融合推理网络深度解读:从三网分离到统一架构的AI推理变革
大模型技术正在从研发实验室走向全面的商业落地。在 AI 设备的完整生命周期中,通常包含训练与推理两个关键阶段。训练是在封闭环境中让模型学习技能,而推理则是模型学成后, 7×24小时不间断地为公众或企业内部实时解决问题、提供服务。因此,AI 推理网络的性能与稳定性,将直接决定最终的用户体验。
过去,智算中心常采用计算、存储、前端业务“三网分离”的传统物理隔离架构,这带来了高昂的硬件采购成本与复杂的运维挑战。为了打破这一瓶颈,融合推理网络应运而生。
本文将深入探讨融合推理网络的底层架构、关键技术以及具体的落地方案,帮助企业在保障 AI 低时延体验的同时,大幅实现降本增效。
什么是融合推理网络?
融合推理网络是指通过统一的物理网络拓扑,将原本物理隔离的计算、存储及前端业务流量融合到同一张高性能网络中。
传统DC、AI训练与AI推理网络的流量形态对比
为了更直观地理解融合推理网络的优势,我们需要对比三种不同的网络流量特征:
| 特征维度 | 传统数据中心(DC) | AI 训练网络 | AI 推理网络 |
| 主要流量形态 | 标准 TCP/IP 流量,带宽较小,南北向与东西向平衡 | 大象流(Elephant Flow)密集,具强周期性,属网络密集型负载 | 大象流(Elephant Flow)密集,具强周期性,属网络密集型负载 |
| 丢包容忍度 | 可容忍轻微丢包与重传 | 零丢包容忍(基于无损 RoCE 后端网) | 零丢包容忍,且对低时延要求极高 |
| 核心性能诉求 | 吞吐量与基本连通性 | 高吞吐、零丢包、算力集群并行效率 | 超低首字延迟与极低长尾时延 |
| 主要网络瓶颈 | 传统链路拥塞 | 严格同步带来的周期性拥塞 | 高并发请求触发的 Incast 拥塞 |
在 AI 推理场景中,当用户向 AI 发起提问(Prompt)时,进入网络的是并发度高、数据量小的老鼠流;与此同时,AI 为了生成回答,集群内部会瞬间爆发海量的模型权重加载及缓存跨节点迁移,产生吞吐量极大的大象流。
这种复杂的混合流量形态,使得网络极易在多对一通信时形成 Incast 拥塞。
突破硬件隔离:三网融合架构的硬核价值
在传统的“三网分离”架构中,一台 GPU 服务器需要插上三种不同的网卡:专供 GPU 计算的网卡、专供分布式存储的存储网卡、以及连接业务前端的常规网卡,并分别接入三套独立的交换机设备。
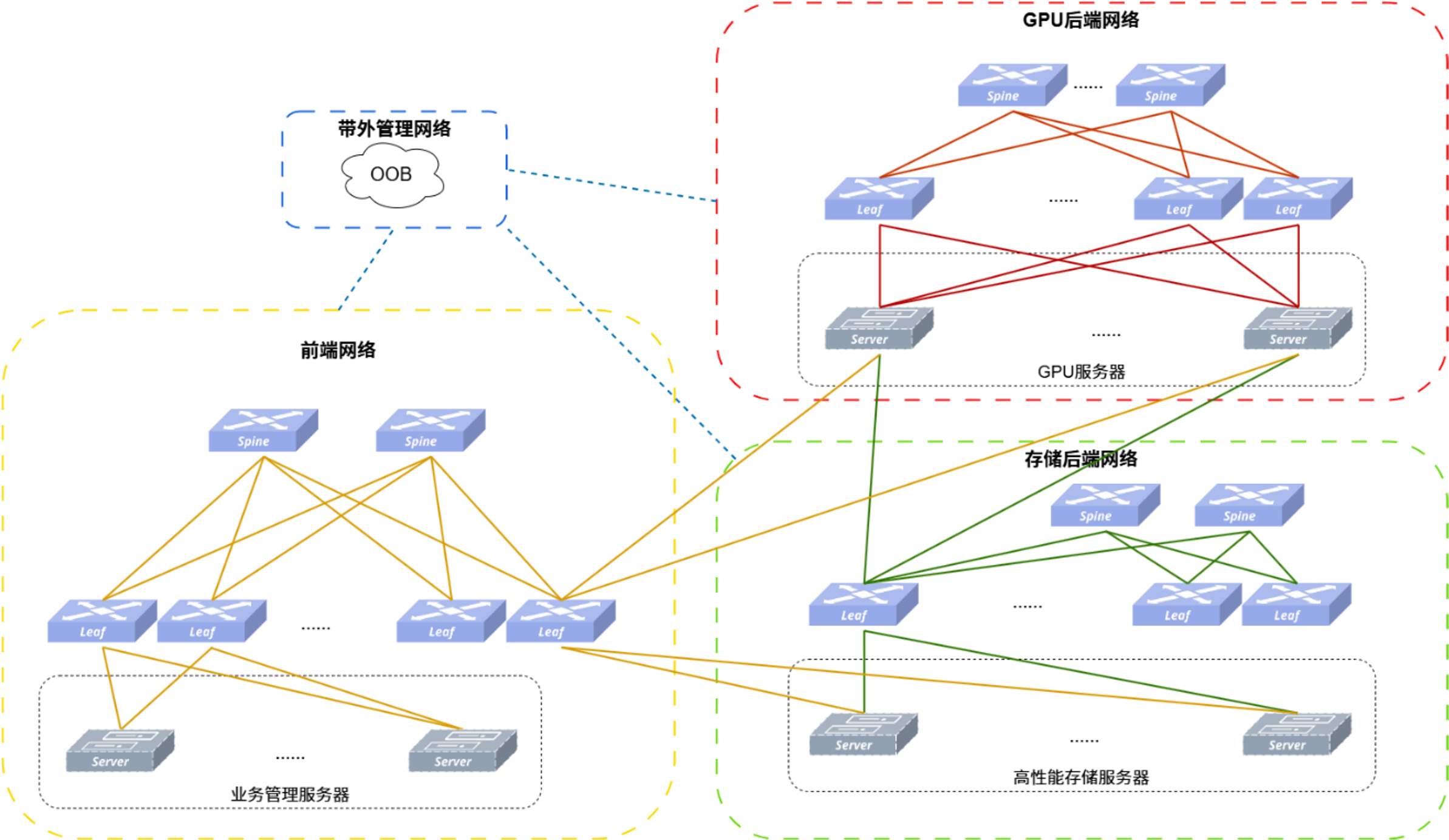
物理隔离意味着网络带宽和资源无法互通。例如,在推理任务中,当模型加载完成后,存储网会有高达 90% 的时间处于闲置状态,而旁边的计算网却可能因为高并发请求堵得水泄不通,两边的带宽根本无法动态调配和复用。
而三网融合网络架构彻底打破了这种硬性隔离:
- 极致控本:服务器端只需安装一张统一的高性能网卡,配合一套物理拓扑(Spine-Leaf)即可承载所有流量,大幅缩减交换机、网卡和光模块的采购成本。
- 动态带宽共享:利用交换机自身的 QoS 业务分级与调度机制,让无损流量(RoCE)与有损流量(传统 TCP)弹性共存,实现空闲带宽的动态复用。
- 高效一键运维:依托 Easy RoCE 等技术,在一套网络上进行一次部署配置即可,无需在多张网上重复倒腾,部署效率成倍提升。
工程边界提示:对于采用 4090 等轻量级 GPU 的集群,由于显卡本身没有 NVLink 互联通道,其 GPU 间的集合通信转发全卡在 PCIe 或外部网络上,且服务器内部没有富余空间插多张无损网卡。在这种场景下,融合网络架构是企业必须选择的唯一落地解法。
支撑融合推理网络的五大关键技术
要在同一张物理网上同时跑赢对时延极敏感的计算流、大吞吐的存储流和复杂的业务流,必须依赖以下核心技术的协同:
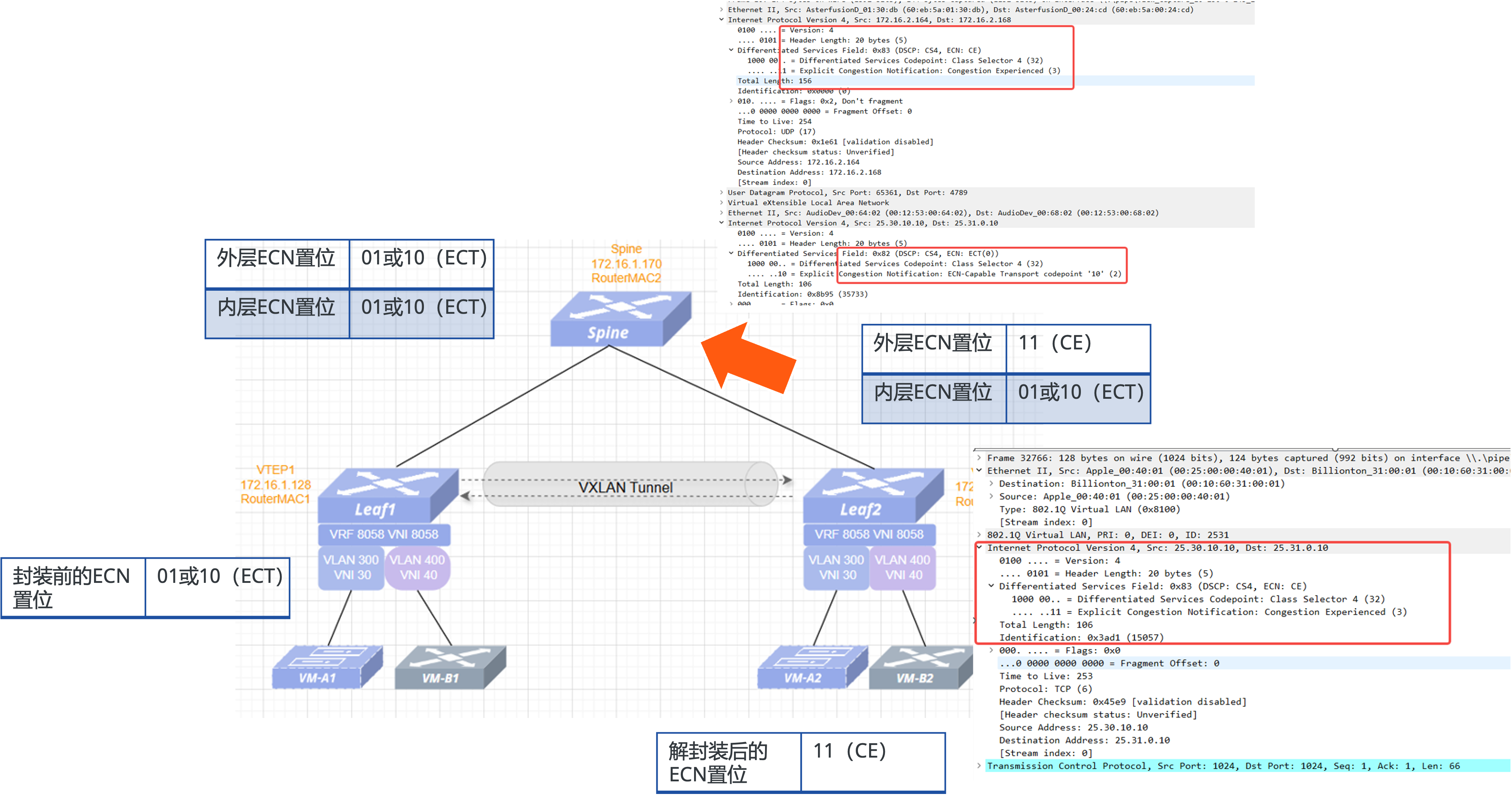
1、ECN over VXLAN:消除 Overlay 网络的拥塞盲区
在智算中心多租户场景下,通常采用 VXLAN 技术进行 Overlay 隔离。但 VXLAN 封装会加上新的外层头部,导致 Underlay 的 Leaf 层和 Spine 层交换机发生拥塞时,外层报文无法将拥塞状态传递给终端网卡,导致拥塞管理失效。 ECN over VXLAN 技术实现了内外层 ECN 置位的双向映射。当 Spine 出口拥塞并在外层标记 CE 错位时,Leaf 解封装时会将其完美映射回内层,确保端侧服务器能精准感知上游拥塞并及时发送 CNP 降速报文。
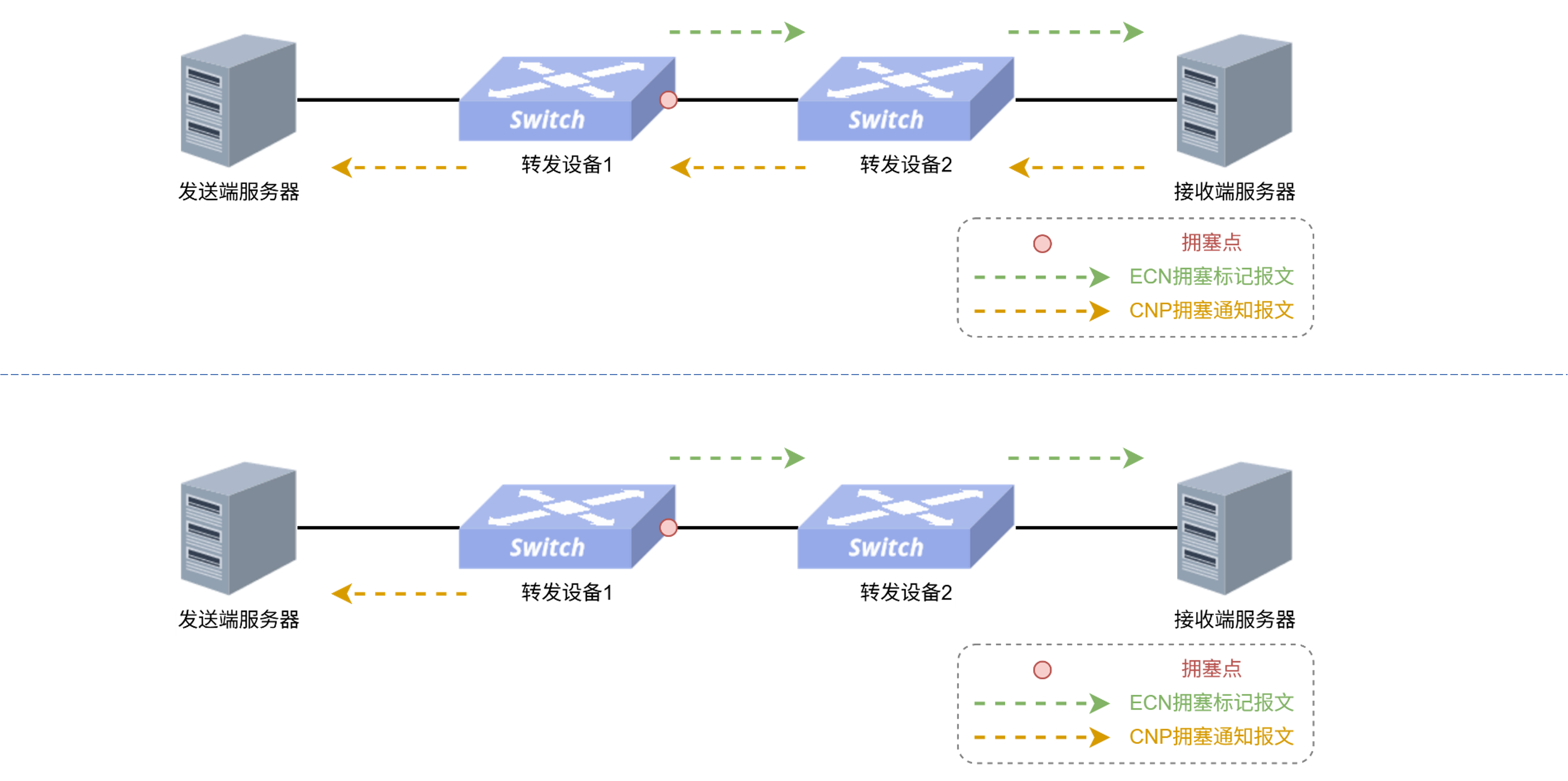
2、Fast CNP(快速拥塞通知):微秒级闭环响应
传统 DCQCN 机制中,从交换机发生拥塞到接收端服务器,再由接收端反向向发送端发回 CNP 报文,需要经历至少一个 RTT 的反馈路径,极易导致降速不及时而触发 PFC 丢包重传。 Fast CNP 技术由交换机在内部直接捕获 RoCE v2 会话并维护流表。一旦交换机检测到拥塞,无需绕道接收端,直接在芯片内部反向构造出 CNP 报文发给发送端服务器。响应路径直接缩短一半以上,实现微秒级响应,从根本上减少了 PFC 兜底的概率,保障了整体吞吐量。
3、QoS 业务分级与混合调度
为了防止有损的前端流量抢占无损的计算与存储通道,融合网络对不同流量的 DSCP 优先级进行了深度映射与严格分级:
- 队列 7(最高优先级,SP 严格优先级调度):集群控制与管理流量。带宽占比极小,但关乎集群生死,拥有最高转发特权。
- 队列 6(次高优先级):拥塞控制报文(CNP,固定 DSCP 48)。确保拥塞通知绝不丢包、绝不延迟。
- 队列 4 & 队列 3(无损队列,权重 50% / 30%):分别划给计算流量与存储流量,严禁丢包。
- 队列 0(有损队列):前端业务网与用户访问请求。外部请求不可预测,允许在极度拥塞时主动丢包并触发 TCP 重传,全面力保无损队列的畅通。
4、微分段(Micro-segmentation):细粒度安全隔离
在单个租户或单个 VRF 内部,传统网络很难做到精细的主机级隔离。微分段技术支持基于具体的主机 IP(32位)或特定的 IP 网段(24位),在同一个租户内部划定精细的安全访问策略。例如,可轻松配置策略让同一网段的 A1 与 A2 互通,但严禁 A1 访问 A5 主机,完美满足企业对 AI 算力实例的精细化安全审计需求。
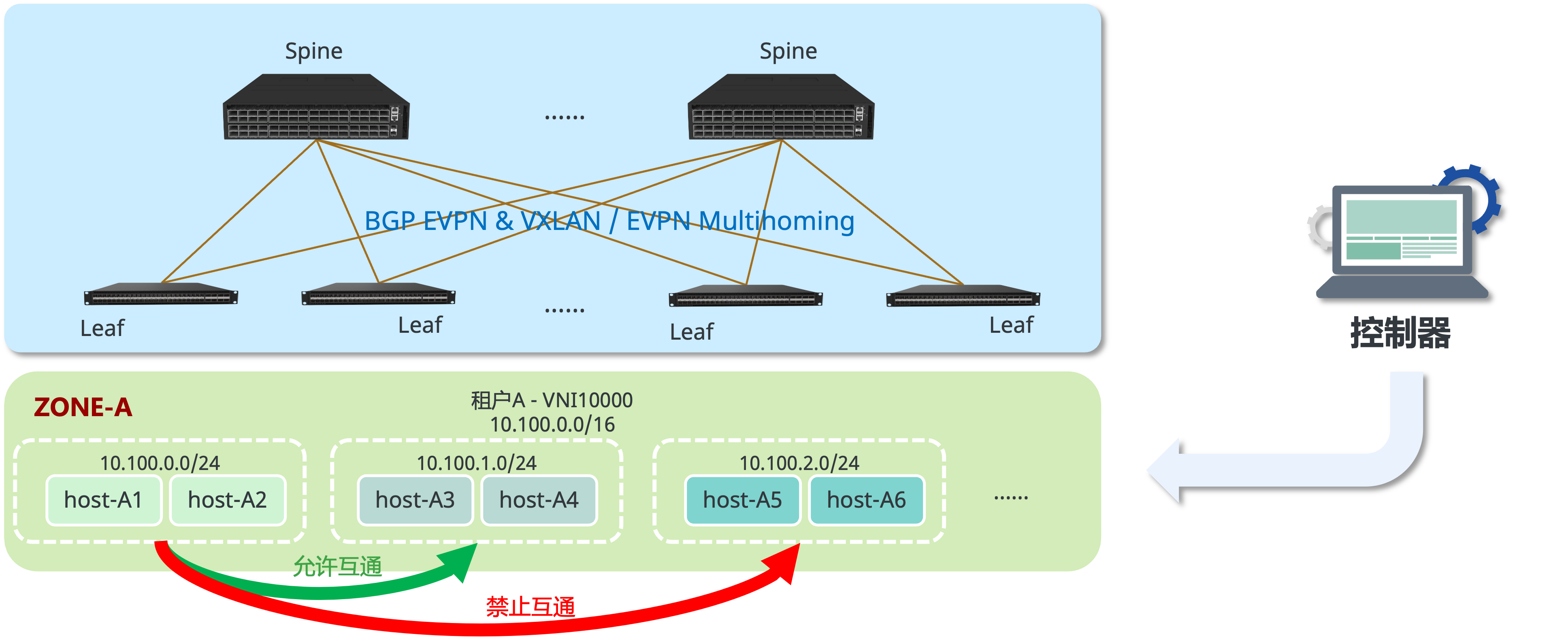
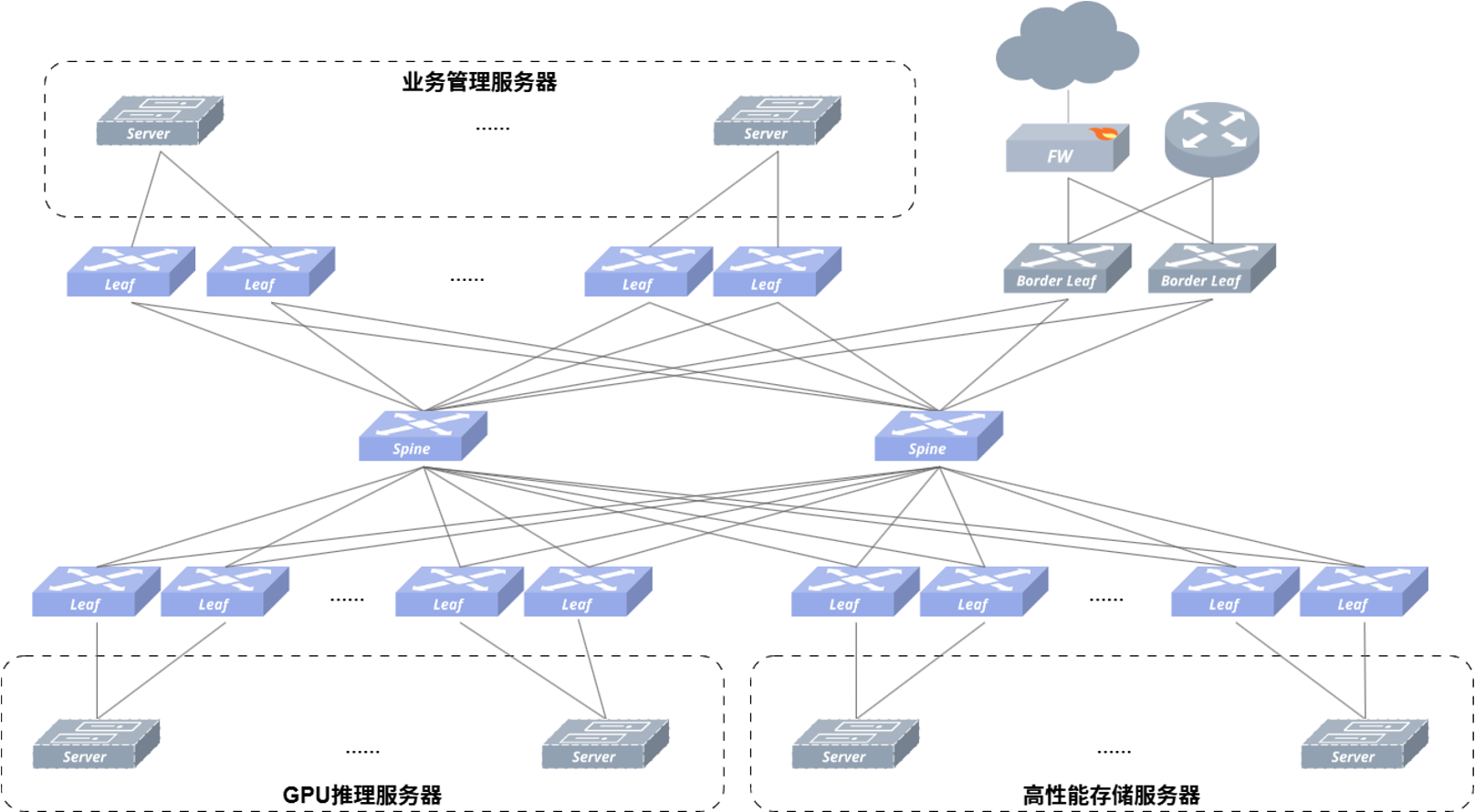
智算中心融合推理网络落地方案设计
接入形态与收敛比设计
在落地实践中,中小型企业与私有化本地大模型部署多采用 25G 接入(轻量级推理算力卡,性价比主力军)或 100G 接入(小规模推理与知识库检索)。
在无损网络中,设计通常追求 1:1 的无阻塞收敛比。但在融合推理网络中,由于 Fabric 带宽能够弹性共享,追求 1:1 并没有太大必要。推荐采用 1.5:1 或 2:1 的非对称收敛比设计。以典型交换机为例:下行接入 48 个 25G 端口,上行提供 8 个 100G 端口,在非 MC-LAG 场景下收敛比约为 1.5:1;若划出 2 个 100G 跑 MC-LAG 堆叠,上行剩余 6 个 100G,收敛比则为 2:1。该设计能最大化榨干网络拓扑的每一兆带宽残余。
组网高可靠设计
为了让分布式推理摆脱“木桶效应”的长尾时延拖累,计算节点与存储节点的网卡速率必须严格对齐()。在接入侧,服务器统一采用双上行网卡做 Bond 接入:
- 纯 Underlay 场景:推荐部署 MC-LAG 或 ARP to Host 路由技术实现双归高可靠。
- Overlay 多租户场景:推荐采用 EVPN MC-LAG 或 EVPN Multipoint Homing,确保在任一 Leaf 设备或链路发生硬件故障时,推理业务能够做到全自动无感切换。
QoS业务分级设计
| 业务流量分类 | 数据流特征描述 | 建议DSCP | 映射本地硬件队列 | 队列调度算法 | 流控与拥塞管理特性 |
|---|---|---|---|---|---|
| 集群控制与管理流量 (K8s管理/控制心跳) | 交换机路由协议流、K8s控制流及集群状态监测流。流量整体带宽占比小,但关系到集群稳定性。 | DSCP: 56 | Queue 7 (控制专用有损队列) | SP (Strict Priority) 绝对严格优先级 | 有损队列。由于享有最高转发权,优先于一切数据业务流进行转发,确保网络局部拥塞时控制链路不断开。 |
| 拥塞控制报文(CNP) | 由接收端网卡或交换机(Fast CNP)反向构造,不携带业务数据(纯反向小包),但具有极高的时延敏感度 。 | DSCP: 48 | Queue 6 (CNP专用有损队列) | SP (Strict Priority) 绝对严格优先级 | 属于有损队列,但享有仅次于集群管理流的绝对转发特权 。确保“刹车指令”全网最快送达 。 |
| 推理计算流量 (张量并行TP/流水线并行PP) | 机间并行参数流,属于小包高频微秒流。对时延抖动和丢包极度敏感,呈高频强突发特征。 | DSCP: 32 | Queue 4 (计算专属无损队列) | DWRR 权重: 50% | 无损队列。开启 PFC。在 DWRR 无损队列中优先级最高,兼顾高吞吐与低长尾延迟。 |
| 高性能存储流量 (NVMe-oF读写/KV Cache迁移) | 模型权重高速加载、分布式 KV Cache 跨节点迁移流。属于大块数据突发、高带宽、高 IOPS 吞吐型流。 | DSCP: 24 | Queue 3 (存储专属无损队列) | DWRR 权重: 30% | 无损队列。开启 PFC。设定科学的 ECN/WRED 动态加权打标门限,使存储流在端侧提前微降速。 |
| 前端业务与用户API (常规用户请求/有损TCP杂流) | 外部用户高并发模型推理 API 请求。呈现不可预测性,表现为高突发老鼠流与有损标准 TCP/IP 流量混杂。 | DSCP: 0 | Queue 0 (常规通用有损队列) | DWRR 权重: 20% | 有损队列。拥塞溢出时主动丢包,防止其强占无损通道缓存。 |
- NCCL测试:双机16卡(连接NVIDIA H100集群,400G CX-7 NIC)
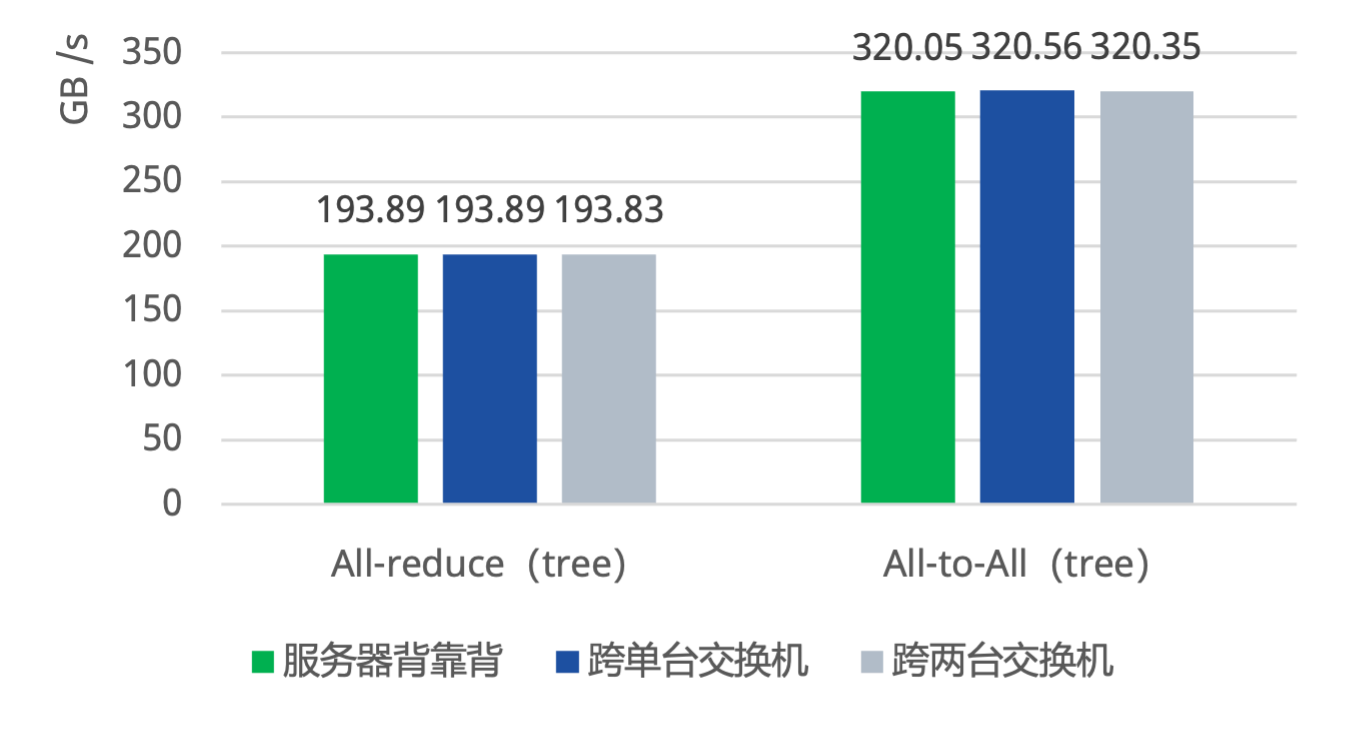
端到端All-Reduce吞吐量190GB/s; 端到端All-to-All吞吐量约320GB/s; 均与背靠背连接时性能相当。
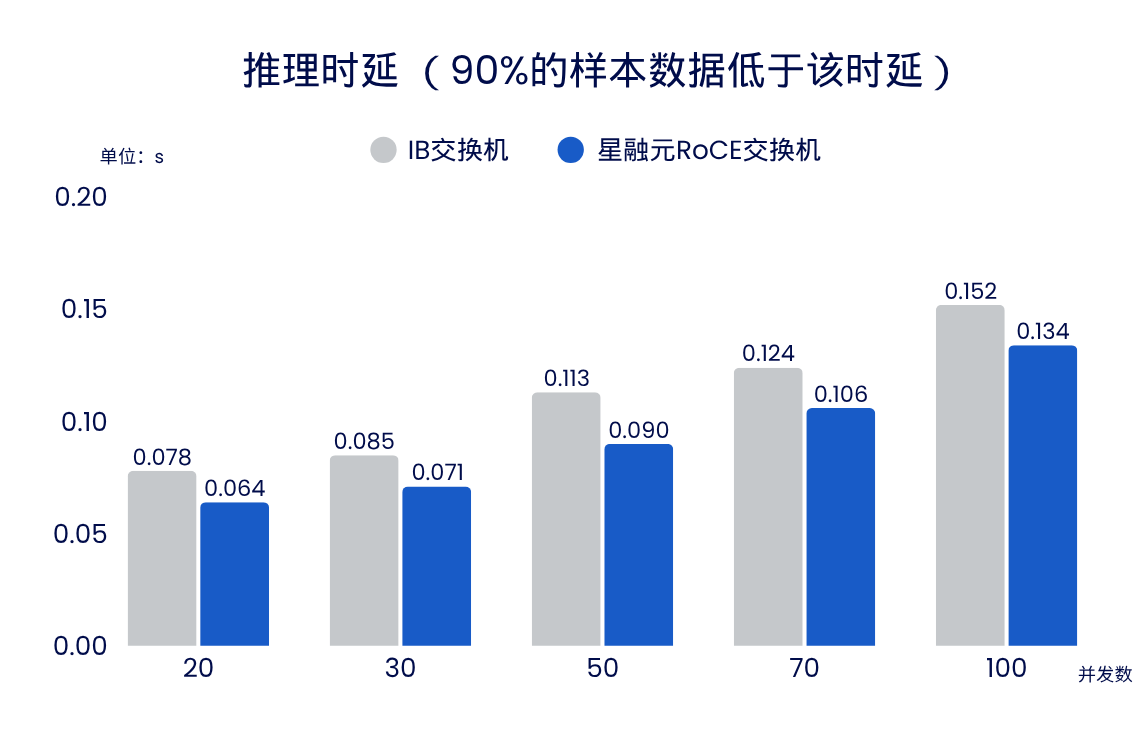
- 部署DeepSeek 671B 大模型测试推理性能测试: 双机16卡(NVIDIA H20 GPU卡 + 400G CX-7 NIC)
在不同的并发推理请求场景下(20~100),使用 Asterfusion RoCE 交换机的推理延迟始终低于使用 InfiniBand(IB)交换机。在 50 个并发请求下,90% 推理延迟降低了 20.4%
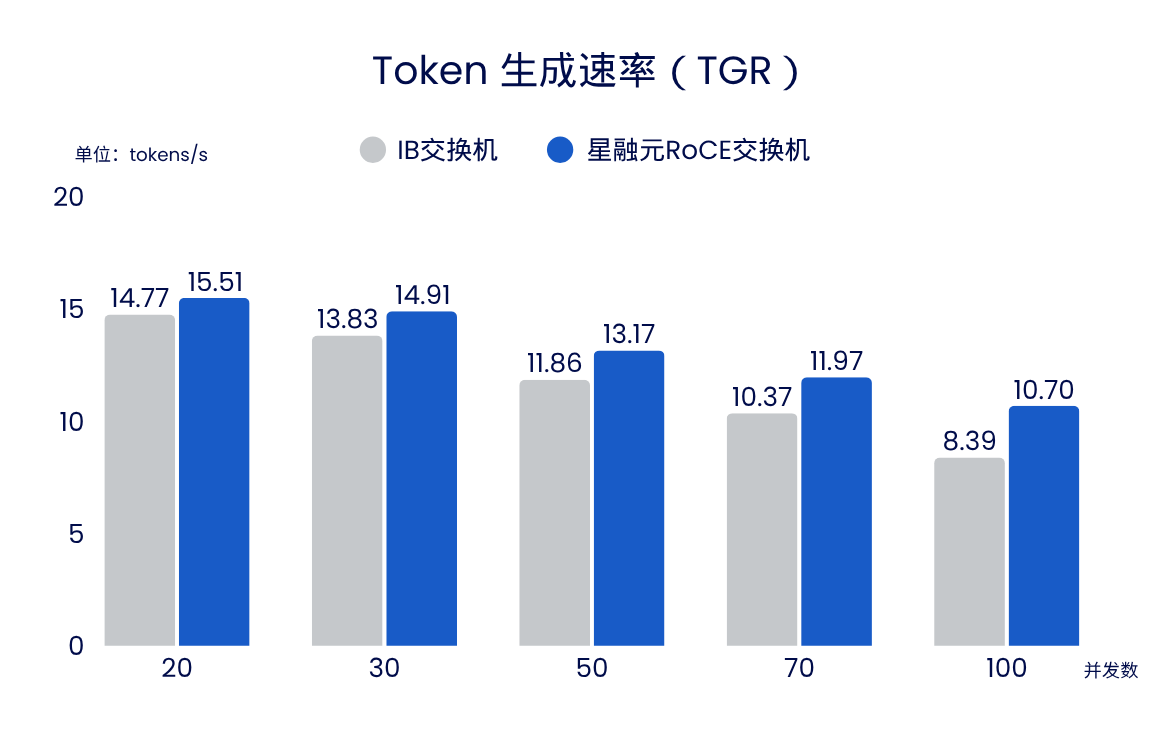
Token生成速率:对于 20 到 100 个并发推理请求,星融元Asterfusion的 RoCE 交换机始终提供比 InfiniBand (IB) 交换机更高的Token 生成速率。随着并发请求数量的增加,增长幅度进一步扩大,在 100 个请求时,TGR 提升了 27.5%。
真实案例:某算力服务商的千台高密推理网络实践
国内某领先的算力服务提供商为了降低本地化轻量推理集群的初期投入,在其单个网络 Pod 内落地了扁平一体化的三网融合方案:
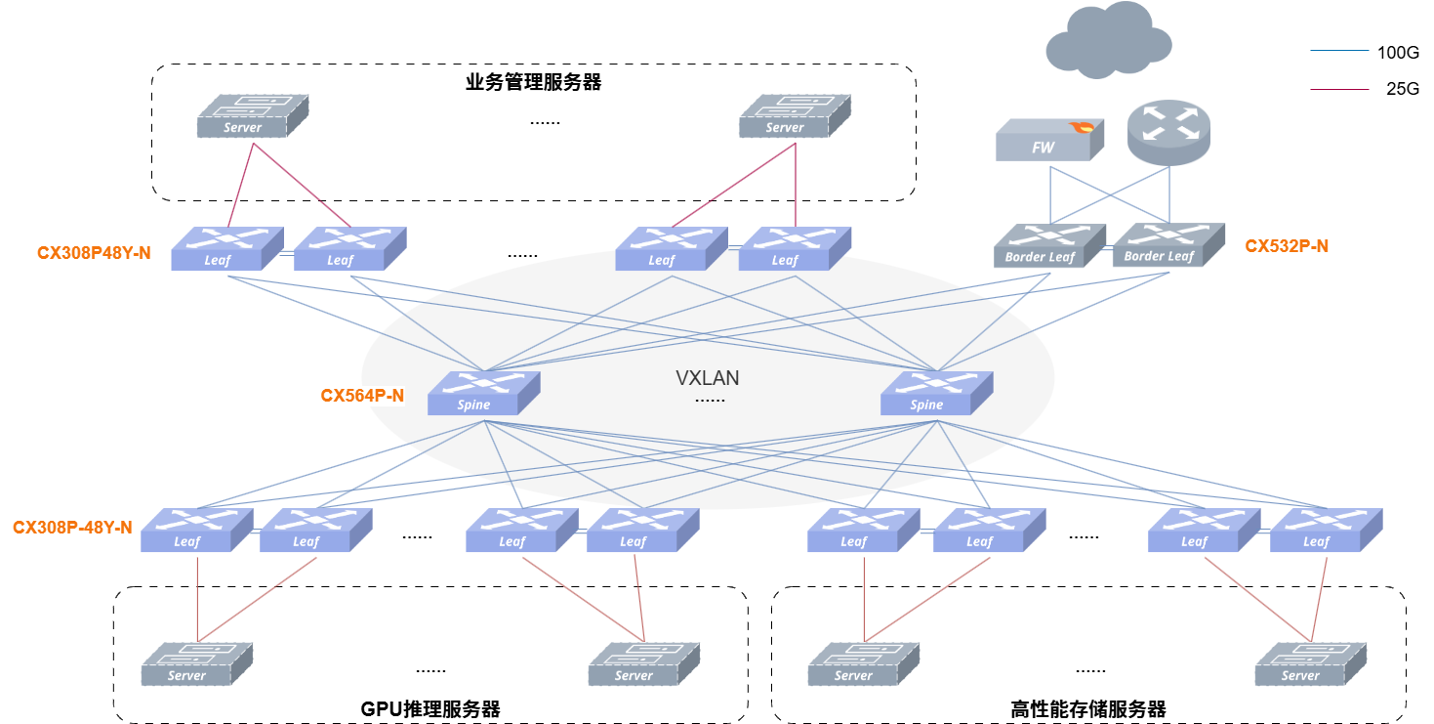
设备选型:Spine 层选用 4 台 64 端口 100G 交换机;接入层部署 62 台 25G 交换机,外加 2 台高性能交换机作为 Border Leaf 挂载防火墙向外网提供推理 API 服务。
支撑规模:在单一物理拓扑内,完美支持了 1000 多台服务器(混部了前端、推理与存储节点)的高密无损接入。
落地成效:该方案成功帮客户省去了两套独立的交换机网络,大幅压低了初期建设成本。配合 Prometheus + Grafana 可视化监控平台与 INT(带内遥测)技术,运维体验得到了质的提升。
大模型商业落地的号角已经吹响,网络作为算力释放的底层血管,其架构的优劣直接决定了企业的 ROI。融合推理网络凭借低成本、高带宽利用率以及一键式运维的绝对优势,正在成为中小型企业与私有化大模型部署的黄金标准。
如果您的算力集群正面临建网成本高、并发 Incast 拥塞卡顿、或多租户隔离困难等痛点,欢迎点击下方按钮联系我们的资深网络专家,我们将为您量身定制一整套基于 Easy RoCE 与 Fast CNP 技术的无损三网融合网络设计方案,助您的 AI 业务快人一步!




