
配置指导:存储场景性能指标与常用测试工具
1 存储场景介绍
如果以产品/架构划分,可分为NAS、SAN、软件定义存储,软件定义存储又可以根据业务场景和架构细分为:分布式存储架构、超融合架构、数据库一体机架构,架构图如下所示。
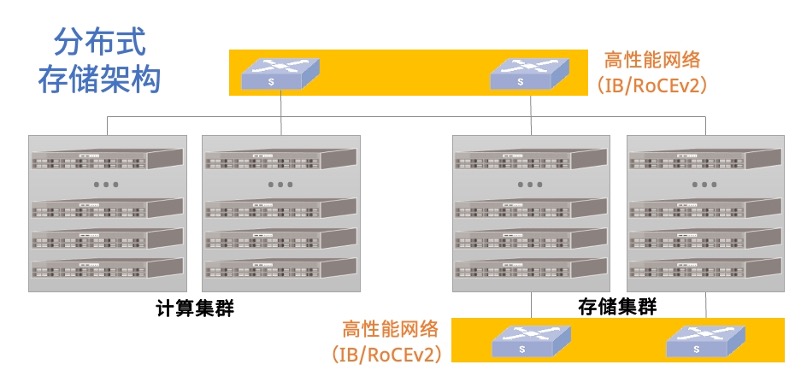
图1:分布式存储架构
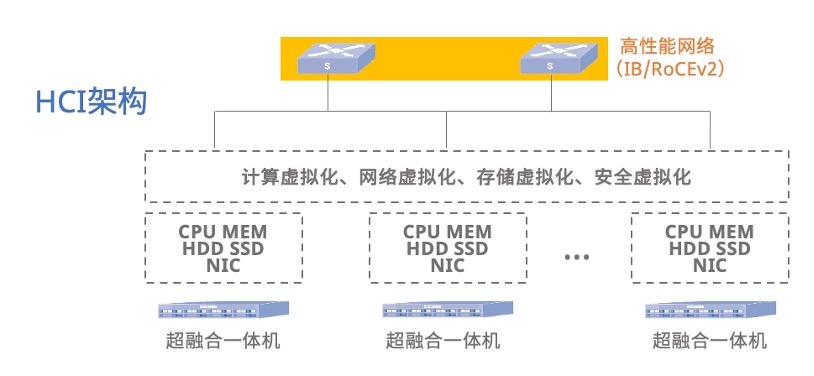
图2:超融合架构
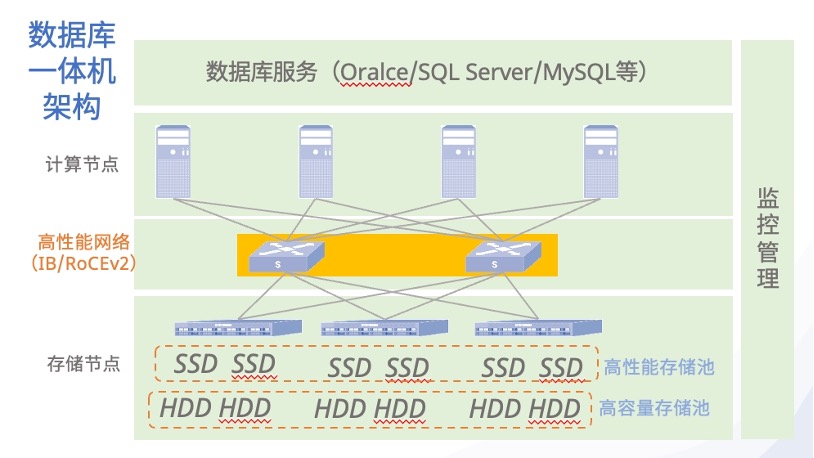
图3:数据库一体机架构
如果以存储最终用户的视角来划分,可以分为块(业务场景为虚拟机用的虚拟硬盘、数据库等)、文件(业务场景为AI、HPC、大数据等)、对象(海量数据存储场景)。对于存储场景的性能指标和常用测试工具的了解,我们就需要以最终用户视角的划分来理解,以上三个架构图仅作为背景信息补充。
2 常用的测试工具
| 应用场景 | 工具名称 |
| 基础性能测试/块 | dd、fio、iostat |
| 文件系统 | filebench、iozone、mdtest |
| 对象存储 | cosbench |
| 数据库 | swingbench、hammerdb |
| 云环境 | vdbench |
3 存储性能指标解读
存储性能测试项整体上分为IO时延和IOPS两个纬度,每个维度中又会按照读/写、数据块的大小分别进行测试。一个IO就是单个读/写请求,IO时延指的是从发起请求到收到存储系统的响应消息所花费的时间,IOPS是指每秒存储系统能处理的IO请求数。
IO的大小对存储的性能表现也有直接的影响。当一次IO操作的数据量比较小的时候,称为小IO,比如1K、4K、8K这样的级别;当一次IO操作的数据量比较大的时候,称为大IO,比如32K、64K甚至更大。总体来说,较大的IO会带来更高的吞吐,较小的IO会产生更高的IOPS。大多数真实的业务场景中,IO的大小是混合的。
另外,IO还有顺序和随机之分,受存储主控的读写缓存策略、预读机制、存储介质的读写原理多方面因素影响,通常情况下随机IO的性能远低于顺序IO、写入性能远低于读取性能。顺序IO指大量的IO请求连续相邻的数据块,典型的业务有日志、数据备份恢复、流媒体等,顺序IO的性能通常就是最高性能;随机IO是指IO请求的是随机分布在存储介质各个区域的数据块,比如高并发读写大量小文件,就会导致IOPS和吞吐的性能下降,典型的业务有OLTP、交换分区、操作系统等,随机IO的性能通常是最低性能。
接下来我们看一个真实的存储性能测试结果,这是国内数据库一体机厂商分别使用Mellanox SB7700与星融元CX532P-N进行组网,使用测试工具fio对数据库一体机的存储系统进行测试后的结果,如下图所示。
| Mellanox SB7700 100G IB交换机 | Asterfusion CX532P-N 低时延以太网交换机 |
|
|---|---|---|
| latr(时延测试-4k随机读) | 141.79us | 132.84us |
| latw(时延测试-4k随机写) | 79.67us | 71.6us |
| latw-8k(时延测试-8k随机读) | 150.64us | 145.83us |
| latw-8k(时延测试-8k随机写) | 80.89us | 73.89us |
| 4kr-1台压力服务器(IOPS) | 1239k | 1275k |
| 4kw-1台压力服务器(IOPS) | 493k | 453k |
| 8kr-1台压力服务器(IOPS) | 1007k | 939k |
| 8kw-1台压力服务器(IOPS) | 330k | 310k |
| 1024kr-1台压力服务器(IOPS) | 11.7k | 11.0k |
| 1024kw-1台压力服务器(IOPS) | 3709 | 3669 |
| 4kr-2台压力服务器(IOPS) | 2548k | 2633k |
| 4kw-2台压力服务器(IOPS) | 850k | 916k |
| 8kr-2台压力服务器(IOPS) | 1992k | 1877k |
| 8kw-2台压力服务器(IOPS) | 535k | 591k |
| 1024kr-2台压力服务器(IOPS) | 17474 | 21.2k |
| 1024kw-2台压力服务器(IOPS) | 3673 | 4820 |
表2:存储性能测试报告
在测试时延时使用的是1v1的方式,测试存储系统IOPS时分别用1v1、2v1的方式进行压测。在衡量存储系统的性能时,时延越低越好,时延代表着存储系统的响应速度;IOPS则越高越好,IOPS x IO Size算出来的峰值,就是存储系统的最大吞吐能力。4 测试流程与使用到的软件
通常,在存储业务场景中,涉及到网络的测试流程分为以下三个步骤:
首先,会进行存储网络的性能测试,这里会关注网络单链路的吞吐和时延,常用的工具是iperf、ib_read/write_bw、ib_read/write_lat;
第二步,会进行存储系统的基础性能测试,这里关注的是存储系统的时延和吞吐,常用的工具是fio;
第三步,会进行业务级别的兼容性、稳定性以及性能测试,兼容性方面主要测试交换机的API是否能满足业务系统的要求,稳定性方面的测试则是网络设备级和链路级别的高可靠,性能测试则会用业务场景专用的测试工具进行压测,比如:数据库一体机常用的工具是swingbench和hammerdb,对象存储场景中常用的工具是cosbench。
5 Fio使用介绍与测试结果说明
5.1 工具介绍
存储性能测试工具fio的全称为Flexible IO Tester,由Jens Axboe开发,Jens Axboe另一个比较有名的身份是Linux内核的块IO子系统的维护者。fio在存储测试中是瑞士军刀一般的存在,首先是诸多可灵活调整的测试参数,使其能够组合出非常多地测试样例,其次就是到现在fio仍处于活跃更新的状态,能根据存储的发展不断进行适配。
5.2 参数说明
本次测试演示,目标是测试服务器在假设的小IO业务场景中(100% 随机,70% 读,30% 写,IO size 4K)的性能表现。
[root@server ~]# fio \
-filename=/root/randrw_70read_4k.fio \
-direct=1 \
-iodepth 1 \
-thread \
-rw=randrw \
-rwmixread=70 \
-ioengine=psync \
-bs=4k \
-size=5G \
-numjobs=8 \
-runtime=300 \
-group_reporting \
-name=randrw_70read_4k_local-filename=/root/randrw_70read_4k.fio
支持文件、裸盘、RBD image。这次要测的是文件系统,filename=<具体的文件名>;如果是RBD image,filename=<具体的image name>;如果是裸盘,filename=<具体的设备名>;该参数可以同时制定多个设备或文件,格式为:-filename=/dev/vdc:/dev/vdd(以冒号分割)。
-direct=1
direct即使用直接写入,绕过操作系统的page cache。
-iodepth=1
iodepth是设置IO队列深度,即单线程中一次给系统多少IO请求。如果使用同步方式,单线程中iodepth总是1;如果是异步方式,就可以提高iodepth,一次提交一批IO,使得底层IO调度算法可以进行合并操作。异步方式,一般设置为32或64。注意响应时间在可接受的范围内,来增加队列深度,因为队列深度增加了,IO在队列的等待时间也会增加,导致IO响应时间变大,这需要权衡。 单路IO测试设置为1, 多路IO测试设置为32。
-thread
fio默认是通过fork创建多个job,即多进程方式,如果指定thread,就是用POSIX的thread方式创建多个job,即使用pthread_create()方式创建线程。
-rw=randrw
设置读写模式,包括:write(顺序写)、read(顺序读)、rw(顺序读写)、randwrite(随机写)、randread(随机读)、randrw(随机读写)。
-rwmixread=70
设置读写IO的混合比例,在这个测试中,读占总IO的70%,写IO占比30%。
-ioengine=psync
设置fio下发IO的方式,包括sync(同步IO)、psync(同步IO,内部使用pwrite、pread方式,和write、read区别是:读写到某个位置时不会改变文件位置指针)、libaio(Linux异步IO,Linux只支持非buffer IO的异步排队,也就是direct需要设置为1)、posixaio(POSIX异步IO,是glibc在用户空间实现的,自己维护多个线程进行异步操作,比较耗费资源,扩展性差)、rados(直接使用libaio接口测试RADOS层IO)、rbd(直接使用librbd接口测试RBD Image IO)。本次测试使用的IO引擎为psync。
-bs=4k
bs即block size(块大小),是指每个IO的数据大小。使用场景是数据库的时候,通常采用4k、8k等小数据块,主要关注IOPS指标;使用场景为视频存储、归档等大文件的时候,通常采用1m、4m等大数据块,主要关注带宽吞吐指标。默认情况下,单位小写代表换算基数为1024,大写代表换算基数为1000,即1m=1024k,1M=1000k。随机读写测试设置为4K,顺序读写吞吐测试设置为1M。
-size=5g
测试总数据量,该参数和runtime会同时限制fio的运行,任何一个目标先达到,fio都会终止运行。
在做性能测试时,尽量设置大点,比如设置2g、5g、10g或者更大,如果基于文件系统测试,则需要-size需要<4g。
-numjobs=8
本次作业同时进行测试的线程或进程数,线程还是进程由前面提到的thread参数控制。
-runtime=300
测试总时长,单位是s。和size一起控制fio的运行时长,在做一般性性能测试的时候,该时间也尽量设置长点,比如5分钟、10分钟。
-group_reporting
多个jobs测试的时候,测试结果默认是单独分开的,加上这个参数,会将所有jobs的测试结果汇总起来。
-name=randrw_70read_4k_local
本次测试作业的名称。
5.3 测试结果
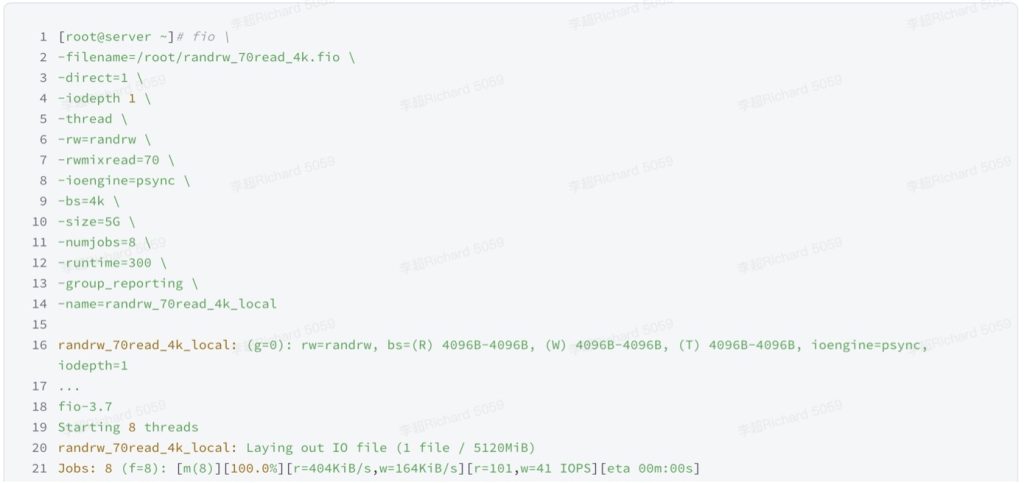

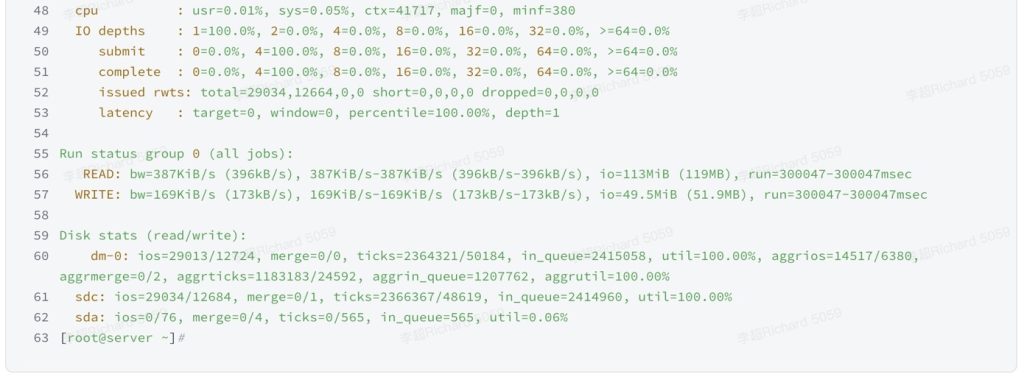
图4:fio性能测试结果
5.4 结果解读
Line 16~22
软件版本、执行参数、任务名、运行过程输出等信息。
randrw_70read_4k_local: (g=0): rw=randrw, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=psync, iodepth=1
...
fio-3.7
Starting 8 threads
randrw_70read_4k_local: Laying out IO file (1 file / 5120MiB)
Jobs: 8 (f=8): [m(8)][100.0%][r=404KiB/s,w=164KiB/s][r=101,w=41 IOPS][eta 00m:00s]
randrw_70read_4k_local: (groupid=0, jobs=8): err= 0: pid=49066: Wed Mar 8 14:33:21 2023Line 23~33
此部分是读性能的测试结果,其中整体IO时延lat = 提交时延slat + 完成时延clat。slat(submission latency) 是提交IO花费的时间,指从fio创建IO到内核开始处理IO的时间,即在队列中排队的时间。fio会分别统计出最小延迟、最大延迟、平均延迟、标准方差延迟,因为同步IO没有队列,所以,选择同步模式的存储引擎时不显示slat。clat(completion latency)是完成IO花费的时间,从内核开始处理IO,到IO处理完成的时间,不包括提交IO时间。
另外,这部分报告还会统计整体时延分布状态,以99.99th=[ 1020]为例,它的含义是 99.99%的IO的时延都低于1020ms。最后两行分别时读取时带宽和IOPS的测试结果。
# What is the difference between kB s and KiB s?
# 1 kB = 1000 bytes. 1 KiB = 1024 bytes.
# 时间的换算关系:
# 1秒(s) =1000毫秒(ms, millisecond)
# 1毫秒(ms)=1000微秒 (us, microsecond)
# 1微秒(us)=1000纳秒 (ns, nanosecond)
# 1纳秒(ns)=1000皮秒 (ps, picosecond)
# 读性能
read: IOPS=96, BW=387KiB/s (396kB/s)(113MiB/300047msec)
clat (usec): min=159, max=1206.1k, avg=81519.63, stdev=87349.89
lat (usec): min=159, max=1206.1k, avg=81519.97, stdev=87349.89
clat percentiles (msec):
| 1.00th=[ 4], 5.00th=[ 8], 10.00th=[ 14], 20.00th=[ 21],
| 30.00th=[ 30], 40.00th=[ 41], 50.00th=[ 54], 60.00th=[ 70],
| 70.00th=[ 93], 80.00th=[ 127], 90.00th=[ 184], 95.00th=[ 245],
| 99.00th=[ 405], 99.50th=[ 493], 99.90th=[ 835], 99.95th=[ 885],
| 99.99th=[ 1020]
bw ( KiB/s): min= 7, max= 143, per=12.66%, avg=48.99, stdev=20.31, samples=4730
iops : min= 1, max= 35, avg=12.17, stdev= 5.09, samples=4730Line 34~44
此部分是写性能的测试结果,报告中各个指标项的含义与上文中的读性能测试结果一致,不再赘述。
# 写性能
write: IOPS=42, BW=169KiB/s (173kB/s)(49.5MiB/300047msec)
clat (usec): min=155, max=956586, avg=2619.71, stdev=32750.22
lat (usec): min=156, max=956586, avg=2620.25, stdev=32750.24
clat percentiles (usec):
| 1.00th=[ 208], 5.00th=[ 233], 10.00th=[ 247], 20.00th=[ 306],
| 30.00th=[ 330], 40.00th=[ 453], 50.00th=[ 529], 60.00th=[ 857],
| 70.00th=[ 971], 80.00th=[ 1156], 90.00th=[ 1614], 95.00th=[ 4047],
| 99.00th=[ 14877], 99.50th=[ 18744], 99.90th=[750781], 99.95th=[817890],
| 99.99th=[918553]
bw ( KiB/s): min= 7, max= 120, per=14.85%, avg=24.95, stdev=15.98, samples=4044
iops : min= 1, max= 30, avg= 6.16, stdev= 4.00, samples=4044
Line 45~47
此部分是整体时延的分布统计,250=3.28%表示时延在0us ~ 250us的IO占比为3.28%,因此本次测试的时延分布情况为:0us ~ 250us 3.28%、250us ~ 500us 11.27%、…、750ms ~ 1000ms 0.24%、> 1000ms 0.13%。
lat (usec) : 250=3.28%, 500=11.27%, 750=2.09%, 1000=5.49%
lat (msec) : 2=6.16%, 4=1.48%, 10=3.85%, 20=9.96%, 50=19.76%
lat (msec) : 100=17.51%, 250=15.85%, 500=2.91%, 750=0.24%, 1000=0.13%Line 48
此部分是CPU的使用率,分别是:用户态CPU使用率、内核态CPU使用率、上下文切换次数、主要的页面错误数、次要页面错误数。
cpu : usr=0.01%, sys=0.05%, ctx=41717, majf=0, minf=380Line 49~53
此部分是IO深度分布情况,反映了存储系统处理IO请求的速度,本次测试使用的depth为1,因此结果中显示1=100%。
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=29034,12664,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Line 55~57
此部分是读写带宽测试结果的汇总,分别有带宽(bw)、总IO数据量(io)、运行时间(run)。
Run status group 0 (all jobs):
READ: bw=387KiB/s (396kB/s), 387KiB/s-387KiB/s (396kB/s-396kB/s), io=113MiB (119MB), run=300047-300047msec
WRITE: bw=169KiB/s (173kB/s), 169KiB/s-169KiB/s (173kB/s-173kB/s), io=49.5MiB (51.9MB), run=300047-300047msec
Line 59~62
此部分是测试过程中,服务器上块设备的使用情况,包括:设备名称、总IO数(ios,以‘/’分割,前面为read ios、后面为write ios)、IO scheduler合并的IO数(merge,读合并数/写合并数)、设备处理的ticks数(ticks,读使用的ticks/写使用的ticks)、在设备队列中花费的总时间(in_queue)、设备使用率。
Disk stats (read/write):
dm-0: ios=29013/12724, merge=0/0, ticks=2364321/50184, in_queue=2415058, util=100.00%, aggrios=14517/6380, aggrmerge=0/2, aggrticks=1183183/24592, aggrin_queue=1207762, aggrutil=100.00%
sdc: ios=29034/12684, merge=0/1, ticks=2366367/48619, in_queue=2414960, util=100.00%
sda: ios=0/76, merge=0/4, ticks=0/565, in_queue=565, util=0.06%整个测试报告中,Line22~33和Line34~44分别是读写两项测试结果的汇总,基本上可通过这两部分的数据判断出存储系统的性能表现,整体时延越低、IOPS越高,即意味着存储性能越好。附录:常用测试工具的使用文档
【1】dd.md
【2】fio.md
【3】iostat.md
【4】HammerDB.md
如有其它问题,请填写右侧需求表单联系我们。
