[root@controller ~]# mysql -uroot -p
MariaDB [(none)]> CREATE DATABASE zun;
MariaDB [(none)]> GRANT ALL PRIVILEGES ON zun.* TO 'zun'@'localhost' \
IDENTIFIED BY 'ZUN_PASS';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON zun.* TO 'zun'@'%' \
IDENTIFIED BY 'ZUN_PASS';
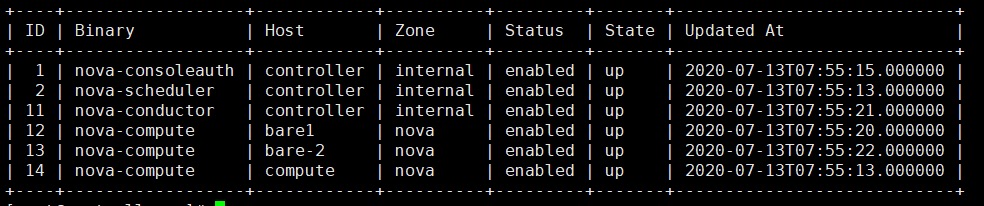
[root@controller ~]# openstack compute service list
7.4 验证Endpoint
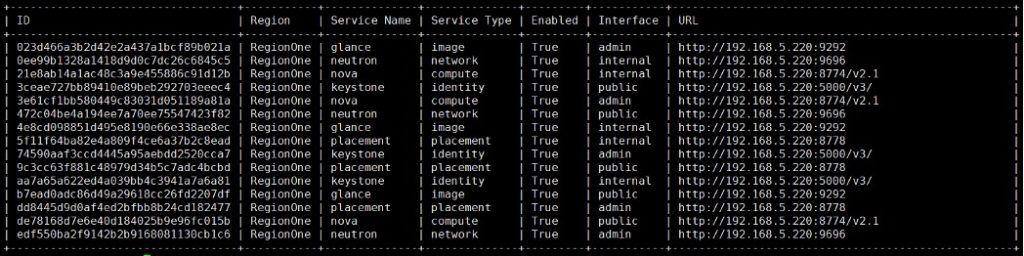
[root@controller ~]# openstack endpoint list
7.5 验证Neutron
[root@controller ~]# openstack network agent list
8 部署Ironic(控制节点、Bare Metal)
8.1 MySQL中创建库和权限(控制节点)
在数据库中创建Ironic库,并且授予用户访问库的权限。
[root@localhost ~]# mysql -uroot -p
MariaDB [(none)]> CREATE DATABASE ironic CHARACTER SET utf8;
MariaDB [(none)]> GRANT ALL PRIVILEGES ON ironic.* TO 'ironic'@'localhost' identified by 'tera123';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON ironic.* TO 'ironic'@'%' identified by 'tera123';
[root@controller ~]# glance image-create --name deploy-vmlinuz --visibility public --disk-format aki --container-format aki < coreos_production_pxe.vmlinuz
[root@controller ~]# glance image-create --name deploy-initrd --visibility public --disk-format ari --container-format ari < coreos_production_pxe_image-oem.cpio.gz
[root@controller ~]# openstack server create --flavor my-baremetal-flavor \
--nic net-id=3793d3bd-5a26-4dd2-a637-007b8ed7c2b0 \
--image 08e111be-d256-4c43-bb07-ea65a1219f77 test
13.2 验证结果
[root@controller ~]# openstack server list
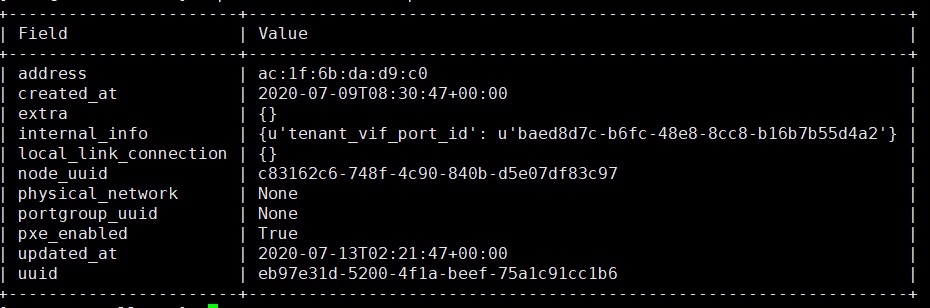
[root@controller ~]# openstack baremetal port show eb97e31d-5200-4f1a-beef-75a1c91cc1b6
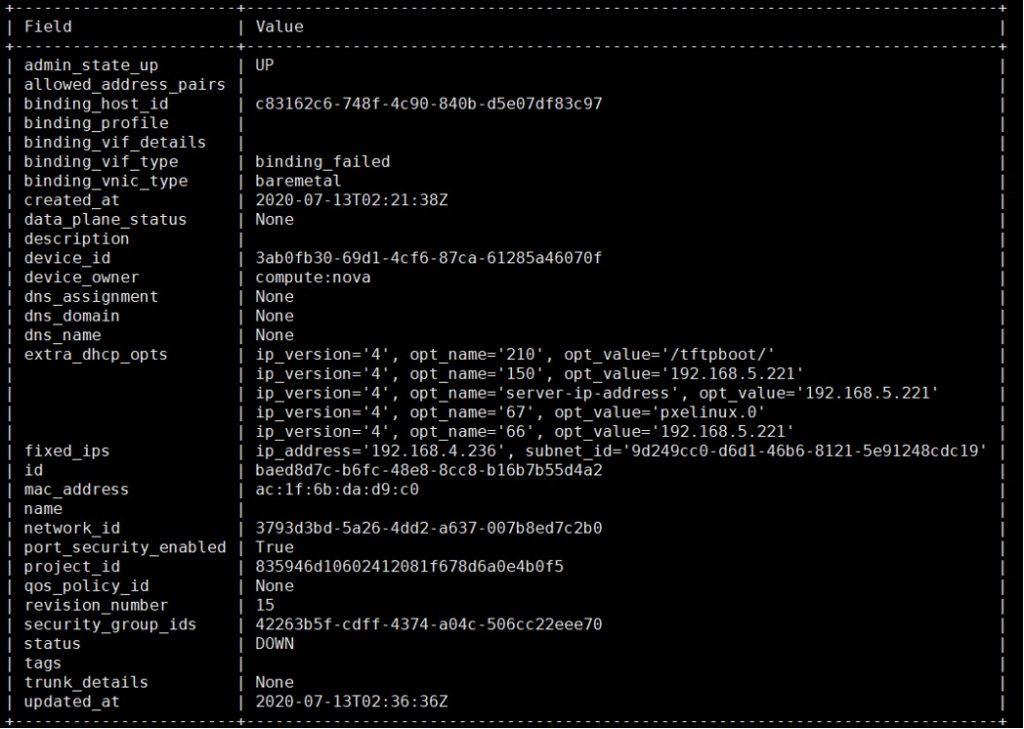
[root@controller ~]# openstack port show baed8d7c-b6fc-48e8-8cc8-b16b7b55d4a2
[root@controller ~]# ssh root@192.168.4.236
14 常见问题
14.1 获取swift_temp_url报错
MissingAuthPlugin: An auth plugin is required to determine endpoint URL。因为我们选择了Direct的部署方式,裸机服务器的IPA会从Swift Object Storage将User Image拉到本地,在裸机端完成镜像注入,但是我们环境中没有部署Swift,所以需要改为ISCSI的部署方式。
PXE-E51: No DHCP or proxyDHCP offers were received。这是在为裸机MAC地址分配IP地址时发生的报错,主要原因是因为DHCP服务器与裸机网络不通,需要确保DHCP服务器与裸机之间可以通信。检查Neutron的配合文件,测试Provisioning网络的可用性。
[root@bare ~]# vi /etc/ironic/ironic.conf
[neutron]
cleaning_network=3793d3bd-5a26-4dd2-a637-007b8ed7c2b0
cleaning_network_security_groups=42263b5f-cdff-4374-a04c-506cc22eee70
provisioning_network=3793d3bd-5a26-4dd2-a637-007b8ed7c2b0
provisioning_network_security_groups=42263b5f-cdff-4374-a04c-506cc22eee70
14.6 获取Deploy Image报错
ERROR while preparing to deploy to node : MissingAuthPlugin: An auth plugin is required to determine endpoint URL,这是一个Bug。获取Image的时候MissingAuthPlugin是因为没有配置Glance。
[root@localhost ~]# mysql -uroot -p
MariaDB [(none)]> create database keystone;
MariaDB [(none)]> GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'localhost' identified by 'tera123';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'%' identified by 'tera123';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'openstack' identified by 'tera123';
[root@localhost ~]# openstack project create --domain default \
--description "Service Project" service
[root@localhost ~]# openstack role create user
8.7 验证Keystone
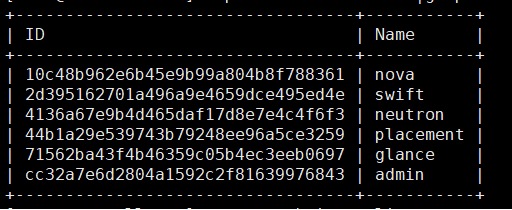
[root@localhost ~]# openstack user list
+----------------------------------------------------------------+--------------+
| ID | Name |
| 57341d3e37eb4dc997624f9502495e44 | admin |
+-----------------------------------------------------------------+--------------+
[root@localhost ~]# mysql -uroot -p
MariaDB [(none)]> create database glance;
MariaDB [(none)]>GRANT ALL PRIVILEGES ON glance.* TO 'glance'@'localhost' identified by 'tera123';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON glance.* TO 'glance'@'%' identified by 'tera123';
MariaDB [(none)]>GRANT ALL PRIVILEGES ON glance.* TO 'glance'@'openstack' identified by 'tera123';
[root@localhost ~]# mysql -uroot -p
MariaDB [(none)]> create database nova_api;
MariaDB [(none)]> create database nova;
MariaDB [(none)]> create database nova_cell0;
MariaDB [(none)]> create database placement;
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'localhost' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'%' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'openstack' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'localhost' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'%' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'openstack' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'localhost' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'%' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'openstack' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON placement.* TO 'placement'@'localhost' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON placement.* TO 'placement'@'%' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON placement.* TO 'placement'@'openstack' identified by 'tera123';
[root@localhost ~]# vi /etc/httpd/conf.d/00-nova-placement-api.conf
Listen 8778
<VirtualHost *:8778>
<Directory /usr/bin>
<IfVersion >= 2.4>
Require all granted
</IfVersion>
<IfVersion < 2.4>
Order allow,deny
Allow from all
</IfVersion>
</Directory>
WSGIProcessGroup nova-placement-api
WSGIApplicationGroup %{GLOBAL}
WSGIPassAuthorization On
WSGIDaemonProcess nova-placement-api processes=3 threads=1 user=nova group=nova
WSGIScriptAlias / /usr/bin/nova-placement-api
<IfVersion >= 2.4>
ErrorLogFormat "%M"
</IfVersion>
ErrorLog /var/log/nova/nova-placement-api.log
#SSLEngine On
#SSLCertificateFile ...
#SSLCertificateKeyFile ...
</VirtualHost>
Alias /nova-placement-api /usr/bin/nova-placement-api
<Location /nova-placement-api>
SetHandler wsgi-script
Options +ExecCGI
WSGIProcessGroup nova-placement-api
WSGIApplicationGroup %{GLOBAL}
WSGIPassAuthorization On
</Location>
10.6 同步数据库
导入nova-api、nova、cell0、placement库SQL。
[root@localhost ~]# su -s /bin/sh -c "nova-manage api_db sync" nova
[root@localhost ~]# su -s /bin/sh -c "nova-manage cell_v2 map_cell0" nova
[root@localhost ~]# su -s /bin/sh -c "nova-manage cell_v2 create_cell --name=cell1 --verbose" nova
[root@localhost ~]# su -s /bin/sh -c "nova-manage db sync" nova
[root@localhost ~]# openstack compute service list --service nova-compute
[root@localshot ~]# su -s /bin/sh -c "nova-manage cell_v2 discover_hosts --verbose" nova
Found 2 cell mappings.
Skipping cell0 since it does not contain hosts.
Getting computes from cell 'cell1': 54e6c270-7390-4390-8702-02b72874c5a7
Checking host mapping for compute host 'compute': 39d80423-6001-4036-a546-5287c1e93ec5
Creating host mapping for compute host 'compute': 39d80423-6001-4036-a546-5287c1e93ec5
Found 1 unmapped computes in cell: 54e6c270-7390-4390-8702-02b72874c5a7
OpenStack Networking plug-ins and agents:OpenStack通用代理是L3,DHCP和插件代理
12.1 MySQL中创建库和权限
在数据库中创建Neutron用户,并且授予用户访问库的权限。
[root@localhost ~]# mysql -uroot -p
MariaDB [(none)]> create database neutron;
MariaDB[(none)]>GRANT ALL PRIVILEGES ON neutron.* TO 'neutron'@'localhost' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON neutron.* TO 'neutron'@'%' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON neutron.* TO 'neutron'@'openstack' identified by 'tera123';
ERROR oslo.messaging._drivers.impl_rabbit [-] [94fc1201-373b-451f-a9e2-46fc81b5de20] AMQP server on controller:5672 is unreachable: [Errno 111] ECONNREFUSED. Trying again in 24 seconds.: error: [Errno 111] ECONNREFUSED
ERROR oslo_db.sqlalchemy.engines [-] Database connection was found disconnected; reconnecting: DBConnectionError: (pymysql.err.OperationalError) (2013, ‘Lost connection to MySQL server during query’) [SQL: u’SELECT 1′] (Background on this error at: http://sqlalche.me/e/e3q8)
[root@localhost ~]# vi /etc/my.cnf
[mysqld]
wait_timeout=28800
7.2 新增节点报错
ERROR nova.scheduler.client.report [req-fb678c94-091f-4dd3-bd44-49068015a07e – – – – -] [req-a7dd9b65-4ef2-4822-8110-f4a311839683] Failed to create resource provider record in placement API for UUID 73542ad1-f32b-4ba8-a62c-98ec704234c3. Got 409: {“errors”: [{“status”: 409, “request_id”: “req-a7dd9b65-4ef2-4822-8110-f4a311839683”, “detail”: “There was a conflict when trying to complete your request.\n\n Conflicting resource provider name: compute already exists. “, “title”: “Conflict”}]}.
[root@localhost ~]# mysql -uroot -p
MariaDB [nova_api]> update resource_providers set uuid='4d9ed4b4-f3a2-4e5d-9d8e-2f657a844a04' where name='compute' and uuid='e131e7c4-f7db-4889-8c34-e750e7b129da';
[root@localhost ~]# mysql -uroot -p
MariaDB [(none)]> create database keystone;
MariaDB [(none)]> GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'localhost' identified by 'tera123';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'%' identified by 'tera123';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON keystone.* TO 'keystone'@'openstack' identified by 'tera123';
[root@localhost ~]# openstack user list
+----------------------------------------------------------------+--------------+
| ID | Name |
| 57341d3e37eb4dc997624f9502495e44 | admin |
+-----------------------------------------------------------------+--------------+
[root@localhost ~]# mysql -uroot -p
MariaDB [(none)]> create database glance;
MariaDB [(none)]>GRANT ALL PRIVILEGES ON glance.* TO 'glance'@'localhost' identified by 'tera123';
MariaDB [(none)]> GRANT ALL PRIVILEGES ON glance.* TO 'glance'@'%' identified by 'tera123';
MariaDB [(none)]>GRANT ALL PRIVILEGES ON glance.* TO 'glance'@'openstack' identified by 'tera123';
[root@localhost ~]# mysql -uroot -p
MariaDB [(none)]> create database nova_api;
MariaDB [(none)]> create database nova;
MariaDB [(none)]> create database nova_cell0;
MariaDB [(none)]> create database placement;
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'localhost' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'%' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_api.* TO 'nova'@'openstack' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'localhost' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'%' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova.* TO 'nova'@'openstack' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'localhost' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'%' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON nova_cell0.* TO 'nova'@'openstack' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON placement.* TO 'placement'@'localhost' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON placement.* TO 'placement'@'%' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON placement.* TO 'placement'@'openstack' identified by 'tera123';
[root@localhost ~]# vi /etc/httpd/conf.d/00-nova-placement-api.conf
Listen 8778
<VirtualHost *:8778>
<Directory /usr/bin>
<IfVersion >= 2.4>
Require all granted
</IfVersion>
<IfVersion < 2.4>
Order allow,deny
Allow from all
</IfVersion>
</Directory>
WSGIProcessGroup nova-placement-api
WSGIApplicationGroup %{GLOBAL}
WSGIPassAuthorization On
WSGIDaemonProcess nova-placement-api processes=3 threads=1 user=nova group=nova
WSGIScriptAlias / /usr/bin/nova-placement-api
<IfVersion >= 2.4>
ErrorLogFormat "%M"
</IfVersion>
ErrorLog /var/log/nova/nova-placement-api.log
#SSLEngine On
#SSLCertificateFile ...
#SSLCertificateKeyFile ...
</VirtualHost>
Alias /nova-placement-api /usr/bin/nova-placement-api
<Location /nova-placement-api>
SetHandler wsgi-script
Options +ExecCGI
WSGIProcessGroup nova-placement-api
WSGIApplicationGroup %{GLOBAL}
WSGIPassAuthorization On
</Location>
10.6 同步数据库
导入nova-api、nova、cell0、placement库SQL。
[root@localhost ~]# su -s /bin/sh -c “nova-manage api_db sync” nova
[root@localhost ~]# su -s /bin/sh -c “nova-manage cell_v2 map_cell0” nova
[root@localhost ~]# su -s /bin/sh -c “nova-manage cell_v2 create_cell –name-cell1 --verbose” nova
[root@localhost ~]# su -s /bin/sh -c “nova-manage db sync” nova
[root@localhost ~]# openstack compute service list --service nova-compute
[root@localshot ~]# su -s /bin/sh -c “nova-manage cell_v2 discover_hosts --verbose” nova
Found 2 cell mappings.
Skipping cell0 since it does not contain hosts.
Getting computes from cell 'cell1': 54e6c270-7390-4390-8702-02b72874c5a7
Checking host mapping for compute host 'compute': 39d80423-6001-4036-a546-5287c1e93ec5
Creating host mapping for compute host 'compute': 39d80423-6001-4036-a546-5287c1e93ec5
Found 1 unmapped computes in cell: 54e6c270-7390-4390-8702-02b72874c5a7
OpenStack Networking plug-ins and agents:OpenStack通用代理是L3,DHCP和插件代理
12.1 MySQL中创建库和权限
在数据库中创建Neutron用户,并且授予用户访问库的权限。
[root@localhost ~]# mysql -uroot -p
MariaDB [(none)]> create database neutron;
MariaDB[(none)]>GRANT ALL PRIVILEGES ON neutron.* TO 'neutron'@'localhost' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON neutron.* TO 'neutron'@'%' identified by 'tera123';
MariaDB[(none)]>GRANT ALL PRIVILEGES ON neutron.* TO 'neutron'@'openstack' identified by 'tera123';
evpnmh-leaf-1# show link-aggregation summary
Flags: A - active, I - inactive, Up - up, Dw - Down, N/A - not available,
S - selected, D - deselected, * - not synced
No. Team Dev Protocol Ports Description ----- --------------- ----------- ------------- -------------
0100 lag 100 LACP(A)(Dw) 0/64 (D) N/A
VXLAN(Virtual eXtensible Local Area Network)技术是VLAN的一种扩展方案,由IETF在RFC7348中定义。VXLAN采用MAC in UDP(User Datagram Protocol)封装方式,是NVO3(Network Virtualization over Layer 3)中的一种网络虚拟化技术。
此配置示例是采用 Asterfusion 虚拟 SONiC 交换机 (vAsterNOS) 实现的,因此需要运行 vAsterNOS 的虚拟环境。具体环境搭建请参考本文第二章的相关链接。
4.4 设备互联IP
设备名称
接口
IP地址
备注
Spine
Ethernet 0/0
11.11.11.2/24
Spine
Ethernet 0/1
22.22.22.2/24
Spine
Loopback 0
10.1.0.210/32
Router-id and vtep ip same as loopback0
Leaf1
Ethernet 0/0
11.11.11.1/24
Leaf1
Vlan 100
100.0.0.1/24
Leaf1
Vlan 200
200.0.0.1/24
Leaf1
Loopback 0
10.1.0.211/32
Router-id and vtep ip same as loopback0
Leaf2
Ethernet 0/0
22.22.22.1/24
Leaf2
Vlan 300
100.0.0.1/24
Leaf2
Loopback 0
10.1.0.212/32
Router-id and vtep-ip same as loopback0
VM-A1
eth0
100.0.0.2/24
VM-A2
eth0
100.0.0.3/24
VM-B1
eth0
200.0.0.2/24
VM-A3
eth0
100.0.0.4/24
4.5 测试前的准备工作
确保每个 vAsterNOS 和 VM 设备都正确上线,并按照拓扑正确连接。
4.6 配置步骤
第 1 步
修改 leaf1、leaf2 和 spine 设备的 mac 地址。由于初始 mac 地址相同,因此在配置服务之前,必须先修改 mac 地址。修改leaf1、leaf2及spine设备的mac地址,由于初始mac地址相同,所以在进行业务配置之前,必须先进行mac地址的修改,才能使EVPN VXLAN等功能正常运行。这里分别修改leaf1和leaf2设备地址,使三台设备的mac地址不相同。
sonic# system bash
admin@sonic:~$ sudo vi /etc/sonic/config_db.json
本次测试中,使用vAsterNOS及VM设备组网并配置EVPN VXLAN网络后,各VM之间能互相正常通信,并且leaf之间能正确建立vxlan隧道,相关路由也正常工作,说明vAsterNOS的EVPN VXLAN功能特性正常,可满足用户组网需求,同时Asterfusion Data Center switch的功能特性与配置方法与vAsterNOS 是完全一致的,用户通过vAsterNOS验证配置之后,可以直接用Asterfusion Data Center switch实施。