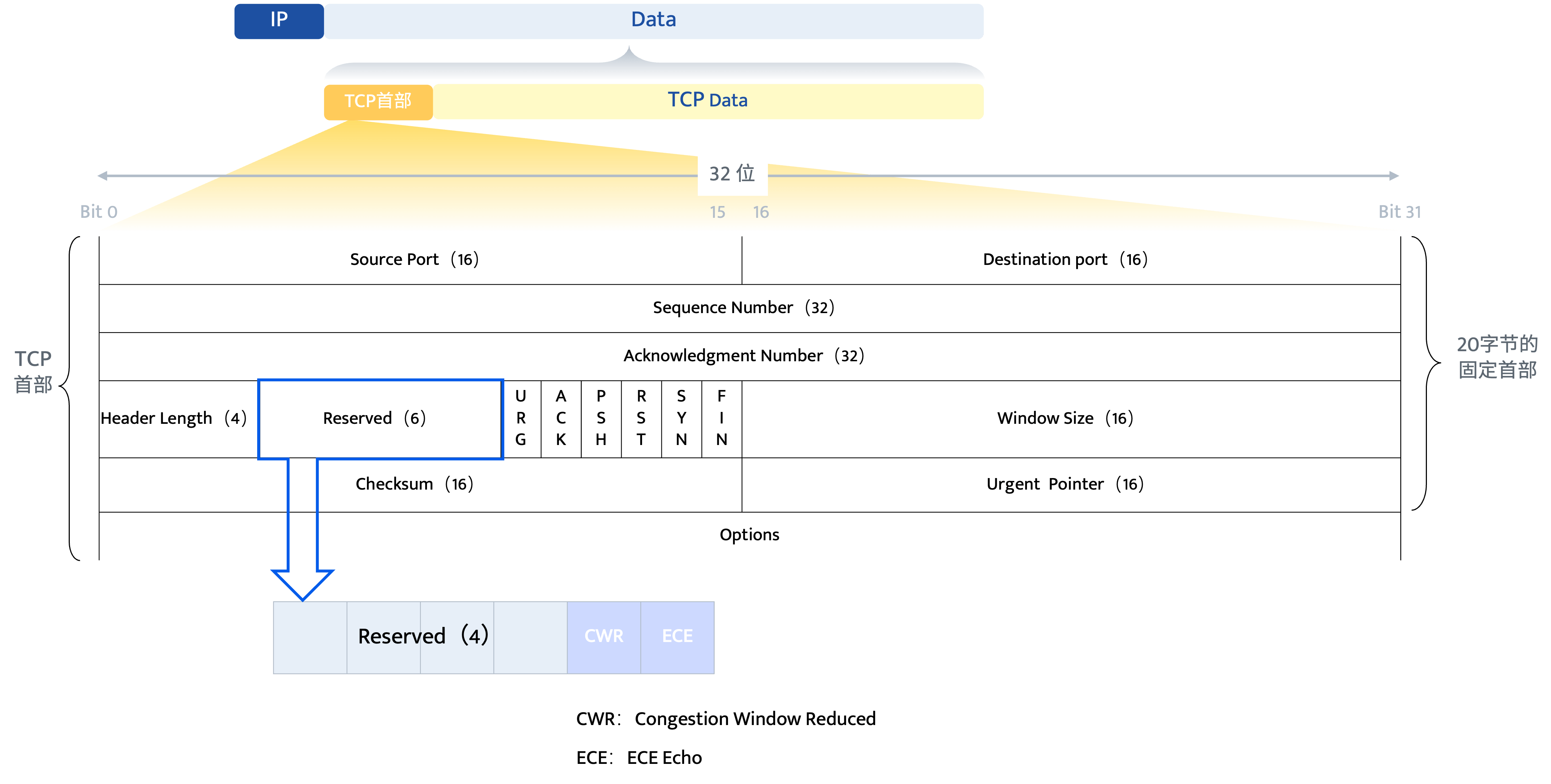
云网融合:如何为OpenStack设计高性能、可扩展的物理网络
近期文章
简单来说,OpenStack 是一个开源的云计算管理平台项目,它允许你使用一套软件来构建和管理你自己的私有云或公有云。
你可以把它想象成开源的、可以自己掌控的 Amazon Web Services(AWS) 或 Microsoft Azure。它提供了一系列组件来协调和管理数据中心内大量的计算、存储和网络资源,并将所有这些资源以一个云的形式提供给用户。

什么是OpenStack?
想象一下,一个现代化的数据中心就像一个巨大的“硬件仓库”:
- 计算资源:成千上万的服务器(CPU和内存)
- 存储资源:硬盘、固态硬盘组成的存储池
- 网络资源:交换机、路由器构成的复杂网络
OpenStack 就像是这个仓库的 “超级管理员和自动化控制系统”。它不会直接去搬动服务器或插拔网线,而是通过软件来抽象化资源,把这些物理硬件变成可以按需分配的逻辑资源池。用户通过一个网页(控制台)或API就能申请一台虚拟机、一块硬盘或一个网络,而无需知道这台虚拟机具体运行在哪台物理服务器上。高效且智能地将用户请求的资源分配给底层的物理设备。
特点:
- 开源开放:代码完全公开,任何人都可以免费使用、修改和分发。这避免了供应商锁定。
- 模块化架构:OpenStack 不是单一的巨大软件,而是由许多独立的、但又相互关联的组件(服务)构成的。
- 大规模可扩展:设计之初就是为了管理成千上万台服务器,可以轻松地通过增加节点来扩展云的能力。
- 灵活性高:支持多种虚拟化技术(如 KVM, VMware, Xen 等)、存储后端和网络技术。
Openstack 项目组件(服务)
OpenStack 项目包含很多组件,其中最核心和常用的有:
| 组件名称 | 项目代号 | 主要功能 |
|---|---|---|
| 计算服务 | Nova | 负责管理和管理虚拟机的整个生命周期(创建、调度、销毁)。它是云的核心“发动机”。 |
| 镜像服务 | Glance | 存储和管理虚拟机镜像模板(如操作系统模板)。用户创建虚拟机时从此处选择镜像。 |
| 对象存储 | Swift | 提供海量、可扩展的、冗余的分布式对象存储。用于存储非结构化的数据,如图片、文档、备份等。 |
| 块存储服务 | Cinder | 为虚拟机提供持久化的块存储设备(类似硬盘)。可以动态地挂载和卸载。 |
| 网络服务 | Neutron | 管理云环境的网络资源,为虚拟机提供网络连接,如创建私有网络、路由器、防火墙、负载均衡等。 |
| 身份认证服务 | Keystone | 为所有 OpenStack 服务提供统一的身份验证和授权管理。是所有服务的“守门人”。 |
| 控制面板 | Horizon | 提供一个基于 Web 的图形化界面,让管理员和用户可以通过点击来管理和使用云资源。 |
支撑 OpenStack 的物理网络架构
OpenStack 的本质是通过软件将大量物理服务器资源池化。如果把这些服务器比作一个个独立的“城市”,那么物理网络就是连接这些城市的 “高速公路系统”。一个设计拙劣的公路系统会导致交通拥堵、事故频发,同样,一个糟糕的物理网络设计会导致云平台性能瓶颈、服务中断和运维噩梦。
网络流量类型
OpenStack 云最终需要运行在物理硬件上,物理网络的架构设计直接决定了云平台的性能、可靠性、可扩展性和安全性。
- 管理网络: 用于 OpenStack 各服务组件内部的通信。要求高可靠性。
- 数据网络: 也称为租户网络或业务网络,承载虚拟机之间的数据流量。要求高带宽和低延迟。
- 外部网络: 用于虚拟机访问互联网或对外提供服务。通常需要公网 IP。
- 存储网络: 专门用于 Cinder 和 Swift 的存储流量,避免 I/O 操作影响其他网络性能。
- IPMI 网络:用于服务器的带外管理,进行远程开机、关机和监控。这是一个独立的物理网络,通常与业务网络隔离。
物理网络架构
这里主要展开说传统三层架构及Spine-Leaf 架构
传统三层架构(经典核心-汇聚-接入)
1、拓扑结构:
- 核心层:网络的高速骨干,专注于快速的数据包转发和连接多个汇聚层。要求极高的可靠性和吞吐量。
- 汇聚层:承上启下,提供策略实施(如路由、安全、QoS)、VLAN间路由、广播域控制等功能。
- 接入层:连接服务器和终端设备,提供端口密度,进行基本的VLAN划分和二层交换。
2、与OpenStack的结合
- 所有计算、存储、网络节点都连接到接入层交换机。
- 通过在不同层级配置VLAN,来逻辑隔离管理、数据、存储等流量。
3、适用场景:中小型OpenStack私有云、开发和测试环境。
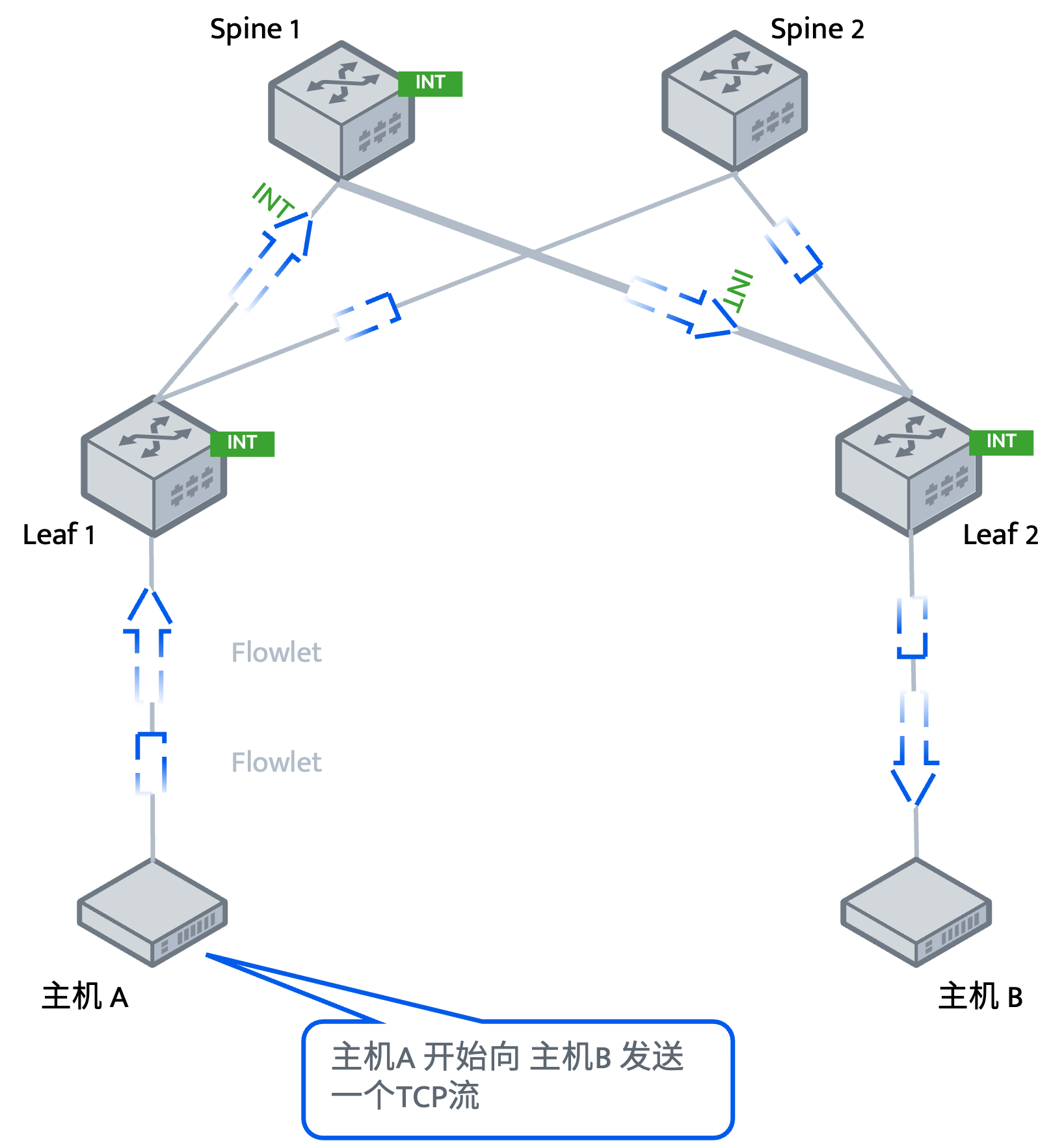
Spine-Leaf架构(CLOS架构)
这是现代大型数据中心和云环境的标配,为东西向流量和高密度计算而设计。
1、拓扑结构
- Leaf层(叶交换机):作为接入层,每一个 Leaf交换机都连接所有的服务器。
- Spine层(脊交换机):作为核心层,每一个 Spine交换机都连接到每一个 Leaf交换机。Spine交换机之间不互连。
- 形成一个全互联的Fabric网络。
2、与OpenStack的结合
- 计算、存储节点连接到Leaf交换机。
- 网络节点的外部网络接口可能连接到边界Leaf或专门的服务Leaf。
- 物理网络(Underlay)采用简单的IP路由(如OSPF、BGP),为Overlay网络(如VXLAN)提供无阻塞的IP承载网。
3、适用场景:中大型到超大规模OpenStack云环境,对东西向流量性能要求高的场景(如NFV、大数据分析)。
构建高性能、灵活可扩展的云数据中心网络
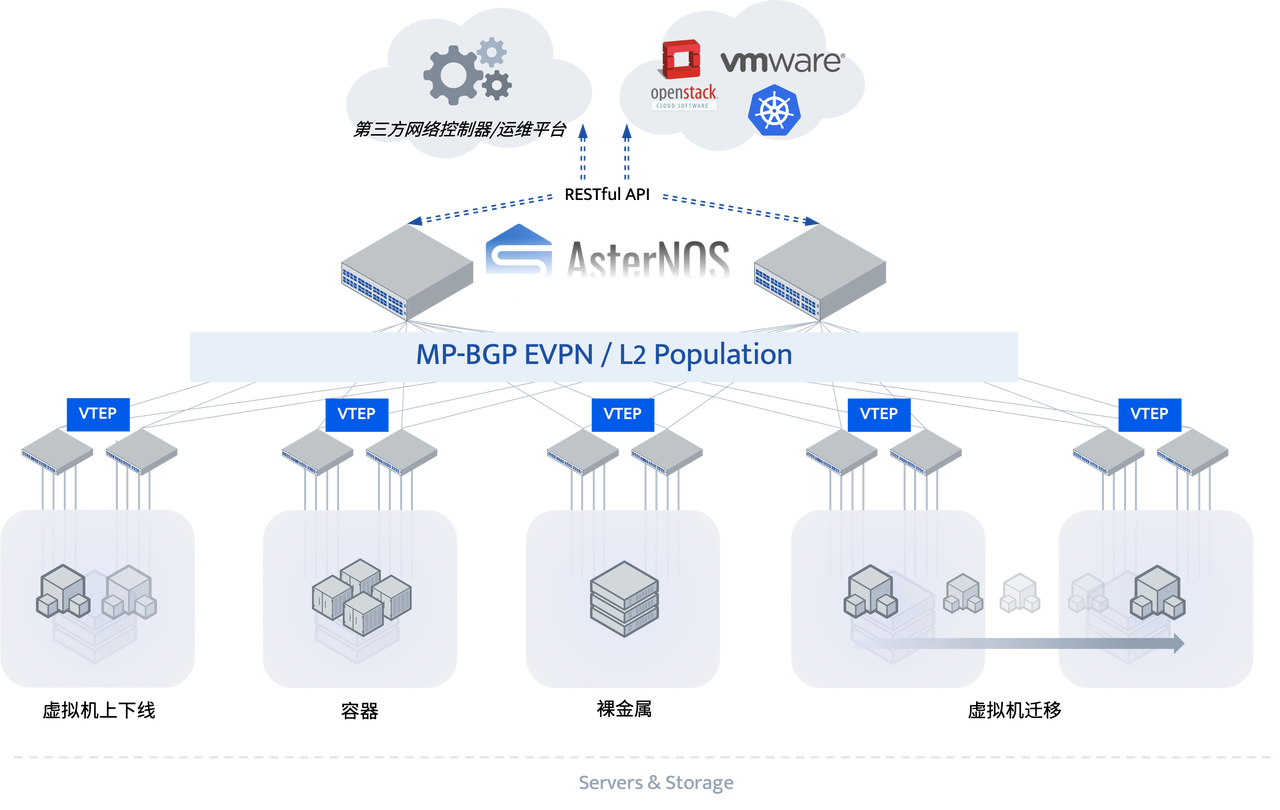
基于开放SONiC的AsterNOS与第三方云网控制器深度融合,通过VXLAN、BGP-EVPN、MC-LAG等技术与盒式设备,构建高可靠、扁平化的云数据中心网络,在实现自动化配置、图形化运维和灵活扩展的同时,显著降低TCO,助力用户无缝对标一线云架构。