800G以太网:解锁下一代数据中心的高速互联
近期文章
随着AI技术的快速发展,尤其是大模型的训练和推理过程,数据量呈爆炸式增长,这也对底层基础设施提出了更高的要求,网络传输必须朝着更高带宽和更高密度的方向发展以满足需求。800G以太网在400G的基础上进行扩展,提供800Gbps的数据传输速率。
800G以太网优势何在?
- 高带宽与高速率:提供800Gbps的数据传输速率,远超当前主流网络标准。
- 高吞吐量和低延迟:显著提升数据传输的吞吐量和降低延迟。当下已推出51.2T交换芯片。
- 支持高密度与大规模传输:800Gps的传输速率使其能够在有限的物理空间或资源下,有效传输更多的数据,支持更广泛的网络拓扑和大规模部署。
800G以太网的技术解读
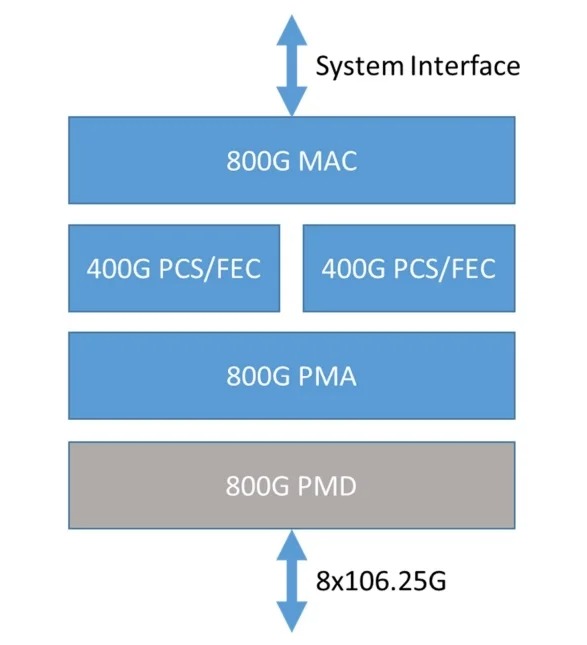
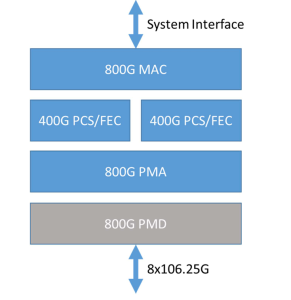
如图1所示,800G以太网实际上是一种接口技术,可以支持单个MAC以800Gb/s的速率运行。800G以太网通过集成两个400G PCS实例来实现其高速率传输。这两个400G PCS实例在数据传输过程中协同工作,共同支撑800G的带宽需求。800G-ETC-CR8/KR8规定,800G PMD子层基于IEEE 802.3ck标准的400Gb/s技术,将原来的4个并行通道扩展为8个并行通道。这就将PAM4(四电平调制)和SerDes速度从上一代的50Gbps翻倍至100Gbps,实现了网络的高带宽与高速率。
800G以太网行业现状
目前市场上的800G交换芯片主要有Broadcom Tomahawk 5、Marvell Teralynx 10和Cisco Silicon One G200,NVIDIA Spectrum-4芯片不对外售卖。它们的制作工艺大多基于5nm,吞吐量都为51.2Tb/s,在端口速率配置和一些特色功能上略有不同。比如Broadcom Tomahawk 5芯片更侧重其高效的SerDes设计降低功耗,Marvell Teralynx 10强调其业界超低延迟表现,Cisco Silicon One G200采用P4可编程并行处理器,更加灵活可定制,而NVIDIA Spectrum-4则是专注于AI网络性能的提升。下面附上芯片能力表格以便直观对比。
| 厂商 | Broadcom | Marvell | NVIDIA | Cisco |
|---|---|---|---|---|
| 芯片名称 | Tomahawk 5 | Teralynx 10 | Spectrum-4 | Silicon One G200 |
| 制程工艺 | 5nm | 5nm | 定制4N工艺 | 5nm |
| 吞吐量 | 51.2Tb/s | 51.2Tb/s | 51.2Tb/s | 51.2Tb/s |
| 端口速率 及配置 | 64x800Gb/s, 128x400Gb/s, 256x200Gb/s | 32x1.6Tb/s, 64x800Gb/s, 128x400Gb/s | "64x800Gb/s (可做两条400Gb/s链路)" | "64x800Gb/s,128x400Gb/s, 256x200Gb/s" |
| 特色功能 | 高效SerDes设计(借助多达 64 × [PM8x100] SerDes灵活配置端口) | 延迟表现低至500纳秒 | 显著提升AI云网性能 | 采用P4可编程并行分组处理器,高度灵活可定制 |
基于这些主流的800G交换芯片已有交换机厂商率先推出800G以太网交换机,例如Arista 7060X5、edgecore AIS800-64D、Cisco Nexus 9232E、星融元Asterfusion CX864E-N等
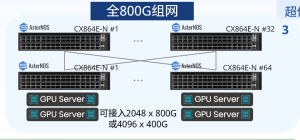
这代表了网络硬件技术的飞跃,满足高速数据传输需求的同时推动了相关行业应用,但800G以太网技术仍未完善,所有市面上的相关产品仍旧有各自的提升空间和要面临的网络挑战。
800G以太网技术如何破局?
挑战一:误码问题
信号在高速传输的过程中受多种因素影响,例如信号衰减、反射散射和噪声抖动等。这些因素会导致信号质量下降,甚至出现比特错误,即误码。误码率指数据传输中错误比特数与总传输比特数的比例,是数字通信系统中衡量传输质量的关键指标。误码率越高,数据损耗程度越严重。然而在更高速的800G以太网中,常规的信号处理技术不足以解决误码问题,需要更复杂的方式来应对。
解决方案:
- 更复杂的FEC算法:FEC是一种前向纠错技术,可以在数据传输过程中添加冗余信息,以便在接收端检测和纠正错误。800G以太网目前所有通道均采用 400 Gb/s 标准支持的 RS(544,514)FEC。然而正在开发的下一代800G收发器将使每个通道的速率达到200Gbps,需要更多的冗余数据、更多的纠错机制和更复杂FEC算法来确保数据传输的可靠性。
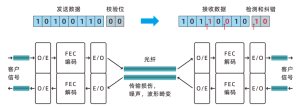
图3:FEC工作原理
- 更先进的DSP技术:优化数字信号处理技术,使得DSP芯片对接收到的信号进行更精确的处理,提高信号的质量和稳定性,减少误码的发生。
挑战二:能耗问题
随着数据中心容量和密度的提升,采用传统可插拔光模块方式逐渐遇到一个困难。传统交换芯片与光模块之间有一条较长的电通道,电通道在速率提升时数据损耗越来越大,为了克服通道上的数据损耗,需要在电通道上做复杂信号处理,这些处理会显著增加系统功耗。再加上光模块本身功耗大,尽管已经进行了高效设计,但在大型数据中心中拥有数以万计的光模块,其整体功耗仍是问题。除了光模块外,SerDes的通道数量和单个通道的速率也在不断提升。在800G以太网中,SerDes的速度增加到100Gbps,芯片周围的SerDes通道数量增加到512,这都会导致功耗的上升。
解决方案
- CPO光电共封装技术:OFC 2022的Workshops针对高速以太网的功耗问题提到了CPO(Co-packaged Optics)技术。该技术将交换芯片和光引擎共同装配在同一个Socketed(插槽)上,形成芯片和模组的共封装。这样的封装方式显著减小了电通道带来的能耗损失和信号干扰,为800G以太网提供更高的功效。
- 更高效的SerDes设计:SerDes需要支持更高的速率和更低的功耗,同时保持较小的面积和成本。
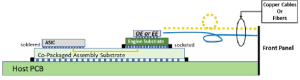
图4:CPO技术的电路板组装 - 优化电路板设计:采用更高效的电路设计和低功耗材料来减少功耗,提高整体能效。
800G以太网的未来
- 从技术创新的角度来说:交换机和光模块技术不断发展,比如100Gbps SerDes广泛应用,都为800G以太网的实现提供了技术基础,有望在未来几年实现800G以太网的大规模商用。目前一些领先的芯片制造商已经发布了支持1.6T以太网PHY解决方案的产品,这表明800G以太网将向着更高速率迈进。
- 从行业标准的制定来说:2022年,OIF完成了400ZR标准规范,并正在制定800G LR和ZR的规范,包括光系统参数、FEC算法、DSP技术、OTN映射等技术方面。2023年,IEEE 802.3dj项目中就800G 10km应用是否采用IMDD(强度调制和直接检测)还是其他相关技术进行了讨论。目前,IEEE 802.3正在积极推进800G及1.6T以太网接口的标准化工作。预计在未来两年内,IEEE 802.3、OIF等国际标准组织将陆续完成800G以太网物理层标准的制定,并推动其在实际应用中的开发和验证。
- 从市场的角度来说:5G 网络、云计算和人工智能等领域快速发展,数据中心对带宽的需求日益增长。800G以太网能够提供更高的带宽和更低的延迟,必定会投入使用,扩大市场规模。再加上目前国内外市场不断有企业在800G通信领域取得显著进展,不难看出800G以太网将成为通信市场的重要增长点。有相关机构预测,到2025年,800G以太网将占数据中心交换机端口的25%以上,表明在未来几年内,800G以太网将实现快速普及。
总结
综上,800G以太网技术是应对未来网络需求的关键解决方案,不断推动数据中心和网络基础设施的升级,满足日益增长的数据传输和处理需求。未来,随着技术的不断进步和市场的扩大,800G以太网有望在未来几年内实现更广泛的商业化和部署。