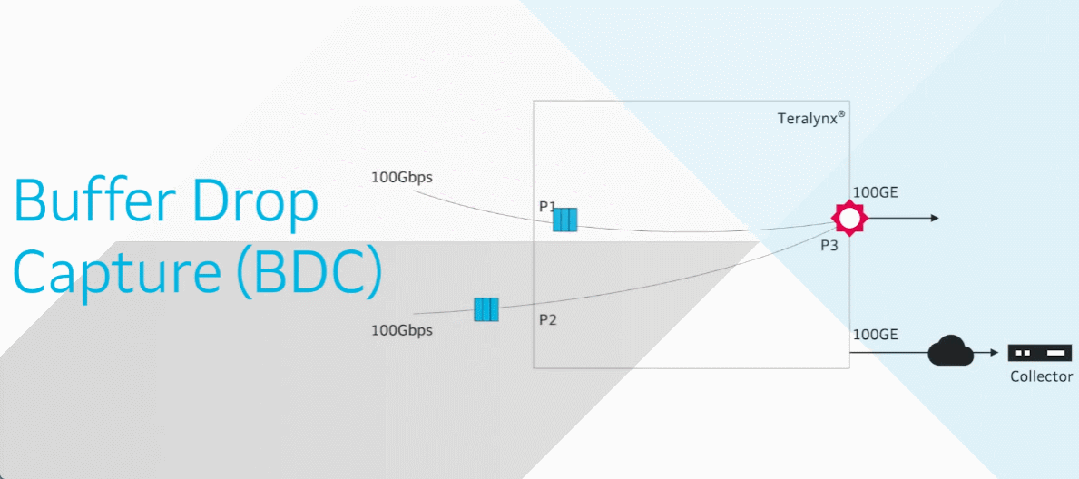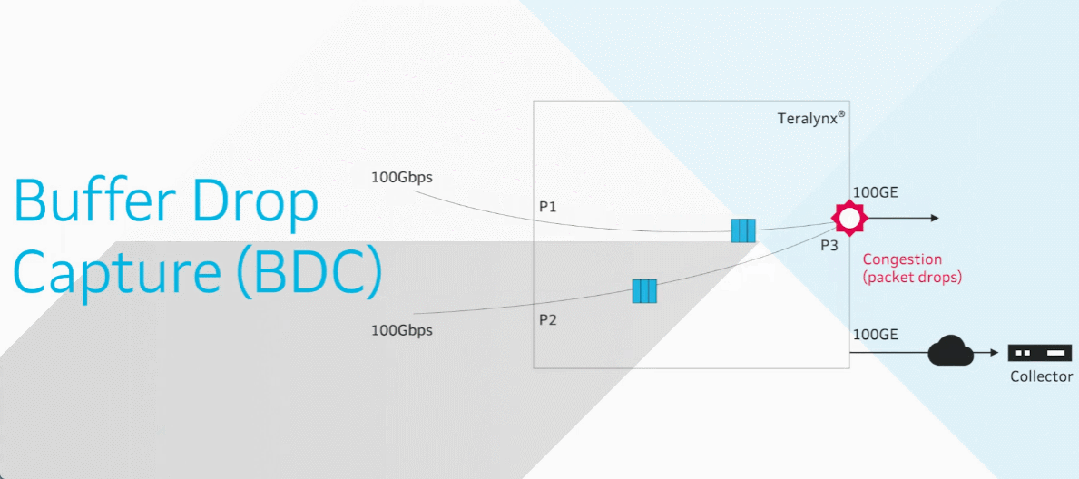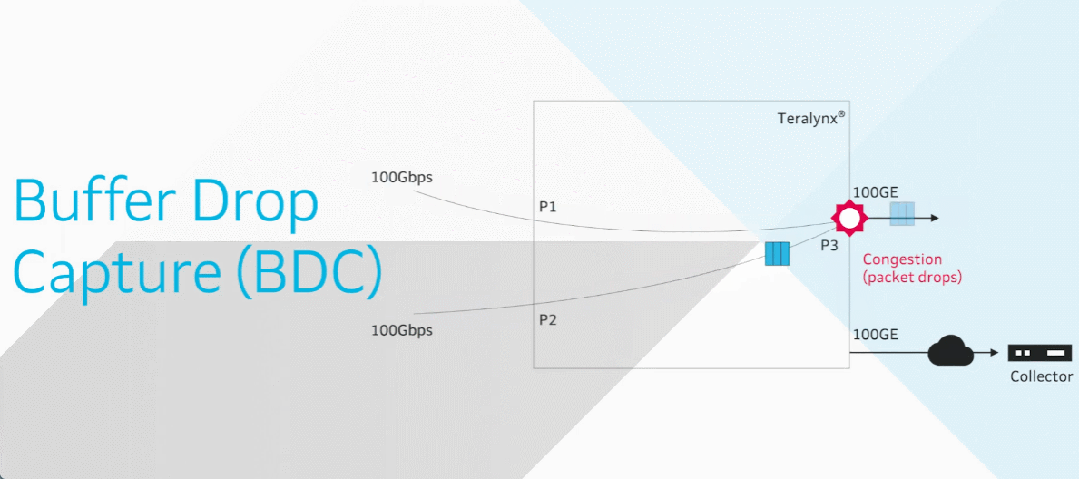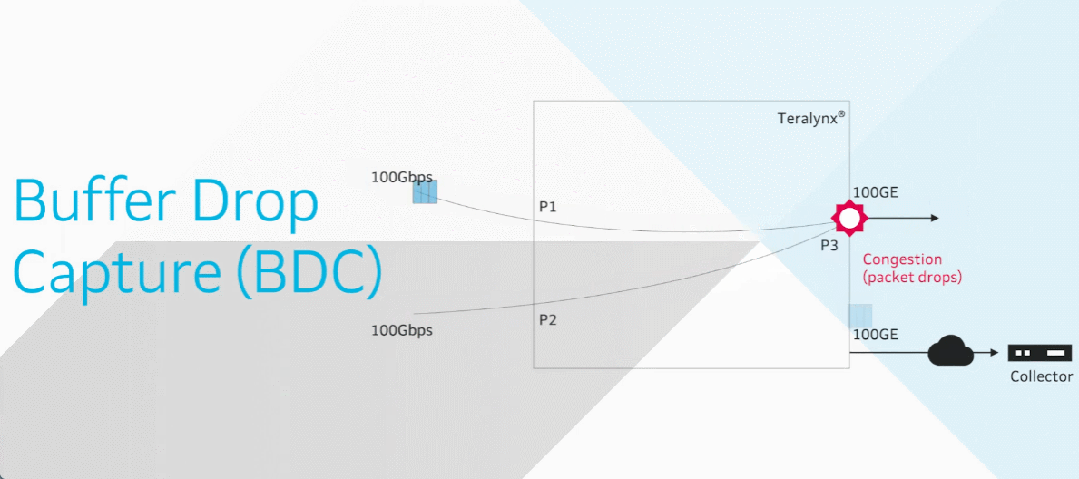
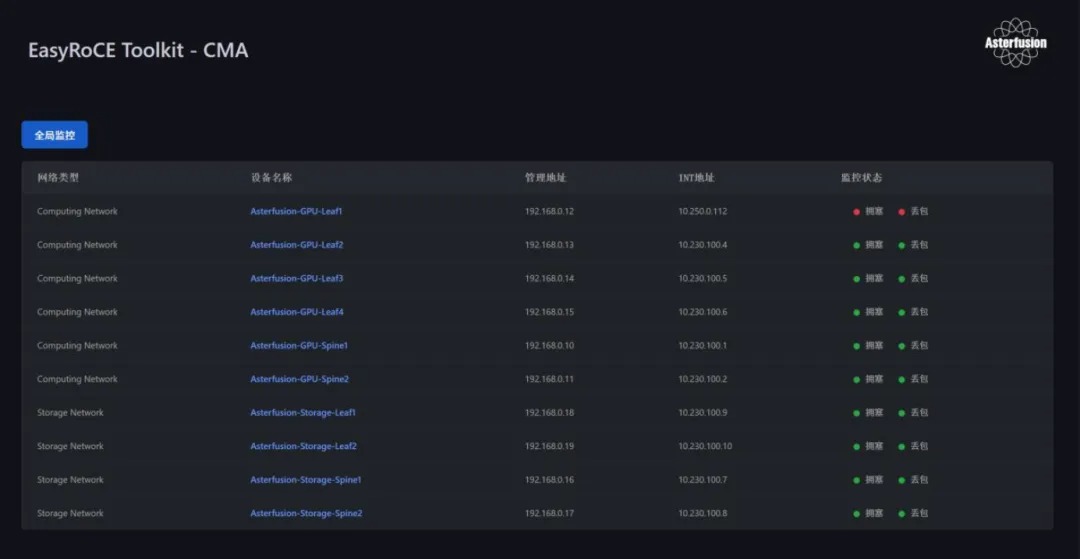
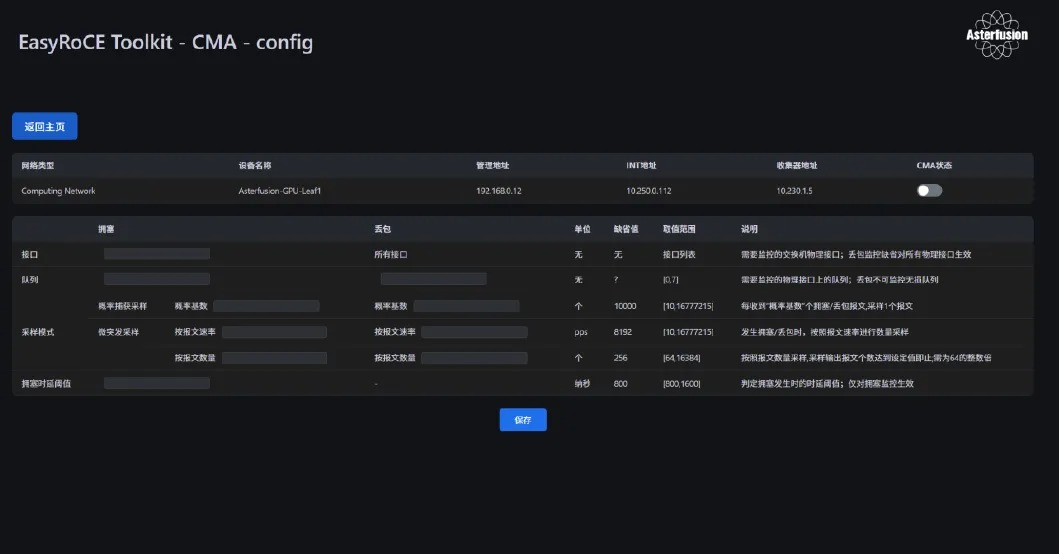
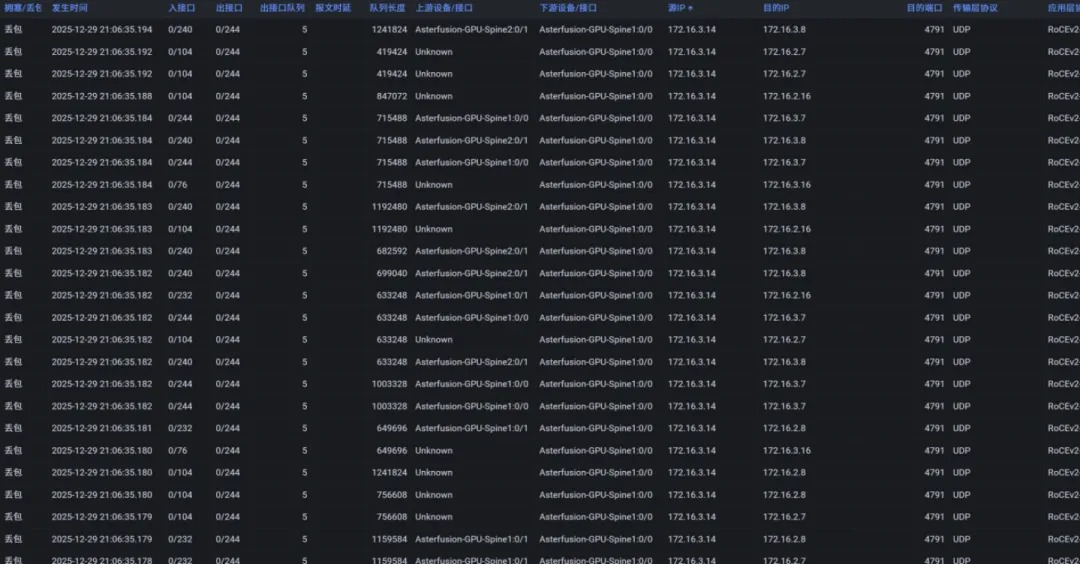
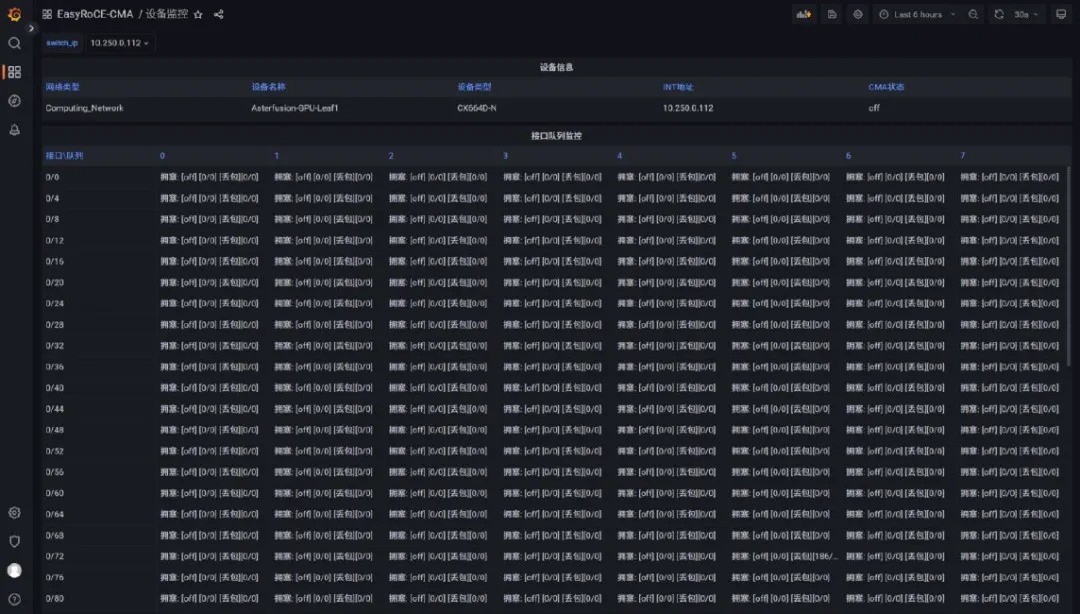
前言
AI集群涉及三种网络:Frontend Fabric、GPU Backend Fabric和Storage Backend Fabric。其中,Frontend Fabric指前端网络,用于连接互联网或存储系统,加载训练数据;GPU Backend Fabric指GPU后端网络(又称计算网),用于支撑GPU间的通信,提供无损连接并实现集群规模扩展,是承载GPU节点间训练数据交互的核心;Storage Backend Fabric指存储后端网络,负责海量数据的存储、检索和管理,实现GPU与高性能存储设备之间的通信。
本文聚焦不同规模下的400G AI智算GPU后端网络设计,以星融元数据中心400G/800G高密度接口交换机为核心硬件载体,采用Clos组网,基于Rail-only、Rail-optimized两种架构,提供标准化部署的解决方案。
读者对象
本手册主要适用于方案规划设计及现场实施人员,相关人员应具备以下能力:
熟悉Asterfusion数据中心网络交换机产品
了解RoCE、PFC、ECN等技术
1 概述
AI/ML(Artificial Intelligence/Machine Learning,人工智能/机器学习)应用的快速演进推动大规模AI集群的需求持续攀升,其核心挑战在于:AI训练属于典型的网络密集型工作负载,GPU节点间需高频交互海量梯度数据与模型参数,对网络基础设施提出“高带宽、低时延、抗干扰”三大核心诉求。
传统通用型数据中心网络难以适配AI训练中大象流主导、低熵值的流量特征,易引发带宽瓶颈、传输拥塞及时延抖动等问题,无法满足AI训练的严苛需求。后端网络作为AI集群的“算力传输中枢”,直接决定GPU算力的释放效率。因此,亟需一套高效的集群组网方案,满足低时延、高吞吐的机间通信。
2 AI后端网络架构
2.1 Rail-Only架构
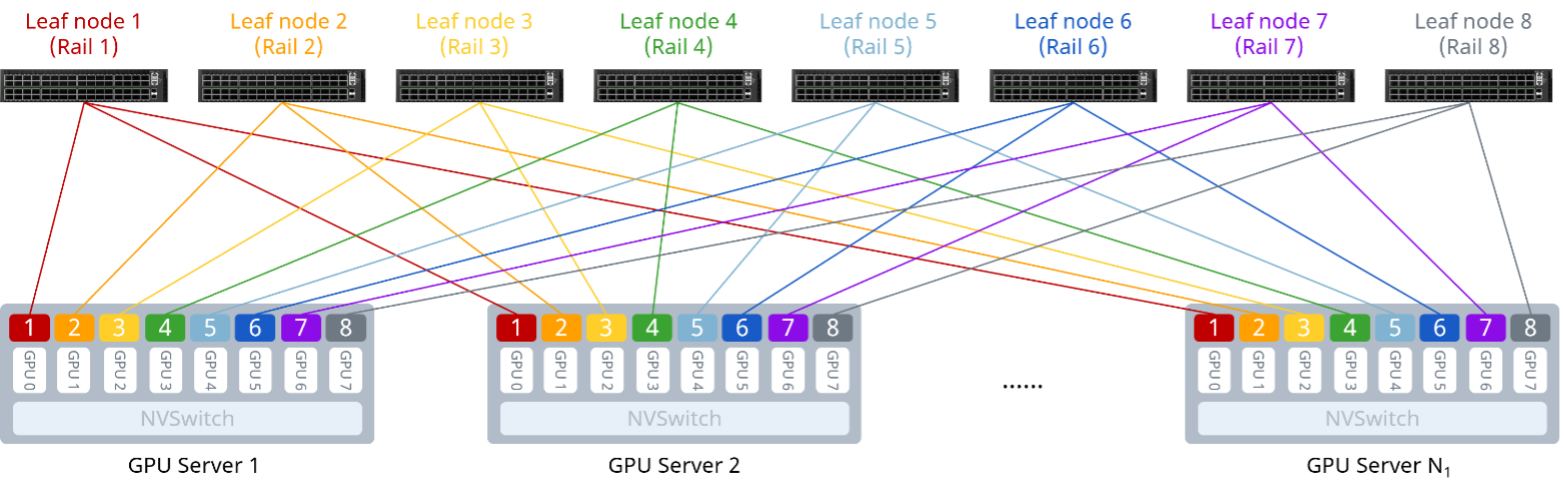
连接到不同服务器同编号GPU的Leaf节点,被定义为一个Rail(轨道)平面,即Rail N通过第N台Leaf交换机实现所有N号GPU的互联。如下图,每台服务器上的GPU编号为0~7,对应Rail 1~Rail 8。同轨传输是指源GPU与目标GPU的对应网卡接入到同一台Leaf交换机。LLM(Large Language Model)训练通过混合并行(数据并行、张量并行、流水线并行)策略优化流量分布,使得大部分流量集中在节点内和同轨道内。
图1 Rail-only架构
Rail-only架构采用单层组网设计,将整个集群的网络在物理上划分为8个独立的轨道,不同节点的GPU间通信均为同轨传输,轨道内通信可实现“一跳直达”。
相较于传统Clos架构,Rail-only架构省去了Spine层,通过减少网络层级节省交换机和光模块数量,进而降低硬件成本,是专为AI大模型训练量身定制的低成本、高性能网络架构,适用于小规模计算集群。
2.2 Rail-Optimized架构
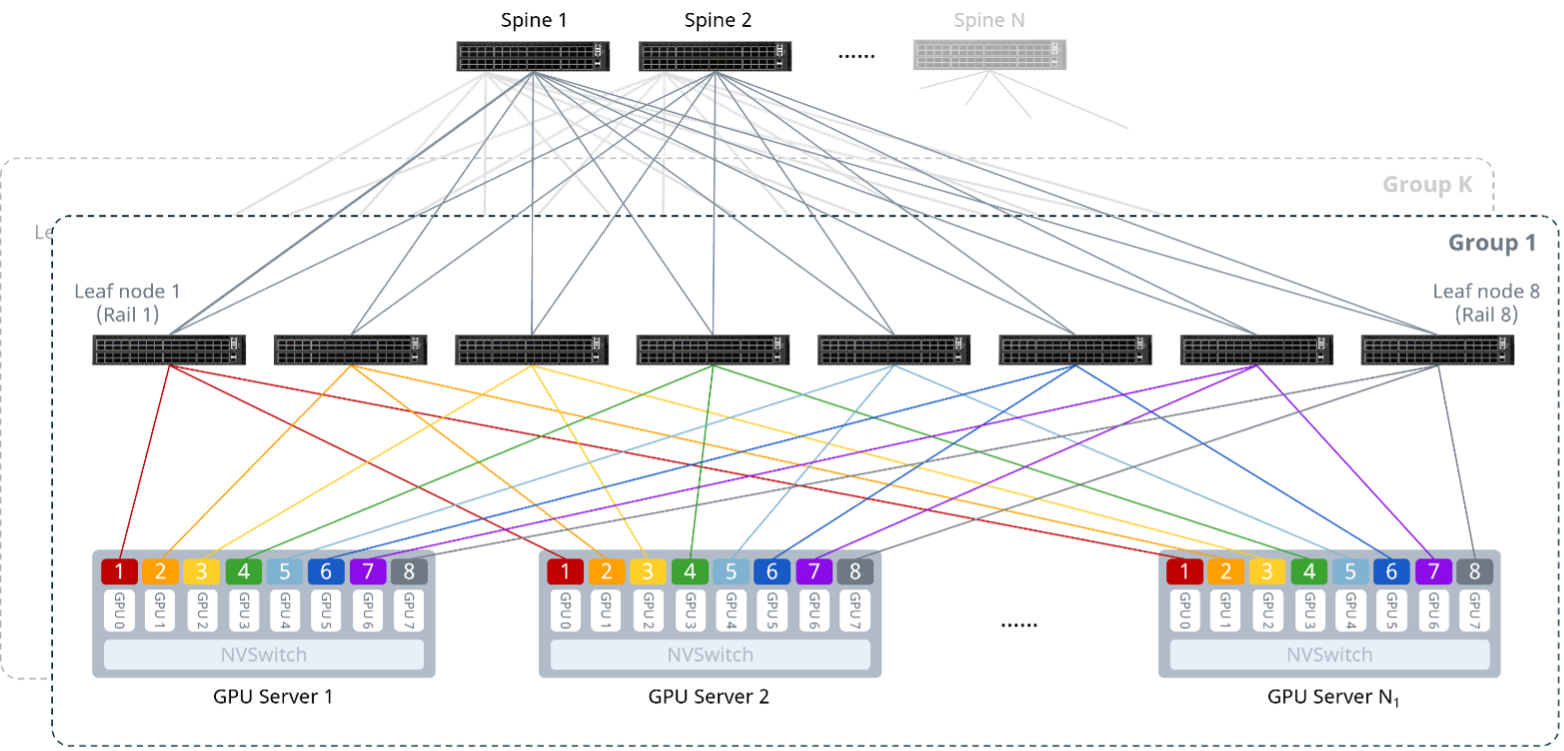
在Rail概念的基础上,把由一组Rail组成的基础构建单元视作一个Group,其中包含若干台Leaf交换机与GPU服务器。当集群规模扩大时,可通过水平堆叠多个Group来扩展,从而支撑更大规模的集群部署。
可将计算网想象成一套铁路系统:计算节点是装载算力的“车站”,Rail是连接各站同号GPU的“专属铁路线”保障高速直达;Group则是整合多条轨道及其配套交换机的“标准站台区”单元。通过这种模组化的堆叠,智算中心能像搭积木一样横向扩展,既保证了单条轨道内的极速通信,又实现了万卡集群的高效互联。
图2 Rail-optimized架构
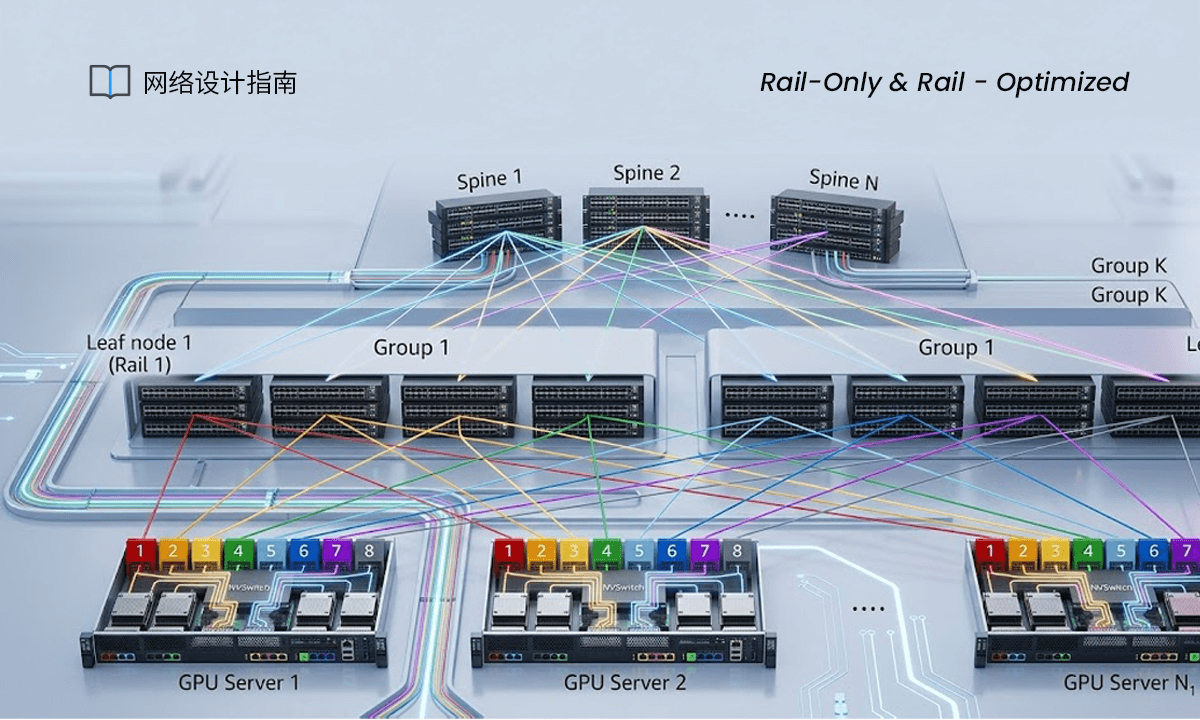
如上图,Rail-optimized(轨道优化)架构的核心设计思路是将每台服务器的同号网卡接入同一台Leaf交换机,确保GPU间的多机通信尽可能经过最少跳数内完成。在这种设计下,GPU节点间的通信可利用自身的NVSwitch¹内部通路,只需要经过一跳即可到达,而无需跨多台交换机,避免产生额外时延。具体如下:
服务器内互联:8张GPU通过NVLink总线连接至NVSwitch,实现服务器内部GPU间的低时延通信,降低Scale-Out网络传输压力;
服务器-网络互联:所有服务器遵循统一的连线逻辑,网卡按“NIC1-Leaf1、NIC2-Leaf2……”的规则,分别接入多台Leaf交换机;
网络层互联:Leaf与Spine交换机采用全互联模式,采用2层Clos架构。
¹ NVSwitch为NVIDIA推出的承载高速NVLink的交换芯片,在Scale-Up网络实现多GPU以NVLink能够达到的最高速度进行通信。
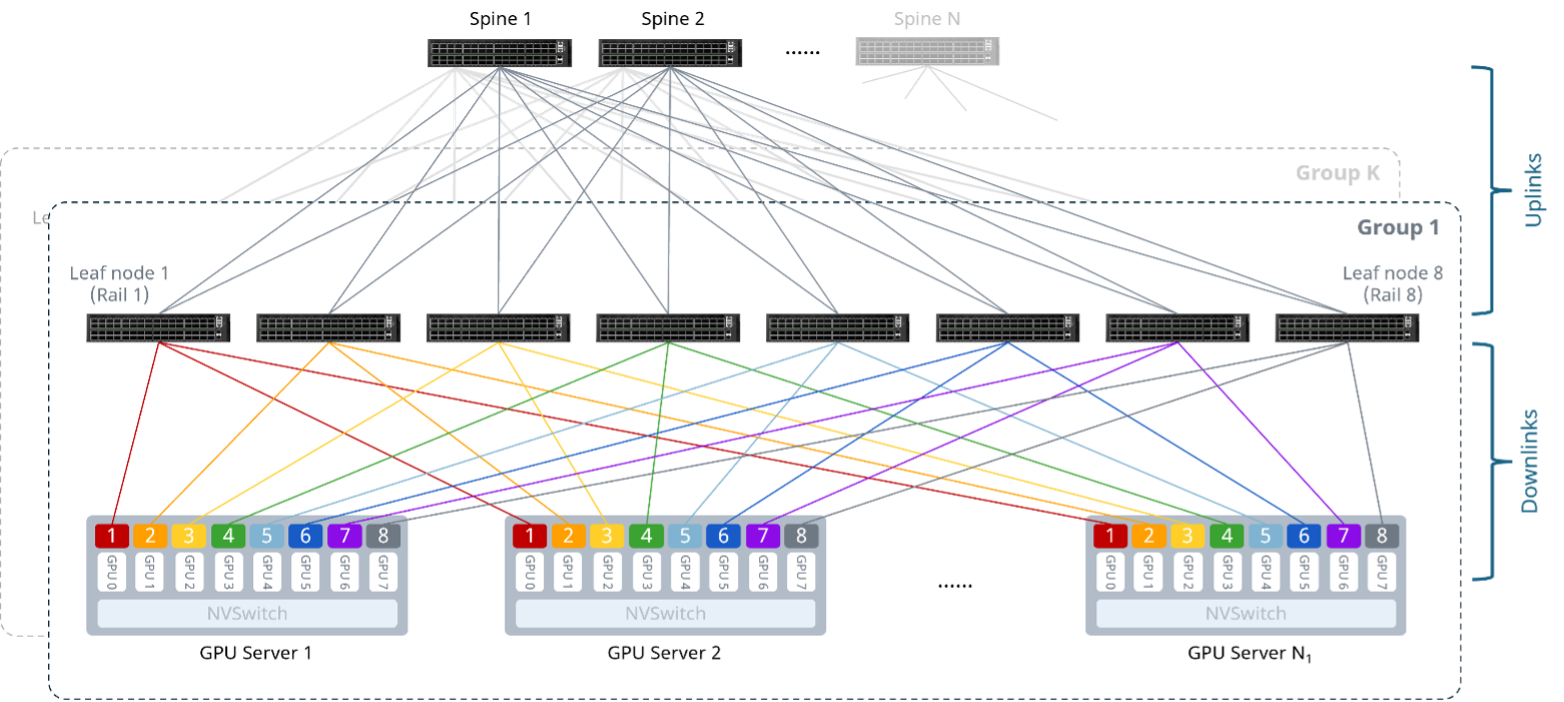
在多级Clos架构设计中,需要合适的收敛比(Oversubscription Ratio)。收敛比是指下行总带宽(Leaf节点到GPU服务器)和上行总带宽(Leaf节点到Spine交换机)的比值(如下图)。若收敛比大于1:1,当下行流量达到线速时,Fabric将没有足够的容量来处理GPU间的流量,可能引发拥塞或丢包。
图3 Rail-optimized架构中的收敛比
图3 Rail-optimized架构中的收敛比
简言之,收敛比越小,通信越无阻塞,但成本越高;收敛比越大,成本越低,但易出现拥塞。在高性能AI智算网络中,一般建议使用收敛比1:1的无阻塞网络设计。
2.3 流量路径分析
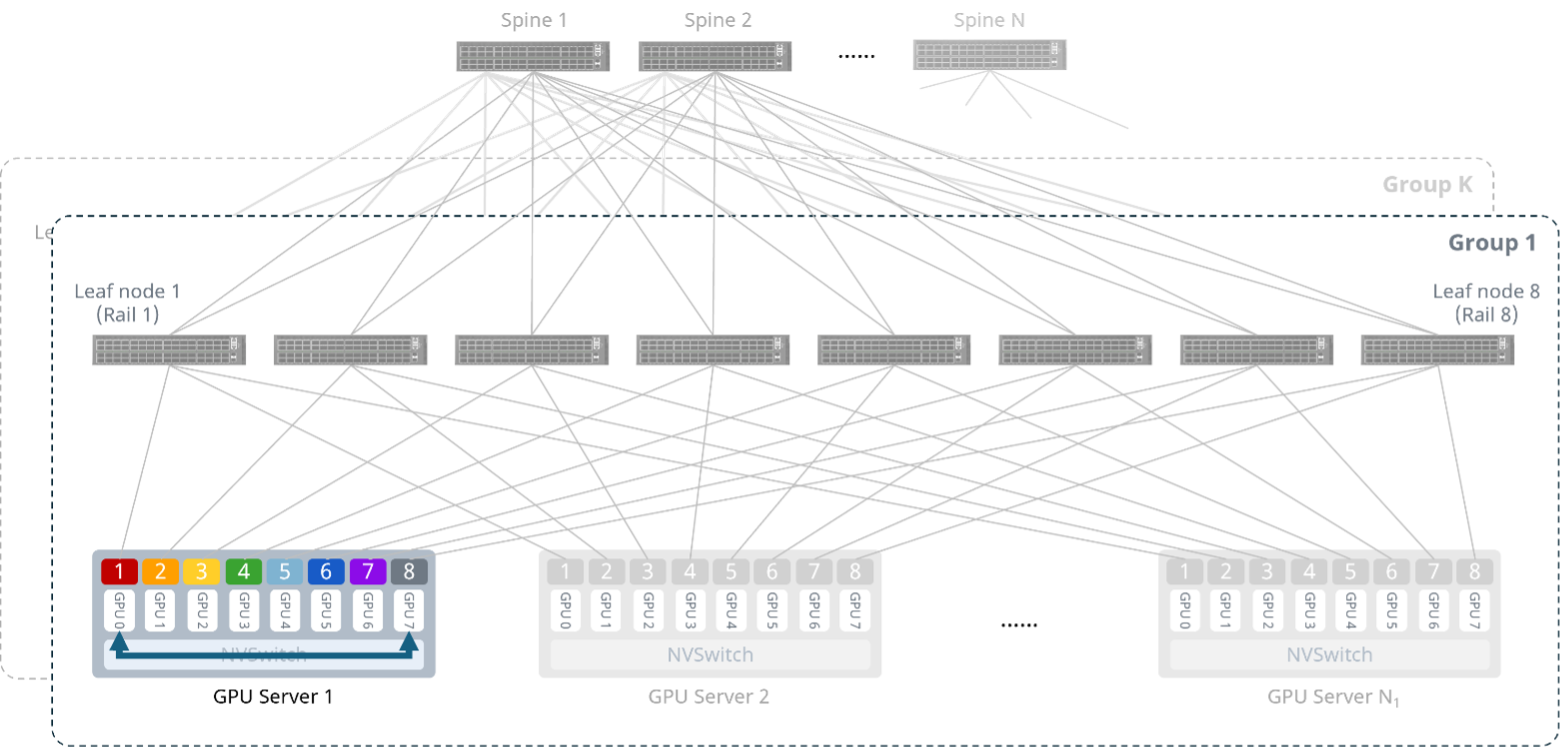
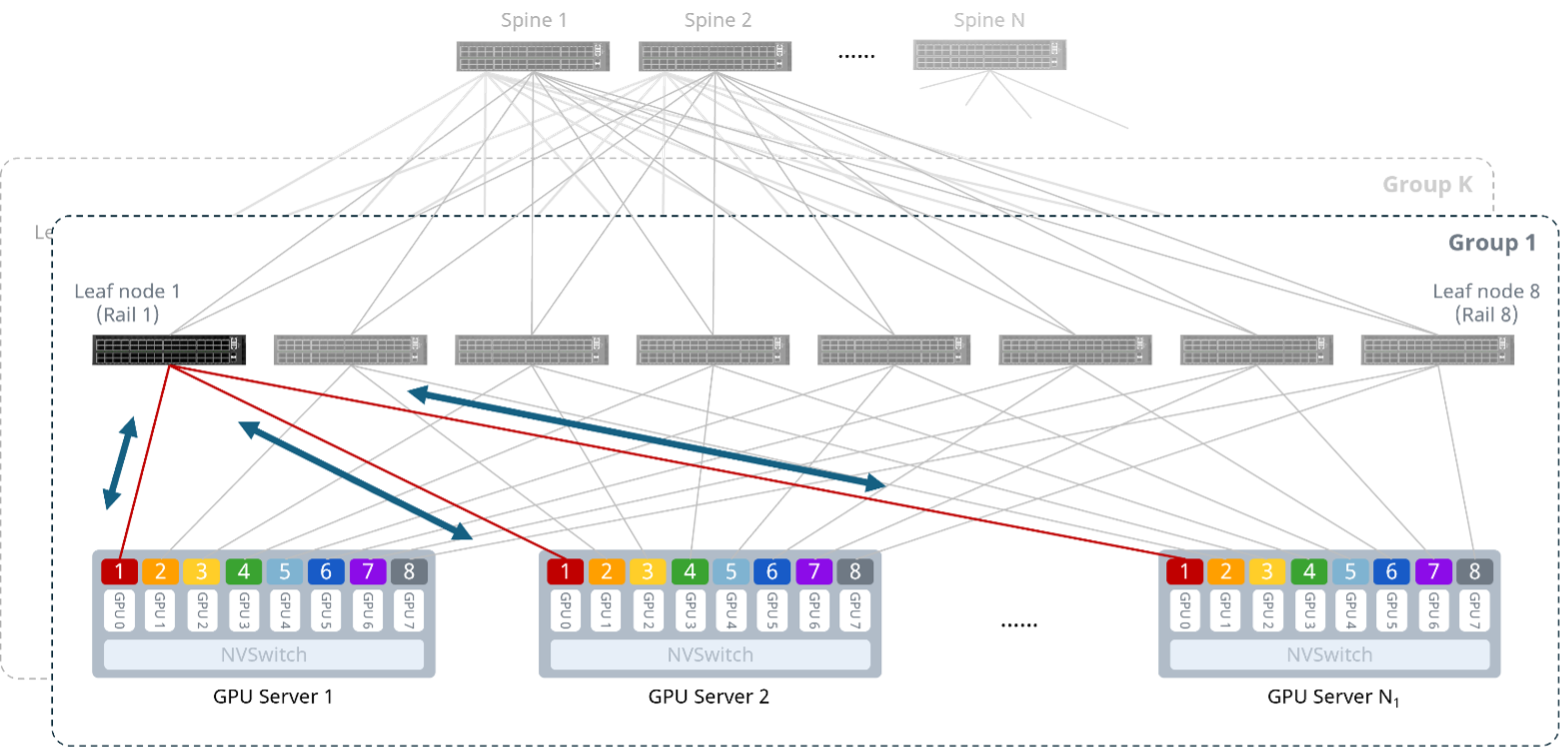
上述两种架构在节点内、轨道内通信路径类似。下面以Rail-optimized架构为例,详细分析不同情况下的GPU间通信路径。
机内GPU间的通信通过NVSwitch完成,无需经过外部网络。
图4 节点内GPU通信示意图
同轨GPU间的通信经过一台Leaf交换机转发。
图5 同轨GPU通信示意图
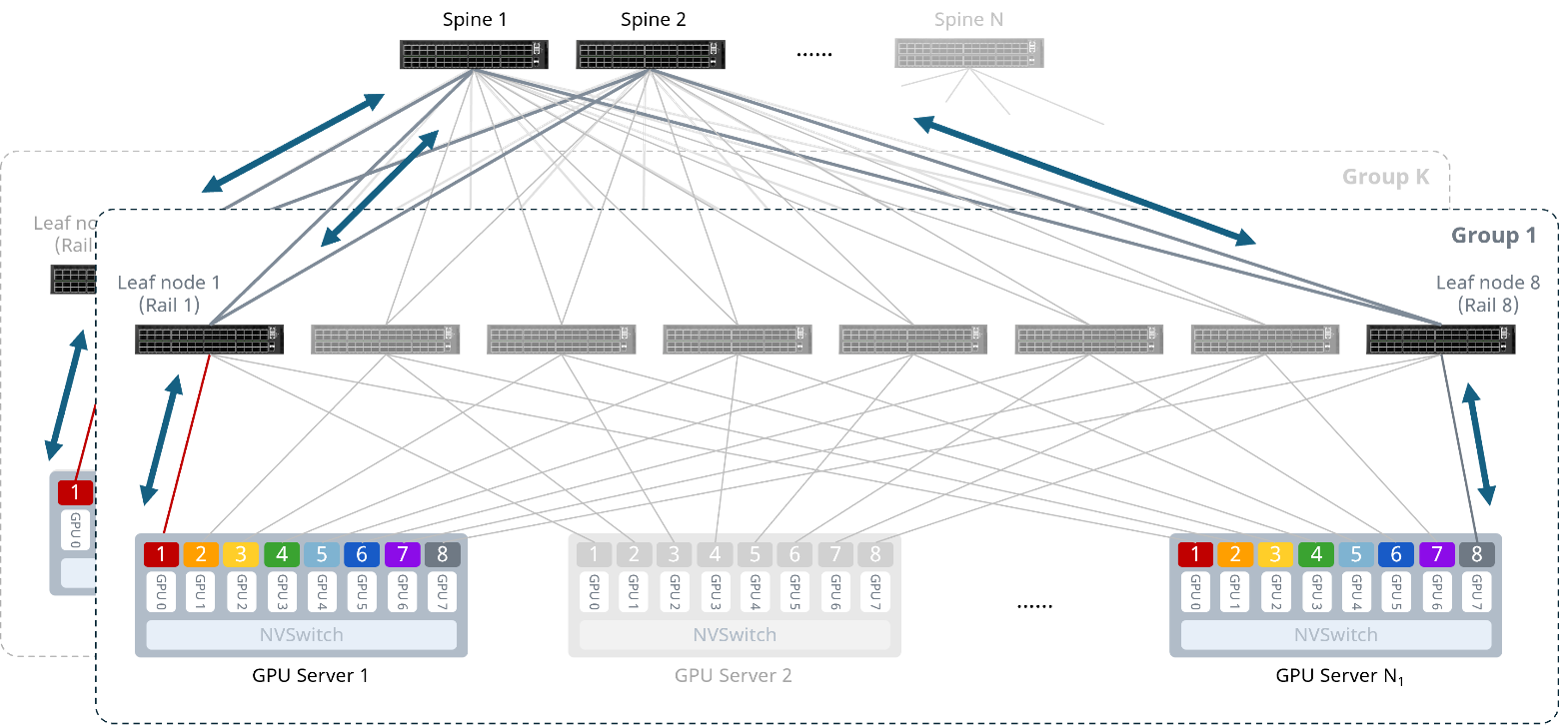
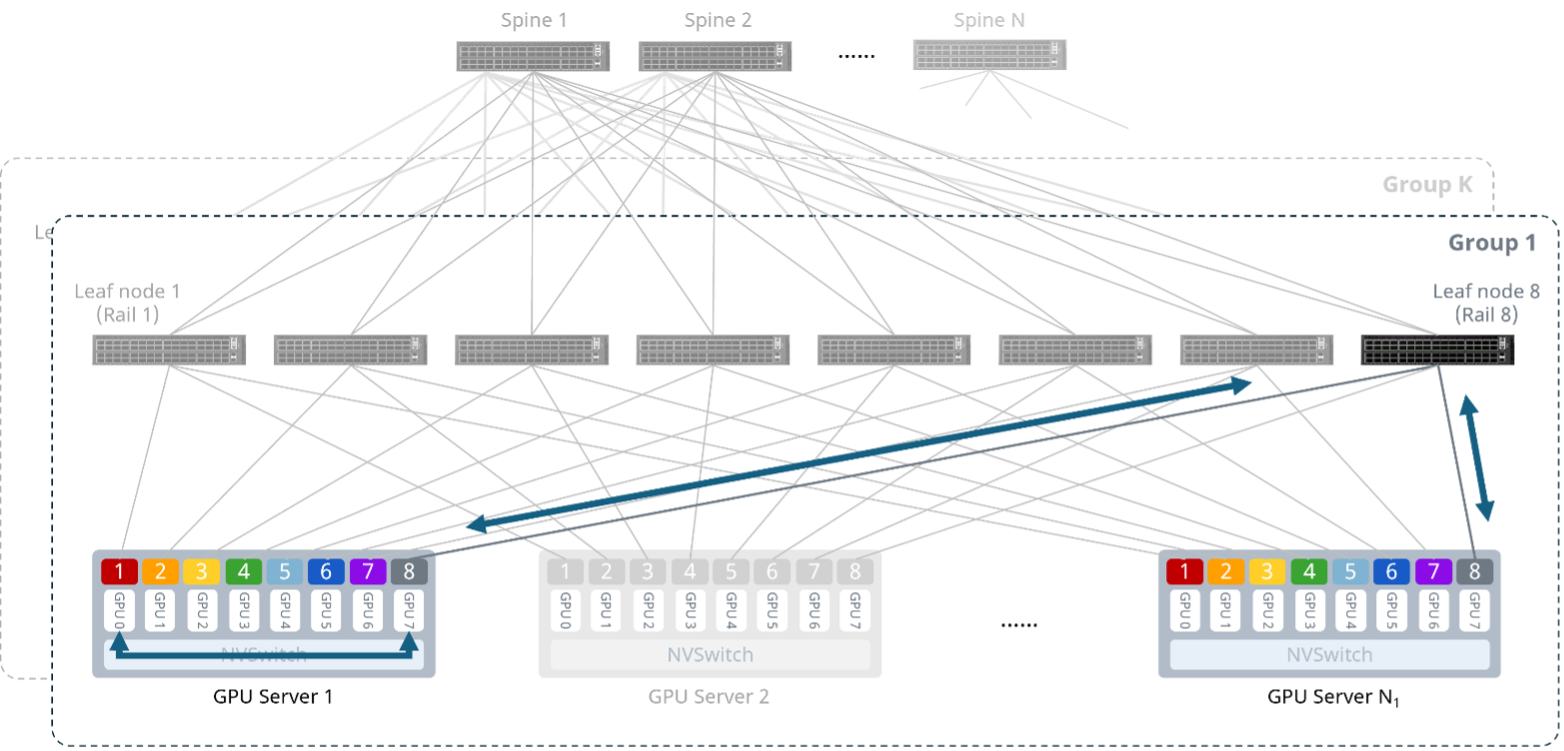
未开启PXN(PCIe x NVLink)²,则跨轨GPU间的通信需要跨Spine传输。跨组的GPU间通信也是如此。
图6 跨轨(不开启PXN)及跨组GPU通信示意图
² PXN是NCCL中的一项关键技术,使GPU能够先通过NVLink将数据聚合到节点内与网卡直连的GPU,再由该GPU通过PCIe高速发送到网卡,提升跨节点集体通信的效率。
配合PXN技术,则无需跨Spine,单跳完成传输。
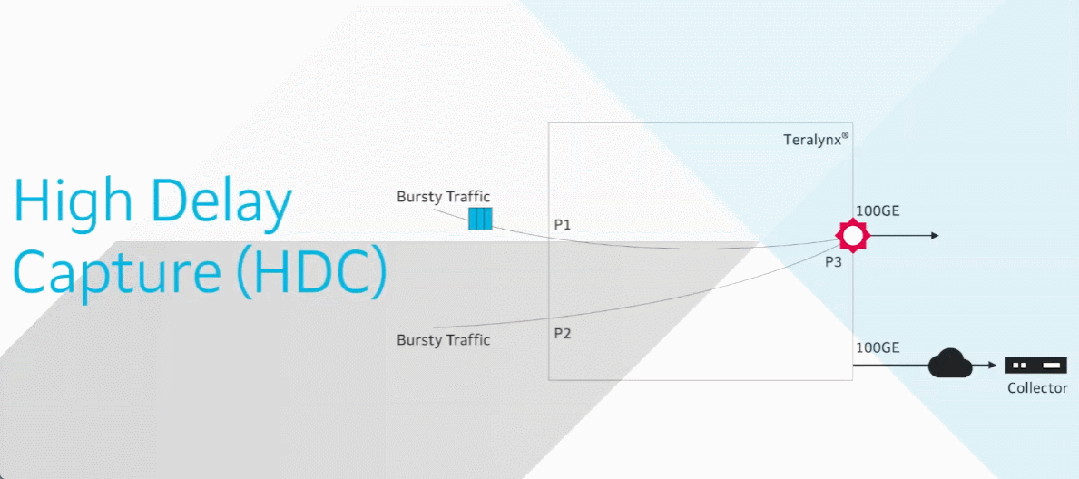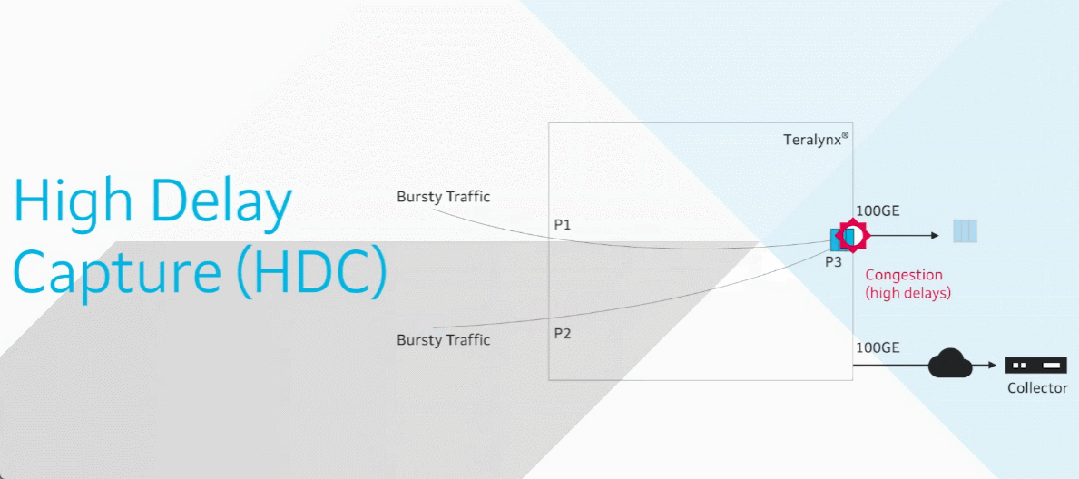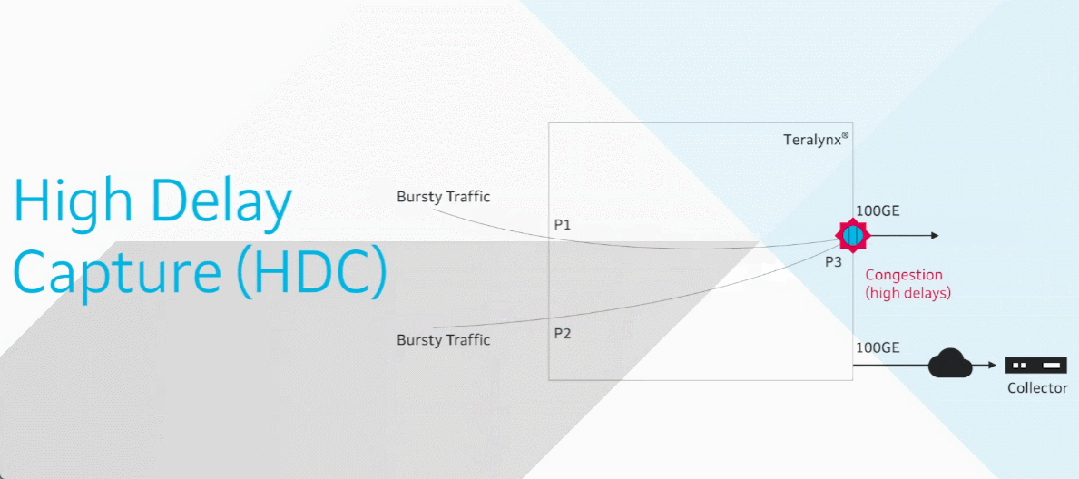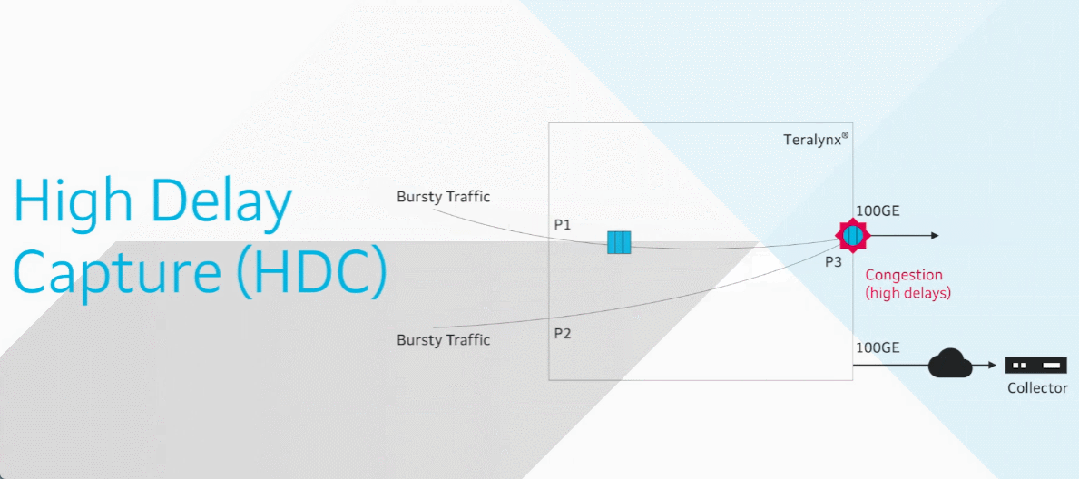
3 支撑无损网络的技术
3.1 DCQCN技术
RDMA(Remote Direct Memory Access,远程直接内存访问)技术作为一种基于网络的内存访问技术,被广泛应用于超算、AI训练、存储等多个场景。RDMA最初在InfiniBand网络上实现,后来发展出通过以太网承载RDMA的网络协议——iWARP和RoCE(RDMA over Converged Ethernet,以太网RDMA)。
RoCEv2是基于无连接的UDP协议,其无损传输依赖端到端拥塞控制机制,因此需要PFC(Priority Flow Control,基于优先级的流控)和ECN(Explicit Congestion Notification,显式拥塞通知)技术来保证数据传输的可靠性。然而,如果仅依赖PFC可能会导致交换机过早停止转发流量,影响转发性能;如果仅依赖ECN,由于ECN反馈路径较长,可能会导致端侧降速不及时,进而出现丢包。为此需要一种协同机制,让PFC和ECN发挥互补作用,实现无损传输。
(请参阅:一文梳理基于优先级的流量控制(PFC))
DCQCN(Data Center Quantized Congestion Notification,数据中心量化拥塞通知)正是这样一种混合拥塞控制算法:在拥塞初期触发ECN机制,让GPU网卡平缓降低发送速率;当拥塞加剧时,将PFC作为兜底手段,逐跳快速阻断上游交换机的对应流量。
DCQCN的协同逻辑严格遵循特定顺序:
当交换机队列开始积压时,会触发WRED阈值并对数据包进行打标。接收端收到ECN置位的数据包,开始向发送端反馈CNP(Congestion Notification Packet,拥塞通知报文)。发送端收到CNP后,平滑降低发送速率,将拥塞控制在一定范围内。此时网卡仅放缓发送速度,流量仍保持传输,避免突然中断。
若拥塞持续加剧,导致交换机缓冲区占用达到xOFF阈值,交换机会向上游设备发送pause帧。上游设备收到后会临时停止对应优先级队列的传输,防止丢包。
当缓冲区水位下降至xON阈值以下,交换机会发送恢复指令,通知上游设备可恢复对应队列的流量传输。
配置合适的PFC、ECN参数至关重要,既要保证ECN能够在拥塞早期触发及时调整速率,避免不必要的PFC触发,同时要保证PFC在必要时及时触发,防止丢包。这对网络部署或运维工程师提出了较高要求。一般建议遵循如下原则:WRED Min<WRED Max<PFC xON<PFC xOFF。
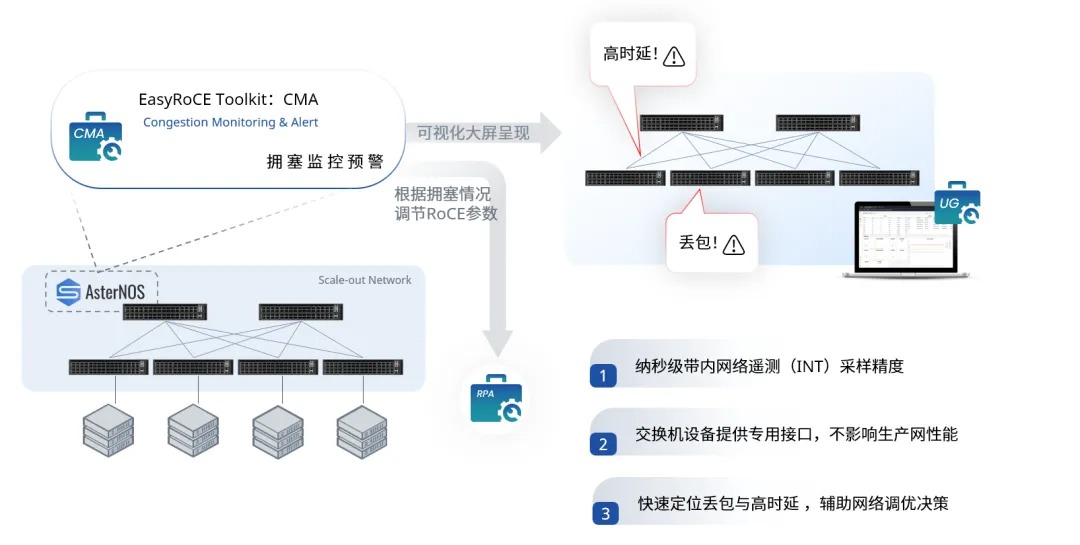
为简化无损以太网部署和运维的难度,星融元在AsterNOS网络操作系统上推出“一键RoCE”功能。该功能针对RoCEv2场景的配置需求,支持自动生成RoCE参数,实现了业务级的命令行封装,大幅提升RoCEv2场景下的可维护性和可用性。
3.2 负载均衡技术
ECMP(Equal-Cost Multi-Path,等价多路径)逐流负载均衡,是数据中心网络中应用最广泛的选路策略。通过对数据包的固定字段(如源/目的MAC地址、IP五元组等)作为哈希因子,利用哈希算法生成哈希值,在多条路径中随机选路。这种基于数据包的特征字段的负载均衡方式也称为静态负载均衡。
然而,逐流负载均衡在流量特征单一时易引发负载分担不均,尤其当“大象流”出现时,会加剧所选中成员链路的拥塞,严重影响网络性能,甚至引起丢包。深度学习模型高度依赖于All-Reduce、All-Gather、Broadcast等集合通信操作,这类操作会在各GPU间产生密集流量交互,传输速率通常高达每秒数太比特(Tbps)。同时,大模型参数同步依赖的集合通信存在木桶效应——若流量分布不均,即使只有一条路径发生拥塞,也可能拖慢整个训练任务的进度,放大负面影响。因此,传统逐流负载均衡方式并不适用于基于RoCEv2的AI后端网络。
针对这一问题,本文介绍三种替代传统逐流负载分担的技术方案:基于子流(Flowlet)的负载均衡技术、智能选路技术,以及包喷洒技术。
3.2.1 自适应路由切换
ARS(Adaptive Routing and Switching,自适应路由切换)是一种基于Flowlet(子流)的负载均衡技术。其借助ASIC提供的硬件ALB(Auto-Load-Balancing)³ 能力,能够在减少乱序的同时实现近乎逐包负载分担的均衡性。该技术通过将哈希值相同的数据流按一定时间间隔分割成一系列Flowlet,再通过实时感知端口的带宽利用率、队列深度等链路质量指标,将Flowlet主动分配至空闲路径,从而提升整体网络带宽利用率。
(请参阅:一文看懂ARS(自适应路由切换):基于 Flowlet 的动态负载均衡技术)
3.2.2 智能选路
智能选路技术根据负载均衡实现的方式分为动态和静态两种。
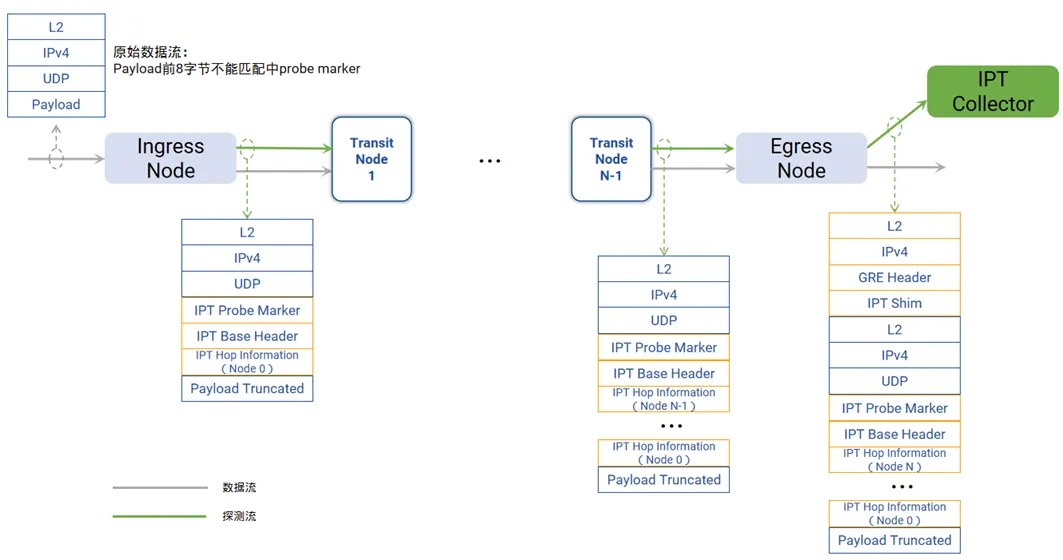
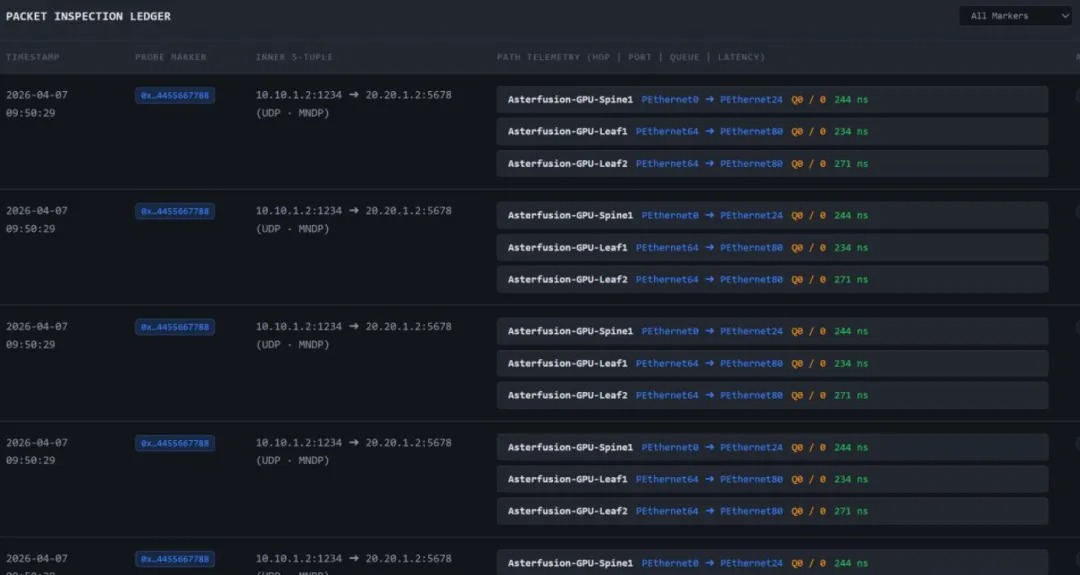
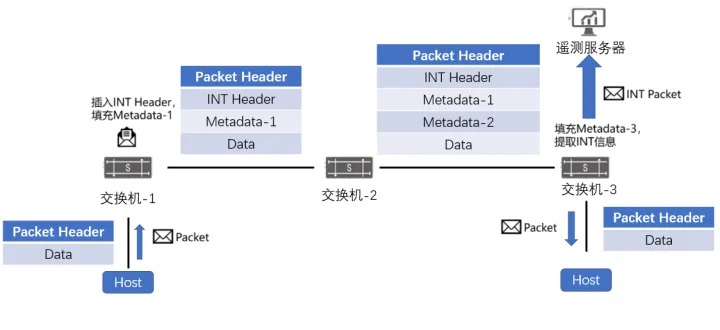
动态智能选路是一种基于感知路由的负载均衡技术,综合评估带宽使用、队列占用、转发时延等关键参数,精准判断网络路径质量。其中,带宽和队列使用基于ASIC硬件寄存器统计,精度达百毫秒级;转发时延基于INT(In-band Network Telemetry,带内网络遥测)技术,精度达纳秒级。各交换机实时检测路径质量,通过BGP扩展属性传递信息,并结合逐流的动态WCMP(Weighted Cost Multipath,加权多路径),将流量动态分配至最佳路径,避免网络瓶颈,提升带宽利用率。
静态智能选路是一种基于预设策略的负载均衡技术,将GPU发往Leaf不同下行接口的流量通过业务隔离与定向转发,结合PBR(Policy-Based Routing,策略路由)将流量重定向至指定的Leaf上行接口,从而进入预设的Spine设备,实现1:1收敛下的上行负载均衡。该技术将特定流量与物理路径强绑定,适用于对路径稳定性要求较高、流量模型相对固定的场景。
(请参阅:动态感知+智能决策,一文解读 AI 场景组网下的动态智能选路技术)
3.2.3 包喷洒
包喷洒⁴是一种逐包负载均衡技术,通过将数据包均匀喷洒到各条链路上,避免单一路径拥堵。包喷洒技术包含两种算法:
Random算法:将数据包随机分散至各条链路;
Round Robin算法:按顺序将数据包逐一、等量地分散至各条链路。
尽管逐包负载均衡在理论上能实现网络利用率最大化,但也面临显著挑战——实际组网中,当数据包通过不同链路能到达目的地时,由于各链路的转发时延不同,造成接收端报文出现乱序,影响整体性能。因此,逐包负载均衡技术需要硬件层面的强力支持,即端侧高性能网卡需具备乱序重排能力。
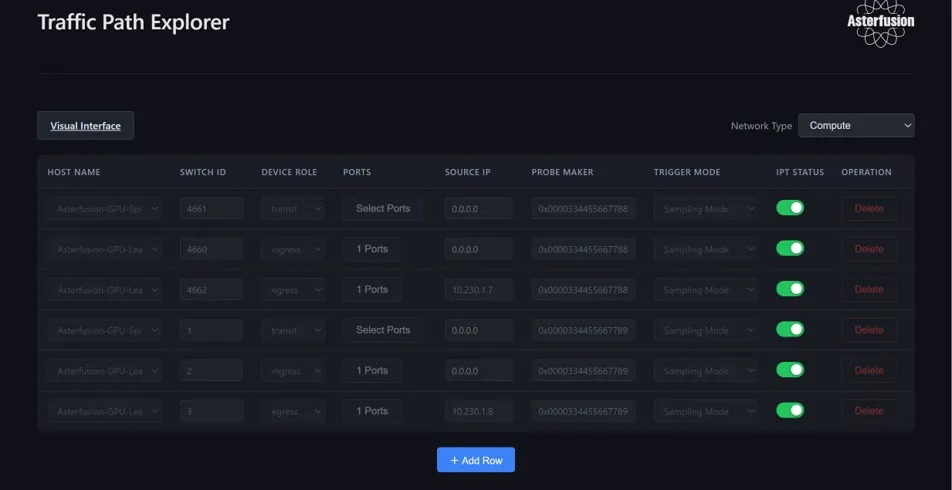
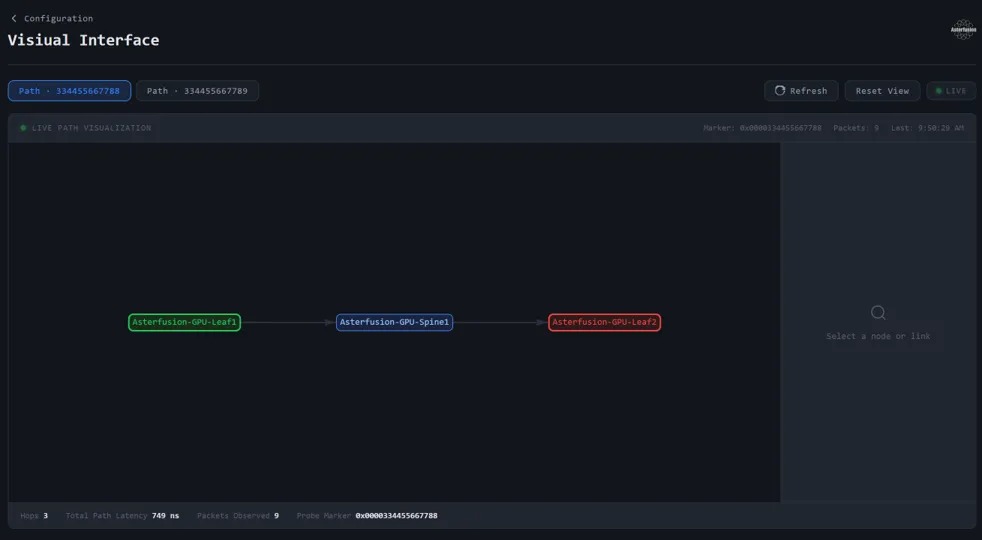
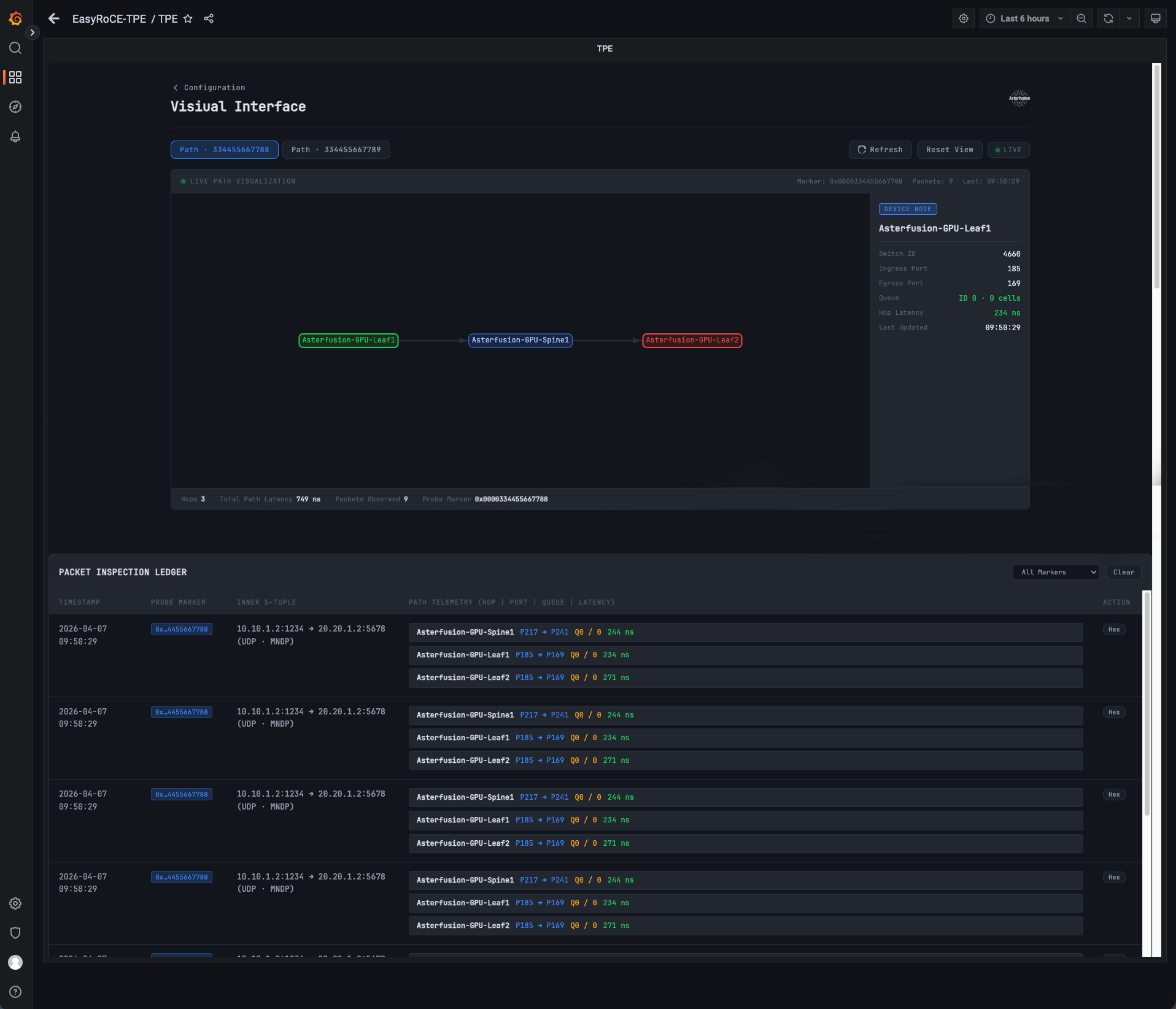
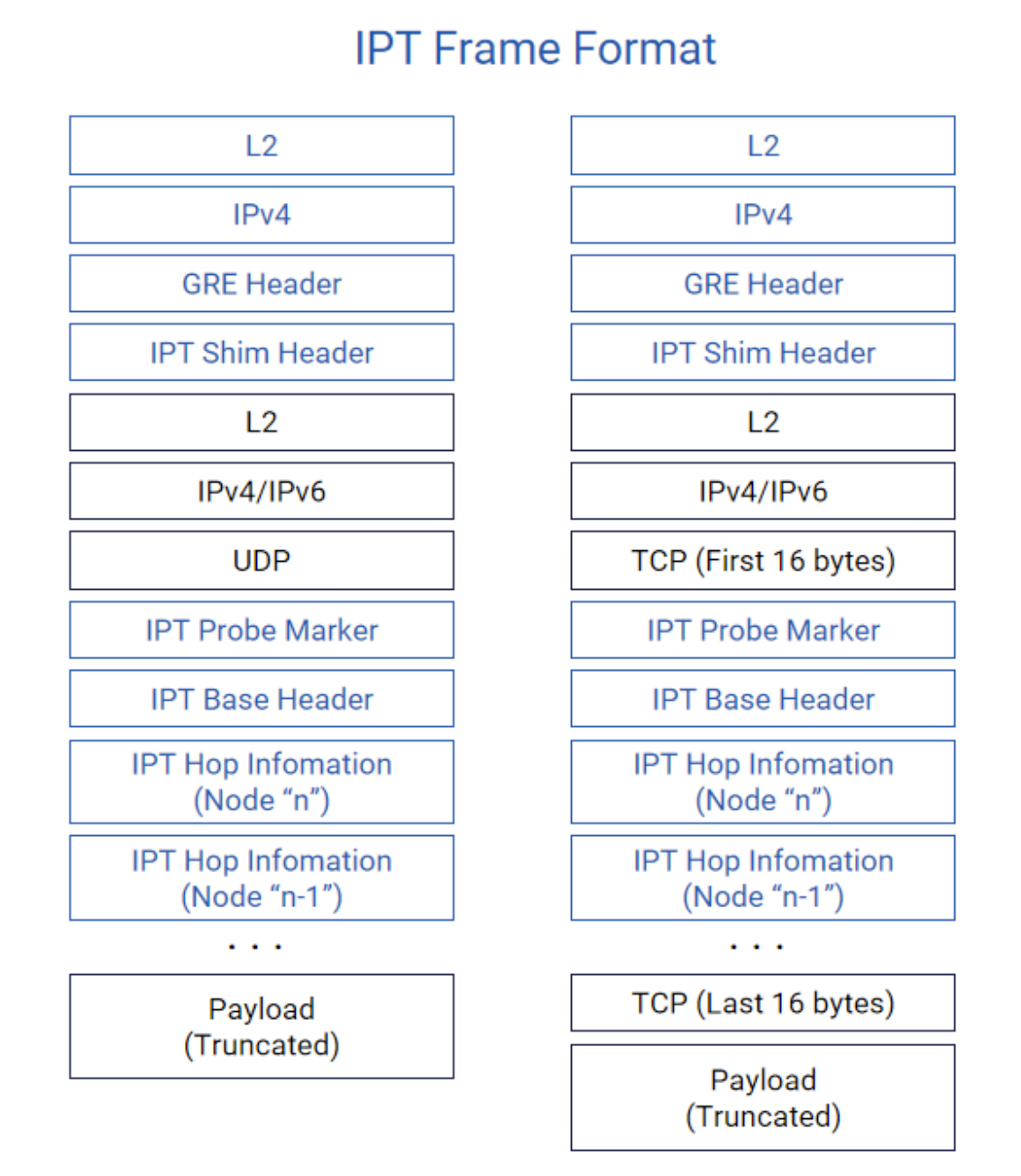
(请参阅:51.2T 800G AI智算交换机软硬件系统设计全揭秘)
³ ⁴ CX864E-N型号产品具备该能力
4 搭建400G AI后端网络
AI集群大小根据工作负载的要求不同存在差异,综合考虑硬件成本及可扩展性,不同规模GPU集群下的方案设计建议如下:
表格 1 不同规模GPU集群下的方案设计建议
GPU集群规模
方案设计建议
32~256 GPUs
选用CX732Q-N作为Leaf节点,采用单层Clos组网Rail-only架构,最多支持256个GPU接入。
256-1024 GPUs
选用CX864E-N作为Leaf节点,采用单层Clos组网Rail-only架构,最多支持1024个GPU接入。
1024-2048 GPUs
选用CX732Q-N作为Leaf节点,CX732Q-N或CX864E-N作为Spine节点,采用2层Clos组网Rail-optimized架构,最多支持2048个GPU接入。即使只有一组Leaf,考虑到故障容错,也建议至少部署2个Spine节点。
2048-8192 GPUs
选用CX864E-N作为Leaf、Spine节点,采用2层Clos组网Rail-optimized架构,最多支持8192个GPU接入。
下面将详细介绍标准化组网方案和设备选型。
4.1 小规模集群组网设计
4.1.1 标准化组网方案
小规模400G AI后端网络标准化组网
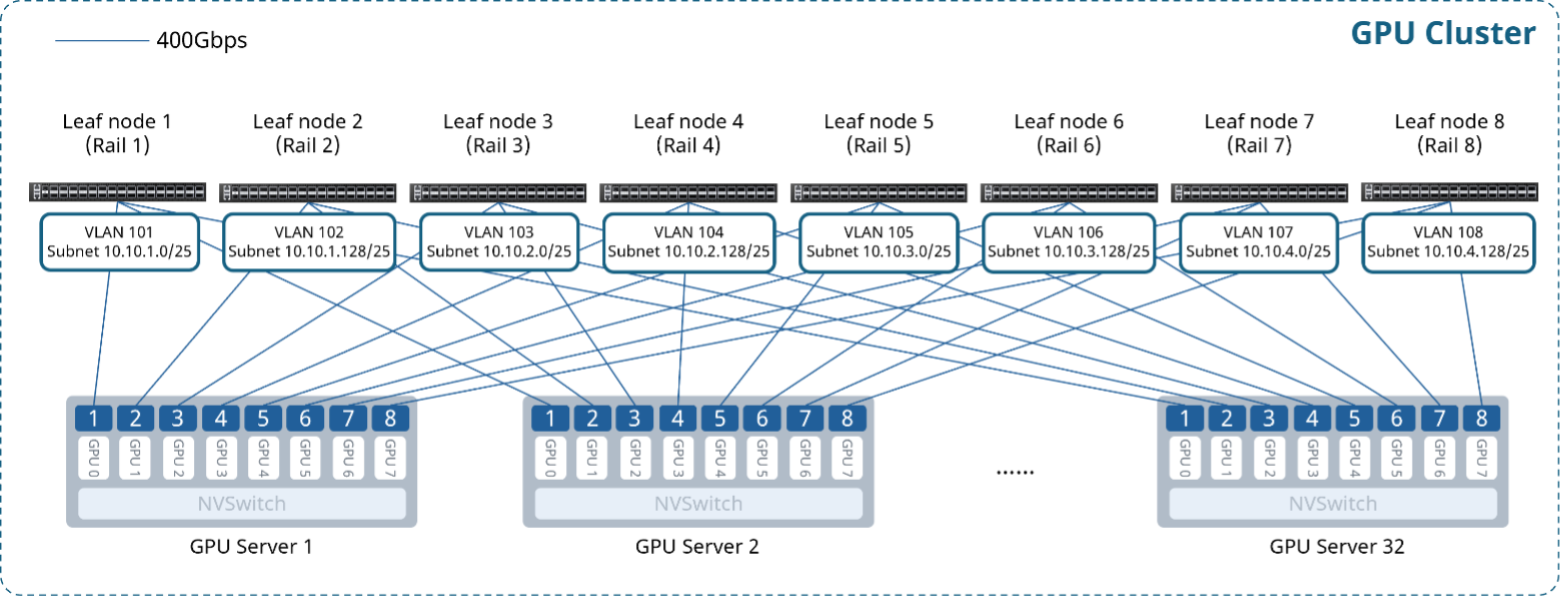
上图为一个32计算节点(256个GPU)的400G AI后端网络Rail-only架构组网图,部署8台CX732Q-N作为Leaf节点,其核心设计原则如下:
每个GPU连接专用网卡,每台服务器的网卡按照“NIC1-Leaf1、NIC2-Leaf2……”的规则接入到Leaf交换机,为每个Rail规划独立子网,Leaf交换机作为Rail内的默认网关。
网络采用单层Clos架构;
Leaf交换机启用一键RoCE,提供无损网络。
4.1.2 设备选型
建设小规模400Gbps RoCEv2网络,可选用星融元数据中心交换机CX864E-N或CX732Q-N进行部署。以NVIDIA DGX H100 GPU服务器为例,每台服务器搭载8个NVIDIA H100 Tensor Core GPU。不同型号交换机的最大接入能力如下表所示:
表格 2 Rail-only架构下不同型号交换机的最大接入能力
型号
单台最多接入的GPU数量
8台设备最多接入的GPU数量
8台设备最多接入的服务器数量
CX732Q-N
32
256
32
CX864E-Nv
128
1024
128
说明:CX864E-N配备了64个800GE接口,通过接口拆分,最多可提供128个400G接口。
举例:假设要构建一个64台H100服务器(512个GPU)的GPU集群,选用CX864E-N作为Leaf节点。则:
Leaf节点数量 = 512÷128 = 4
最大可扩展的Leaf节点数量 = 8
最大可扩展的GPU数量 = 8×128 = 1024
对于Leaf节点的计算及可扩展的最大规模,有如下总结:
Leaf节点数量 = 集群所需的GPU数量÷单台设备最多可接入的GPU数量
最大可扩展的Leaf节点数量 = 每台服务器的GPU数量
最大可扩展的GPU数量 = 每台服务器的GPU数量×单台设备最多可接入的GPU数量
4.2 中大规模集群组网设计
4.2.1 标准化组网方案
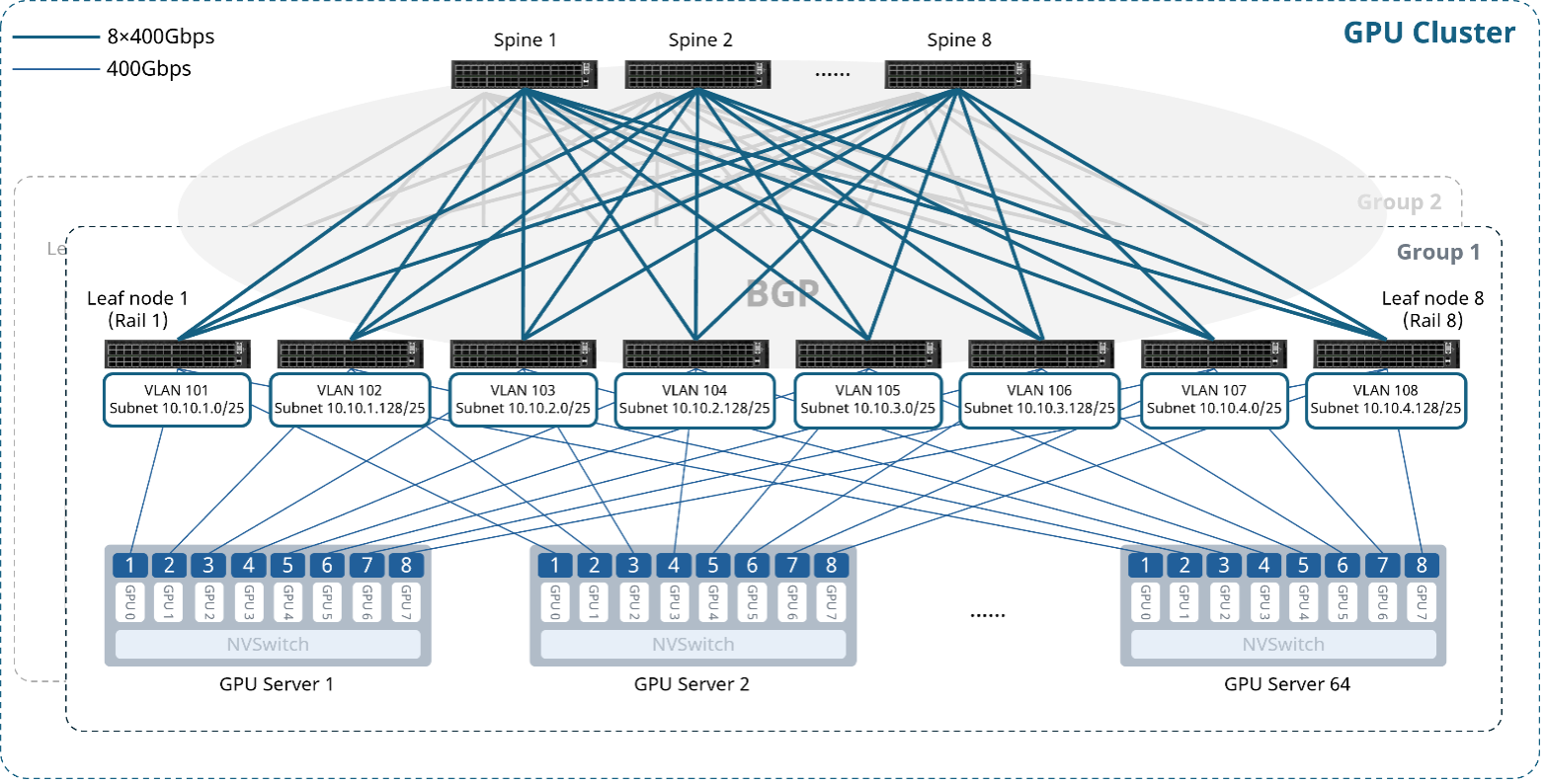
图9 中大规模400G AI后端网络标准化组网
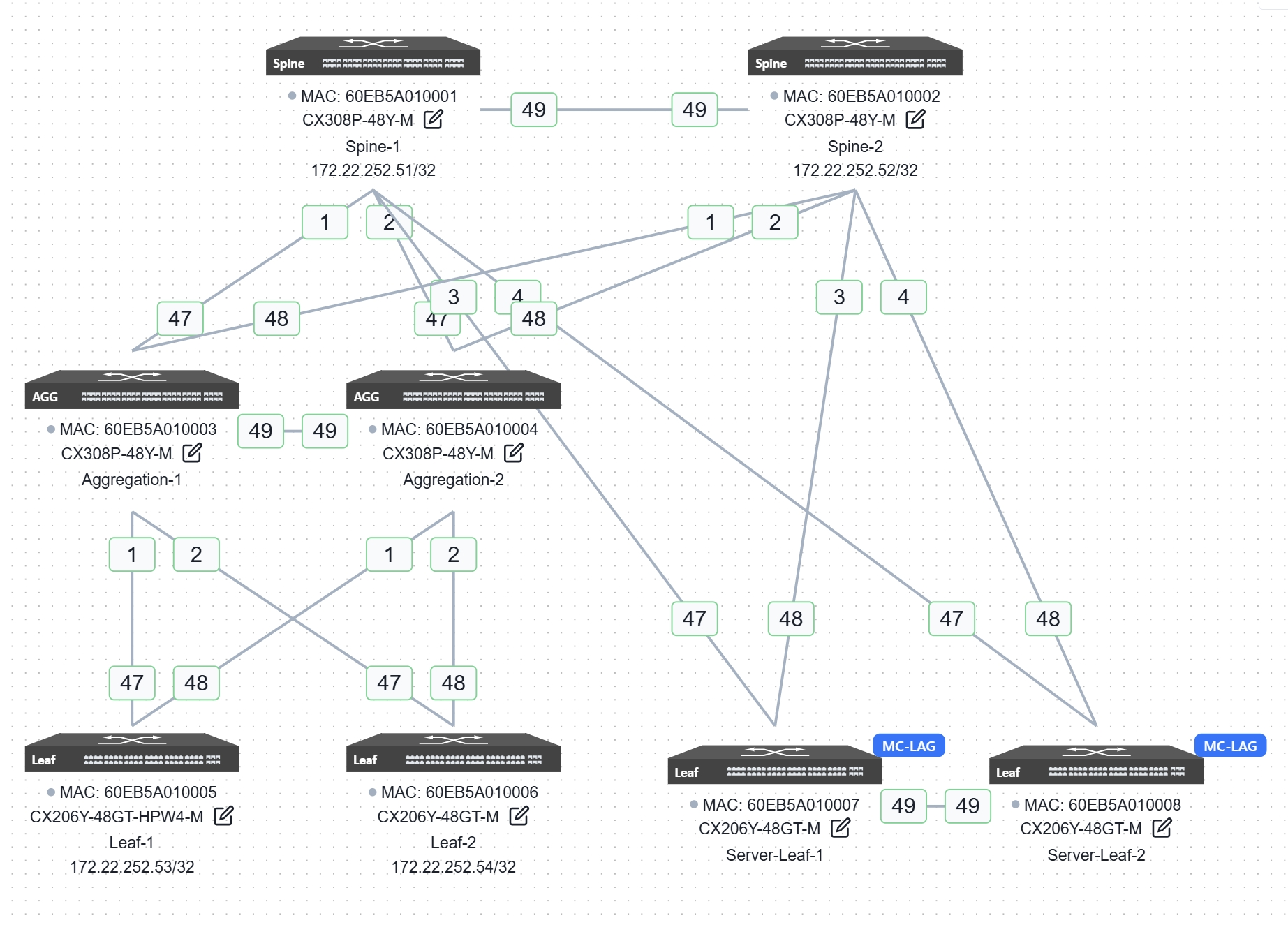
上图为一个128计算节点(1024个GPU)的400G AI后端网络Rail-optimized架构组网图,部署24台CX864E-N(8台Spine节点,16台Leaf节点),包含两个Group,每个Group 8台Leaf节点。其核心设计原则如下:
每个GPU连接专用网卡,每台服务器的网卡按照“NIC1-Leaf1、NIC2-Leaf2……”的规则接入Leaf交换机,为每个Rail规划一个子网,Leaf交换机作为Rail内的默认网关。
网络采用2层Clos架构,Spine与Leaf全互联,利用IPv6 link-local特性建立unnumbered BGP邻居,宣告各Rail的网段路由,实现路由交换,无需为Leaf-Spine互联接口规划IP地址;
Leaf下行与上行容量的比值应严格遵循1:1收敛比,保证无阻塞传输;
Leaf、Spine交换机启用一键RoCE及负载均衡特性,构建无损网络。
4.2.2 设备选型
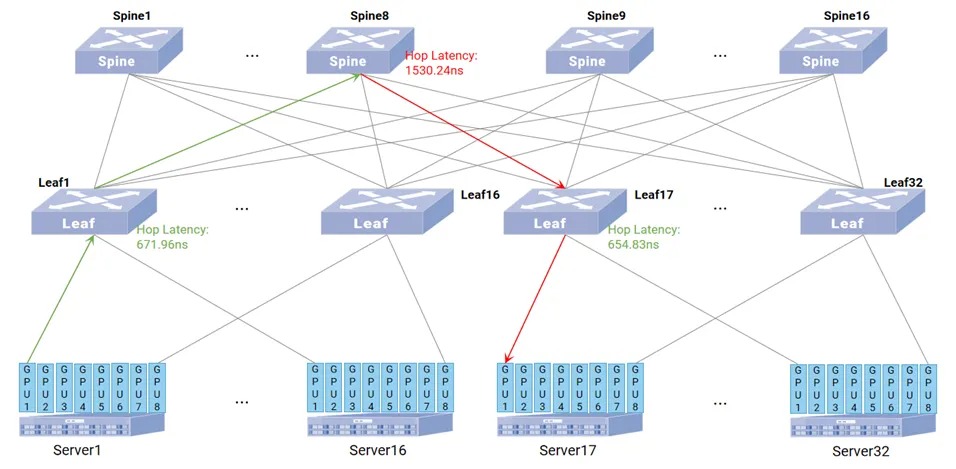
建设中大规模400Gbps RoCEv2网络,推荐选用星融元数据中心交换机CX864E-N、CX732Q-N,核心依托两款设备的超低转发时延特性——CX864E-N端到端转发时延低至560ns,CX732Q-N更可达500ns,可实现同轨传输约600ns超低时延,跨轨传输(Leaf-Spine-Leaf)三层转发的端到端网络时延控制在2μs以内,充分满足RoCEv2网络对低时延的严苛要求。
在Rail-optimized组网中,单Group内的Leaf节点数量与每台服务器的GPU数量(即Rail数量)相关。以NVIDIA DGX H100 GPU服务器(每台搭载8个GPU)为例,一个Group需配置8个Leaf节点,对应8个Rail。
每个Group可接入的服务器最大数量与Leaf节点的接口形态相关。为保证1:1收敛比,Leaf节点的一半接口用于连接GPU服务器,另一半接口则连接Spine节点,因此每个Group最多可接入的GPU服务器为Leaf节点可用接口数量的一半。不同型号交换机的最大接入能力如下表所示:
表格 3 Rail-optimized组网下不同型号交换机每个Group的最大接入能力
Leaf节点型号
每台设备可用的400G接口数量
每个Group最多可接入的GPU/服务器数量
CX732Q-N
32
128/16
CX864E-N
128
512/64
说明:CX864E-N配备了64个800GE接口,通过接口拆分,最多可提供128个400G接口。
Spine节点数量与Leaf节点的接口数量相关。假设Leaf、Spine节点分别提供了M、N个400G接口,则所需的Spine节点的数量=(总Leaf节点数量×M÷2)÷N。若Leaf、Spine选用同一款机型,则Spine节点的数量 = Leaf节点数量÷2。
举例:
假设要构建一个512台H100服务器(4096个GPU)的GPU集群,选用CX864E-N作为Leaf、Spine节点。则:
每个Group中的Leaf节点数量 = 8
每个Group最多可接入的服务器数量 = 128÷2 = 64
每个Group最多可接入的GPU数量 = 64×8 = 512
Group数量 = 4096÷512 = 8
总Leaf数量 = 8×8 = 64
总Spine数量 = 4×8 = 32
设计计算网络时,需同步考虑可扩展性。为保证全连接,该网络最多支持的Group数量受限于Spine节点的可用接口数。以CX864E-N为例,最多可连接128台Leaf节点,每个Group含8台Leaf,则最多支持16个Group。选用CX864E-N作为Leaf、Spine节点时,可扩展的最大规模如下:
最大支持的Group数量 = 128÷8 = 16
最大支持的服务器数量 = 16×64 = 1024
最大支持的GPU数量 = 16×512 = 8192
下表分别为选用CX864E-N、CX732Q-N部署不同GPU数量后端网络的节点配置需求:
表格4 选用CX864E-N部署不同GPU数量的后端网络所需的节点配置需求
总GPU数/服务器数
Leaf节点数量
Spine节点数量
每台Leaf与Spine之间的400G链路数
256/32
4
2
32
512/64
8
4
16
1024/128
16
8
8
2048/256
32
16
4
4096/512
64
32
2
8192/1024
128
64
1
表格 5 选用CX732Q-N部署不同GPU数量的后端网络所需的节点配置需求
总GPU数/服务器数
Leaf节点数量
Spine节点数量
每台Leaf与Spine之间的400G链路数
128/16
8
4
4
256/32
16
8
2
512/64
32
16
1
针对节点配置需求,有如下总结:
每个Group中的Leaf节点数量 = 每台服务器的GPU数量
每个Group最多可接入的服务器数量 = Leaf节点的可用接口数÷2
每个Group最多可接入的GPU数量 = 每个Group最多可接入的服务器数量×8
Group数量 = 集群所需的GPU数量÷每个Group最多可接入的GPU数量
总Leaf数量 = 每个Group中的Leaf节点数量×Group数
总Spine数量 = 总Leaf数量×M÷2÷N
针对可扩展的最大规模,有如下总结:
最大支持的Group数量 = Spine节点的可用接口数÷每个Group中的Leaf节点数量
最大支持的服务器数量 = 最多支持的Group数量×每个Group最多可接入的服务器数量
sGPU数量 = 最多支持的Group数量×每个Group最多可接入的GPU数量
5 结语
本方案采用Rail-only、Rail-optimized架构设计,减少集群中GPU间通信的跳数,加速all-to-all性能并缩短训练时间。本方案可有效支撑不同规模的AI集群计算网部署,如想了解具体配置实施案例,请后台回复“AI智算后端网络最佳实践”。
方案白皮书下载地址:AI智算后端网络设计指南