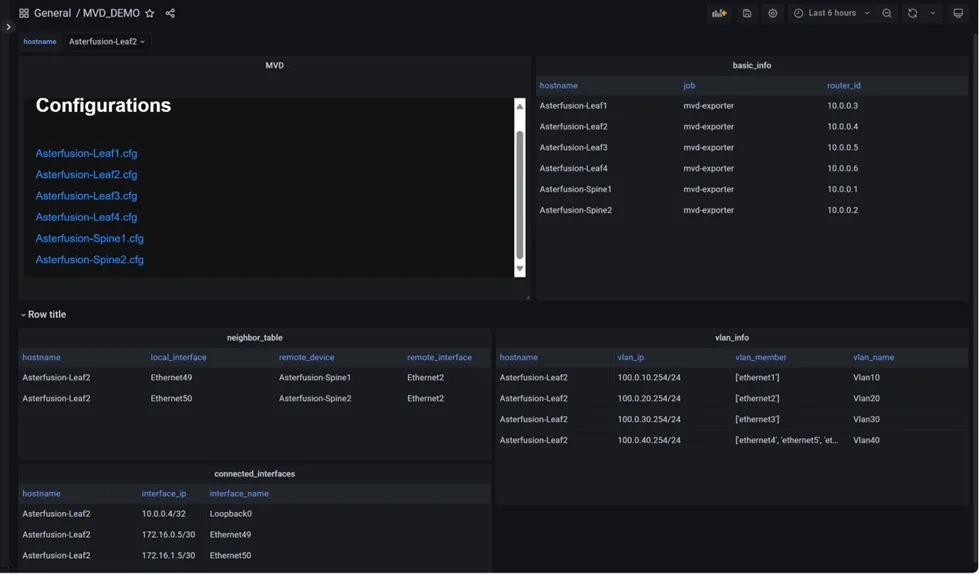
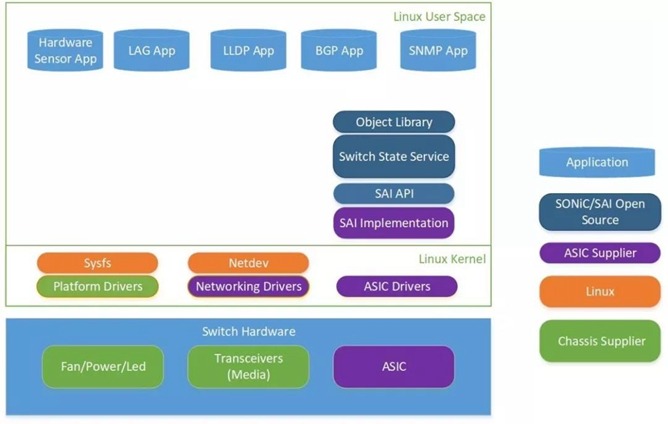
协同防御:利用DCQCN和PFC构建无拥塞、零丢包的数据中心网络
近期文章
DCQCN ( Data Center Quantized Congestion Notification),数据中心量化拥塞通知。它是一种专门为数据中心网络设计的端到端拥塞控制协议。其核心目的是在使用RDMA(RoCEv2) 的网络中,高效地管理网络拥塞,从而保证高吞吐、低延迟和零丢包(或极低丢包)。
简单来说,DCQCN就是RDMA在以太网(RoCE)环境中的“交通警察”,它确保高速数据流不会造成网络堵塞。
本文参阅文献:Congestion Control for Large-Scale RDMA Deployments.pdf
在现代RDMA数据中心网络中,PFC和DCQCN必须同时部署。PFC为RDMA提供了一个安全的、无损的链路层保障,而DCQCN则在更上层智能地管理流量,防止PFC的负面效应出现并优化全局网络效率。它们一快一慢,一局部一全局,共同构成了RoCE网络的拥塞管理基石。
DCQCN的运行条件
DCQCN依赖于PFC(Priority-based Flow Control) 来构建无损链路层,防止因为缓冲区过载导致的丢包。首先,在交换机端口上为承载RoCEv2流量的优先级(例如Priority 3)启用PFC。必须为每个端口预留足够的“空中”缓存(t_flight),以容纳在PFC PAUSE消息生效过程中,对端可能继续发送的数据包。(此值通常与端口速率和链路延迟有关)
数据中心交换机需要支持ECN和RED功能,这是CP(交换机)算法运行的基础。(大多数现代数据中心交换机都支持此功能。)
终端主机必须使用支持RoCEv2和DCQCN的智能网卡(如NVIDIA ConnectX系列),并安装相应的驱动程序和管理工具(如dcbtool)。
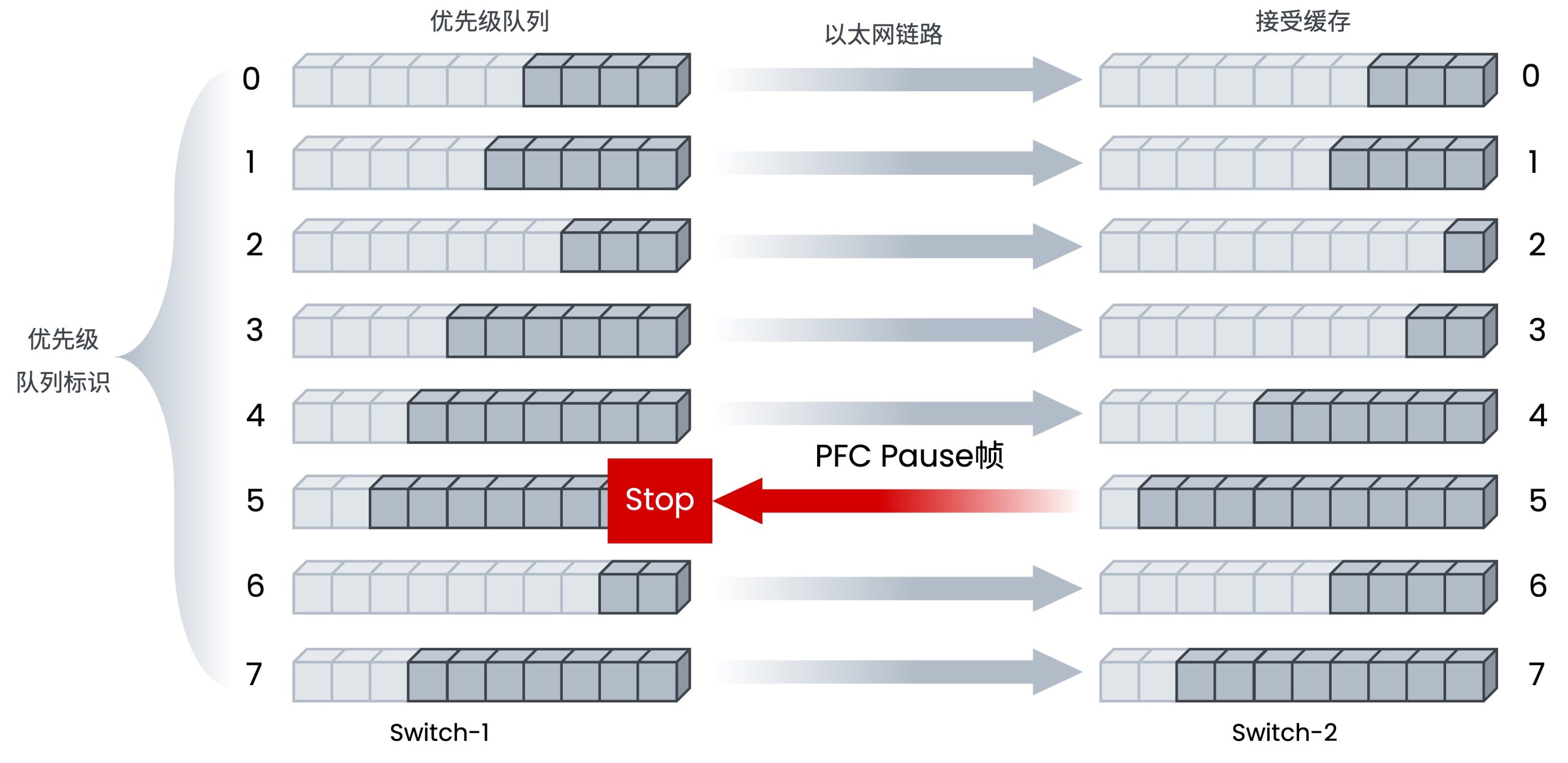
PFC – 优先级流量控制
工作机制:接收端交换机端口上的某个优先级队列(如RoCE流量队列)的缓冲区即将被填满。接收端会向发送端发送一个 Pause Frame,告诉它“暂停发送”这个特定优先级的流量。发送端收到后,立即停止发送该优先级的流量,直到接收端发送“解除暂停”的信号或等待一段时间后超时恢复。PFC可以实现无损网络,确保在拥塞时也不会丢包。这对于RDMA的可靠性和性能至关重要。
DCQCN – 数据中心量化拥塞通知
工作机制:交换机检测到拥塞,给数据包打上标记。接收端收到标记包后,向发送端发送拥塞通知包。发送端收到通知后,主动降低自己的发送速率,从源头上减少注入网络的数据量。DCQCN主动管理拥塞,通过降低发送速率来缓解网络中的拥塞点,同时保证不同数据流之间的公平性。
DCQCN与PFC的协同配置
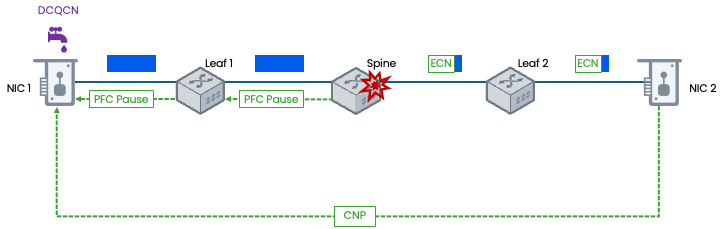
在实际的RoCE网络中,PFC和DCQCN是同时启用、协同工作的。它们的交互流程完美呈现了“治标”与“治本”的结合:
瞬时微突发: 当网络中出现短暂的流量突发时,交换机缓冲区可能瞬间被填满。此时,PFC会迅速介入,触发暂停机制,防止了丢包。这是“治标”,解决了瞬时问题。
持续拥塞: 如果拥塞是持续性的(例如多个服务器同时向一个目标发送大量数据),PFC会反复被触发。虽然它防止了丢包,但并没有解决根本问题。拥塞还在持续,缓冲区始终很高,最终导致延迟增加。
DCQCN根除拥塞: 就在PFC工作的同时,交换机也检测到了持续的拥塞(高队列深度)。它开始给数据包打ECN标记。接收端生成CNP,CNP通知发送端降低速,DCQCN机制随后被激活,交换机队列深度开始下降,拥塞根源得到缓解。随着DCQCN发挥作用,网络中的拥塞被消除,交换机缓冲区水位下降。PFC检测到队列低于阈值,便会发送“解除暂停”的信号,链路恢复正常传输。
| 特性 | PFC | DCQCN |
|---|---|---|
| 层级 | 数据链路层 | 网络层/传输层 |
| 范围 | 逐跳 | 端到端 |
| 机制 | 发送暂停帧,强制停止发送 | 发送通知,建议发送端降速 |
| 目标 | 治标:实现无损,避免丢包 | 治本:管理拥塞源,消除拥塞 |
| 比喻 | 交警在路口临时封路 | 交通中心让所有车辆慢行 |
| 协作角色 | 应急刹车,应对瞬时突发 | 巡航控制,进行长期流量调节 |
DCQCN的应用与部署
DCQCN由Mellanox(现NVIDIA的一部分)在其网卡中实现,并广泛应用于微软等大型数据中心,以支持其云存储、分布式缓存等需要高吞吐量和低延迟的服务。由于其重要性和影响力,DCQCN在2025年获得了SIGCOMM“经典之作奖”。
- AI与大模型训练:在数据并行、流水线并行和张量并行等分布式训练模式中,节点间需要频繁同步海量参数(通常达百GB级别)。DCQCN能有效减少网络拥塞,避免因PFC“刹停”或丢包导致的计算长尾延迟,保障训练任务高效运行。
- 高性能计算(HPC):用于需要极高网络带宽和极低延迟的科学计算、模拟等场景,DCQCN帮助RDMA实现接近线速的传输。
- 云存储与分布式系统:如微软的云存储服务,DCQCN保障了后端存储节点间大数据块传输的效率和稳定性,同时极大降低了CPU开销。
要想实现DCQCN,你的数据中心网络需要满足一些特定条件,并理解其三个核心组件(对应下图)的职责:
| 组件 | 角色与职责 | 硬件要求 |
|---|---|---|
| 交换机 (CP) | 监控出口队列长度,超过阈值时根据RED算法对数据包进行ECN标记。 | 支持ECN和RED功能的标准数据中心交换机。 |
| 接收端网卡 (NP) | 检测带有ECN标记的数据包,生成CNP拥塞通知包并返回给发送端。 | 支持RoCEv2的智能网卡 |
| 发送端网卡 (RP) | 根据收到的CNP包降低发送速率;在未收到CNP时逐步提升速率。 | 支持RoCEv2的智能网卡 |
智算中心的硬件核心在于为 RoCEv2提供稳定、高性能的无损网络环境。这不仅需要网卡支持,更需要交换机的深度配合。CX-N系列数据中心交换机通过其超低时延、无损网络技术、对大容量缓存的优化、高级遥测功能以及对自动化运维的支持,为DCQCN协议在AI计算、高性能计算等场景中的高效、稳定运行提供了坚实的硬件基础。
【参考文献】