本文将从以下几个维度梳理相关知识信息,篇幅较长,建议先转发收藏。
- 存储架构沿革
- 分布式存储网络协议选择
- 交换机硬件设备选型
- RoCE无损网络配置和管理(手动配置和自动化配置)
- 性能测试方案(关键指标、测试工具和参数解读)
- 最佳实践
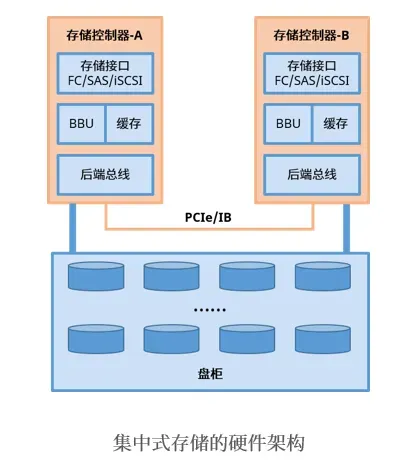
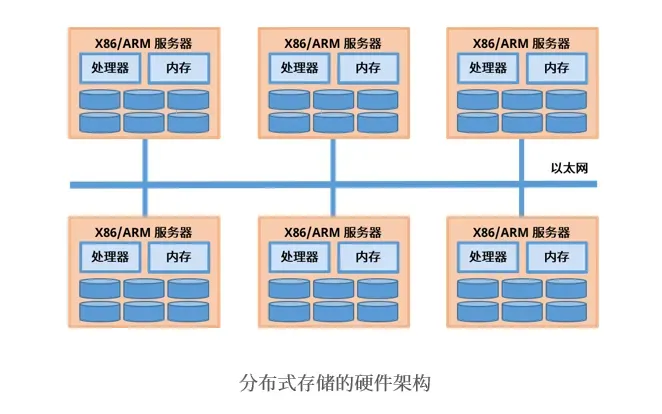
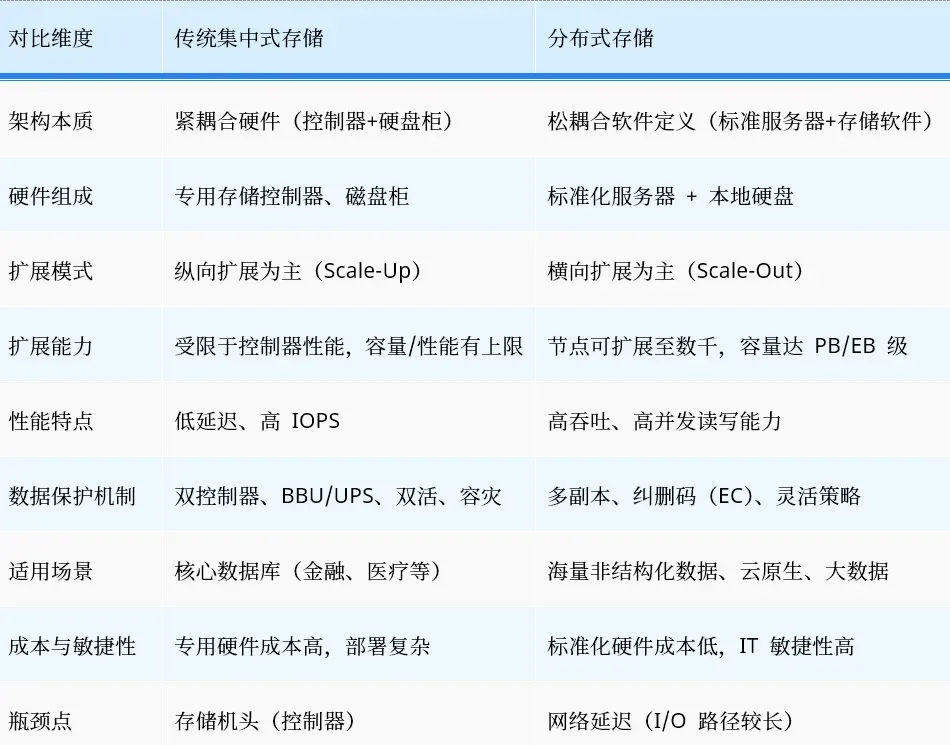
传统集中式存储和分布式存储的对比
传统集中式 SAN/NAS 存储起步早、技术成熟,具备高IOPS、低时延、数据强一致性等优势,适合金融、医疗等行业的核心业务系统的数据库存储场景,但集中式的架构同时决定了它的扩展能力受限于存储机头,无法很好地支撑大规模数据存储和高并发访问场景。
随着云计算技术快速迭代,AI智算的逐步落地应用推广,计算能力与上层业务规模的急速扩展推动着存储基础设施转变为分布式存储架构。
分布式存储作为新一代的存储技术,使用分布式存储软件将算力服务器本地的硬盘组成统一的存储资源池,从架构层面解决了传统集中式存储的扩展性问题,规模可扩展至上千个节点,容量可扩展到PB甚至EB级,并且性能可随容量线性提升。
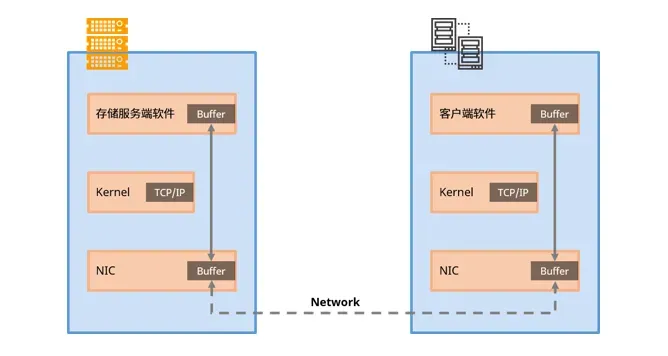
在分布式存储中,网络通信方面若采用传统的TCP/IP以太网会占用大量的CPU资源,并且需要额外的数据处理。进入全闪存储时代,传统的以太网通信协议栈已无法再满足存储网络需求。
分布式存储网络的搭建
网络协议的选择
为了解决分布式存储I/O路径长和传统TCP协议带来的性能瓶颈,业界已经广泛采用高带宽低时延的RDMA网络与集群内外部的互联。
RDMA可以简单理解为利用相关的硬件和网络技术,服务器A的网卡可以直接读写服务器B的内存,应用程序不需要参与数据传输过程,只需要指定内存读写地址,开启传输并等待传输完成即可。
当前主流的RDMA网络分为了InfiniBand和RoCEv2两大阵营。
IB网络因其性能优异早已广泛应用到 HPC 场景,但需要专用的网卡、交换机配套线缆和管理平台。
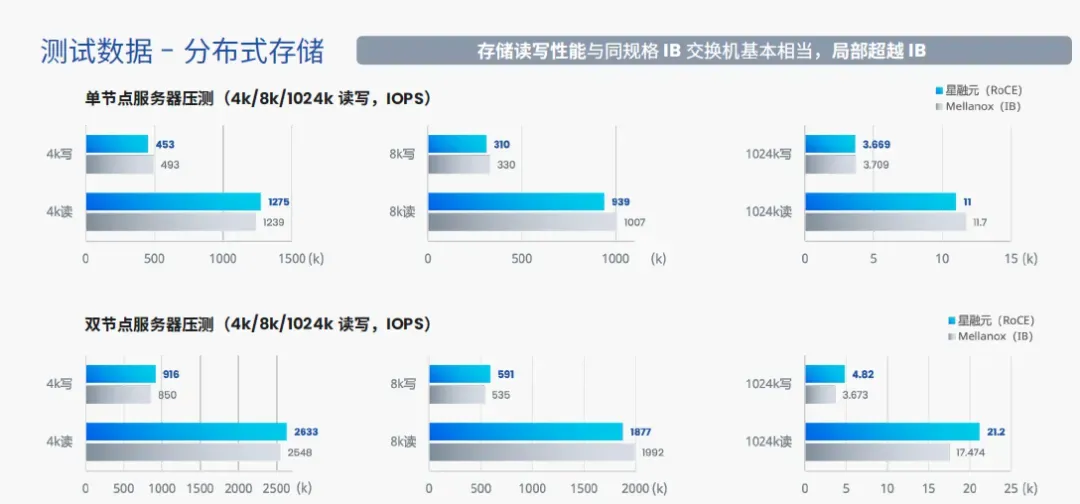
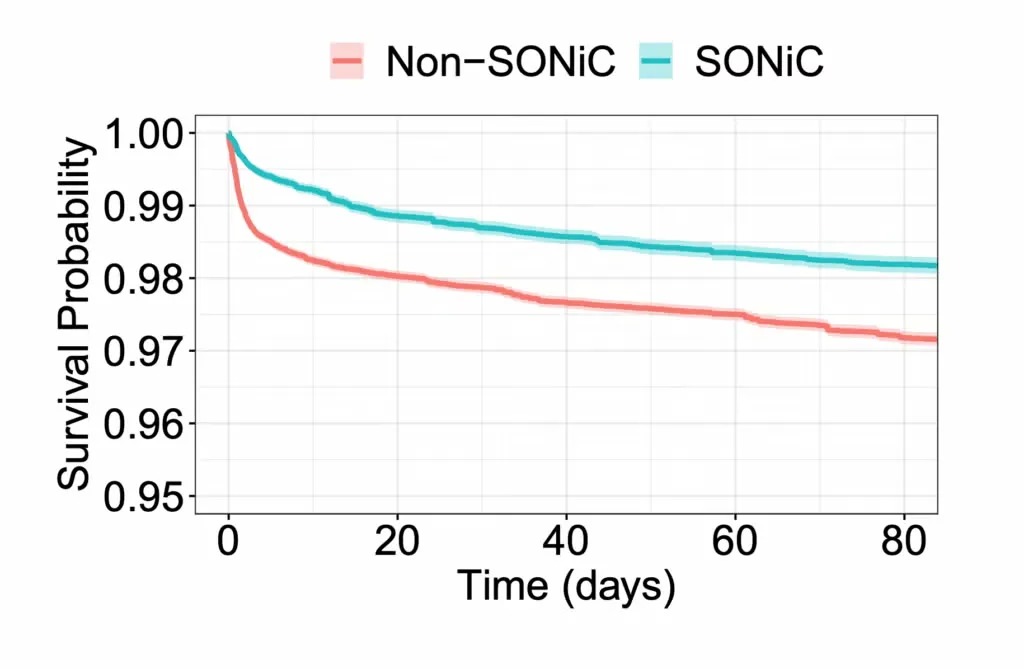
RoCEv2使用开放和标准化协议在以太网上传输IB流量,整体部署成本优势明显,采用厂商优化的RoCE网络设备,端到端性能足够稳定替代IB。以下是星融元CX-N系列RoCE交换机与同规格IB交换机的存储集群组网,测试结果甚至局部超越IB,后文会提供更详细的测试信息。

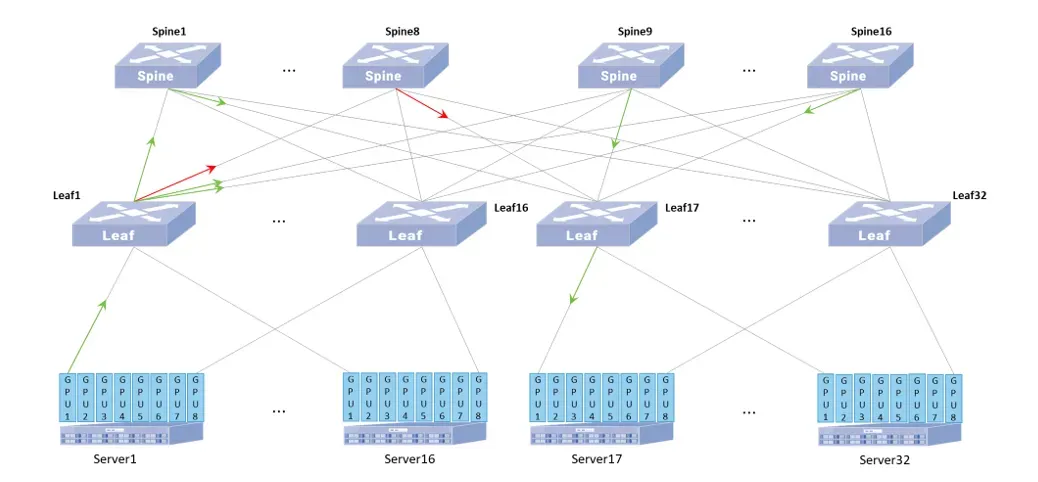
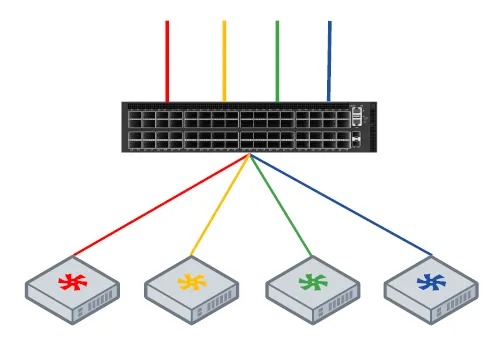
组网架构
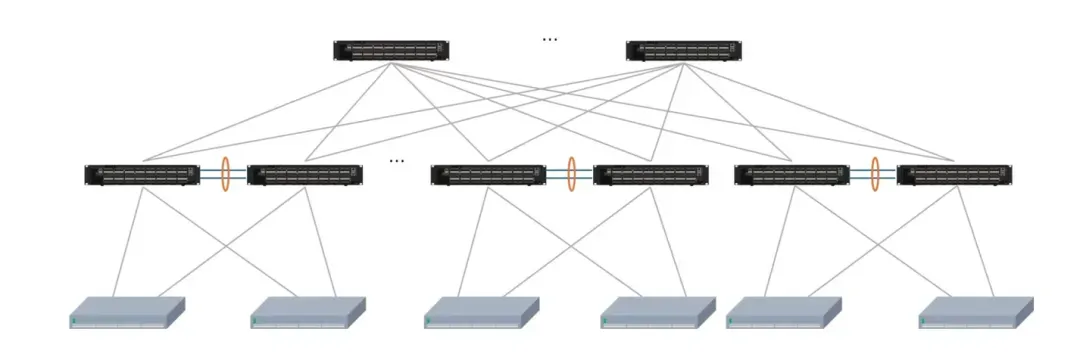
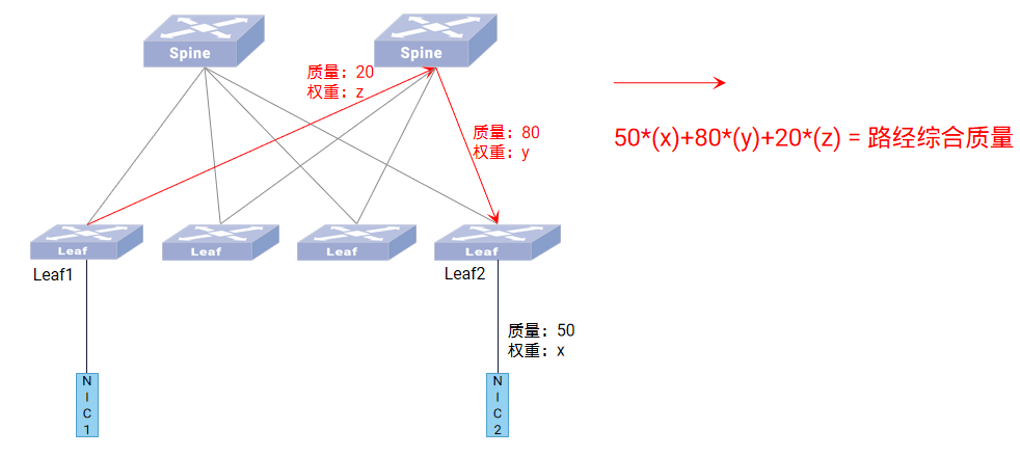
在计算和存储分离的部署场景中,我们推荐部署2张Spine-Leaf 架构的物理网,存储后端网将单独使用一张物理网,以保证分布式存储集群能够快速无阻塞地完成多副本同步、故障后数据重建等任务,而存储前端网和业务则可用一张物理网。
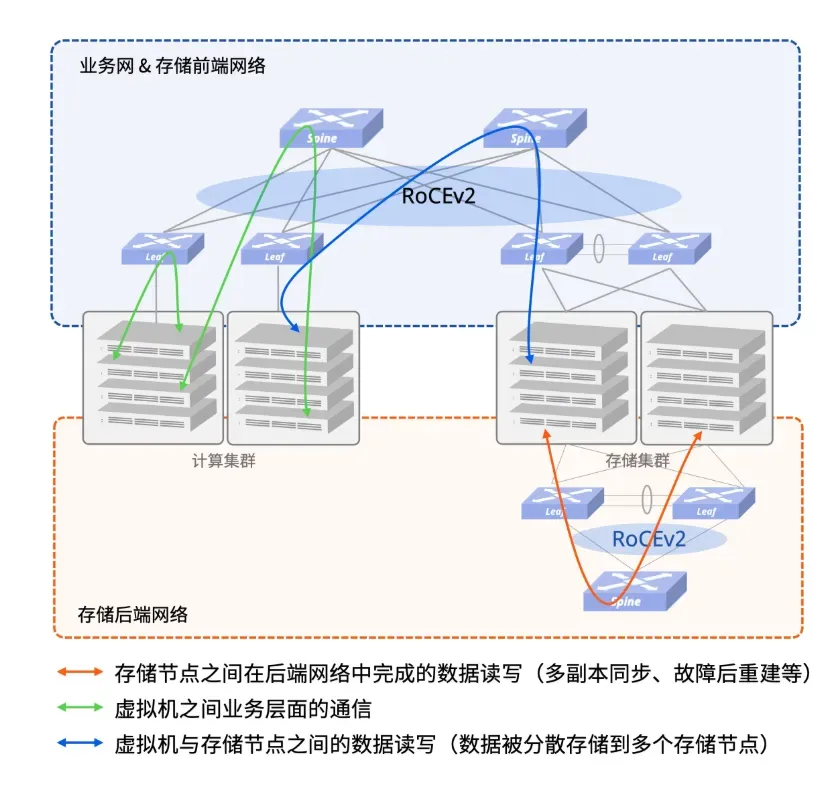
另外,存储节点对网络接入侧的可靠性要求相对较高,因此存储集群中的节点,一般推荐使用双归或多归(Multi-homing)方式接入。
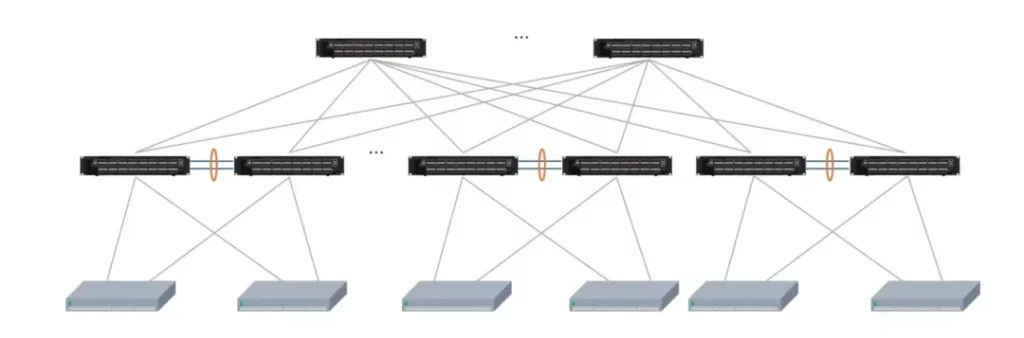
网络硬件选型
存储网络的硬件选型方面一般要满足如下几点:
- 高密度的100G/200G/400G接口,尽量减少交换机台数
- 支持IB/RoCE协议,500ns以内的端口转发时延,支持PFC/ECN等无损网络特性
- 全盒式设备形态,提供灵活、扁平的横向扩展能力(支持多达数千个存储/计算节点,并可保证同集群下的任何两台存储服务器之间的通信不超过三跳)
RoCE 无损网络的配置和管理
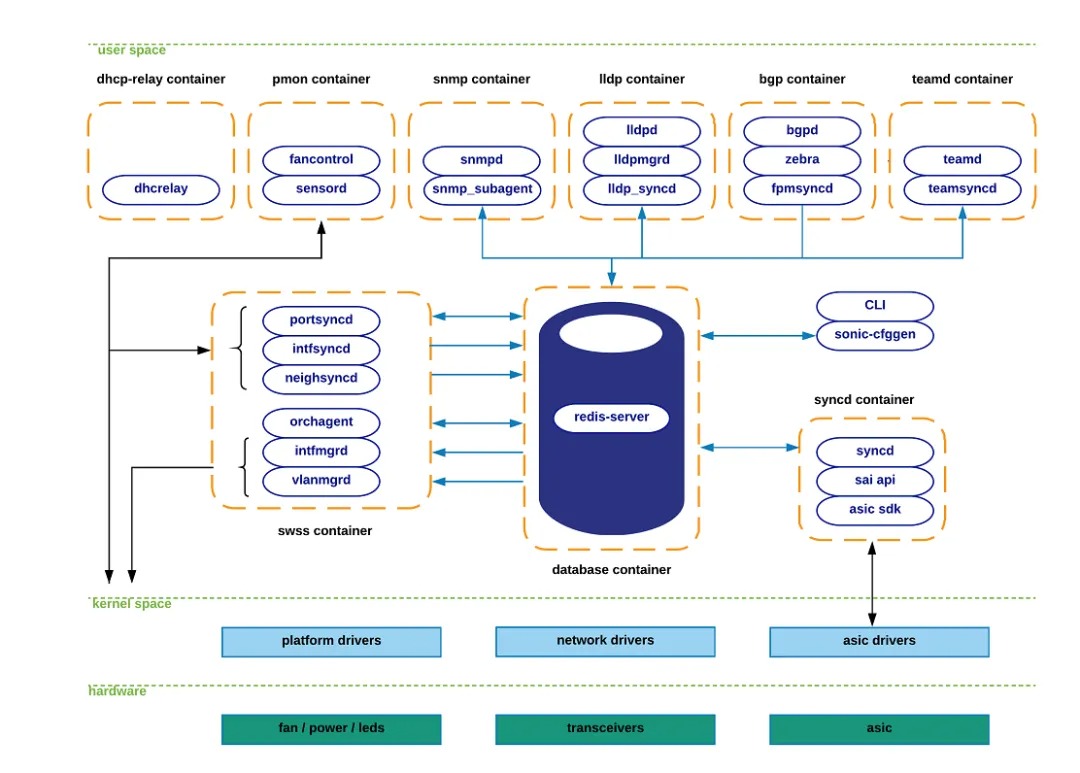
NVIDIA IB网络的配置和管理已经高度系统化和整体化,此处不加赘述。
与IB相比,未经优化的RoCE网络需要在交换机上手动配置调整,步骤会相对复杂;不过在部分交换机上(星融元CX-N系列)也可以借助于其开放的软件架构和API,引入自动化工具简化RoCE配置,并提供与UFM类似的网络监控和管理能力。
一般手动方式
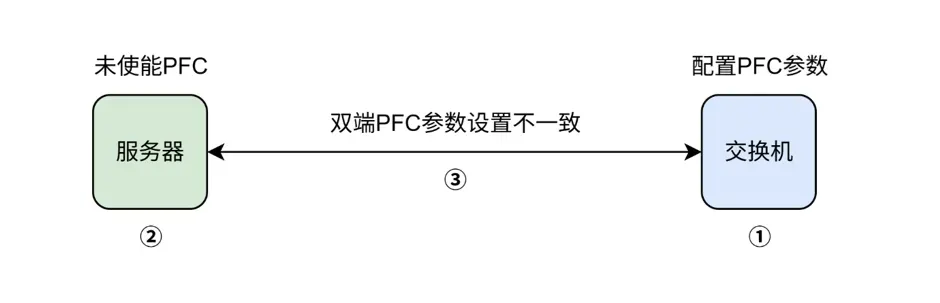
在完成基础的连接与配置后,需要先根据业务场景对全网的流量优先级进行规划,并对所有的交换机使能PFC与PFC死锁监控功能,让不同的业务流量进入不同的队列进行转发,使基于RoCEv2的存储业务流量优先转发。
同时,使能所有交换机的ECN功能,保障存储队列的低时延和高吞吐。需要注意的是,交换机和服务器网卡上共同的参数需要保持一致,对于队列划分、缓存、PFC门限及ECN门限等配置需要结合业务情况动态调整,以达最佳性能表现。
#确保服务器网卡工作在 RoCEv2 模式下
#为业务流量配置 PCP 或 DSCP,并启用 ECN。
#设置网卡RDMA CM的工作模式
[root@server ~]# cma_roce_mode -d mlx5_0 -p 1 -m
#设置网卡的优先级类型为DSCP
[root@server ~]# mlnx_qos -i enp1s0f0 –trust=dscp
DCBX mode: OS controlled
Priority trust state: dscp
#在队列3上开启PFC
[root@server ~]# mlnx_qos -i enp1s0f0 -f 0,0,0,1,0,0,0,0
#在队列3上开启DCQCN
[root@server ~]# echo 1 > /sys/class/net/enp1s0f0/ecn/roce_np/enable/3
[root@server ~]# echo 1 > /sys/class/net/enp1s0f0/ecn/roce_rp/enable/3
#设置CNP DSCP
[root@server ~]# echo 48 >
#在交换机端口配置以启用 PFC 和 ECN 功能并指定队列
#在交换机的指定队列(与服务器上的队列匹配)上启用 PFC 和 ECN
#调整缓冲区和阈值
# 设置PFC门限值
sonic(config)# buffer-profile pg_lossless_100000_100m_profile
sonic(config-buffer-profile-pg_lossless_100000_100m_profile)# mode lossless dynamic -2 size 1518 xon 0 xoff 46496 xon-offset 13440
sonic(config-buffer-profile-pg_lossless_100000_100m_profile)# exit
# 在3、4队列开启PFC功能(AsterNOS的PFC功能默认使能3、4队列,无需配置)
sonic(config)# priority-flow-control enable 3
sonic(config)# priority-flow-control enable 4
sonic(config)# exit
# 设置ECN门限值
sonic(config)# wred roce-ecn
sonic(config-wred-roce-ecn)# mode ecn gmin 15360 gmax 750000 gprobability 10
sonic(config-wred-roce-ecn)# exit
# 配置Diffserv map
sonic(config)# diffserv-map type ip-dscp roce-dmap
sonic(config-diffservmap-roce-dmap)# ip-dscp 48 cos 6
# 配置Class map
sonic(config)# class-map roce-cmap
sonic(config-cmap-roce-cmap)# match cos 3 4
sonic(config-cmap-roce-cmap)# exit
# 配置Policy map
sonic(config)# policy-map roce-pmap
sonic(config-pmap-roce-pmap )# class roce-cmap
sonic(config-pmap-c)# wred roce-ecn
sonic(config-pmap-c)# priority-group-buffer pg_lossless_100000_100m_profile
sonic(config-pmap-c)# exit
sonic(config-pmap-roce-pmap )# set cos dscp diffserv roce-dmap
sonic(config-pmap-roce-pmap )# exit
# 进入以太网接口视图,绑定策略,将RoCE网络配置在接口上使能
sonic(config)# interface ethernet 0/0
sonic(config-if-0/120)# service-policy roce-pmap
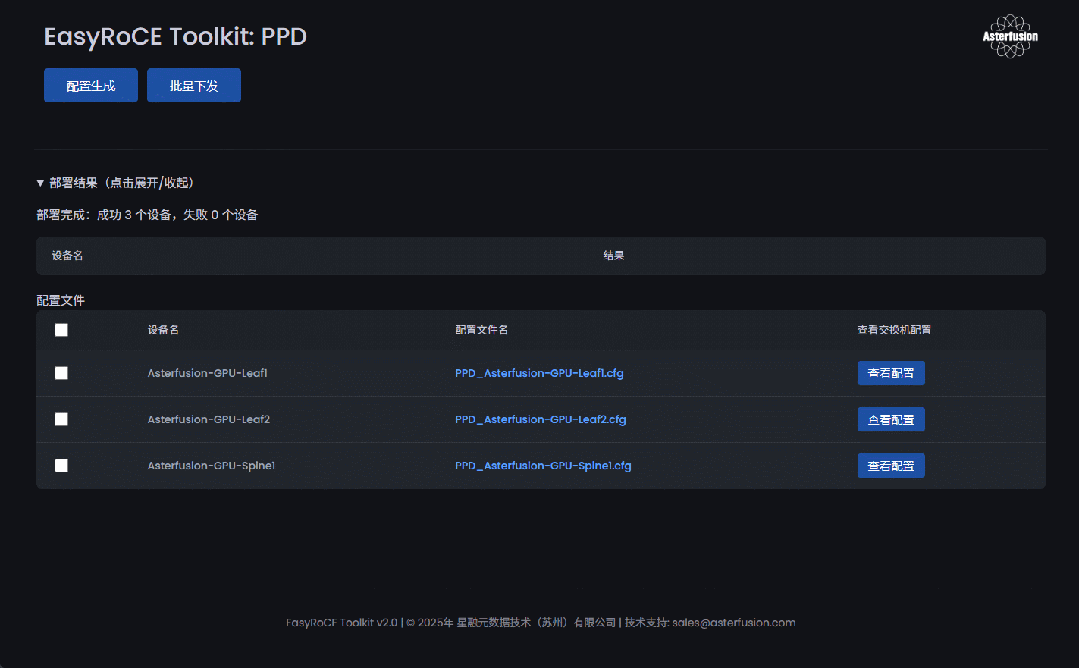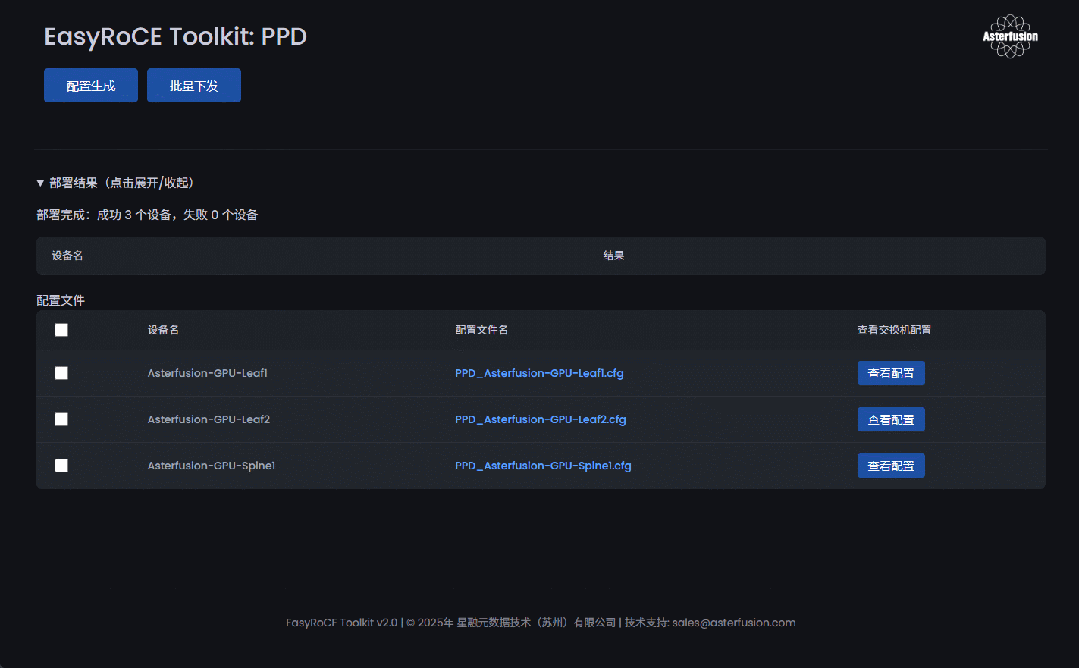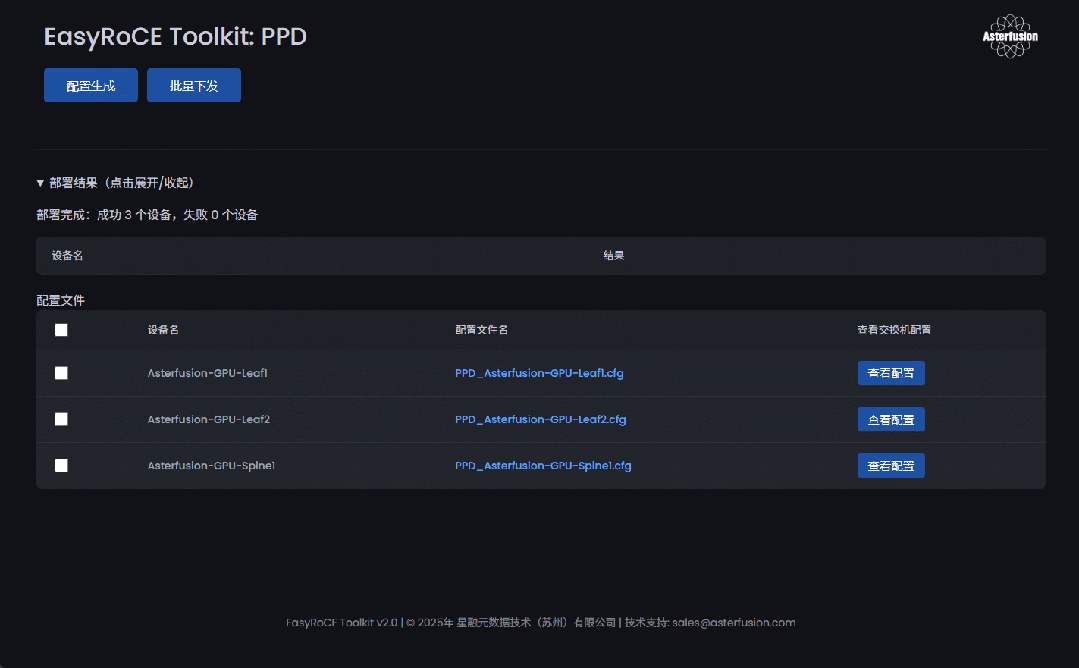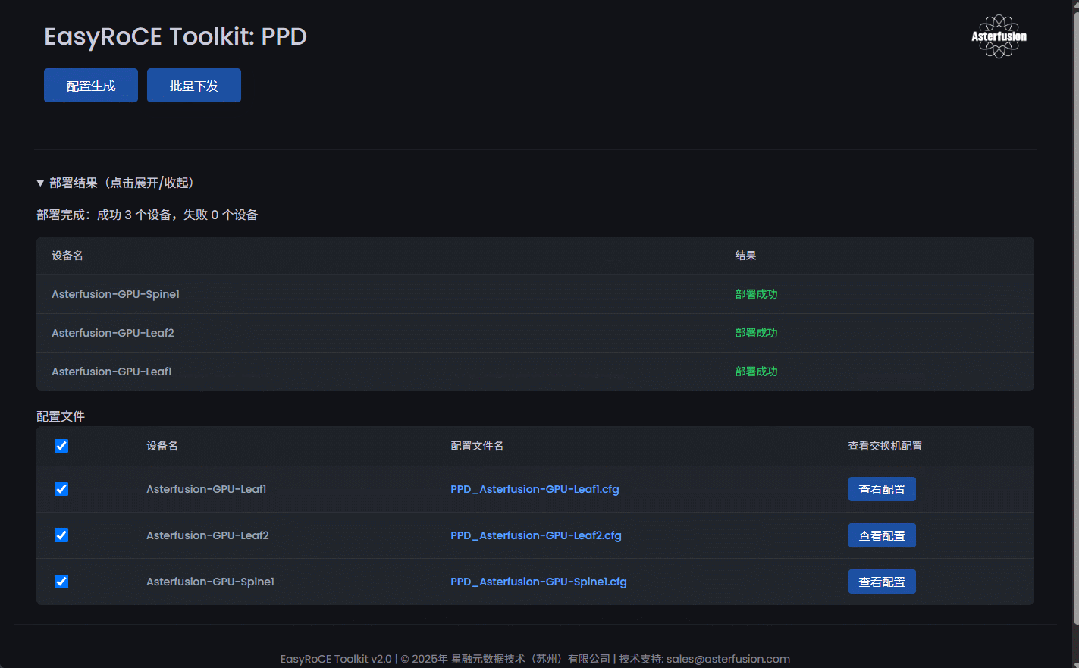
基于网络自动化工具
以下能力均来自于星融元 EasyRoCE Toolkit 内相关组件模块,当前该工具套件对签约客户免费。详情访问:https://asterfusion.com/easyroce/
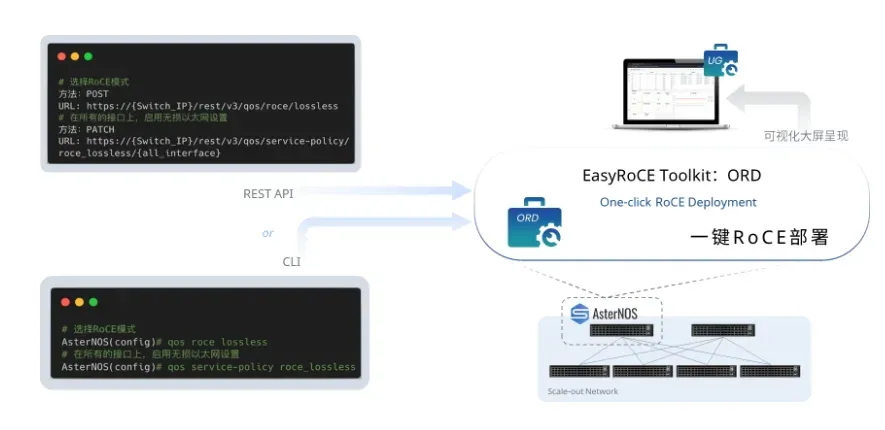
- 1条命令行启用和模板化配置RoCE :针对无损网络优化的命令行视图和业务级的命令行封装,实现一条命令行启用;基于芯片规格和应用场景,预设最佳参数模版
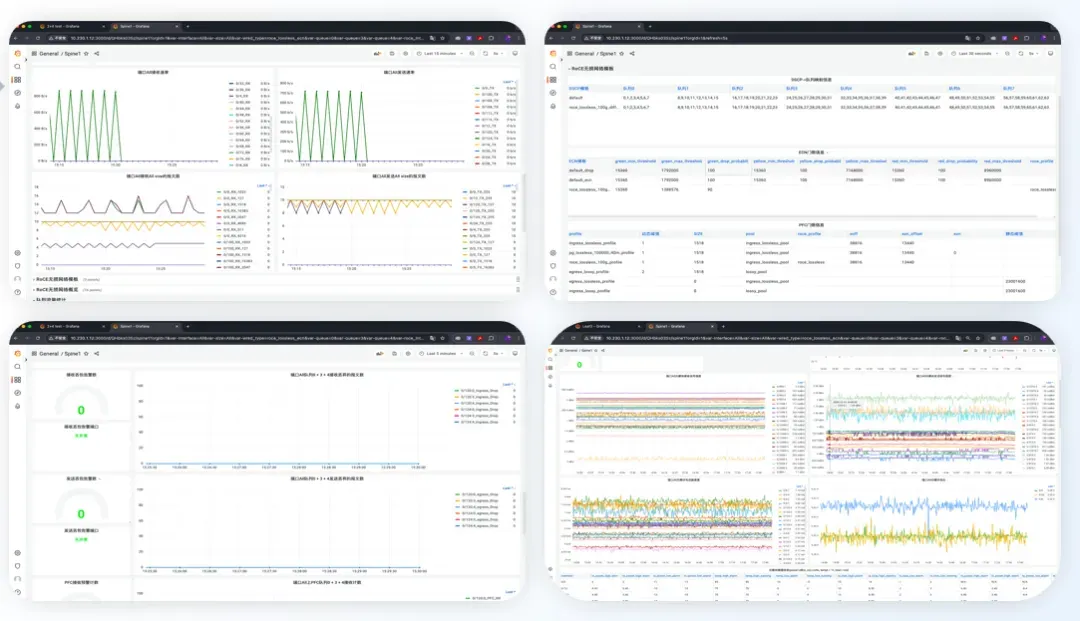
- 关键RoCE指标导出和可视化呈现:在交换机内运行一个容器化的监控采集前端(RoCE Expoter),将RoCE业务相关网络指标采集给开源监控方案Prometheus,为运维团队提供一个开箱即用的RDMA网络监控方案
- RoCE 网络参数集中呈现:RoCE相关的配置调试信息组织起来集中展示到Prometheus面板,简化排障流程提高效率
存储性能测试的关键指标和软件工具
关键测试指标
存储性能测试项整体上分为IO时延和IOPS两个纬度,每个维度中又会按照读/写、数据块的大小分别进行测试。
通常情况下随机IO的性能远低于顺序IO、写入性能远低于读取性能。
- IO:单个读/写请求
- IO时延:发起请求到收到存储系统的响应消息所花费的时间
- IOPS:每秒存储系统能处理的IO请求数。
- 顺序IO:大量的IO请求连续相邻的数据块,典型的业务有日志、数据备份恢复、流媒体等。顺序IO的性能通常就是最高性能
- 随机IO:IO请求的是随机分布在存储介质各个区域的数据块,比如高并发读写大量小文件,就会导致IOPS和吞吐的性能下降,典型的业务有OLTP、交换分区、操作系统等。随机IO的性能通常是最低性能
此外,数据块大小对存储的性能表现直接的影响。
- 小IO,如1K、4K、8K
- 大IO,如32K、64K甚至更大
较大的IO会带来更高的吞吐,较小的IO会产生更高的IOPS。大多数真实的业务场景中,IO的大小是混合的。
性能测试步骤和工具
- 存储网络的性能测试。主要关注网络单链路的吞吐和时延,常用的工具是iperf、ib_read/write_bw、ib_read/write_lat;
- 会进行存储系统的基础性能测试。这里关注的是存储系统的时延和吞吐,常用的工具是fio;
- 业务级别的兼容性、稳定性以及性能测试。兼容性方面主要测试交换机的API是否能满足业务系统的要求,稳定性方面的测试则是网络设备级和链路级别的高可靠,性能测试则会用业务场景专用的测试工具进行压测,比如:数据库一体机常用的工具是swingbench和hammerdb,对象存储场景中常用的工具是cosbench。
测试参数说明
以下是国内某数据库厂商分别使用 Mellanox SB7700与星融元CX532P-N组网,使用测试工具fio得出的结果概要:
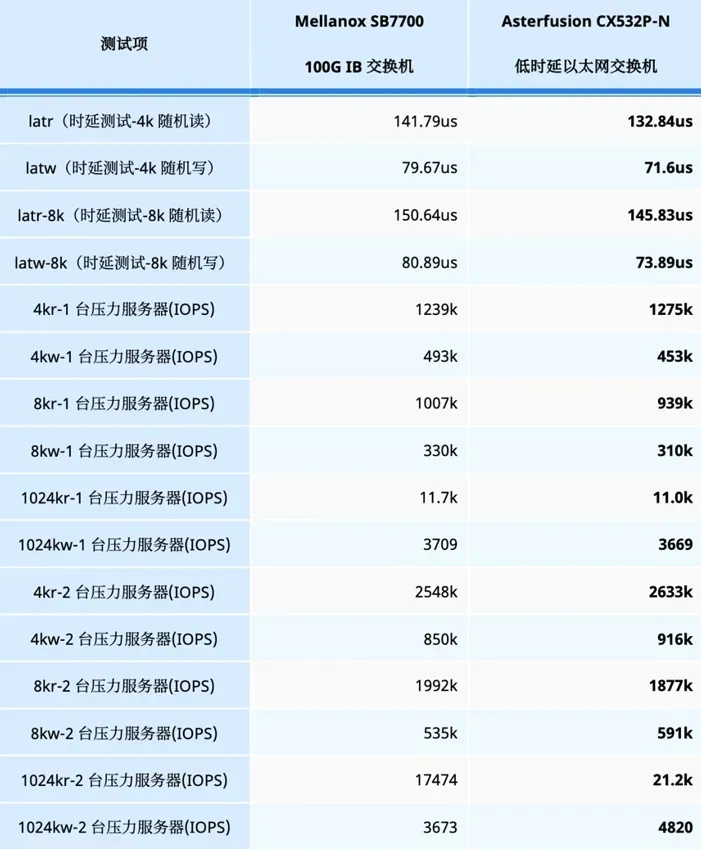
测试时延时使用的是1v1的方式,测试存储系统IOPS时分别用1v1、2v1的方式进行压测。目标是测试服务器在假设的小IO业务场景中(100% 随机,70% 读,30% 写,IO size 4K)的性能表现。
[root@server ~]# fio \
-filename=/root/randrw_70read_4k.fio \
-direct=1 \
-iodepth 1 \
-thread \
-rw=randrw \
-rwmixread=70 \
-ioengine=psync \
-bs=4k \
-size=5G \
-numjobs=8 \
-runtime=300 \
-group_reporting \
-name=randrw_70read_4k_local
`-filename=/root/randrw_70read_4k.fio`
支持文件、裸盘、RBD image。该参数可以同时制定多个设备或文件,格式为:-filename=/dev/vdc:/dev/vdd(以冒号分割)。
`-direct=1`
direct即使用直接写入,绕过操作系统的page cache。
`-iodepth=1`
iodepth是设置IO队列深度,即单线程中一次给系统多少IO请求。如果使用同步方式,单线程中iodepth总是1;如果是异步方式,就可以提高iodepth,一次提交一批IO,使得底层IO调度算法可以进行合并操作,一般设置为32或64。
`-thread`
fio默认是通过fork创建多个job,即多进程方式,如果指定thread,就是用POSIX的thread方式创建多个job,即使用pthread_create()方式创建线程。
`-rw=randrw`
设置读写模式,包括:write(顺序写)、read(顺序读)、rw(顺序读写)、randwrite(随机写)、randread(随机读)、randrw(随机读写)。
`-rwmixread=70`
设置读写IO的混合比例,在这个测试中,读占总IO的70%,写IO占比30%。
`-ioengine=psync`
设置fio下发IO的方式,本次测试使用的IO引擎为psync。
`-bs=4k`
bs即block size(块大小),是指每个IO的数据大小
`-size=5g`
测试总数据量,该参数和runtime会同时限制fio的运行,任何一个目标先达到,fio都会终止运行。在做性能测试时,尽量设置大点,比如设置2g、5g、10g或者更大,如果基于文件系统测试,则需要需要小于4g。
`-numjobs=8`
本次作业同时进行测试的线程或进程数,线程还是进程由前面提到的thread参数控制。
`-runtime=300`
测试总时长,单位是s。和size一起控制fio的运行时长,在做一般性性能测试的时候,该时间也尽量设置长点,比如5分钟、10分钟。
`-group_reporting`
多个jobs测试的时候,测试结果默认是单独分开的,加上这个参数,会将所有jobs的测试结果汇总起来。
`-name=randrw_70read_4k_local`
本次测试作业的名称。
最佳实践
星融元(Asterfusion)为中国TOP3公有云打造媲美IB的低时延网络。
需求背景
该公有云用户作为中国TOP3云计算服务市场的重要参与者之一,为政府、企业和个人用户提供安全可靠的云计算解决方案。2022年需要对存储业务区域进行扩容,进一步提升网络服务质量。
- 设备时延要低,满足分布式存储的业务需求
- 具有良好的供应链保障机制
- 能够提供及时且专业的技术支持
方案介绍
通过星融元CX664D-N(64x200GE)大容量低时延以太网交换机提高应用响应速度,同时为业务提供无损传输保障,满足高可靠、低时延的需求。
- 整网采用RoCEv2,通过PFC、ECN、DCBX保障业务无损,提供与IB媲美的性能和无损网络
- 超低时延提高业务并发量,加快数据传输速度,提升业务响应效率,抢占市场先机
- 更低的技术门槛和运维成本,可以在传统以太网上实现超低时延、零丢包、高性能的网络传输