云数据中心交换机向400G过渡,面临着哪些机遇与挑战?
更多相关内容
2021 年,云数据中心交换机的销售额以两位数增长,而非云领域的销售额则以中等个位数增长。到 2026 年,全球数据中心交换机市场的价值预计将达到 199 亿美元,年复合增长率为 5.6%。近年来,数据中心交换机市场的云计算部分预计将以几乎是非云计算市场两倍的速度扩张。以下是促成如此强劲的市场预测的主要因素:
- 持续的供应链问题推动了冲动消费
- 各行业数字化转型速度加快
- AI的等新兴业务驱动下,网络基础设施建设进入一轮扩张周期
数据中心交换机市场的美好前景固然带来了巨大的机遇,但在向400G过渡的过程中也面临着挑战。
400G交换机的市场机遇
- 芯片平台的多样性: 芯片多样性是过去几年数据中心行业的主题,这也给半导体巨头 Broadcom 带来了一定的压力。
- 智能设备: 智能设备的技术进步推动了对复杂连接和增强型网络解决方案的需求。预计这一趋势将推动芯片在数据中心服务器中的集成,从而为全球数据中心交换机市场提供利润丰厚的增长机会。
400G交换机的市场挑战
- 数据中心运营成本: 数据中心需要考虑当地的能源价格,因为能源成本在整体运营成本中占很大比重。对于云服务提供商和超大规模数据中心来说,能源成本本身就会令人望而却步。此外,机器维护和人工等额外运营费用也阻碍了市场的扩张。
- 复杂的架构: 由于云计算、服务器虚拟化、计算和存储技术的发展,数据中心架构变得越来越复杂。虽然高性能和更高带宽的数据中心交换机可以处理巨大的工作负载,但在各种架构中实施高带宽解决方案仍面临诸多挑战。
- 此外,在数据中心使用的各种技术之间建立兼容性也变得十分困难,这可能会导致大量额外开支,并阻碍新的部署。

星融元推出的32x400G规格的低时延交换机在公有云、私有云等场景下都有着不俗的性能表现,可为云数据中心多业务融合、高性能计算、大数据分析、高频交易等多种业务场景提供卓越的网络服务。
除了400G规格以外,CX-N系列还有以下型号以供组网选择:
| 型号 | 业务接口 | 交换容量 | 包转发率 | |
|---|---|---|---|---|
| CX864E-N | 64 x 800GE OSFP,2 x 10GE SFP+ | 102.4Tbps | 28700Mpps | |
| CX732Q-N | 32 x 400GE QSFP-DD/QSFP56/QSFP28/QSFP+, 2 x 10GE SFP+ | 25.6Tbps | 7600Mpps | |
| CX664D-N | 64 x 200GE QSFP56/QSFP28/QSFP+, 2 x 10GE SFP+ | 25.6Tbps | 7600Mpps | |
| CX564P-N | 64 x 100GE QSFP28/QSFP+, 2 x 10GE SFP+ | 12.8Tbps | 7600Mpps | |
| CX532P-N | 32 x 100GE QSFP28/QSFP+, 2 x 10GE SFP+ | 6.4Tbps | 6300Mpps | |
| CX308P-48Y-N | 48 x 25GE SFP28/SFP+, 8 x 100GE QSFP28/QSFP+ | 4.0Tbps | 2600Mpps | |
CX-N系列预装的网络操作系统为AsterNOS(基于SONiC),具备高度的功能定制和可扩展性,帮助实现网络运维自动化。对比社区版SONiC,AsterNOS在以下方面做了大量功能补充和增强:
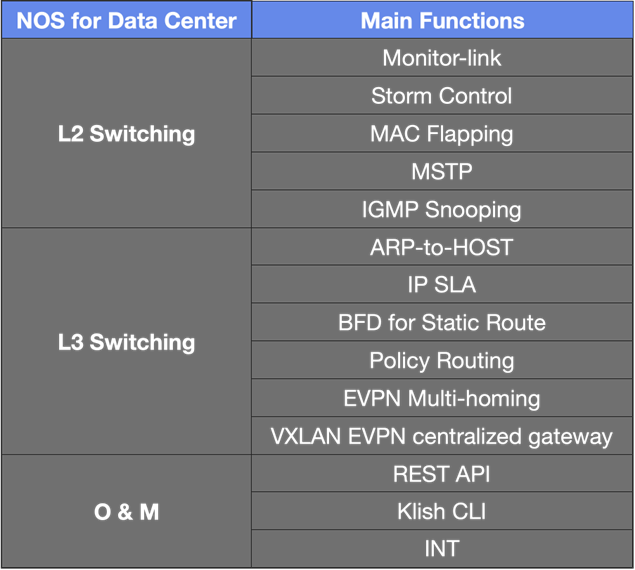
值得一提的是,与MC-LAG 解决方案相比,EVPN Multi-homing不仅能更好地解决可扩展性和流量负载平衡方面的限制,还能提高 VXLAN 接入端的可靠性。
更多有关EVPN Multi-homing的介绍:
MC-LAG还是Multi-Homing?探讨网络通信高可用性的新选择
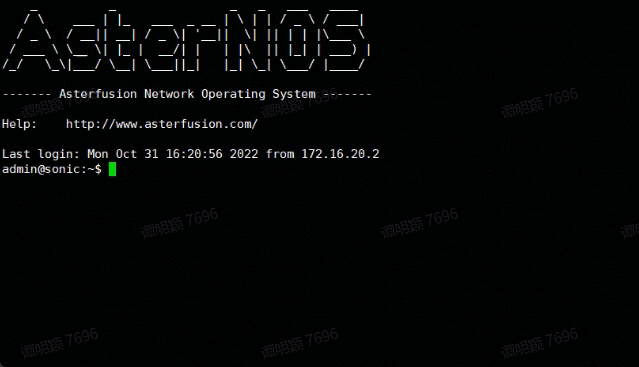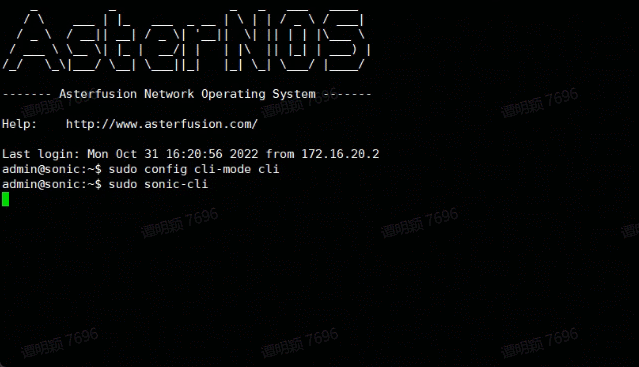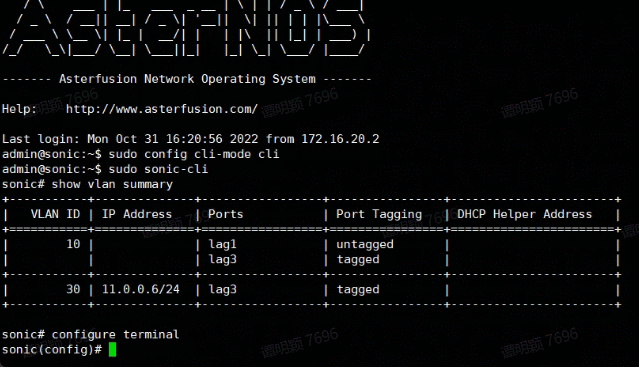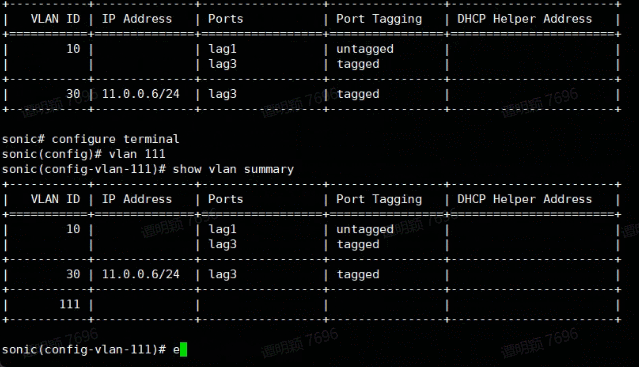
此外,AsterNOS 完全支持类似 Cisco 的命令行模式,大大降低了运维端的学习成本。
下面是我们在使用 AserNOS 的交换机上演示以 不同的命令行模式(Klish/Bash)配置 VLAN。
欢迎关注微信公众号“星融元Asterfusion”,获取更多技术分享和最新产品动态。

-图1.png)
-图2.png)
-图3-1024x220.png)

-图1.png)
-图2.png)
-图3-1024x389.png)
-图4.png)
 NetDevOps对网络提出了软件编程、软件定义、按需定制、运营优化的要求,而开放网络的理念与架构方法恰恰能够满足这些要求。NOS作为网络设备的“灵魂”,NetDevOps要求NOS从封闭、黑盒的体系向开放、透明的体系演进。
NetDevOps对网络提出了软件编程、软件定义、按需定制、运营优化的要求,而开放网络的理念与架构方法恰恰能够满足这些要求。NOS作为网络设备的“灵魂”,NetDevOps要求NOS从封闭、黑盒的体系向开放、透明的体系演进。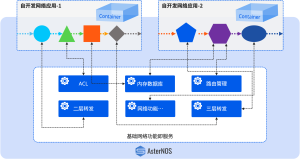
-图1-1024x486.png)

-图1.png)
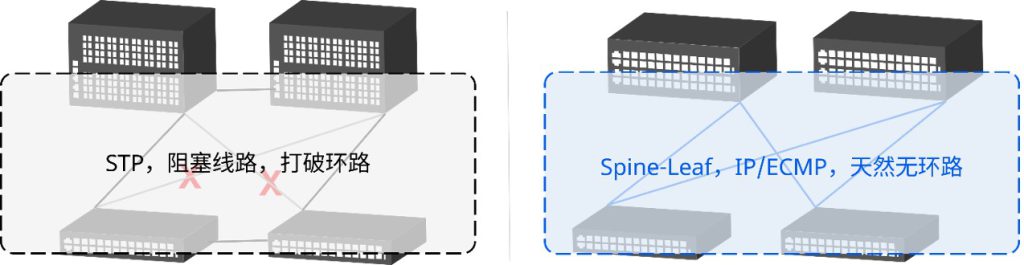
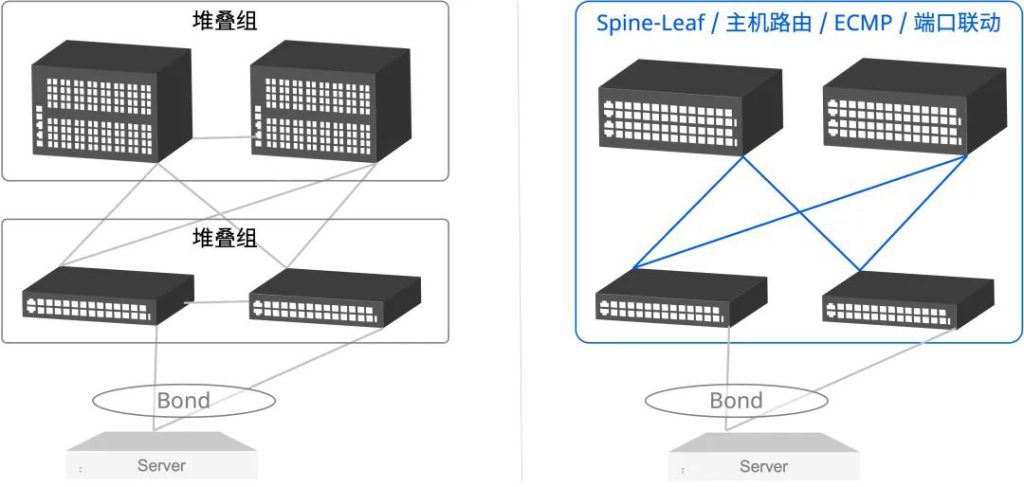
 随着数字化转型的需求变得日益明显,企业也需要重新考虑自身的网络基础设施。
随着数字化转型的需求变得日益明显,企业也需要重新考虑自身的网络基础设施。-图2-1024x471.png)

-图1-1024x504.png)
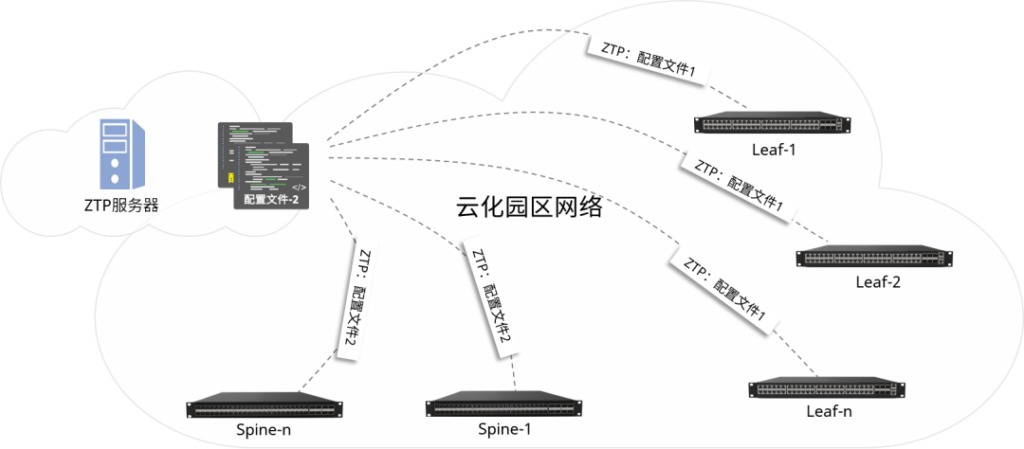
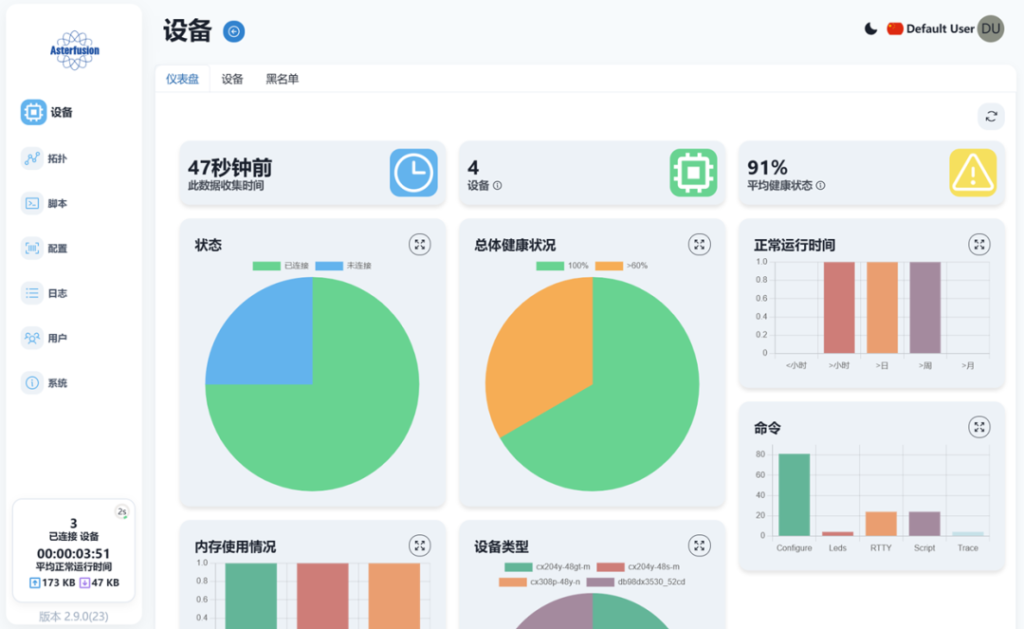
-图2-1024x422.png)

-图1-285x300.jpeg)
