SONiC交换机 PK IB交换机,是“越级碰瓷”还是“有点东西”?
聊起AI、HPC或其他无损传输网络场景,RoCE or IB 无疑是个老生常谈的话题了。关于两种协议栈的区别和联系,我们之前有写过一篇详尽的文章(请参阅:RoCE与IB协议栈对比解析)。简言之:RoCE 实际上只是将成熟的IB传输层和RDMA移植到了同样成熟的以太网和IP网络上。
IB因其是最早支持RDMA的协议,起步早,技术成熟,在一整套专用软硬件体系加持下,可提供极致的低时延传输性能,但同时也因供应商唯一,导致整体TCO较高。
与之相对的,RoCEv2在互操作性和成本上的显著优势被认为更适合大规模部署,例如今年xAI公司在美国孟菲斯建设的十万卡AI集群,便是使用400GbE以太网构建的无损高速网络。
开放网络能否平替IB?
援引Amazon高级首席工程师Brian Barret的话,AWS之所以放弃IB方案主要是因为:
“要满足资源调度和共享等一系列弹性部署的需求,专用的IB网络集群如同汪洋大海中的孤岛”
既然追求标准开放与多厂商兼容已是业界共识,以SONiC为代表的开放网络在顶级大厂云的商业化部署也有目共睹了,我们不禁要问:到了性能要求更苛刻的AI/HPC场景,支持RoCE的开放网络能否担得起 “IB平替” 的期待?
或者再进一步,开放架构的力量能否赋能更广大的数据中心建设运营者? 比如简化受人诟病的RoCE网络部署调优,提高运维诊断能力等等…或者更多可能?
铺垫有点多了,上干货!
测试背景
我们挑选了三大典型场景下的SONiC交换机 (RoCE) 和IB的现场实测对比结果,涉及AI训练,HPC和分布式存储环境。测试结果保真保鲜,同时也会简要附上方法步骤,希望能对各位读者有所参考价值。
-
AI智算场景:E2E转发测试、NCCL-TEST、大模型训练网络测试 -
HPC场景:E2E转发性能、MPI、Linpack、HPC应用(WRF、LAMMPS、VASP) -
分布式存储:FIO工具压测读写性能
当然,正经搞对比测试不能不讲武德,跟IB正面对垒的选手绝不能是随便淘个白盒跑跑社区版软件的野生玩家。被测RoCE交换机为星融元CX-N系列,产品采用超低时延硬件平台,搭载企业级SONiC发行版AsterNOS,全端口标配支持RoCEv2,以及EasyRoCE Toolkit。
EasyRoCE 是星融元依托开源、开放的网络架构与技术提供的一系列实用特性和小工具。从前期规划实施到日常运维监控,EasyRoCE 简化了各环节的复杂度并改善了操作体验,更提供二次开发和集成空间,供网络架构师充分利用开放网络最新技术成果。
Toolkit 更新传送门:官网详情页 | 统一监控面板(UG) | 高精度流量监控(RTR)| 一键RoCE部署(ORD)

测试结论
先说结论,开放架构的星融元CX-N系列交换机(RoCE)与IB交换机的端到端性能基本持平,局部超越。
AI智算场景
1、E2E转发带宽达到网卡直连速率上限,单机转发时延低至560ns
2、双机16卡运行NCCL-test (ring算法),通过两台被测交换机测得最大总线带宽与IB交换机基本一致(约195GBps),且带宽使用率与网卡直连情况一致,已达到服务器Scale-out网络传输速率上限。
3、轨道优化拓扑下,双机16卡 Llama2-7B(样本序列长度2048)的单次训练用时与网卡直连以及IB组网的测试结果一致。
HPC 场景
1、E2E时延表现与IB交换机基本持平,差异保持在纳秒级。
2、MPI基准测试,E2E表现与IB交换机基本持平,时延差异保持在纳秒级。
3、Linpack效率与使用同规格IB交换机组网结果基本相当,差异约在0.2%。
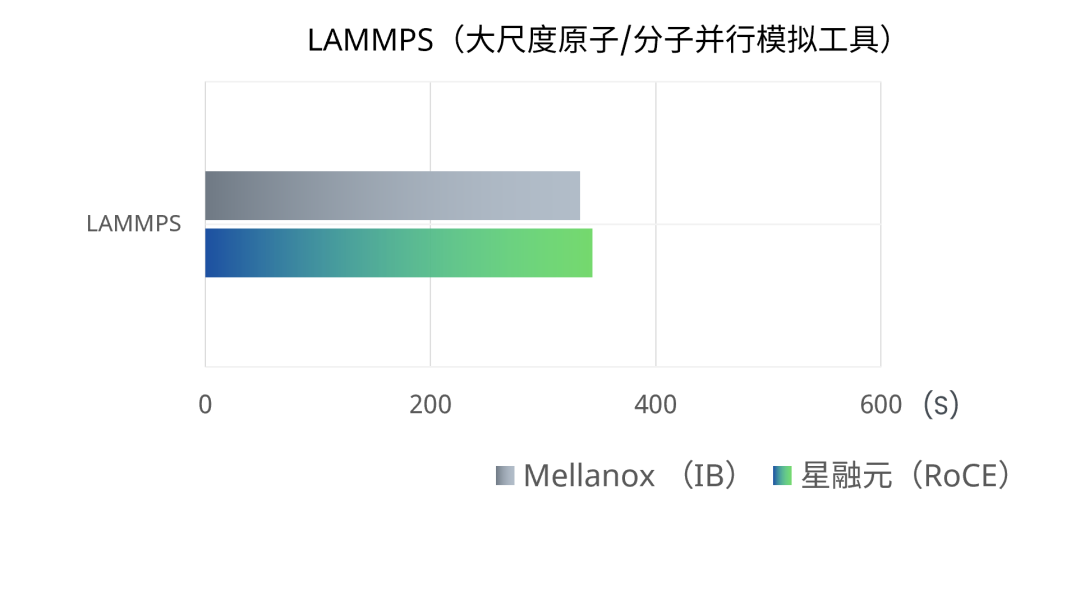
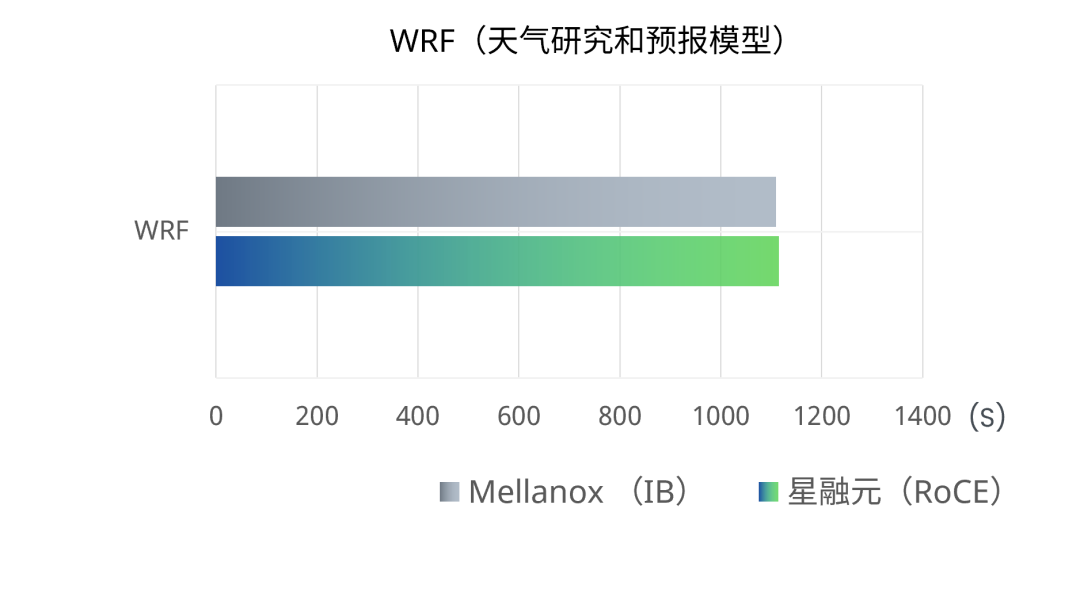
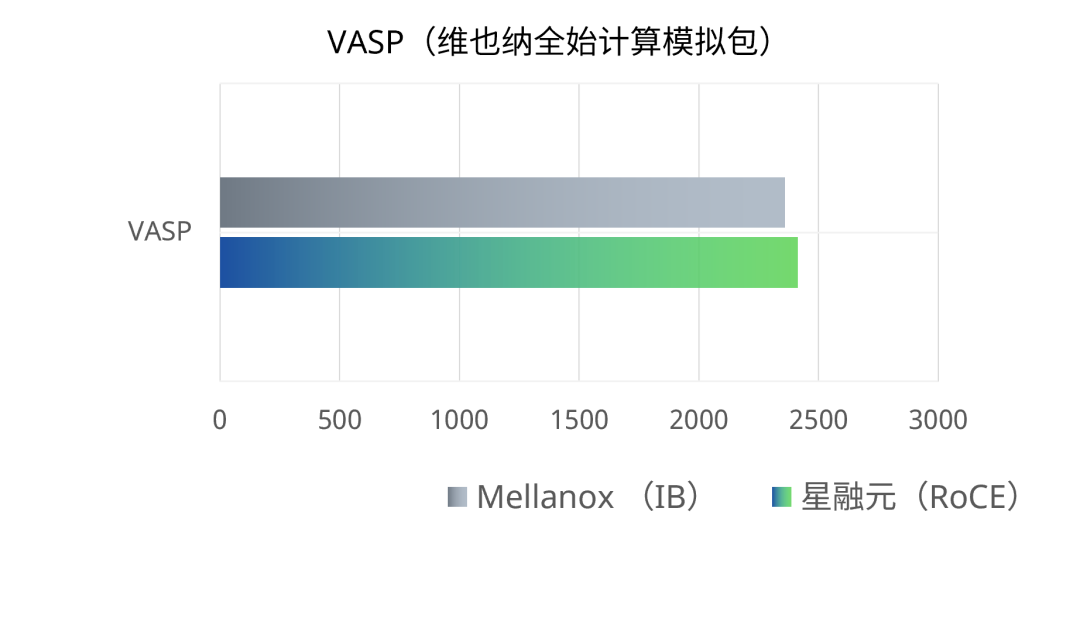
4、HPC集群内并行运行WRF、LAMMPS和VASP应用,RoCE交换机完成一次相同计算任务的平均用时与使用IB交换机组网的用时基本相当,两者差异在0.5%~3%之内。
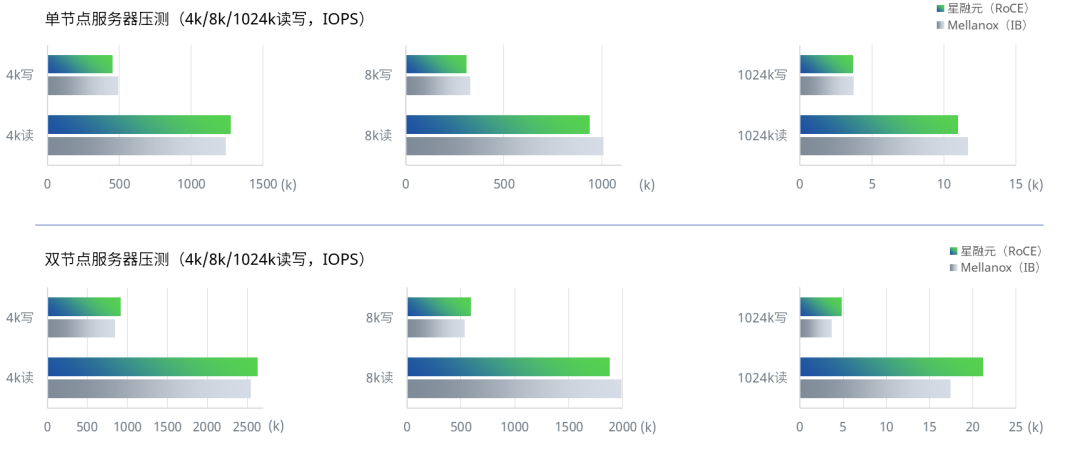
分布式存储场景
采用RoCE组网的分布式存储系统读写性能(IOPS)与采用同规格IB组网持平,部分条件下优于IB。