
DeepSeek优化徒劳?揭秘99%的AI推理集群都适用的组网设计
DeepSeek的优化,精细但门槛极高
作为开源周的“彩蛋”,DeepSeek于上周六展示了采用混合专家模型(MoE)DeepSeek-V3 / R1 所使用的推理架构的整体方法——从增大吞吐和降低时延的目标出发,再次优化了PD分离架构,不过暂时没有开源代码。
与Llama等采用张量并行(TP)的Dense(稠密)模型不同,混合专家(MoE)模型通过组合多个专家模型来处理复杂任务,每个专家模型专注于输入数据的不同部分,每次计算任务只需激活特定专家(而非整个神经网络)。
DeepSeek-V3 / R1 的推理系统架构一方面引入了更复杂的跨节点和多节点的传输提升计算效率和改善内存墙,同时也通过异步通信和流水线调度设计,确保由此增加的通信开销被计算任务掩盖。
值得注意的是,根据官方公布的信息,若要充分发挥DeepSeek MoE 模型的能力,起步资源是320卡,且不论在未开源的情况下面临的技术挑战。
综合成本和需求考量,上述面向专家并行的推理系统优化仅在部分toC云计算场景具备一定研究意义。现阶段toB行业大模型以及边缘计算场景仍以Dense模型为主,需要高并发的大集群平台部署可延续现有主流的算力网络设计思路,面向本地低并发需求则可采用大内存单机部署方案。
回顾:AI推理集群的PD分离和流量特征
大模型的推理任务一般分为两个阶段,一是Prefill,处理所有输入的 Token,生成第一个输出 token 和 KV cache,是算力密集型;二是Decode,利用 KV Cache 进行多轮迭代,每轮生成一个 token,需要反复读取前面所有token的 Key 和 Value,瓶颈在于内存访问。
从用户实际体验层面看,推理过程中最关键的指标是 “第一个Token的延迟” (Time To First Token, TTFT) 和后续token输出的延迟(Time Per output Token, TPOT)。
如果 Prefill 和 Decode 两个阶段在同一张GPU卡上运行,则容易发生资源争抢影响到 TTFT 和 TPOT 表现,尤其是当用户输入一段长 prompt 时,不光需要较多算力来支撑prefill运算, 也需要大内存来存储 KV Cache。

因此,业界通常采用 Prefill-Decode 分离的架构:用高算力卡做 Prefill(prefill server), 低算力卡做 Decode(decode server), Prefill节点在完成计算传输 KV cache 后即可释放本地显存。
AI推理系统的 Scale-out 组网设计
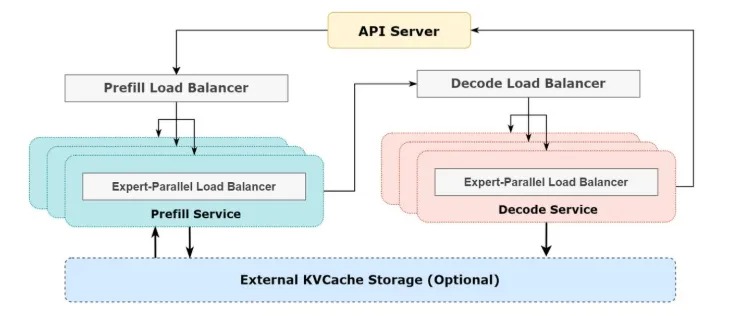
推理集群的工程部署方面,由于 Prefill 和 Decode 采用的GPU并行方式不一样,Prefill和Decode集群是相互独立的,但两个集群间需要互联以同步KV cache。从两个阶段的输入输出来看,Prefill 流量的特征是低频大流量,要求大带宽;Decode 阶段流量的特征是高频小流量,要求低时延。
1、分离网络架构
- 分为Prefill网络和Decode网络,分别负责本集群内流量,两个集群之间的流量通过互联网络实现
- 两个网络分别运维管理,但Prefill和Decode GPU之间的流量至少需要3跳
2、统一网络架构
- 单个网络同时负责集群内和集群间流量
- 网络统一运维管理,Prefill和Decode GPU之间流量可一跳直达
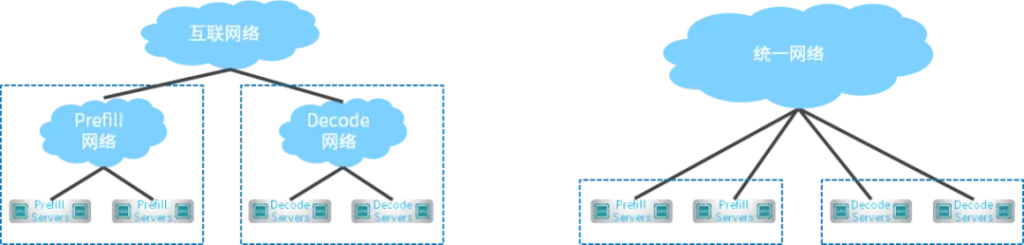
我们推荐采用统一网络架构,借助 QoS、自适应路由技术对 Prefill 和 Decode 流量分别处理。
Rail-only 拓扑
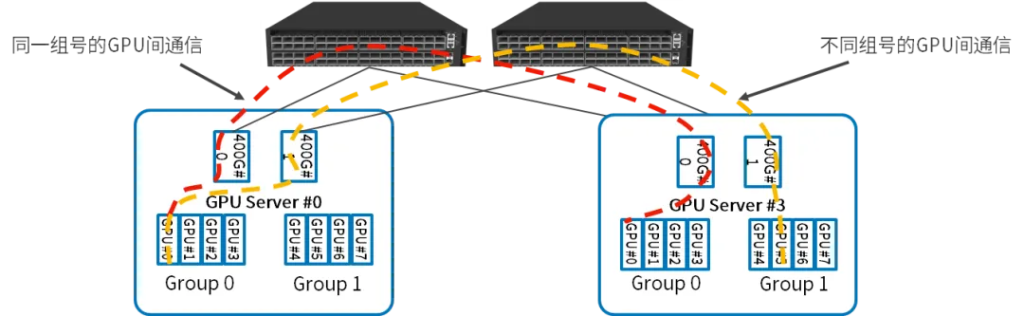
- GPU服务器内部:每四个GPU作为一组,共享一个并行推理网卡,连接到同一个PCI Switch,两组GPU之间的通信通过两个PCI Switch之间的直连通道完成;
- GPU服务器之间:同一组号的GPU之间的通信通过交换机直接完成;不同组号的GPU之间的通信,先通过PCI Swtitch将流量路由到另一组的网卡,然后通过交换机完成
小规模并行推理网络拓扑
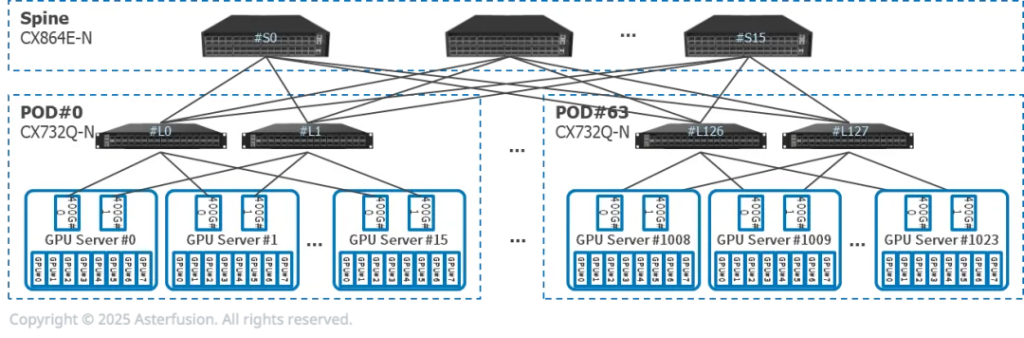
- 每台推理服务器有8张GPU,2张400G网卡,双归连接到两台CX732Q-N
- 16个推理服务器(128张GPU)和2个CX732Q-N组成一个PoD。Prefill和Decode服务器可能属于不同PoD
- 可横向扩展至64个PoD
中大规模并行推理网络拓扑
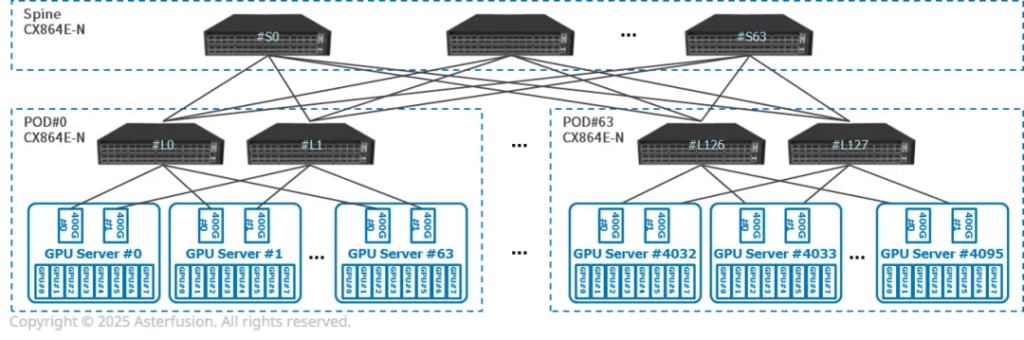 每台推理服务器有8张GPU,2张400G网卡,双归连接到两台CX864E-N
每台推理服务器有8张GPU,2张400G网卡,双归连接到两台CX864E-N- 64个推理服务器(512张GPU)和2个CX864E-N组成一个PoD,Prefill和Decode服务器在同一个PoD,服务器间一跳可达
- 可横向扩展至64个PoD
拓扑设计仅供预览参考,方案均采用星融元(Asterfusion)提供的CX-N系列 AI智算网络产品:基于SONiC的开放NOS(AsterNOS)+ 100G/200G/400G/800G 超低时延以太网交换机硬件,全端口支持 RoCEv2 & EasyRoCE Toolkit。了解产品详情或项目定制方案请与我们联系。


