云网络的回归之路-高性能篇(下)
关注星融元

上一篇中星融元Asterfusion提出了全面创新的高性能网络方案,并已经从四个方面做了详细的分析,那么,今天大家继续跟着小编来细品这个方案~
自动感知虚拟计算世界的变化
虚拟计算节点的动态变化(创建、删除、迁移、停机、启动等)是云计算的最本质特征之一,也对云网络提出了一个最基础的需求:
云网络需要自动感知虚拟计算世界的变化,随之调整自身的逻辑拓扑、连接关系、策略设置等,成为一张随需而动的虚拟网络。
以802.1Qbg为代表的边缘虚拟化网络技术试图为云计算提供一个计算资源和网络资源交互感知的架构,相应地,对虚拟网络边缘的控制与调度也成为支撑这种交互感知的关键点。
星融元Asterfusion云网络以802.1Qbg为基础构建虚拟网络边缘交换的整体框架。
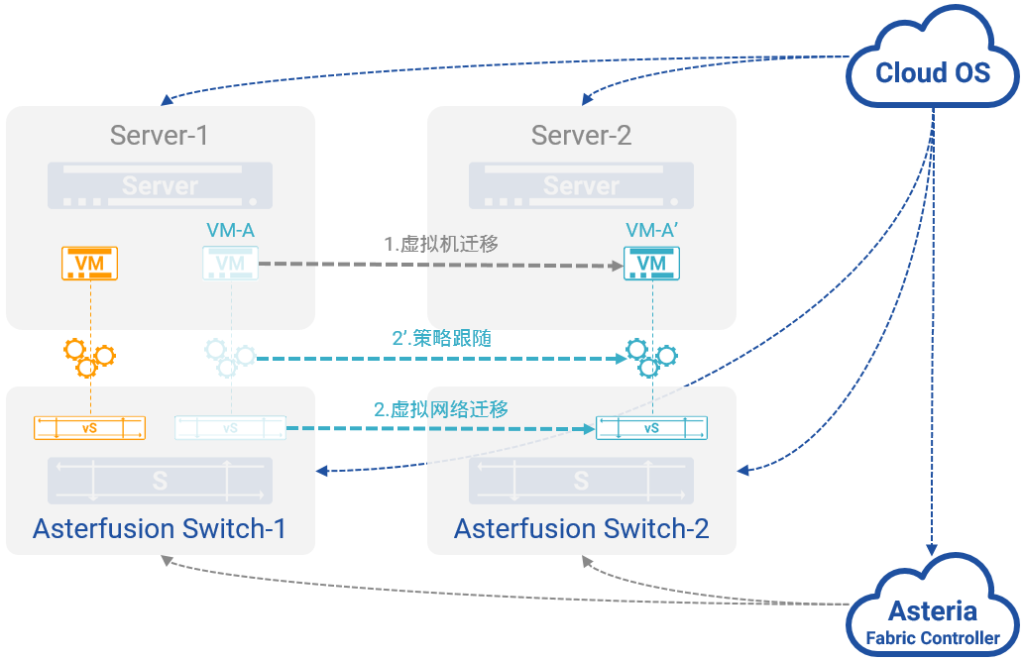
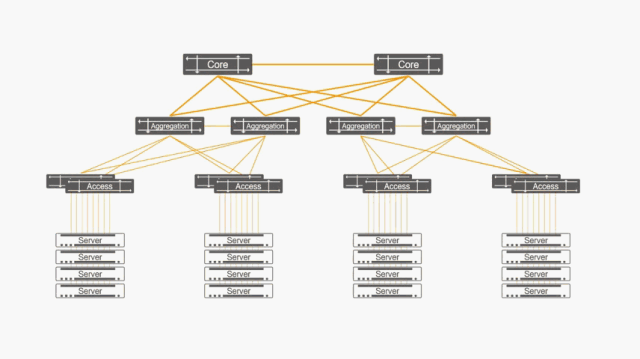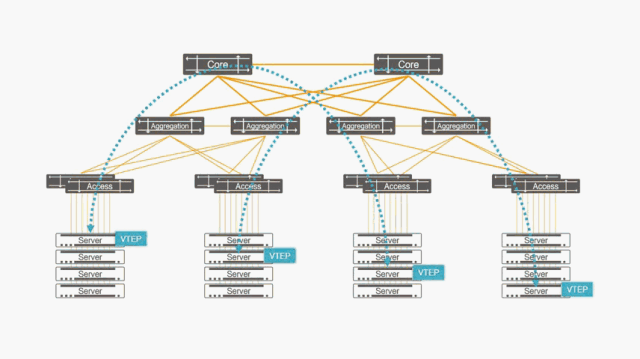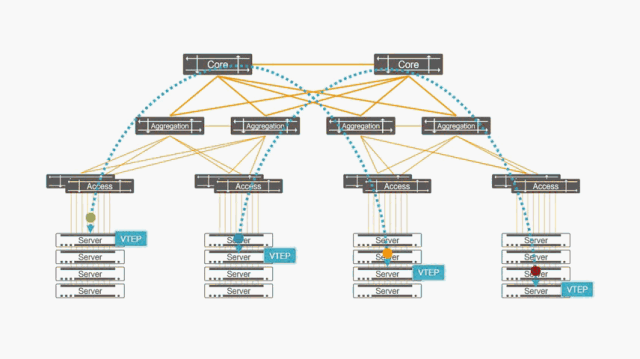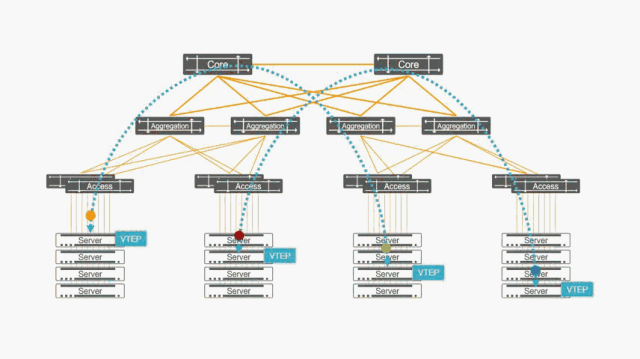
图10:自动感知虚拟计算世界的变化
在星融元Asterfusion云网络中:
- 网络与计算一样,都以资源池的形式被Cloud OS自动化地统一管理和调度,任何对于网络的操作,都以软件调用REST API的形式完成,不需要管理员再手工地进行任何配置;
- 以802.1Qbg为基础完成虚拟计算世界到虚拟网络之间的映射,属于同一虚拟网络的虚拟计算节点,无论其真实物理位置在云中的何处,都被以全局规划、统一分配的方式与其所属的虚拟网络完成关联映射;
- 通过与Asteria Fabric Controller(AFC)和Cloud OS的联动,对于虚拟计算世界发生的任何动态变化,星融Asterfusion云网络都可以同样动态地自动发生变化。图10中,当属于蓝色虚拟网络的某虚拟计算节点VM-A从物理服务器Server1迁移到Server2,“变成”VM-A‘时,星融元Asterfusion云网络通过与Cloud OS之间的控制通道能够即时获取相关信息(物理服务器、所连接的物理交换机和端口、虚拟网络映射信息等),从而自动完成虚拟网络的调整与部署。
- 也可以通过AFC完成,进一步提升整体效率,降低Cloud OS的压力和复杂度。
基于硬件加速的VXLAN虚拟网络
架构在传统网络之上的云面临着如下限制:
- VLAN(Virtual LAN)支持虚拟网络数量太少(少于4K)
- 虚拟网络二层广播域范围受限(无法跨越三层域)
- 影响虚拟计算节点的可迁移性(跨三层域迁移需要变更IP地址)
VXLAN(Virtual eXtensible LAN)的出现帮助云网络成功克服了上述问题,因此成为云中虚拟网络的不二之选。
但是因为传统网络自身的封闭性,使其无法被Cloud OS通过REST API自动化地统一管理和调度。
因此云计算的建设者们不得不抛弃了在传统网络上部署VXLAN的思路,转而在服务器内部通过使用CPU的计算力构建“软件模拟虚拟网络”,来规避传统网络无法被软件定义这一障碍。
所以,更贴切地说,今天的云中广泛部署的SDN,Software Defining Network,其实应该是Software Simulated Network,即软件模拟虚拟网络。
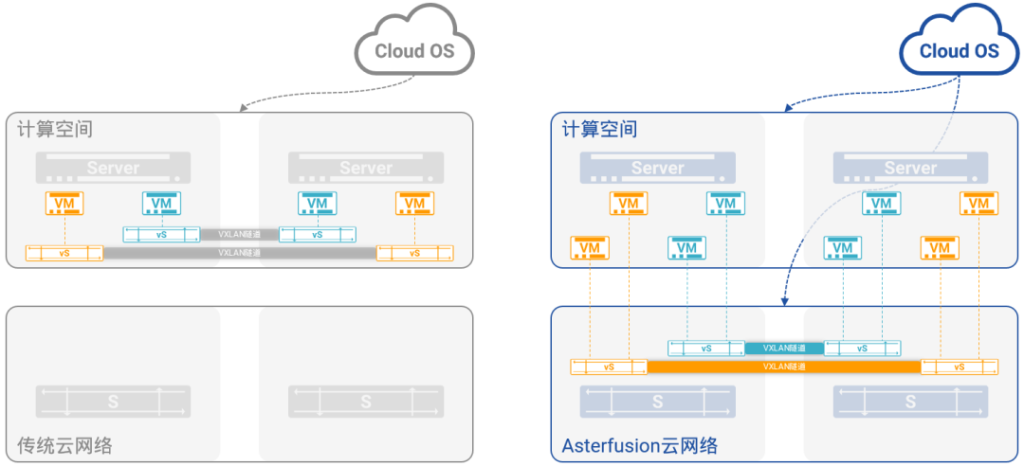
图11:基于硬件加速的VXLAN虚拟网络
如图11,左半部分所示,软件模拟网络的缺点也如其优点一样,是显而易见的:
- 服务器CPU的大量计算力被用于模拟网络,而不是用在虚拟计算上带来更高的回报;
- 同时,花费不菲成本建设的底层网络使用效率极低,相对于能力来说,基本处于限制状态。
可以说,在今天基于软件模拟网络的云中,云计算的建设者面临着“里外里双重浪费”的局面。
在星融元Asterfusion云网络中,这样的局面不会存在。如图11,右半部分所示:
- VXLAN被从服务器的计算空间中卸载到底层网络的硬件交换机上,所有VXLAN相关的操作(隧道建立、维护,报文封装、去封装,虚拟网络多实例与隔离)全部由高性能的硬件完成;
- 曾经大量耗费在软件模拟虚拟网络上的服务器CPU计算力最大程度释放出来被用于完成更多的虚拟计算任务,从而提升整体的ROI;
- 在Cloud OS看来,对星融Asterfusion云网络的操作运维体验,与操作运维计算空间中的软件模拟网络并无二致,同样是点击两下鼠标、或者调用几个REST API,即可完成对星融元Asterfusion云网络的管理;
- 基于PICFA™的支持,星融元Asterfusion云网络一举将云中虚拟计算节点的容量提升到千万量级,同时赋予云网络更高的性能和更优的质量。
因此,星融Asterfusion云网络让云计算中的网络真正回归到网络自身,“计算的归计算,网络的归网络”。
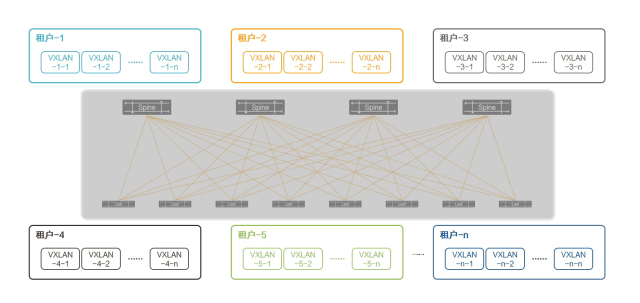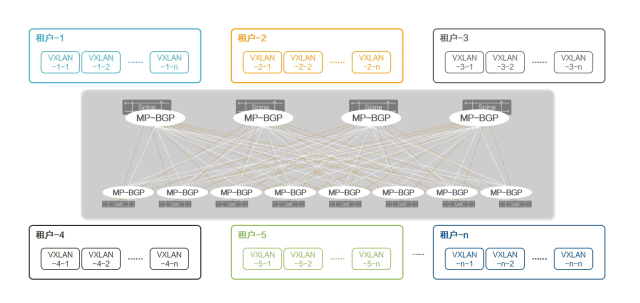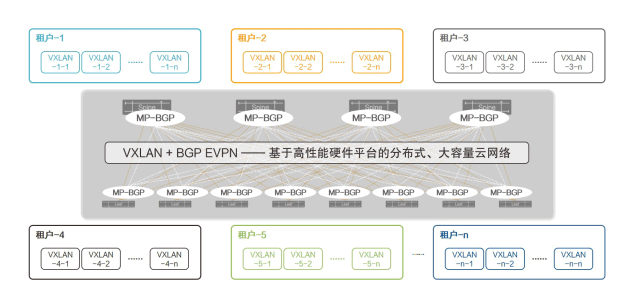
基于BGP EVPN的虚拟网络控制平面
VXLAN很好地解决了前述的问题,但是,因为在最初并没有考虑为其设计独立的信令与控制平面,因此在VXLAN中所有隧道信息、路由信息都是通过人工静态配置和通过数据平面广播学习的方式来完成的。
也正是如此,在VXLAN环境中,部署、配置、变更等全部依赖于人力,效率低下、出错风险高,而且基于广播的学习导致VXLAN中泛洪流量频发,继而致使整网效率低下。
为了解决这个问题,基于原有的MPLS/BGP VPN理念与模型,IETF设计并开发BGP Ethernet VPN(简称BGP EVPN)标准,作为包括VXLAN在内的三种虚拟网络的独立控制平面,BGP EVPN成功地为VXLAN构筑了独立于数据平面的控制平面。
基于BGP的多协议承载能力自动在VXLAN站点之间传播多租户的隧道信息、路由信息、链路状态信息,彻底摒弃了人工静态配置和广播学习的缺点,使VXLAN网络的运维复杂度大幅降低、效率大幅提升。
BGP EVPN让在大规模生产环境中部署VXLAN成为可能。
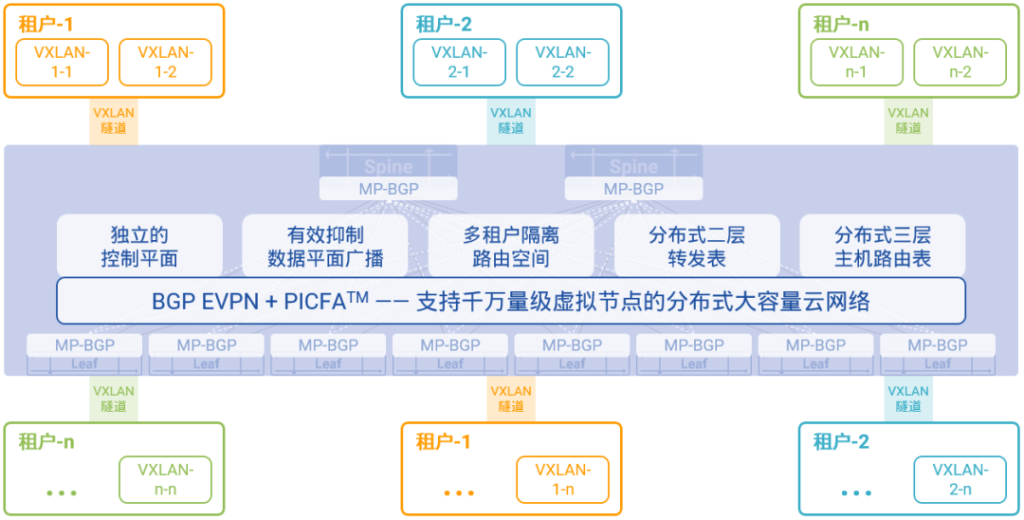
图12:基于BGP EVPN的虚拟网络控制平面
星融元Asterfusion云网络也将BGP EVPN作为虚拟网络独立的控制平面,并且将其与创新的PICFA™融合在一起,形成超大容量、快速收敛、自动管理的虚拟网络解决方案。
在星融Asterfusion云网络中:
- 不但所有虚拟网络的二层转发表以分布式的方式承载在所有网络交换机上,三层主机路由表也被分布到所有网络交换机上,从而使得云中虚拟网络的容量增长100倍至千万量级;
- 交换机的多实例能力将不同租户的不同虚拟网络加载在不同的路由空间中,彼此安全隔离、互不影响;
- 具备多协议能力的BGP承载多租户的路由信息在VXLAN站点之间自动交互,不再依赖人工配置确保转发路径与逻辑的正确性,将手工配置出错的风险降至最低;
- 虚拟网络上出现广播流量的可能性被降至最低,有效地提升了虚拟网络为云中业务提供服务的性能与效率;
- 独立的控制平面,标准化的协议交互,让多家厂商的互通对于用户来说不再是不可能的任务。
融合到转发平面的高性能NFV
NFV(Network Function Virtualization,网络功能虚拟化)是指将一些常用的网络功能以虚拟化的形式部署在云中为运行在云中的业务提供服务,常见的这些网络功能包括四层SLB(Server Load Balancing,服务器负载均衡)、NAT(Network Address Translation,网络地址转换)、DDoS(Distributed Denial of Service,分布式拒绝服务)攻击流量识别与统计。
在当前架构的云中,这些网络功能的虚拟化实现与软件模拟虚拟网络的思路类似,即:如果某个租户的某一种业务需要,就在服务器的CPU上用软件模拟出所需的网络功能来。
以SLB为例,假设有1,000个租户,每个租户有10个业务需要使用SLB,那么就在服务器上创建出10,000个虚拟机,再在这些虚拟机上加载SLB软件为每个租户的每个业务服务;保守估计,这样地场景需要2-3机柜的服务器来专门运行这10,000个SLB的虚拟机。
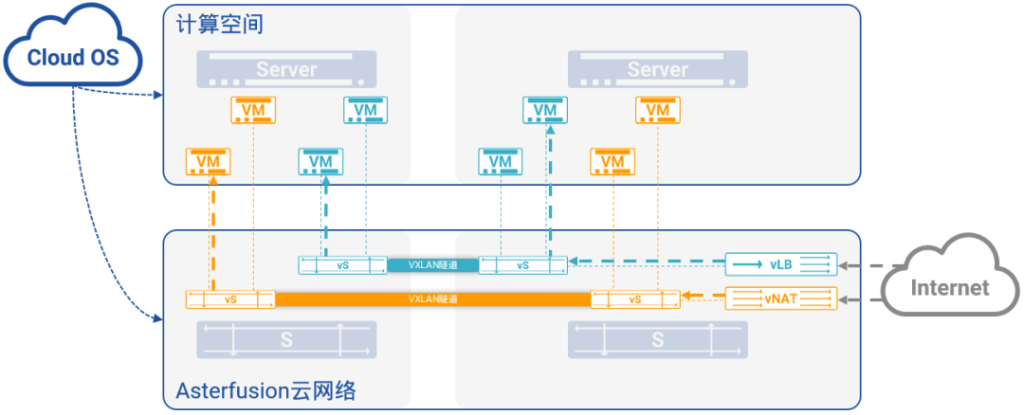
图13:融合到转发平面的高性能NFV
但在可编程交换芯片的支持下,星融Asterfusion创造性地将这些常用的NFV功能在云交换机的转发平面中编程实现,从而提升了云网络的整体性能和使用效率,帮助用户解决了在计算空间中,部署大量虚拟计算节点使用软件模拟NFV,所带来的计算空间性能降级、运维复杂度升高、NFV效率低下等问题。
如上所述的需求,即便再增加一个数量级,仅仅一台星融Asterfusion云交换机就能够轻松地支撑。更为重要的是,这样的NFV功能是在不影响交换机正常转发性能的前提下提供的。
为云中业务提供端到端的QoS
QoS(Quality of Service,服务质量)能力是衡量网络为业务提供服务的质量的最直接标准,一般来说,QoS能力由网络设备的多等级业务标记、多优先级队列发送、拥塞发现与控制、拥塞避免、传送带宽控制等功能构成。
遗憾的是,在今天的云网络中,QoS几乎无从谈起…
运行在计算空间中的软件模拟虚拟网络将底层的物理网络当作一根物理线路,虚拟网络自身缺乏基本的QoS能力,被当作物理线路的底层网络的QoS算法又只能根据所传送流量的外层报文头特征做出QoS判断,而真正能够描述不同租户、同一租户不同业务的优先级特征信息全部被封装在VXLAN隧道中,底层网络设备根本无法识别,QoS算法也不具备处理隧道内层信息的能力。
有了可编程交换芯片的支持,星融Asterfusion云网络成功地解决了这一问题。
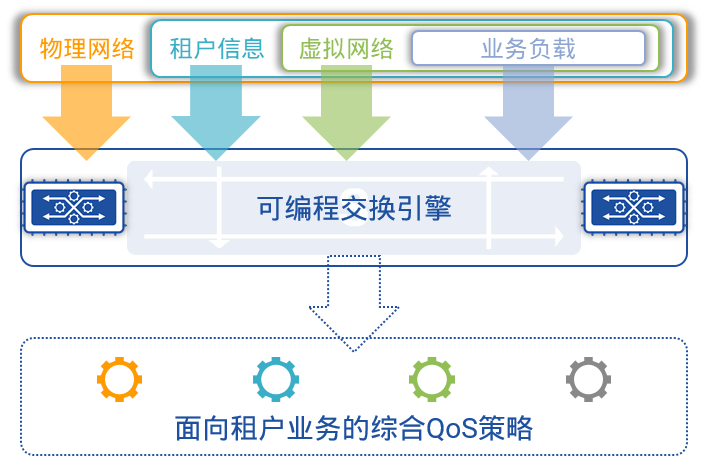
图14:面向租户业务的综合QoS策略
在星融元Asterfusion的云交换机中:
- 对网络流量进行QoS处理时,能够提取、查找、比对、标记的不仅包含外层报文头的各种特征信息,而且包含封装在VXLAN隧道内的租户信息、租户虚拟网络信息、业务信息;
- QoS算法的输入参数也包含上述两部分信息,从而确保算法所作出的决策是针对不同租户或者同一租户的不同业务,而非简单地针对物理线路。
更值得一提的是,在提供高性能、大容量等能力的同时,基于PICFA™架构的星融元Asterfusion云网络还具备真正意义上的端到端QoS能力。
基于创新性的数据平面转发协议,PICFA™架构的星融Asterfusion云网络能够按照用户需求,动态地从底层网络的所有Spine交换机中分配一部分出来,让这部分Spine交换机专门为某一种业务(或某一类应用、某一些虚拟网络、某一群租户)服务,从而确保达到预期的服务质量和商业目标。
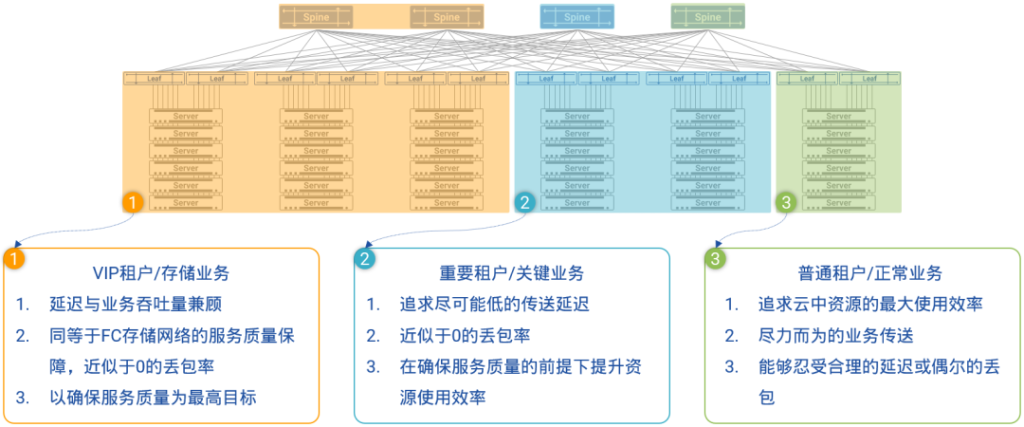
图15:PICFA™为不同租户/关键业务提供端到端的QoS保障
如图15所示,在基于PICFA™架构的星融元Asterfusion云网络中,所有Spine交换机能够被动态地划分为三组,其中第三组可以被指定用来承载VIP租户和关键业务,这组Spine交换机将会被PICFA™从物理上与其他Spine交换机隔离开来,运行在HULL架构(High-bandwidth Ultra-Low LatencyArchitecture)所描述的资源使用率较低的状态下,真正做到了物理隔离,让低优先级租户的流量与尽力传送型业务流量对VIP租户和业务的影响降至0,完全达到SLA(Service Level Agreement)所规定的服务质量保证——极低的网络延迟和近似于0的丢包率。
全面支持DevOps
DevOps是一种新型的软件产品交付模型,它将与软件产品生命周期过程中的各个相关部门(例如研发、测试、运营等)以一种空前的方法连接了起来,并且对他们的沟通、协作等提出了更敏捷、更快速、更频繁的要求。
Asterfusion云网络全力助推云计算进入新时代
星融元Asterfusion云网络是为云计算时代设计的全新一代云网络架构,这个架构完美地解决了当前的云网络方案所面临的诸多挑战。
- 充分释放服务器CPU计算力,降低TCO
基于纯粹的SDN理念和领先的虚拟化技术,星融Asterfusion云网络在底层网络的可编程、高性能硬件平台上构建了面向云中租户与业务的虚拟网络,将大量的服务器CPU计算力从“软件模拟虚拟网络”的压力中释放出来,从而使得服务器CPU计算力的使用效率得到近乎翻倍的提升。 - 大幅提升底层网络的使用效率,提升ROI
传统的云网络架构将花费不菲成本构建的底层网络定义为“粗但是傻”的线路,底层网络大量的功能与性能处于闲置状态。星融元Asterfusion云网络将底层网络重新定义为“粗并且灵”的智能网络,让云中租户与业务服务的虚拟网络直接承载在上面,提供虚拟化、多租户的同时,支持NFV等增值功能,让云的ROI“里外里”地增长。 - 超高性能、超大容量的虚拟网络
星融Asterfusion的专利算法PICFA™将网络对云的支撑能力提升100倍,将单数据中心可制成的虚拟计算节点数量一举提升到千万量级,为大规模公有云向更多的租户提供业务支撑打下坚实的基础。 - 面向租户与业务的端到端QoS
星融元Asterfusion云网络是真正具备面向不同租户和不同业务的端到端QoS能力的云网络,作为QoS算法决策依据的参数不仅仅是底层网络的线路特征信息,而且包含了不同租户和不同业务的特征信息;同时,星融元Asterfusion的PICFA™专利算法天然具备将不同优先级的租户、业务、网络分布到不同底层硬件网络并且充分隔离的能力,从而让QoS真正成为端到端的能力。 - 全面开放的软硬架构彻底融入云
在星融元Asterfusion云网络中,软件的网络操作系统与硬件的交换机平台被彼此解耦,网络彻底解除了对用户的锁定,开放的架构与软件定义的接口让网络真正成为云中的基础设施之一,所有对网络的操作全部通过软件定义的方式进行,并且将Cloud OS对虚拟网络及各种网络功能的管理复杂度降低两个数量级。
我们看到,星融元Asterfusion为云计算构建新一代超大容量、超高性能、超高效率的云网络已经做好了充足准备,摩拳擦掌,蓄势待发!
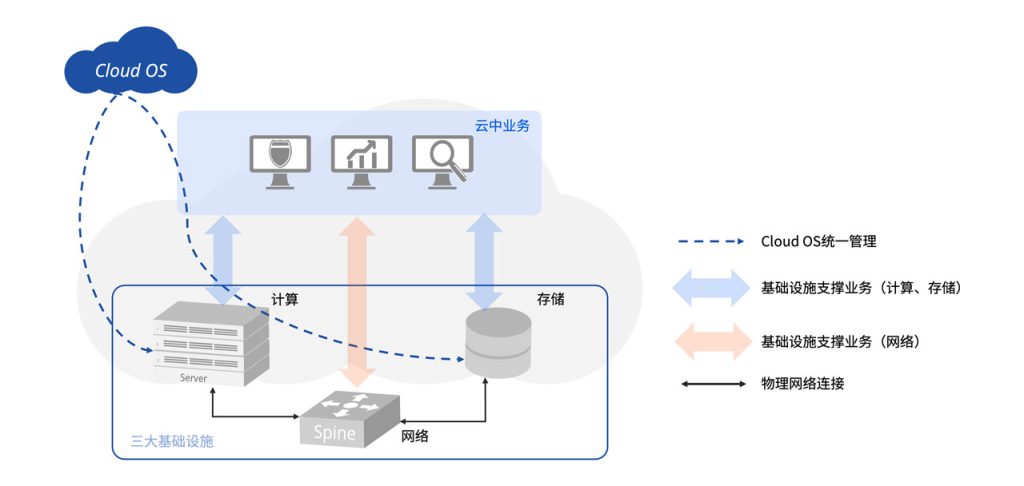
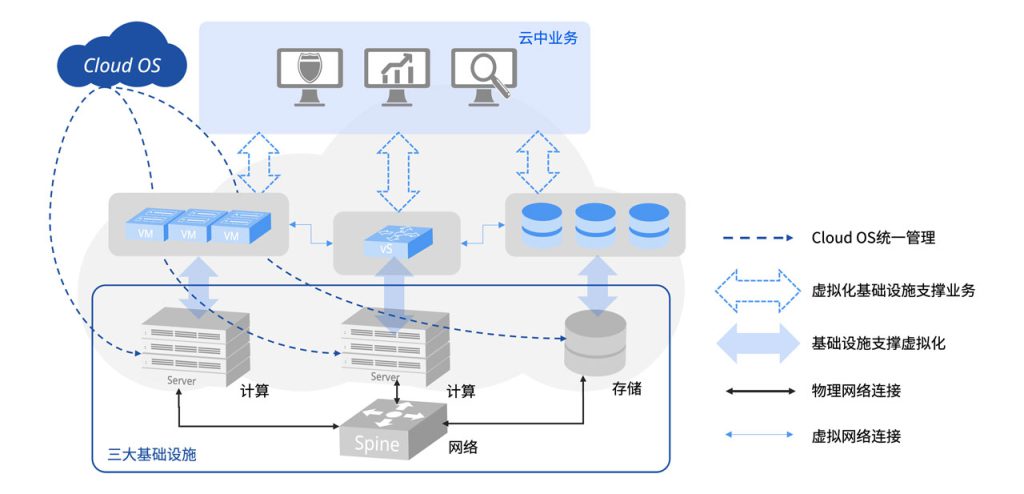
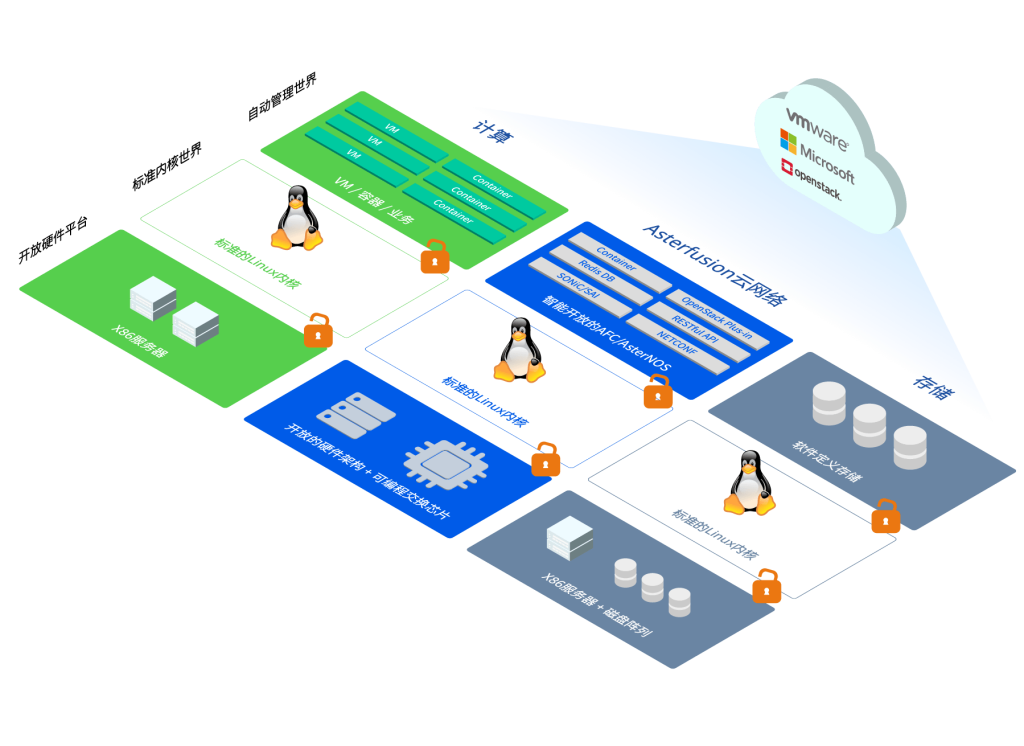
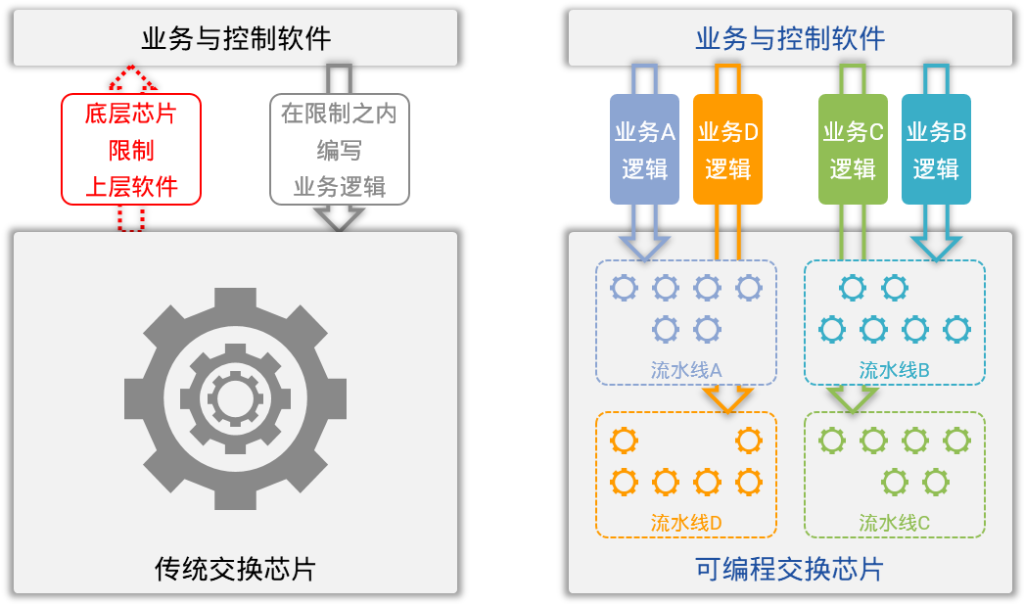
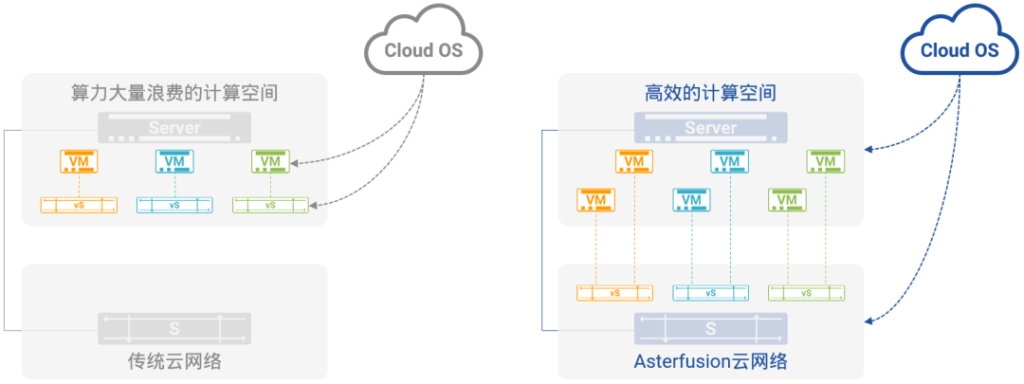
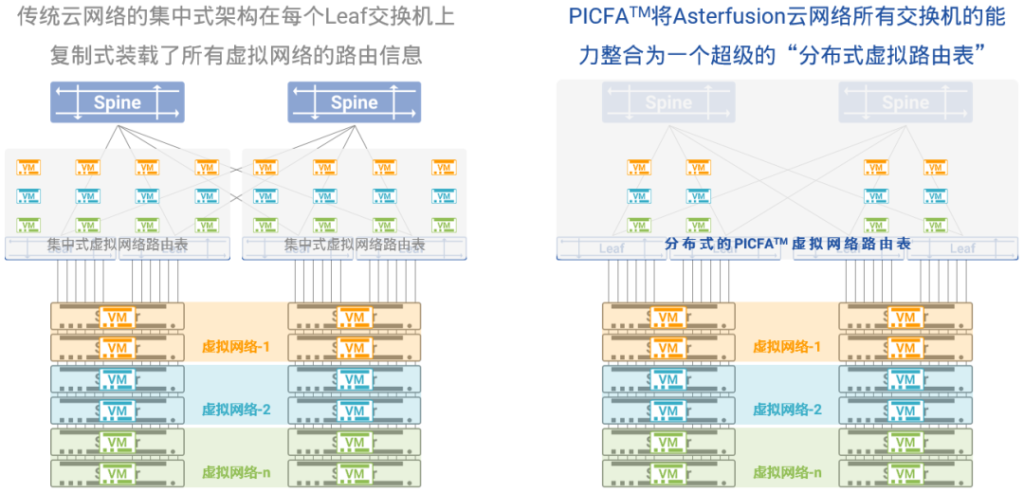

 图1,开放的高性能交换硬件平台
图1,开放的高性能交换硬件平台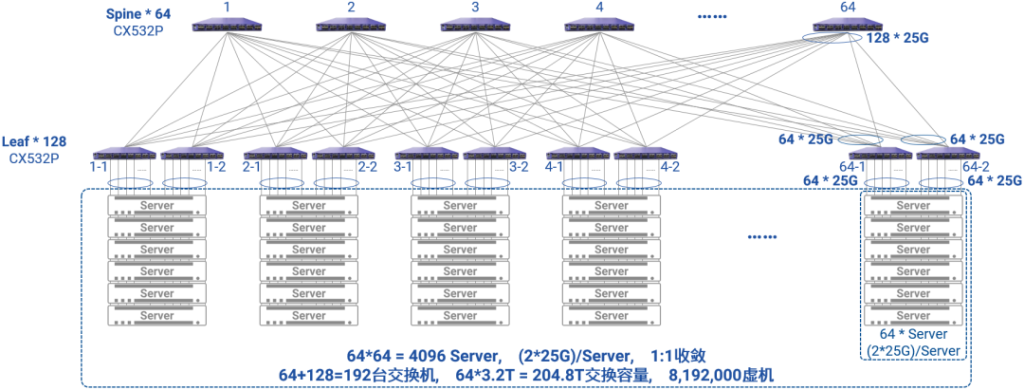 图2,基于Scale-wide架构的大规模Asterfusion云网络
图2,基于Scale-wide架构的大规模Asterfusion云网络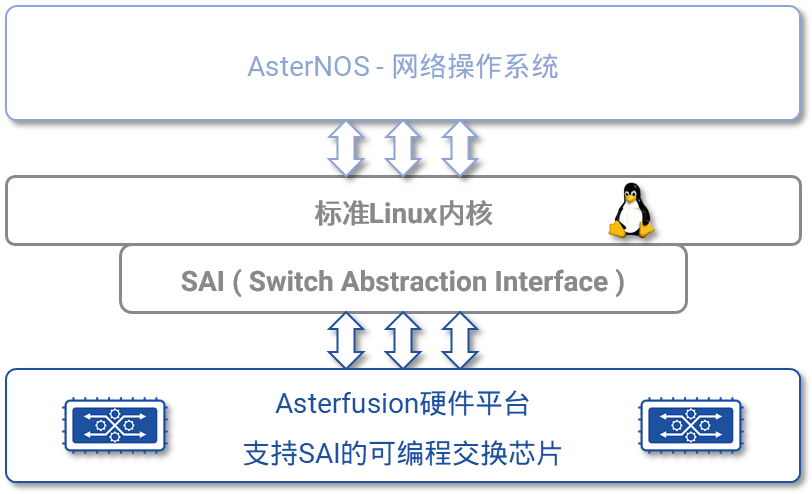 图3,彻底解耦的软件系统与硬件平台
图3,彻底解耦的软件系统与硬件平台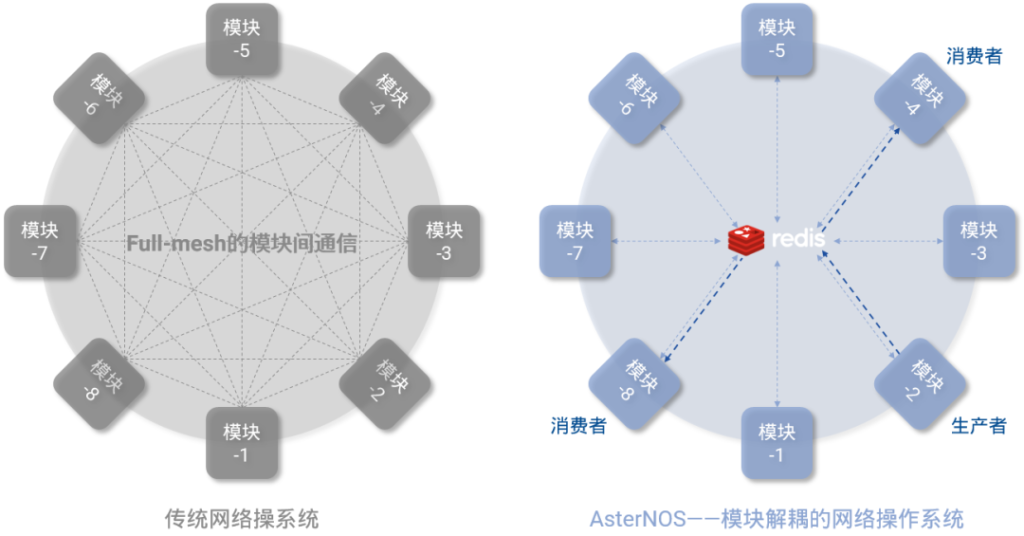 图4,软件模块解耦的网络操作系统
图4,软件模块解耦的网络操作系统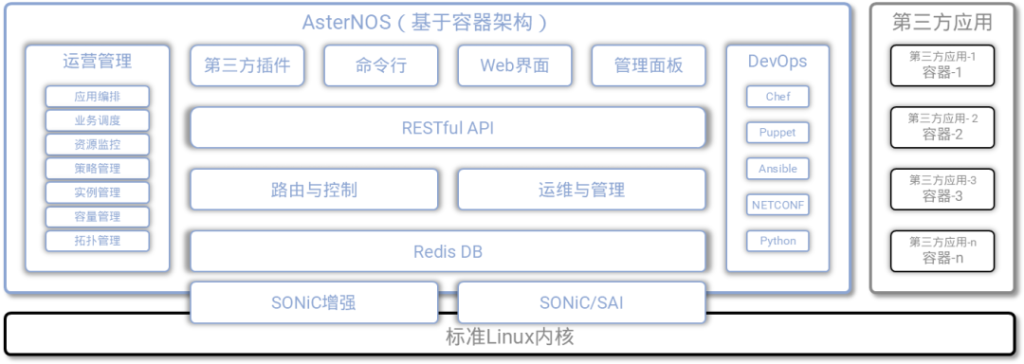 图5,AsterNOS系统架构[/caption]
图5,AsterNOS系统架构[/caption]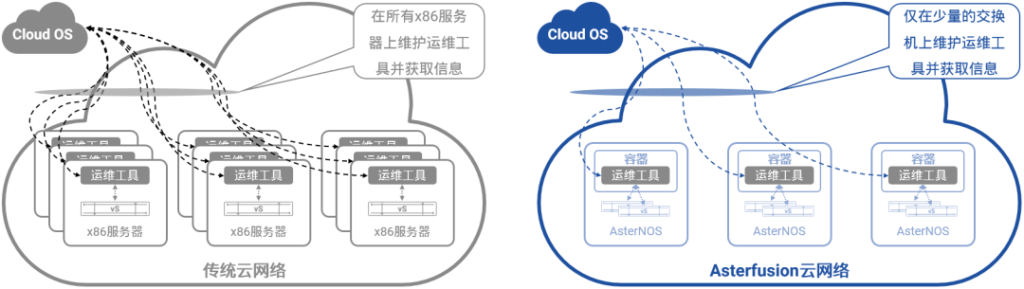
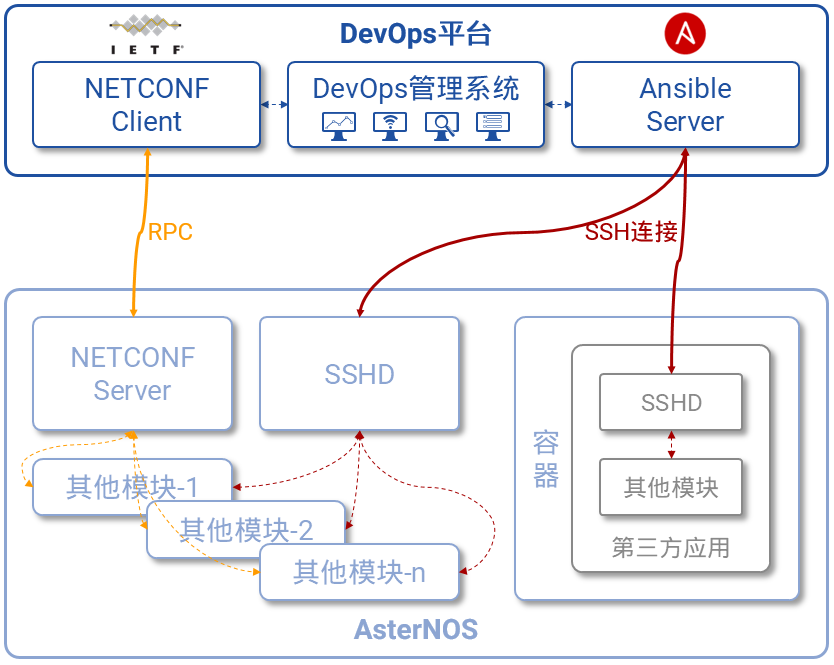 图7,Asterfusion云网络支持DevOps
图7,Asterfusion云网络支持DevOps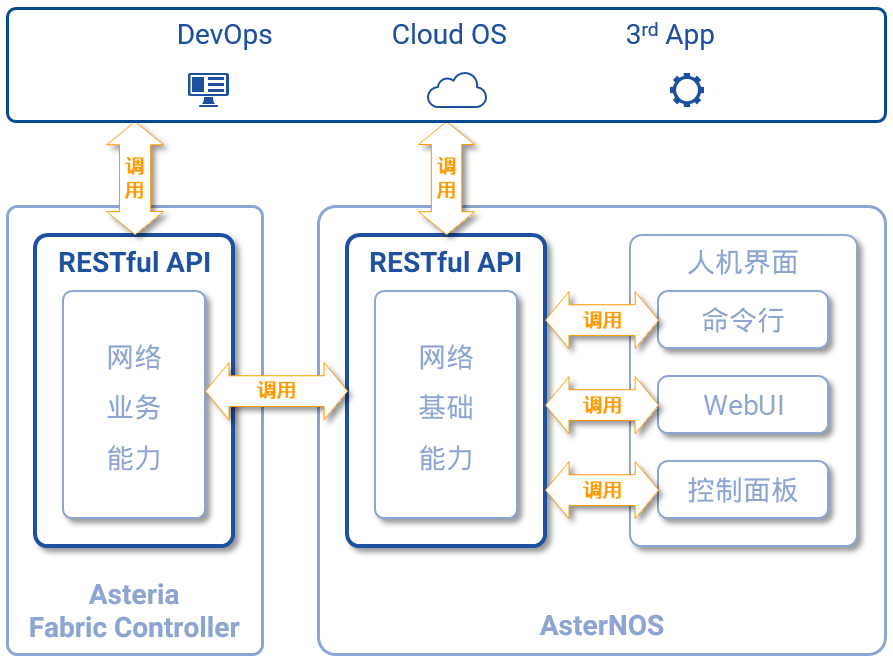 图8,Asterfusion云网络开放所有能力
图8,Asterfusion云网络开放所有能力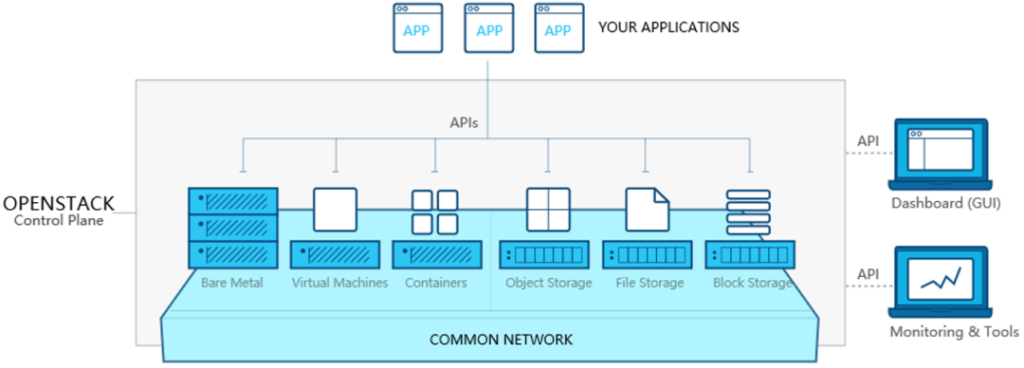 图9,OpenStack——开源、开放的Cloud OS
图9,OpenStack——开源、开放的Cloud OS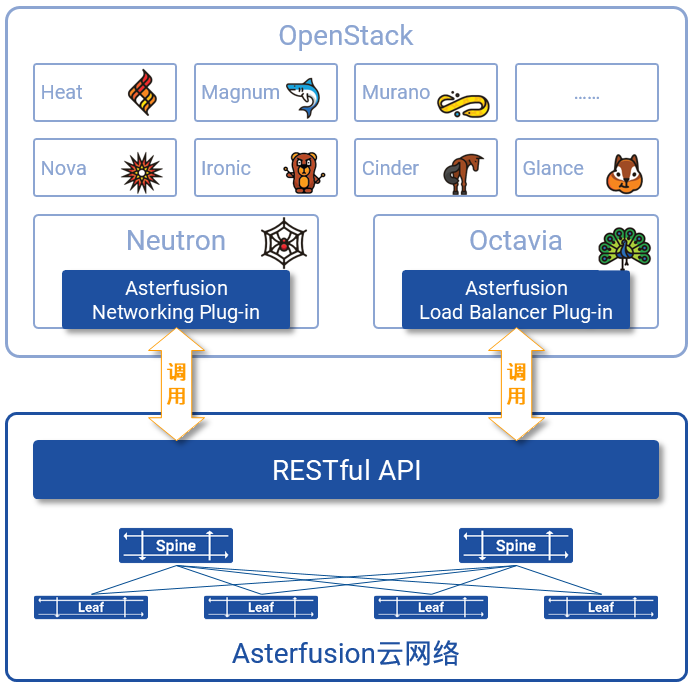 图10,Asterfusion云网络与OpenStack的集成
图10,Asterfusion云网络与OpenStack的集成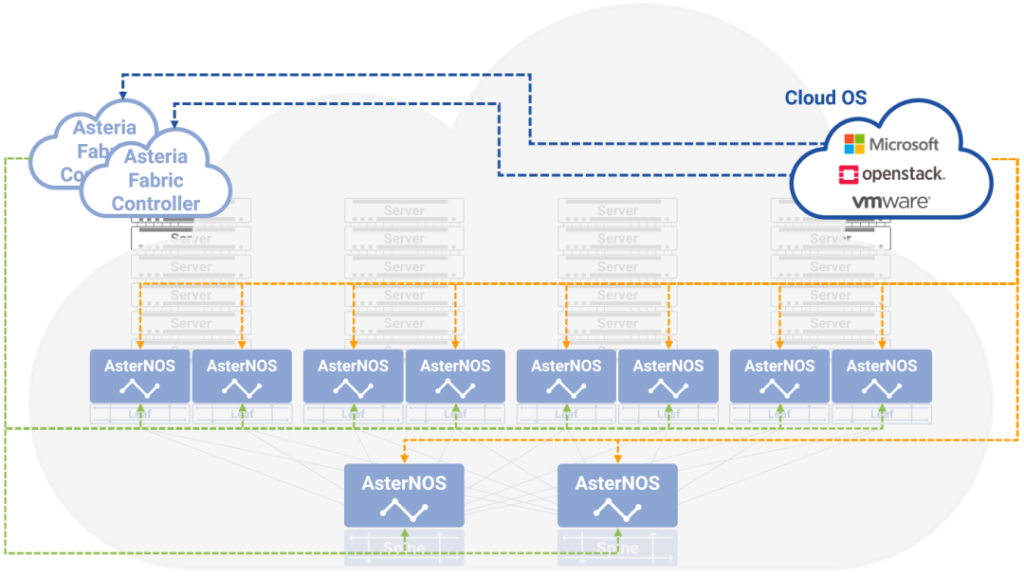

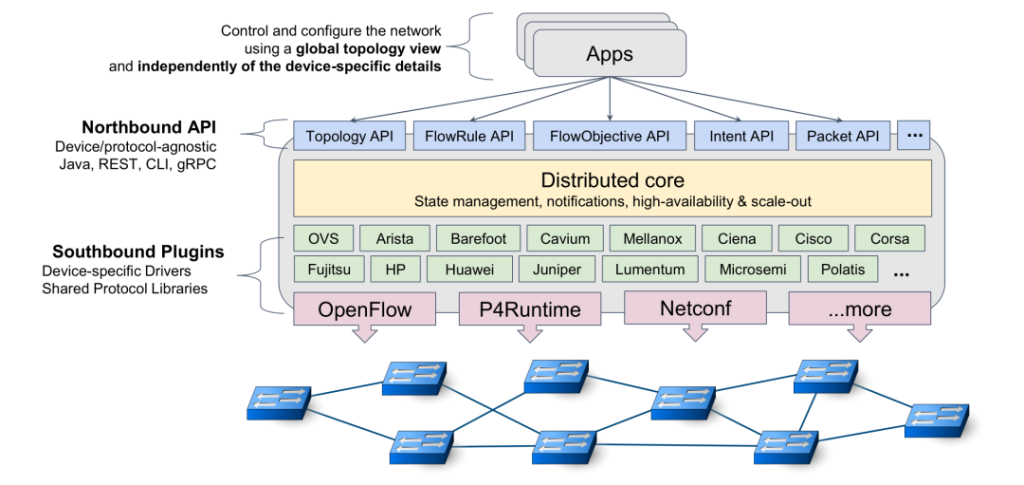 图1 ONOS的总体架构
图1 ONOS的总体架构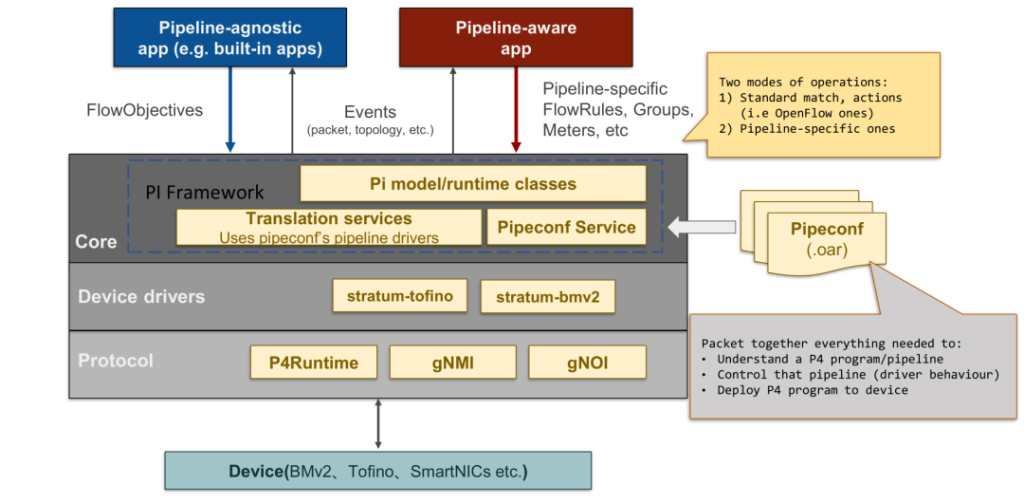 图2:PI框架在ONOS中的架构设计
图2:PI框架在ONOS中的架构设计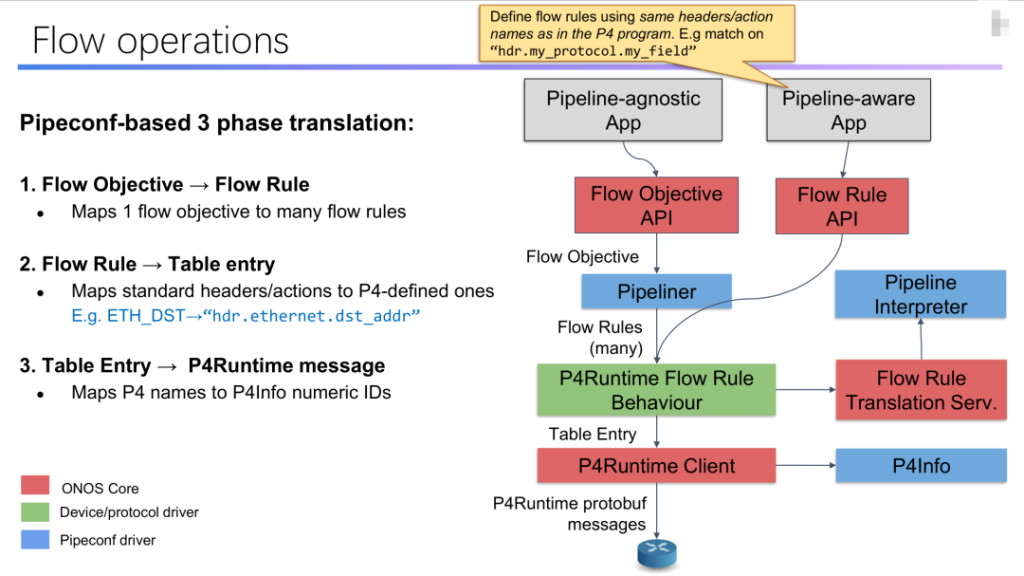 图3 FlowRule Translation
图3 FlowRule Translation