
AsterNOS-VPP 与硬件卸载:打造下一代高性能 IPsec 网关
在数字化转型的浪潮中,企业网络边界正在迅速扩张 。随着光纤宽带向 10G、25G 甚至 100G 演进,网络工程师面临着一个棘手的挑战:如何在开放网络架构下,实现与带宽能力相匹配的安全加密性能 ?
面对海量加密流量时,传统的软件路由方案往往力不从心 。今天我们将深入探讨这一性能瓶颈背后的技术逻辑,剖析 AsterNOS 如何利用 VPP(矢量报文处理)与硬件卸载技术打破性能天花板。
技术基础:IPsec 如何工作?
要理解性能瓶颈的根源,首先需要深度理解 IPsec 的运行机制 。
什么是 IPsec?
IPsec(互联网协议安全)并非单一协议,而是由 IETF 定义的一套开放的网络层安全框架协议族 。它主要由三个核心组件构成:
- AH(Authentication Header,认证报文头):提供数据源认证和完整性校验,确保报文未被篡改,但不提供加密功能
- ESP(Encapsulating Security Payload,封装安全载荷):提供加密、认证和完整性校验 。由于涉及数据载荷加密,这是 VPN 中最耗费性能的部分
- IKE(Internet Key Exchange,因特网密钥交换):用于自动协商密钥并建立安全联盟(Security Association,SA)
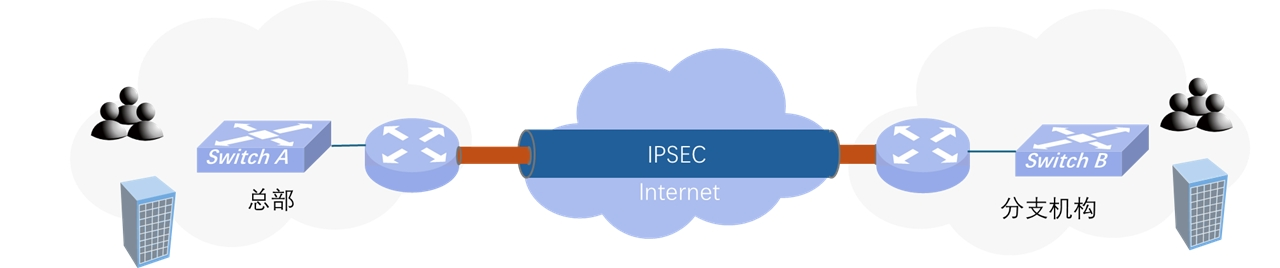
典型场景:企业分支机构互联
假设总部网络(192.168.1.0/24)需要与分支网络(10.1.1.0/24)通信 。
通过在两端网关配置 IPsec,我们可以在不可信的公共网络(互联网)上建立虚拟加密隧道:所有流经该隧道的报文在离开网关前会自动加密,并在进入对方网关时解密,这一过程对终端用户是透明的 。
IPsec 运行在 OSI 模型的网络层(第 3 层),其典型的处理流程如下:
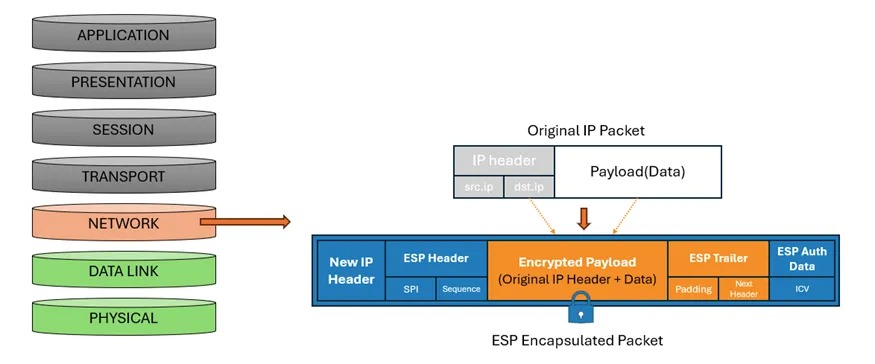
- 流量引导(兴趣流匹配):网络设备接收到报文后,将报文的五元组等信息和IPsec策略进行匹配来判断报文是否要通过IPsec隧道传输
- IKE 协商(控制面):双方建立安全通道,协商具体的密钥和算法
- 数据传输(数据面):发送方使用 SA 对原始 IP 报文进行 ESP 封装(加密载荷并添加首部),接收方则进行解密并校验 ICV(完整性校验值)
为什么传统软件路由在 10 Gbps+ 环境下会失效?
在传统网络架构中,通用 CPU(x86/ARM)是核心处理单元 。虽然 CPU 擅长处理复杂的控制逻辑,但在处理计算密集型的 ESP 封装任务时却有先天劣势 :
- 计算压力:通过接口的每一个数据包都需要进行高强度的数学运算(AES 加解密)和 SHA 哈希校验
- 上下文切换开销:在 10Gbps+ 的高并发流量下,海量报文会导致频繁的 CPU 中断和上下文切换,消耗大量计算资源
- 控制平面的不稳定性:当 CPU 被加密任务占满时,路由协议(如 BGP/OSPF)的存活报文可能无法及时处理,导致网络震荡
这种“用通用计算处理专用任务”的失配,会导致吞吐量大幅下降,延迟剧增 。
解决方案:VPP 矢量处理与硬件卸载加速
长期以来,企业在规划安全网关时常陷入两难:是选择灵活性高但性能有限的通用软件路由,还是选择性能强大但封闭昂贵的专用硬件 ?
星融元通过异构计算架构给出了第三种答案。通过深度融合 VPP 的矢量软件效率与 DPDK 硬件卸载的确定性算力,AsterNOS 成功解耦了控制面与数据面 :不仅让通用硬件焕发出媲美专用 ASIC 的线速加密能力,还保留了 SONiC 云原生生态的开放性与可编程性 —— 步入 10Gbps+ 互联时代的企业无需再为加密支付昂贵的“性能税” 。
相关硬件参阅:
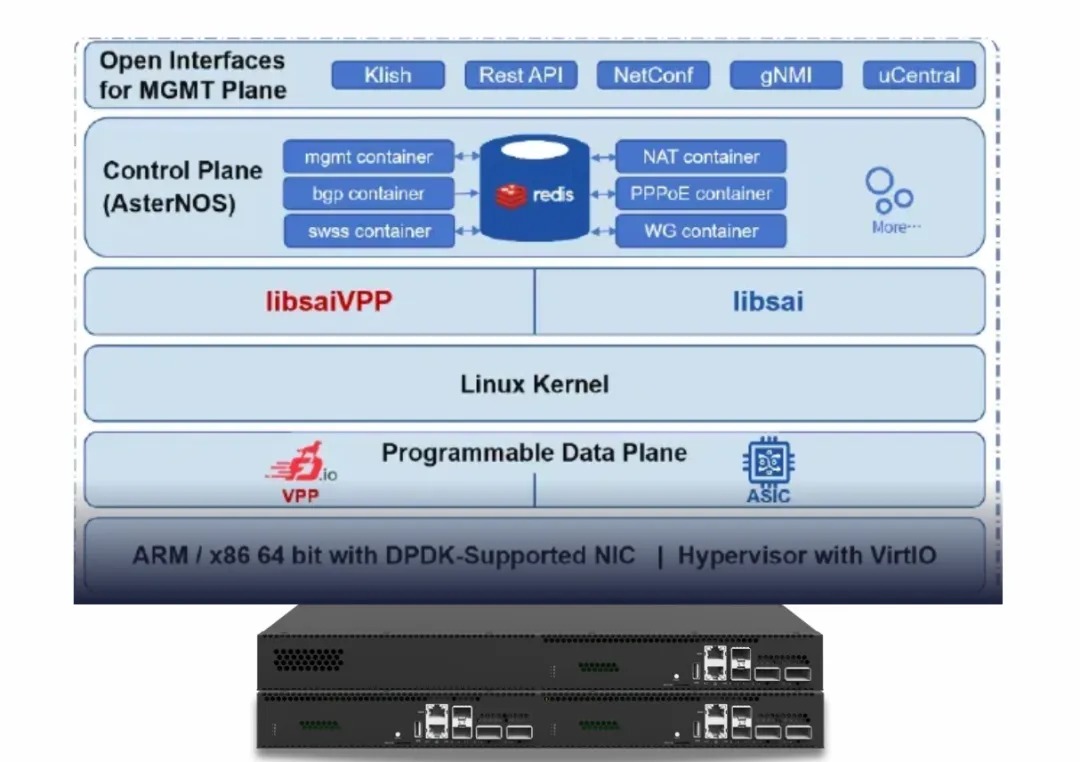
第一重进化:软件架构革新
即便没有专用硬件加速卡,AsterNOS 的运行速度也优于传统路由 。
传统的 Linux IPsec 处理采用“逐包中断”模式,效率极低 。相比之下,AsterNOS 基于 VPP(矢量报文处理)架构,采用“批处理”模式处理报文 。
这类似于公交车(一次运输数十人)与出租车(一次仅运输一人)之间的效率差异 。这使得 AsterNOS 仅依靠通用 CPU 就能实现远超传统 Linux 内核的 IPsec 处理性能 。
第二重进化:释放硬件潜能(硬件卸载)
当带宽需求上升到 10G/25G+ 线速时,我们引入了 IPsec 硬件卸载 ,借助专用的加密引擎(Crypto Engine),将繁重的数学运算从 CPU 中完全剥离 。CPU 仅负责“下达指令”,而硬件负责“暴力计算” 。
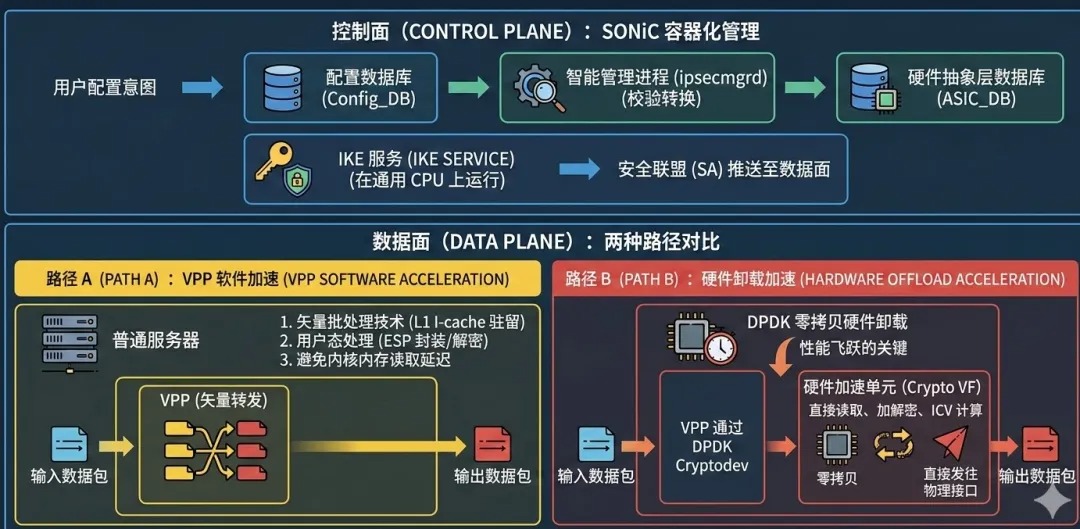
- 控制面(SONiC 容器化管理):采用数据库驱动模式 。用户配置意图先写入配置数据库(Config_DB),经由智能管理进程(ipsecmgrd)校验转换后,下发至底层的硬件抽象层数据库(ASIC_DB)
- IKE 服务:负责密钥协商的进程运行在通用 CPU 上,处理身份认证和密钥交换逻辑;协商完成后,将生成的安全联盟(SA)推送到数据面
- 数据面路径 A(VPP 软件加速):在普通服务器上,VPP 利用矢量批处理技术,确保核心处理代码始终驻留在 CPU 的 L1 指令缓存(I-cache)中 。它完全在用户态处理 ESP 封装和解密,避免了传统内核频繁读取内存带来的延迟
- 数据面路径 B(DPDK 零拷贝硬件卸载):这是性能飞跃的关键 。VPP 通过 DPDK Cryptodev 接口直接与底层硬件加速单元(Crypto VF)通信 。数据包在硬件引擎中直接完成读取、加解密及 ICV 计算,无需在内存中反复拷贝,随后直接发往物理接口
同时,AsterNOS 采用了符合云原生网络理念的虚拟隧道接口(VTI)架构 ,IPsec 隧道被视为标准的逻辑 3 层接口 ,流量进入隧道的逻辑由路由表控制,简化了复杂的策略配置。
带来的收益
实验室测试数据表明,该架构具有显著优势:
- 软件定义的灵活性:即便在无硬件加速卡的设备上,AsterNOS 也能凭借 VPP 架构提供优秀的性能基线,满足多数中小企业的 VPN 需求
- 接近线速的吞吐量:在 4x10GE 的物理网络环境下,AsterNOS 在 512 字节包长下轻松实现了 35.2 Gbps 的聚合加密吞吐量 ,该数值已达到物理接口的带宽极限(而非加密引擎的极限)
- 极低的 CPU 占用率:由于繁重的计算已卸载到专用引擎之上,CPU 可专注于业务逻辑和策略控制,不再成为瓶颈
- 广泛的算法兼容性:全面支持高效的 AES-GCM (128/192/256) 算法,并兼容 AES-CBC/CTR 。支持高达 MODP-8192 和 ECP-521 的 DH 组,满足金融级安全合规要求



