更多相关内容
AIGC承载网优化设计方案(下)
AIGC承载网优化设计思路
网络性能瓶颈问题
通信时长的考虑
带宽:与单机不同,多机之间的网络带宽是比单机内部的带宽要低很多的,
多机之间的网络通信往往会受到网络拓扑、物理连接和网络设备等因素的限制,导致实际的带宽较单机内部的带宽低很多。如单机内部NVLink3.0带宽高达600GB/s;而多机之间的网络一般是400Gb/s或200Gb/s(且是Gb/s)
在AIGC承载网络中,多机之间的通信是必要的,尤其是在分布式计算环境下,不同计算节点之间需要进行数据传输、模型同步和参数更新等操作。这些通信过程可能影响到整体的网络性能和计算效率。
设备转发时延:IB交换机或低时延交换机
-图02.png)
性能提升
(1)提升单机网络宽带
提升单机网卡带宽,同时需要匹配主机PCIe带宽和网络交换机的带宽
| 网卡速率 | 40G | 100G | 200G | 400G |
| PCIe | 3.0*8 | 3.0*16 | 4.0*16 | 4.0或5.0*16 |
| 交换机Serdes | 4*10G | 4*25G | 4*50G | 8*50G |
增加网卡的数量,初期业务量少,可以考虑CPU和GPU共用,后期给CPU准备单独的1到2张网卡,给GPU准备4或8张网卡。
-图03.png)
(2)应用RDMA网络(IB或RoCE)
借助RDMA技术,减少了GPU通信过程中的数据复制次数,优化通信路径,降低通信时延。
-图04.png)
-图05.png)
(3)减少网络拥塞
胖树结构:通过多路径的布线和聚合链路的利用,可以提供高带宽、低延迟和高可靠性的通信。
1:1收敛比
-图06.png)
双网分流:通过同时连接到两个不同的网络,将流量分流到两个路径上,从而减轻单一网络的负载和拥塞情况。这里, CPU的流量与GPU流量彻底分离开。
-图07.png)
(4)通信算法优化
单机优化
-图08.png)
多级优化
-图09-1024x335.png)
- 利用NVLink高带宽优势在单机内部的GPU之间完成数据同步
- 多机之间的GPU利用多网卡建立多个环,对不同分段数据进行同步
- 最后单机内部的GPU再同步一次,最终完成全部GPU的数据同步
大规模网络扩展问题
算力昂贵是大家普遍的共识,由于GPU资源本身稀缺的特性,尽可能多的把GPU资源集中在一个统一的资源池里面,将有利于任务的灵活调度,减少AI任务的排队、减少资源碎片的产生、提升GPU的利用率。
要组成大规模GPU集群,网络的组网方式需要进行优化。
(1)网络架构横向扩展
ToR交换机用于和GPU Server直接连接,构成一个Block。
ToR交换机向上一层是Leaf交换机,一组ToR交换机和一组Leaf交换机之间实现无阻塞全连接架构,构成一个Pod
不同Pod之间使用Spine交换机连接。
-图10-1024x496.png)
接入能力分析
-图11.png)
- Block是最小单元,包括256个GPU
- Pod是典型集群规模,包括8个Block,2048个GPU
- 超过2048个GPU,通过Fabric-Pod模式进行扩展
GPU网卡的连接建议
-图12.png)
-图13.png)
以某厂家的技术实现为例:基于异构网络自适应通信技术,不同服务器上相同位置的GPU,在同一轨道平面,仍然走机间网络通信。
要去往不同位置的GPU(比如host1上的GPU1,需要向其它host上的GPU8 送数据),则先通过机内网络,转发到host1上的GPU8上,然后通过机间网络,来完成通信。机间网络的流量,大部分都聚合在轨道内传输(只经过一级ToR)。机间网络的流量大幅减少,冲击概率也明显下降,从而提供了整网性能。根据实测,异构网络通信在大规模All-to-All场景下,对中小数据包的传输性能提升在30%左右。
(2) 计算与存储网络分离
网络可用性问题
可用性问题在GPU集群中要求不高
因为大规模分布式的AI任务基本都是离线的训练任务,网络中断不会对主业务造成直接影响。
但是也需要关注,因为一个AI训练持续的时间可能会很长,如果没有中间状态保存的话,网络中断就意味着前面花费时间训练出来的成果全部失效,所使用的GPU资源也全部被浪费掉。
AI训练任务对网络拓扑的高度敏感性
某一处网络的中断,会导致其他节点网络的非对称,无限增加上层处理的复杂度,因此,在设计集群的时候需要考虑中断容忍的网络架构。
(1)存储双上联
由于网络中断,导致一个存储节点下线,可能会在网络内触发大量数据恢复流量,增加网络负载,因此,建议采用双上联设计,确保某个交换机或上联链路中断不会影响存储节点的可用性。
(2) 计算网单上行
由于AI训练的特殊性,综合性能与成本考虑,暂不考虑双上联设计。
(3)采用GPU网卡连接方式
同一个GPU Server上的8块卡连接到8个ToR,可以节省机间网络的流量,大部分都聚合在轨道内传输(只经过一级ToR),机间网络的流量大幅减少,冲击概率也明显下降,从而提供了整网性能
但是,上面的方案,GPU Server上任何一个网卡或链接中断都会导致网络的非对称,整个GPU Server都会受到影响。所以,干脆让所有网卡共享同一个交换机,好处是,如果ToR交换机故障,影响到的GPU Server会尽可能少,从整个系统的角度出发,可用性反而提高了
-图15.png)
AIGC承载网设计实践
需求汇总(以某客户项目模型为例)
| RoCE的计算网络 | RoCE存储网络 |
|---|---|
| 1.不少于600端口200G以太网接入端口,未来可扩容至至少1280端口 | 1.不少于100端口200G以太网接入端口,未来可扩容至至少240端口 |
| 2. 全网无收敛(1:1收敛比),全线速交换 | 2. 带宽收敛比不大于3:1 |
| 3. 支持RoCE实现无损以太网 | 3. 支持 RoCE 实现无损以太网 |
整网的方案设计
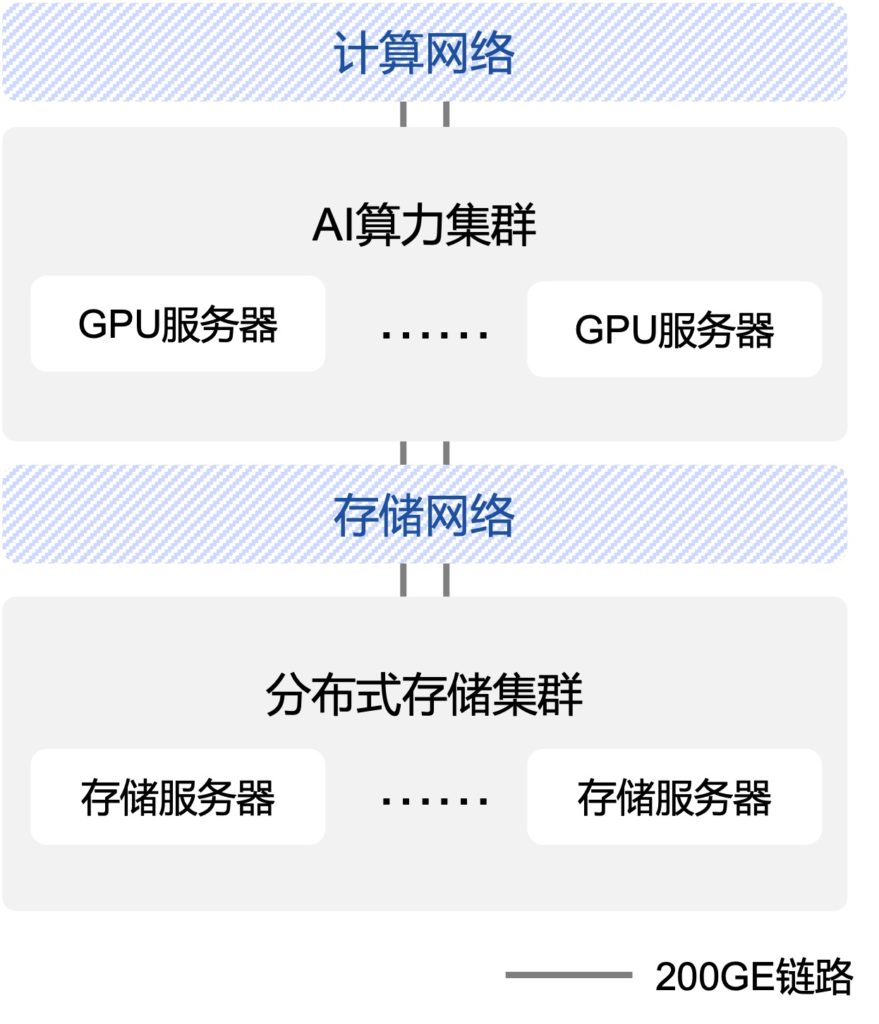

计算网络设计—-方案1(整网1:1无收敛)
不考虑GPU的8个接口的接入方式,8个接口接入1台或多台ToR
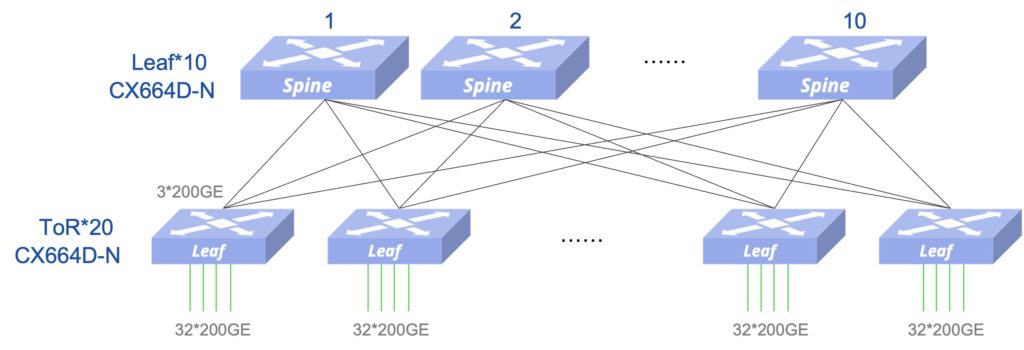
- 交换机 10 Leaf + 20 ToR= 30 台,提供640个接入端口(20*32=640),每台GPU服务器8端口,可以最大可接入GPU服务器 80台
- 接入侧和Fabric内部互联均可以使用200G的AOC(含两端的200G光模块),其中接入侧600条,Fabric侧600条,合计1200条
方案1扩展性
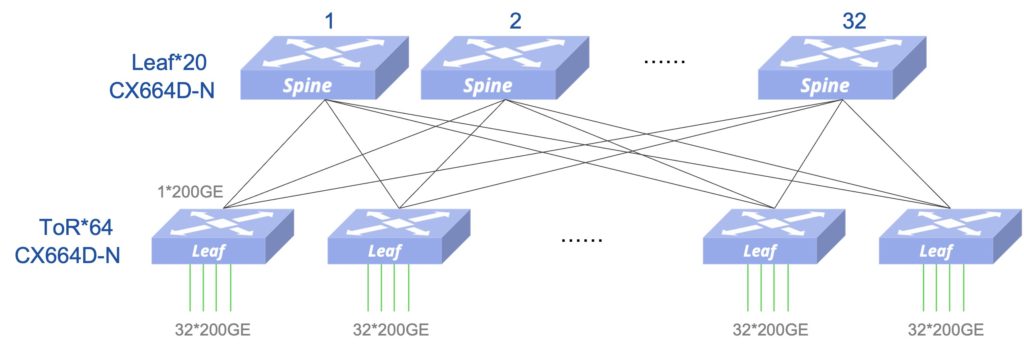
基于该架构,最多可以接入64台ToR,最大可以扩展到2048个200G接口接入,满足1280接口接入的扩展性要求
计算网络设计—-方案2(整网1:1无收敛)
考虑GPU的8个接口的接入方式,8个接口接入到8台Leaf,每8台Leaf作为一个分组
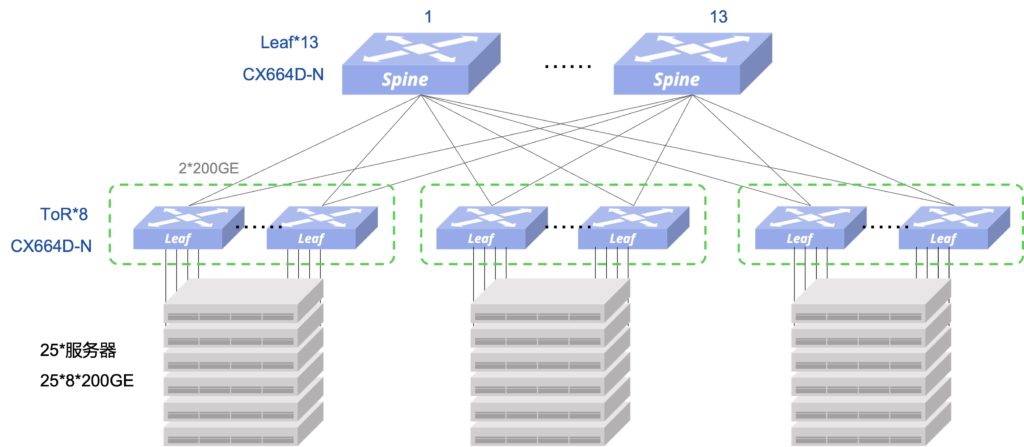
- 交换机 13 Leaf + 24 ToR = 37 台,按600个接入端口(75台GPU服务器),每组8个ToR接入25台GPU服务器,3组ToR接入75台
- 每组ToR接入25台GPU服务器,下行接入带宽为200*200GE,因此,上行也需要至少是200*200GE带宽,每台ToR到每台Leaf为2条200G,总上行带宽为2*13*8*200GE,满足1:1收敛要求
- 接入侧和Fabric内部互联均可以使用200G的AOC(含两端的200G光模块),其中接入侧600条,Fabric侧624条,合计1224条
方案2扩展性
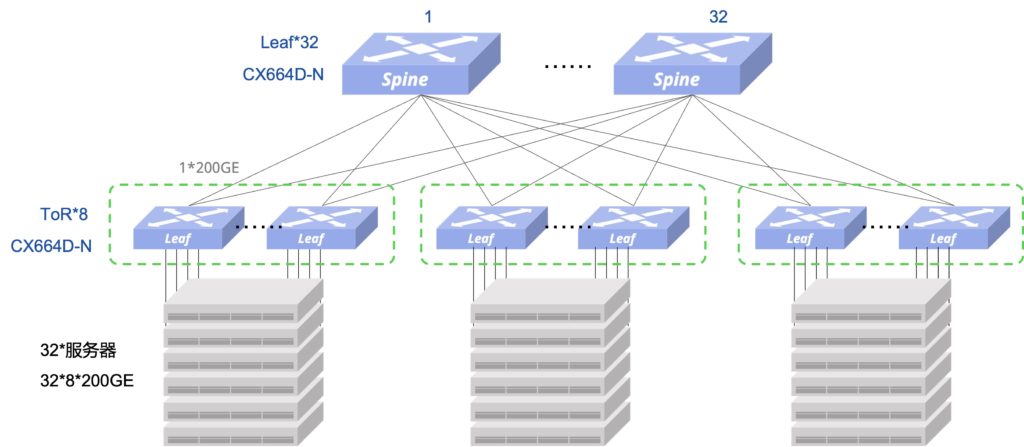
- 基于该架构,最多可以接入8组ToR ,每组8个ToR接入32台GPU服务器,8组ToR接入256台
- 最大可以扩展到2048个200G接口接入,满足1280接口接入的扩展性要求
存储网络设计(整网3:1收敛)
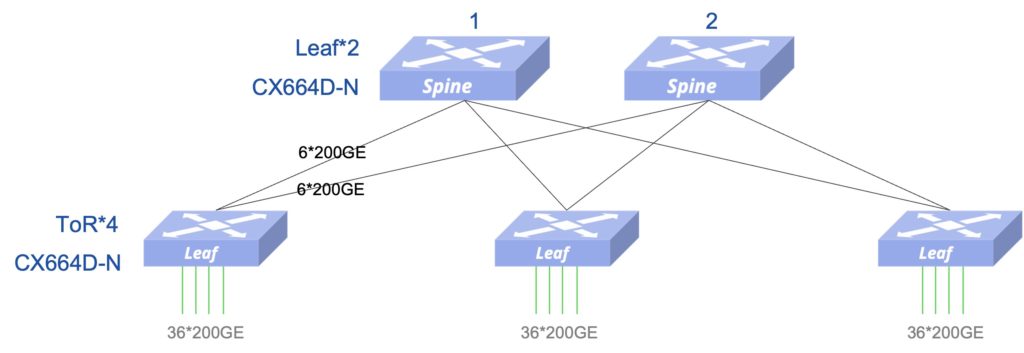
- 交换机 2 Leaf + 3 ToR = 5 台,提供最大144个接入端口(满足100个接入需求)
- 如果不考虑Leaf高可靠部署,也可以单Leaf接入
- 接入侧和Fabric内部互联均可以使用200G的AOC(含两端的200G光模块),其中接入侧100条,Fabric侧36条,合计136条
存储网络设计的扩展性
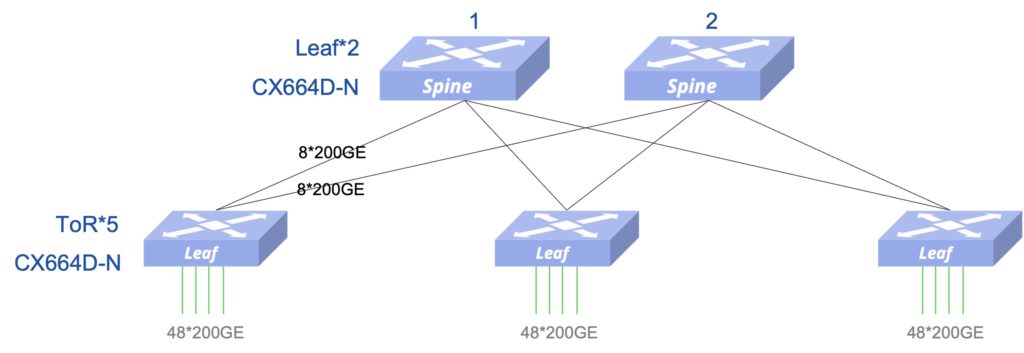
- 交换机 2 Leaf + 5 ToR = 7 台,提供最大240个接入端口(满足240个接入的扩展需求)
设备配置汇总
| 网络类型 | 设备类型 | 设备型号 | 台数 | 合计 |
|---|---|---|---|---|
| 方案1 | ||||
| 计算网络(600*200GE端口) | Spine | CX664D-N | 10 | 35 |
| Leaf | CX664D-N | 20 | ||
| 存储网络(100*200GE端口) | Spine | CX664D-N | 2 | |
| Leaf | CX664D-N | 3 | ||
| AOC线缆(含模块) | AOC | 1336条 | ||
| 方案2 | ||||
| 计算网络(600*200GE端口) | Spine | CX664D-N | 13 | 42 |
| Leaf | CX664D-N | 24 | ||
| 存储网络(100*200GE端口) | Spine | CX664D-N | 2 | |
| Leaf | CX664D-N | 3 | ||
| AOC线缆(含模块) | AOC | 1360条 | ||
