更多相关内容
简述AI网络
人工智能(AI)是一项革命性技术,正在改变许多行业和领域。
技术正在从医学到金融服务和娱乐,它正在改变我们日常生活的许多行业和方面。
娱乐,实时游戏、虚拟现实、生成式人工智能和元宇宙应用的快速发展,正在改变我们的日常生活、 虚拟现实、生成式人工智能和元宇宙应用的快速发展正在改变网络、计算、内存、存储和互连 I/O 的交互方式、 存储和互连 I/O 的交互方式。随着人工智能以前所未有的速度 以前所未有的速度发展,网络需要适应 流量的巨大增长。
随着人工智能以前所未有的速度不断发展,网络需要适应数以百计和数以千计的处理器通过数万亿次交易和千兆位 吞吐量。随着人工智能迅速从实验室和研究项目向主流应用迈进的同时,也要求增加网络和计算资源。
最近的发展 ,只是未来十年发展的基石。
我们认为,人工智能集群在未来几年将大幅增长。
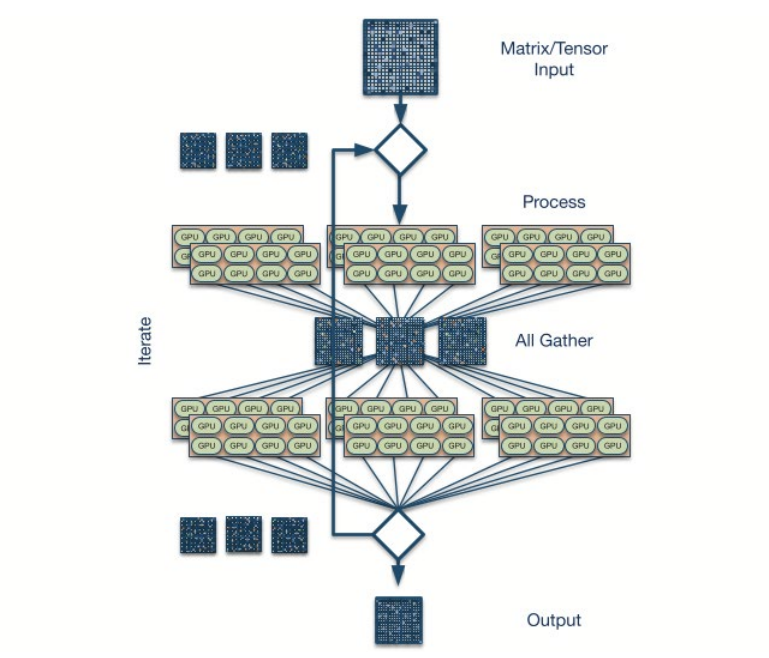
这些人工智能工作负载的一个共同特点是,它们都是数据和计算密集型的。典型的人工智能训练工作负载 涉及数十亿个参数和分布在数百或数千个处理器(CPU、GPU 或 TPU)上的大型稀疏矩阵计算。CPU、GPU 或 TPU。这些处理器进行密集计算,然后与同级处理器交换数据。来自对等处理器的数据 或与本地数据合并,然后开始新一轮的处理。在这个计算-交换-还原的循环中,大约有 20-50% 的作业时间用于跨网络通信,因此瓶颈对作业完成时间有很大影响。
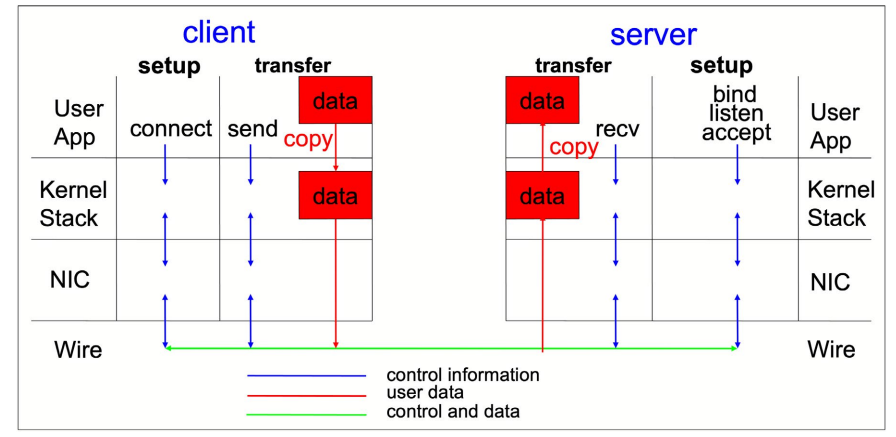
TCP/IP 和 RDMA
RDMA 是一种关键的卸载技术,可实现现代人工智能应用所需的可扩展并行处理。在 TCP/IP 套接字中、数据必须先从用户空间复制到内核空间,然后才能到达网络驱动程序和网络。当处理与人工智能应用相关的大量数据时,CPU 可能会成为瓶颈。
这就是远程直接内存访问(RDMA)的用武之地。在高性能计算系统中,RDMA 无处不在,因为它无需依赖内核即可在主内存中交换数据。RDMA 有助于提高吞吐量和性能,从而提高数据传输速率,降低启用 RDMA 的系统之间的延迟,因为它减少了CPU 周期。
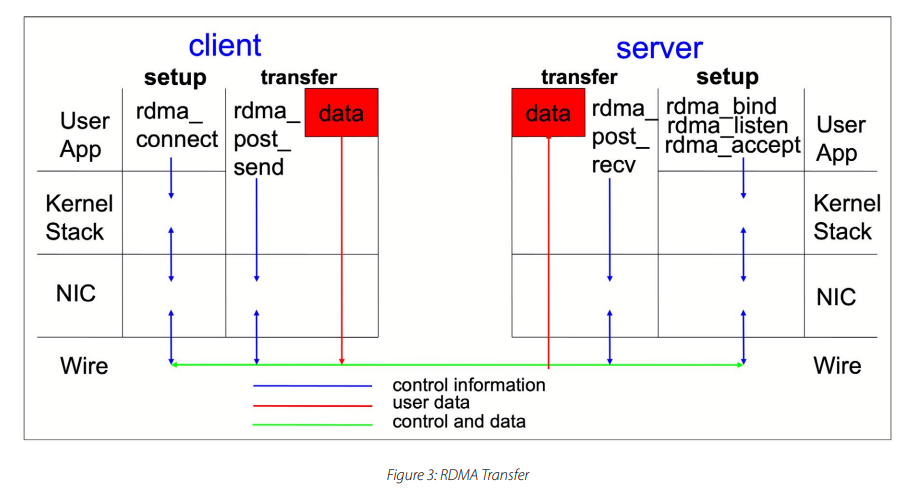
RDMA 传输的语义由 InfiniBand Verbs 软件接口定义。这包括内存块的注册、描述符的交换以及 RDMA 读写操作的发布、描述符的交换以及 RDMA 读写操作的发布。该接口独立于作为物理传输层的 Infiniband物理传输层。
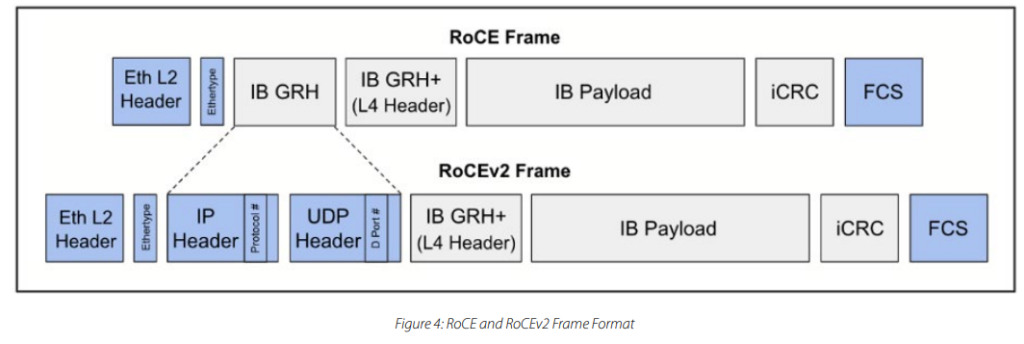
RoCE 定义了如何通过以太网传输 InfiniBand 有效载荷。RoCEv2 通过允许流量路由,进一步扩展了这种可扩展性和功能,允许对流量进行路由,并支持在以太网上扩展 RDMA。
集体交流
现代大型语言模型以数十亿或数万亿个参数为基础,并使用大量数据集进行训练,这些数据集无法在任何单个主机 GPU 中运行。任何单个主机 GPU 都无法容纳。这些数据集和模型被分割到多个 GPU 中并行训练,得出的 梯度和权重,然后通过集体通信在各成员 GPU 之间聚合和同步。
集体通信允许在通信器的所有进程之间交换信息。常用的集体通信原语包括广播、聚集、分散、全对全、全局还原(或全还原)和全聚集。最终目标 是确保所有进程在每一步都能同步。在所有参数同步之前,通信器中的任何进程都不能继续运行。
程序员可以利用流行的集体通信库(如 NCCL、oneCCL、RCCL、MSCCL 等),将高效、久经考验的通信算法集成到其应用程序中。应用中集成高效、久经考验的通信算法。
环形算法和二叉树算法通常用于像 allreduce 这样需要在所有 GPU 之间交换信息的集体程序。所有 GPU 之间交换信息。下图显示了用于在四个进程间交换信息的环形算法。

环路具有带宽最优性,要求网络在所有终端主机之间提供线速带宽。虽然带宽效率高,但随着用于训练模型的 GPU 数量增加,延迟也会随环路线性增加。
树形算法通过对参与进程进行排序并将其拆分为不重叠的二进制树,可在保持低延迟的同时扩展 GPU。
分成不重叠的二叉树。下图显示了 16 个进程被分成两棵不重叠的二叉树。

每个进程从两个对等进程接收信息,并向两个对等进程发送信息。这种模式的延迟 不会像环模式那样线性增加,但它要求网络有效地管理流量传输,以便上游进程能以尽可能接近线速的带宽向每个接收进程发送信息。
必须为人工智能网络选择合适的互连设备,以便高效地交换信息,并让进程通过每个障碍,继续前进,进程越过每个障碍,进入下一阶段的计算。
人工智能网络互联
以太网广泛部署在数据中心、骨干网、边缘网和园区网中,其使用情况各不相同,从非常低的速度到目前的 100G、200G、400G 和 800G 高速度,以及未来的 1.6T。到目前的 100G、200G、400G、800G 等高速,路线图中将达到 1.6T。另一方面,Infiniband 是一种网络技术 而 Infiniband 则是 HPC 集群中常用的一种网络技术。如前所述,AI/ML 工作负载是网络密集型的,不同于传统的 HPC 工作负载。
此外,随着大型语言模型(LLM)的激增 此外,随着大型语言模型(LLM)的激增,对 GPU 和存储容量的需求也在不断增加。容量。现代人工智能应用需要拥有数千个 GPU 和存储设备的大型集群。
现代人工智能应用需要配备数千个 GPU 和存储设备的大型集群,而这些集群 随着需求的增长,这些集群必须扩展到数以万计的设备。增长。随着 GPU 速度每隔一年翻一番,避免计算和网络瓶颈至关重要。通过可扩展的网络设计来避免计算和网络瓶颈。可扩展的网络设计。
当应用团队关注计算能力时 网络团队则必须根据以下几个因素对互连进行仔细评估互连:
绩效
衡量人工智能集群性能的关键指标之一是作业完成时间。工作完成时间。要达到理想的 性能,网络必须是无损的、无阻塞的,并且 提供合理的链路利用率。正如后面所讨论的,有了适当的 拥塞控制机制和高效负载平衡技术 技术,RoCEv2 可提供人工智能工作负载所需的最佳性能。
带宽和速度
随着培训工作的规模越来越大,提供更快的网络非常重要。使用端口速度更快的高密度 更快的端口速度。使用商用硅以太网解决方案,网络带宽可以每两年翻一番。同时降低每比特成本和每比特功耗。
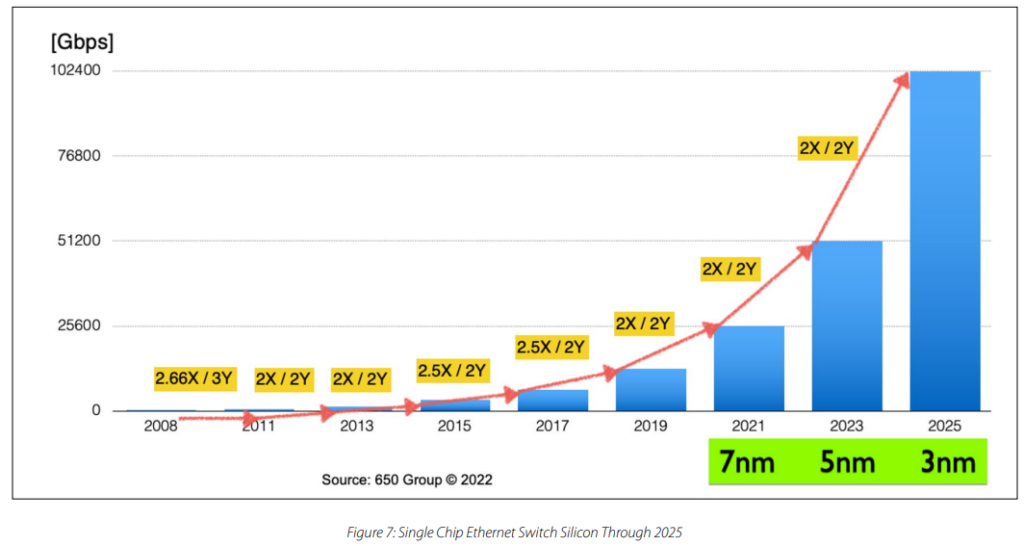
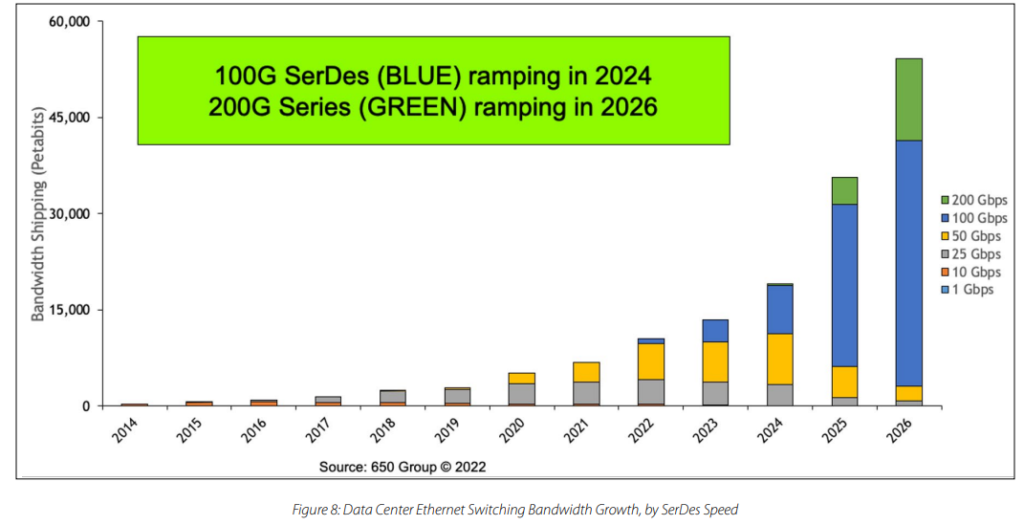
无损网络
虽然更快的速度很有用,但无损网络对作业完成时间至关重要。Infiniband 采用基于信用的流量 流量控制,以避免数据包丢失。发送方在收到目标主机发送的表示有可用缓冲区的数据包之前,等待发送数据包。缓冲区。通过使用显式拥塞通知(ECN)和优先级流量控制(PFC),以太网也可作为无损信道运行。无损信道。这些机制对发送方施加反向压力,以避免主机或交换机缓冲区超限。可靠的传输 通过 IB 流量控制或带有 ECN/PFC 的以太网进行可靠传输,对于最大限度地提高 RDMA 性能至关重要
可扩展性
随着 LLM 模型规模的不断扩大,其能力也得到了可靠且可预测的提升。这反过来又推动了更大 这反过来又推动了更大的 LLM,进而推动了更大的人工智能集群互连。简而言之,网络的可扩展性是一个非常重要的考虑因素。
以太网已经证明了其在全球最大云网络中的扩展能力。网络团队能够采用云 设计,并利用运行边界网关协议(BGP)的 CLOS 架构构建分布式网络。
另一方面,Infiniband 的控制平面通过单个子网管理器集中管理,该子网管理器可发现物理拓扑,并在每个节点上设置转发表和 QoS 策略。它定期扫描网络,并根据拓扑变化重新配置设备。这在小型集群中效果良好,但在大规模集群中可能会成为瓶颈。有一些经过深思熟虑的复杂解决方案可以起到修补作用。不过,以太网中的分布式控制平面的规模超过了 Infiniband 48000 的最大子网规模,并提供了更高的弹性。
恢复能力
当 Infiniband 的子网管理器发生故障时,整个子网都可能瘫痪。Infiniband 确实有一些技术可以在某些情况下实现连续转发。在某些情况下可以连续转发,但最终控制平面仍然是集中式的,而且很脆弱。完全故障切换到 而子网越大,停机时间就越长(需要传输的状态越多、 跨节点的扫描范围越大)。根据与客户的交谈,停机时间可能是 30 秒到几分钟不等。在某些用例中,客户 但对于大型人工智能/ML 工作负载来说,这种故障会严重影响作业完成时间和整体性能。性能。使用以太网和 Arista SSU 等功能的分布式可扩展架构,链路和节点故障对整体性能的影响极小甚至没有影响。对大型人工智能网络的整体性能影响极小甚至没有影响。
可见性
遥测和可视性对于实现网络自动化和无缝操作极为重要。网络团队希望将目前用于数据中心通用计算和存储的工具、流程和解决方案扩展到人工智能集群中。
互操作性
OAI 网络通常与各种存储和通用计算基础设施相连接。基于以太网的人工智能网络实现了高效、灵活的网络设计,避免了通过这些不同系统的管道瓶颈。虽然 IP 流量可以通过物理 Infiniband 网络传输,但所有服务器都必须配备 Infiniband HCA 或通过 Infiniband 至以太网网关,这极大地限制了进出 IB 网络的吞吐量。
开放
以太网拥有一个非常强大的生态系统,包括多个芯片供应商、系统供应商和光学供应商,并推动基于开放和标准的解决方案在各供应商之间实现互操作。InfiniBand 则由于选择有限和锁定解决方案而明显落后。
 总之,以太网因其可扩展性、互操作性、可靠性、成本效益、灵活性和熟悉度而被认为是人工智能网络的最佳解决方案。以太网的良好记录、广泛采用和对高速网络的支持,使其成为希望建立高效、可扩展的网络基础设施以支持其人工智能工作负载的企业的不二之选。
总之,以太网因其可扩展性、互操作性、可靠性、成本效益、灵活性和熟悉度而被认为是人工智能网络的最佳解决方案。以太网的良好记录、广泛采用和对高速网络的支持,使其成为希望建立高效、可扩展的网络基础设施以支持其人工智能工作负载的企业的不二之选。
让我们来看看使用以太网的人工智能工作负载的关键要求。网络需要支持 RoCEv2 的无损传输、优先处理控制流量的服务质量 (QoS)、可调整的缓冲分配、有效的负载平衡和实时监控。
