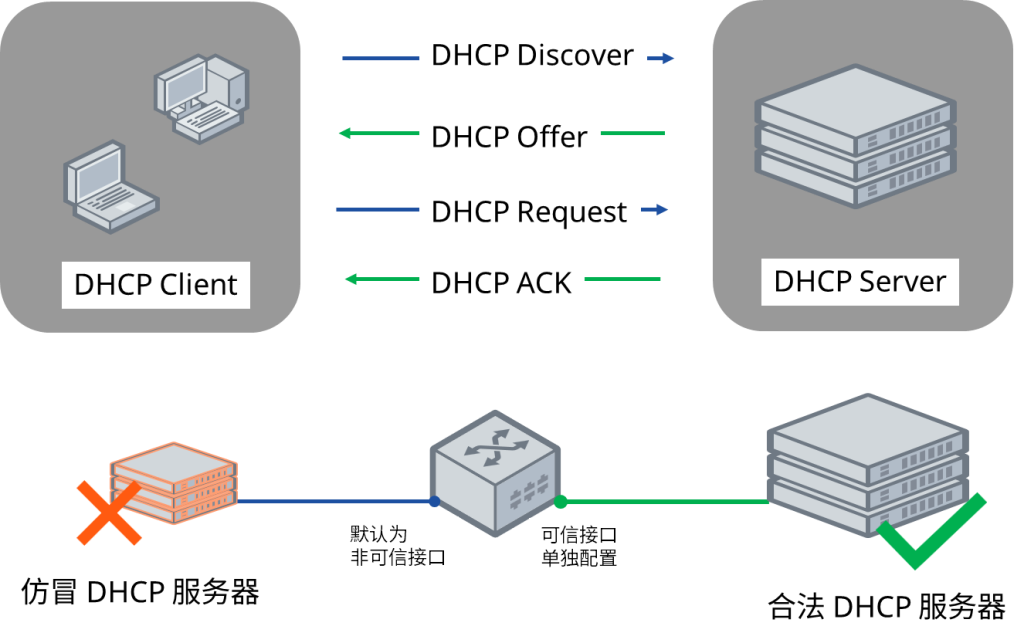
DHCP侦听(DHCP snooping)是一种部署在以太网交换机上的网络安全机制,用于阻止未经授权的 DHCP 服务器为客户端分配 IP 地址。该机制通过检查 DHCP 消息并仅允许来自受信任端口的 DHCP 消息通过,从而防止非法 IP 地址分配,确保网络环境安全稳定。
为什么需要DHCP侦听?
在企业、校园甚至公共网络中,与 DHCP 相关的问题并不少见,而且它们可能会造成严重的网络中断。有时,仅仅是配置错误的设备意外地充当了 DHCP 服务器,分配了错误的 IP 地址,导致连接中断。有时,问题更为严重,例如攻击者设置了恶意 DHCP 服务器,通过虚假网关或 DNS 服务器重新路由用户,从而为中间人攻击打开了方便之门。即使是客户端手动为自己分配静态 IP 地址,也可能造成混乱,引发冲突,并使网络安全管理更加困难。
项目
DHCP
静态 IP
分配方法
由服务器自动分配
手动配置
管理努力
低,适合大规模部署
高,需要单独设置
解决稳定性问题
每次设备连接时可能会发生变化
固定不变
设置效率
快速、即插即用
速度慢,需要手动输入
适合
最终用户设备、动态环境
服务器、打印机、关键设备
安全
需要配合保护机制(例如 DHCP 侦听)
更可控,但有手动配置错误的风险
DHCP 侦听的好处:
阻止恶意 DHCP 服务器干扰网络。
确保客户端收到准确的 IP 地址和网络配置。
通过降低攻击风险来增强网络安全。
DHCP 侦听如何工作?
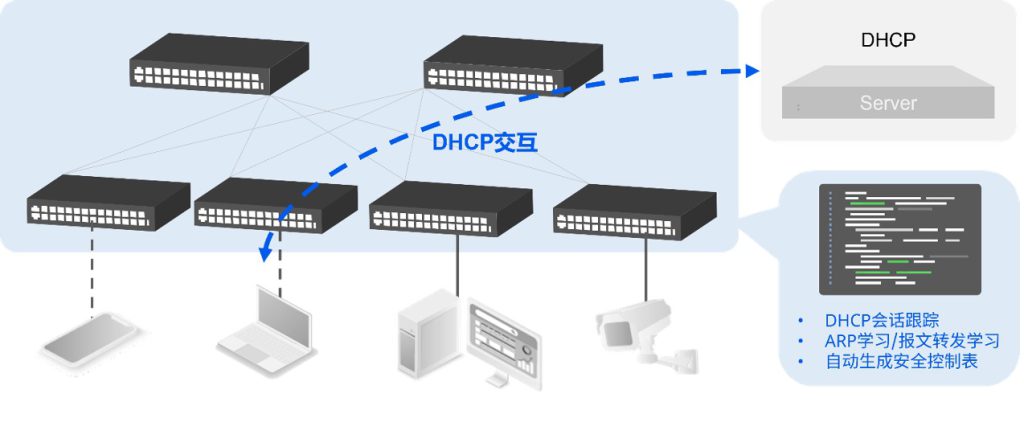
要真正理解DHCP 监听的工作原理,首先必须清楚了解DHCP(动态主机配置协议)的工作原理。当设备加入网络且尚未获得 IP 地址时,它会发起与 DHCP 服务器的对话——这是一个四步握手过程,包括:发现 (Discover )、提供 (Offer)、请求 (Request)和确认 (Acknowledge )。可以将其视为设备和服务器之间获取 IP 身份的快速协商过程。下图详细分析了此动态交换过程中每个步骤的具体细节。
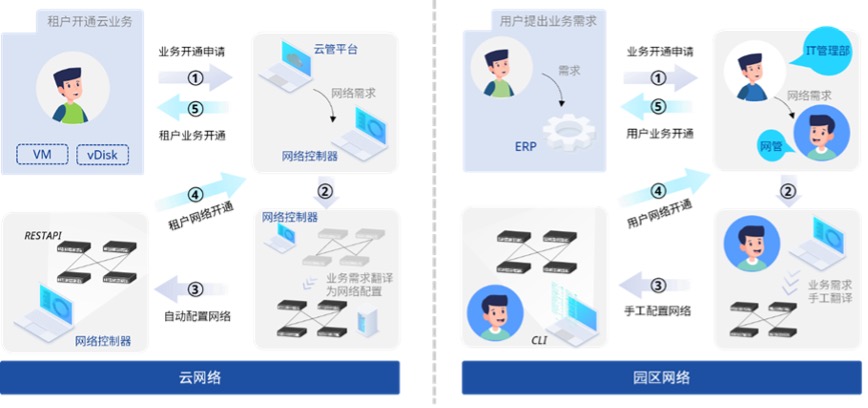
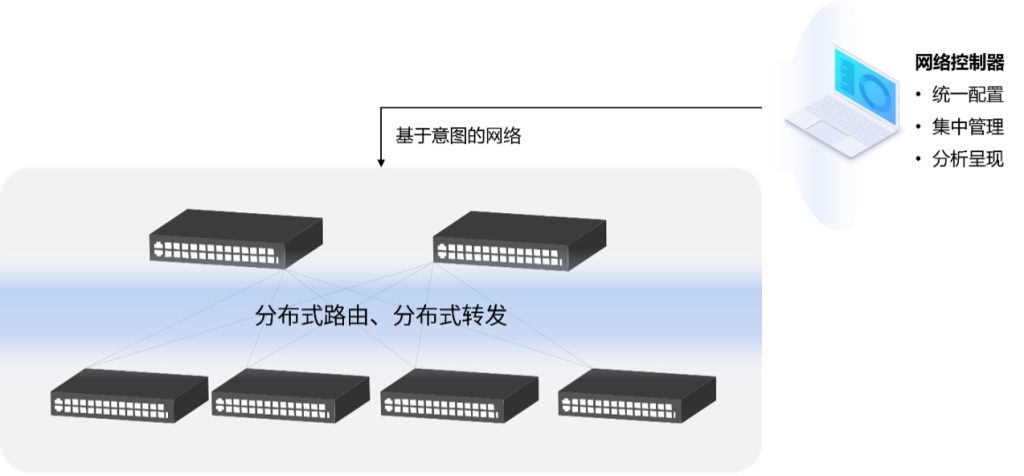
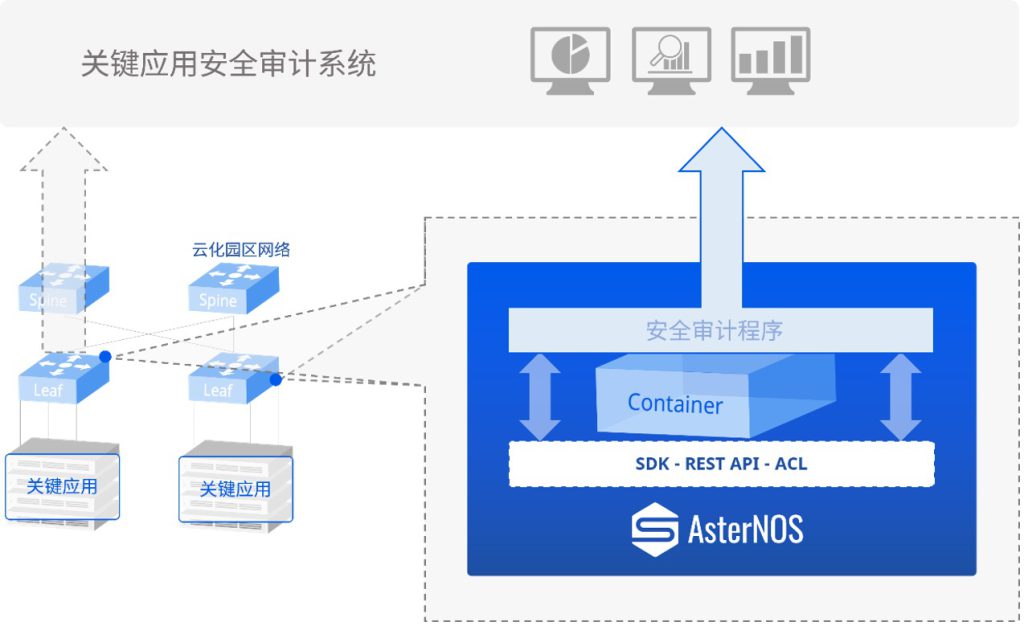
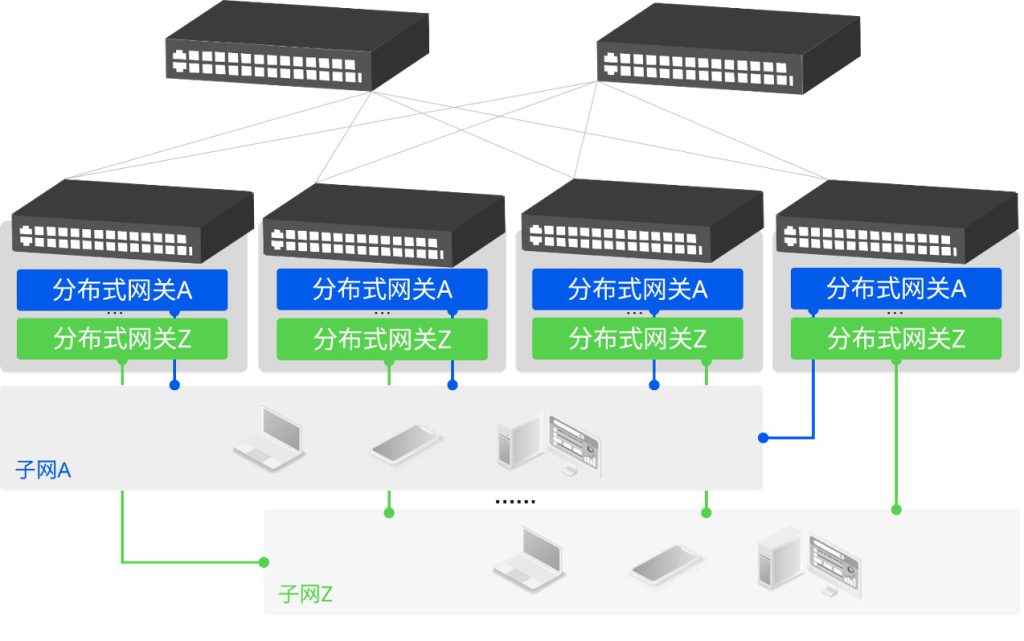
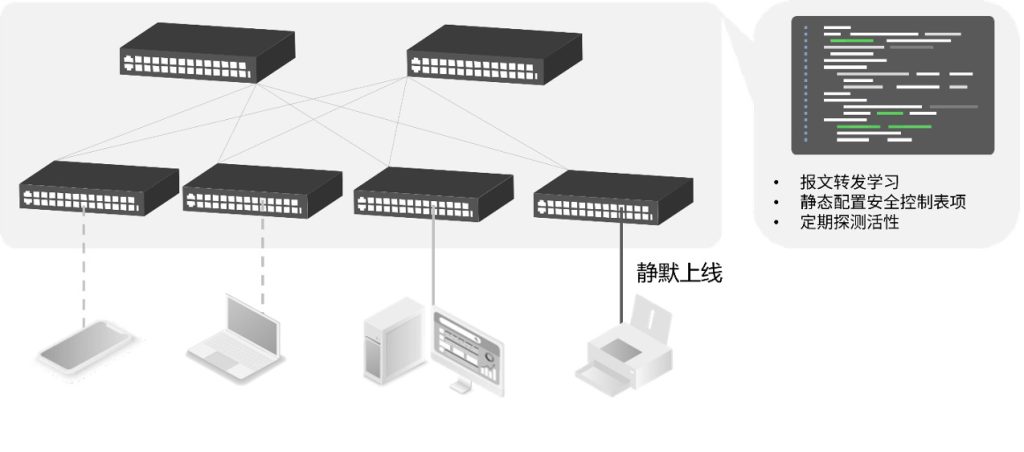
星融元的云化园区网络解决方案,通过一个开源、开放架构(基于OpenWiFi)的网络控制器来为有线无线网络设备下发配置,进行开局配置时在交换机上会默认开启DHCP Snooping,有效防止 DHCP Server 仿冒者攻击,使 DHCP 客户端能够通过合法的DHCP 服务器获取 IP 地址,管理员无需关注不同设备的信任接口与非信任接口,而是通过控制器的拓扑信息自动生成。
根据当前网络的所需的安全等级,管理员可在控制器界面上自行选择是否还需要开启ARP检测(DAI)和IP源攻击防护(IPSG)功能,该功能主要是通过全局的 DHCP Snooping 表项判断主机是否合法,不仅可以防止恶意主机伪造合法主机访问网络,同时还能确保主机不通过自己指定 IP 地址的方式来访问或攻击网络,造成可能的IP 地址冲突。
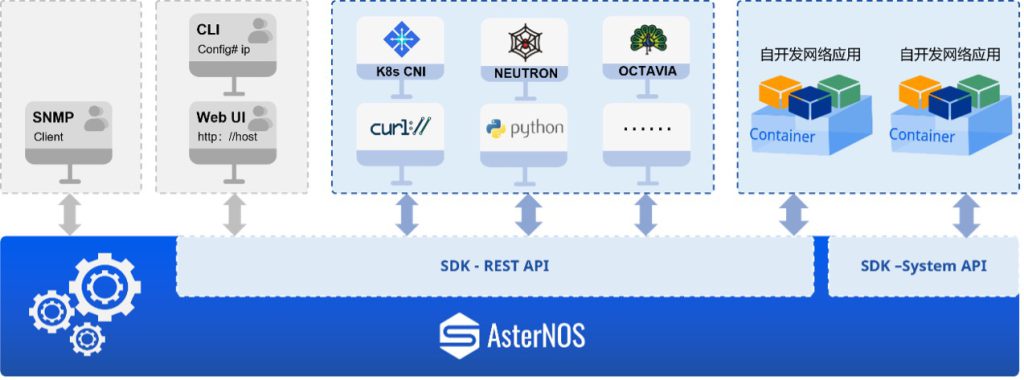
SONiC(Software for Open Networking in the Cloud) 是开源社区的网络操作系统,其核心目标是构建开放、解耦的云数据中心网络架构。作为全球首个完全开源的网络操作系统,SONiC基于Linux内核设计,支持标准化硬件(如白盒交换机)与容器化微服务架构,通过模块化组件(如SAI——交换机抽象接口)实现灵活的功能扩展。其开源特性吸引了全球云服务商、运营商及企业的广泛参与,逐步成为云原生网络的事实标准。
尽管社区版 SONiC 通过模块化设计为云数据中心提供了开放灵活的基础架构,但其在复杂协议支持上的短板始终制约着企业级场景的深度应用。以MPLS为例,社区版本需依赖第三方扩展或定制化开发,导致功能碎片化、性能不稳定,难以满足金融专网、跨云互联等高可靠性需求。
AsterNOS基于 SONiC 的开放式园区交换机的完整产品组合现在完全支持 MPLS,它提高了数据包转发速度,支持精细的流量控制,并支持多协议环境,使其成为电信、企业 WAN 和云数据中心中的大规模网络不可或缺的工具。
LLM 训练是一项 GPU 高度密集型工作负载,对 CPU 工作负载要求低。CPU 运行是一些简单任务,例如 PyTorch ,控制 GPU 的其他进程、初始化网络和存储调用,或者运行虚拟机管理程序等。Intel CPU 相对更容易实现正确的 NCCL 性能和虚拟化,而且整体错误更少。如果是采用AMD CPU ,则要用 NCCL_IB_PCI_RELAXED_ORDERING 并尝试不同的 NUMA NPS 设置来调优。
2、 RAM 降级到 1 TB
RAM 同样是计算节点中相对昂贵的部分。许多标准产品都具有 2TB 的 CPU DDR 5 RAM,但常规的AI工作负载根本不受 CPU RAM 限制,可以考虑减配。
3、删除 Bluefield-3 或选择平替
Bluefield-3 DPU最初是为传统 CPU 云开发的,卖点在于卸载CPU负载,让CPU用于业务出租,而不是运行网络虚拟化。结合实际,奔着GPU算力而来的客户无论如何都不会需要太多 CPU 算力,使用部分 CPU 核心进行网络虚拟化是可以接受的。此外Bluefield-3 DPU 相当昂贵,使用标准 ConnectX 作为前端或采用平替的DPU智能网卡完全可满足所需。
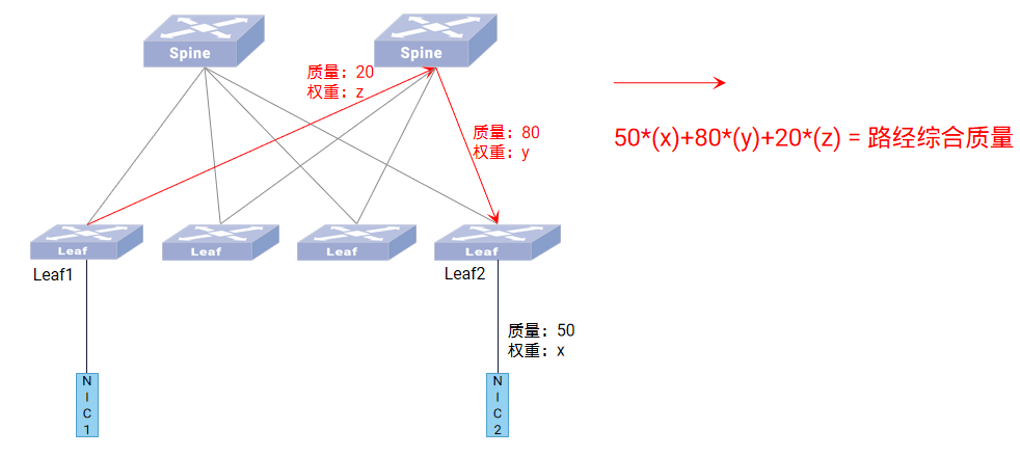
轨道优化拓扑的另一个好处可以超额订阅(Oversubscription)。在网络架构设计的语境下,超额订阅指的是提供更多的下行容量;超额订阅率即下行容量(到服务器/存储)和上行带宽(到上层Spine交换机)的比值,在 Meta 的 24k H100 集群里这个比率甚至已经来到夸张的7:1。
通过设计超额订阅,我们可以通过突破无阻塞网络的限制进一步优化成本。这点之所以可行是因为 8 轨的轨道优化拓扑里,大多数流量传输发生在 pod 内部,跨 pod 流量的带宽要求相对较低。结合足够好的自适应路由能力和具备较大缓冲空间的交换机,我们可以规划一个合适的超额订阅率以减少上层Spine交换机的数量。
但值得注意的是,无论是IB还是RoCEv2,当前还没有一个完美的方案规避拥塞风险,两者应对大规模集合通信流量时均有所不足,故超额订阅不宜过于激进。(而且最好给Leaf交换机留有足够端口,以便未来 pod 间流量较大时增加spine交换机)
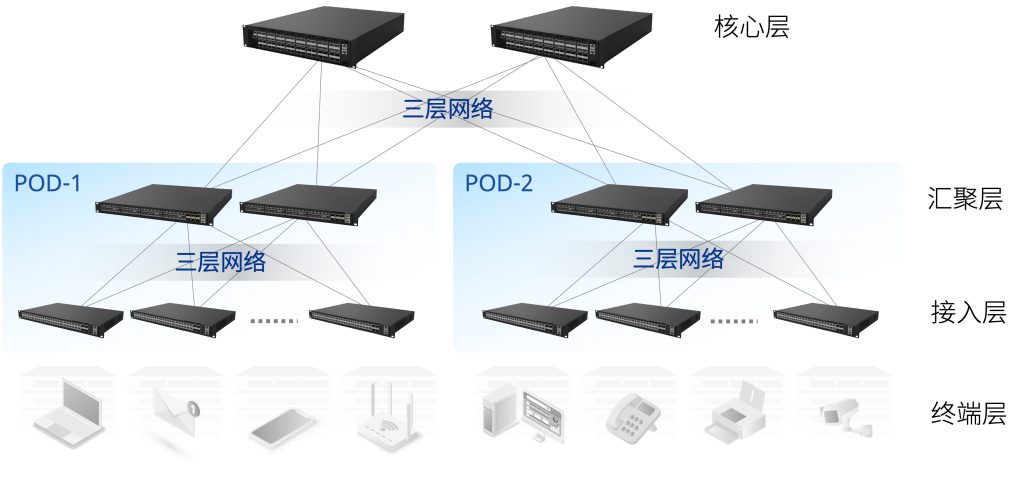
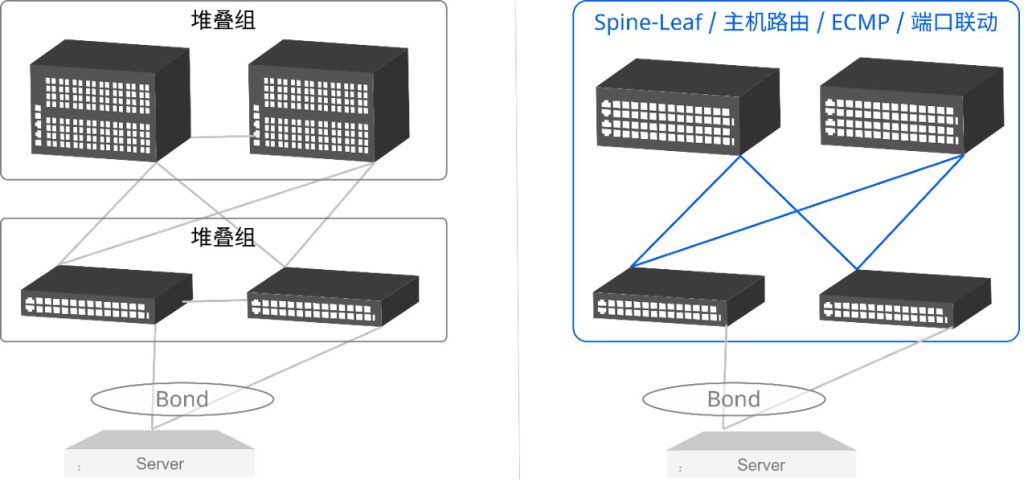
底层硬件平台基于开放架构、商用可编程交换芯片设计,在为上层软件提供高性能运行环境的同时,彻底抛弃传统网络硬件私有、黑盒的设计理念。更加值得一提的是,星融元云网络的整体架构设计完全遵循了业界最领先公司广泛部署和使用的Scale-wide架构(按需自由扩展架构),将原本封闭在大型机架式网络设备中的CLOS交换架构开放到网络拓扑设计当中,帮助用户在只采用盒式网络设备的前提下仍然能够搭建出大规模的扁平化云网络,使用户在享受高性能、按需自由扩展的同时,最大限度地降低云网络的TCO(Total Cost of Ownership,总拥有成本)。
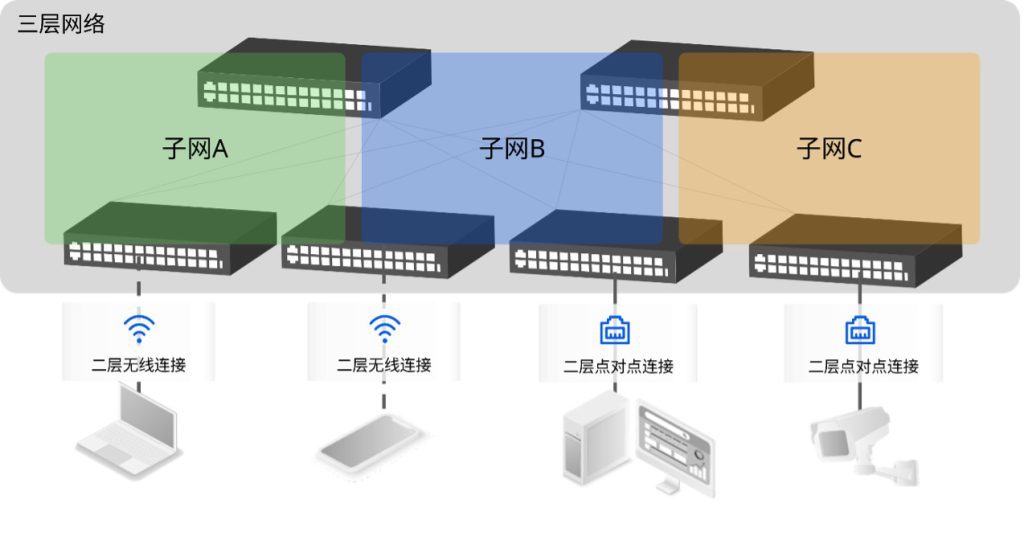
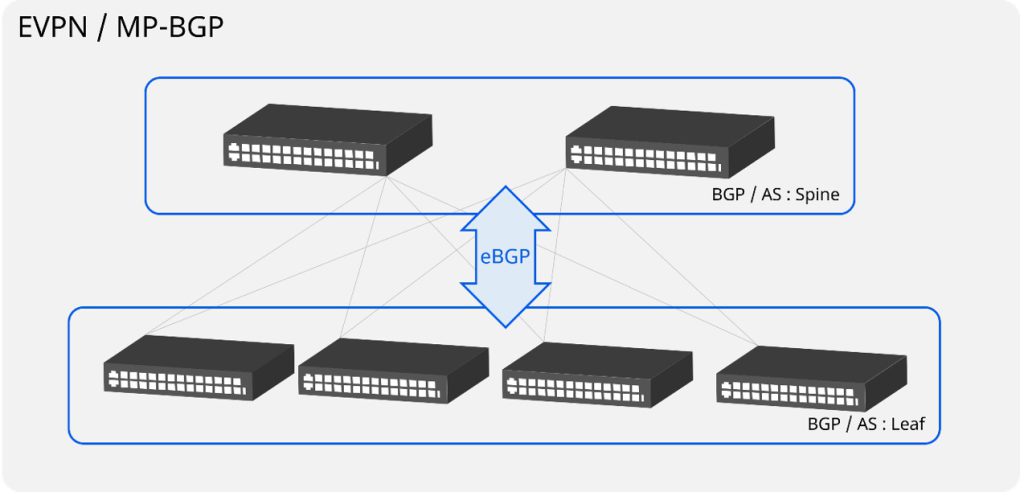
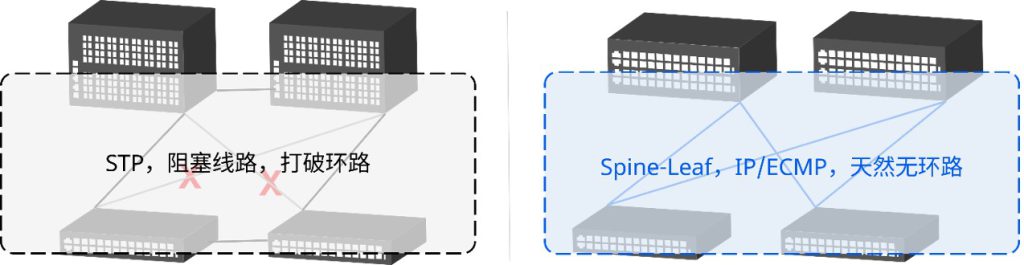
以太网工作在网络参考模型的二层(Layer 2,简写为L2),其大部分交互逻辑建立在广播这种机制之上,因此是一种高效的通信协议。为这种高效所支付的代价是,当在一定范围内(例如,跨越两台以上的交换机)部署以太网时,需要将广播报文在不同的交换机之间传播,由此则带来了潜在的广播风暴风险;为了规避这种风险,又出现了类似于STP(Spanning Tree Protocol,生成树协议)及其各种相关的协议和保护机制。由此,大规模部署的二层以太网结构变得越来越复杂、健壮性变得越来越差,建设和维护成本都高居不下。究其根本原因,基本可以认为是(大范围的二层)广播导致了这一切的发生。更为严峻的是,很多网络安全漏洞,都是利用以太网的广播机制工作的。那么,在不破坏以太网基础工作原理的基础之上,如何解决这个问题?





架构-300x137.png)
CX864E-N交换机1-300x159.png)
CX864E-N交换机2-300x106.png)
星智AI网络解决方案-300x109.png)

2-300x109.png)
1-300x87.png)
2-300x106.png)