
揭秘超以太网联盟(UEC)1.0 规范最新进展(2024Q4)
近期,由博通、思科、Arista、微软、Meta等国际顶级半导体、设备和云厂商牵头成立的超以太网联盟(UEC)在OCP Global Summit上对外公布其最新进展——UEC规范1.0的预览版本。让我们一睹为快吧!

UEC 旨在提出一种“升级版”的以太网通信协议栈用以应对AI智算、HPC等领域对RDMA网络的性能挑战——当前大规模计算节点互联场景下主要有InfiniBand和基于以太网协议的RoCE两大技术路线。有关IB和RoCE协议栈的详尽对比可参阅:
相比较为封闭的IB架构,以太网在互操作性和带宽成本上的优势已在市场层面得到了广泛认可,尤其是大规模的AI算力中心场景。当前全球TOP500的超级计算机中RoCE和IB的占比相当,以端口带宽总量计算,IB占比为39.2%,RoCE已达48.5%。
尽管IB和RoCE在高性能传输的拥塞控制、QoS皆有应对设计,但也暴露出一些缺陷。例如乱序需要重传、不够完美的负载分担、Go-back-N问题,DCQCN 部署调优复杂等等。
面向GPU Scale-out网络的UEC 1.0 规范从软件API、运输层到链路层以及网络安全和拥塞控制皆有涉及,较传统RDMA网络有了大量改进,我们将挑出重点介绍。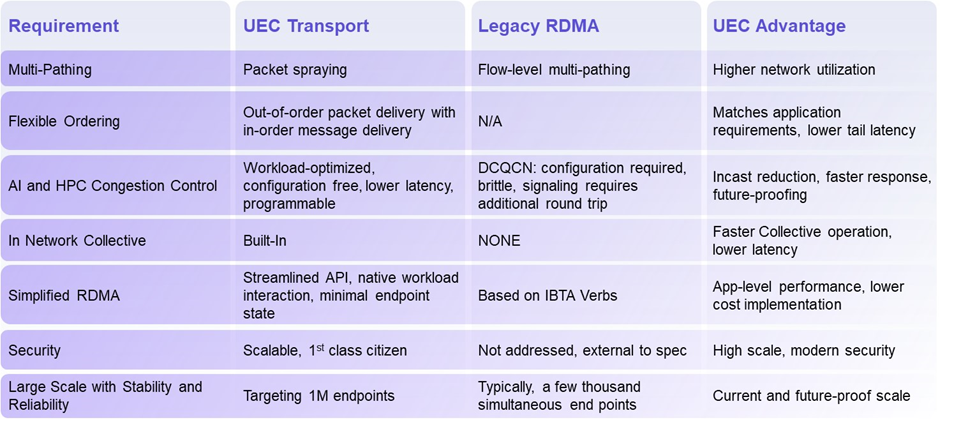
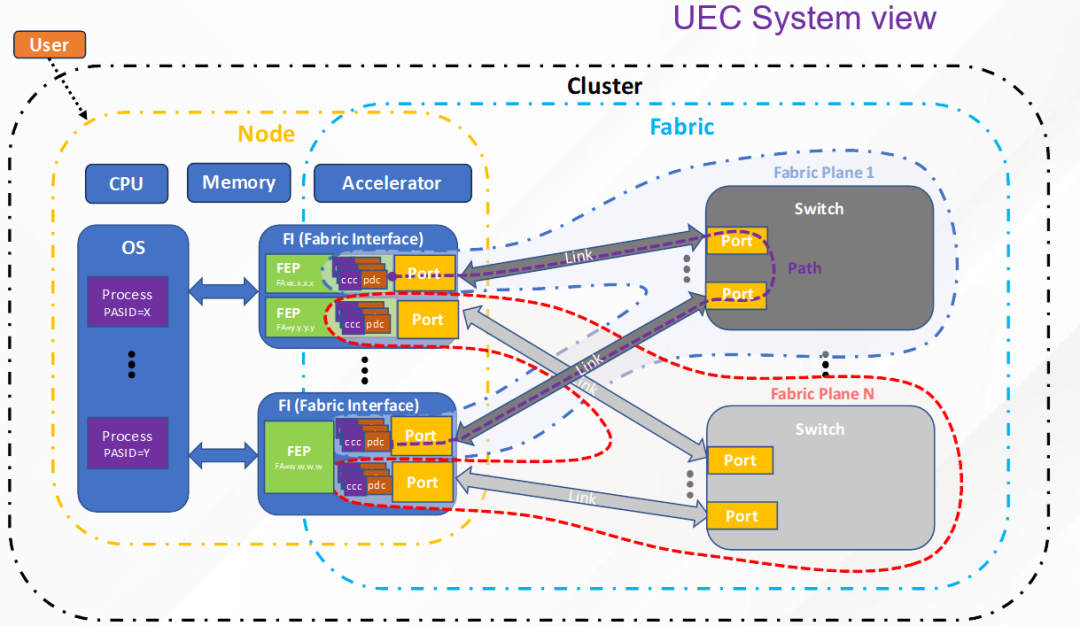
什么是超级以太网系统
一个超级以太网系统的组成如下。一个集群(Cluster)由节点(Node)和网络(Fabric)组成,节点通过网卡(Fabric Interface)连接到网卡,一个网卡中可以有多个逻辑的网络端点(Fabric End Point,FEP)。网络由若干平面(Plane)组成,每个平面是多个FEP的集合,通常通过交换机互联。
超以太网协议栈概览
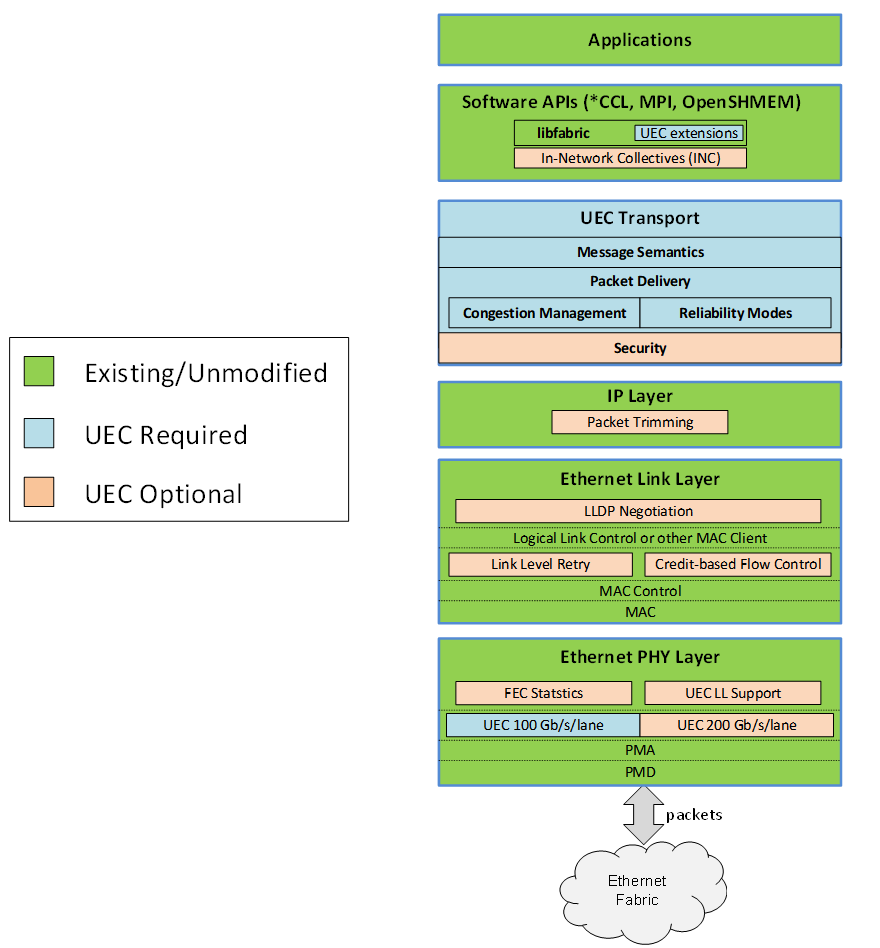
▣ 物理层与传统以太网完全兼容,可选支持FEC(前向纠错)统计功能
▣ 链路层可选支持链路层重传(LLR),并支持包头压缩,为此扩展了LLDP的协商能力
▣ 网络层依然是IP协议,没有变化
▣ 传输层是全新的,作为UEC协议栈的核心数据包传输子层(Packet Delivery)和消息语义子层(Message Semantics)。包传输子层实现新一代拥塞控制、灵活的包顺序等功能,消息语义子层支持xCCL和MPI等消息。可选支持安全传输。另外,在网集合通信(In Network Collective,INC)也在这一层实现
▣ 软件API层。提供UEC扩展的Libfabrics 2.0
物理层
UEC 1.0规范下的物理层与传统以太网(符合IEEE802.3标准)完全兼容,支持每通道100Gbps和200Gbps速率,在此基础上实现800Gbps和更高的端口速率。
另外可选支持物理层性能指标统计功能(PHY metrics)。这些指标基于 FEC 码字进行计算,不受流量模式和链路利用率的影响。估计算法基于FEC错误计数器的数据,从而得出不可纠正错误率(UCR )和数据包错误平均间隔(MTBPE)。这些指标衡量了物理层的传输性能和可靠性,用于上层的遥测和拥塞控制等。为了支持新的 UEC 链路层功能,UEC规范中也对协调子层(RS)进行了相应的修改。
链路层
UEC链路层最大的变化是引入了LLR(Link Level Retry)协议。它可以让以太网不依赖PFC,实现无损传输。
LLR 机制是基于帧的。每个帧都分配了一个序列号,接收端成功接收这一帧后,检查帧的序列号是否符合预期,如果正确,发送确认消息(ACK),如果发现帧乱序或者丢失,则发送否定确认消息 (NACK)。发送端具有超时机制,用于保证在 NACK 丢失时重传。
传输层:UET,新一代协议栈的核心
前文提过,传统的RDMA网络传输层(包括IB和RoCE)在多路径传输、负载分担、拥塞控制以及参数调优等方面存在着不足之处。随着AI/HPC集群规模增长,网络的确定性和可预测性越来越困难,需要全新的方法来解决。
选择性重传(Selective Retransmit)
乱序交付(Out-of-Order Delivery)
UET不仅支持有序传输,也支持无序传输。这是因为现代网络中通常有多路径存在,同一个流的数据包经过不同路径传输,就可能造成乱序。如果还要求严格的顺序传输,就无法利用多路径来实现负载分担。此外,选择性重传也需要无序传输的支持。为了实现无序传输,需要接收方有更大的数据包缓冲区,从而将乱序的数据包组成一个完整的RDMA消息。
包喷洒(Packet Spraying)
包喷洒是一种基于包的多路径传输。由于传统传输协议不支持无序传输,同一个数据流必须按照同一个路径传输,否则就会造成乱序,引发重传。而在AI/HPC应用中,存在大量的“大象流”,它们数据量大、持续时间长,如果能使用多路径传输一个流,将显著提高整个网络的利用率。
由于支持了RUD,UET就可以将同一个流的不同包分散到多个路径上同时传输,实现包喷洒功能。这让交换机可以充分发挥ECMP甚至WCMP(Weighted Cost Multi- Pathing)路由能力,将去往同一目的地的数据包通过多条路径发送,大幅度提高网络利用率。
拥塞控制(Congestion Control)
UET 拥塞控制包含以下重要特性,由端侧硬件和交换机配合完成,有效减小了尾部延迟。
▣ Incast管理。它用于解决集合通信(Collective)中下行链路上的扇入问题。AI和HPC应用经常采用集合通信在多个节点之间同步信息,当多个发送者同时向一个接收者发送流量,就会产生Incast拥塞。
▣ 速率调整加速。现有的拥塞控制算法,在发生网络拥塞后调整速率的过程较长,而 UET 可以快速上升到线速。方法是测量端到端延迟来调节发送速率,以及根据接收方的能力通知发送方调整速率。
▣ 基于遥测。源自网络的拥塞信息可以通告拥塞的位置和原因,缩短拥塞信令路径并向终端节点提供更多信息,从而实现响应速度更快的拥塞控制。
▣ 基于包喷洒的自适应路由。当拥塞发生时,通过包喷洒技术将流量重新路由到其它路径上,绕过拥塞点。
端到端的安全
在网计算(In Network Collectives)
在网计算最早应用在HPC集群,业界主要有两个思路,一是基于网卡的,二是基于交换机。
UEC V1.0 的目标是后者,即将集合操作卸载到各级交换机上完成,避免过多的收发次数,降低节点交互频率和处理时延开销,减少约一半数据传输量,从而加速All-Reduce操作。
在部署实现上,目前AI智算领域唯一大规模商用的案例仅有英伟达的SHARP(在ASIC层面实现的硬件加速),以太网设备厂家仍处在探索阶段,例如将算力内置于交换机或外接,甚至P4可编程都是可能的思路方向。
软件层:Extended Libfabrics 2.0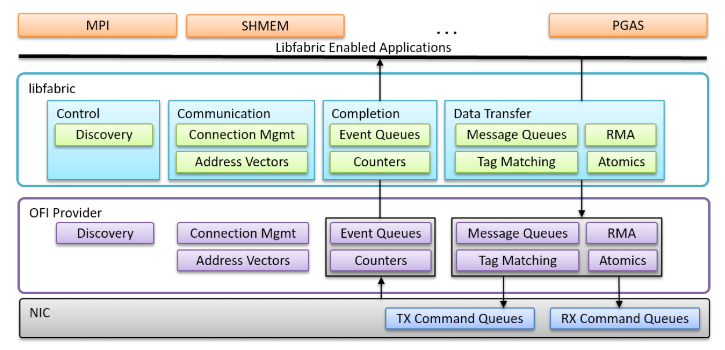
UEC在规范中定义了支持超级以太网交换机的架构,可以看到大体是继承了SONiC的架构。这部分的主要关注在于控制平面上支持INC和SDN控制器;数据平面升级了SAI(Switch Abstraction Interface)API调用硬件提供的INC等能力。
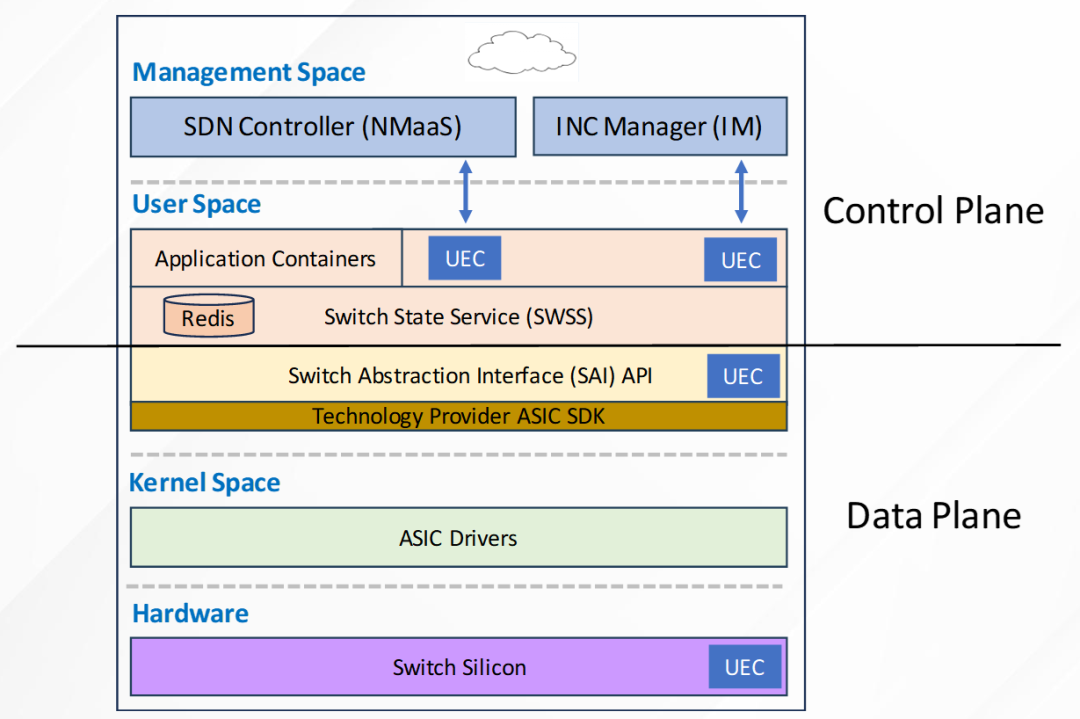
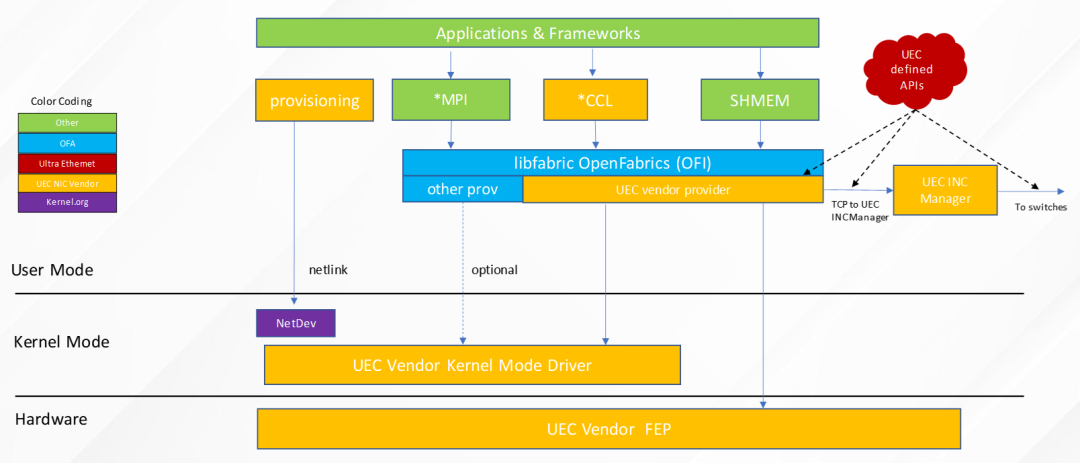
UEC同样定义了网络端点(Fabric End Point)的软硬件架构。在硬件层,网卡升级支持UEC功能。在操作系统内核态,实现网卡驱动。在用户态,基于libfabric扩展实现INC管理等功能,支持上层的xCCL/MPI/SHMEM等应用。
星融元RoCE交换机与UEC


