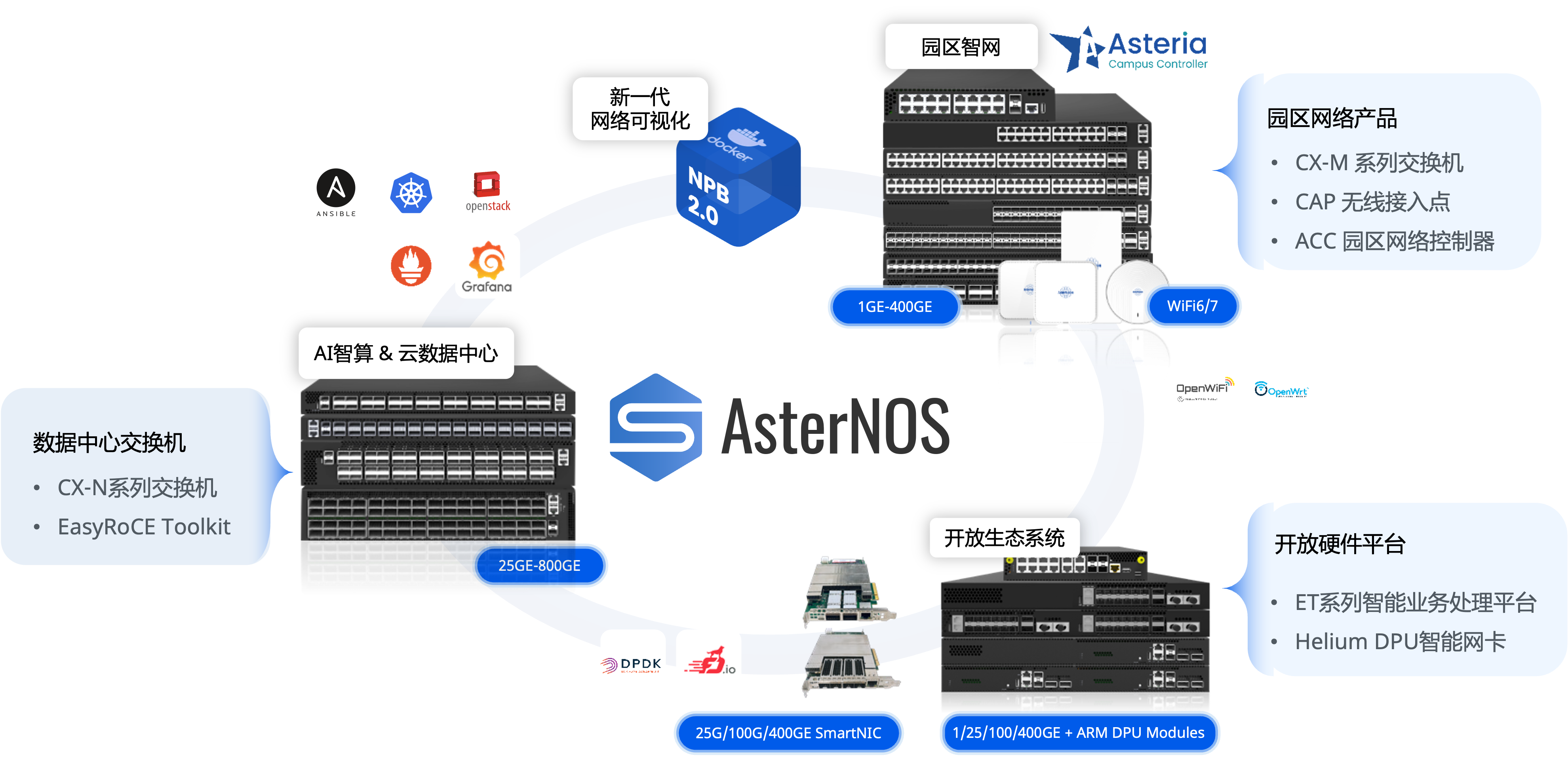
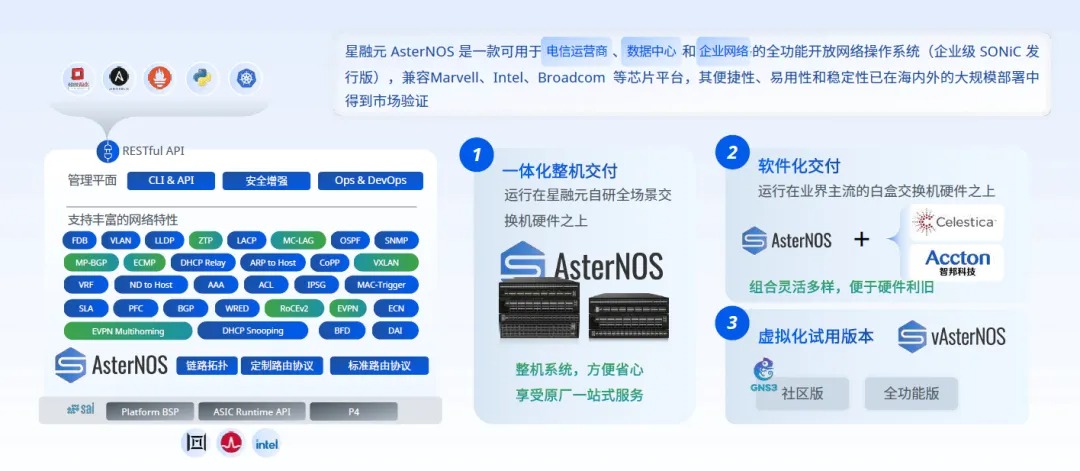
清明公休假稍瞬即逝,与“断点续传”的工作记忆一同到来的还有一年一度在深圳举办的中国电子信息博览会(CITE)。
借着这个电子信息产业最新产品和技术的国家级平台,我们将自研的(也是业内最尖端的)800G 51.2T RoCE 交换机首次带进了展会现场,并与华南地区的上下游企业,区域集成商合作伙伴进行了高密度的面对面交流。
短短三天,六米见方的展台里,我们经历了一次次来访者的试探、不解,甚至当面挑战,直到与我们建立起技术信任、向我们发出高层交流甚至现场测试的邀约。
这些有着不同技术市场背景和工作经历的来访者,往往理解行业、了解客户、知道问题、渴望答案——他们或在星融元的展台上找到了答案,或为星融元的持续创新带来了启发。

“都没听说过你们公司,有案例吗”
此次展会多数都是AI服务器系统集成商,其中一位来访者之前都是将服务器直接配置IB交换机整体打包给客户。年初由于DeepSeek的爆火他们接触到不少小规模算力组网需求,而当前国际市场环境下,采购英伟达IB交换机总归有点风险(别说之前还遭遇过6个月交付周期+超预算的困境)。他见我们是做RoCE网络的,于是带着存疑的态度前来咨询。
“都没听过你们公司,你们的产品在DeepSeek推理网有案例吗?”
接待他的同事结合自己对DeepSeek开源模型理解,就着刚刚完成的基于星融元CX732Q-N(400G)的详细组网方案给这位集成商介绍起来——我们的组网方案比起其它RoCE友商64口400G和32口400G成本更优;又如我们此前为沐曦C500 DeepSeek做的组网方案,一台机器可以将训练网、存储网、业务网融合,简单到网络即插即用,完全可以替换IB,成本至少降低了三分之一;结合最近中美关税政策,能降低一半。

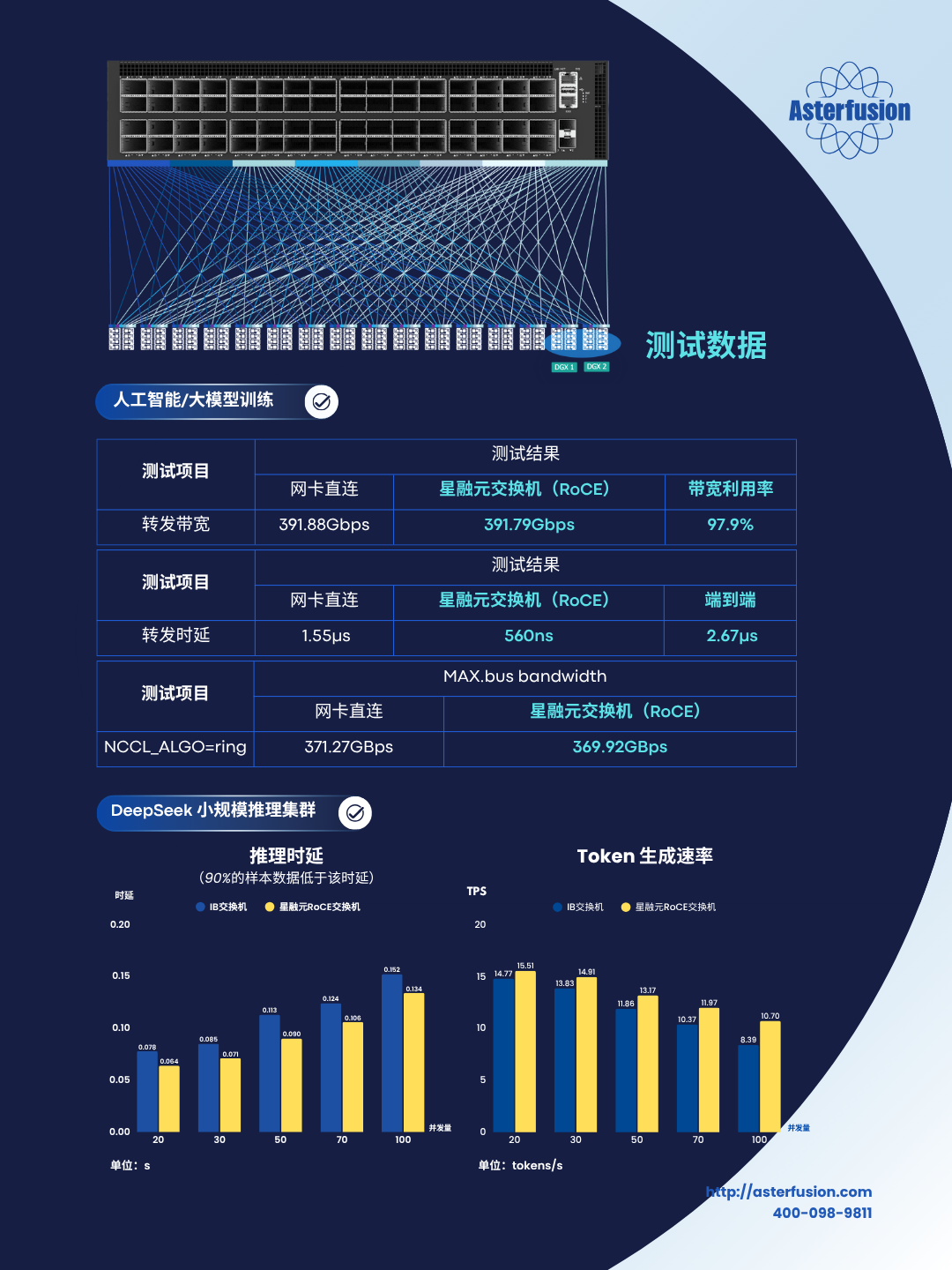
至于性能,我们直接向他展示CX-N系列交换机与IB在AI智算,HPC和分布式存储等场景的多个对比数据(–>测试报告参考)。一番沟通下来,这位项目经理直接与我们共享了之前给某运营商的DeepSeek AI硬件基础设施报价, 其中全套IB的网络价格直接与采购的AI服务器价格相近了,导致客户认为网络成本太高而没能顺利落单。
再细细核算一波,如果当时用我司设备组网,应该就能符合客户预期了。
“Hash不均你们怎么解决”
有位算力行业的客户来到我们展台,他虽非网络工程师,但对RoCE网络在算力场景下的IB替代趋势和面临的一些挑战已有不少了解。
与那位AI服务器系统集成商类似,他也问到了我们的RoCE网络相对其他的厂家优势所在,不过要更加具体。
“比如对于大模型中常见的hash不均,你们会怎么解决?”。他表示一般厂商会采用例如调整哈希因子之类的方式,但仅以他本人在项目中的感知,实际效果非常有限,不足以满足需求,想知道我们是否还有其他办法。
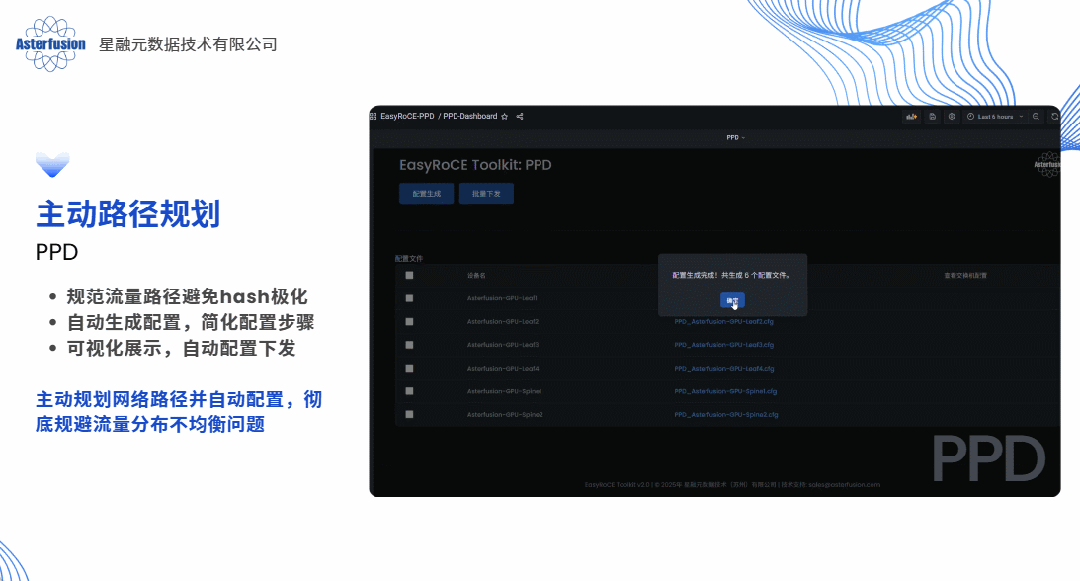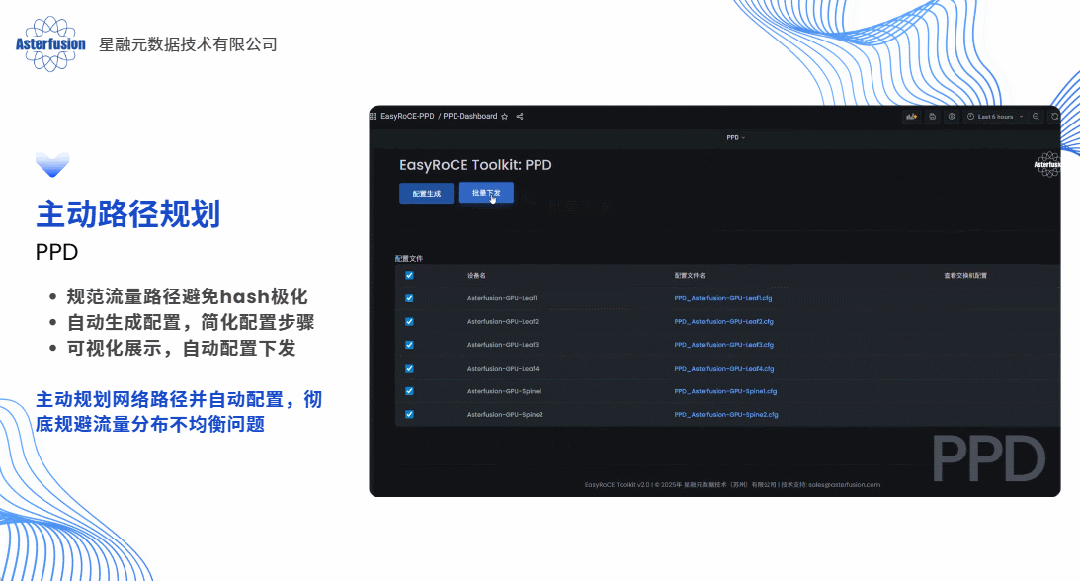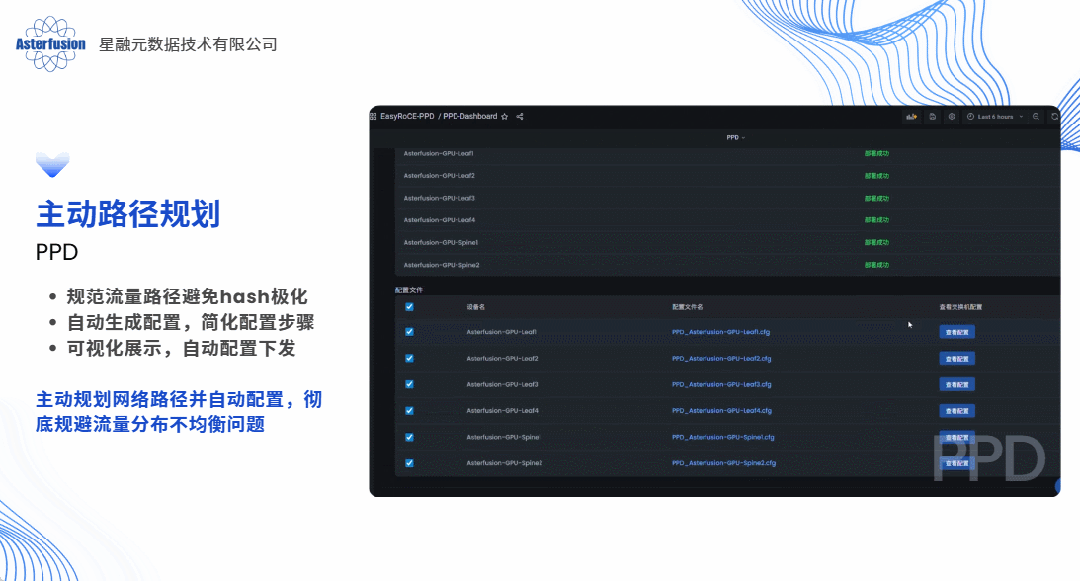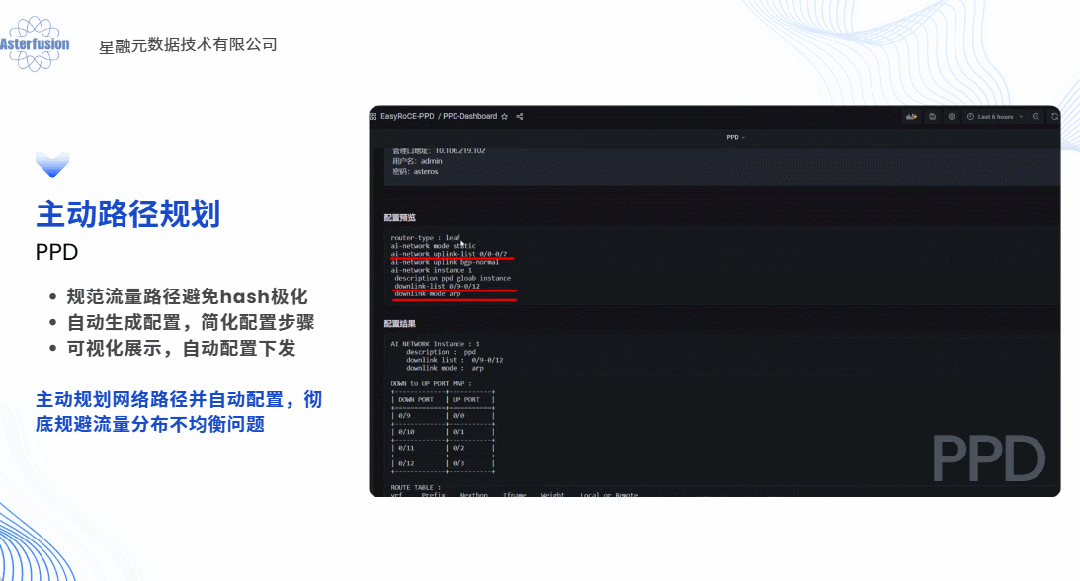
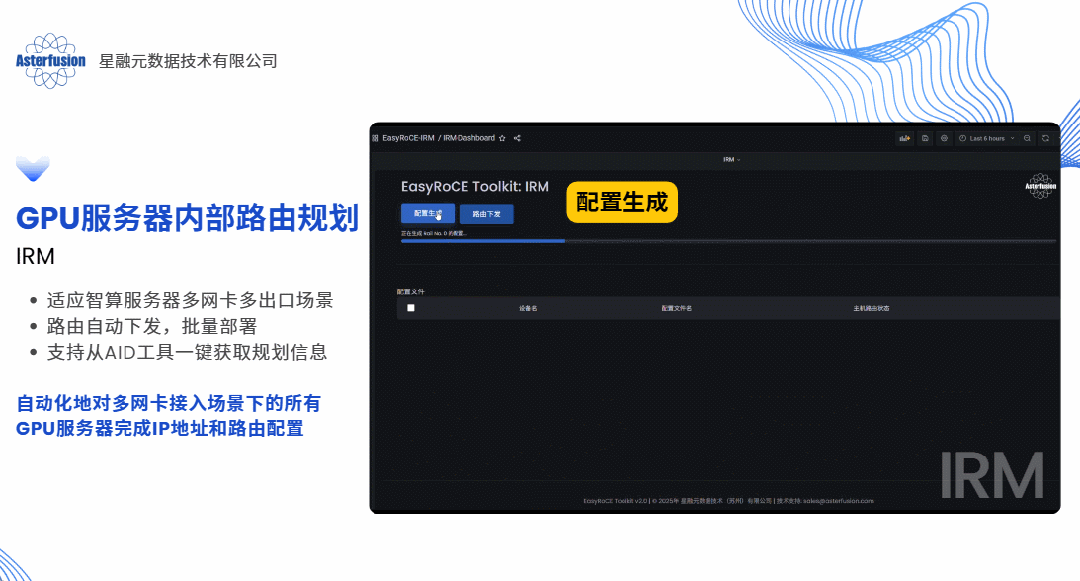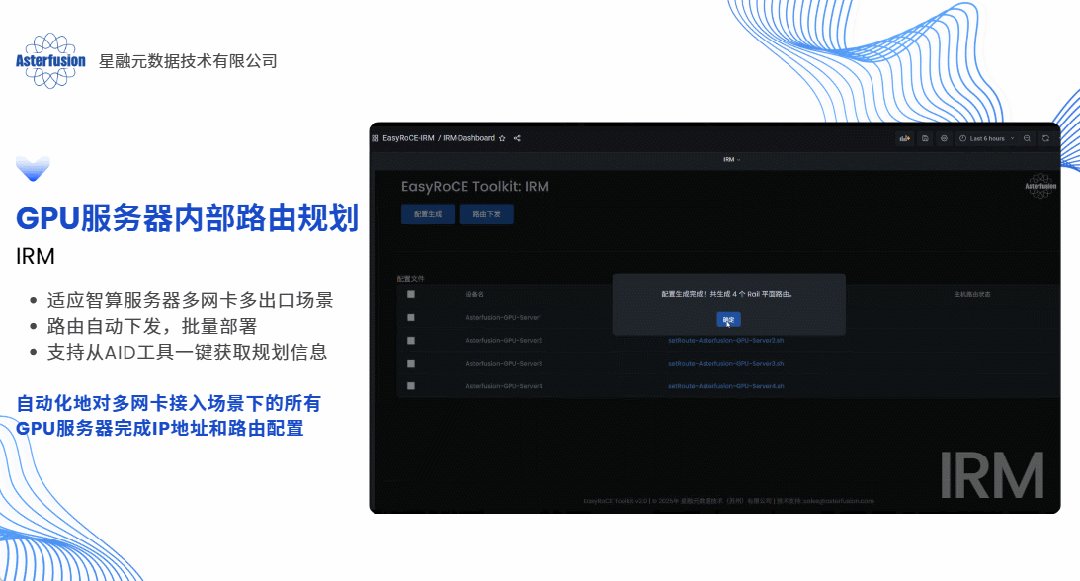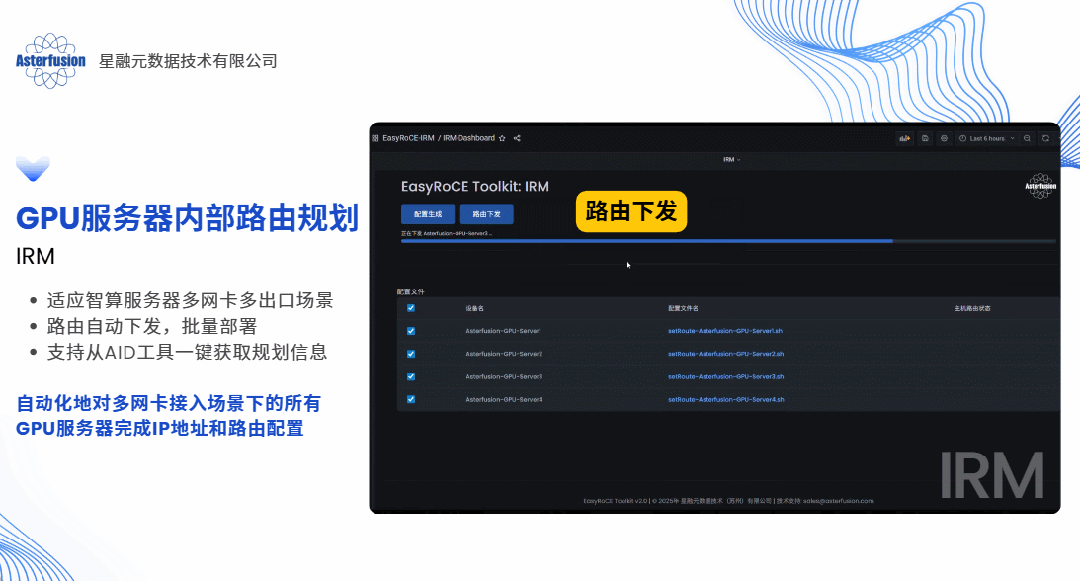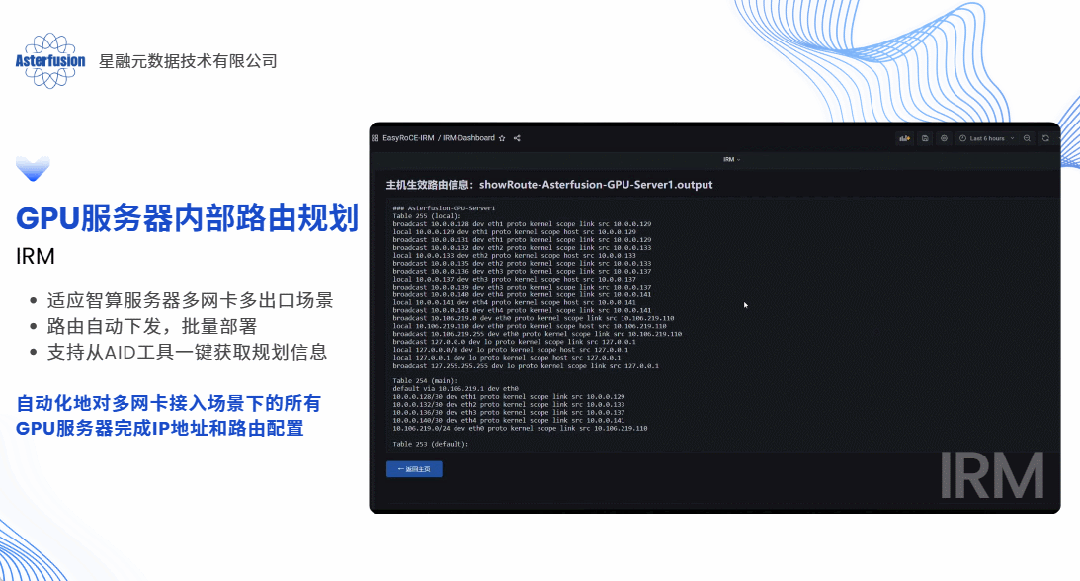
答案当然是肯定的,这几乎也是每个算力网络运维架构师都会问到我们的问题。具体来说,如果以软件方式实现,我们完全可以采用“主动规划”的思路为每条业务流提前规划路径,预先设置,生成脚本一键下发,就像提前给每辆车固定住了行驶的路线并且自动为客户设备加载路由条目,这便是开放网络的技术路线带给客户最直观的价值体现之一。
除了主动规划,还可以结合硬件能力的实现类似“自动驾驶”(动态哈希)方案,就好比让每辆车自动选择不堵车的线路和选择多种解决hash不均的实现以适应不同的使用场景。
可惜时间场地受限,我们没法在这个闹哄哄的展台长时间地交流。互相交换联系方式后我们推荐他关注微信公众号(与他谈到的产品动态和技术分享多少都能在日常更新里找到),之后再预约时间深度交流,探讨合作空间。
相关阅读:解锁AI数据中心潜力:网络利用率如何突破90%?

“像IB一样好用的RoCE网络,真的吗”
一位年轻的工程师站在展台的EasyRoCE展示屏前面看了又看,似有疑虑但不知如何开口。主动上前三言两语聊下来,我们大概了解到这位工程师是华南的一家规模很大的系统集成商的网络方案架构师,这家集成商在网络方面的主要业务之一是为客户提供基于IB的网络方案,应用场景主要是高性能计算和最近两年爆火的AL/ML网络。
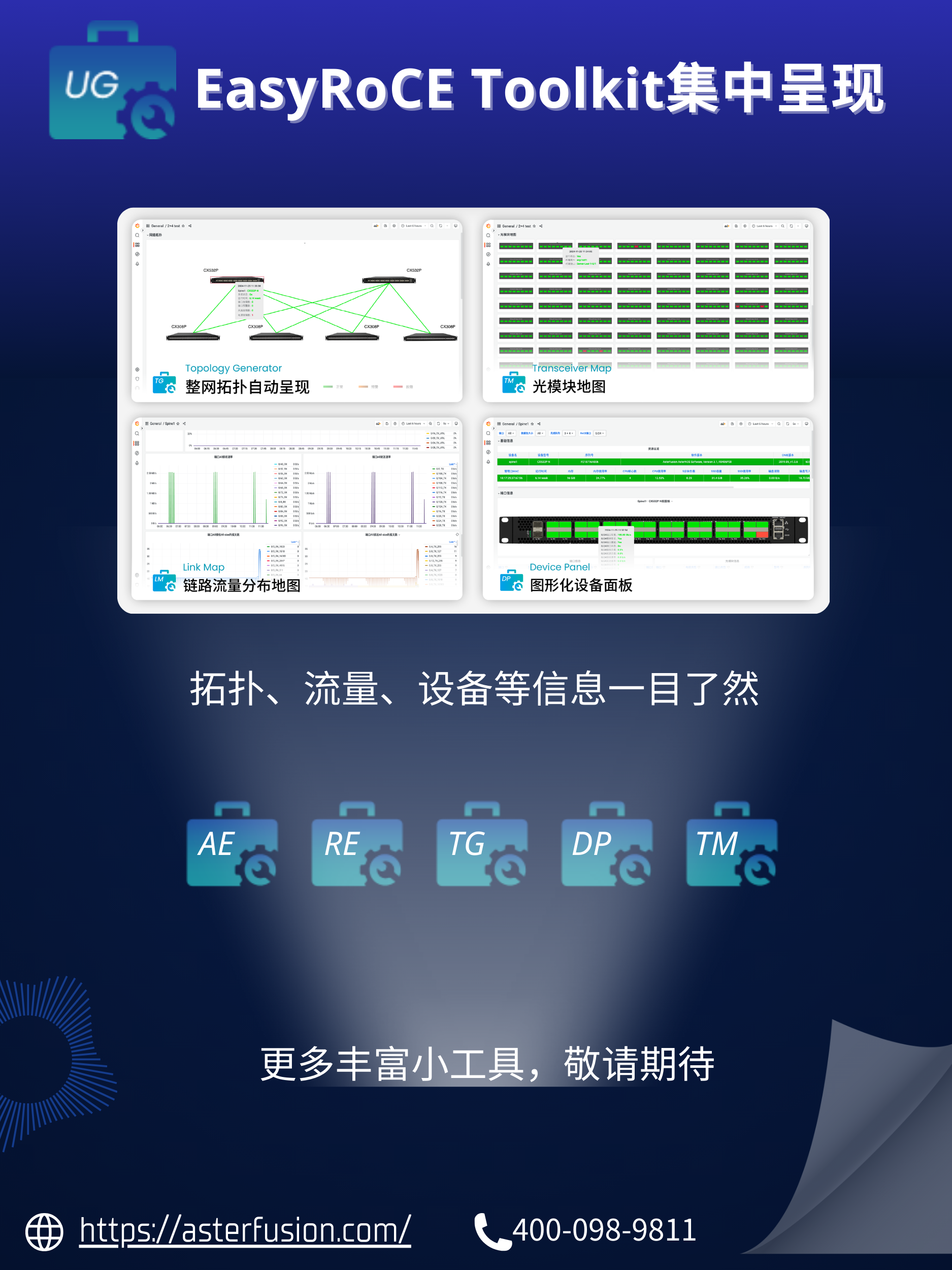
吸引这位工程师流连在星融元展台的主要原因是EasyRoCE提供的简捷部署和整体监控方案。作为一位技术从业人员,这位工程师对RoCE技术、方案与产品已有很深入的理解,但是往往在考察了市面上现有的方案,考虑到的部署、实施、运维、监控等环节的挑战之后,就被劝退了。
“我们的很多现场工程师往往只具备最基础的运维能力,不能要求他们具备在现场去分析、定位交换机的队列、水线以及它们之间复杂关联的能力,他们更需要在问题发生的时候能够一眼就看到故障点在哪里、然后快速解决……”,这位年轻人如是说。
在了解了EasyRoCE的工具集的各项能力之后,他表示能够感觉到这些工具解决的问题真的是在很多方案中都遇到过的。
“你们这个方案是不是可以替换UFM了?”
的确,EasyRoCE工具集可以说就是星融元RoCE方案的“UFM”。我们将自己在过往两三年中,在AI/ML的RoCE网络部署中踩过的坑、碰到的问题,结合我们的技术能力,全部工具化了,通过这些工具将RoCE赋能给合作伙伴和最终用户。
像IB一样好用的RoCE网络,这一点,我们来真的。

“这对IT运维排障人员太友好了!”
还是有关EasyRoCE。
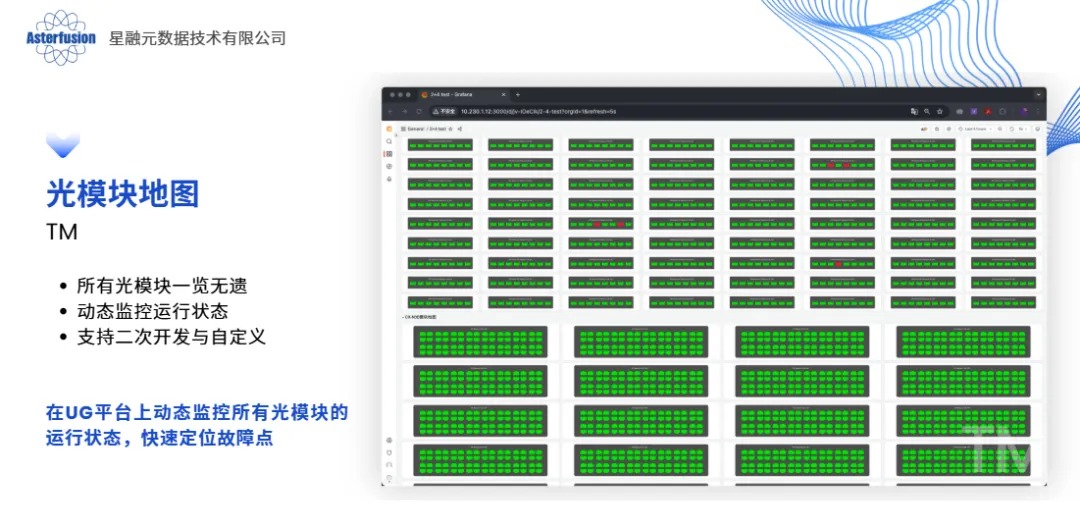
在给某华南地区数据中心IT负责人介绍EasyRoCE多个小工具的时候,他看到光模块地图立刻叫了暂停,跟我们确定地图上的不同颜色是否表示交换机的光模块的运行状态。在得到肯定答复后他忍不住感叹:再也不用收到网络故障通知后,不管三七二十一先挨个ssh到交换机上去show一下全局接口状态了。“通过光模块地图一眼就可以排除物理因素,并且直观定位故障模块,这个东西对IT运维排障人员太友好了!”
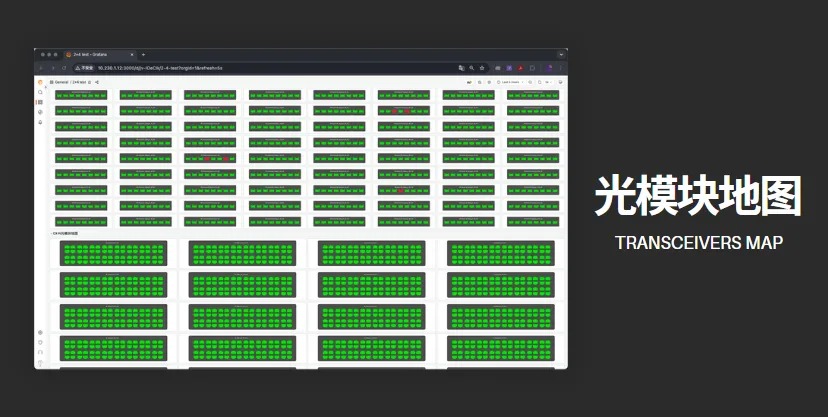
“几百万的设备怕是还不如你们的SONiC交换机”
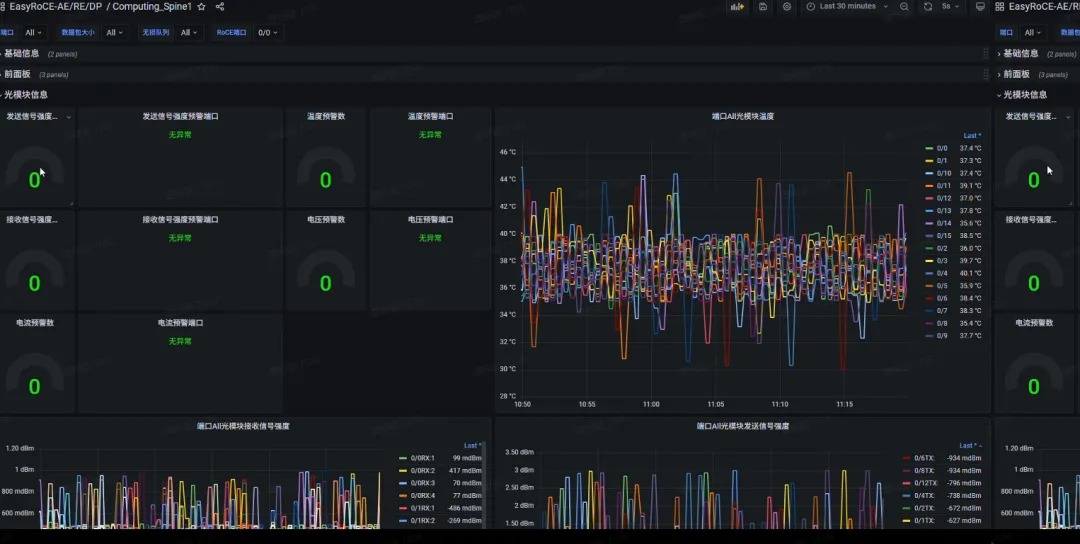
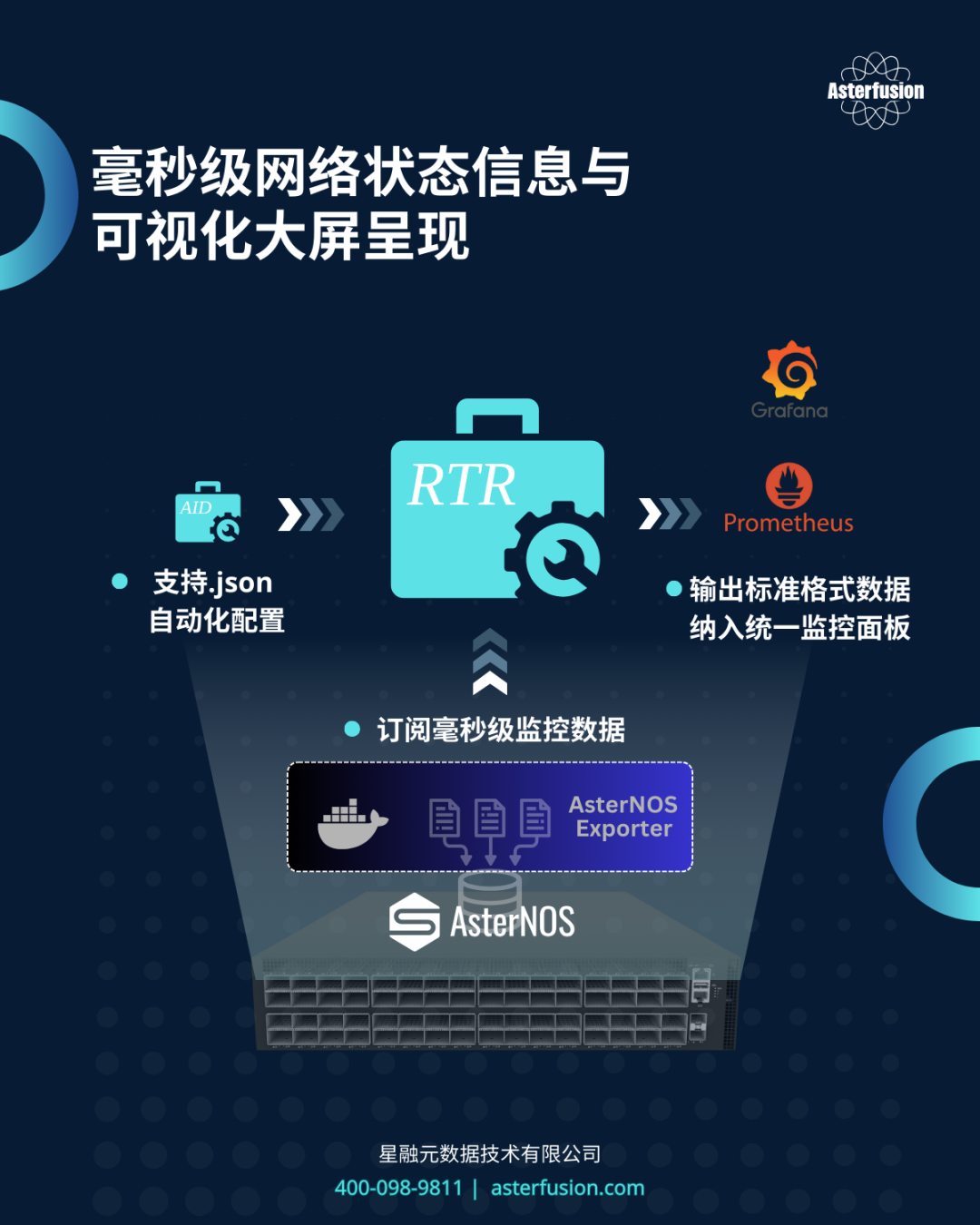
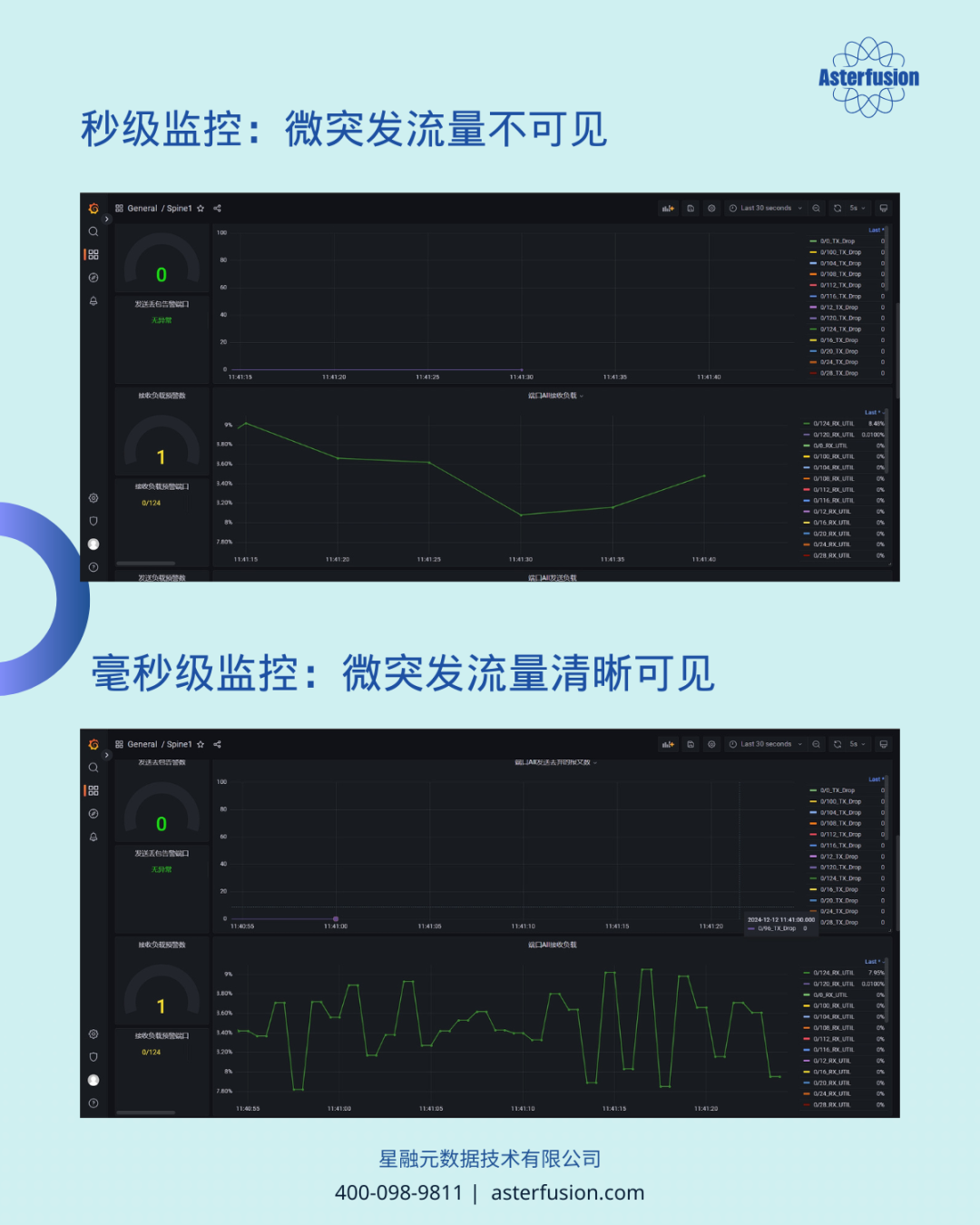
一位国内某量化交易公司的一线工程师在前台拿着彩页仔细看了好一会儿,才指着”高精度监控”向我们发问。算力系统经常出现毫秒级延迟波动,传统网管工具完全无法定位。于是我们引导他前往展示区,结合远程演示环境和数据,现场介绍如何捕捉由微突发引发的丢包。
“原来我们每年花几百万买的’高端设备’,精度还不如你们一台白盒交换机!” 虽不知他们到底买了什么高端设备,但得到这样的评价我们还是十分高兴的,也期待后续有机会在他们的新建网络中展示开放网络的更大潜力。
“这小盒子玩得挺花,说不定我能用上”
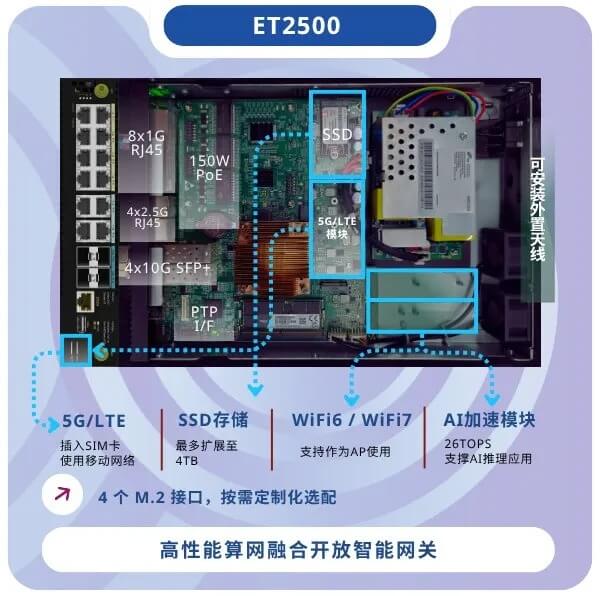
800G 交换机之外,我们还带了一台半宽的开放硬件平台:ET2500。这款设备我们尚未正式在国内市场发布,初步定位的场景是部署在企业出口,作为算网融合开放网关承担从路由器、防火墙到网络流量分析器的全部功能,替代原本用价格不菲的多台专用设备串联而成的出口架构。
不过,它的玩法绝不止于此——小小的盒子提供1G/2.5G/10G接口,内置了PoE模块、PTP模块、5G/LTE模块,还能选配AI 加速卡和WiFi7/6E模块和外置天线,加之上层运行的标准Linux和我们定制优化的DPDK/VPP软件包(已开源),给足了用户想象空间。
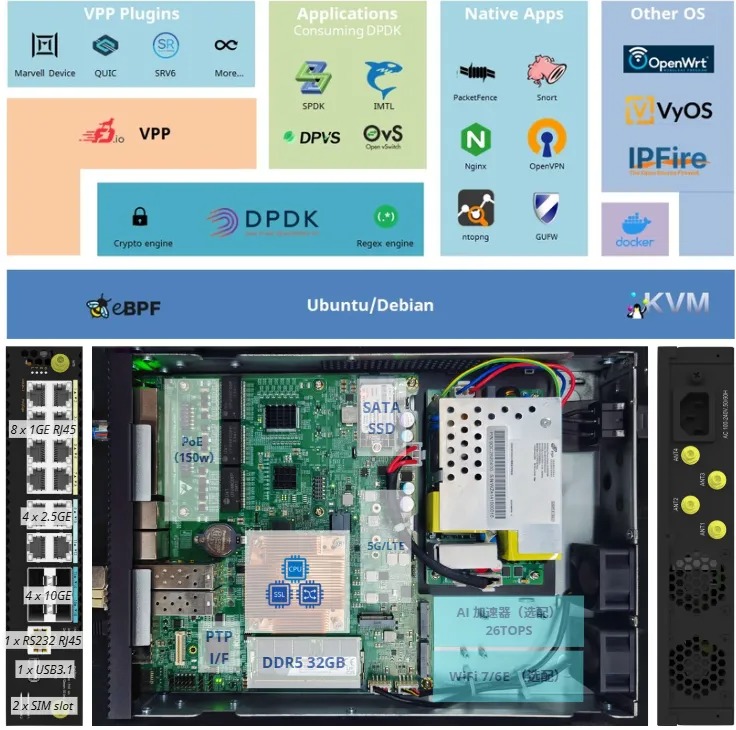
有位路过的客户转头一瞥就被我们的ET2500外观吸引住了,左右打量半天,开口问的第一个问题是,这个小盒子能帮我做算力调度吗?
接着就畅谈他们的业务场景:算力调度网络,把分布在全国的零散算力资源统一调度起来,分布式计算的场景和ET2500(以及此前发布的 CX102S-DPU)天然契合——小盒子里面的三颗芯片协同工作,可以帮他们极大减少边缘部署的设备数量和复杂度。经过一番业务场景的沟通和探讨之后,他对这款小盒子非常感兴趣,留下了联系方式并表示后续要再交流探讨。
电博会上与星融元偶遇的这些人,那些事,再一次坚定了我们用高效、实用的开放网络技术栈帮助各行业客户切实解决问题的信心,并将其作为星融元在这个充满着挑战和机遇的全球市场上不变的生存与发展之道。