
动态感知+智能决策,一文解读 AI 场景组网下的动态智能选路技术
1. AI时代的网络进化
1.1 传统网络为何无法承载AI流量?

在传统数据中心网络中,数量众多的小流使得基于流的负载均衡技术,即使不感知网络的实际状态,仍能实现较好的负载均衡和拥塞避免效果。
而AI场景流量特征的巨大差异(高带宽利用率、少数大象流等)导致传统负载均衡技术失效,从而出现极端的负载分担不均衡,而且这种不均衡一旦引发网络丢包,就会对整体 AI 模型的任务完成时间带来显著的负面影响。因此业界越来越重视 AI 场景组网的负载均衡算法优化方案,以实现流量更加均衡的负载在多条路径中。
1.2 动态感知与智能决策的融合
动态智能选路技术是一种基于感知路由的负载均衡技术,通过使用组网中交换机感知到的路径质量,来调整本地交换机的路径选择,并支持动态加权负载均衡方式平衡流量负载。
考虑到数据中心以及运营商已经习惯使用 BGP 作为数据中心网络的底层路由协议,动态智能选路技术以 BGP 为基础,通过 BGP 扩展能力,定义了一个新的扩展社区属性,基于多维度高精度测量值综合评价路径质量,通过 BGP 协议的扩展社区属性进行传递,用于指导后续业务流量的转发,提高整网负载均衡效率,减少应用响应时间。
2. 如何实现智能流量调度
当前网络均衡的主流技术有以下三种:
- 逐流 ECMP 均衡,是当前最为常用的负载均衡算法,基于流量的五元组进行 HASH 负载均衡,在流链接数量较多的场景下适用,它优势在于无乱序,劣势在于流数量较少时,例如AI训练场景下,存在 HASH 冲突问题,网络均衡效果不佳。
- 基于子流 flowlet 均衡技术,它依赖于子流之间时间间隔 GAP 值的正确配置来实现均衡,但如果网络中全局路径级时延信息不可知,因此 GAP 值无法准确配置。
- 逐包 ECMP 均衡,理论上均衡度最好,但实际在接收端侧存在大量乱序问题。
星融元CX-N系列RoCE交换机(SONiC-Based)选用的动态智能选路创新方案结合了逐流 ECMP 均衡和基于子流 flowlet 均衡提出动态WCMP(Weighted Cost Multipath)和基于flowlet 的 ALB(Auto Load Balancing),下面将介绍具体相关技术。
2.1 路径质量测量
基于过去在用户生产网 AI 集群的长期实践与观察,动态智能选路技术引入带宽使用情况、队列使用情况、转发时延等在AI集群网络中影响较大的参数,作为计算因子用于网络路径质量综合评价。
2.1.1 统计计数
带宽使用情况、队列使用情况基于 ASIC 硬件寄存器统计计数,精度可达百毫秒级。ASIC 硬件寄存器实时统计端口转发计数和队列转发计数,控制面 SONiC 软件系统通过 SAI 接口以亚秒级的精度读取 ASIC 计数并存入 redis 数据库,如下图所示。
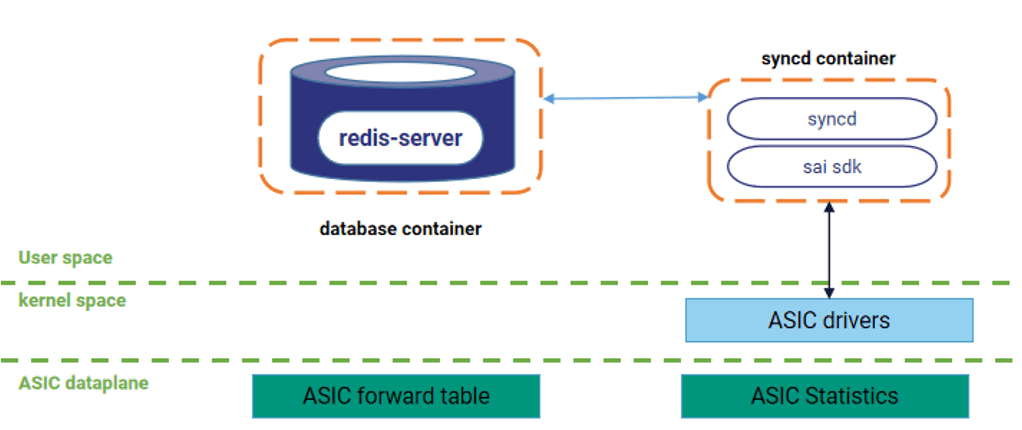
动态智能选路控制面程序使用 ASIC 统计计数进行接口质量衡量,并将结果通过 BGP 宣告出去。如果按照统计计数的亚秒级精度进行 BGP 宣告则整网控制面压力较大,所以目前使用秒级间隔进行 BGP 宣告,端口转发计数和队列转发计数均选取多个数据点进行加权平均(越靠近计算时间点的数据权重越高)。
2.1.2 带内遥测
转发时延计算因子基于INT(In-band Network Telemetry)技术,精度可达纳秒级。HDC(High Delay Capture)是一种能捕获 ASIC 中经历高延迟的数据包信息的 INT 技术。
通过使用 HDC,星融元交换机能够捕获任何超过用户指定延迟阈值的数据包的延迟信息,并将原始数据包的前150字节连同元数据(包含出入端口、时延等关键信息)作为 HDC 数据包发送到收集器。
动态智能选路技术在星融元交换机上开启 HDC 功能,并将 CPU 作为 HDC 的收集分析器,通过分析 HDC 报文实现高精度测量交换机转发时延,并将时延信息作为路径质量评价因子,提高路径质量评价精度。
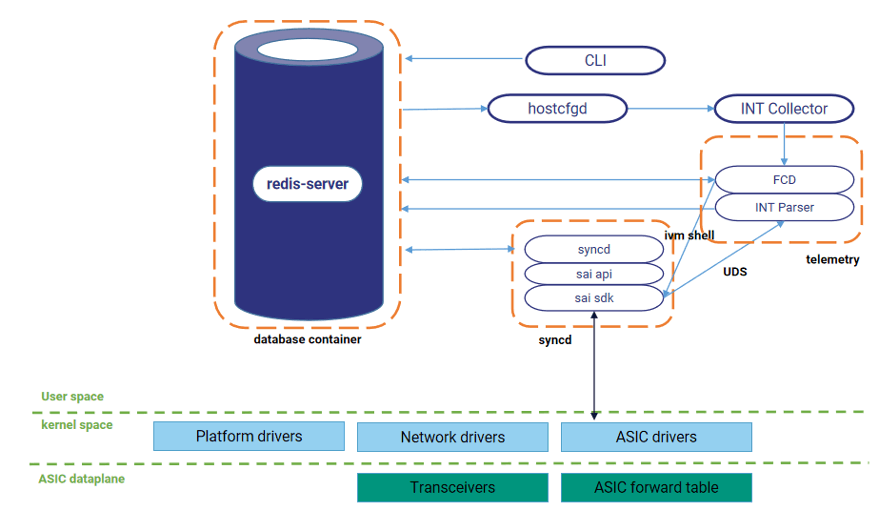
命令行配置 HDC 功能控制INT进程运行,之后通过 socket 连接进行收包循环,将收取到的报文进行解析并将关键信息(出入端口、转发时延等)写入数据库。
2.2 路径质量同步
动态智能选路技术以 BGP 为基础,通过 BGP 扩展能力,使用一个新的扩展社区属性(Path Bandwidth Extended Community),用来指示通往目的路径的质量和。该扩展社区属性扩展类型字段高八位的值为 0x00(暂未使用),低八位的值为 0x05。在Value Field字段中,Global Administrator 子字段的值表示 AS 号。路径质量使用4个字节,以 IEEE 浮点格式,单位为GB/s。
路径质量同步算法逻辑如下图所示:
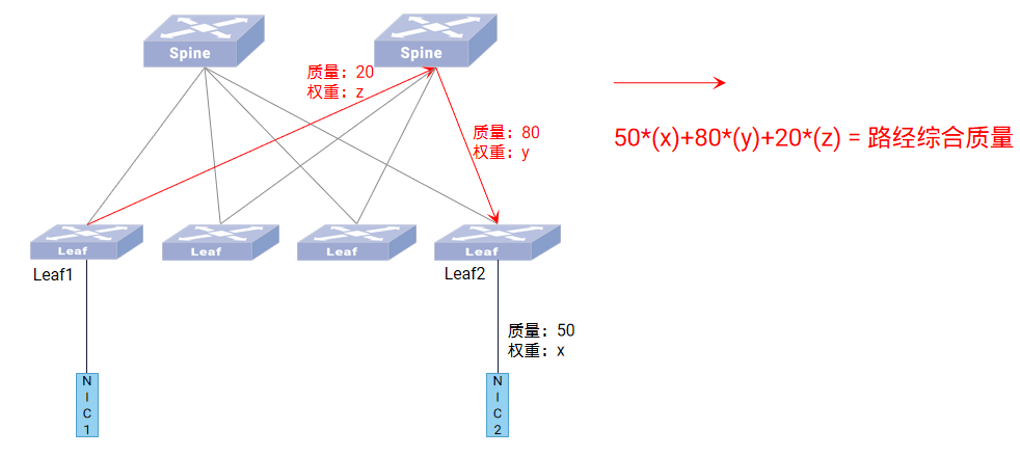
当 NIC1 与 NIC2 通信时,NIC2 首先将自身IP宣告给 Leaf2,Leaf2 携带对应链路质量(指向 NIC2 的链路质量乘以 Leaf2 下行口权重)将 NIC2 IP 宣告给 Spine,Spine 携带对应链路质量(指向Leaf2的链路质量乘以 Spine 权重加上路由信息中已经携带的值)将 NIC2 IP 宣告给 Leaf1,Leaf1 汇总路径质量并生成路由指导转发。
动态智能选路技术将两层 Leaf-Spine 组网中的交换机端口分为了三类:Leaf 上行口、Leaf 下行口和 Spine口,每种类型端口赋予不同的计算系数,且每种端口的计算系数可配。
2.3 动态WCMP
负载分担(Load Balance)是指网络节点在转发流量时,将负载(流量)分摊到多条链路上进行转发,要在网络中存在多条路径的情况下,比如all-to-all流量模型下,实现无损以太网络,达成无丢包损失、无时延损失、无吞吐损失,需要引入该机制。数据中心中常用的负载分担机制为等价多路径路由 ECMP。
WCMP 能够将流量按照比例在不同链路上进行转发,ECMP是它的特例。在动态智能选路技术中,WCMP 根据路径质量来动态调整路由的权重,从而实现更为灵活的负载均衡。
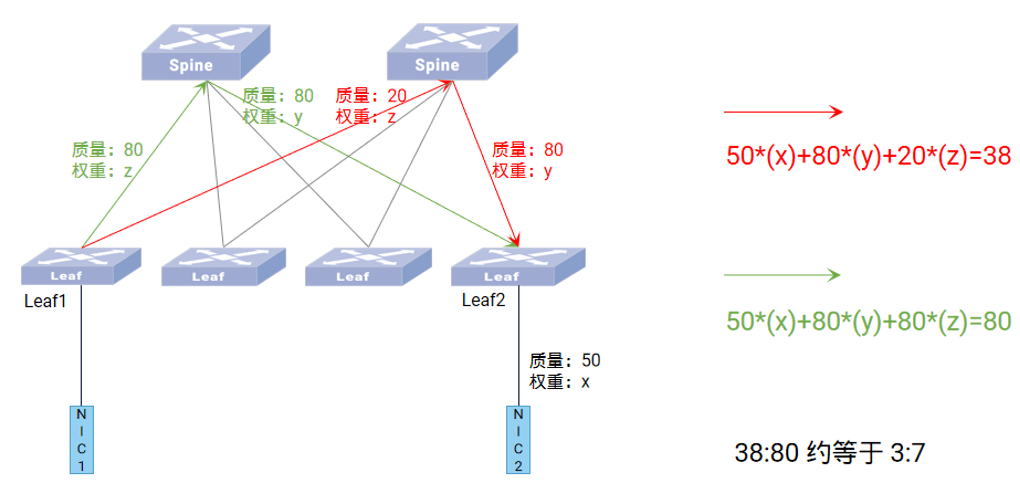
如上图所示,当NIC1与NIC2通信存在两条路径时,假设根据 [2.2路径质量同步] 中的算法逻辑在 Leaf1 中计算出指向NIC2的红色路径综合质量为38,指向NIC2的绿色路径综合质量为80,最终下发WCMP时两条路径的权重比为3:7。
同时随着整网流量不停的变化,路径质量也会随之变化,这些变化最终都会转变成路径质量通过 BGP 汇总到每一台 Leaf,从而在 Leaf 上生成动态 WCMP 路由指导流量转发。
2.4 异常路径剔除
当路径的综合质量小于约定的系数时,我们认为该条路径在 AI 场景下不再可用,判定为异常路径,需要剔除,剩余路径继续实现动态 WCMP 进行流量转发,当路径综合质量正常后,恢复这⼀路径。剔除短期内此路径不可⽤,造成少量浪费,但是避免了异常路径导致的路径拥塞甚至丢包等更为严重的后果。
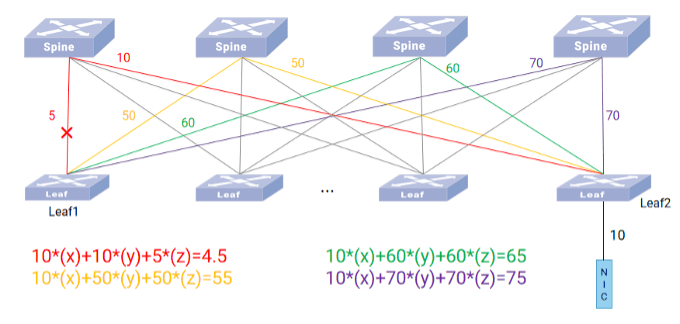
如图所示,当 Leaf1 与 Leaf2 通信存在四条路径时,假设根据 [2.2路径质量同步] 中的算法逻辑在 Leaf1 中计算出四条路径综合质量分别为4.5、55、65和75,此时红色路径会被剔除,剩下的三条路径根据各自路径质量形成 WCMP。
2.5 智能负载均衡
LB技术实现基于 flowlet 的负载分担,ALB 通过在 ASIC 中实时测量不同端口上负载和时延,将 flowlet 路由到负载更⼩或时延更低的链路上,在传统 ECMP 的基础上从⽽实现更精细的流量调度和负载均衡。
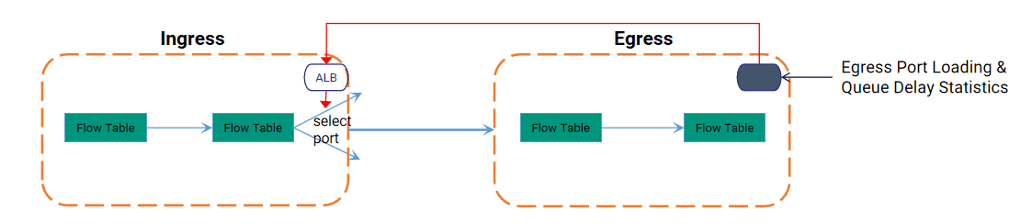
如图所示,通过ALB技术,在出端口感知瞬时、平均负载以及队列的瞬时、平均延迟,并将数据同步给 Ingress,进行出端口的选择。同时 ALB 还支持端口 fail-over,出端口链路故障,会主动触发端口流量的重分配。
2.6 虚拟化
前端⽹络通常要⽀持多租⼾,将不同的 GPU 分配给不同⽤⼾。动态智能选路技术采⽤ VRF 实现多租⼾的隔离,每个用户对应分配一个 VRF。
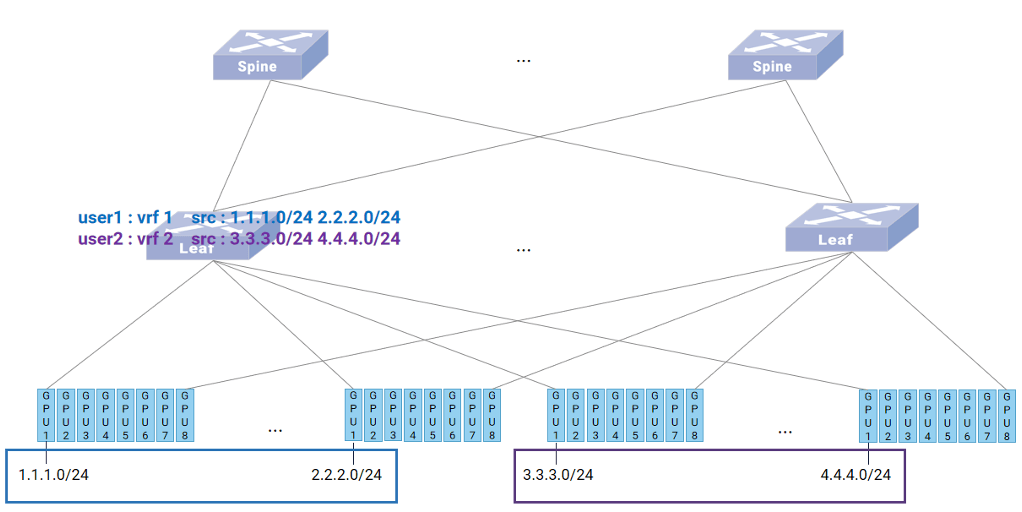
如图所示(NIC和GPU一对一,实际 Leaf 与 NIC直连,此处省去 NIC,下同),组网承载两个用户的流量,user1 对应 vrf1,使用1.1.1.0/24和2.2.2.0/24网段对应的两个 GPU,user2 对应 vrf2,使用3.3.3.0/24和4.4.4.0/24网段对应的两个GPU。
通过用户配置将使用的 GPU 对应的网段划分进用户VRF,通过ASIC中的 PRE ACL 对进入交换机的流量进行区分,所有源IP处于 1.1.1.0/24 和 2.2.2.0/24 网段的流量打上 vrf1 的标记,所有源IP处于 3.3.3.0/24 和 4.4.4.0/24 网段的流量打上 vrf2 的标记,使得对应用户流量只能在对应VRF中进行查表转发,实现租户隔离。
3. 应用场景
3.1 动态WCMP如何化解流量洪峰?
以 256 个400G的GPU端口数量为例,整体网络架构采用两层Clos网络架构,按照下行端口与上行端口 1:1 的收敛比设计。在保证网络高吞吐、高带宽的基础上,1:1 的带宽收敛比能够避免因为带宽不对称导致的性能问题。
产品型号可以选择星融元CX864E-N 或 CX732Q-N 两款,CX864E-N 提供更高的端口密度以及扩展性,CX732Q-N 在满足高带宽的接入需求同时,为用户提供更高的性价比。下面以 CX732Q-N 组网为例:
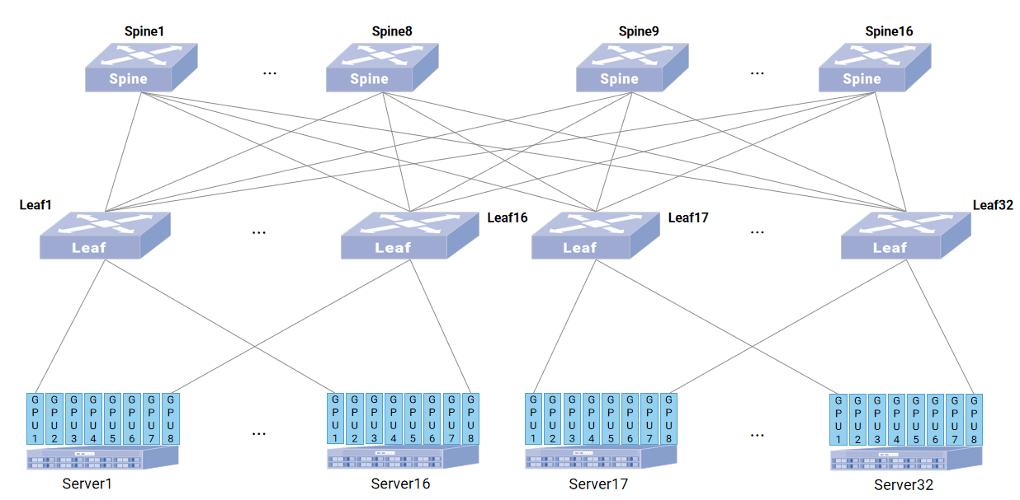
假设 Server1 的 GPU1 要与 Server17 的GPU1通信,按照传统 ECMP 的逻辑,流量会选择Spine中的一个然后到达 Leaf17,传统 ECMP 不会感知路径实时状态,所以 AI 场景下的少量大象流极易被均衡到同一 Spine 上从而导致 Leaf1 上行端口拥塞甚至出现丢包。
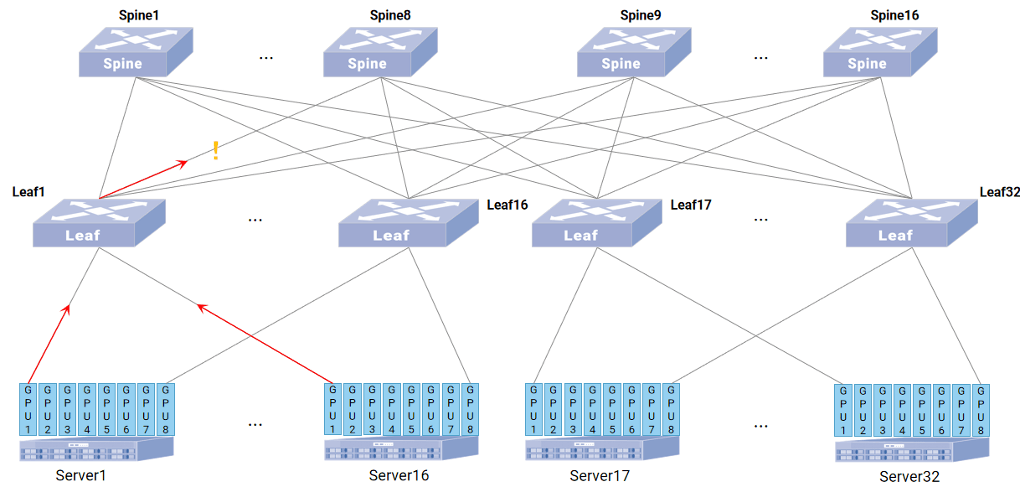
如果交换机开启了动态智能选路技术,当 Server17 将 GPU1 的路由信息通过 Leaf17 向整网通告时,首先 Leaf17 会将自身通往 Server17-GPU1 的路径质量附带在路由通告中发给所有 Spine,然后每个 Spine 将自身通往 Leaf17 的路径质量累积在路由通告中发给 Leaf1,Leaf1 将自身通往 Leaf17 的路径质量继续累积在路由信息中,此时 Leaf1 上有到达 Server17-GPU1 的全路径以及每条路径对应的路径质量,Leaf1 先去掉路径质量异常的路径(如质量较低路径认为不适合进行流量转发),再根据综合路径质量计算剩余路径的权重,形成 WCMP,指导流量转发。
3.2 Flowlet级负载均衡
以上述 256 个 400G 的 GPU 组网为例,如果使用了动态智能选路技术,但是不是每台设备都适合使用动态 WCMP,则交换机会动态选择基于 flowlet 的 ALB 进行流量的负载均衡。整网形成 ECMP 之后,ASIC的 ALB 功能会实时测量 ECMP 组中不同链路上负载和时延,将 flowlet 路由到负载更⼩或时延更低的链路上。
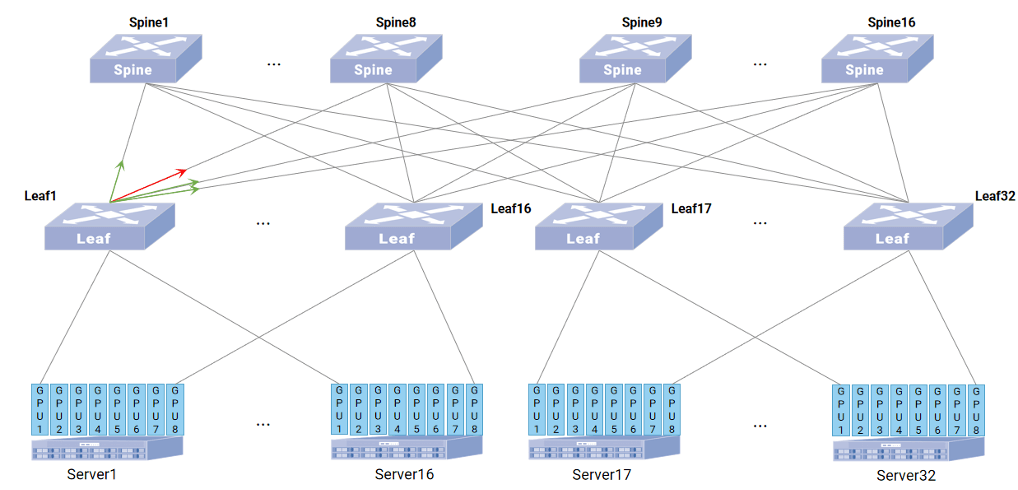
如图所示,Leaf1 上的多个指向Spine的链路同时负载流量,当红色接口负载流量较高,转发时延过长,此时 ASIC 基于 flowlet 做 ECMP 时,会自动跳过红色路径对应的出口,直到该出口负载和转发时延恢复正常值之后,ECMP 才会再选中该端口进行流量转发。
更多AI智算网络技术分享,请持续关注星融元
产品与方案咨询:400-098-9811


