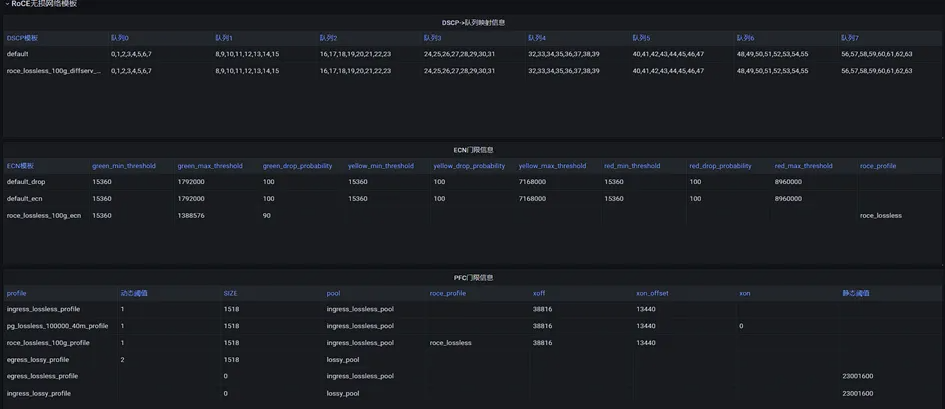
另外,结合带内网络遥测(INT)能力还可对RoCE网络实现亚秒级的精细监控,用以辅助网络拥塞控制。
常见错误
- 诊断消息(dmesg)两个常见 dmesg 消息是电缆被拔出以及 NIC 或者光收发器过热。
- 静默数据损坏 (SDC)没有收到诊断消息等错误报告,但却输出错误的矩阵乘法结果。这些错误称为静默数据损坏 (SDC)。确定 GPU 上是否有该问题的最简单方法是使用 Nvidia DCGMI 诊断级别 4 工具 sudo dcgmi diag -r 4。该工具将捕获 95% 的最常见静默数据损坏问题。
- NCCL故障 常见NCCL故障包括死锁和停滞,可能会导致训练作业暂停 30-35 分钟, 而后 PyTorch 的 NCCL watchdog 会终止整个训练作业。对此可以考虑添加电力消耗监控来检查AI作业是否正常运行。更多NCCL排障请参考:https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/troubleshooting.html
- Infiniband UFM 的错误代码 常见如 110(符号错误)、112(链接中断)、329(链接中断)、702(端口被视为不健康)和 918(符号位错误警告)。遇到上述任何错误代码,应立即联系网络技术工程师进一步调查。
11 部署验收和日常维护
集群规模的验收测试应持续至少 3-4 周,尽可能排除早期失效期出现的节点组件故障。AI训练非常依赖网络、HBM 和 BF16/FP16/FP8 张量核心,而目前常用的高性能计算测试工具,例如LINPACK(国际上使用最广泛的测试浮点性能的基准测试)不会大量使用网络,也不会占用太多 GPU 的 HBM 内存,而是仅使用和测试 GPU 的 FP64 核心。稳妥起见,我们建议验收测试尽量以模拟真实业务的方式展开。
NCCL-TEST
nccl-test 工具是 NVIDIA 开源的一项用于测试 NCCL 集合通信的工具,我们建议在正式运行业务之前先使用nccl-test来检测集合通信是否正常、压测集合通信速率等,看看否存在任何性能不足或下降。关于nccl-test日志的分析我们将在接下来的主题中展开。
日常维护
集群中最常见的问题包括收发器抖动、GPU掉线、GPU HBM 错误和 SDC等。大多数情况下,这些问题只需简单地启动物理服务器的硬重启,或者断电后重启即可解决。重新插拔收发器或清除光纤电缆上的灰尘也可以解决一些意外故障。更复杂的情况请交给厂商技术服务团队处理。
产品型号: 星融元(Asterfusion)CX864E-N (64 x 800G OSFP)
功能特性:RoCEv2, PFC, ECN, DCBX ……
应用场景:GPU算力集群,分布式存储
最后更新:2026-05-18
产品型号: 星融元(Asterfusion)CX664D-N(64 x 200G QSFP56/QSFP28/QSFP+)
功能特性:RoCEv2, PFC, ECN, DCBX ……
应用场景:分布式存储,数据中心,GPU算力集群
最后更新:2026-05-26




