对于追求开放和标准的技术栈,或是已建设有业务管理平台的用户,现阶段我们如何在开源、开放生态下实现RDMA网络监控?
关键监控指标有哪些?
RoCE(RDMA over Converged Ethernet)是一种在智算/超算场景广泛应用的高性能网络传输技术。RoCE 通过用以太网和IP头部替代IB报文的链路层和网络层,使得以太网也能承载RDMA流量。
为实现高性能的端到端通信,RoCE网络必须做到低时延和零丢包。RoCE交换机本身的硬实力虽是基础,但运维侧的强化也必不可少——除了监控常规的设备健康和流量性能,也要格外关注链路状态和拥塞控制信息,评估流量优先级设置的合理性,不断调优。
一套具有生产力的监控方案,需要将以上相关网络状态信息科学、合理地组织起来,转换为可读性更强的数据形式,并尽可能实时呈现网络动态以便快速排障。
RoCE网络的监控指标通常有以下几类:
- 流量性能:吞吐量、时延、抖动、丢包率…
- 拥塞控制:PFC(Priority Flow Control)暂停帧、ECN(Explicit Congestion Notification)标记状态和对应配置生效状态…
- 设备健康状态:交换机端口负载、网卡/光模块状态、队列buffer…
- 网络拓扑:链路流量分布、设备间连接状态…
RoCE网络监控实现步骤
本文将主要围绕星融元目前已推出的 EasyRoCE Toolkit(高效运维部分)梳理开放生态下的RoCE网络监控实现步骤,分为以下章节:
- 数据采集和存储
- 可视化监控平台配置
- 高精度监控
- 实用运维信息整合
- 告警通知
- 场景优化和升级方向
EasyRoCE Toolkit 是星融元依托开源、开放的网络架构与技术,为AI 智算、超算等场景的RoCE网络提供的一系列实用特性和小工。https://asterfusion.com/easyroce/
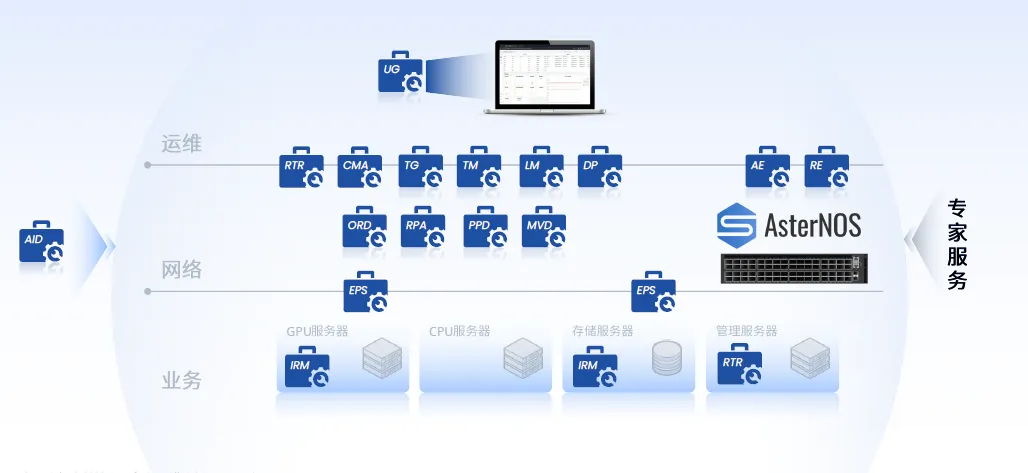
从前期规划实施到日常运维监控, EasyRoCE Toolkit 简化了各环节的复杂度并改善了操作体验,且具备二次开发和集成空间。该工具集对星融元签约用户完全开放,并常态化更新,无额外收费。
1. 数据采集与存储
数据来源是首要问题。传统以太网的监控手段对RDMA网络支持不佳(难以获取PFC、ECN的配置和监控信息,且精度不佳),可用方案往往也是基于各厂商的“SDN控制器”实现,监控逻辑高度固化。
开放网络生态下的RDMA网络监控提供的是支持自定义监控策略的高精度数据源。
开放交换机的操作系统(AsterNOS)从可编程ASIC的计数器取得各类统计信息,并存储在内存里,上层的数据采集器(Exporter)通过Redis数据库的订阅-发布通信机制快速取得所需数据。
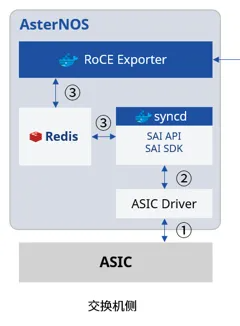
星融元 EasyRoCE Toolkit 包含了两个数据采集器工具,它们支持以容器形式部署在交换机上,分别负责从系统里提取通用网络信息和RoCE网络关键指标,将其转化为后端监控系统所需的标准格式,暴露到自定义HTTP端口供调用。注:最新版本的AsterNOS已内置以上采集器。
- 通用网络监控:AsterNOS Exporter(AE)可获取常规的设备硬件指标(CPU/内存等)、接口状态,队列级的收发包/丢包统计;根据实际运营需求,AE也支持采集BGP状态、EVPN等网络协议状态信息,方便了解Overlay和Underlay网络运行状态。
- RoCE指标监控:RoCE Exporter (RE)是 AsterNOS Exporter 的子组件,负责从运行AsterNOS的交换机设备上导出RoCE网络相关监控指指标(例如:接口收发带宽和速率,RoCE、PFC、ECN、DSCP配置状态信息,ECN标记包,PFC帧数等,队列Buffer信息……详细指标请与我们联系获取)
2.可视化监控平台配置
Prometheus 是目前开源、开放网络领域最主流的系统监控和报警系统,它以其强大的数据收集、存储和查询能力而闻名,支持多种Exporter采集数据,性能足够支撑上万台规模的集群。
星融元在EasyRoCE Toolkit 中提供的统一监控面板(Unified Glancer, UG)基于Prometheus系统搭建,支持一键对接 AsterNOS Exporter 和 RoCE Exporter 导入标准格式的监控数据,也可导入其他兼容的数据格式,并将所有相关信息图形化地集中呈现在一套数据面板之中。有开发能力的用户完全可在UG平台基础上二次开发定制。
UG平台运行在物理服务器上,我们推荐8核心CPU和至少16GB内存以确保流畅运行,UG平台的关键组件有:
- Pushgateway:用于解决Prometheus无法直接获取监控指标的场景,允许任何客户端向其推送符合规范的自定义监控指标,然后Prometheus统一收集监控。
- Grafana:监控数据分析和可视化套件,最常用于对基础设施和应用数据分析的时间序列数据进行可视化分析。
以上组件皆已完成离线化封装设计,对于 CentOS 及 Ubuntu 等主流操作系统环境,用户可使用UG平台配套的自动化部署工具完成配置,预计1分钟左右可完成平台搭建、设备监控和各组件之间的对接。
对于部分非标准操作系统环境或特殊架构,用户也可自行下载预封装的软件镜像,对照着指导手册完成部署。
3. 高精度监控
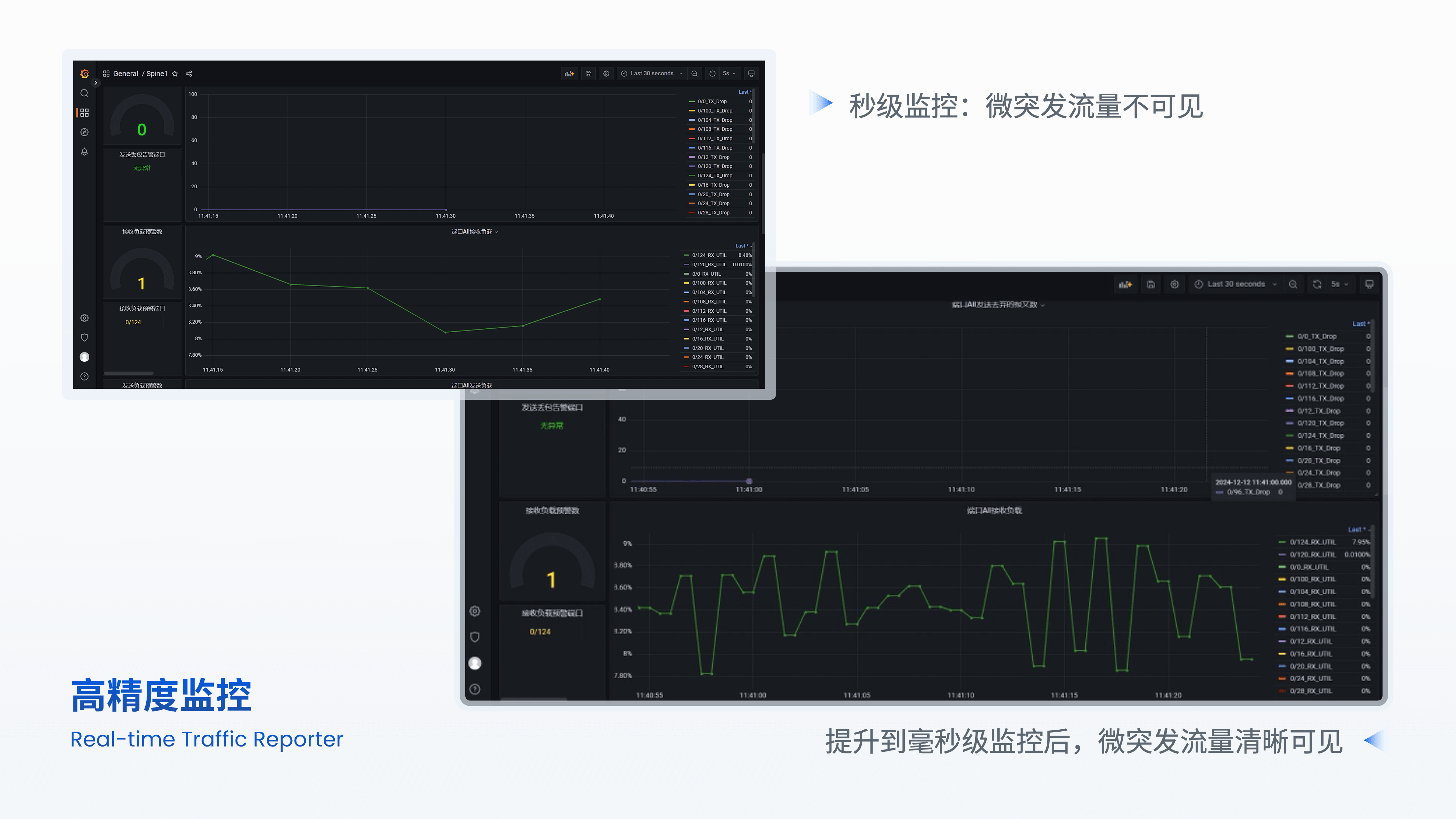
RDMA场景网络监控要求较传统数据中心更高,秒级精度的传统监控有时会不够用。以智算中心为例,其内部突发流量往往发生在毫秒级或更短的时间内,此时秒级指标失真,因微突发流量导致的网络时延上升和丢包很难定位。
有赖于操作系统的快速通信机制,通过提高CPU占用我们可以提升数据源的采样精度,像前文提及的AE和RE已可采集到亚秒级的监控数据。但数据源只是第一步,如何完成更高精度的数据整理并呈现到监控平台,通常又涉及到复杂的配置。
EasyRoCE Toolkit下的高精度监控工具(Real-time Traffic Reporter, RTR)解决的便是高精度数据源的呈现问题。该工具将监控面板的设计、采集器的对接等配置工作打包到一个json文件里,用户将其导入UG平台后即可生成详尽的毫秒级监控数据图表,并且支持选择不同精度档位,辅助运维优化决策。
4.实用运维信息整合
除了必备的关键流量和配置状态呈现,现有EasyRoCE工具包里还添加了其他实用组件,可按需快速集成到UG平台。用户也可以自行按需开发、补充进UG平台。
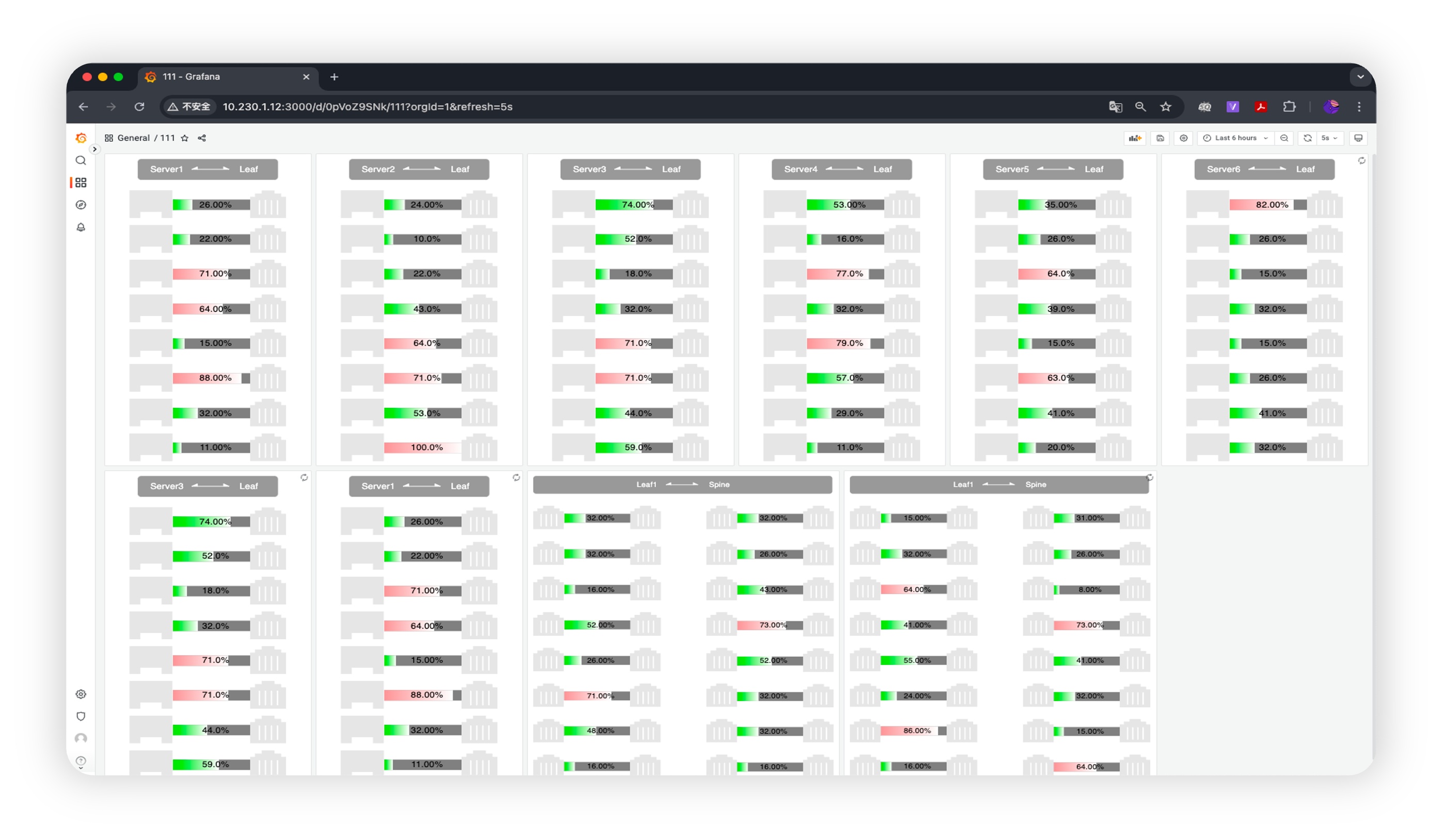
链路地图(Link Map, LM)
实时呈现所有链路的负载情况, 动态监控整网运行状态
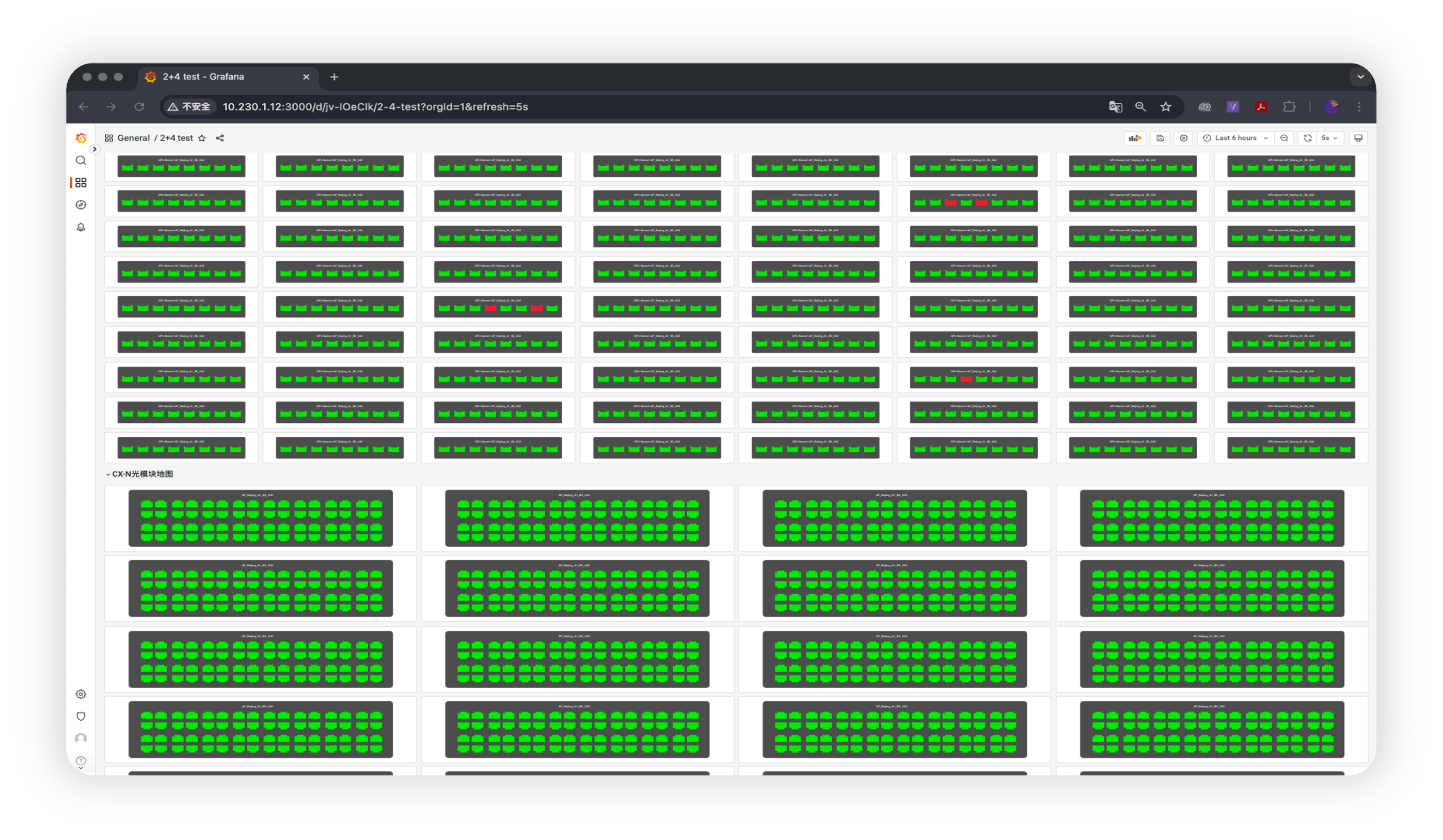
光模块地图(Transceiver Map, TM)
动态监控所有光模块的运行状态(up/down),快速定位故障点
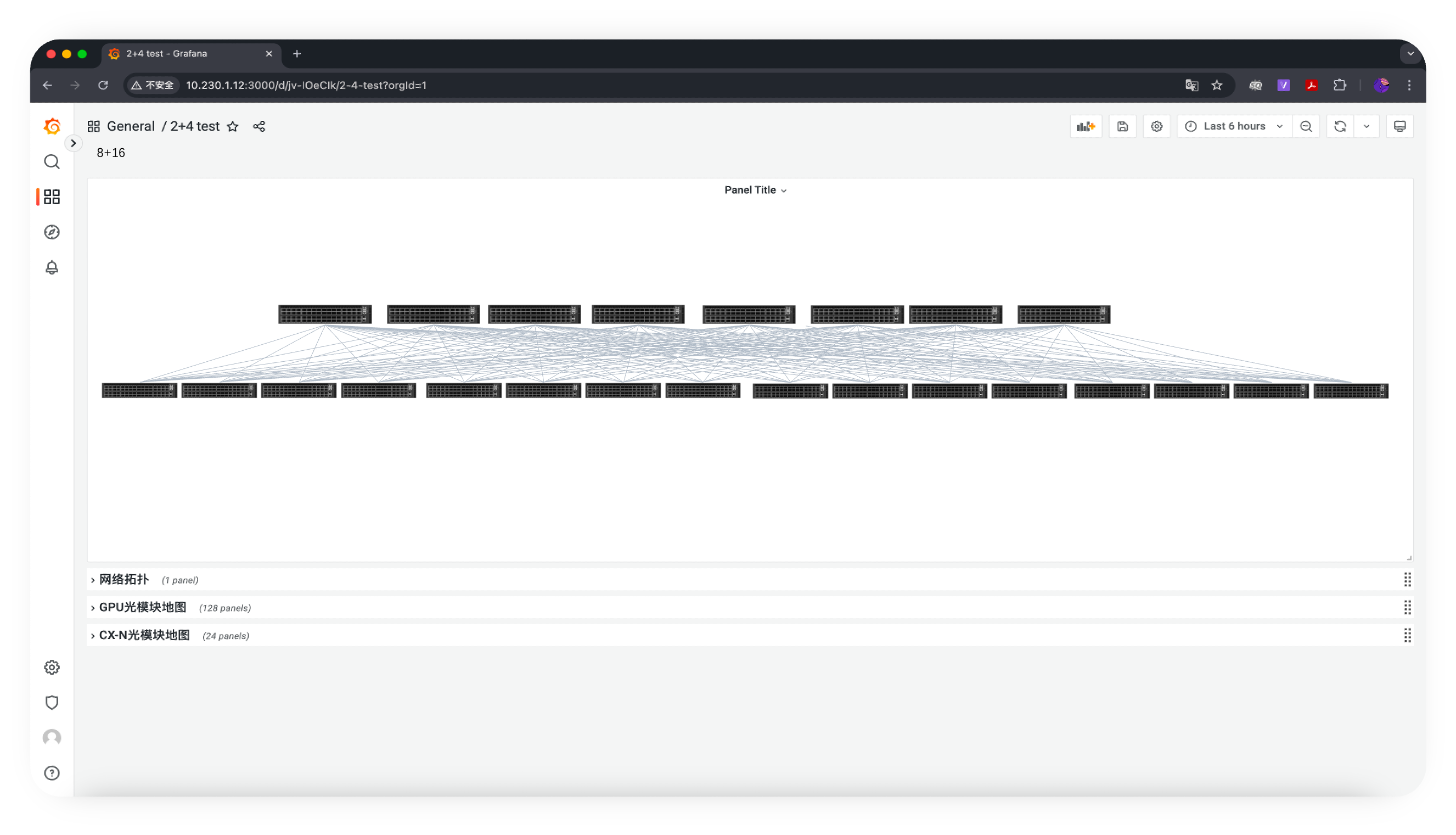
拓扑呈现(Topology Generator, TG)
从逻辑到物理映射,自动呈现拓扑,帮助运维人员快速、精准定位异常
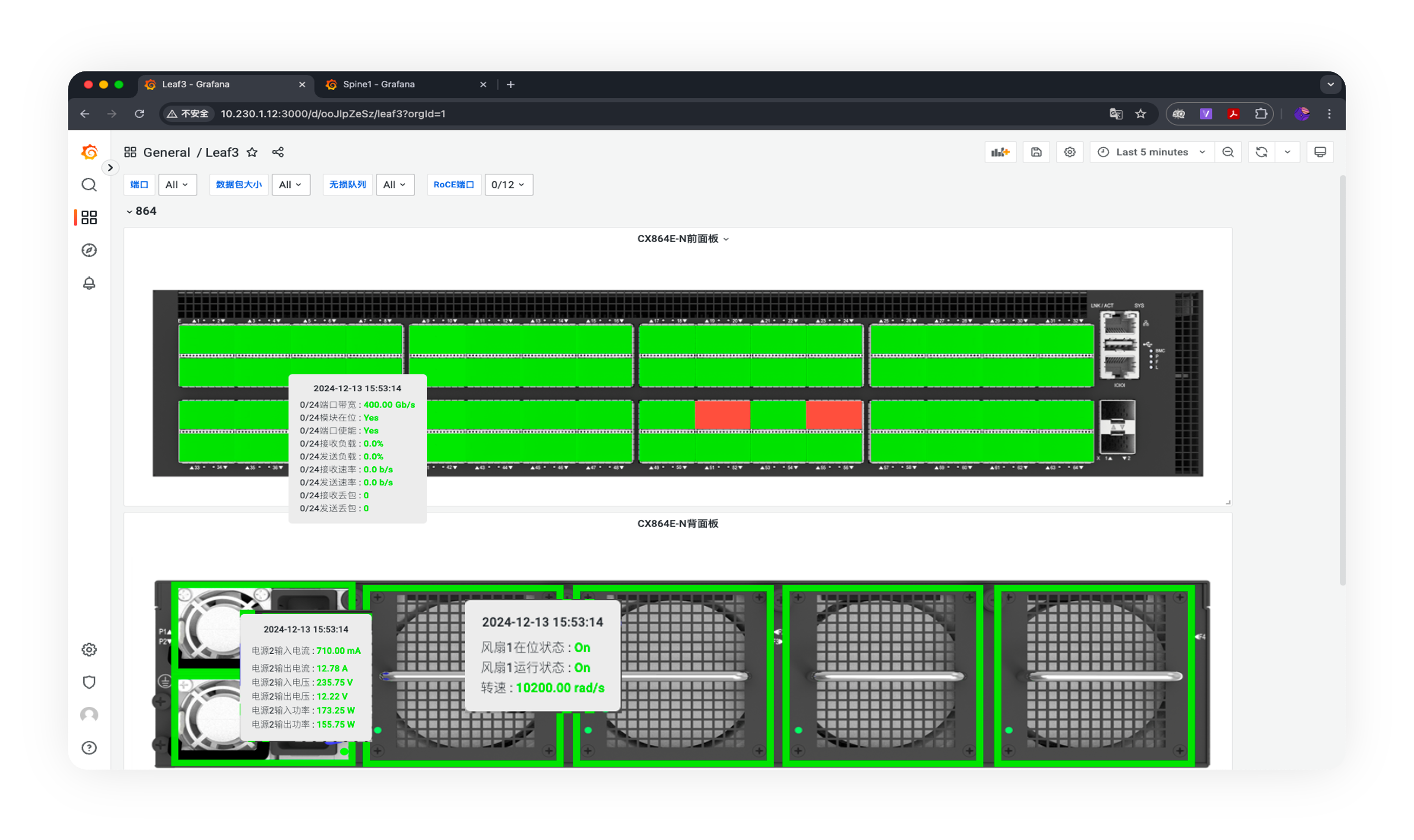
图形化面板(Device Panel, DP)
以交换机的实际面板布局为基础,图形化展示设备的运行状态,通过颜色变化(橙色或红色)显著标记设备异常点
5. 告警与自动化通知
基于现有系统可以较为简便地实现告警通知,基本步骤是先设置好阈值触发条件(例如连续丢包率超过0.1%或时延超过1ms),再通过Webhook接口连接到第三方IM应用,办公应用、邮件系统等等。
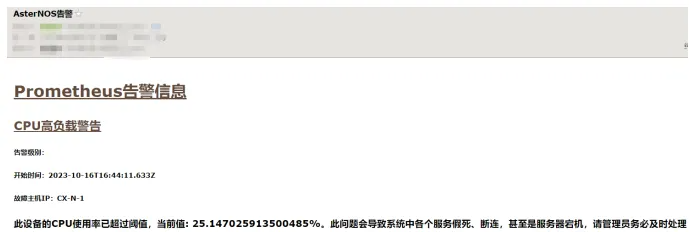

上述监控方案系统里涉及到的组件有:
- Alertmanager: 用于接收 Prometheus发送的告警信息,并及时地将告警信息发送到 Prometheus Alert
- Prometheus Alert: 运营告警中心消息转发系统,支持Prometheus 以及所有支持Webhook接口的系统发出的预警信息,将收到的信息通过微信、邮箱、飞书、短信、Slack等渠道推送。
Webhook具体对接方式请参考各平台发布的官方指南。
6. 场景优化和升级方向
分布式追踪:在Kubernetes集群中,监控Pod间RoCE通信性能
拥塞预警通知:应用 In-Band Network Telemetry(INT)技术,基于事件提供更加精准、实时的RDMA网络数据信息
如您有其他RDMA网络监控需求和优化建议,欢迎留言或拨打咨询热线与我们交流。后台发送“EasyRoCE”可获取相关彩页。
相关文献
[1] https://prometheus.io/
[2] https://grafana.com/




