企业网络安全利器:VRF隔离技术在园区网的最佳实践
近期文章
在数字化转型的浪潮中,企业园区网络早已不再是单纯的“连通管道”。财务数据、研发源码、访客流量以及物联网终端的指令都在同一张物理网上交织传输。如何在保障业务互通的同时,实现严格的逻辑防护?VRF(虚拟路由和转发)隔离技术通过在网络三层引入多路由表实例,允许我们在同一台物理设备上构建多个虚拟网络,为不同业务部门提供如同物理隔离般的安全感。
为什么现代企业园区网需要VRF隔离?
1、传统扁平化网络的安全隐患
传统的基于VLAN的二层网络划分虽然简单,但其广播域的控制能力有限,且访问控制列表(ACL)的配置随着业务增长变得异常复杂。一旦设备被攻破,攻击者很容易通过泛洪或ARP欺骗横向移动,威胁整个核心网。
2、多业务承载与合规性需求
无论是PCI-DSS还是等保2.0,都要求对敏感数据进行严格的网络隔离。例如,在新建的互联网办公大楼中,不仅需要区分办公网和访客网,还可能需要通过VRF协议实现不同部门、楼层间的灵活控制和隔离,以满足合规审计要求 。VRF提供的是类似“专线”级别的路由隔离,确保某条路由的震荡不会影响其他业务的路由表。
什么是VRF?——不只是另一种“VLAN”
VRF的核心原理:多路由表共存
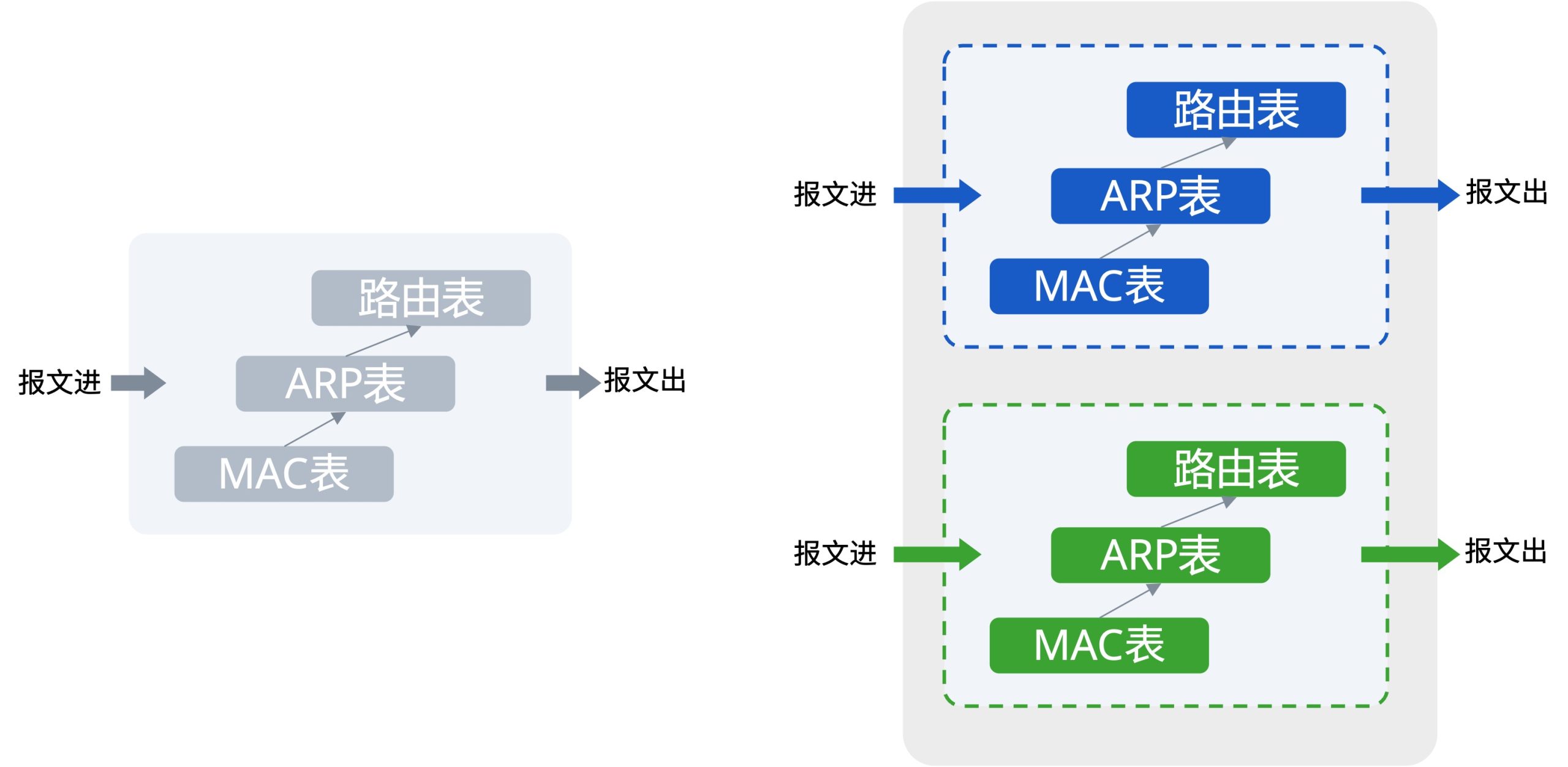
VRF技术“逻辑隔离”的原理
VRF(Virtual Routing and Forwarding)的核心是在一台路由器或三层交换机上创建多个逻辑的路由表实例 。每个VRF实例拥有自己独立的接口、路由协议进程和转发表。从网络层的角度看,一台物理设备此时已经变成了多台完全不互通的虚拟设备。这种隔离是通过路由区分符(RD)来确保地址不会冲突,并通过路由目标(RT)来控制路由的导入和导出策略。
VRF vs. VLAN:三层隔离与二层隔离的本质区别
这是网络设计中容易混淆的概念。简单来说,VLAN工作在OSI模型的第二层,主要是隔离广播域;而VRF工作在第三层,隔离的是路由转发路径。VLAN通常依赖于IP子网的划分,而VRF则允许不同实例使用完全相同的IP地址段而互不影响。在企业园区中,通常建议VLAN与VRF结合使用:VLAN负责接入层的划分,而VRF则负责核心层和汇聚层的路由隔离。
企业园区网中部署VRF隔离的三大架构模式
边缘VRF:接入层的第一道防线
在新建大楼或分支机构场景中,可在汇聚交换机上创建多个VRF实例。例如,将摄像头所在的VLAN映射到“Monitor-VRF”,将办公电脑映射到“Office-VRF”。这种设备虚拟化的方式确保了即使监控系统存在漏洞,攻击者也无法通过监控网络路由到财务服务器。
基于MPLS VPN的端到端隔离
对于跨园区的大规模组网,MPLS L3VPN是VRF技术的经典应用。企业可以像服务提供商一样,在骨干网上运行MPLS,边缘设备(PE)通过MP-BGP会话交换不同VRF的路由信息。这种模式允许在总部和分支之间构建安全的“虚拟专用网”,而无需租用昂贵的物理专线。
多租户专用VRF设计
在大型园区或多云数据中心整合的场景中,可以为每个业务部门(租户)分配一个专用的VRF实例。例如,在一套物理网络中同时承载“研发部”和“市场部”,两者拥有完全独立的转发实例。最新的技术文档指出,通过在单一T0网关下挂载多个租户VRF,可以在共享出口带宽的同时,保障路由层面的绝对隔离。
落地实践:VRF配置中的关键考量
如何实现受控的“跨VRF”互访
绝对的隔离有时也会造成业务不便。当需要实现跨VRF互访时(如财务需要查研发的工时系统),有三种主流方案:通过防火墙进行路由泄漏(最安全)、通过SDN控制器动态下发策略 、或在路由器上配置静态路由进行互指。对于生产环境,强烈建议通过防火墙等安全设备进行跨VRF通信,以便进行入侵检测和流量审计。
RD与RT的规划策略
部署VRF不仅仅是敲几条命令那么简单。路由区分符(RD) 只是用来解决地址重复问题的“命名空间”,而路由目标(RT) 才是控制路由分发策略的核心 。建议采用“Hub-Spoke”或“Extranet”的RT规划模型。例如,所有部门VRF(Spoke)的RT都导出给共享服务VRF(Hub),而Hub的RT则分别导入给每个部门,从而实现所有部门都能访问中心杀毒服务器,但部门之间依然保持隔离。
园区交换机的VRF创新实践
轻量级VRF
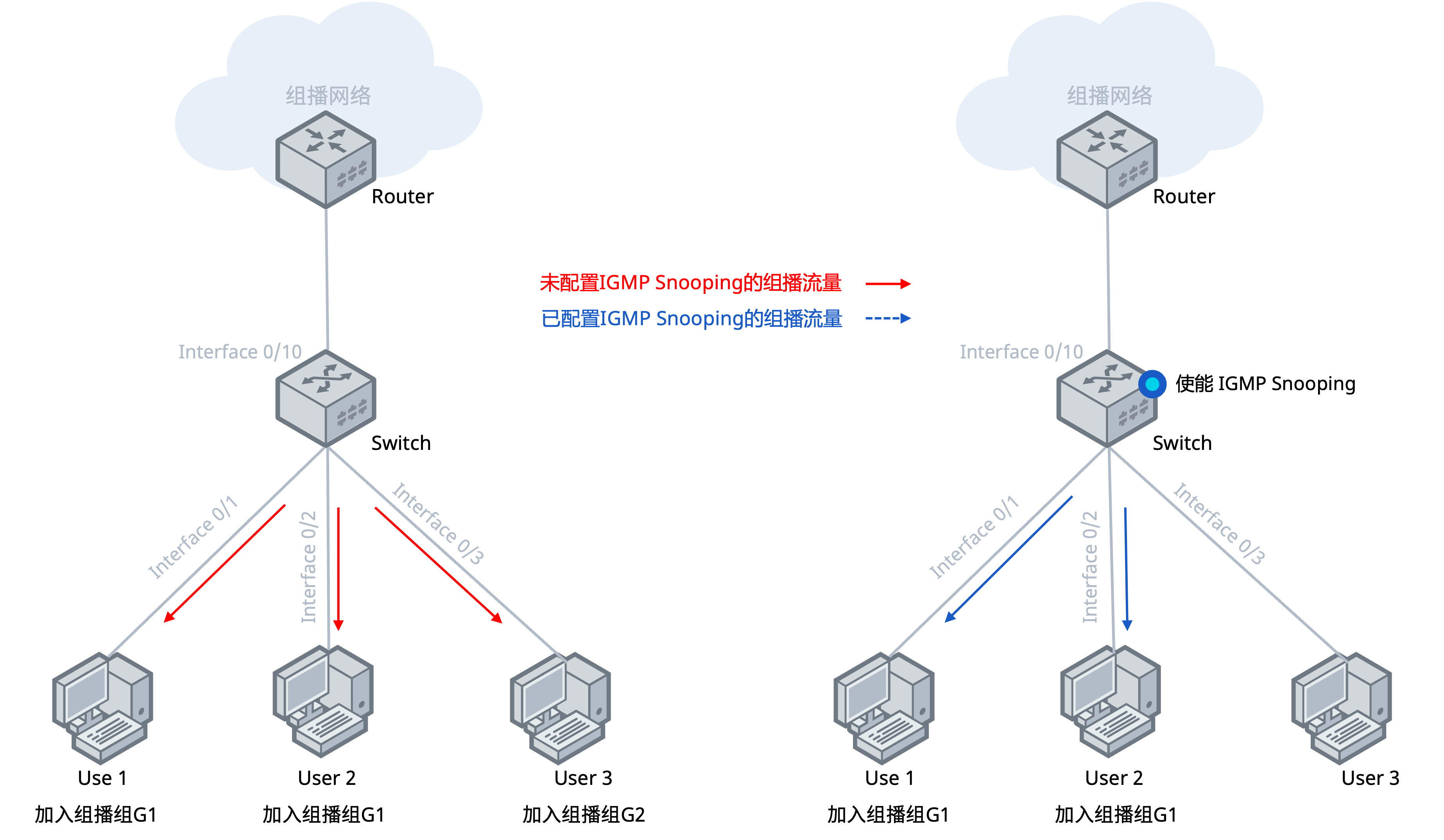
在VRF技术的实际落地中,设备的选择至关重要。作为开放网络架构的先行者,在其CX-M系列园区交换机中引入了轻量级的虚拟路由转发(VRF)技术。与传统厂商复杂的VRF配置不同,方案中可让多种业务复用一张物理网络,实现“一网多用”——办公网、研发网、物联网在同一套物理设备上各跑各的路由表,互不干扰。对于超大规模场景,还支持VXLAN/EVPN协议,实现更灵活的网络虚拟化。
全三层组网:从根源杜绝广播风暴
通过将二层广播域压缩至交换机的每一个物理端口,终端仅和接入层Leaf接口上的网关IP进行二层通信,从根源上阻断了广播风暴的发生。在这种架构下,每个接口就是一个广播域,因二层广播机制而产生的ARP欺骗、DHCP饿死等安全风险都将不复存在。配合分布式网关技术,终端在跨楼层、跨楼栋移动时,IP地址和安全策略保持不变,漫游切换无感知。
AsterNOS:开放架构下的灵活管控
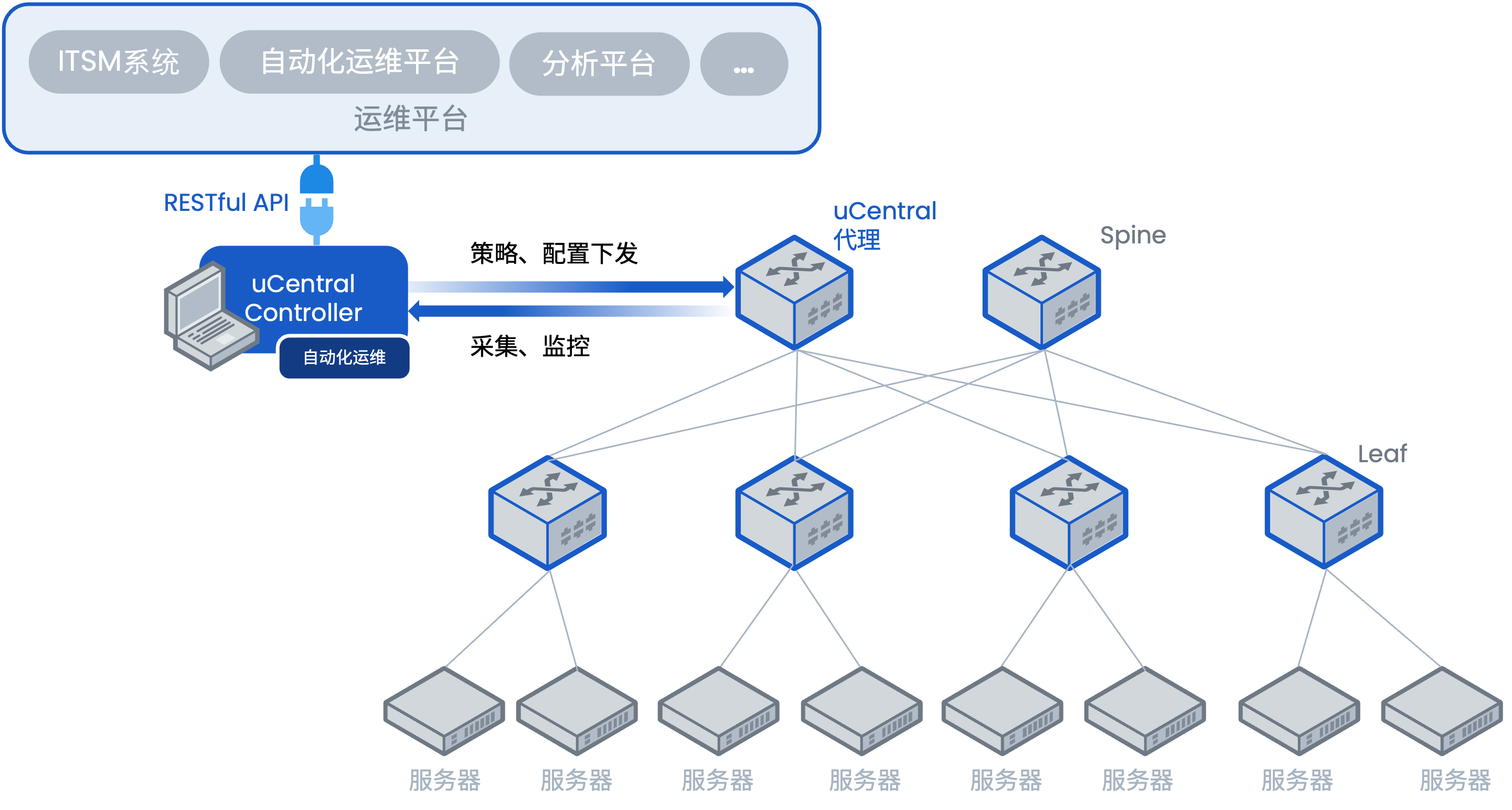
园区交换机搭载了基于开源SONiC深度开发的AsterNOS网络操作系统。这意味着网络工程师不再受限于厂商的私有命令行,可以通过容器化环境、可编程接口实现对VRF策略的精细化管控。无论是通过云园区控制器实现30分钟极速业务开通,还是通过API对接第三方运维平台,开放网络架构都为多租户VRF隔离场景提供了前所未有的灵活性。
想让你的网络架构具备运营商级的稳定性吗? 立即联系我们的网络专家,获取针对你园区环境的定制化VRF部署方案!