800G光模块选型指南
近期文章
800G实现之路并非一蹴而就,而是建立在400G的坚实技术基础之上,并通过持续的创新来应对新的挑战。本文将从技术驱动、核心突破、部署挑战及未来展望等方面,勾勒出800G实现的技术演进路径。
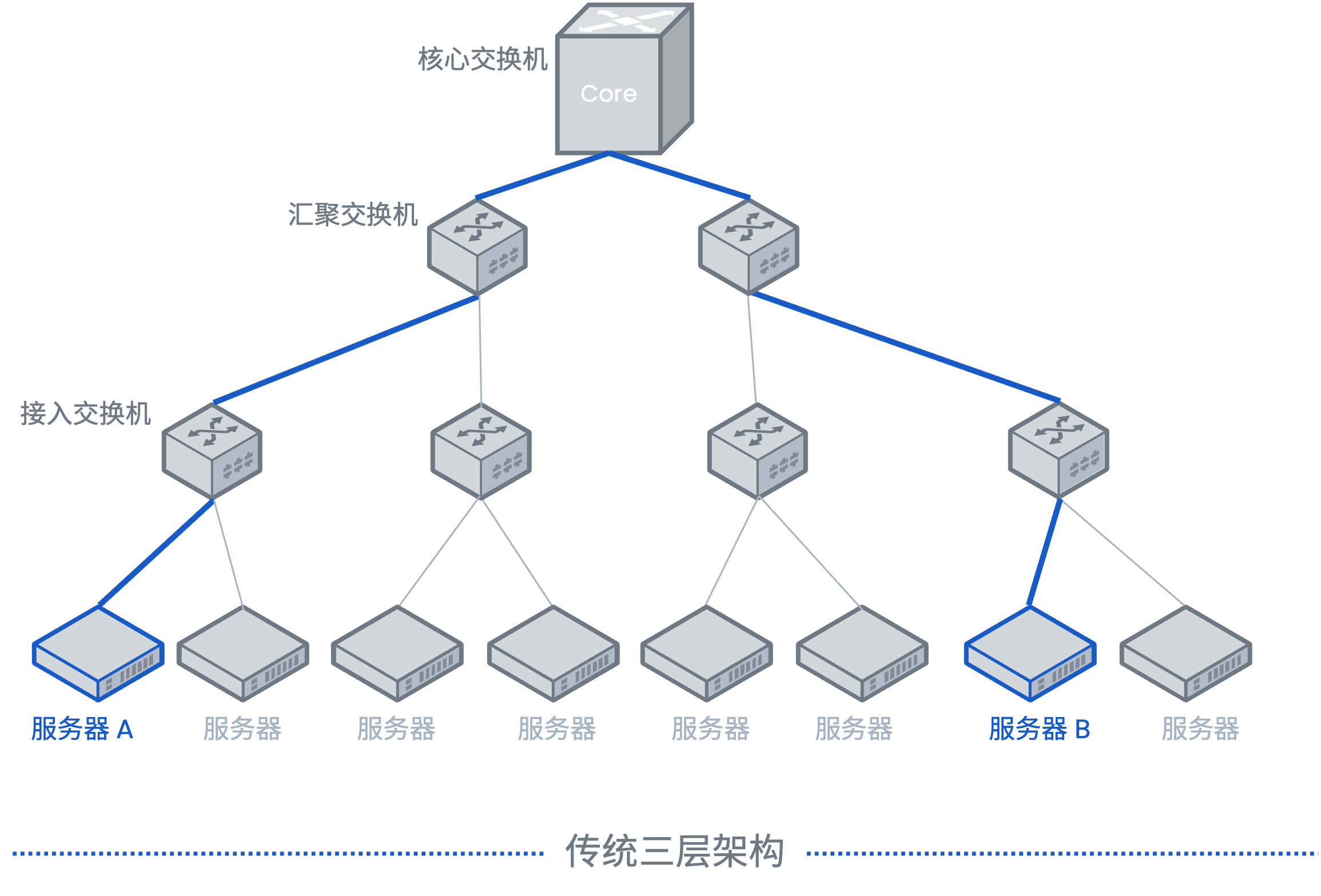
演进基石:400G为800G铺平道路
800G并非一次革命性的跳跃,而是400G技术的自然演进与扩展。其技术根基深深植根于当前400G的成熟体系。
- PAM4编码的延续与强化:400G广泛应用的四级脉冲幅度调制(PAM4)技术,通过在每个信号符号中承载2比特信息,将NRZ编码的效能翻倍,是实现单通道50G/100G速率的关键。800G将继续沿用并深化PAM4技术,将单通道速率提升至100G,从而通过8个通道实现8x100G=800G的总速率。对PAM4信号更高效的调制和更精确的信号完整性管理,是演进的核心。
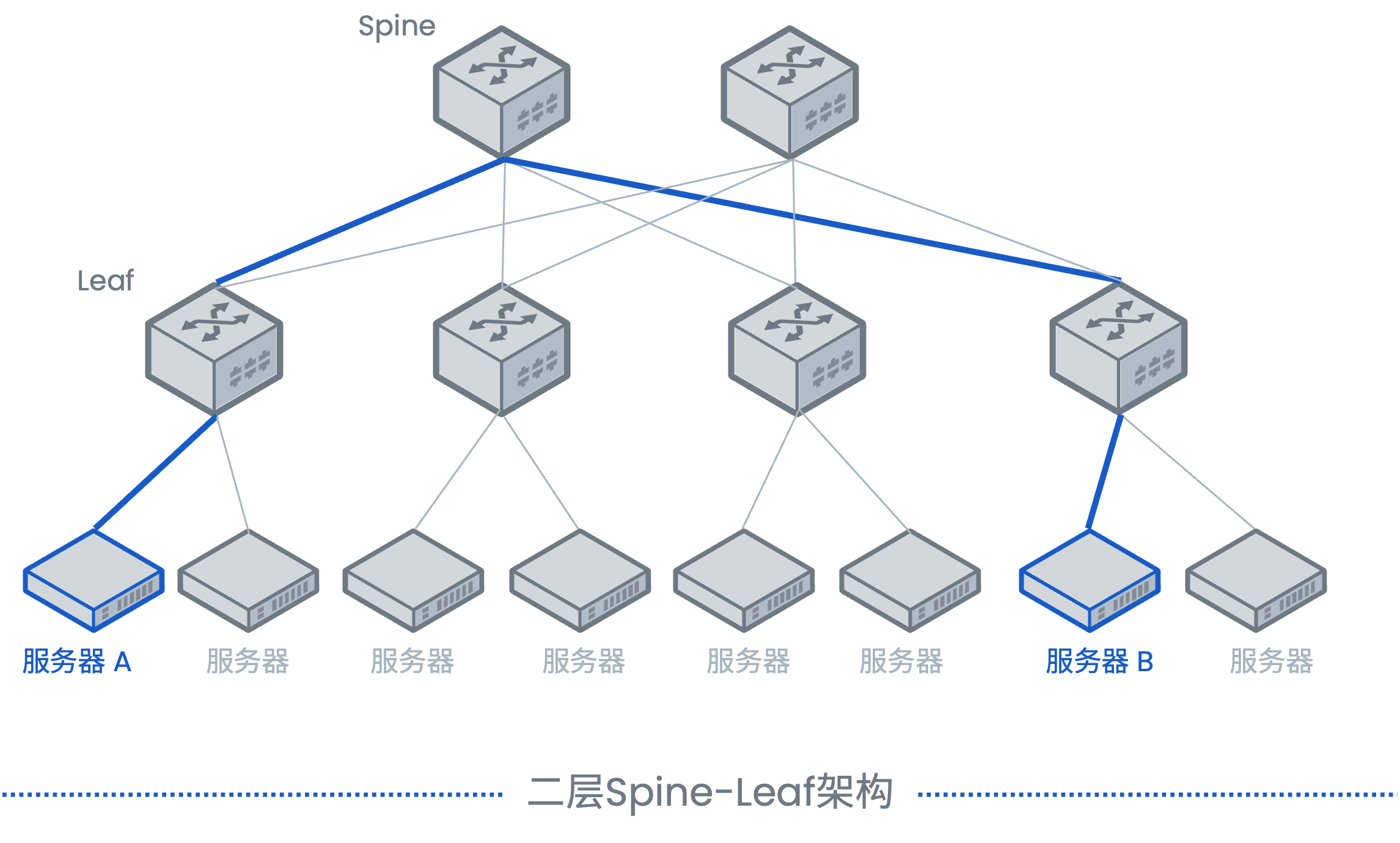
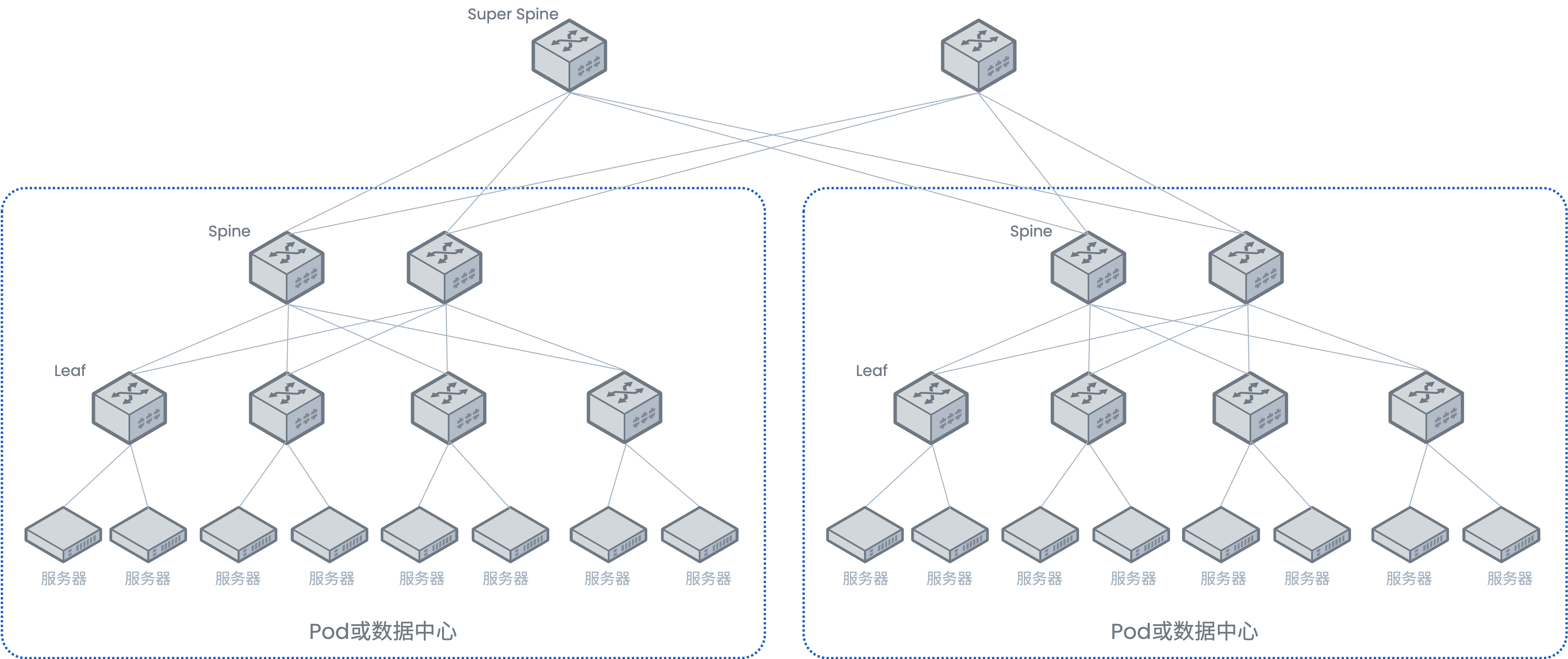
- 可插拔收发器架构的演进:400G时代成熟的QSFP-DD(双密度)和OSFP(可插拔)等封装形式,为800G提供了物理基础。这些高密度、可插拔的接口标准,通过增加通道数量或提升单通道速率,能够平滑地支持800G光模块的设计,保护了用户在基础设施上的投资。
- 光纤基础设施的提前布局:800G及未来的1.6T应用将推动对Base-16 MTP连接的需求。这意味着,当前为400G部署的、支持Base-8或Base-12的布线系统,需要为更高速率做好向更高光纤芯数升级的准备。提前规划高性能OM4/OM5多模或OS2单模光纤布线,是通往800G的必经之路。
核心突破:800G实现的技术关键
在400G的基础上,实现800G仍需一系列关键技术的突破。了解800G收发器的核心技术参数,下面这个表格汇总了主流类型的核心规格。
| 收发器 | 标准 | 接口类型 | 扇出支持 | 光纤类型 | 传输距离 | 光纤芯数 | 连接器 |
|---|---|---|---|---|---|---|---|
| 800G-SR8 | IEEE 802.3ck及相关MSA | QSFP-DD800, OSFP | 支持 | OM3/OM4/OM5(多模) | ≤ 100m (OM4/OM5) | 16 (8Tx + 8Rx) | 16F/24F MTP |
| 800G-DR8 | IEEE 802.3ck及相关MSA | QSFP-DD800, OSFP | 支持 | 单模 | 500m | 8(4Tx+4Rx) | 12F/16F MTP |
| 800G-2FR4/FR4 | IEEE 802.3ck及相关MSA | QSFP-DD800, OSFP | 支持 | 单模 | 2km | 2(1Tx+1Rx) | 双工LC/单芯的CS |
| 800G-LR4 | IEEE 802.3ck及相关MSA | QSFP-DD800, OSFP | 支持 | 单模 | 10km | 2(1Tx+1Rx) | 双工 LC |
| 800G ZR/ZR+ | OIF Implementation Agreements | QSFP-DD | 支持 | 单模 | 80km-120km以上(ZR+Pro) | 2(1Tx+1Rx) | 双工 LC |
核心技术与标准
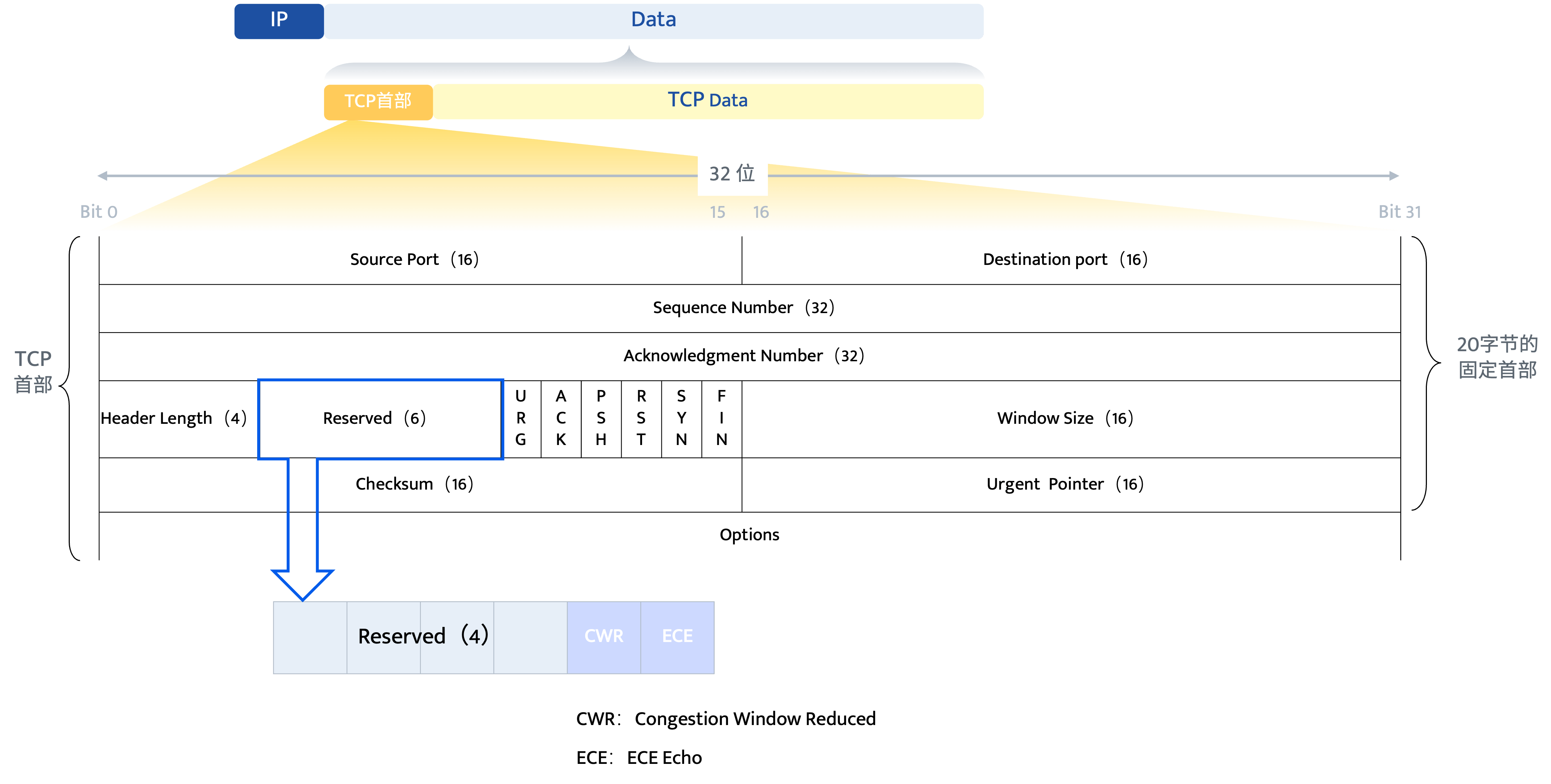
800G以太网由 IEEE 802.3ck工作组标准化,其物理层基础建立在 PAM4(4级脉冲幅度调制)技术上。PAM4每个符号周期可传输2个比特,使单通道100Gbps的速率得以实现,从而聚合达到800G的总带宽。
在硬件机械规格和互联互通性方面,则由多个MSA组织制定关键规范。其中,QSFP-DD800外形是当前主流,它在QSFP-DD基础上增强,优化信号完整性和散热,并保持向后兼容性。OSFP外形略大,散热能力更优,为800G及更高速率设计。
对于超长距离传输,OIF制定的 800G ZR标准采用相干光学技术,实现在一对光纤上传输800G信号至80公里以上 。
接口类型与扇出支持
800G光模块的物理接口和连接器选择与传输方案紧密相关。
- 并行光学接口:如SR8和DR8,采用多根光纤并行传输。SR8使用16芯多模光纤,适用于极短距离;DR8使用8芯单模光纤,传输距离可达500米。它们通常使用MPO多芯连接器。
- 波分复用接口:如FR4和LR4,采用波分复用技术将多个波长信道复用到一对光纤中传输,极大节省光纤资源。它们使用常见的双工LC连接器,传输距离分别为2公里和10公里 。
- 扇出功能:这是800G收发器提升网络灵活性的关键特性。它允许将一个高速端口拆分为多个低速端口使用,实现网络资源的按需分配和平滑升级 。
如何选择适合的800G光模块?
1、数据中心内部(短距)
- 机柜内或相邻机柜(≤100米):优先考虑800G SR8(多模)或超低功耗的800G LPO AOC(多模)。若布线受限,也可使用800G AOC有源光缆。
- 机房内不同模块间(500米):800G DR8 或 800G DR4 是经济高效的选择。
2、数据中心园区互联(中长距)
- 2公里距离:800G FR4(双纤双向)或 800G DR8+ 都能满足要求。
- 10公里距离:可以选择 800G DR8++ 模块。
3、数据中心互连/DCI(长距):对于40公里甚至80公里的超长距离互联,则需要采用800G相干光模块技术。
未来展望:超越800G,迈向1.6T
800G只是一个驿站。技术演进的下一个目标是1.6T(1600G)。其实现路径可能有两种
- 通道数量翻倍:在800G的8通道基础上,通过16个100G通道实现1.6T,但这将需要更复杂的32芯光纤连接,挑战难度可想而知。
- 单通道速率再提升:开发下一代200G PAM4 per lane技术,通过8个200G通道实现1.6T。这将是对芯片和材料科学的终极考验。
在800G数据中心时代,RoCE交换机以其卓越的设计,完美呼应了技术演进的核心需求。我们基于QSFP112-DD可插拔的模块架构,为客户提供从400G平滑升级的路径。通过强化PAM4信号完整性管理,确保单通道100G的稳定性能。