
替代IB交换机,如何选择数据中心100G低时延网络设备?
对比IB专网,基于以太网的 RDMA(或 RoCE)可能是目前性价比最高的方案了,我们唯一要解决的难题就是如何构建出一个无损以太网环境。CX-N系列超低时延交换机提供不输专用IB交换机的性能,可帮助构建承载RDMA应用的高性价比融合无损以太网。
2010年后,数据中心的业务类型逐渐聚焦为三种,分别是高性能计算业务(HPC),存储业务和一般业务(通用计算)。这三种业务,对于网络有着不同的诉求。
- HPC业务:分布式计算集群,多节点进程间通信对于时延要求非常高
- 存储业务:对通信可靠性的要求非常高,网络需要实现绝对的0丢包
- 一般业务:规模巨大,要求网络低成本、易扩展
一般业务的需求,或许传统以太网还能勉强应付,但一旦面向的是高性能计算和存储业务,则实在难以为继。存储从硬盘驱动器(HDD)发展到固态驱动器(SSD)和存储类内存(SCMs),使得存储介质延迟缩短了 100 倍以上;算力也从通用CPU发展到各类支持并行计算的分布式GPU、专用AI芯片等等…反观网络却越发成为数据中心性能提升的瓶颈——通信时延在整个存储的E2E(端到端)时延中占比已经从10%跃迁到60%以上。
试想宝贵的存储资源有一半以上的时间是在等待通信空闲;昂贵的处理器,也有一半时间在等待通信同步…这滋味怎一个“酸爽”了得!
为什么如此虐心虐肺?——这可能需要从传统的TCP/IP协议说起了。
在典型的IP数据传输中,当网络流量以很高的速率交互时,发送和接收的数据处理性能会变得非常的低效,这其中主要有两个原因。
首先,处理时延高:TCP协议栈在收/发报文时,需要做多次上下文切换,每次切换需耗费5μs~10μs左右时延;多次数据拷贝,严重依赖CPU进行协议封装,协议栈本身就有数十微秒的固定时延。
其次,消耗CPU:TCP/IP还需主机CPU多次参与协议栈内存拷贝。网络规模越大,网络带宽越高, CPU在收发数据时的调度负担越大,导致CPU持续高负载。当网络带宽达到25G以上(满载),绝大多数服务器,至少50% CPU资源将不得不用来传输数据。
面对传统TCP/IP协议栈的低效,RDMA技术应运而生
这里我们不妨先回过头来看看数据中心网络流量传输的实际情形。
当前,越来越多的新兴业务应用建设于公有云之上。终端用户看似简单的一个访问行为,会在数据中心内部产生一系列连锁反应——数据信息在web应用服务器,大数据分析服务器,存储服务器、运营数据显示系统之间一通传递之后,最终才会将访问结果推送到终端,这就导致数据中心网络中的东西向流量剧增,甚至占据了80%的网络带宽,出现了大量的远程内存访问需求。
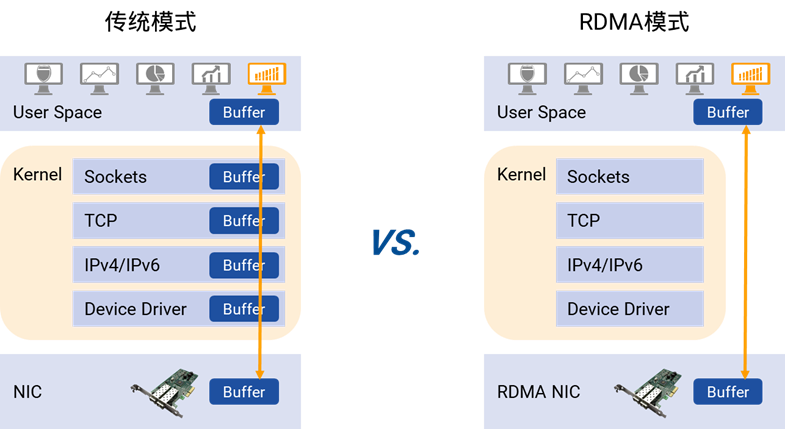
与TCP/IP数据传输相比,远程直接内存访问(Remote Direct Memory Access, RDMA) 可以让数据直接从一台服务器的存储器传输到另一台服务器,无需中央处理器、CPU缓存的干预。这样不仅节省了大量CPU资源,同样也提高了系统吞吐量、降低了系统的网络通信延迟,尤其适合在大规模的并行计算机集群网络中应用。据测算,用 RDMA代替 TCP/IP 进行通信,使得网络化 SSD 存储的 I/O 速度提高了约 50 倍。
我们很容易注意到,应用程序执行RDMA读取/写入请求时的确是走了捷径,但是网络传输侧的压力却依旧存在。
云计算时代的数据中心不断抛出“既要又要还要”的复杂网络需求,有人曾经为此构建了类似这样的网络——
- 低时延的IB(InfiniBand)网络:用于高性能的分布式计算网络
- 无丢包的光纤通道(Fiber Channel)网:用于存储区域网络(SAN)
- 低成本的以太网(Ethernet):用于一般的IP业务网
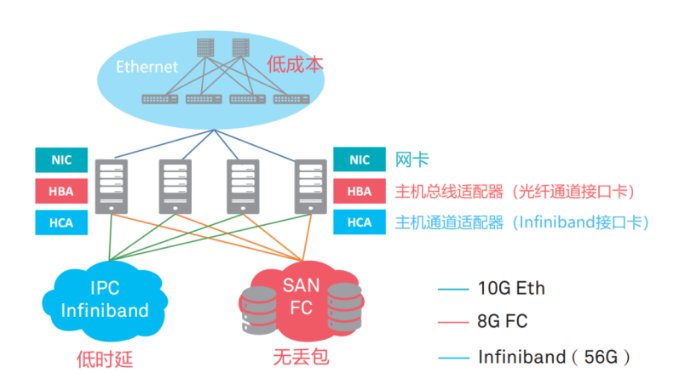
各取所长,看起来很完美对不对?
非也!
IB专网和FC专网的性能很强,但是价格昂贵,是以太网的数倍。而且,两种专网需要专人运维,会带来更高的维护成本。
我们暂且拿IB专网细说一番:InfiniBand是一种封闭架构,交换机是特定厂家(目前主要是Mellanox)提供的专用产品。要构建这样的无损网络,服务器需要专用的IB网卡,专用的IB交换机,价格一般是普通网络设备的五到十倍,相应的还会带来配套设施成本增加(如线缆、模块、监控、电耗等);而且,IB是私有协议,无法做到与其他网络设备互通互访。另外IB 专网运维依赖原厂,故障定位困难,且解决问题时间较长,网络的升级也取决于Mellanox产品发布的进度,无法做到和业界统一。
存储网络(SAN)创建FC专网的情况也与之类似,尽管性能和扩展性都不错,但仍旧需要专用设备。
综合以上,无论从建设成本还是运维角度来看,上述方案都并非是一个最佳选择。
RDMA究竟需要怎样的网络?
RDMA各类网络技术的比较(via.ODCC智能网络无损技术白皮书 2021)
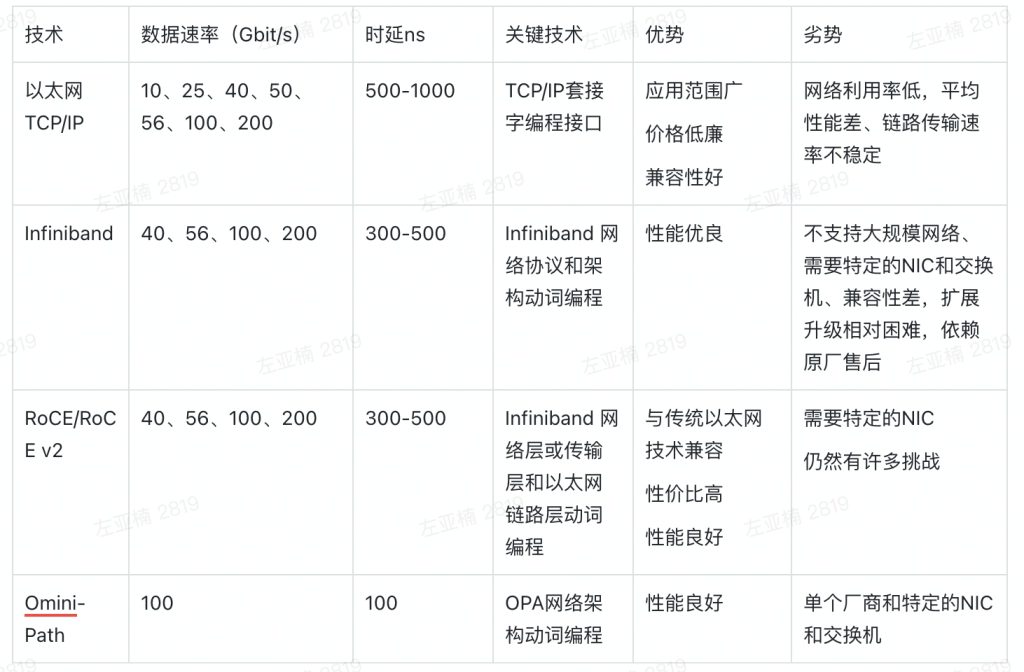
通过上表我们不难看出,基于以太网的 RDMA(RoCE)可能是目前性价比最高的方案了。这种情况下,我们唯一要解决的难题就是:如何构建出一个适合RDMA传输的以太网环境,让RDMA真正发挥出极致性能。
网络传输好比是快递运输。如果遇到了堵车,一定时间内运量就会大幅减少,运输效率大大降低,如果还不小心弄丢了包裹就需要重新发货,耗时更多。这就是我们常说的网络拥塞和丢包。
- 一般来说,数据中心内部发生网络拥塞有如下技术原因:
- 上下行非对称设计。网络设计通常采用非对称的方式,上下行链路带宽不一致(即,收敛比)。当交换机下联的服务器上行发包总速率超过上行链路总带宽时,上行口就会出现拥塞。
- ECMP。数据中心多采用Fabric架构,并采用ECMP来构建多条等价负载均衡的链路,通过设置HASH因子并HASH选择一条链路来转发,该过程没有考虑所选链路本身是否有拥塞,所选择的链路流量饱和时,就会发生网络拥塞。
- TCP Incast。当服务器向一组节点发起请求时,集群中的节点会同时收到该请求,并且几乎同时做出响应,从而产生了“微突发流”,如果交换机上连接服务器的出端口缓存不足就会造成拥塞。
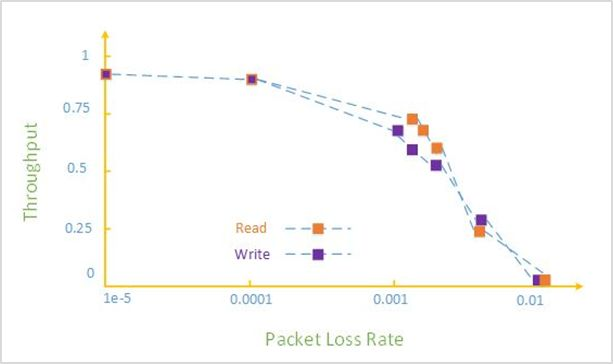
丢包对网络数据传输性能的影响也是巨大,如下图所示[1] :0.1%的丢包率,将导致RDMA吞吐率急剧下降;2%的丢包率,会使得RDMA的吞吐率下降为0。
我们需要 “0丢包、低时延、高带宽”的无损以太网,但这绝非易事
- 0丢包:会抑制链路带宽,导致低吞吐,同时会增加大流的传输时延;
- 低时延:降低交换机队列排队,容易导致低吞吐;
- 高带宽:保持链路高利用率,容易导致交换机的拥塞排队,导致小流的“高时延”。
云计算时代下,你需要怎样的数据中心基础网络设备?
从上述“0丢包、低时延、高带宽”三大要素出发,落到实际层面上便对承载云基础网络的交换机提出了以下具体要求。
1. 支持构建无损以太网的关键技术
- 流量控制技术 – 用于解决发送端与接收端速率匹配,做到无丢包;
- 拥塞控制技术 – 用于解决网络拥塞时对流量的速率控制问题,做到满吞吐与低时延
- 流量调度技术 – 用于解决业务流量与网络链路的负载均衡问题,做到不同业务流量的服务质量保障。
星融元CX-N系列超低时延交换机,支持传输RoCE流量和面向数据中心的高级网络功能(如:PFC、ECN、ETS、DCBX),并通过PFC死锁预防机制、VLAG以及先进的拥塞控制算法等,帮助构建高可靠的无损以太网。
【演示视频在线观看:PFC、ECN…】
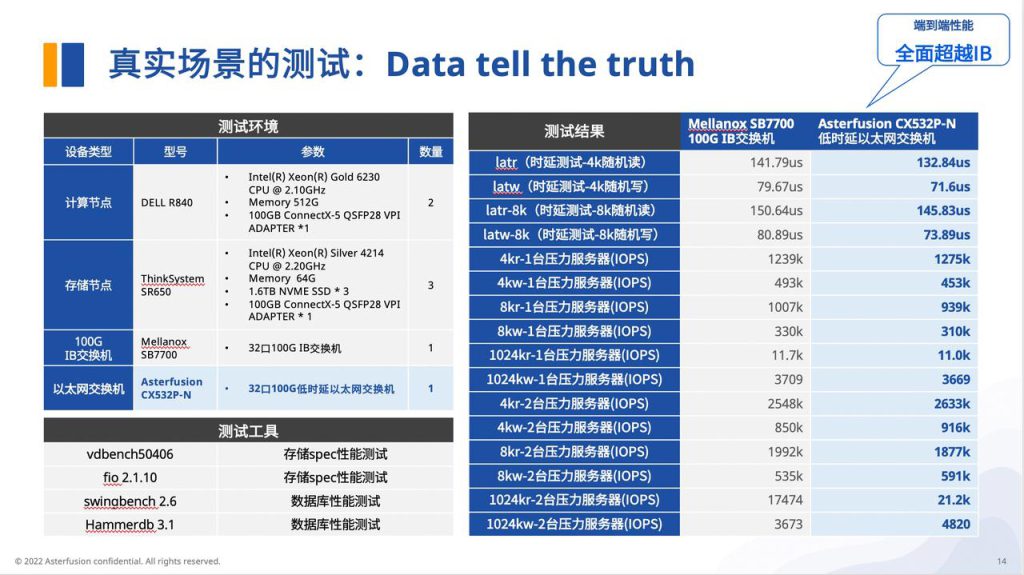
2. 设备本身具备尽可能低的转发时延
在设备转发时延方面,我们以采用业界领先的可编程超低时延交换芯片的星融元CX532P-N以太网交换机,对比Mellonox的SB7700 IB交换机进行了对比测试。
结论是:星融元超低时延以太网交换机的端到端性能,可全面超越IB交换机。
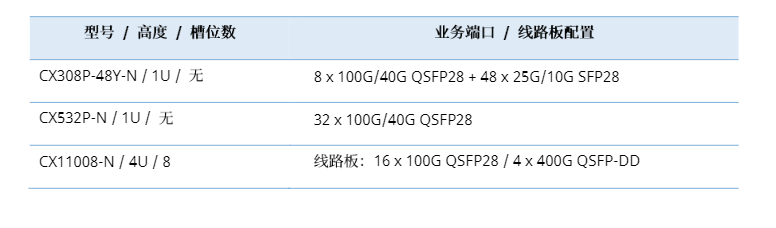
3. 全盒式设备提供高密度接口,组网灵活易扩展
得益于高密度高性能端口的规格设计,我们可以从容地选用不同规格的CX-N系列云交换机搭建出Spine-Leaf架构*的两层网络,以实现大规模计算/存储集群的接入与承载。
Spine-Leaf架构相对传统三层组网架构,具有无阻塞转发、可扩展性强和网络可靠性高等优势。而且在这样的网络架构中,任何两台服务器之间的通信不超过三台交换机,进一步降低了网络流量的转发时延。

4. 存储+高性能计算+一般业务三网合一,SDN智能运维
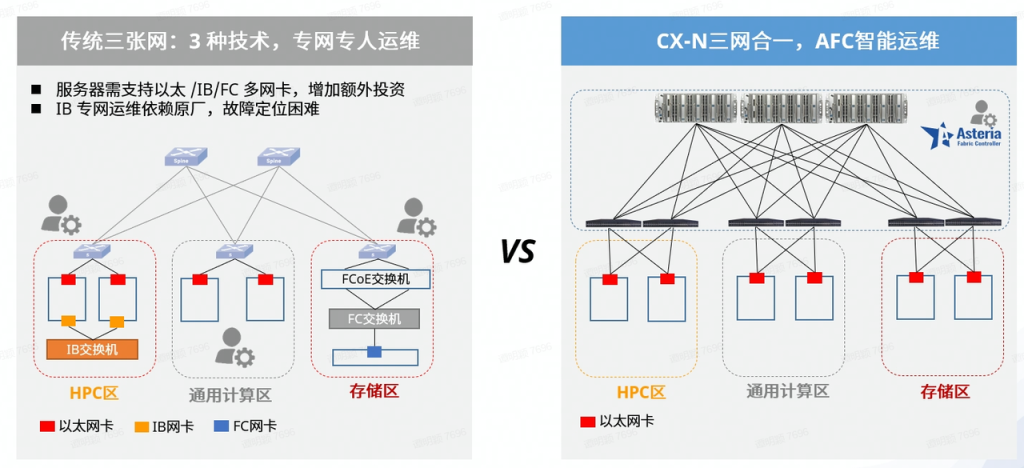
(此外值得一提的是,CX-N系列超低时延交换机搭载的是星融元为云计算时代设计开发的开放网络操作系统,它以标准的Linux、SONiC和SAI为内核,可与第三方云管平台无缝融合,并且提供Cisco风格的命令行;该交换机的硬件平台也全面遵从OCP所制定的开放性原则,涉及的技术标准和开发规范完全开放,确保用户拥有的是一个完全透明的开放系统。)
[1] Zhu, Y., H. Eran, D. Firestone, C. L. M. Guo, Y. Liron, J. Padhye, S. Raindel, M. H. Yahia and M. Zhang,Congestion Control for Large-Scale RDMA in Proceedings of the 2015 ACM Conference on Special Interest Group on Data Communication (SIGCOMM ’15), London, United Kingdom, 2015.
[2]https://www.odcc.org.cn/download/p-1437654565852237825.html ODCC智能无损网络技术白皮书
[3]https://info.support.huawei.com/info-finder/encyclopedia/zh/%E6%99%BA%E8%83%BD%E6%97%A0%E6%8D%9F%E7%BD%91%E7%BB%9C.html
[4]https://blog.csdn.net/SDNLAB/article/details/88746460


