星融元高性能私有云网络解决方案
关注星融元

背景与需求
客户的IT建设面临着以下几个问题:
- 随着公司规模日趋发展壮大,目前已经有北京、西安、苏州、武汉、长沙等多个研发中心,研发队伍不断壮大,截止2021年研发人员数量已经达到120多人。大多数研发仍然在个人PC上进行开发,涉及到交换机操作系统的编译,一次编译需要好几个小时,开发效率很低。
- 公司目前在公有云和公司内部机房部署了不少应用,如BUG管理平台、文档管理平台、源码管理平台、企业官方网站、ERP系统、网盘系统,这些应用分散,占用的资源大多还需要额外付费,维护起来也比较麻烦。
针对以上问题,客户决定建设一套自己的私有云网络环境。通过私有云来分配较高配置的虚机满足研发的快速编译需求;通过将企业的IT应用迁移到私有云来节省不必要的开支,并实现统一运维和管理;
Asterfusion解决方案
私有云分成两个区域,一个区域为线上使用环境,主要满足研发虚机分配和客户IT应用部署的需求;
另外一个区域为测试演示环境,主要满足产品测试需求和客户演示需求。同时两个区域相互可达。
客户私有云共分为两期实现:
- 一期线上使用环境主要满足研发虚机使用需求,迁移部分应用,测试演示环境满足基本的组网测试需求。
- 二期主要扩容测试环境,通过加入更多的星融元网络设备,完成更多虚机支撑、业务覆盖全面的的数据中心组网环境。
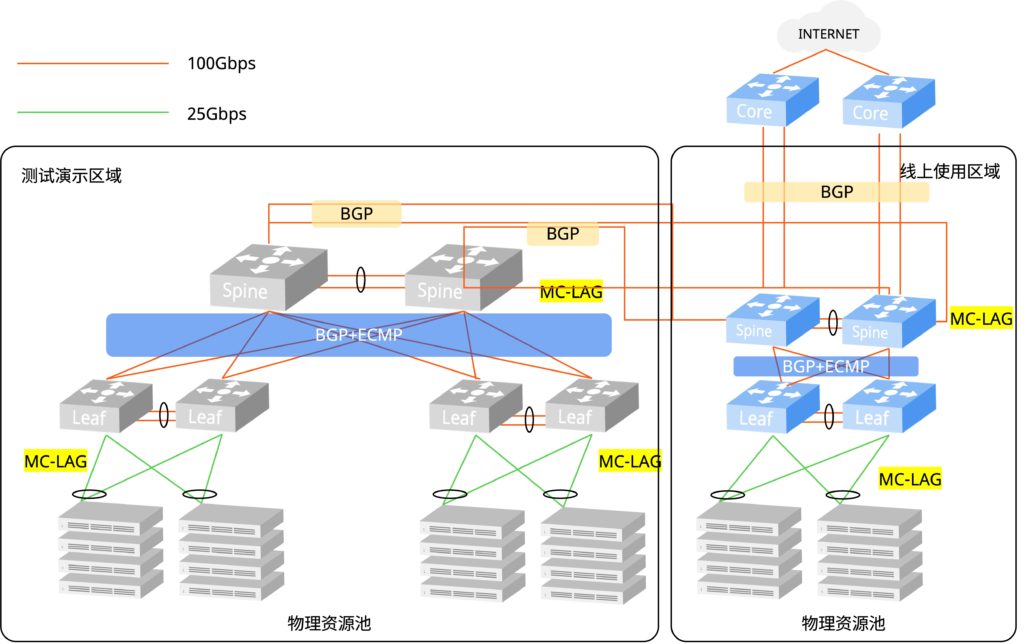
图1:客户私有云一期网络拓扑图
图1为私有云一期网络拓扑,CX532 设备做Spine,CX306 设备做Leaf
- 线上使用区域:2台Spine,2台Leaf,15台服务器。
- 测试演示区域:2台Spine,4台Leaf,10台服务器。
1RU的标准机身,Asterfusion CX5系列下一代云交换机可以提供32个100G/40G高速以太网接口,向下接入服务器和/或向上连接到骨干层的Spine交换机。其具体款型:CX532P整机交换容量为6.4Tbps。
在1RU的标准空间内,Asterfusion CX3系列下一代云交换机可以提供48个10G或25G以太网接口,向下接入服务器,同时提供6个100G/40G高速以太网接口,向上连接到骨干层的Spine交换机。其具体款型:CX306P-48S和CX306P-48T的整机交换容量为2.16Tbps,CX306P-48Y的整机交换容量为3.6Tbps。
无论是线上区域还是测试区域,Spine和Leaf的端口密度都完全满足需求,并为后期扩容提供冗余空间。
在本案例中主要用到了CX306支持的以下高级功能:
- 最大支持64路基于权重的ECMP(实现流量的负载均衡,保证网络转发的高性能)。
- 支持EVPN,可实现VXLAN隧道自动建立、虚拟网络路由动态传播 、分布式网关、非对称IRB、对称IRB。
- 支持LAG/LACP,最大256个聚合组,每聚合组最大128个接口。
- 支持静态路由 / BGP / MP-BGP。
- 支持命令行 / WebUI / Controller / 集中管理 / REST API。
针对一期测试设备种类较少,覆盖功能不全面,客户私有云二期在测试演示环境又增加了一些网络设备。主要增加了防火墙和border-leaf边缘出口交换机。
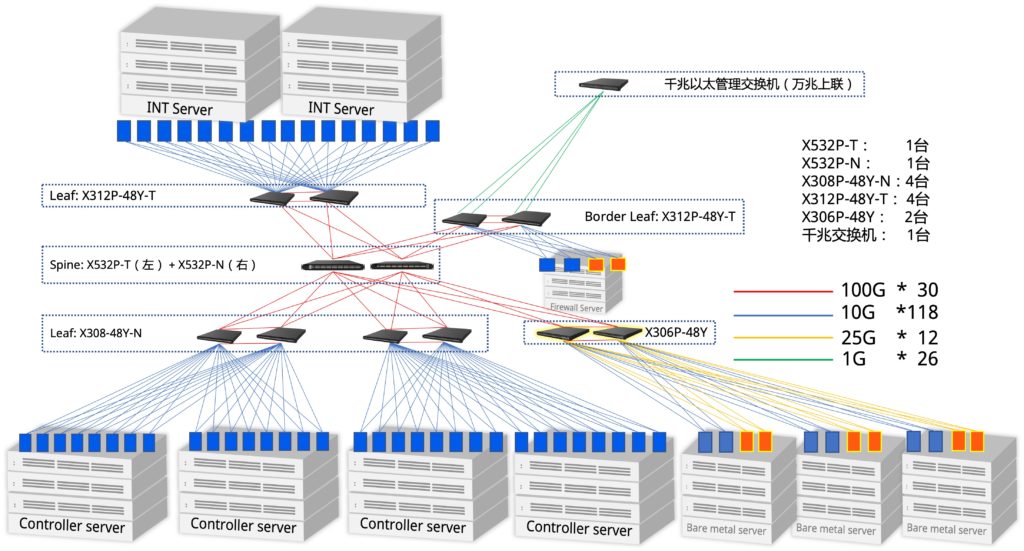
图2:私有云二期测试演示环境扩容后网络拓扑图
图2是客户私有云二期演示环境扩容后的网络拓扑图。X532做Spine,X308、X312、X306做Leaf。服务器4台部署Openstack云平台,2台做INT网络监测方面的测试,1台做Firewall、其余3台做裸金属。
二期主要设备类型:Spine -X532,Leaf-X308,Leaf-X312,Leaf-X306
测试演示环境扩容后能够覆盖更多的网络设备,能够演示更多的网络功能。
另外,星融元的网络设备都可以通过星融元控制器AFC来进行统一配置管理。
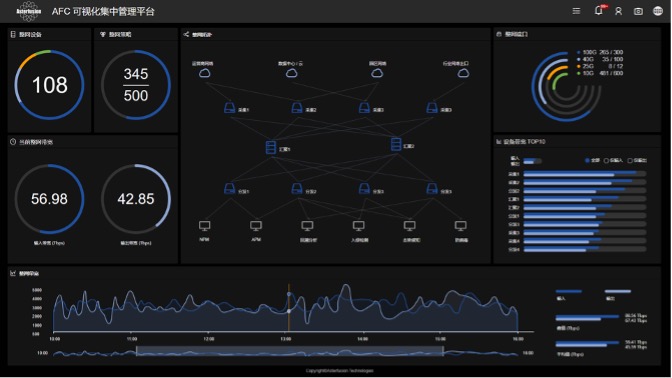
图3:星融AFC控制器主界面
AFC(星融元控制器)覆盖主要功能:
- 整网拓扑自动绘制,拓扑中展示流量的来源、去向,拓扑中带宽占比TOP10设备展示
- 整网输入输入流量建模并AI分析
- 整网设备数量、类型展现,整网端口使用情况、整网实时输入输出流量折线图概览、历史峰值、平均值
- 整网规则余量、整网策略(融合规则)配置,支持搜索某一融合策略并显示该策略途径设备的拓扑
- 支持RestAPI导出第三方接口
- 支持快照功能,包括流量快照、拓扑快照、策略快照等
- 支持AAA、TACACS认证、用户管理、日志、告警、系统设置
- 支持设备批量升级、配置导入导出
- 支持登录设备自带WEB
- X86服务器部署、计划最多支持100台设备的管理
客户的私有云管平台线上环境采用平安自研的云管平台PA_Stack。如下图4是PA_Stack的运营管理员主界面,可以看到目前的虚机资源分配情况。
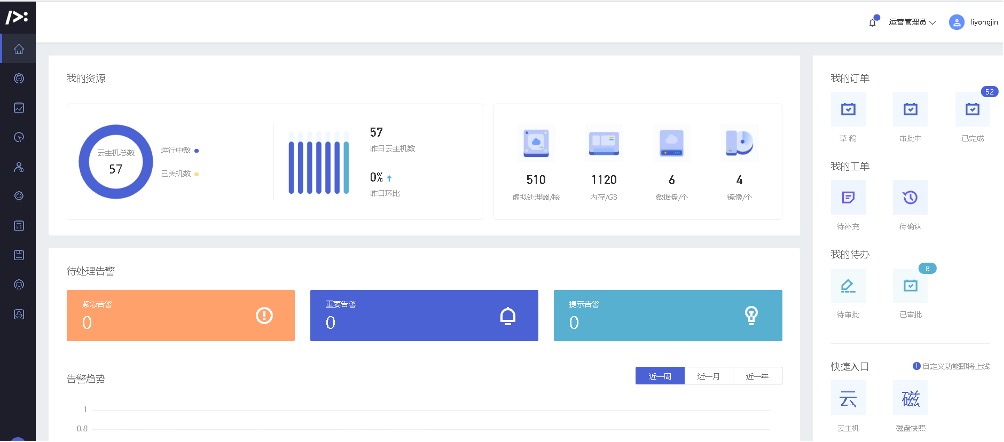
图4:星融私有云管平台主界面
客户私有云管平台测试演示环境采用开源的OpenStack(Rocky版本),同时星融元基于该版本开发了Networking-AFC插件。通过将L2/L3网络功能(网络overlay)卸载至CX交换机上,提高云环境下计算节点的性能。插件依赖于AFC软件,通过该软件所提供接口配置CX交换机。
特色亮点与客户价值
高密度的高速接口设计
在1RU的标准空间内CX3系列下一代云交换机可同时交付48个10G/25G以太网端口和6个100G/40G高速以太网端口,最大程度上提升了空间、能源的使用效率,降低TCO(总拥有成本)的同时获得更高的ROI(投资回报)。
按需自由扩展的扁平化云网络
在 Scale-wide 的云网络中,不需要再为价格高昂的框式 Spine 交换机支付超额的成本,并且将网络的规划、部署、调整、优化、扩展的主动权牢牢掌握在自己手中。CX系列构建的扁平云网络极大地简化了云网络基础架构的复杂性,同时具备超强的横向扩展能力,使云计算 Pay-as-you-grow 的基本理念在云网络中得以体现。
转发平面集成线速的NFV
在可编程交换芯片的支持下,星融元 创造性地将云计算常用的NFV(网络功能虚拟化)特性在CX系列的转发平面中编程实现,从而进一步提升了云网络的使用效率。CX系列云交换机目前支持的NFV功能包括:四层SLB(服务器负载均衡)、NAT(网络地址转换)、DDoS(分布式拒绝服务)攻击流量识别与统计。
易用、多样的网络操作系统支撑二次开发
基于对网络应用的深刻理解,星融元在提供的网络操作系统AsterNOS之上开发了从操作系统内核适配、驱动适配、接口适配、虚拟化网络协议、高可靠控制协议等多种功能特性,以改善开源的SONiC/SAI和Stratum/gNMI/gNOI的可用性、易用性。
与云计算无缝融合的云网络
运行在每一台CX系列云交换机上的 AsterNOS 是星融元基于纯粹的 SDN 理念为云计算时代设计开发的一款开放、智能、易用、高性能的网络操作系统。Asteria Fabric Controller (AFC) 是星融为云计算环境设计开发的Cloud SDN Controller,是一个面向云中业务与应用的Cloud SDN 平台。


-素材-6.jpg)
-图1-1024x483.jpg)
-图2-1024x492.jpg)
-图3-1024x803.jpg)
-图4-1024x391.jpg)

-图片-1-1024x311.jpg)
-图片-2-1024x688.jpg)
-图片-3-1024x541.jpg)

-图-1-1024x201.jpg)
-图-2-1024x56.jpg)

