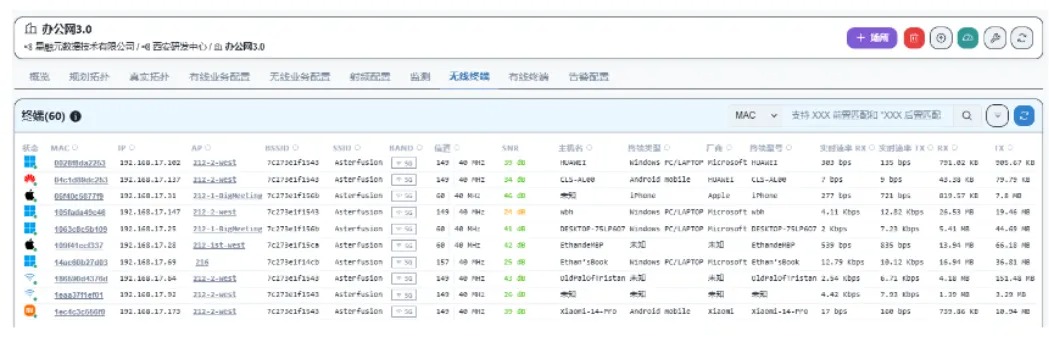
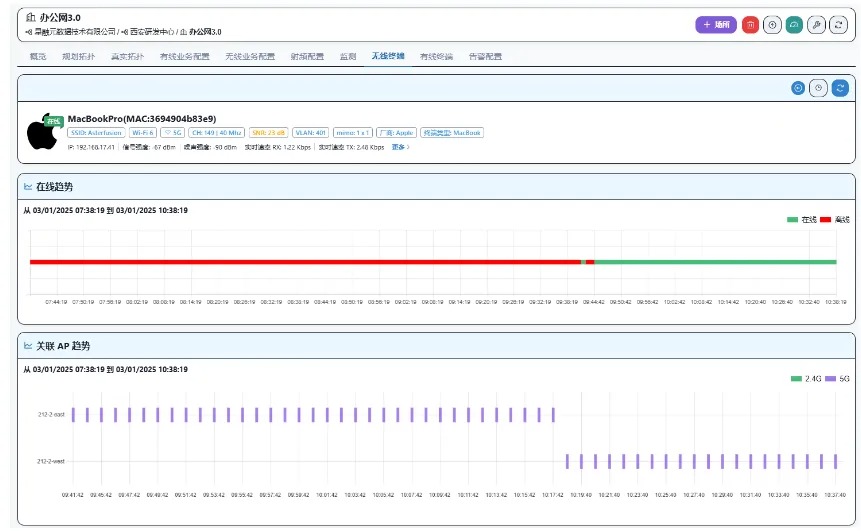
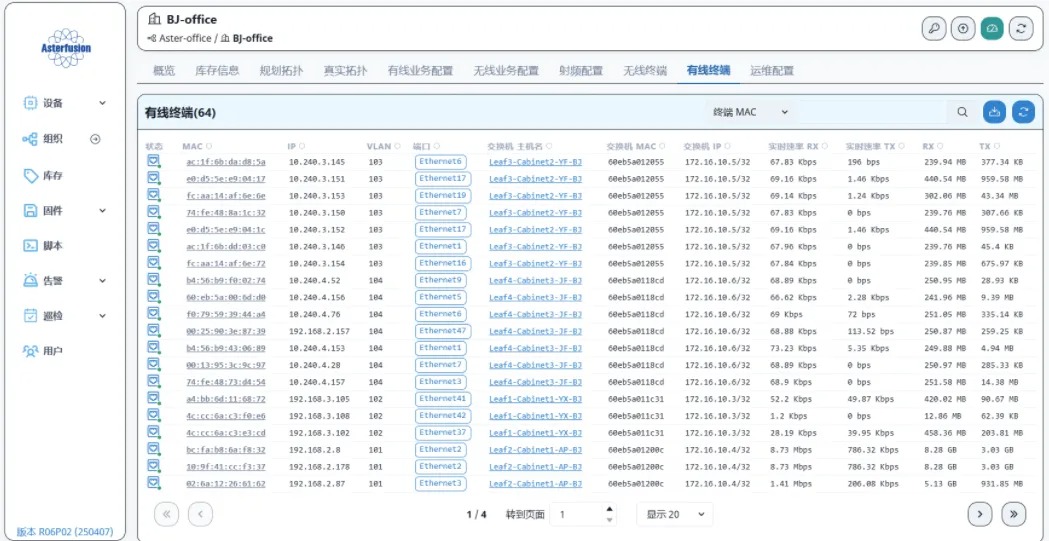
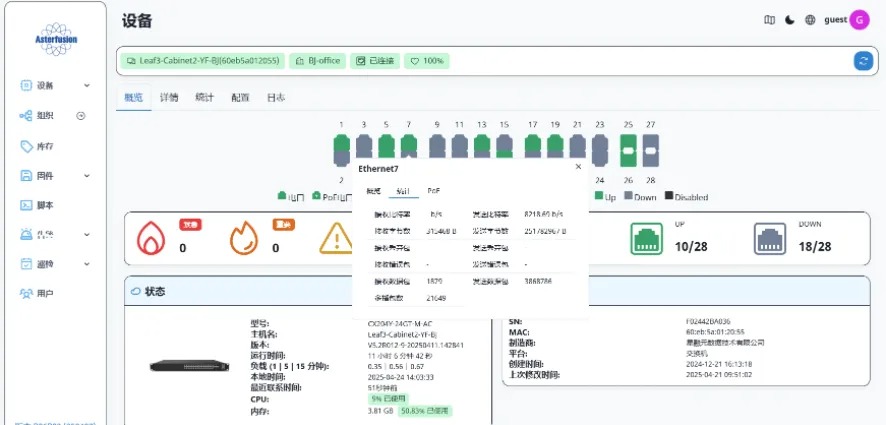
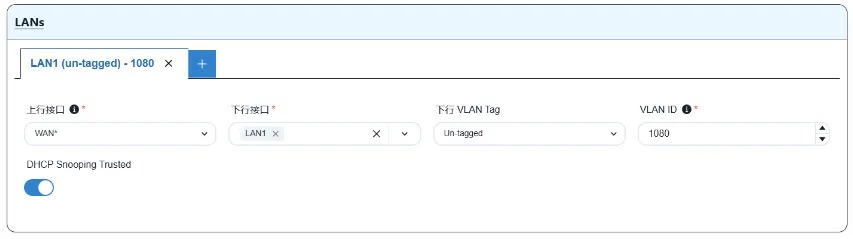
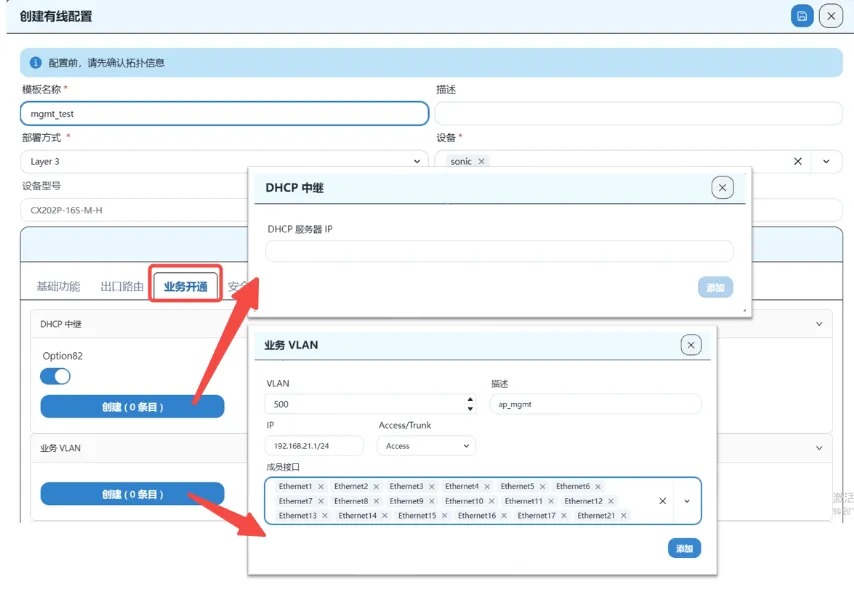
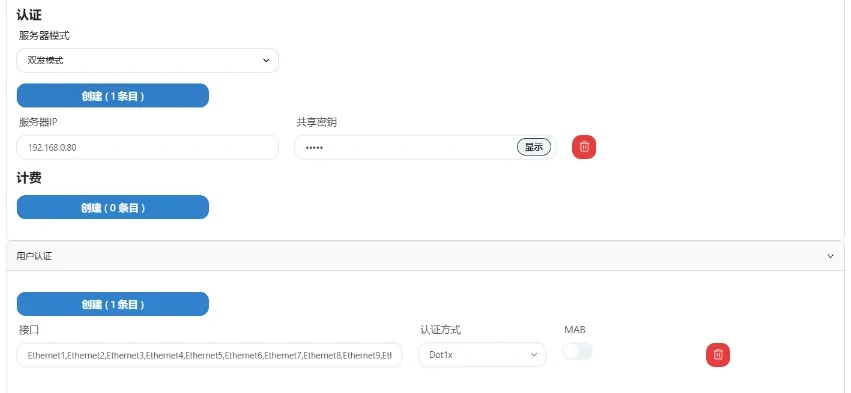
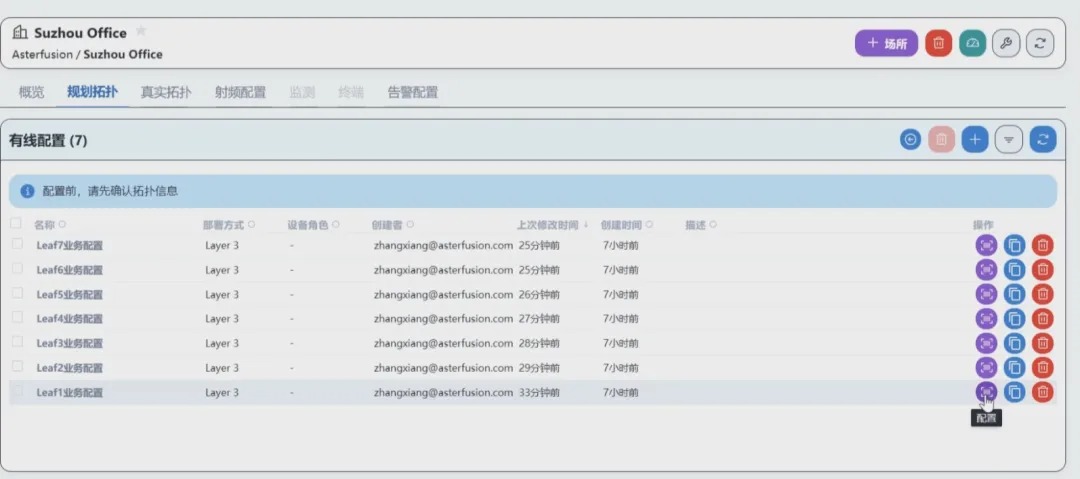
A-Lab | 主动规划+自动化配置工具,简单应对AI智算网络 ECMP 负载不均
关注星融元

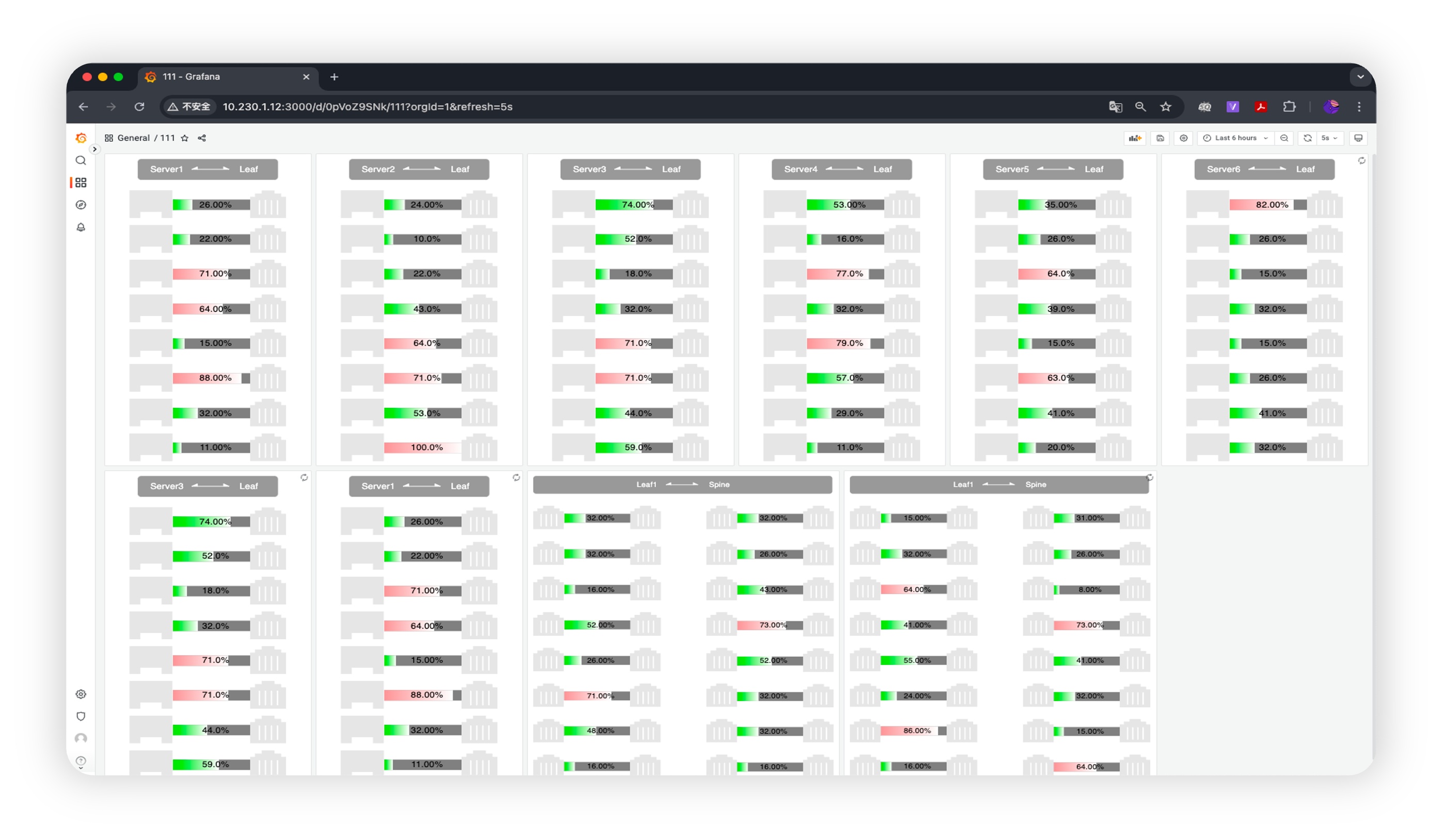
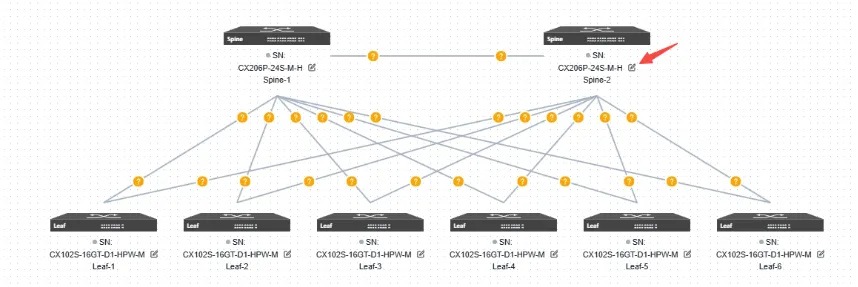
智算环境组网采用的 Clos 架构下,各交换节点基于常规的 ECMP 路由(分布式运行和自我决策转发)往往无法完全感知全局信息,容易导致多层组网下的流量发生 哈希(HASH)极化 现象,导致某些路径负载过重(拥塞),而其他路径负载很轻(闲置),严重拖慢智算集群整体性能。
什么是哈希极化?
哈希极化,又称哈希不均,其根本原因在于哈希算法的一致性与网络拓扑结构和流量模式特性之间的相互作用。
一般情况下,网络设备通常使用相同或非常相似的哈希算法和相同的输入参数(如标准的五元组)。
当网络中存在大量具有相似特征的流(例如,大量流共享相同的源IP或目的IP),而这些特征恰好是哈希算法的主要输入,那么这些相似的流非常有可能不像预期那样被分布到所有可用的等价路径上,而是呈现出明显的偏向性。
此外,当流量经过多个使用 ECMP 的网络设备(原本在leaf层被“打散”的流量,经过Spine 层转发又被集中到少量链路上),以及流量模式本身的特征(由少数大流主导),都会加剧哈希极化现象。
主动路径规划配置逻辑
在不引入动态负载均衡技术的情况下,我们可以通过增加参与哈希计算的因子,以及主动规范流量路径的方式来应对 AI 算力集群规模化部署的痛点(例如负载均衡和租户隔离等),主动路径规划需要网络工程师按照如下转发逻辑去配置 RoCE 交换机:
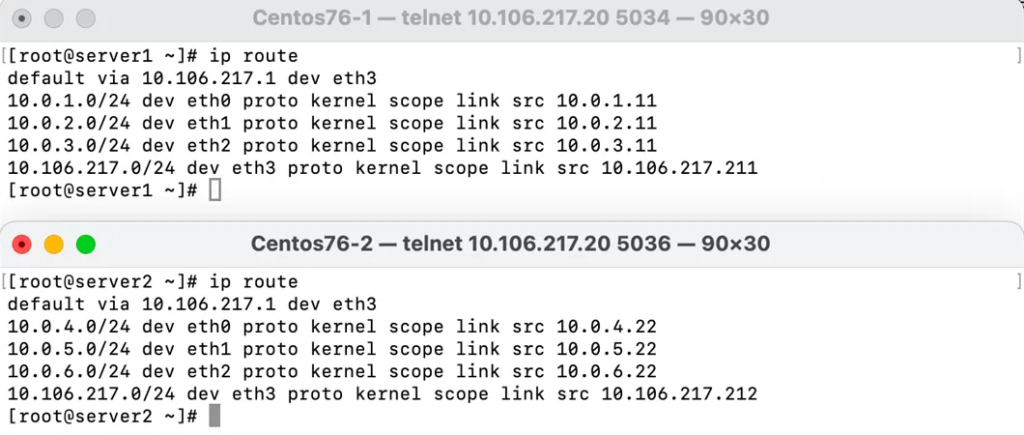
1. 智算服务器上每张网卡都对应一个接口,服务器产生跨 Spine 的上行流量会在Leaf交换机判定并执行策略路由转发给对应 Spine
- 在1:1无收敛的情况下,Leaf 交换机的每个下行端口绑定一个上行端口
- 在 n:1 的情况下,上下行端口以倍数关系(向上取整) 形成 n:1 的映射
2. 跨 Spine 上行流量在 Spine 上按照标准 L3 逻辑转发在智算环境下的轨道组网中,多数流量仅在轨道内传输,跨轨传输流量较小,网络方案可以暂不考虑在 Spine 上拥塞的情况;
3. 跨 Spine 下行流量进入 Leaf 后根据 default 路由表指导转发。
可以看到,以上配置逻辑若完全以手动输入命令行的方式下发到所有交换机,会是一件相当繁琐且耗时的事情,也容易引入配置失误。
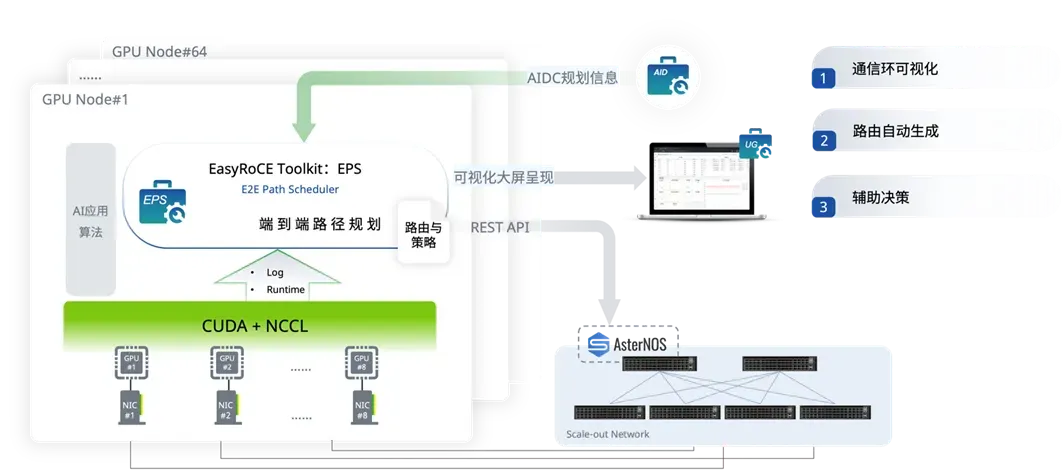
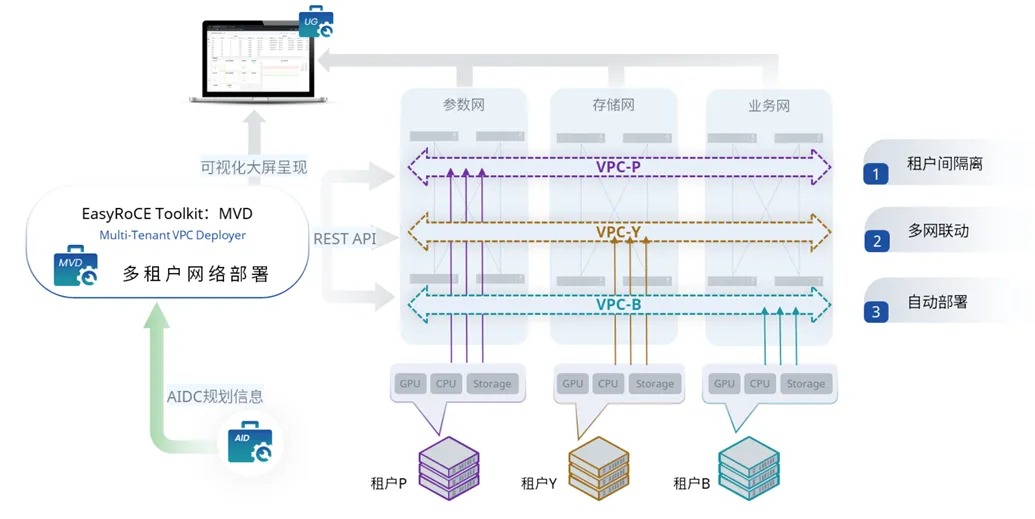
借助 EasyRoCE 工具配置
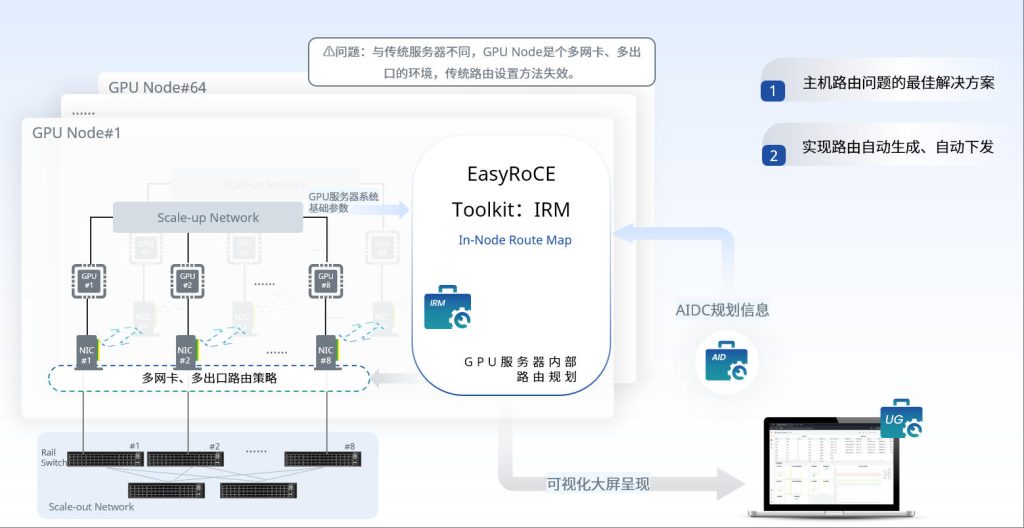
为加速智算场景下的路由优化配置,此前我们有介绍过 PPD 工具(主动路径规划,Proactive Path Definer)的1.0 版本。如今经过一段时间的实践打磨,PPD 工具迎来了一轮迭代,升级到2.0版本,其主要运行步骤如下:
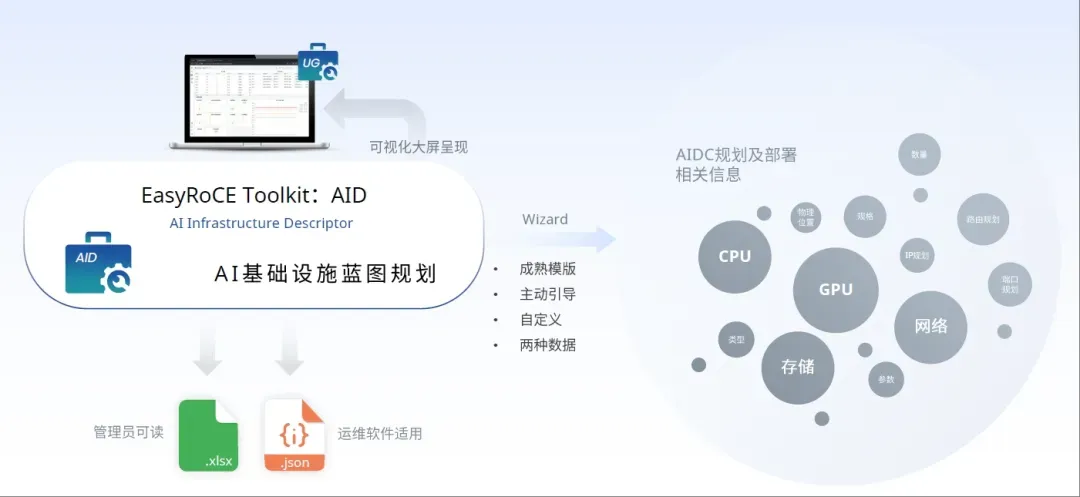
- 从 AID 工具(AI基础设施蓝图规划,AI Infrastructure Descriptor)读取网络基础配置信息。
- 运行 PPD 工具,生成路由配置文件。
- 在 UG 工具 (统一监控面板,Unified Glancer)中展示配置文件,用户核对并确认配置下发。
作为 EasyRoCE 工具套件的构成部分,PPD 可以独立运行在服务器上,也可以代码形式被集成到第三方管理软件中。
EasyRoCE Toolkit 是星融元依托开源、开放的网络架构与技术,为AI 智算、超算等场景的RoCE网络提供的一系列实用特性和小工具,如一键配置RoCE,高精度流量监控等…所有功能对签约客户免费开放。
详情访问:https://asterfusion.com/easyroce/
PPD 2.0 升级了什么?
PDD 2.0 版本主要带来了以下几点的显著提升:
- 改善 AID 与 PPD 工具的对接流程,完全实现网络基础信息的自动化填充
- 优化 PPD 工具的图形界面操作体验,配置下发进度和结果可即时呈现,便于管理员快速排查异常原因
- 自动集成到统一监控面板(UG),与其他 RDMA 网络配置信息在一处集中查看和管理
使用演示
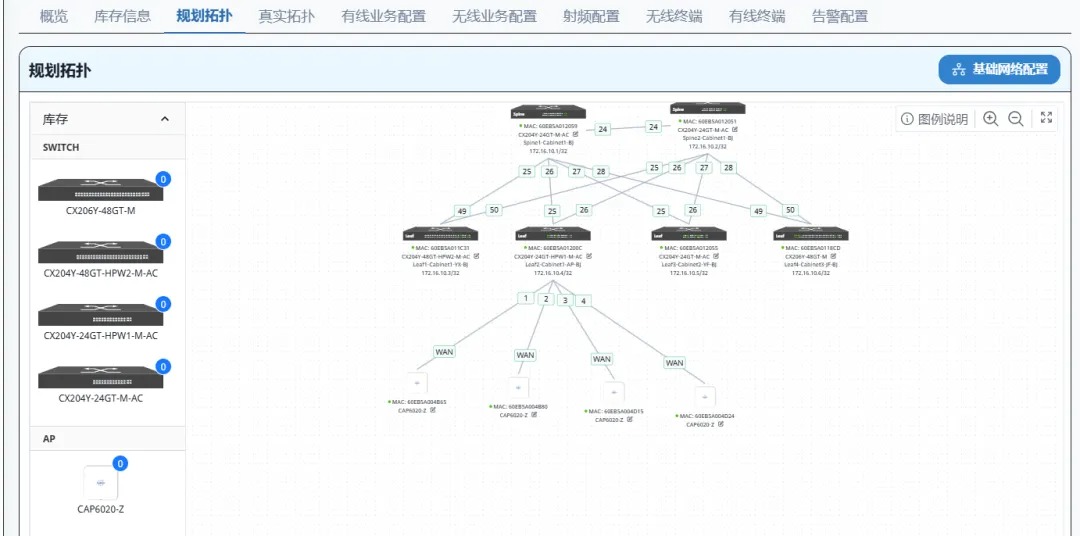
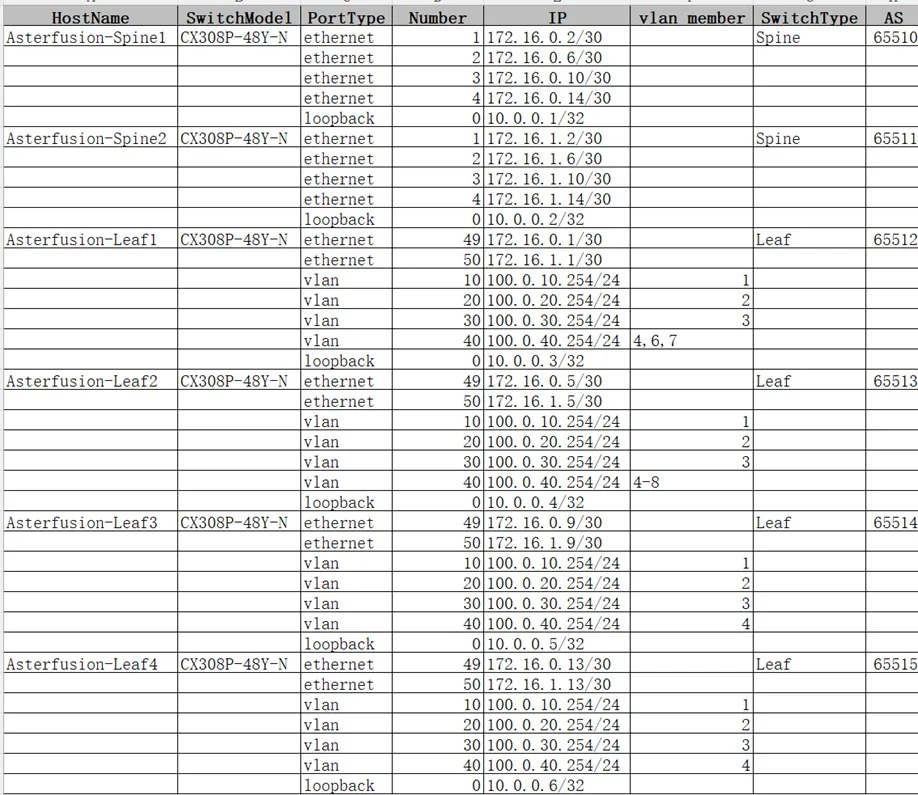
第一步:导入基础网络信息
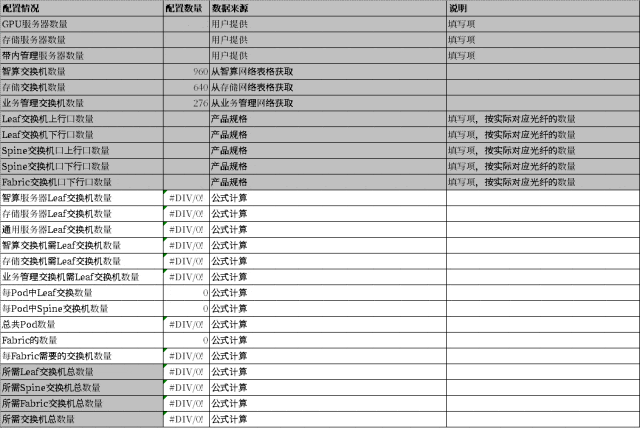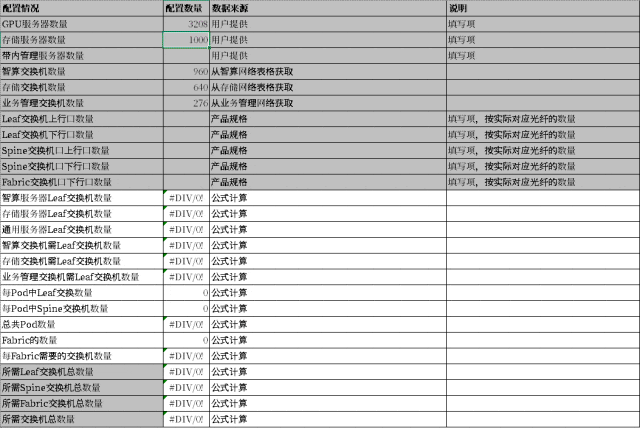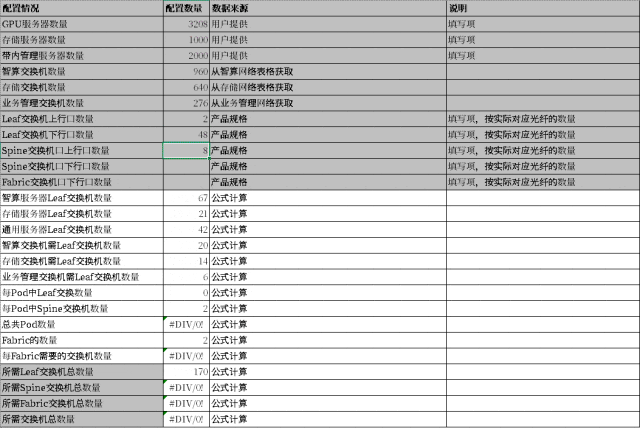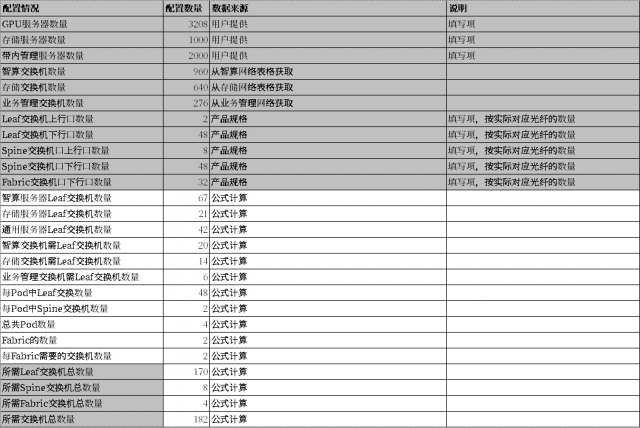
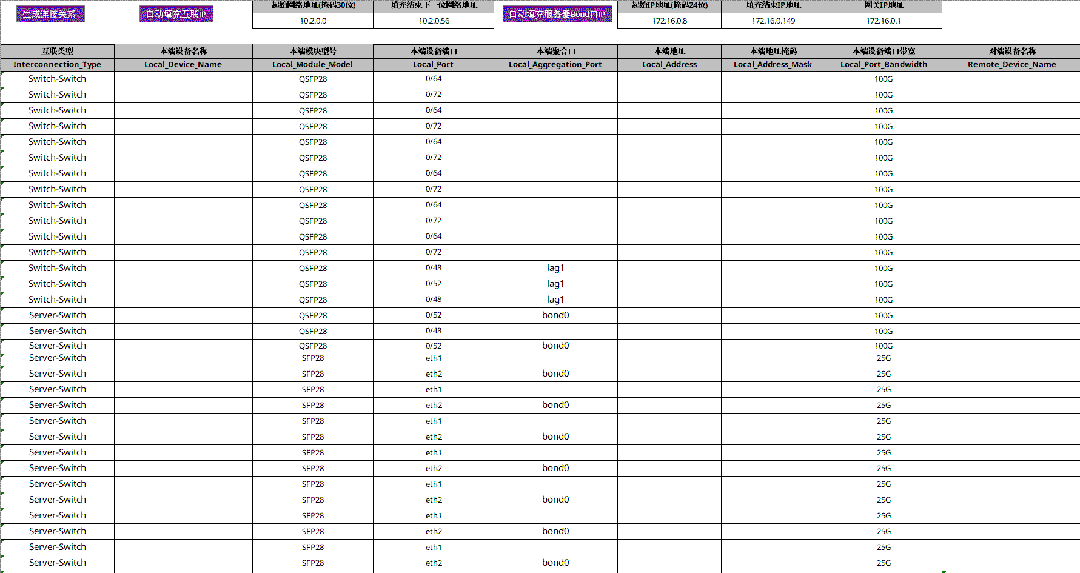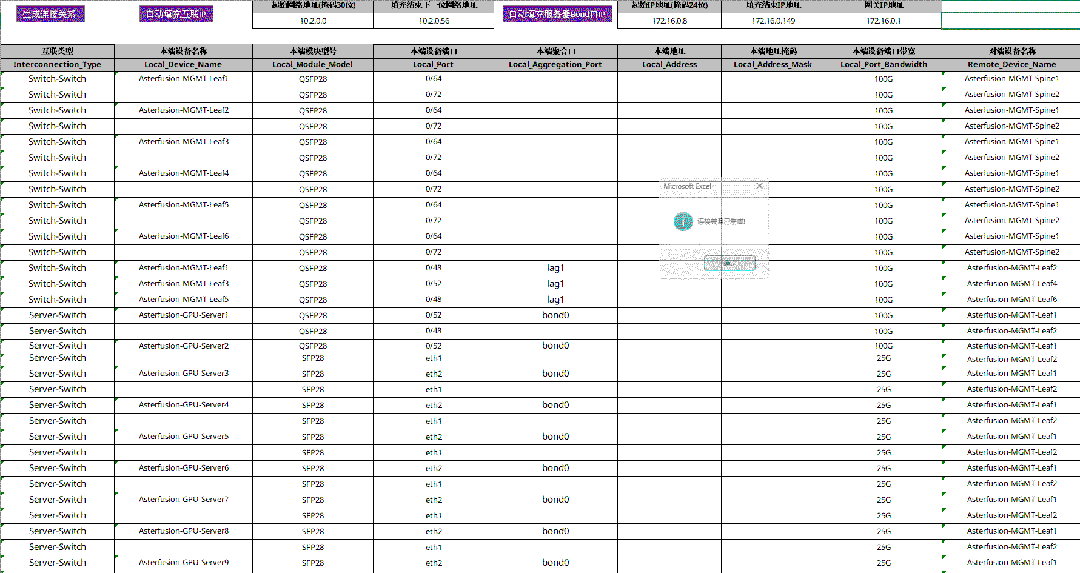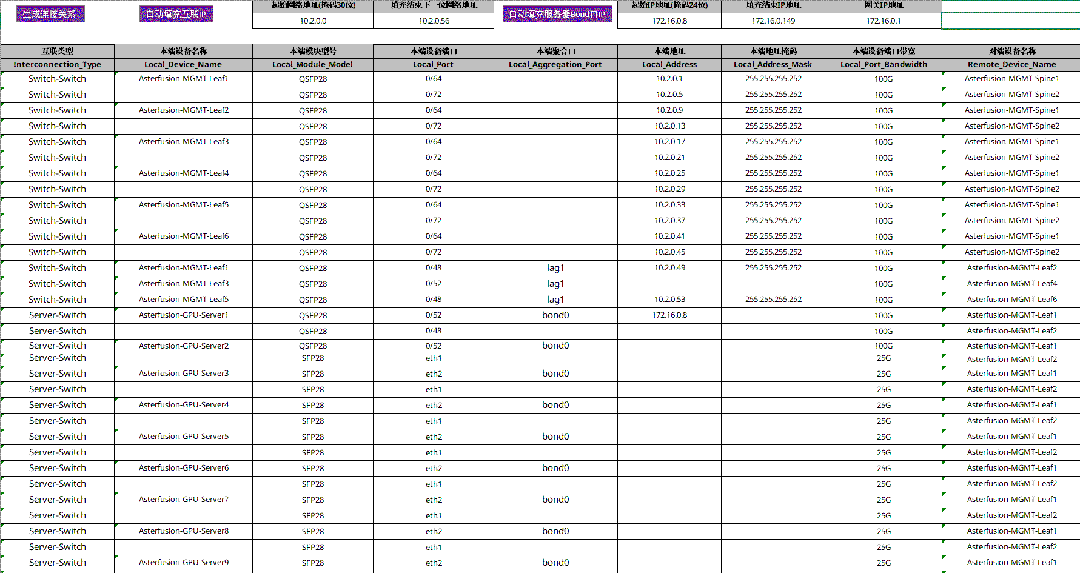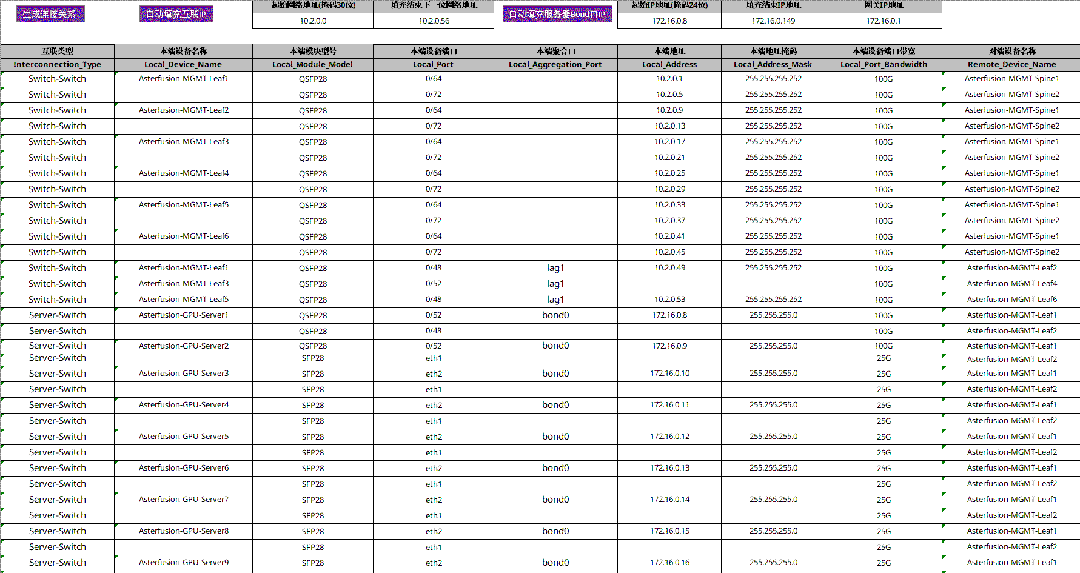
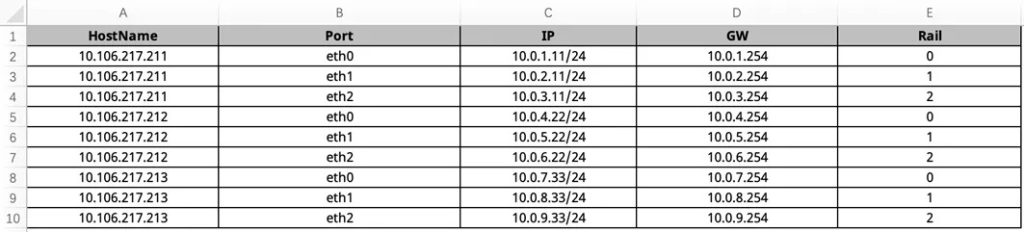
AID 工具是 PPD 的“数据源”,其中有一个专门的工作表存储了 PPD 工具所依赖的所有基础网络信息,主要是 GPU server 各网卡的 IP 地址、交换机接口互联关系和其对应的 IP 地址等,以上都支持一键自动填充;此外,该工作表内还预留有与多租户网络配置相关的标识信息(InstanceID和 Description),管理员可按需手动填写以便于后续管理、使用。
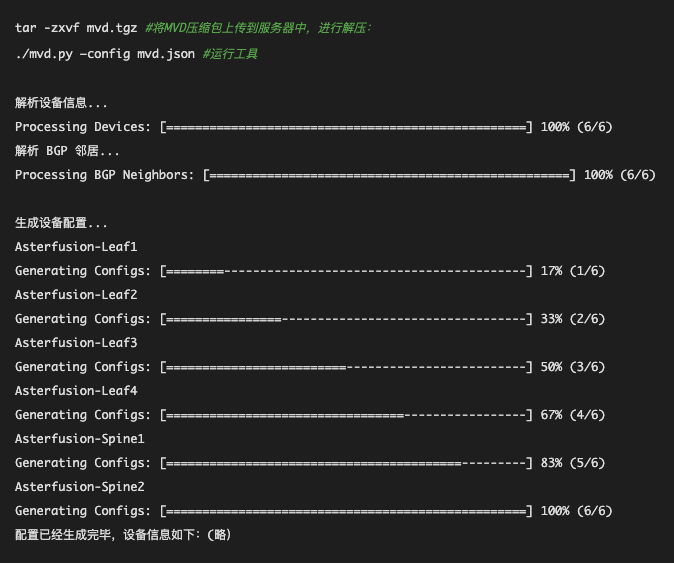
第二步:运行PPD工具生成路由配置
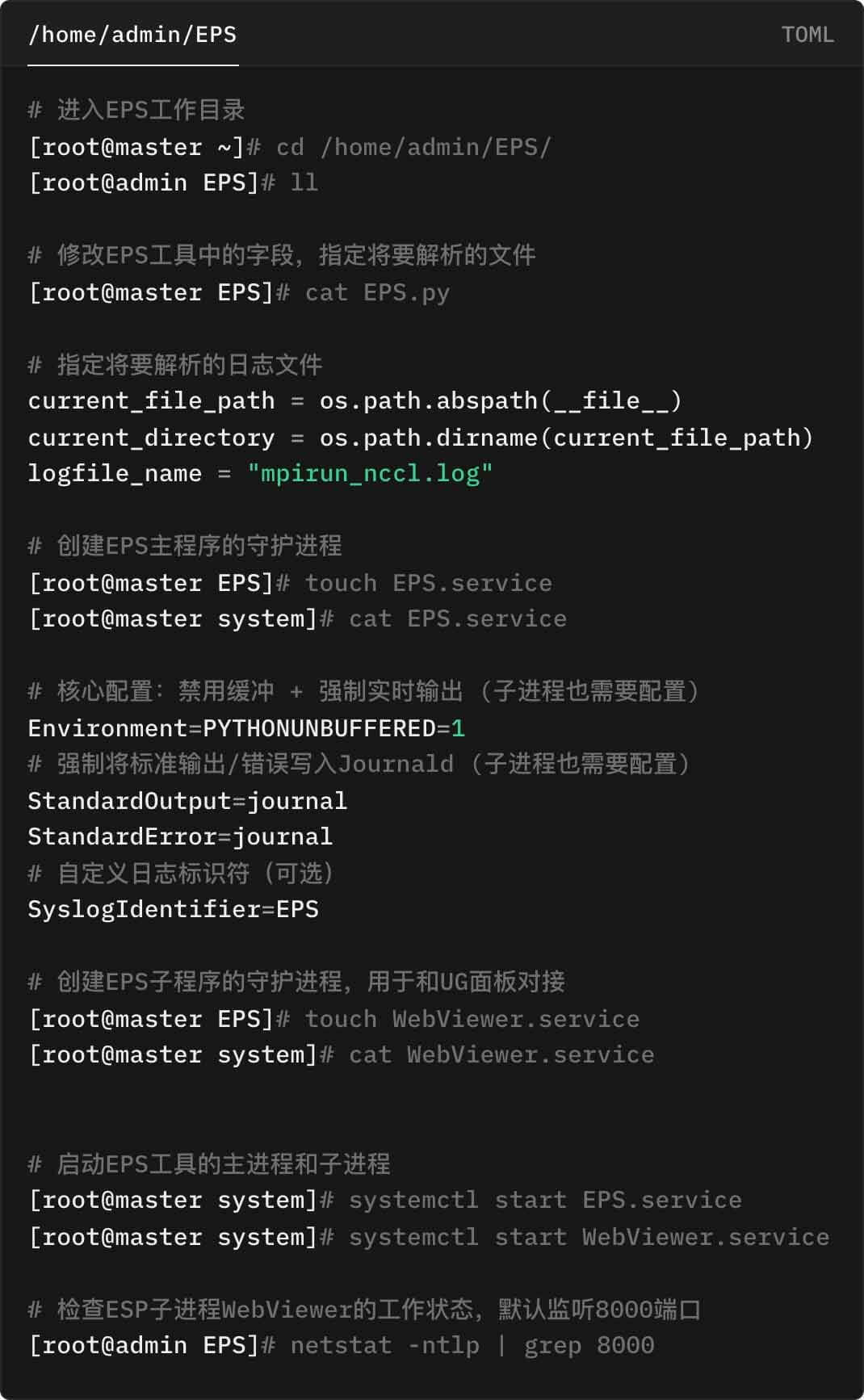
上传PPD相关工具到管理服务器,解压后程序结构如下:
运行 start_ppd.sh 命令即可启动PPD。
第三步:选择下发配置
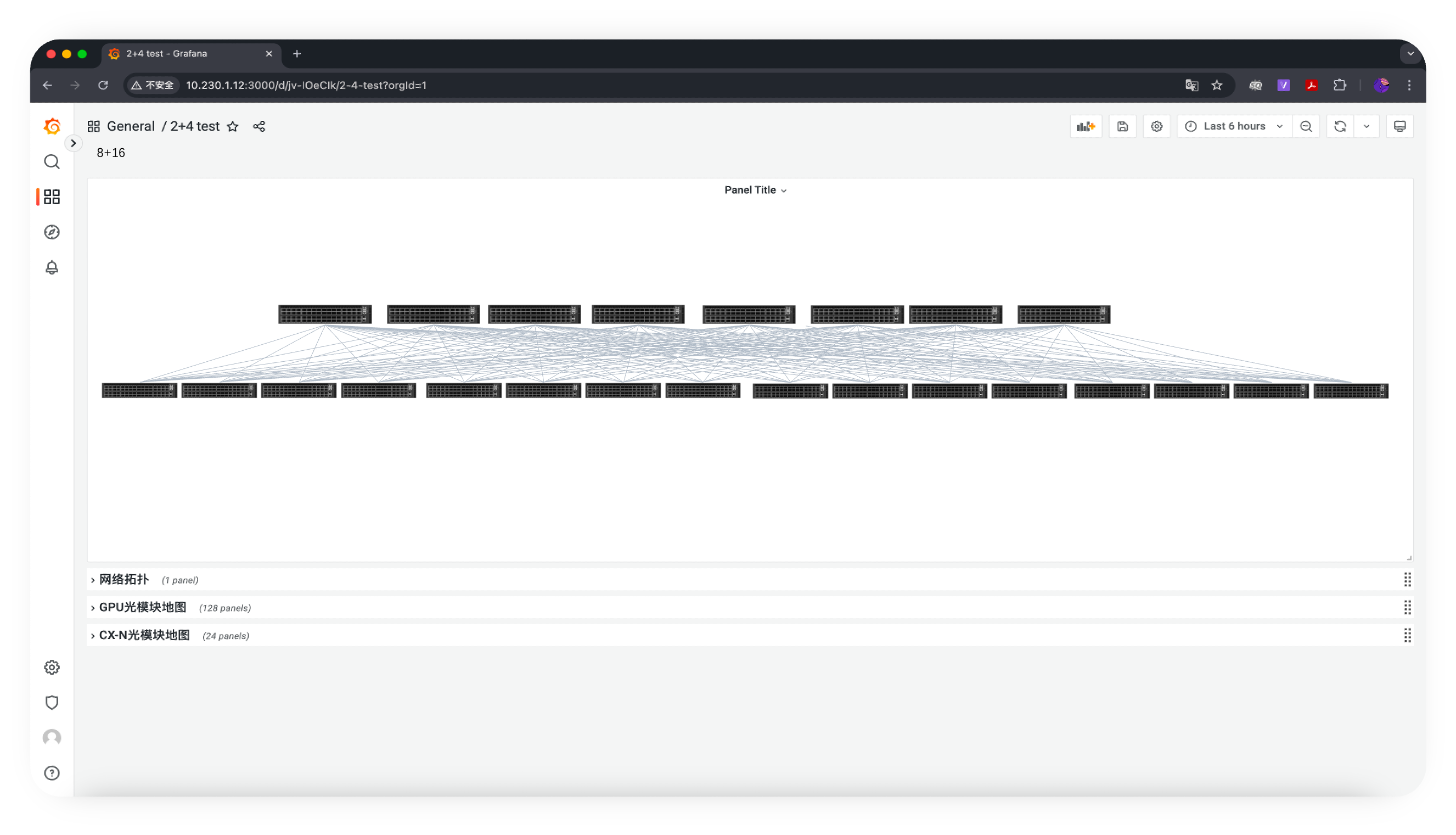
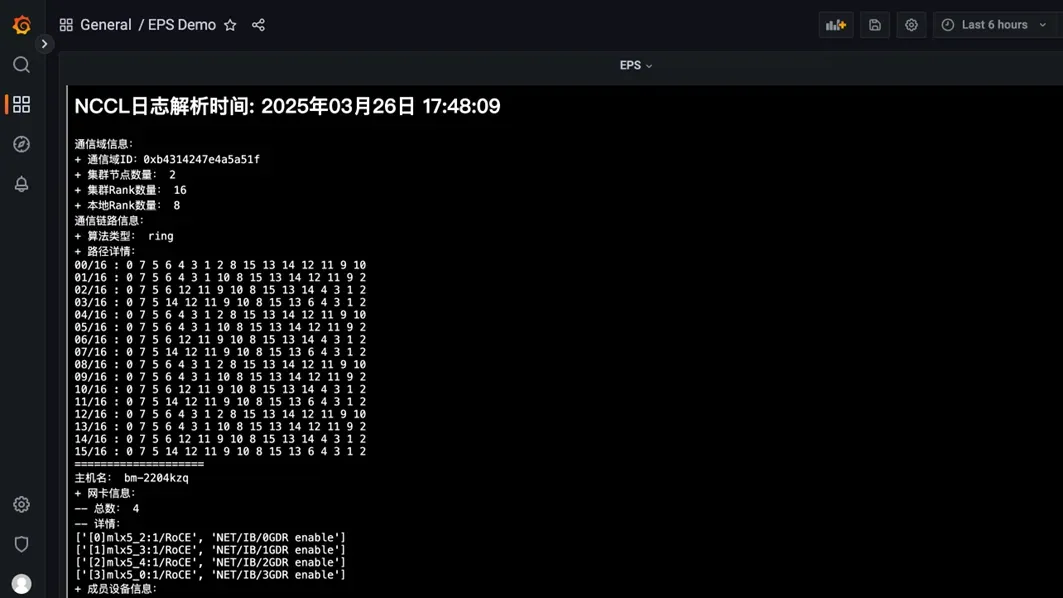
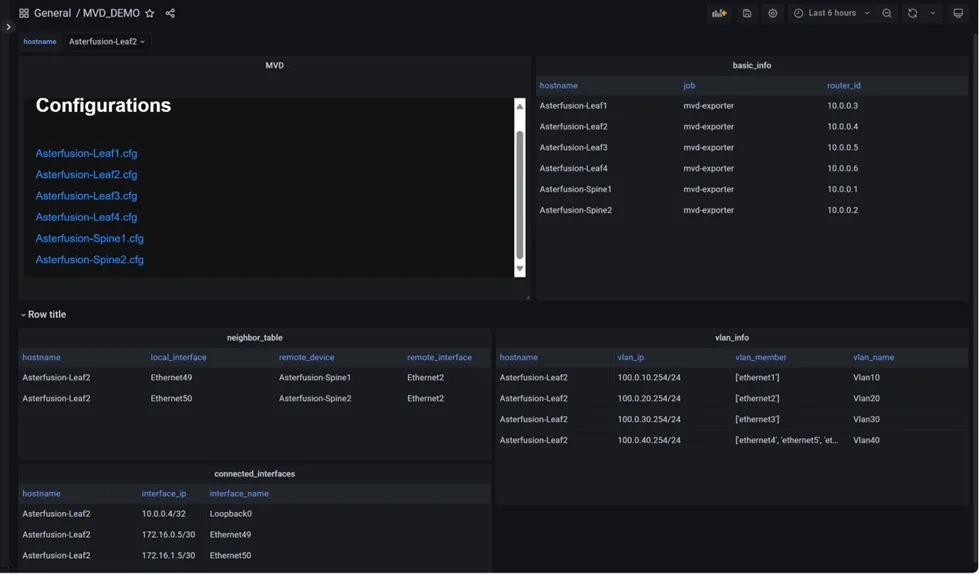
此时,所有与主动路由规划相关的信息已经自动集成到了统一监控面板,管理员登录UG面板可以看到 PDD 工具界面。
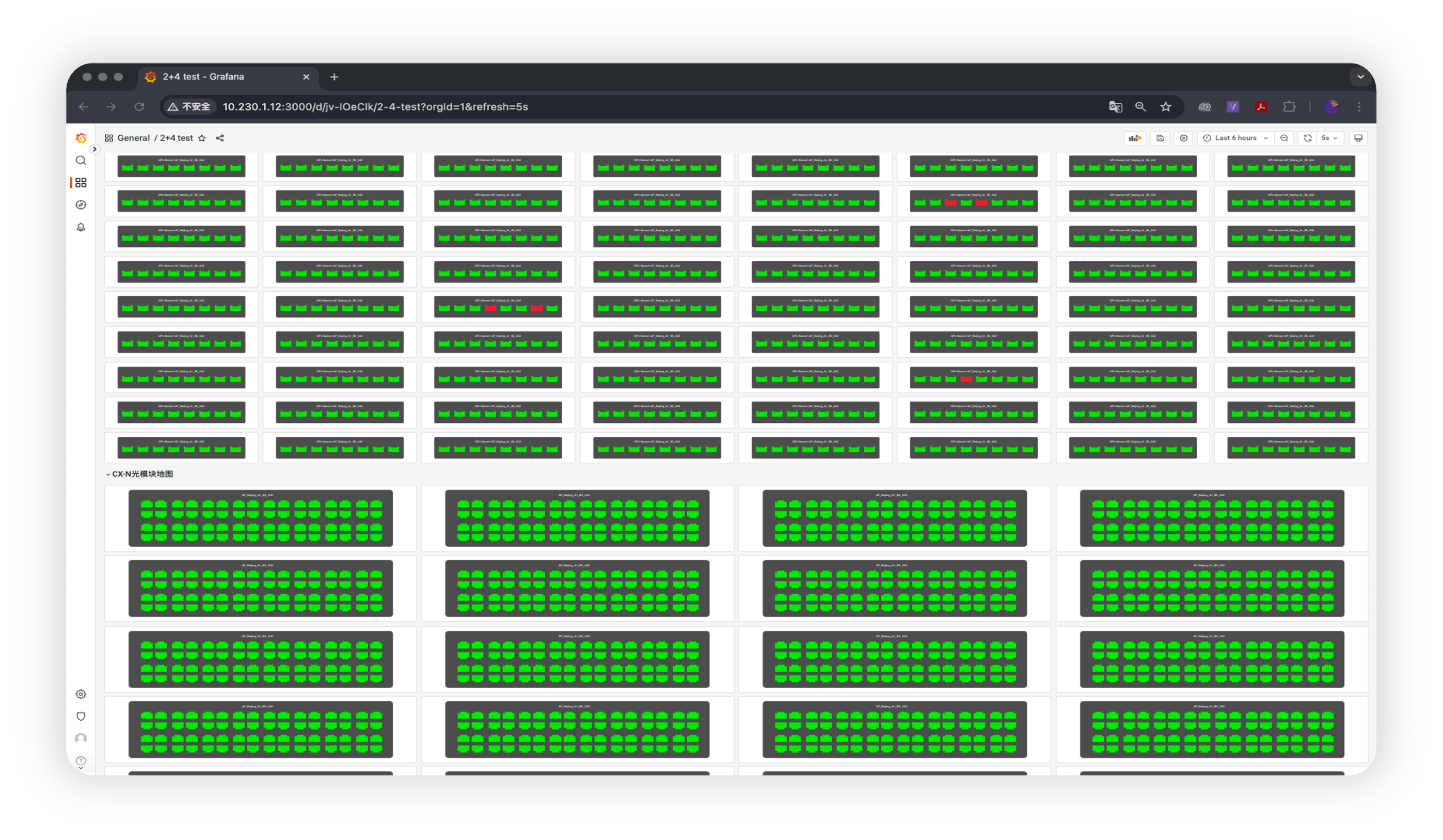
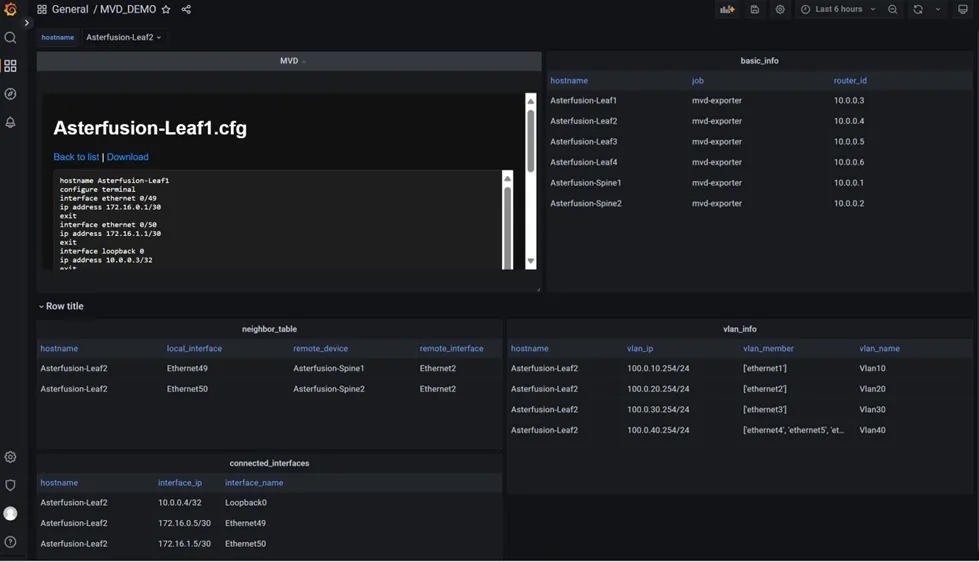
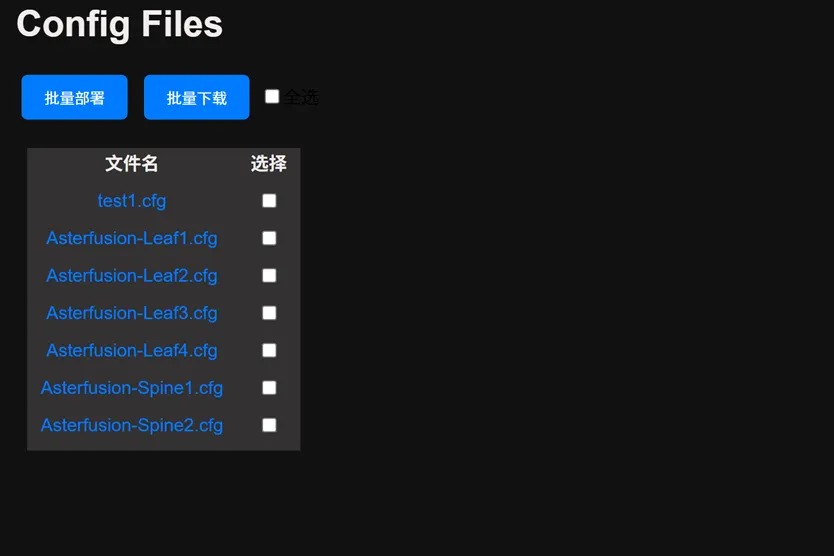
点击左上配置生成按钮,会出现设备可用的配置文件(XXXX.cfg)。管理员可以查看生成配置文件详情二次核对,确认勾选,再点击上方批量下发即可等待工具自动下发配置。
待配置全部下发完成,界面即时显示设备当前部署结果,失败设备提供报错信息,排障后可尝试二次下发。
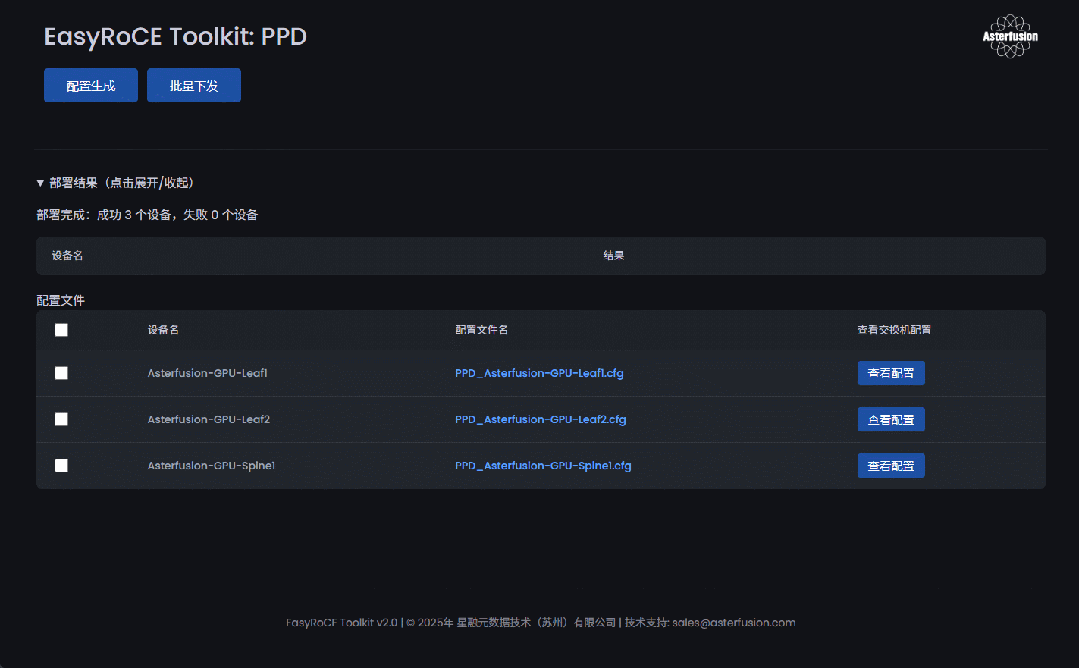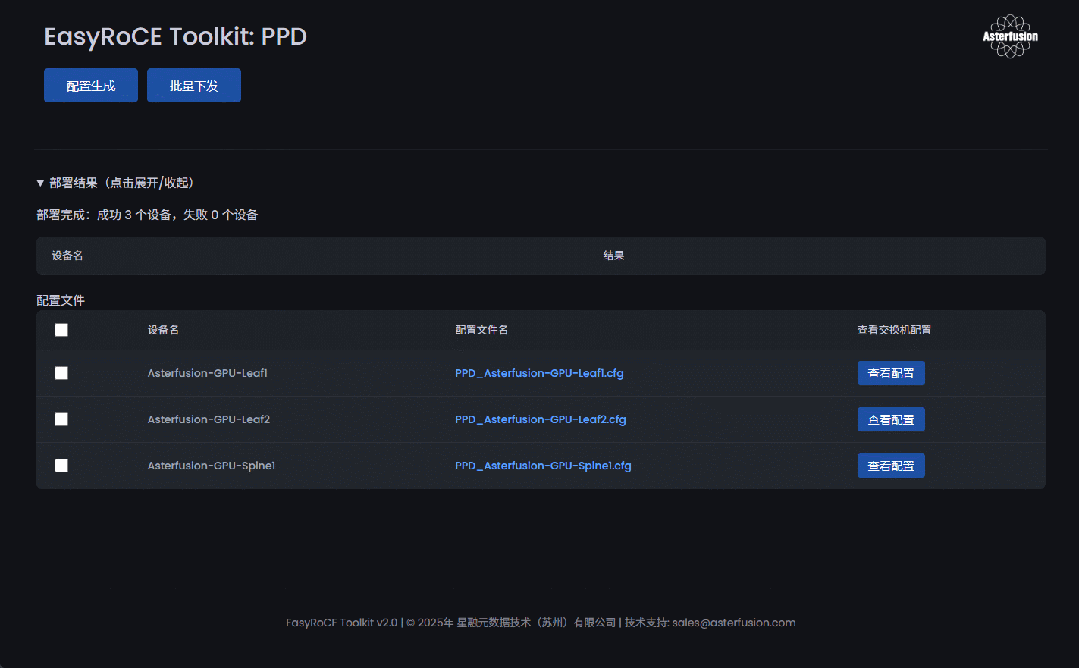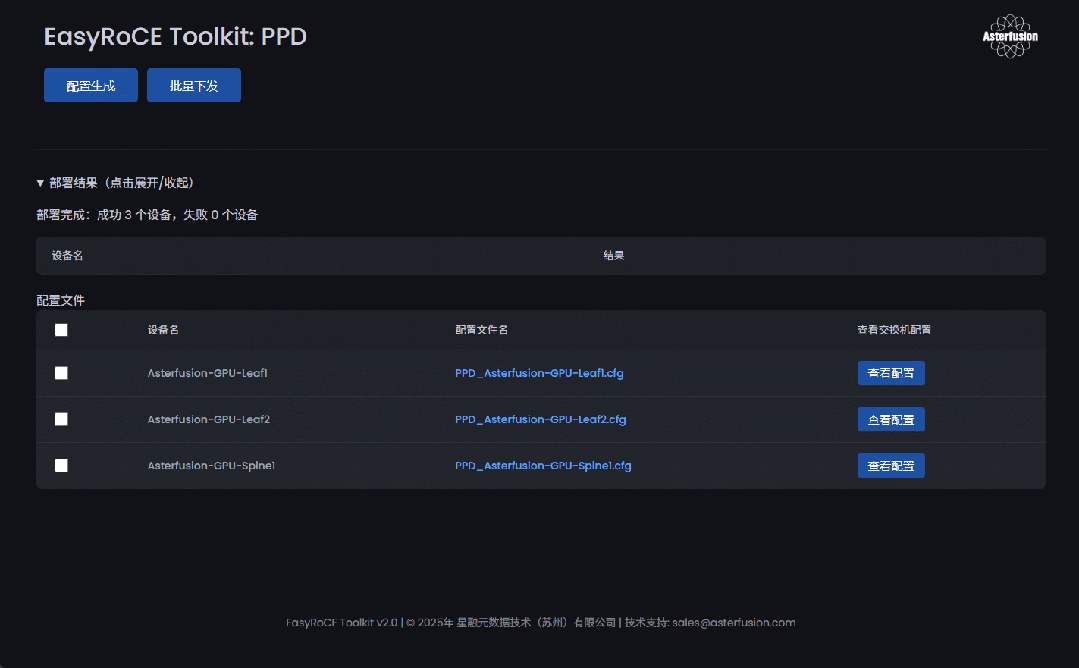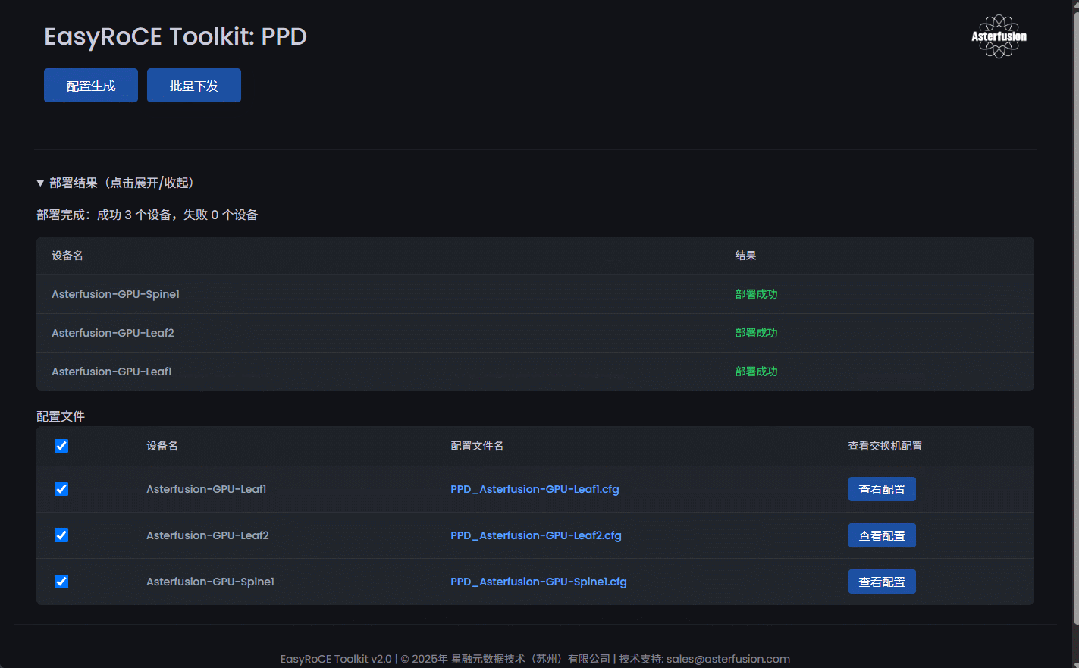
EasyRoCE-PPD 工具界面概览