
解锁AI数据中心潜力:网络利用率如何突破90%?
01 传统以太网为何难以突破利用率瓶颈?
网络利用率是数据通信网络的关键指标,定义为实际传输的流量与可用带宽之比。在AI数据中心网络中,网络利用率会直接影响训练完成时间(Job Completion Time)、推理吞吐量(Inference Throughput)等业务性能,因此这一指标尤为关键。
传统以太网的利用率大约在35%~40%,这一现象由多种原因造成:
- 流量多样化:流量具有随机性和不确定性,各种包大小、速率和持续时间的流量同时存在。网络需要为最繁忙的流量高峰而设计,从而导致在空闲期间网络利用率较低。
- 网络设计存在阻塞:传统的接入-汇聚-核心网络的多级设计中,各级之间存在收敛比。要么接入链路空闲,要么汇聚链路拥塞,网络性能难以得到充分优化。
- 网络传输存在损失:当网络发生拥塞时,队列尾部的报文会被丢弃,导致端到端之间的数据重传,进一步浪费了网络带宽。
- 流控机制感知能力弱:流控机制对网络负载的感知和调整能力较弱,导致无法及时调整流量大小。在启动、调整过程中,网络带宽无法得到充分利用。
- 网络负载不均衡:基于流的ECMP技术调度粒度较粗,加上传统路由协议基于静态网络带宽等信息来计算最佳路径,导致某些网络链路过载,而其他链路则处于空闲状态。
02 超级以太网旨在提升网络利用率
在AI数据中心网络中,我们需要将网络利用率提升到85%以上,这也是UEC (Ultra Ethernet Consortium) 提出的目标 [1]。
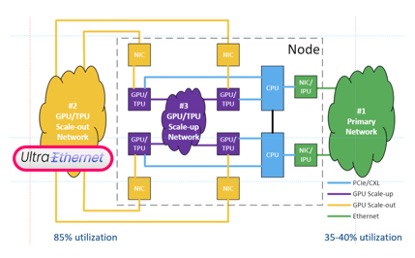
专用网络
当AI模型、并行方式和输入数据确定的情况下,AI训练和推理的流量是可预测的 [2], 如果我们为AI训练和推理流量建设专用的网络,与其它流量完全隔离,就为提升网络利用率打下了基础。
无阻塞拓扑
接下来,我们需要设计无阻塞的网络结构,如CLOS、Dragonfly, Torus, MegaFly, SlimFly等。目前,CLOS是最流行的网络结构 [3],在这个网络结构中,总接入带宽与总汇聚带宽相等,并容易在纵向和横向上扩展,在宏观上实现了无阻塞。然而由于流量不均衡和微突发现象的存在,在局部链路上,拥塞仍然会存在。
无损传输
在传统以太网中,当发生拥塞时,交换机通常采用尾丢弃或WRED(加权随机早期检测)等机制丢弃部分报文,以解决网络流量短暂超过带宽的现象。这一策略无疑是粗暴的。为了克服这一缺陷,InfiniBand和RoCE协议采用了ECN和链路级流量控制技术,例如,InfiniBand的CBFC(基于信用的流量控制)和RoCE的PFC(基于优先级的流量控制)。这些技术能有效应对点对点的突发拥塞,并且已经在数据中心网络中得到广泛应用。
然而,AI训练和推理会生成集合通信(Collective Communication),如Broadcast、All-Reduce、All-Gather、All-to-All等形式的流量,导致In-Cast类型的拥塞,即多个源同时向一个目的地发送流量,进而在目的链路上产生拥塞。解决这种拥塞需要新的技术。为此,UEC提出了INC(In Network Computing)技术,旨在通过交换机的计算能力,减少在网络中需要传输的流量,从而避免In-Cast拥塞现象。然而,该技术主要对All-Reduce这类可以在网络传输过程中合并的流量有效,对其他集合通信流量的效果较为有限。In-Cast拥塞仍然需要更先进的技术来解决。
UEC拥塞控制
当In-Cast拥塞产生后,目前主要通过端到端的流控机制来缓解这一问题。例如,基于ECN的DCQCN/DCTCP技术通过调节源端的发送流量速率,适应网络的可用带宽。由于ECN携带的信息只有1个bit,这种调节方式不够精确。例如,DCQCN在收到ECN后,首先会大幅度降低速率,然后逐步提高速率,直到与可用带宽匹配。这个过程较为缓慢,期间网络带宽的利用率明显不足。为了解决这一问题,UEC传输层(UET,Ultra Ethernet Transport Layer)提出了以下改进措施:
加速调整过程:UET通过测量端到端延迟来调节发送速率,并根据接收方的能力通知发送方调整速率,快速达到线速。
基于遥测:来自网络的拥塞信息可以通告拥塞的位置和原因,缩短拥塞信令路径并向终端节点提供更多信息,从而实现更快的拥塞响应。
包喷洒
UEC的流控技术有望解决源和目的之间的拥塞问题,但在整个网络中仍然存在负载不均衡的情况,即一些链路占用率过高,而另一些链路占用率较低。传统上,数据通信使用ECMP来实现整网的负载均衡。当两个交换机之间存在多条等价路径时,通过Hash算法将不同的流(通常由IP五元组定义)均匀调度到这些路径上。然而,当多个流的流量不均衡时,仍然会导致路径上的流量不均衡。尤其在AI训练和推理流中,熵值较低,每个流的持续时间长、流量大,容易出现“极化”现象,导致不同的流集中在某些路径上,造成其他路径空闲。
为此,UEC提出了包喷洒技术。该技术将不同的包均匀地分散到多个等价路径上,从而更充分地利用网络带宽。由于这种方式会导致目的地接收到的报文乱序,因此需要修改传输协议,允许包乱序到达,并在目的地重新组装为完整的消息。然而,重组过程带来了额外的开销,增加了整个流的延迟,且目的端需要等待该流的所有包传输完毕后才能处理整个消息,无法实现流水线操作。
03 星融元解锁超级以太网利用率潜力
可以看到,UEC为采用超级以太网提升网络利用率开辟了方向,然而作为一个正在发展中的标准,UEC的实现依赖于各个厂家的努力。作为UEC的早期会员,星融元在超级以太网的方向上,研发了一系列前沿技术,进一步提升网络利用率,可达到90%。
Flowlet
前面提到,基于流的ECMP容易造成负载不均衡,而包喷洒技术又带来了额外的延迟。有没有两全其美的技术?flowlet应运而生。Flowlet是根据流中的“空闲”时间间隔将一个流划分为若干片段。在一个flowlet内,数据包在时间上紧密连续;而两个flowlet之间,存在较大的时间间隔。这一间隔远大于同一流分片内数据包之间的时间间隔,足以使两个流分片通过不同的网络路径传输而不发生乱序。

并行计算过程中,计算和通信是交替进行的。因而AI并行训练和推理产生的流量是典型的flowlet。
当网络发生拥塞时,可将flowlet调度到较空闲的链路上以缓解压力。在AI训练和推理网络中,RDMA流通常较持久,训练流可能持续数分钟至数小时,推理流多为数秒至数分钟,而flowlet则以微秒到毫秒级的短暂突发为主。这种基于flowlet的精细调度能有效优化流量分配,显著降低网络拥塞,从而提高网络利用率。
基于遥测的路由
为了将包、flowlet或整个流调度到不同的路径上,需要路由协议的控制。传统的路由协议,基于静态的网络信息来计算最优路径,如OSPF基于网络带宽计算最短路径,BGP根据AS-PATH长度计算ECMP等。这种控制与网络实际负载脱节,需要加以改进。
星融元提出的基于遥测的路由(Int-based Routing)技术结合OSPF、BGP和在网遥测(INT)技术,为网络中任意一对节点之间计算多条路径,每个路径的开销是动态测量的延迟,从而能够根据实时的网络负载进行路由,从而充分利用每个路径的带宽。
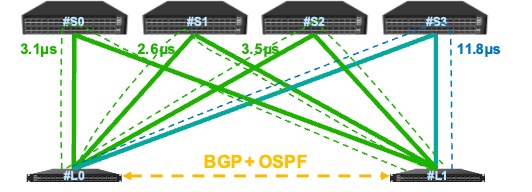
WCMP
ECMP技术将包、flowlet或整个流均匀的分布到多个路径上,忽略了不同路径上的实际负载。为了进一步提升网络利用率。星融元采用加权代价多路径(Weighted Cost Multiple Path)算法,基于遥测获取的时延等信息,在时延更低的路径上调度更多的流量,在时延更高的路径上调度更少的流量,从而实现所有路径的公平利用。在理想情况下,流量经过不同路径的总时延是相等的,可充分利用所有可用带宽。
【引用】
- [1] Ultra Ethernet Consortium, “Ultra Ethernet Introduction” 15th October 2024.
- [2] Asterfusion, “Unveiling AI Data Center Network Traffic” https://cloudswit.ch/blogs/ai-data-center-network-traffic/.
- [3] Asterfusion, “What is Leaf-Spine Architecture and How to Build it?” https://cloudswit.ch/blogs/what-is-leaf-spine-architecture-and-how-to-build-it/.


