
一文揭秘AI智算中心网络流量 – 大模型训练篇
前言:自2017年起,AI模型的规模每半年翻一番,从初代Transformer的6500万增长到GPT-4的1.76万亿,预计下一代大语言模型将达到10万亿规模。另一方面,用于模型训练的数据量持续增长,如C4数据集,原始数据量累计超过9.5PB,每月新增200-300TB,目前经过清洗加工后的数据集大小约38.5 TB,训练样本数364.6M。进一步,随着多模态大模型的兴起,训练数据从单一的文本过渡到图像和视频乃至3D点云,数据规模将是文本数据的1万倍以上。
AI模型的规模巨大并持续快速增长,不仅将带来数据中心流量的指数型增长,独特的流量特征也将为数据中心网络带来崭新的需求。
深入分析AI大模型在训练、推理和数据存储流量将帮助数据中心建设者有的放矢,用更低的成本,更快的速度、更健壮的网络为用户提供更好的服务。
本篇我们将聚焦于介绍AI大模型训练场景下的网络流量,AI推理和数据存储场景会在接下来的文章中呈现,敬请关注。
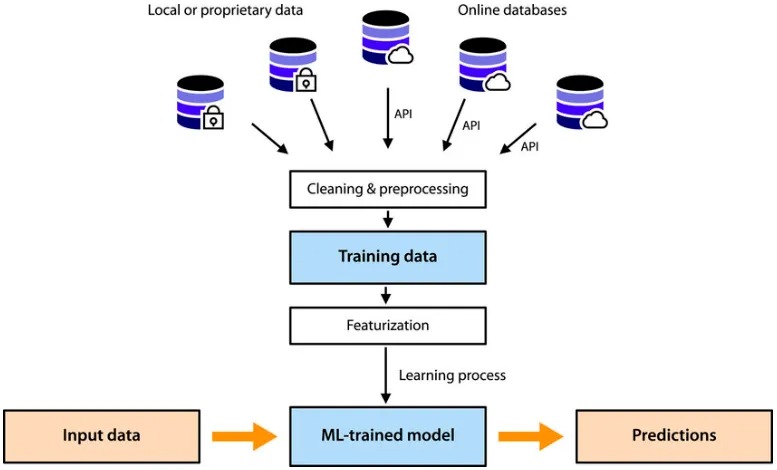
AI训练程序首先将模型参数加载到GPU内存中,之后将经历多个epoch(即使用所有训练集对模型进行一次完整训练),每个epoch的处理过程可以简单描述为4步:
- 加载训练数据,在每个epoch中,根据batch size将整个数据集分为若干个mini-batch,分批次加载训练数据,直到遍历整个训练数据集。
- 训练,包括前向传播、计算损失、反向传播和参数/梯度更新,每个mini-batch都进行上述步骤。
- 评估,使用评估数据集对模型的指标进行评估。这一步是可选的,可以在整个训练完成后单独进行,也可以间隔若干个epoch进行一次。
- 保存checkpoint,包括模型状态、优化器状态和训练指标等。为了减少存储需求,通常经过多个epoch后保存一次。
在大模型出现之前,整个过程在可在一台AI服务器内部完成,训练程序从服务器本地磁盘读取AI模型和训练集,加载到内存中,完成训练、评估,然后将结果存储回本地磁盘。虽然为了加速训练,也会采用多块GPU同时训练,但所有的I/O均发生在一台AI服务器内部,并不需要网络I/O。
AI大模型训练的网络流量有哪些?
进入大模型时代,AI训练的流量路径和其网络需求发生了巨大变革。
首先是模型的参数规模超出了单个GPU的内存,采用GPU集群协同计算,则需要相互之间通信以交换信息,这类信息包括参数/梯度、中间激活值等。
庞大的数据集被所有GPU共享,需要集中存放到远端的存储服务器中通过网络调用,分批加载到GPU服务器上。此外,定期保存的参数和优化器状态也需要通过存储服务器共享,在每个训练epoch中,都要通过网络读写数据。
由此,AI大模型训练的网络流量可分为以下两类:
- 第一类是GPU之间同步梯度和中间激活的网络流量,它发生在所有GPU之间,是一种广播式流量,逻辑上需要所有GPU全连接。
- 第二类是GPU和存储服务器之间的流量,它仅仅发生在GPU和存储服务器之间,是一种单播流量,逻辑上仅需要以存储服务器为中心的星型连接。
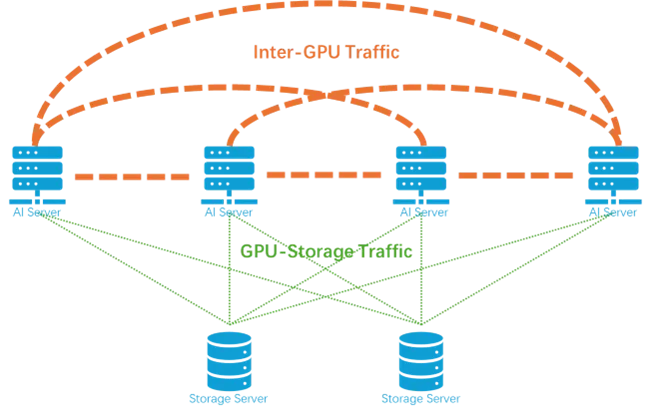
其中,GPU之间的网络流量与传统数据中心内部流量迥然不同,这与AI大模型的训练方法息息相关——并行训练技术。
并行训练:AI智算中心的主要流量来源
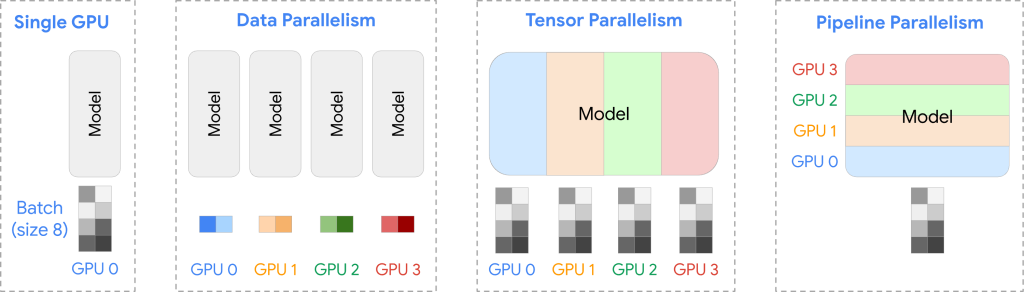
当前广泛应用于AI训练并行计算模式主要有以下三类:
| 数据并行 | 将不同的样本数据分配给不同的GPU,以加快训练速度;用在主机之间 |
| 张量并行 | 将模型的参数矩阵划分为子矩阵,并分配到不同的GPU上,以解决内存限制并加速计算。一般用在主机内部。 |
| 流水线并行 | 将模型分为多个阶段,每个阶段分配给不同的GPU,以改善内存利用率和资源效率。一般用在主机之间 |
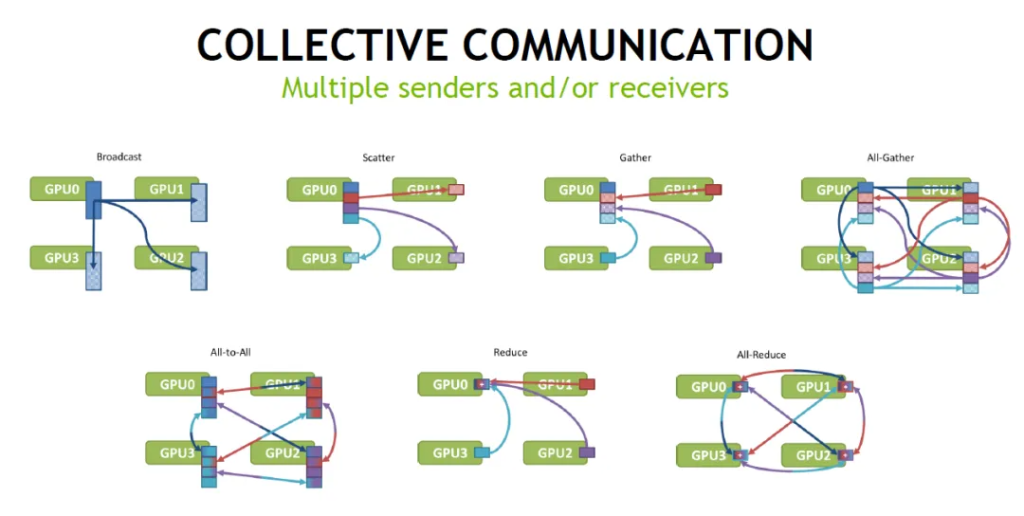
常见的集合通信流量模式(如下图)
1.数据并行(Data Parallelism)
在数据并行时,主要的网络流量来源于梯度同步,它发生在每次mini-batch处理之后,由一个all-reduce操作计算平均值。理想情况下,所有GPU全连接,每个GPU给其它G-1个GPU单独发送数据,共需发送G x(G-1)份数据。
FSDP(完全分片数据并行)是一种改进的数据并行技术,旨在优化内存使用和通信效率。它通过将模型参数和梯度在多个GPU之间分片(shard)存储,实现更高效的内存利用和通信。
在FSDP时,网络流量来自前向传播的参数收集以及反向传播中的梯度同步。
前向传播的参数收集由all-gather操作完成,all-gather的通信复杂度与all-reduce相同。
后向传播的梯度同步由all-reduce操作完成,由于每个GPU的参数只有原来的1/G,一个epoch中总的网络流量只有普通数据并行的1/G。
2.张量并行(Tensor Parallelism)
在张量并行时,模型参数分布到G个GPU上,每个GPU只存储1/G参数。网络流量主要来自前向传播过程的中间激活值的传递以及反向传播过程中的梯度同步。
前向传播中,各个GPU计算出的中间激活值需要合并,由一次all-reduce操作进行求和。对于每个Token,在模型的每个layer的中均进行2次合并,共2xTxL次通信。
反向传播中,梯度需要在GPU之间同步,这种在每一层的处理中发生2次,由all-reduce操作将各个GPU上梯度求和。这种同步发生在每个mini-batch的每个layer的处理过程中。共2×N×L次通信。
3.流水线并行(Pipeline Parallelism)
在流水线并行时,网络流量主要来自前向和反向传播过程的中间激活值的传递。与张量并行不同,这些流量的传递发生在模型的前后两个阶段之间,使用Point-to-point通信而非all-reduce操作,并且频率也大大减小了。
综上,在三种并行方式中,张量并行的网络流量最大、频率最高,流水线并行的流量最低,数据并行的通信频率最低。如下表所示,P为模型参数,T为token数,L为模型层数,H为隐藏状态大小,G为GPU数量,N为mini-batch的数量,采用BFLOAT16数据格式,每个参数占2个字节。在每个epoch过程中:
| 流量模式 | 后向传播总网络流量 | 反向传播同步次数 | 前向过程总网络流量 | 前向过程传递次数 | |
|---|---|---|---|---|---|
| 数据并行 | all-reduce | 2 × N × P × G × (G-1) | 1 | 0 | 0 |
| FSDP | all-gather + all-reduce | 2 × N × P × (G-1) | L | 2 × N × P × (G-1) | L |
| 张量并行 | all-reduce | 4 × N × P × L × (G-1) | 2 × L | 4 × L × T × H × (G-1) × G | 2 × L × T |
| 流水线并行 | Point-to-point | 2 × T × H × (G-1) | G-1 | 2 × T × H × (G-1) | G-1 |
以具有80层(L)的Llama3 70B(P)模型和C4数据集为示例计算:采用BFLOAT16数据格式,每个参数占2个字节,隐藏层维度设为8192(H),使用8个GPU(G)进行数据并行。C4数据集token(T)总数约156B,样本数364.6 millions;batch size为2048,则每个epoch包含约178,000个mini-batch(N)。
计算可得每个epoch过程中:
| 反向传播总网络流量(PB) | 反向传播同步次数 | 前向过程总网络流量(PB) | 前向过程总网络流量 | |
|---|---|---|---|---|
| 数据并行 | 1396 PB | 1 | 0 | 0 |
| FSDP | 175 | 80 | 175 | 80 |
| 张量并行 | 26622 | 160 | 21840 | 160*156*10^9 |
| 流水线并行 | 17.9 | 7 | 17.9 | 7 |
3D并行技术下的网络流量
数据并行、张量并行和流水线并行三个技术通常会组合起来使用,可进一步提高训练大模型时的效率和可扩展性。这时候,GPU也就按照这三个维度组成了GPU集群。
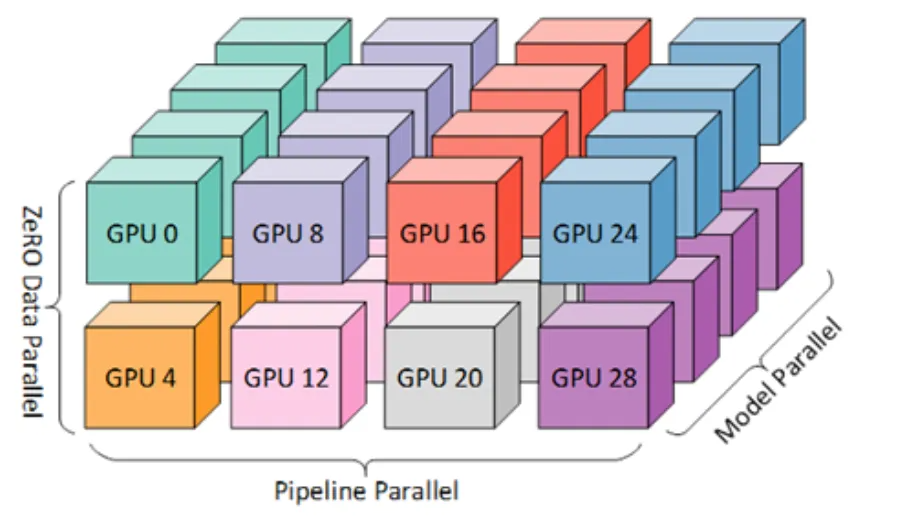
假设共有G(tp)×G(pp)×G(dp) 个GPU组成的3D并行阵列,全部P个参数将分割为G(tp)×G(pp)份,每一份大小为P/G(tp)/G(pp)。在模型并行、流水线并行和数据并行三个维度上都存在网络流量。接下来我们将深入到每个epoch的训练过程,分别计算不同阶段的网络流量组成和规模。
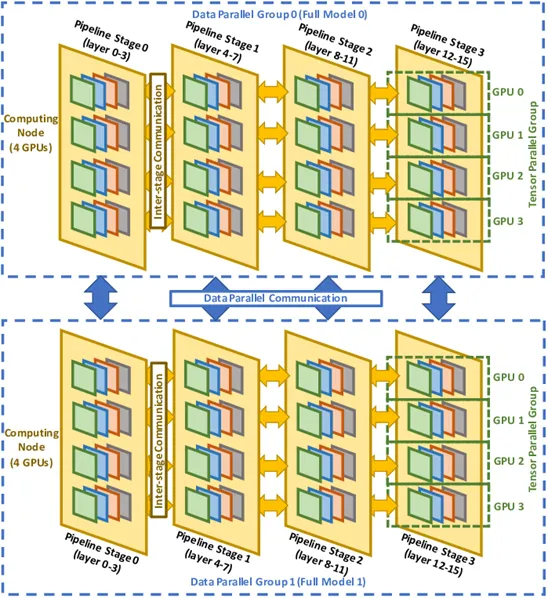
1.反向传播中的网络流量
在每个mini-batch中,反向传播时的梯度同步分为:
- 张量维度上的梯度同步,在模型的每一层和数据维度的每一组中进行,总共 LxG(dp) 次,每次包含2个all-reduce操作。
- 数据维度上的梯度同步,在流水线维度的每个阶段和张量维度的每一组中进行,总共 G(tp)xG(pp) 次,每次包含1个all-reduce操作。
如下图所示:
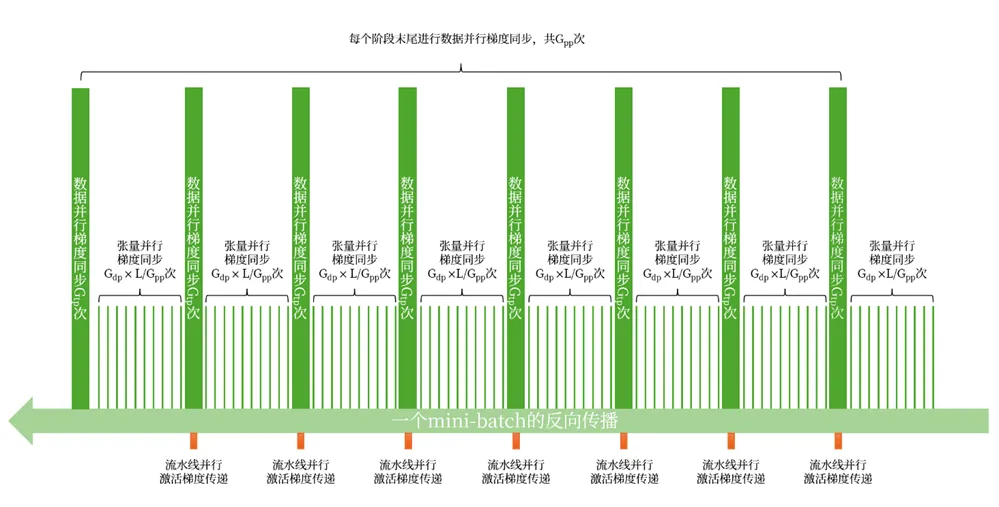
这样,在一个epoch中,梯度同步的总网络流量为:
4xNxP/Gtp/GppxGtpx(Gtp-1)xLxGdp+2xNxP/Gtp/GppxGdpx(Gdp-1)xGtpxGpp=2xNxPxGdpx[2xLx(Gtp-1)/Gpp+(Gdp-1)]
3.流水线并行维度的中间激活梯度传播,流量为:
2xTxHx(Gpp-1)
因此,在一个epoch中,整个反向传播的总流量为:
2xNxPxGdpx[2xLx(Gtp-1)/Gpp+(Gdp-1)]+2xTxHx(Gpp-1)
2.前向传播中的网络流量
前向传播时,中间激活的传递依次在张量并行、流水线并行维度上交替进行,其中张量并行的激活传递每次包含2个all-reduce操作。
如下图,以一个Token的前向传播所示:
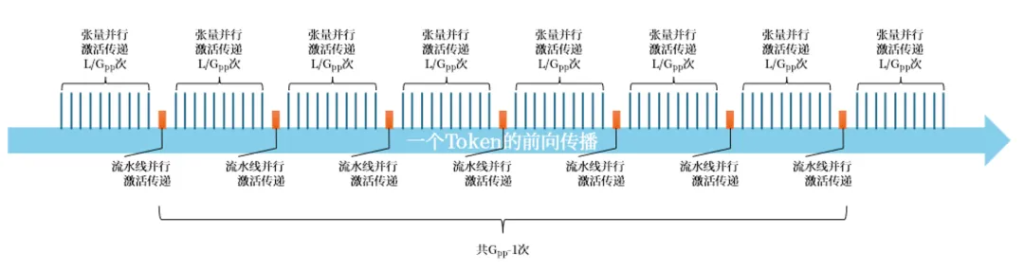
因此,在一个epoch中,前向传播总网络流量为:
4xTxHxLxPxGtpx(Gtp-1)+2xTxHx(Gpp-1)
即:
2xTxHx(2xLxGtpx(Gtp-1)+(Gpp-1)
由此,我们以Llama3-70B模型为例,采用8路张量并行 x 8路流水线并行 x 16路数据并行的模式,在共1024个GPU上进行训练,一个epoch产生的总流量约为85EB。如此庞大的流量规模,如果用1个交换容量为51.2T的交换机,24小时满负荷运行,需要约20天才能传输完毕。
考虑到一次预训练通常包含100个左右epoch,如果需要在100天完成训练,至少需要20台51.2T交换机来传输训练过程产生的数据。
AI训练对智算中心网络的要求
通过以上分析和计算,我们可以得出一个典型的AI智算中心对计算网的核心需求。
- 超高带宽:一个epoch就会产生85EB的数据量,相当于整个互联网2.5天的流量。
- 超低时延:一个训练样本的处理,就会产生100GB以上的数据,并需要在小于1毫秒的时间传输完毕。相当于1000个800G接口的传输速度。
- 集合通信:GPU服务器之间的All-reduce, All-gather操作带来广播式流量,在上万个GPU之间,也就是上亿个GPU-GPU对之间同步。
- 零容忍丢包:基于木桶原理,在集体通信过程中,仅仅是一对GPU之间流量的丢包和重传,也会造成整个集体通信的延迟,进而造成大量GPU进入空闲等待时间。
- 严格时间同步:同样基于木桶原理,如果GPU的时钟不同步,将造成同样的计算量花费不同的时间,计算快的GPU不得不等待计算慢的GPU。
星融元CX-N系列交换机正是为智算中心AI训练场景而生的超低时延以太网交换机——在保持极致性能的同时,实现可编程、可升级的能力,与计算设备形成协同,共同打造10万级别的计算节点互联,将数据中心重构为可与超级计算机媲美的AI超级工厂。
- 最大支持64个800G以太网接口,共51.2T交换容量。
超低时延,在800G端口上实现业界最强的560ns cut-through时延。 - 全端口标配支持RoCEv2,支持Rail-only,全连接Clos以及200G/400G混合组网,灵活适应不同的算力中心建设方案
- 200+ MB大容量高速片上包缓存,显著减小集体通信时RoCE流量的存储转发时延。
- Intel至强CPU + 大容量可扩展内存,运行持续进化的企业级SONiC——AsterNOS网络操作系统,并通过DMA直接访问包缓存,对网络流量进行实时加工。
- INNOFLEX可编程转发引擎,可以根据业务需求和网络状态实时调整转发流程,最大程度避免网络拥塞和故障而造成的丢包。
- FLASHLIGHT精细化流量分析引擎,实时测量每个包的延迟和往返时间等,经过CPU的智能分析,实现自适应路由和拥塞控制。
- 10纳秒级别的PTP/SyncE时间同步,保证所有GPU同步计算。
- 开放API,通过REST API开放全部功能给AI数据中心管理系统,与计算设备相互协同,实现GPU集群的自动化部署。


