配置指导:Ceph存储集群部署
Ceph存储集群部署方案
1 目标
本文档将简要介绍分布式存储Ceph的基本概念,以及选用Asterfusion CX-N系列超低时延交换机进行组网,部署一个3节点存储集群的具体方法。
2 概要介绍
2.1 关于Ceph
Ceph是一个目前非常流行且应用广泛的SDS(Software Defined Storage)解决方案。Ceph官网上用这句话简明扼要地对其进行定义:“Ceph is a unified, distributed storage system designed for excellent performance, reliability and scalability.” 翻译为中文:“Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式的存储系统。”这句话可以作为理解Ceph系统设计思想和实现机制的基本出发点。在这个定义中,应当特别注意“存储系统”这个概念的两个修饰词,即“统一的”和“分布式的”。
具体而言,“统一的”意味着Ceph可以使用一套存储系统来同时提供对象存储、块存储和文件系统存储三种功能,以便在满足不同应用需求的前提下简化部署和运维。而“分布式的”在Ceph系统中则意味着真正的无中心结构和没有理论上限的系统规模可扩展性。在实践当中,Ceph可以被部署于上千台服务器上。
2.2 关于Asterfusion CX-N系列超低时延交换机
星融元Asterfusion自主开发的面向数据中心网络的CX-N系列超低时延交换机,可为云数据中心中的高性能计算集群、存储集群、大数据分析、高频交易、Cloud OS全面融合等多业务场景提供高性能的网络服务。
本次验证部署的存储集群,选用了两台CX-N系列CX308P-48Y-N进行组网,这款1U交换机拥有48个25G/10G SFP28光口,8个100GE/40GE QSFP28光口,交换容量高达4.0Tbps。
3 存储集群组件介绍
Ceph集群最初有MON、OSD、MDS、RGW共四个服务组件,从Luminous版开始引入了MGR组件,用于采集和统计集群的各种指标。L版之后开始必须部署MGR组件,不过即使MGR服务停止运行,整个集群的IO还是可以进行的,只是各种指标不会继续更新,并且与其相关的命令行无法响应(例如:ceph status)。
本次部署的Ceph版本为N版,各组件功能说明如下。
- MON:控制器服务,主要维护集群中的各种MAP,同时也提供安全认证服务,是必要组件;
- OSD:对象存储服务,负责处理数据的复制、恢复、回填与再均衡,是必要组件;
- MGR:集群监控服务,负责监控整个集群的各种指标,并对外提供接口,是必要组件;
- MDS:元数据服务,为CFS存储、维护元数据,只在使用CFS时部署,是非必要组件;
- RGW:对象存储网关,对外提供RESTful访问接口,兼容S3与Swift,是非必要组件。
部署一个最小规模的Ceph集群,必须包含1个MON、1个MGR和2个OSD,否则整个集群是不健康的。因为,Monitor的Leader Elect机制要求集群中的MON最好为奇数,在生产环境中官方推荐使用3个MON来提供高可用性。而2个OSD则是为了满足双副本机制,以确保数据的安全性。
4 环境声明与部署前的准备
4.1 服务器系统与集群版本
- CEPH:Nautilus 14.2.9(鹦鹉螺)稳定版;
- 操作系统:Red Hat Enterprise Linux Server 7.6 (Maipo)。
4.2 节点配置与网络架构
| 主机名 | IP地址 | 处理器 | 内存 | 硬盘 | 节点角色 |
|---|---|---|---|---|---|
| node-01 | 192.168.2.81 管理网 192.168.20.81 存储网 | 32C | 64G | 100G 系统盘 200G*5 OSD | MON/OSD/MGR/RGW |
| node-02 | 192.168.2.82 管理网 192.168.20.82 存储网 | 32C | 64G | 100G 系统盘 200G*5 OSD | MON/OSD/MGR/RGW |
| node-03 | 192.168.2.83 管理网 192.168.20.83 存储网 | 32C | 64G | 100G 系统盘 200G*5 OSD | MON/OSD/MGR/RGW |
集群中3个节点的配置信息如上所示。网络方面按官方推荐,使用管理网(前端)和存储网(后端)两个独立的网络,可以显著提高Ceph集群的性能表现。因此,每台节点上必须配备多块物理网卡(最低两块物理网卡)。
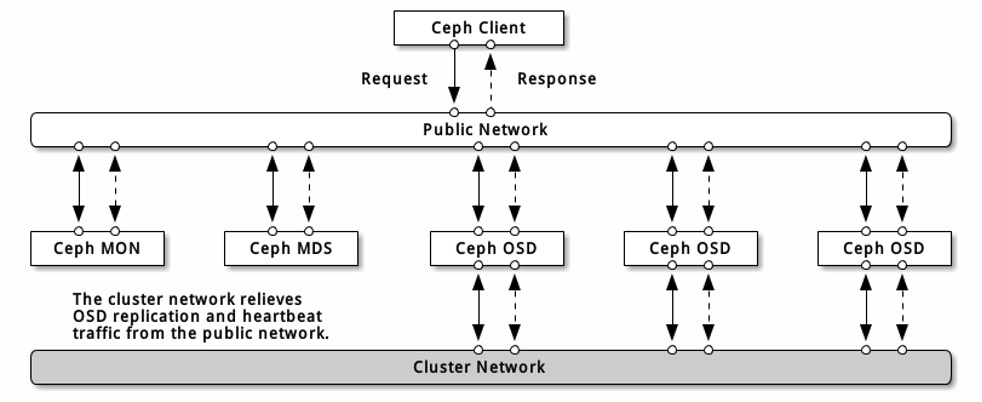
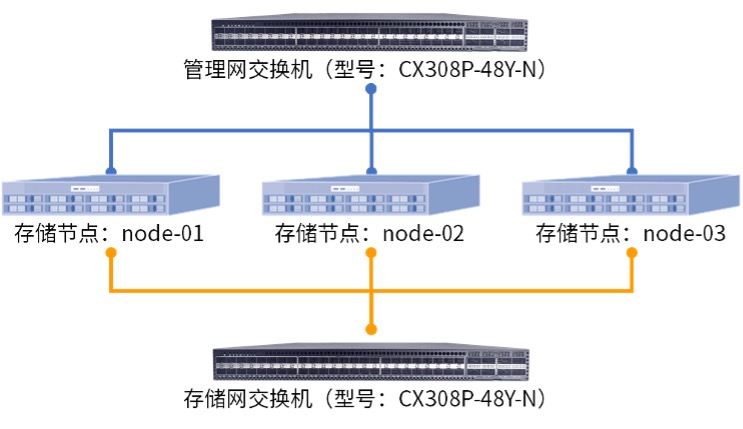
4.3 部署前的网络环境准备
使用25G光纤模块将服务器与管理网、存储网交换机按照图4.2的拓扑连线。对于此次的验证方案,需要两个二层网络,在交换机上电开机后无需其他配置操作,只需要在完成连线后确认各个端口状态为UP且速率协商正常即可。
4.4 部署前的系统环境准备
需要在各个节点上都进行操作,下面的所有配置步骤均以节点node-01为例。
- 禁用SELinux
[root@node-01 ~]# setenforce 0
[root@node-01 ~]# sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/sysconfig/selinux
- 禁用防火墙
[root@node-01 ~]# systemctl stop firewalld
[root@node-01 ~]# systemctl disable firewalld
- 配置IP地址
修改两块网卡的配置文件,如下所示:
[root@node-01 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens192
TYPE=Ethernet
BOOTPROTO=none
NAME=ens192
DEVICE=ens192
ONBOOT=yes
IPADDR=192.168.2.81
GATEWAY=192.168.2.1
DNS1=223.5.5.5
DNS1=223.6.6.6
[root@node-01 ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens224
TYPE=Ethernet
BOOTPROTO=none
NAME=ens224
DEVICE=ens224
ONBOOT=yes
IPADDR=192.168.20.81
GATEWAY=192.168.20.1
[root@node-01 ~]# systemctl stop NetworkManager
[root@node-01 ~]# systemctl disable NetworkManager
[root@node-01 ~]# systemctl restart network
- 配置主机名
[root@node-01 ~]# hostnamectl set-hostname node-01.open-source.cc
[root@node-01 ~]# cat /etc/hosts
......
# Cluster Node Resolve
192.168.2.81 node-01.open-source.cc node-01
192.168.2.82 node-02.open-source.cc node-02
192.168.2.83 node-03.open-source.cc node-03
......
配置国内YUM源
国内YUM源可选择的非常多,如:阿里、163、中科大、清华等,配置YUM源的具体方法此处不赘述,此处仅列出文档中的所有安装包操作依赖的源,如下所示:
[root@node-01 ~]# ll /etc/yum.repos.d/
total 28
-rw-r--r-- 1 root root 1441 May 19 09:00 CentOS7-Base-163.repo
-rw-r--r-- 1 root root 575 May 20 21:26 ceph.repo
-rw-r--r-- 1 root root 951 Oct 3 2017 epel.repo
-rw-r--r-- 1 root root 1050 Oct 3 2017 epel-testing.repo
5 安装步骤
首先,需要在集群中的所有节点上,安装Ceph软件包及其依赖。
[root@node-01 ~]# yum makecache fast
[root@node-01 ~]# yum install -y ceph ceph-radosgw
5.1 单节点部署
在节点node-01上进行以下操作,以完成单节点部署,后续再进一步介绍集群的扩容操作。
- 生成集群ID
[root@node-01 ~]# uuidgen
dd3807d6-0850-4080-8638-a47e946986ed
- 创建配置文件
[root@node-01 ~]# touch /etc/ceph/ceph.conf
[root@node-01 ~]# cat /etc/ceph/ceph.conf
[global]
fsid = dd3807d6-0850-4080-8638-a47e946986ed
mon host = 192.168.2.81
public network = 192.168.2.0/24
cluster network = 192.168.20.0/24
auth cluster required = none
auth service required = none
auth client required = none
osd journal size = 1024
osd pool default size = 2
osd pool default min size = 2
osd pool default pg num = 128
osd pool default pgp num = 128
osd crush chooseleaf type = 1
osd_mkfs_type = xfs
max mds = 5
mds max file size = 100000000000000
mds cache size = 1000000
mon osd down out interval = 900
[mon]
mon clock drift allowed = .50
- 生成monmap文件
[root@node-01 ~]# monmaptool --create --add node-01 192.168.2.81 --fsid <ClusterID> /tmp/monmap- 准备mon的数据目录
[root@node-01 ~]# sudo -u ceph mkdir /var/lib/ceph/mon/ceph-node-01- 初始化mon服务
[root@node-01 ~]# sudo -u ceph ceph-mon --mkfs -i node-01 --monmap /tmp/monmap
[root@node-01 ~]# sudo -u ceph touch /var/lib/ceph/mon/ceph-node-01/done
- 启用msgr2协议支持
[root@node-01 ~]# ceph mon enable-msgr2- 设置mon开机自启
[root@node-01 ~]# systemctl restart ceph-mon@node-01
[root@node-01 ~]# systemctl enable ceph-mon@node-01
- 检查集群健康状态
[root@node-01 ~]# ceph status- 初始化OSD目录树
[root@node-01 ~]# ceph osd tree
[root@node-01 ~]# ceph osd crush add-bucket node-01 host
[root@node-01 ~]# ceph osd crush add-bucket node-02 host
[root@node-01 ~]# ceph osd crush add-bucket node-03 host
[root@node-01 ~]# ceph osd crush move node-01 root=default
[root@node-01 ~]# ceph osd crush move node-02 root=default
[root@node-01 ~]# ceph osd crush move node-03 root=default
- 添加OSD
[root@node-01 ~]# ceph-volume lvm create --data /dev/sdb
[root@node-01 ~]# ceph-volume lvm create --data /dev/sdc
[root@node-01 ~]# ceph-volume lvm create --data /dev/sdd
[root@node-01 ~]# ceph-volume lvm create --data /dev/sde
[root@node-01 ~]# ceph-volume lvm create --data /dev/sdf
- 设置OSD守护进程自启
[root@node-01 ~]# systemctl restart ceph-osd@0.service
[root@node-01 ~]# systemctl enable ceph-osd@0.service
[root@node-01 ~]# systemctl restart ceph-osd@1.service
[root@node-01 ~]# systemctl enable ceph-osd@1.service
[root@node-01 ~]# systemctl restart ceph-osd@2.service
[root@node-01 ~]# systemctl enable ceph-osd@2.service
[root@node-01 ~]# systemctl restart ceph-osd@3.service
[root@node-01 ~]# systemctl enable ceph-osd@3.service
[root@node-01 ~]# systemctl restart ceph-osd@4.service
[root@node-01 ~]# systemctl enable ceph-osd@4.service
5.2 扩容OSD节点
- 在Node-02上添加OSD
[root@node-02 ~]# ceph-volume lvm create --data /dev/sdb
[root@node-02 ~]# ceph-volume lvm create --data /dev/sdc
[root@node-02 ~]# ceph-volume lvm create --data /dev/sdd
[root@node-02 ~]# ceph-volume lvm create --data /dev/sde
[root@node-02 ~]# ceph-volume lvm create --data /dev/sdf
[root@node-02 ~]# ceph-volume lvm list
[root@node-02 ~]# systemctl restart ceph-osd@5.service
[root@node-02 ~]# systemctl enable ceph-osd@5.service
[root@node-02 ~]# systemctl restart ceph-osd@6.service
[root@node-02 ~]# systemctl enable ceph-osd@6.service
[root@node-02 ~]# systemctl restart ceph-osd@7.service
[root@node-02 ~]# systemctl enable ceph-osd@7.service
[root@node-02 ~]# systemctl restart ceph-osd@8.service
[root@node-02 ~]# systemctl enable ceph-osd@8.service
[root@node-02 ~]# systemctl restart ceph-osd@9.service
[root@node-02 ~]# systemctl enable ceph-osd@9.service
- 在Node-03上添加OSD
[root@node-03 ~]# ceph-volume lvm create --data /dev/sdb
[root@node-03 ~]# ceph-volume lvm create --data /dev/sdc
[root@node-03 ~]# ceph-volume lvm create --data /dev/sdd
[root@node-03 ~]# ceph-volume lvm create --data /dev/sde
[root@node-03 ~]# ceph-volume lvm create --data /dev/sdf
[root@node-03 ~]# ceph-volume lvm list
[root@node-03 ~]# systemctl restart ceph-osd@10.service
[root@node-03 ~]# systemctl enable ceph-osd@10.service
[root@node-03 ~]# systemctl restart ceph-osd@11.service
[root@node-03 ~]# systemctl enable ceph-osd@11.service
[root@node-03 ~]# systemctl restart ceph-osd@12.service
[root@node-03 ~]# systemctl enable ceph-osd@12.service
[root@node-03 ~]# systemctl restart ceph-osd@13.service
[root@node-03 ~]# systemctl enable ceph-osd@13.service
[root@node-03 ~]# systemctl restart ceph-osd@14.service
[root@node-03 ~]# systemctl enable ceph-osd@14.service
5.3 扩容MON节点
- 同步配置文件
在Node-01:
[root@node-01 ~]# scp /etc/ceph/ceph.conf node-02:/etc/ceph
[root@node-01 ~]# scp /etc/ceph/ceph.conf node-03:/etc/ceph
- 创建mon数据目录
在Node-02:
[root@node-02 ~]# sudo -u ceph mkdir /var/lib/ceph/mon/ceph-node-02在Node-03:
[root@node-03 ~]# sudo -u ceph mkdir /var/lib/ceph/mon/ceph-node-03- 同步monmap文件
在Node-01:
[root@node-01 ~]# ceph mon getmap -o /tmp/ceph.mon.map
[root@node-01 ~]# scp /tmp/ceph.mon.map node-02:/tmp/
[root@node-01 ~]# scp /tmp/ceph.mon.map node-03:/tmp/
- 初始化mon服务
在Node-02:
[root@node-02 ~]# sudo -u ceph ceph-mon --mkfs -i node-02 --monmap /tmp/monmap
[root@node-02 ~]# sudo -u ceph touch /var/lib/ceph/mon/ceph-node-02/done
在Node-03:
[root@node-03 ~]# sudo -u ceph ceph-mon --mkfs -i node-03 --monmap /tmp/monmap
[root@node-03 ~]# sudo -u ceph touch /var/lib/ceph/mon/ceph-node-03/done
- 将新mon加入集群
在Node-01:
[root@node-01 ~]# ceph mon add node-02 192.168.2.82
[root@node-01 ~]# ceph mon add node-03 192.168.2.83
- 设置mon守护进程自启
在Node-02:
[root@node-02 ~]# systemctl restart ceph-mon@node-02
[root@node-02 ~]# systemctl enable ceph-mon@node-02
在Node-03:
[root@node-03 ~]# systemctl restart ceph-mon@node-03
[root@node-03 ~]# systemctl enable ceph-mon@node-03
- 检查集群状态:
[root@node-01 ~]# ceph status5.4 配置MGR服务
- 准备MGR服务目录
在Node-01:
[root@node-01 ~]# sudo -u ceph mkdir /var/lib/ceph/mgr/ceph-node-01在Node-02:
[root@node-02 ~]# sudo -u ceph mkdir /var/lib/ceph/mgr/ceph-node-02在Node-03:
[root@node-03 ~]# sudo -u ceph mkdir /var/lib/ceph/mgr/ceph-node-03- 启动MGR服务,设置开机自启
在Node-01:
[root@node-01 ~]# systemctl restart ceph-mgr@node-01.service
[root@node-01 ~]# systemctl enable ceph-mgr@node-01.service
在Node-02:
[root@node-02 ~]# systemctl restart ceph-mgr@node-02.service
[root@node-02 ~]# systemctl enable ceph-mgr@node-02.service
在Node-03:
[root@node-03 ~]# systemctl restart ceph-mgr@node-03.service
[root@node-03 ~]# systemctl enable ceph-mgr@node-03.service
5.5 配置MDS服务
- 准备MDS服务目录
在Node-01:
[root@node-01 ~]# sudo -u ceph mkdir /var/lib/ceph/mds/ceph-node-01在Node-02:
[root@node-02 ~]# sudo -u ceph mkdir /var/lib/ceph/mds/ceph-node-02在Node-03:
[root@node-03 ~]# sudo -u ceph mkdir /var/lib/ceph/mds/ceph-node-03- 修改配置文件,追加配置项
在Node-01:
[root@node-01 ~]# cat /etc/ceph/ceph.conf
……
[mds.node-01]
host = 192.168.2.81
[mds.node-02]
host = 192.168.2.82
[mds.node-03]
host = 192.168.2.83
- 同步配置文件到各个存储集群节点
在Node-01:
[root@node-01 ~]# scp /etc/ceph/ceph.conf node-02:/etc/ceph
[root@node-01 ~]# scp /etc/ceph/ceph.conf node-03:/etc/ceph
- 启动MDS服务,设置开机自启
在Node-01:
[root@node-01 ~]# systemctl restart ceph-mds@node-01
[root@node-01 ~]# systemctl enable ceph-mds@node-01
在Node-02:
[root@node-02 ~]# systemctl restart ceph-mds@node-02
[root@node-02 ~]# systemctl enable ceph-mds@node-02
在Node-03:
[root@node-03 ~]# systemctl restart ceph-mds@node-03
[root@node-03 ~]# systemctl enable ceph-mds@node-03
- 创建文件系统的存储池
在Node-01:
[root@node-01 ~]# ceph osd pool create CFS_Data 128
[root@node-01 ~]# ceph osd pool create CFS_Metadata 128
[root@node-01 ~]# ceph fs new CFS CFS_Metadata CFS_Data
[root@node-01 ~]# ceph fs ls
name: CFS, metadata pool: CFS_Metadata, data pools: [CFS_Data ]
[root@node-01 ~]# ceph mds stat
CFS:1 {0=node-02=up:active} 2 up:standby
- 文件系统的挂载与使用
在客户端(Node-00)测试:
[root@node-00 ~]# yum install -y ceph-fuse
[root@node-00 ~]# mkdir /mnt/ceph_fs
[root@node-00 ~]# ceph-fuse -m 192.168.2.81:6789 /mnt/ceph_fs/
[root@node-00 ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/rhel-root 50G 11G 40G 21% /
devtmpfs 7.8G 0 7.8G 0% /dev
tmpfs 7.8G 0 7.8G 0% /dev/shm
tmpfs 7.8G 18M 7.8G 1% /run
tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup
/dev/sda1 1014M 146M 869M 15% /boot
/dev/mapper/rhel-home 146G 33M 146G 1% /home
tmpfs 1.6G 0 1.6G 0% /run/user/0
ceph-fuse 1.4T 0 1.4T 0% /mnt/ceph_fs
[root@node-00 ~]# cd /mnt/ceph_fs
[root@node-00 ceph_fs]# touch ce.file
[root@node-00 ceph_fs]# ll
total 0
-rw-r--r-- 1 root root 0 Feb 22 10:57 ce.file
5.6 配置RGW服务
- 对象存储服务简介
RGW是Ceph集群的对象存储网关,也称Rados网关,它使客户端能够利用标准对象存储API来访问存储集群,它支持S3和Swift API。
通过对象存储,将数据存储为对象,每个对象除了包含数据,还包含数据自身的元数据。对象通过Object ID来检索,无法通过普通文件系统操作来直接访问对象,只能通过API来访问,或者第三方客户端(实际上也是对API的封装)。对象存储中的一个个对象不是整理到目录树中,而是存储在扁平的命名空间中,Amazon S3将这个扁平命名空间称为Bucket,而Swift则将其称为容器。无论是Bucket还是容器都不能嵌套,且Bucket需要被授权才能访问到。一个帐户可以获取多个Bucket的授权,而且不同Bucket的权限是互不干扰、分别制定的。
- 内置网关前端CivetWEB的配置
在所有节点的配置文件中,追加以下配置信息:
[root@node-01 ~]# cat /etc/ceph/ceph.conf
……
[client.rgw.node-01]
host = node-01
log file = /var/log/radosgw/client.radosgw.gateway.log
rgw_s3_auth_use_keystone = False
rgw_frontends = civetweb port = 8080
[client.rgw.node-02]
host = node-02
log file = /var/log/radosgw/client.radosgw.gateway.log
rgw_s3_auth_use_keystone = False
rgw_frontends = civetweb port = 8080
[client.rgw.node-03]
host = node-03
log file = /var/log/radosgw/client.radosgw.gateway.log
rgw_s3_auth_use_keystone = False
rgw_frontends = civetweb port = 8080
- 创建对象存储服务的存储资源池
编写脚本,在Node-01上创建对象存储服务所需的存储资源池:
[root@node-01 ~]# cat rgwPools.txt
.rgw
.rgw.root
.rgw.control
.rgw.gc
.rgw.buckets
.rgw.buckets.index
.rgw.buckets.extra
.log
.intent-log
.usage
.users
.users.email
.users.swift
.users.uid
[root@node-01 ~]# cat createPool.sh
#!/bin/bash
PG_NUM=32
PGP_NUM=32
SIZE=2
for i in `cat /root/rgwPools.txt`
do
ceph osd pool create $i $PG_NUM $PGP_NUM
done
[root@node-01 ~]# bash createPool.sh
- 创建日志文件目录
在Node-01:
[root@node-01 ~]# mkdir /var/log/radosgw/
[root@node-01 ~]# chown ceph:ceph /var/log/radosgw/
在Node-02:
[root@node-02 ~]# mkdir /var/log/radosgw/
[root@node-02 ~]# chown ceph:ceph /var/log/radosgw/
在Node-03:
[root@node-03 ~]# mkdir /var/log/radosgw/
[root@node-03 ~]# chown ceph:ceph /var/log/radosgw/
- 启动并设置RGW守护进程自启
在Node-01:
[root@node-01 ~]# systemctl restart ceph-radosgw@rgw.node-01
[root@node-01 ~]# systemctl enable ceph-radosgw@rgw.node-01
在Node-02:
[root@node-02 ~]# systemctl restart ceph-radosgw@rgw.node-02
[root@node-02 ~]# systemctl enable ceph-radosgw@rgw.node-02
在Node-03:
[root@node-03 ~]# systemctl restart ceph-radosgw@rgw.node-03
[root@node-03 ~]# systemctl enable ceph-radosgw@rgw.node-03
- 测试RGW服务状态
确认所有节点上的RGW服务状态正常,端口监听状态正常(以Node-01为例):
[root@node-01 ~]# systemctl status ceph-radosgw@rgw.node-01
[root@node-01 ~]# netstat -ntlp | grep 8080
tcp 0 0 0.0.0.0:8080 0.0.0.0:* LISTEN 7889/radosgw
- 使用S3CMD连接验证对象存储服务
创建用户:
[root@node-01 ~]# radosgw-admin user create --uid="admin" --display-name="admin"获取Access Key ID和Secret Access Key:
[root@node-01 ~]# radosgw-admin user info --uid="admin"配置S3CMD:
[root@node-01 ~]# s3cmd –configure #进入交互配置模式查看所有Bucket:
[root@node-01 ~]# s3cmd ls创建Bucket:
[root@node-01 ~]# s3cmd mb s3://nextcloud-bucket删除Bucket:
[root@node-01 ~]# s3cmd rb s3://nextcloud-bucket查看Bucket中的文件:
[root@node-01 ~]# s3cmd ls s3://nextcloud-bucket/上传文件到Bucket中:
[root@node-01 ~]# s3cmd put ./Bigfile s3://nextcloud-bucket/Bigfile从Bucket中下载文件:
[root@node-01 ~]# s3cmd get s3://nextcloud-bucket/Bigfile5.7 常用的监控解决方案
- Ceph-Dash
此监控解决方案是一个开源项目,使用Python Flask框架开发,界面干净、简单、整洁,风格让人感到非常舒服。虽然呈现的内容不多,只是将ceph status命令的输出进行了可视化,但是简单的开发框架和界面结构,使得它有二次开发的余地,且便于上手学习。
选择一个 MON 节点部署,或者在所有 MON 节点部署均可:
[root@node-01 ~]# git clone https://github.com/Crapworks/ceph-dash.git
[root@node-01 ~]# pip2 install --upgrade pip
[root@node-01 ~]# pip2 install flask
[root@node-01 ~]# pip2 install rados
[root@node-01 ~]# mv ceph-dash/ /opt/
[root@node-01 ~]# nohup python /opt/ceph-dash/ceph-dash.py > /var/log/ceph/dashboard.log &
启动成功后,监控界面如下图所示:
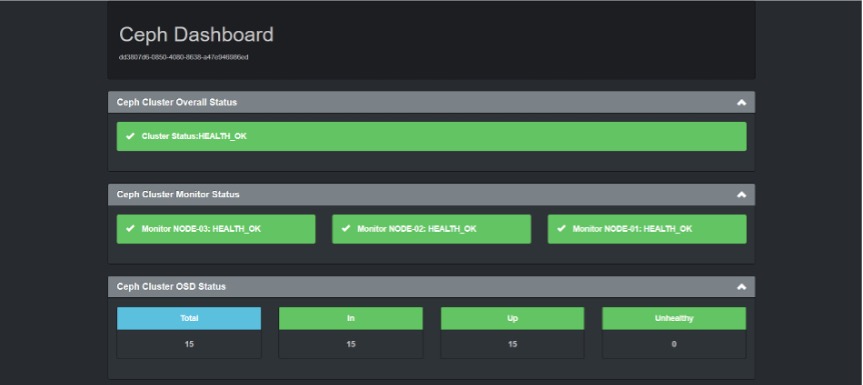
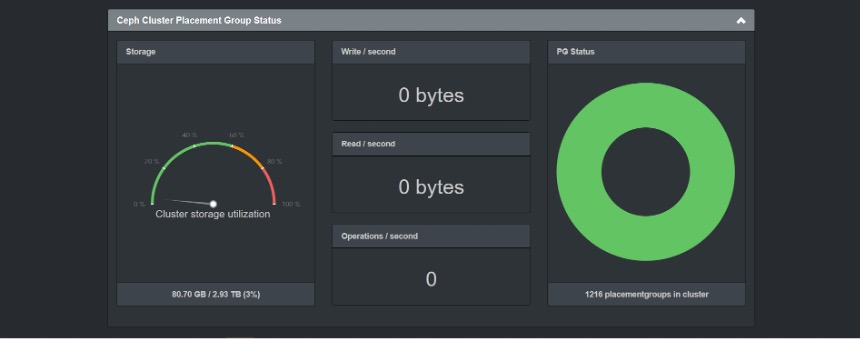
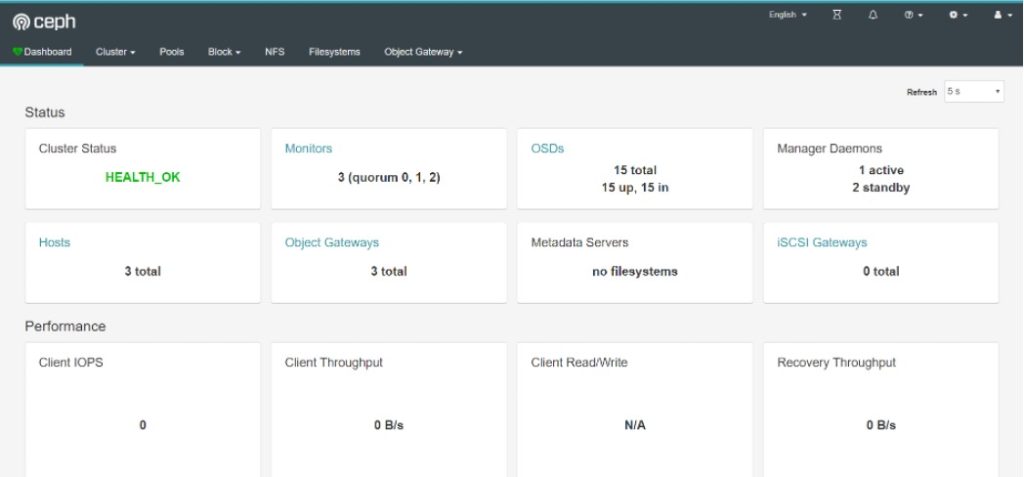
- MGR Dashboard
在集群中的所有MGR节点上安装相应的软件包:
[root@node-01 ~]# yum install -y ceph-mgr-dashboard在集群中的任意MON节点上,开启Dashboard模块:
[root@node-01 ~]# ceph mgr module enable dashboardWeb端配置自签名证书、设置用户名密码:
[root@node-01 ~]# ceph dashboard create-self-signed-cert
Self-signed certificate created
[root@node-01 ~]# ceph dashboard set-login-credentials admin admin
Username and password updated
[root@node-01 ~]# ceph mgr services
{
"dashboard": "https://node-02.open-source.cc:8443/"
}
按照提示的地址,使用设置的用户名密码进行登录,界面如下:
6 参考资料
【1】 Ceph 浅析系列文章(开源技术专家章宇著)
【2】 Ceph 国内社区中文文档
【3】 Ceph 官网的Document
【4】 Ceph 读写性能估算方法
如有其它问题,请填写右侧需求表单联系我们。www.asterfusion.com
