-
基于CX8/7/6(-N系列)数据中心交换机,搭建800G/400G/200G网络连接GPU集群
-
基于CX6/5(-N系列)数据中心交换机,搭建200G/100G网络连接存储集群
-
基于CX5/3(-N系列)数据中心交换机,搭建100G/25G网络连接CPU集群
-
基于CX2(-M系列)云化园区交换机,搭建25G/1G网络,管理集群和网络的所有设备






方案亮点
开放、中立的网络基础设施
星融元AI/ML网络解决方案的开放性确保用户能够重用已有的系统(K8s、Prometheus等)对网络进行管理,无需重复投入;星融元以“中立的网络供应商参与AI生态”的理念为用户提供专业的网络方案,帮助用户规避“全栈方案锁定”的风险。
提升大模型训练效率
CX-N数据中心交换机的单机转发时延(400ns)低至业界平均水平的1/4~1/5,将网络时延在AI/ML应用端到端时延中的占比降至最低,同时多维度的高可靠设计确保网络在任何时候都不中断,帮助大模型的训练大幅度降低训练时间、提升整体效率。
大幅度降低TCO
与业界其他方案不同,CX-N系列数据中心交换机标配全端口支持RoCEv2、智能负载均衡、BGP/EVPN、VXLAN等AI/ML网络必须的能力,并且在大规模运营网络中经过了充分的验证,用户无需再为这些能力支付额外的License费用。
一站式AI/ML网络
采用星融元的“AsterNOS网络操作系统 + CX-N数据中心交换机 + CX-M云化园区交换机”搭建承载AI/ML环境的所有网络模块,统一的软硬件系统、统一的部署逻辑、统一的运维逻辑,用户无需再为来自多供应商的网络支付额外的学习成本。
面向未来的投资保护
为了确保用户网络与最领先的以太网技术保持同步,星融元提供前后向兼容的200G/400G/800G网络能力,已加入超以太网联盟(UEC)并率先支持UEC定义的当前规范,积极参与新一代AI以太网规范的讨论与制定。
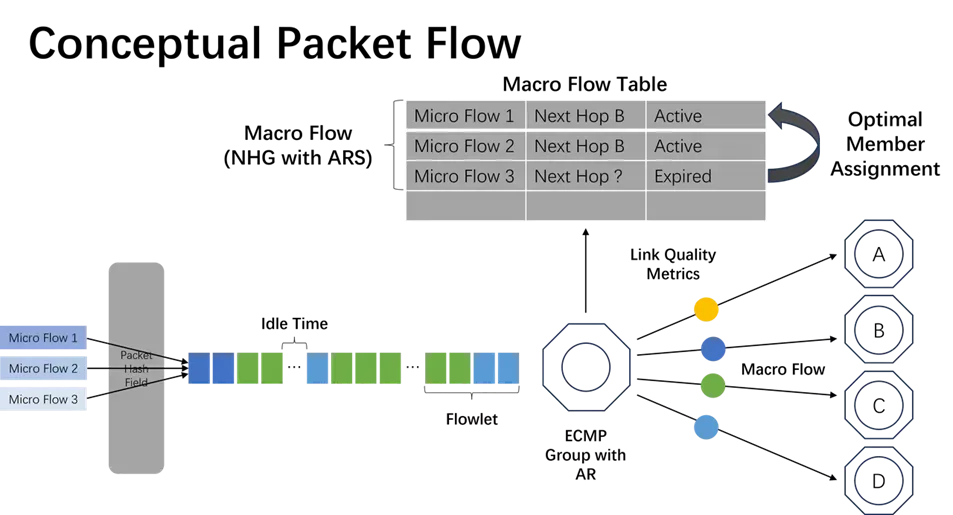
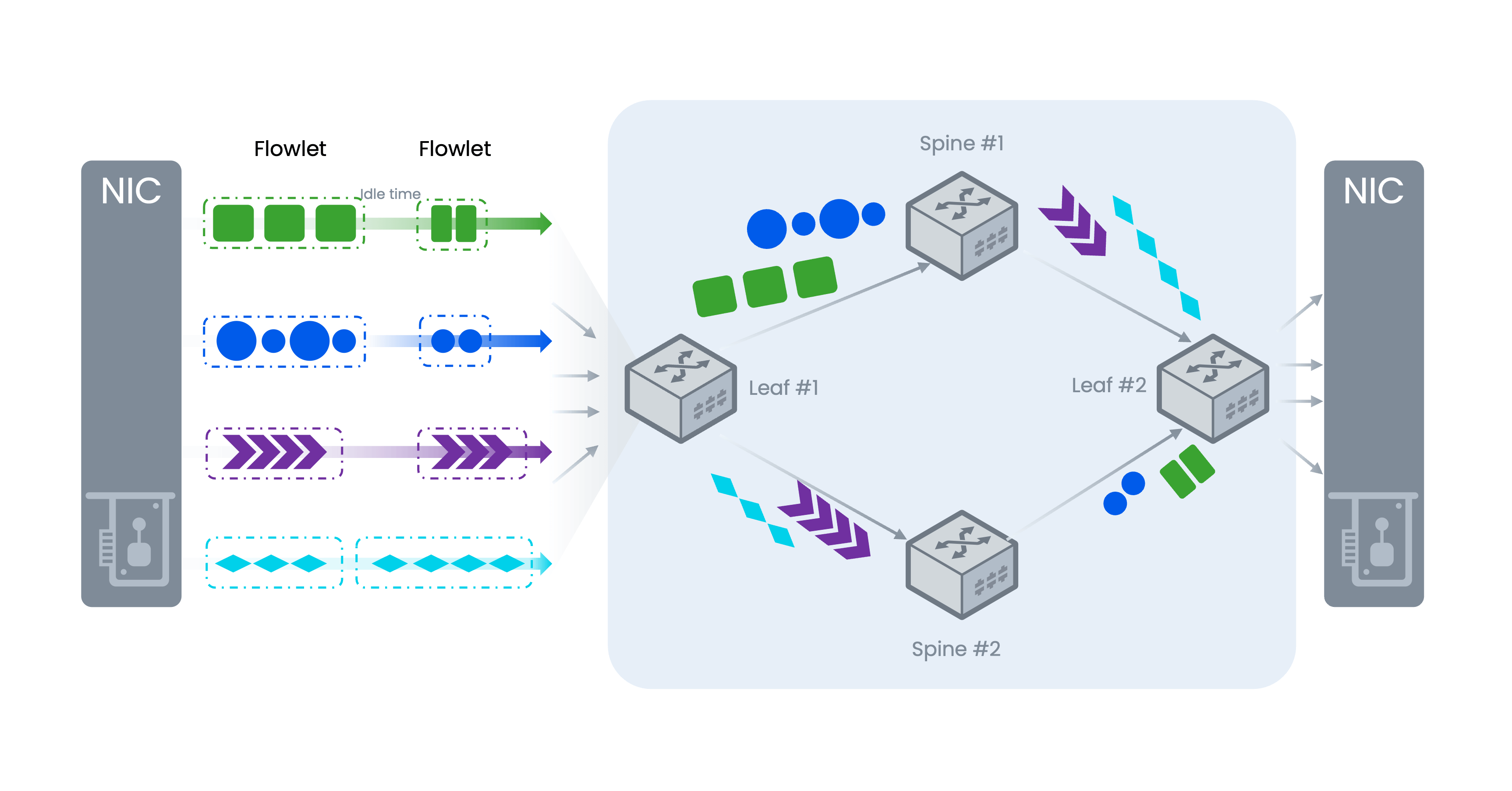
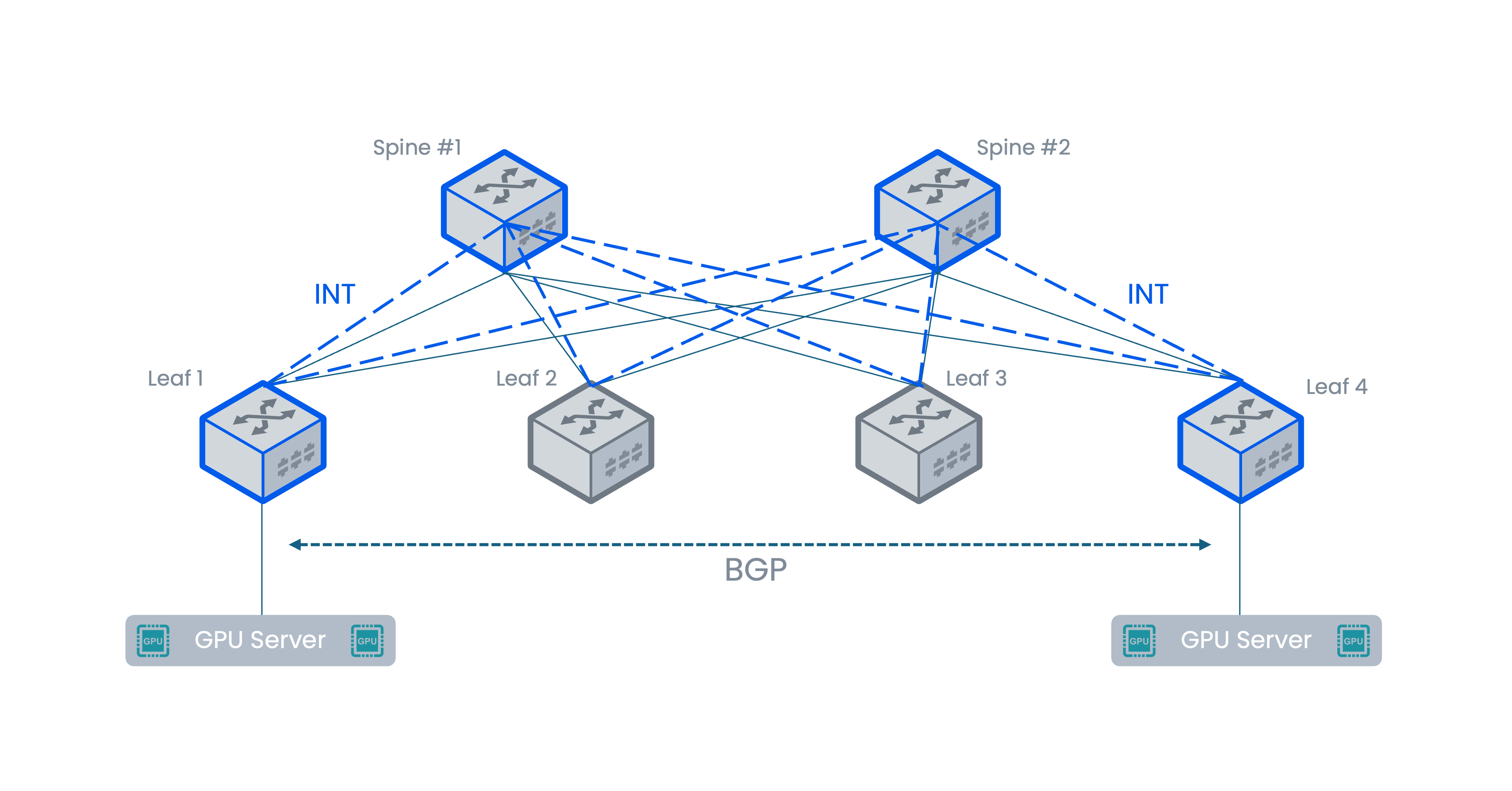
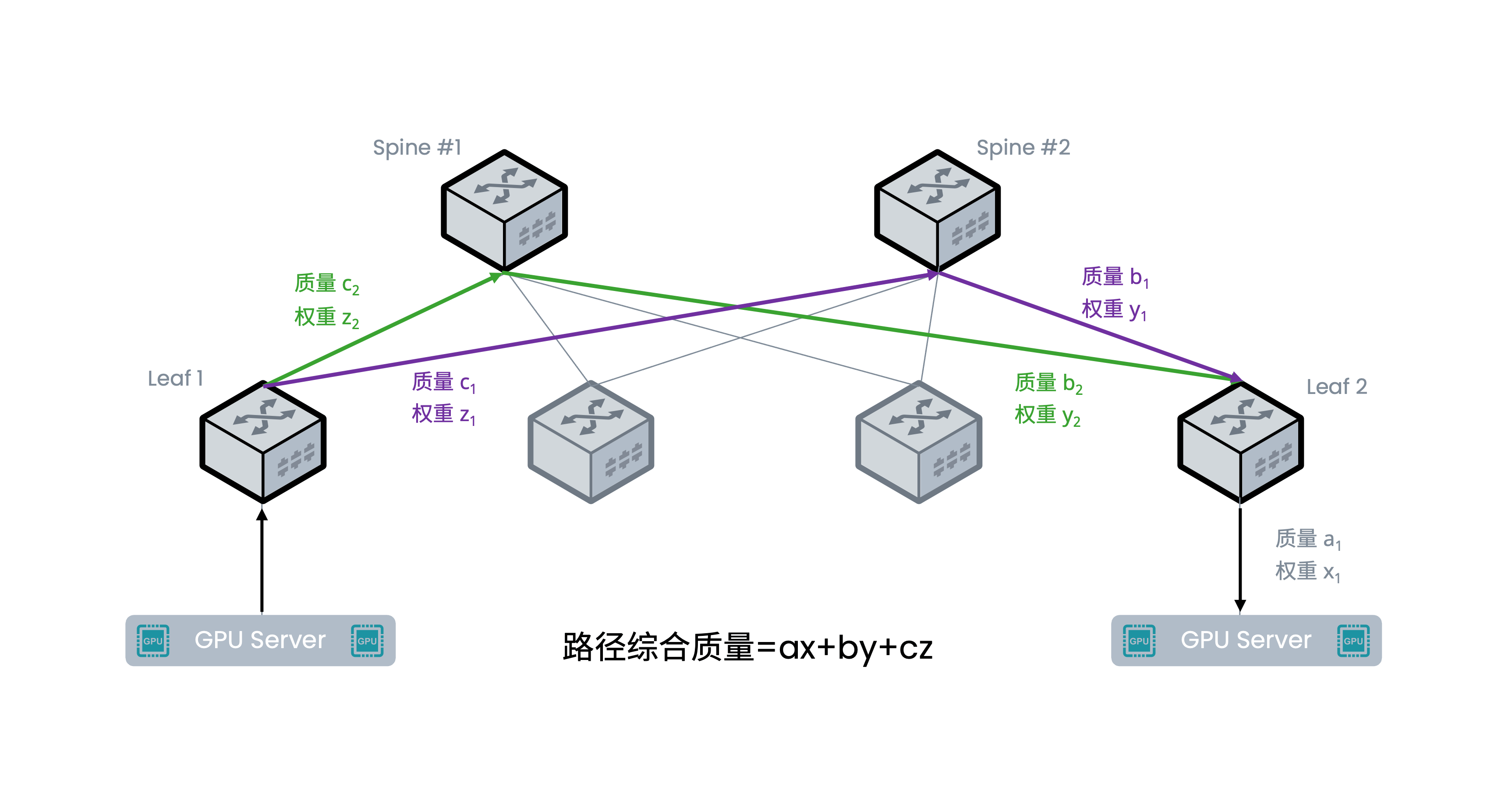
关键技术