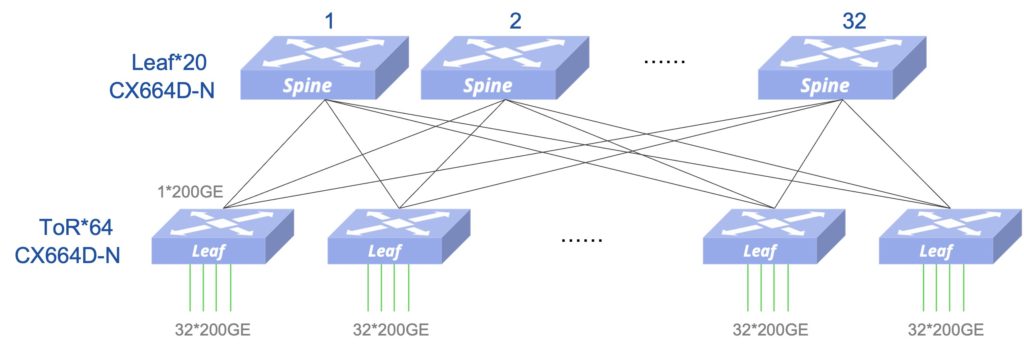
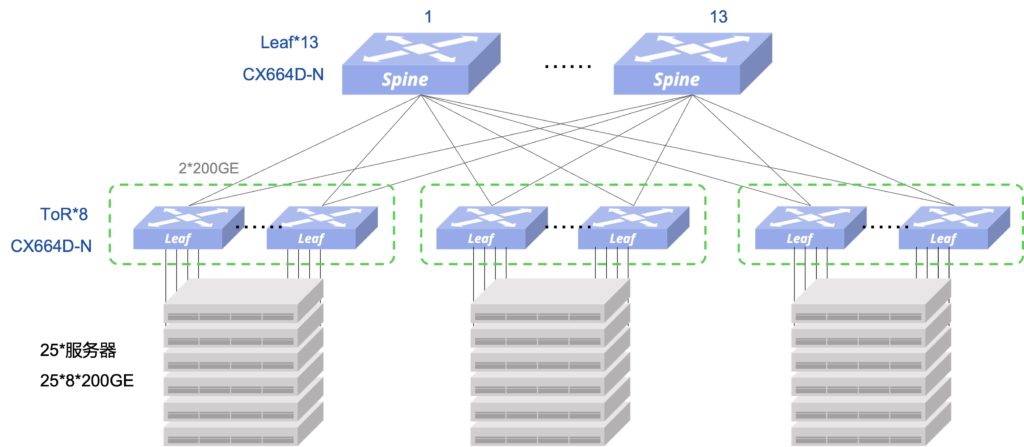
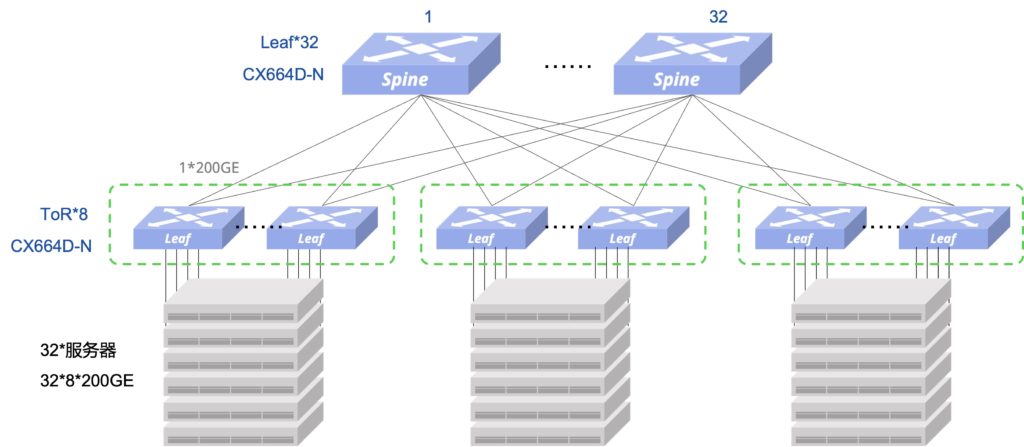
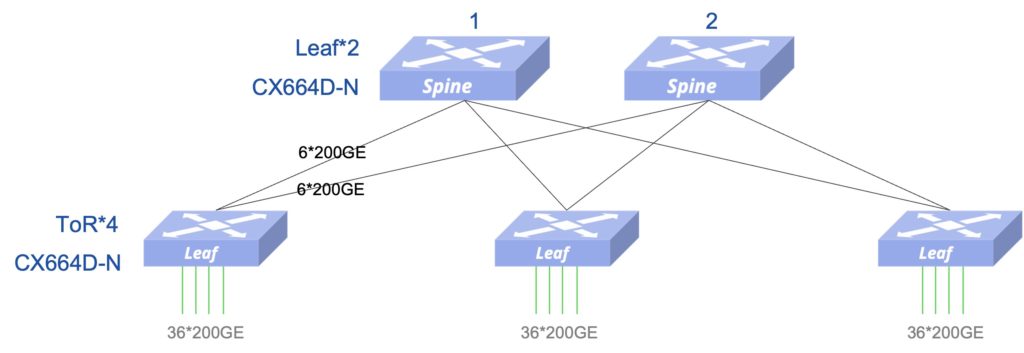
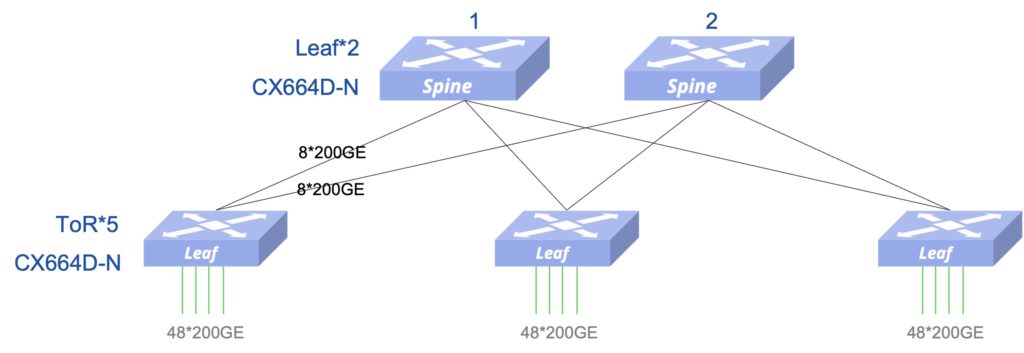
为简化无损以太网的部署和运维,星融元推出“一键RoCE”
关注星融元

故事是这样的
甲方爸爸李工是一名存储行业资深的网络工程师,多年的工作经验让他在服务器上玩得起飞,交换机方面,平时使用的多是 IB 交换机,只会插插线。自从发现IB交换机越用越不爽之后,转向了RoCEv2低时延无损以太网解决方案。但是对接过程中李工也发现,无损以太网络香是真香,但是配置方面也真心不太懂,简直一个大写的懵。
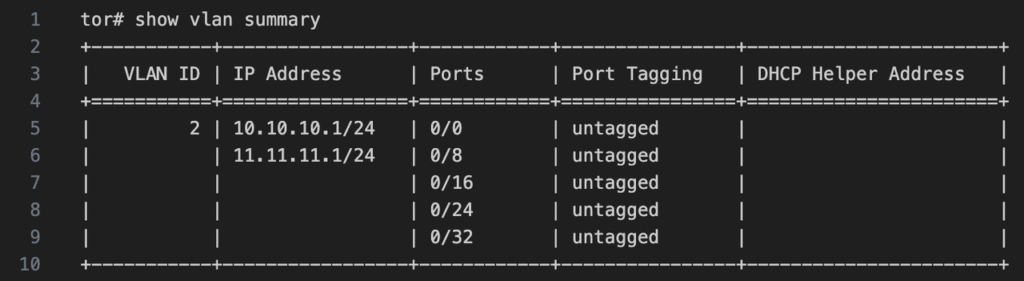
星融元的“一键RoCE”
RoCEv2技术支持在以太网上承载RDMA协议,实现RDMA over Ethernet,但需要网络侧支持无损以太网。目前,星融元网络操作系统AsterNOS使用标准的PFC+ECN来实现无损以太网。在以太网交换机上配置PFC、ECN功能,需要用户熟悉QoS机制、配置逻辑和相关命令行。
对此,星融元针对RoCEv2场景的配置需求进行设计规划,推出一键RoCE,实现了业务级的命令行封装,以达到RoCEv2场景下最佳的可维护性和可用性。
继提供高性价比低时延交换机产品替代方案后,在产品的使用和运维上,星融元进行了网络部署的升级,降低工程师们的运维复杂度,让用户聚焦于业务。
一键启用PFC和ECN,完成无损网络配置
没有一键RoCE配置命令行时,一线实施和运维工程师配置无损网络或者取消配置,需要分别修改PFC和ECN的配置。通常情况下,要配置PFC和ECN,需要工程师理解QoS的配置逻辑和步骤,这对工程师有着一定的网络知识要求。
有了一键RoCE配置命令行后,工程师可以通过一条命令行完成无损网络配置,不需要再使用原子级的命令行,对PFC和ECN进行配置。
无损网络的配置和运行状态,集中展示
在以前运维无损网络时,如果想要进行网络异常定位或者运行状态检查,通常需要到不同命令行视图下进行执行多次show命令,以确定当前的队列映射关系、Buffer使用情况、PFC和ECN在哪个队列中被启用、各种门限的数值、PFC和ECN所在队列的吞吐量、Pasue和CNP报文的触发次数等信息。
现在工程师可以通过show roce命令打印全局的RoCE信息、端口的RoCE信息和计数,以及对RoCE相关计数进行统一清零。
不同业务场景下的参数调优
通过一键RoCE命令行,可以快速配置无损网络,当业务场景不满足于设备提供的默认模板配置时,工程师仍然可以通过qos命令行精细化地调试PFC和ECN的各项参数,让当前业务场景的性能达到最优。
一键RoCE的可应用场景
简化高性能计算和存储网络的部署
一键RoCE的使用对于需要高性能网络传输的应用程序非常有帮助,如高性能计算、存储、大数据分析和人工智能、云计算等领域。它可以提供比传统以太网更高的吞吐量和更低的延迟,从而为这些领域的应用程序提供更高的性能和效率。
高性能计算和存储业务场景中,工程师通常对业务非常熟悉,集中精力在服务器侧的配置调优,对于网络,通常提出的要求是“需要一张高可用、高性能的无损网络”。针对这种情况,高性能计算和存储工程师可以通过一键RoCE命令行,快速完成无损网络配置部署。
这种业务级命令行的封装,将多个原子级命令行进行组合,简化配置流程,节省工程师的时间和精力去完成更有价值的业务侧优化。
定位无损网络的瓶颈和故障
show roce业务级命令行将多个原子级命令行组合成一个语义完整的业务命令,将多个命令的输出信息整合在一起。
在排查网络故障时,可以使用show roce一次性查询和无损网络相关的所有配置信息、运行状态,而不需要逐个查询原子级命令行。从而简化故障排除流程,提高故障排除效率。
图片未来,随着云计算、大数据和AIGC行业的不断发展,对高性能网络传输技术的需求将会越来越大。一键RoCE作为一种快速部署RDMA网络的解决方案,将会在未来得到更广泛的应用。