
A-Lab 杂谈 | 十年老网工,为啥这次没把智算服务器一次配通?
A-Lab 是星融元服务于新一代网络运维工程师的资讯专栏,你可以在这里找到各类基于开放网络技术架构的配置指导和技术分享。访问地址:https://asterfusion.com/alab-for-netdevops/
十年弹指一挥,当年的爆款热词“云计算”已然能搭上“传统” 二字当前缀;
十年弹指一挥,机房滚滚轰鸣声中,网工小王不知不觉熬成了老王;
老王不解啊,十年弹指一挥,咱亲手上架的服务器不说上千也有大几百,不就多了几张网卡,配个智算服务器怎会卡了壳?!
客官别笑,通用云计算中心与智算中心在主机侧网络架构层面的确存在显著差异,老网工偶尔走点弯路也是在所难免的啦。今天就让我们快速捋一捋其中缘由。
为啥出错?
传统CPU服务器多采用单网卡出口设计,通过OS内核协议栈实现网络报文转发,其网络拓扑相对简单,主要满足虚拟化资源的弹性调度需求。
源于AI训练任务对网络带宽的严苛要求,智算中心的GPU服务器普遍采用多网卡出口架构,用于接入参数网、存储网、业务网和带外管理网,其中通常会有8张网卡用于接入参数网,或称计算后端网络。而跨服务器的通信大多发生在同轨(Rail)的网卡/GPU之间。(请参考:关于智算的“多轨道网络架构”)
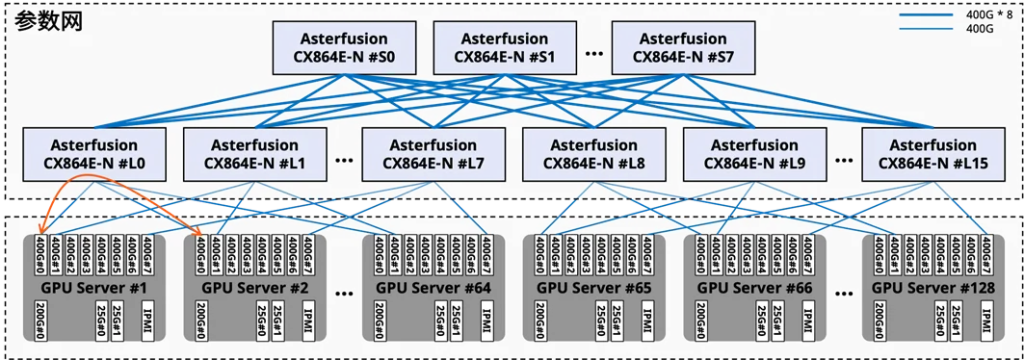
老王遇到的机间通信失败问题主要发生在以下两种场景:
场景1:
智算业务报文从管理网段发出。两台GPU服务器A和B的8张网卡都接入到一张参数网,对应的网卡A1到A8、B1到B8,它们都分配到不同的网段,同轨网卡之间有互通需求(A1-B1,A2-B2…)
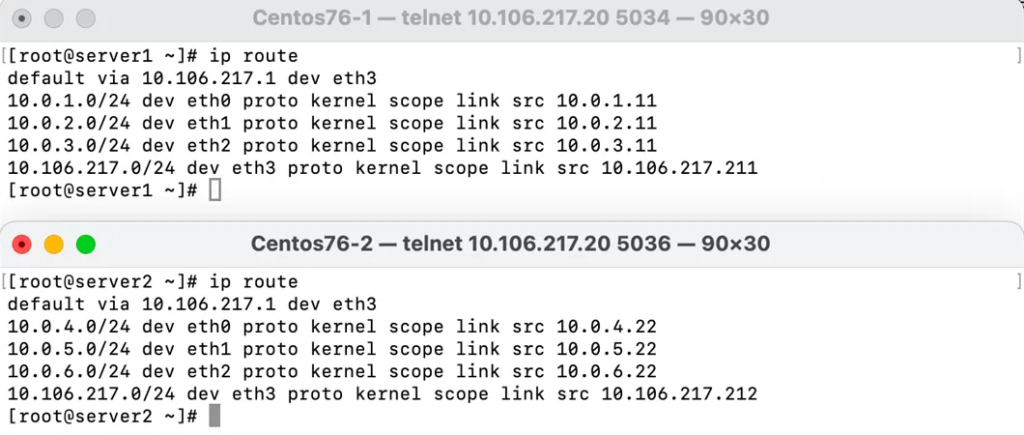
如果没有进行路由规划,通常在GPU服务器A的系统上会看到默认路由是业务网的,8个子网A1~8会产生8条对应的网段路由,报文会命中A的默认路由从管理网段发出,此时A1和B1是无法直接通信的。
场景2:
回程通信失败。如果网卡A1到A8、B1到 B8 都分配到同一个网段下的不同IP,在这种情况下在服务器B上通过B1尝试与A1通信,会发现报文可以到达A1,但是回包会命中默认路由之外的代价最低的路由,很可能会从其他7张网卡中的一张出去,导致通信失败。
通信失败情况下可能的系统路由配置:
应对思路
当传统路由设置方法在智算环境下失效,一个可行的应对方式是提前规划GPU服务器内的路由,借助Linux的多路由表和策略机制实现更加灵活、精细的流量控制和路由管理功能。
具体而言:在Linux内增加一个自定义路由表,并通过策略路由告知系统,特定源地址的报文根据这张自定义路由表转发,并在该表中增加一条指定目的网段的表项(例如前往10.0.5.0/24的报文从指定网卡发出)。
- 多路由表(Multiple Routing Tables):Linux支持多张路由表,这些路由表可以通过不同的标识符来区分,每张路由表中可以包含一组路由规则。Linux系统默认会存在一个主路由表,当不特别指定的时候路由规则会写入默认路由表。
- 策略路由机制(Policy Routing):根据数据包的源目的IP、网卡等条件来选择合适的路由表进行转发。
更高效的实现方式
更高效的办法,当然是用脚本工具批量自动配置啊!
星融元(Asterfusion)AI智算网络解决方案中包含的EasyRoCE Toolkit – IRM工具(In-Node Route Map,GPU服务器内部路由规划)正是用于解决多网卡路由问题——根据已有的IP地址规划表,自动生成并对集群内所有GPU服务器下发内部路由规划和配置。
IRM工具运行过程中需要通过SSH和集群中的所有GPU服务器进行交互,一般运行在管理节点上。
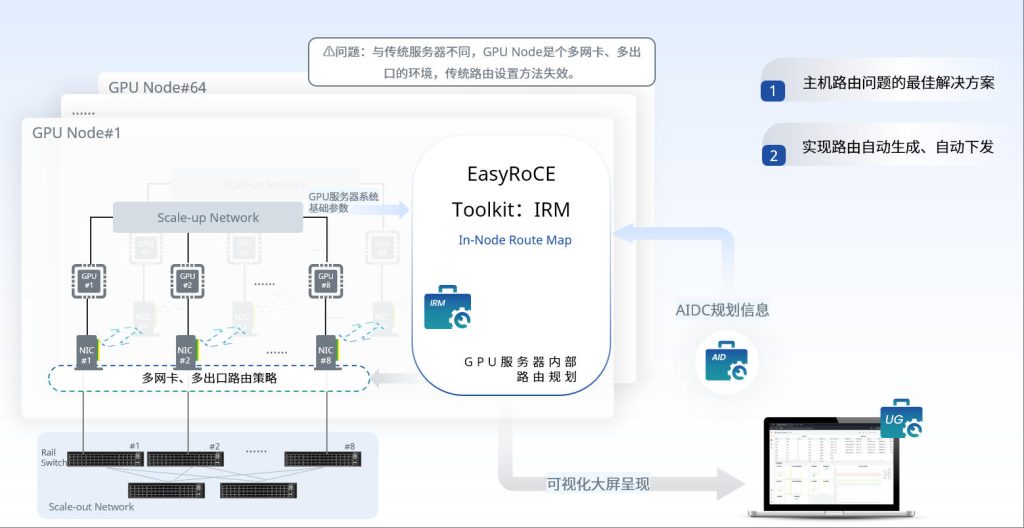
网工老王仅需完成三步微操:
1、将IRM工具上传到管理节点;
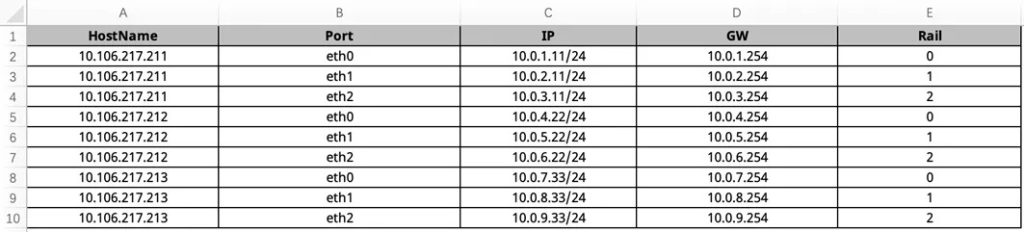
2、指定需要解析的路由规划信息文件。该文件可在EasyRoCE-AID (AI Infrastructure Descriptor,AI基础设施蓝图规划)工具引导下手动填写,形式为下图所示的excel表格,主要包含IP和接口地址规划、Rail平面划分等构造智算网络的必备信息;
3、运行IRM工具脚本。等待上述规划信息完成转换重组后,IRM工具会生成包含路由配置的JSON文件并下发到集群,随后网络运维人员即可查验到所有GPU服务器内部的策略路由都已成功生效,同一个Rail平面内的网段按照预期正常互通。此外,该阶段生成的JSON文件亦可复用于其他客户自定义/第三方工具。


