24年MWC结束了,似乎从来没有在几天时间里说过这么多话、开过这么多会、走过这么多路。
十一月底确定要去巴展,时间已经很仓促了,没有好的展位,一群从来没有搞过展览的年轻人。开始从头做海报、做产品册子,开始琢磨怎样邀请那些熟悉、不熟悉或只有一封邮件之缘的潜在客户来展台,开始用ChatGPT帮我们设计文化衫,腊月二十三产品册子印出来后发现里面还有几个严重错别字需要加紧赶工…



出发前一天一小半人都被流感击中,一边赶路一边吃药… 提前一天到了展厅,展厅位置比想象中还要偏,散漫的加泰罗尼亚人居然把我们主装饰海报搞错了。默默看了看排的十五个沟通会,好吧,那就降低期望,权当借用MWC的场地来一次小型网友奔现活动吧。
26号早上八点半,我穿过春运般的人流向会场挤,突然收到收到Sharon消息说主海报刚刚被更换完毕!在给了工人小哥20欧小费后,瑞士同事前一天带过来,却因deadline已过进不了场馆的展示设备也已经到位、上架。在易拉宝、海报、设备、视频和环绕周围的身着Asterfusion logo T恤衫帅哥美女环绕下,展台好歹终于有那么点点小格调了。


26号10:00迎来了第一个来展厅预约开会的客户,卡,他原来不是来买东西的,他是来推销自己安全模块的(看看人家CEO营销意图隐藏得多好,让我们主动邀请来给我们介绍他家的产品),好走不送~后面还有机会合作,适时结束谈话也需要优雅啊。

送人走的时候,展台外已经有另外两拨visitors在长聊了,展台其实就是摆摊,摊位上有客人的时候总有更多的客人也来凑热闹。
最大开源路由器公司V的CTO应约来访,老兄开始以为我想让他把他们的OS集成到我们的AsterNOS里,并问我场景(我知道会有这样的场景但是我不说,因为我需要你搞定更通用的场景),听了我们基于Octeon CN9670的ET3000和基于Octeon 10的ET2500上的案例后两眼放光,“回家就开始问你们买设备,移植起来!” 这帮他解决了中高端路由器的硬件平台问题~?


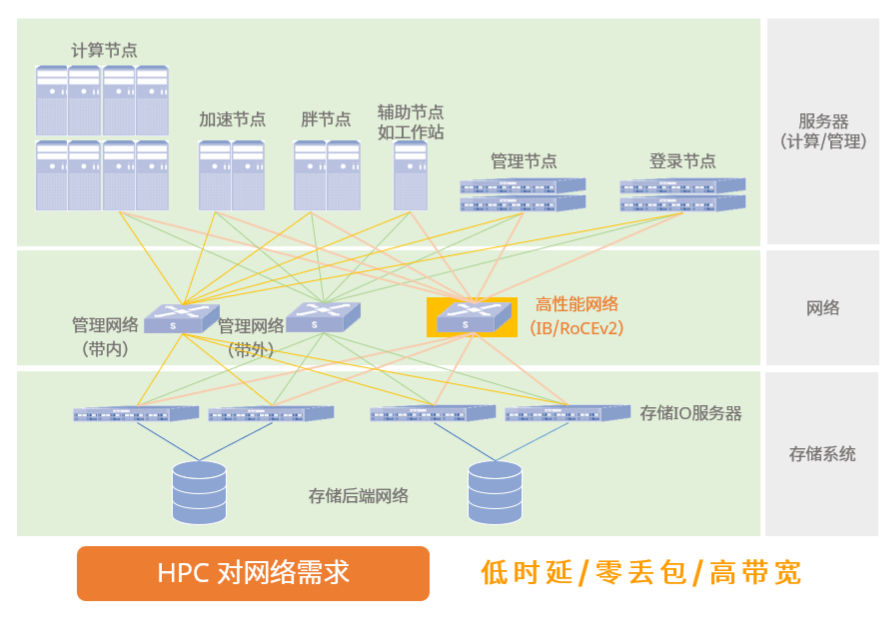
午后还在倒时差,小困,于是CTO Paul老哥用见到路人过展台就 “HOLA, have a look at the best AI switch”的吆喝,一边驱赶睡意一边拉客。当天下午12个客户被Paul拉过来听我们讲了一遍400ns时延和easy RoCE对AI组网的重要性。好吧,的确被拉过来的客人开始有几个一脑门黑线,颇有要和我们辩论一下“AI跟交换机有啥关系呢” 的架势,出门时却都在点头“GPU组网互联确实不能用框啊”。
27号和神交已久的欧洲最大P4与SONiC培训公司S的CEO W会师,在W老兄表达了对P4因为某家停掉路标而起的沮丧时,我们适时送上了(精神和物理的双重)鼓励和治愈,“也许T已死,但P4还在砥砺前行,您且看… ”
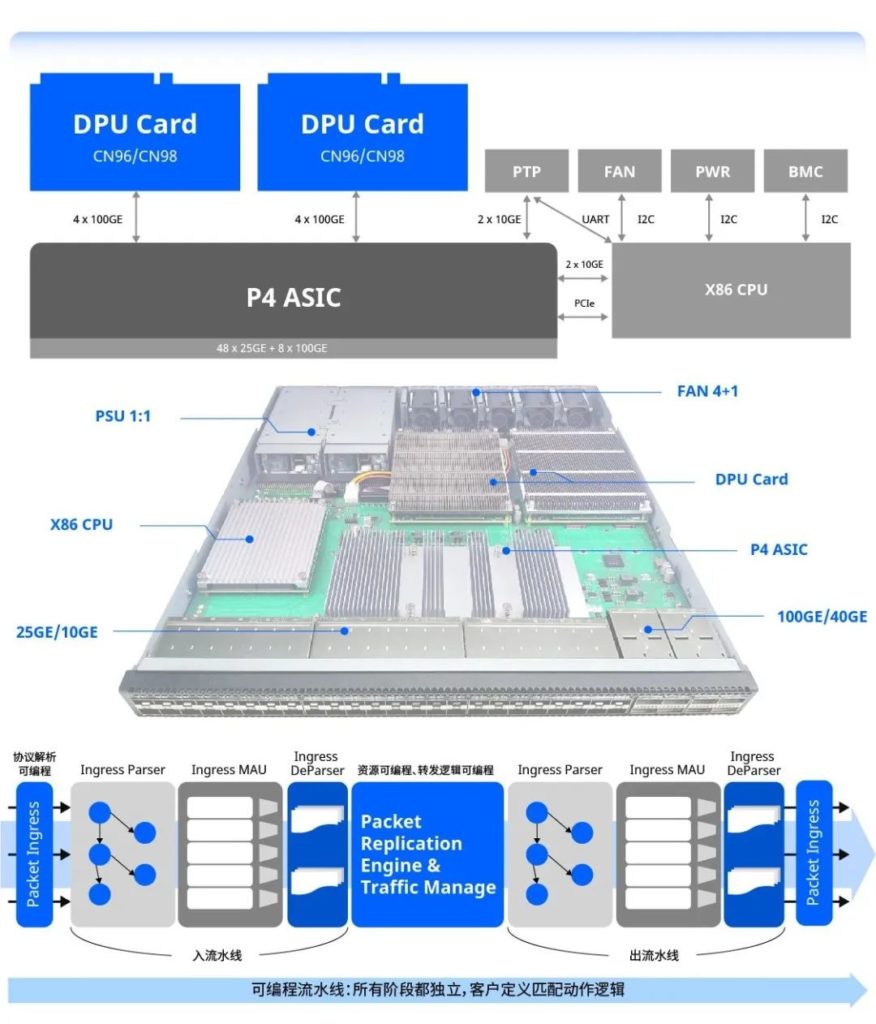
接下来2天,除了费嗓子就是费咖啡,两天七八十来个参观者把我们booth对面展厅的椅子都拽过来了。有法国第三大运营商F的创新研究院副院长,“I don’t like H”;有全球第二大石油公司IT架构负责人,“I don’t like C”;还有跑过来说着友商K价格对比询价36台某型号设备的中东集成商;还有以“oh you are doing the same job as Edgecore”开始听到看到后以 “Oh you are doing much better than Edgecore (because of your excellent software, your hardware portfolio, your service response time) 结论的好多新访客。
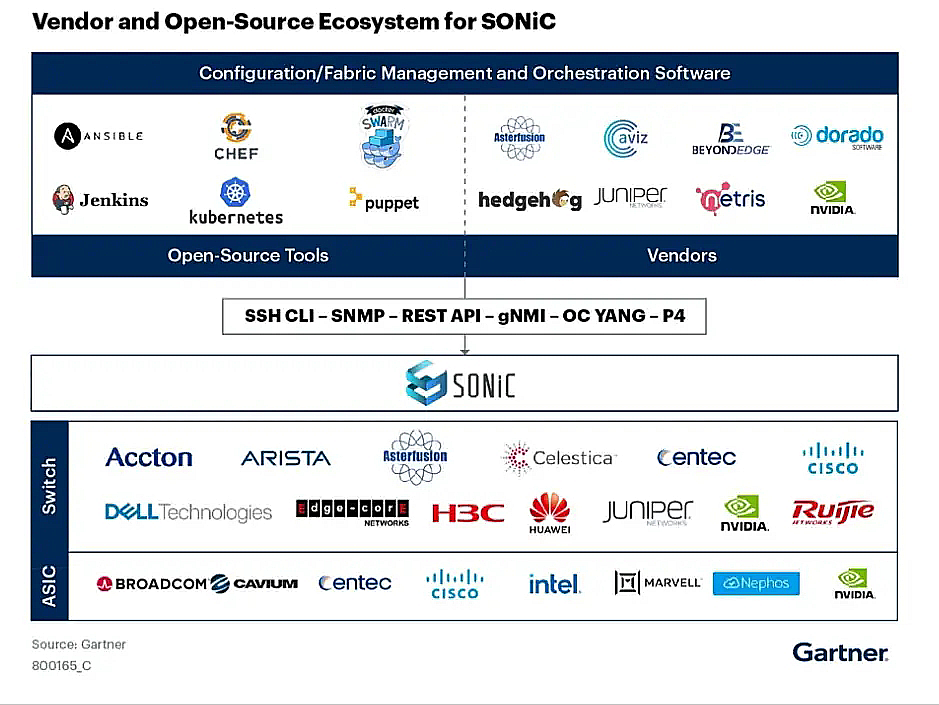
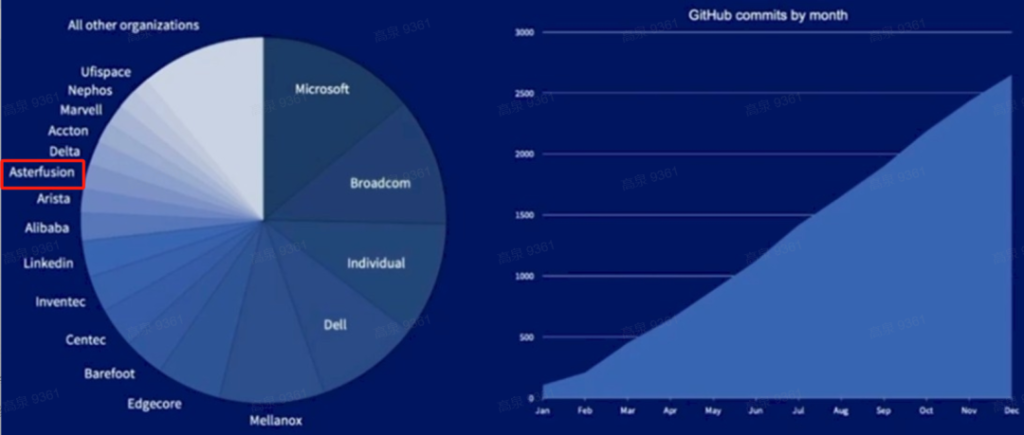
客户眼中 The most powerful SONiC distribution in the planet 确实也被Gartner收录,我们和nvdia是唯二两家同时提供硬件和软件SONiC的玩家
北美客户T的CEO看到PO文里龙年钥匙链挂坠小礼物后,请他在现场的COO也过来了,相比龙年吉祥物,他们应该更喜欢我们这家 “the only turnkey Solution of Open Networking in Cloud, Enterprise and AI”的公司更多一些吧 图片 所以也欣然接受了我们因响应其需求开发的新版本软件升级,影响现网业务的诚挚道歉,并形成结论:一起在现场搭建永久lab,对他们每个新需求发布的的新版本都先在lab中带流量验证,再上线以保障零丢包割接的优化流程。

我们的产品经理Sean在现场感慨说,给客户同时讲龙年吉祥物含义和SONiC交换机能力,这种“传播文化”的感觉真好
更多合作机会和故事略去。和团队复盘时,我问了大家一个问题:为什么这次参展效果超出自己期望?大家众说纷纭,总结的典型打法不表,接下来动手复制就好。
一点点感受:“出海”是最近一段时间挺热门的话题,巴展对我们这样的小公司而言不是一个展示,而是一个验证,欧美市场上,我们的产品方向、客户反馈和团队打法都让人兴奋!ICT进化到IT、封闭标准进化到开放生态的大趋势缓慢但坚定更无法阻挡;世界很大,需要一大群懂需求、有底蕴、守契约、能吃苦、敢冒险、会享受的年轻人把中国程序员的奇思妙想和工程创新传播到全世界,恰好站在这个伟大变局起点的同学们,勇敢往前冲吧!

产品手册(海外版).pdf