交换机上的 DHCP 侦听(DHCP Snooping)功能和配置示例
近期文章
什么是 DHCP 侦听
DHCP侦听(DHCP snooping)是一种部署在以太网交换机上的网络安全机制,用于阻止未经授权的 DHCP 服务器为客户端分配 IP 地址。该机制通过检查 DHCP 消息并仅允许来自受信任端口的 DHCP 消息通过,从而防止非法 IP 地址分配,确保网络环境安全稳定。
为什么需要DHCP侦听?
在企业、校园甚至公共网络中,与 DHCP 相关的问题并不少见,而且它们可能会造成严重的网络中断。有时,仅仅是配置错误的设备意外地充当了 DHCP 服务器,分配了错误的 IP 地址,导致连接中断。有时,问题更为严重,例如攻击者设置了恶意 DHCP 服务器,通过虚假网关或 DNS 服务器重新路由用户,从而为中间人攻击打开了方便之门。即使是客户端手动为自己分配静态 IP 地址,也可能造成混乱,引发冲突,并使网络安全管理更加困难。
| 项目 | DHCP | 静态 IP |
|---|---|---|
| 分配方法 | 由服务器自动分配 | 手动配置 |
| 管理努力 | 低,适合大规模部署 | 高,需要单独设置 |
| 解决稳定性问题 | 每次设备连接时可能会发生变化 | 固定不变 |
| 设置效率 | 快速、即插即用 | 速度慢,需要手动输入 |
| 适合 | 最终用户设备、动态环境 | 服务器、打印机、关键设备 |
| 安全 | 需要配合保护机制(例如 DHCP 侦听) | 更可控,但有手动配置错误的风险 |
DHCP 侦听的好处:
- 阻止恶意 DHCP 服务器干扰网络。
- 确保客户端收到准确的 IP 地址和网络配置。
- 通过降低攻击风险来增强网络安全。
DHCP 侦听如何工作?
要真正理解DHCP 监听的工作原理,首先必须清楚了解DHCP(动态主机配置协议)的工作原理。当设备加入网络且尚未获得 IP 地址时,它会发起与 DHCP 服务器的对话——这是一个四步握手过程,包括:发现 (Discover )、提供 (Offer)、请求 (Request)和确认 (Acknowledge )。可以将其视为设备和服务器之间获取 IP 身份的快速协商过程。下图详细分析了此动态交换过程中每个步骤的具体细节。
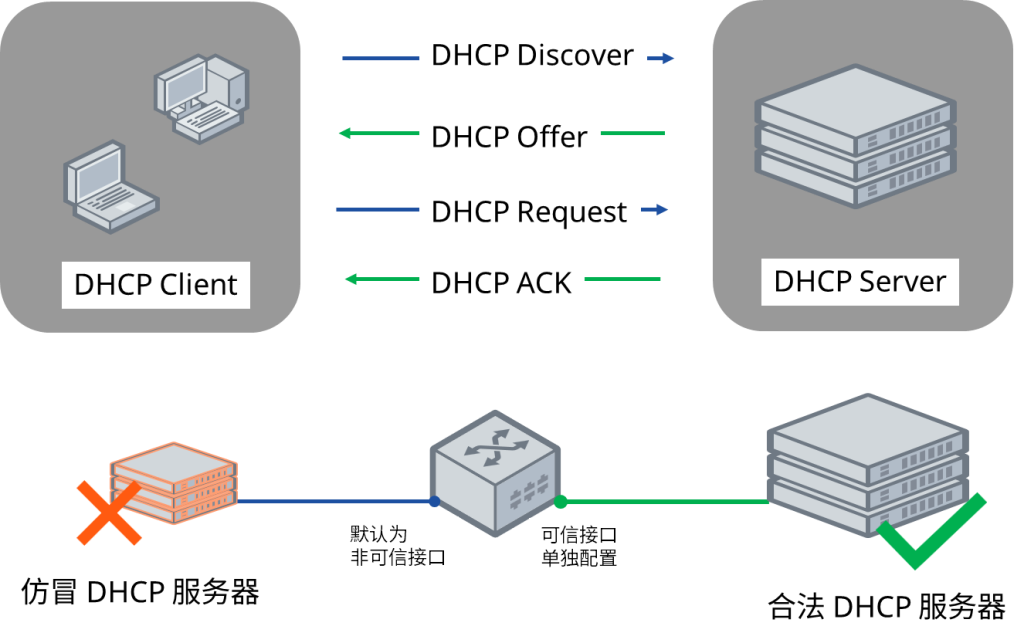
在启用 DHCP Snooping 的网络中,交换机接口分为两个主要角色:可信端口和不可信端口。
- 可信端口:这些端口连接到合法的 DHCP 服务器或上行链路设备(例如路由器或核心交换机),并被允许发送 DHCP 服务器消息(例如 DHCP OFFER、DHCP ACK)。
- 不受信任的端口:这些端口连接到常规客户端(例如,PC 或打印机),并且仅限于发送 DHCP 客户端消息(例如,DHCP DISCOVER、DHCP REQUEST)。
- 默认情况下,所有端口都是不受信任的;必须手动配置受信任的端口。
DHCP 消息过滤:
- 来自不受信任端口的 DHCP 服务器消息(例如 DHCP OFFER、DHCP ACK)将被丢弃,以防止恶意 DHCP 服务器运行。
- 客户端请求(例如,DHCP DISCOVER、DHCP REQUEST)可以来自不受信任的端口,但服务器响应只允许来自受信任的端口。
DHCP绑定表:
- DHCP 侦听维护一个绑定表,其中记录每个客户端的 MAC 地址、分配的 IP 地址、租用期限、VLAN 和端口信息。
- 该表用于验证后续流量,防止 IP 地址欺骗。
与 IP Source Guard 集成:
DHCP 侦听通常与 IP 源防护配合使用,根据绑定表过滤流量,仅允许分配的 IP 地址从客户端发送数据,阻止未经授权的 IP。
支持 DHCP option 82(可选):
DHCP 侦听可以插入或处理 DHCP option 82(中继代理信息),为 DHCP 服务器提供有关客户端端口和交换机的详细信息,从而实现更精确的 IP 分配。
DHCP 侦听可以防范哪些常见网络攻击
DHCP 侦听可有效缓解以下网络威胁:
恶意 DHCP 服务器攻击:
- 工作原理:攻击者设置未经授权的 DHCP 服务器来分发不正确的 IP 地址、网关或 DNS 服务器。
- 影响:客户端流量被重定向到攻击者的设备,从而实现 MITM 攻击、流量拦截或 DNS 欺骗。
- 防御:DHCP 侦听会丢弃来自不受信任端口的服务器消息,仅允许受信任的端口发送 DHCP 响应。
DHCP 饥饿攻击:
- 工作原理:攻击者利用 DHCPDISCOVER 请求淹没网络,耗尽 DHCP 服务器的 IP 地址池。
- 影响:合法客户端无法获取IP地址,导致网络服务中断。
- 防御:当与端口安全或每个端口的速率限制 DHCP 请求相结合时,DHCP 侦听可以防止过多的流量压垮服务器。
中间人(MITM)攻击:
- 工作原理:恶意 DHCP 服务器分配虚假网关或 DNS 服务器,通过攻击者的设备路由客户端流量。
- 影响:攻击者可以监控、修改或重定向客户端通信。
- 防御:DHCP 侦听确保仅处理受信任的 DHCP 消息,从而阻止恶意配置。
IP欺骗攻击:
- 工作原理:客户端手动配置未经授权的 IP 地址来冒充合法主机。
- 影响:这可能导致 IP 冲突、网络中断,或成为进一步攻击的垫脚石。
- 防御:通过与 IP Source Guard 和 DHCP 绑定表集成,DHCP Snooping 可以阻止来自未经授权的 IP 地址的流量。
DHCP 侦听的应用场景
- 公共网络:在咖啡店、酒店或共同工作空间等环境中,恶意用户可能会部署恶意 DHCP 服务器来窃取数据或发起攻击。
- 企业网络:具有多个部门或 VLAN 的大型网络依靠 DHCP 侦听来确保客户端连接到正确的 DHCP 服务器。
- 高安全性环境:在需要遵守数据保护法规和其他有保密等级要求的环境中,DHCP 侦听功能有助于防止未经授权的访问。
- 防范 DHCP 欺骗:它减轻了客户端被重定向到恶意网关的风险,增强了整体网络安全性。
配置示例
传统方式-手动配置
configure Terminal #进入系统配置视图
dhcp snooping enable{v4|v6} #启用DHCP Snooping功能,默认禁用。
interface ethernet interface-id #进入接口视图
dhcp-snooping enable #启用DHCP Snooping功能,默认禁用。
dhcp-snooping trusted #设置端口的信任状态,默认不信任。
sonic# configure terminal
sonic(config)# dhcp snooping enable v4
sonic(config)# interface ethernet 20
sonic(config-if-20)# dhcp-snooping enable
sonic(config-if-20)# dhcp-snooping trusted云化配置方式 – 图形化配置
星融元的云化园区网络解决方案,通过一个开源、开放架构(基于OpenWiFi)的网络控制器来为有线无线网络设备下发配置,进行开局配置时在交换机上会默认开启DHCP Snooping,有效防止 DHCP Server 仿冒者攻击,使 DHCP 客户端能够通过合法的DHCP 服务器获取 IP 地址,管理员无需关注不同设备的信任接口与非信任接口,而是通过控制器的拓扑信息自动生成。
根据当前网络的所需的安全等级,管理员可在控制器界面上自行选择是否还需要开启ARP检测(DAI)和IP源攻击防护(IPSG)功能,该功能主要是通过全局的 DHCP Snooping 表项判断主机是否合法,不仅可以防止恶意主机伪造合法主机访问网络,同时还能确保主机不通过自己指定 IP 地址的方式来访问或攻击网络,造成可能的IP 地址冲突。
更多配置流程请参考:完整流程揭秘:30分钟搞定中大型园区网络业务开通,可行吗?