HPC集群架构和通信流量特征
HPC 集群由多个联网的高速算力服务器组成,广泛使用CPU-CPU的多节点并行计算,并结合GPU、FPGA加速器的异构计算进一步提升性能。节点之间通过高速网络互联完成实时通信,并有一个集中式的管理节点来管理并行计算工作负载。HPC领域专注于解决复杂的科学问题、完成各类场景模拟等任务,与之相关的仿真和模拟技术对计算精度要求极高,通常采用双精度浮点运算(FP64)。
从方法论的角度来看,AI和HPC都是借助并行计算提高运算效率,并通过可扩展设计(Scale-up或Scale-out方向)来适应不断增加的工作负载。但对比AI集群中的大规模集合通信,HPC流量模型多为点对点的局部通信或邻居通信,传递64B-128MB的小消息,主要是对时延极其敏感——例如电磁仿真、流体动力学和汽车碰撞等计算场景高度依赖各节点间的工作协调、计算同步以及信息高速传输。
当然也有相对数据密集型的场景,如气象预报、基因测序、图形渲染和能源勘探等,计算节点在处理大量数据的同时又产生了大量中间数据,虽然也需要较高的网络吞吐量,但与AI训练不在一个量级。(🔗一文揭秘AI智算中心网络流量 – 大模型训练篇 )
下表简单总结了HPC集群与AI智算集群的的联系与区别:
HPC AI 训练 相似点 采用并行计算和可扩展的集群设计提高效率,要求大存储和大内存资源处理数据集,计算和存储节点使用高速网络(IB/RoCE)实现互联,资源分配和作业管理系统都依赖复杂的软件栈实现 算力硬件 主要是CPU、可能包括GPU或FPGA,但使用频率低于AI训练 GPU,以及专为AI优化的TPU 运算精度 FP64高精度计算 FP32、FP16,概率性的近似计算 流量模型 点对点的局部通信或邻居通信,多传递64B-16MB的小消息 大多是大规模集合通信,传递128MB以上大消息 数据管理 结构化的、模拟数据 非结构化数据 软件栈 MPI、OpenMP、科学计算数值库 TensorFlow、PyTorch 工作负载 紧密耦合的、同步的 迭代的、异步的
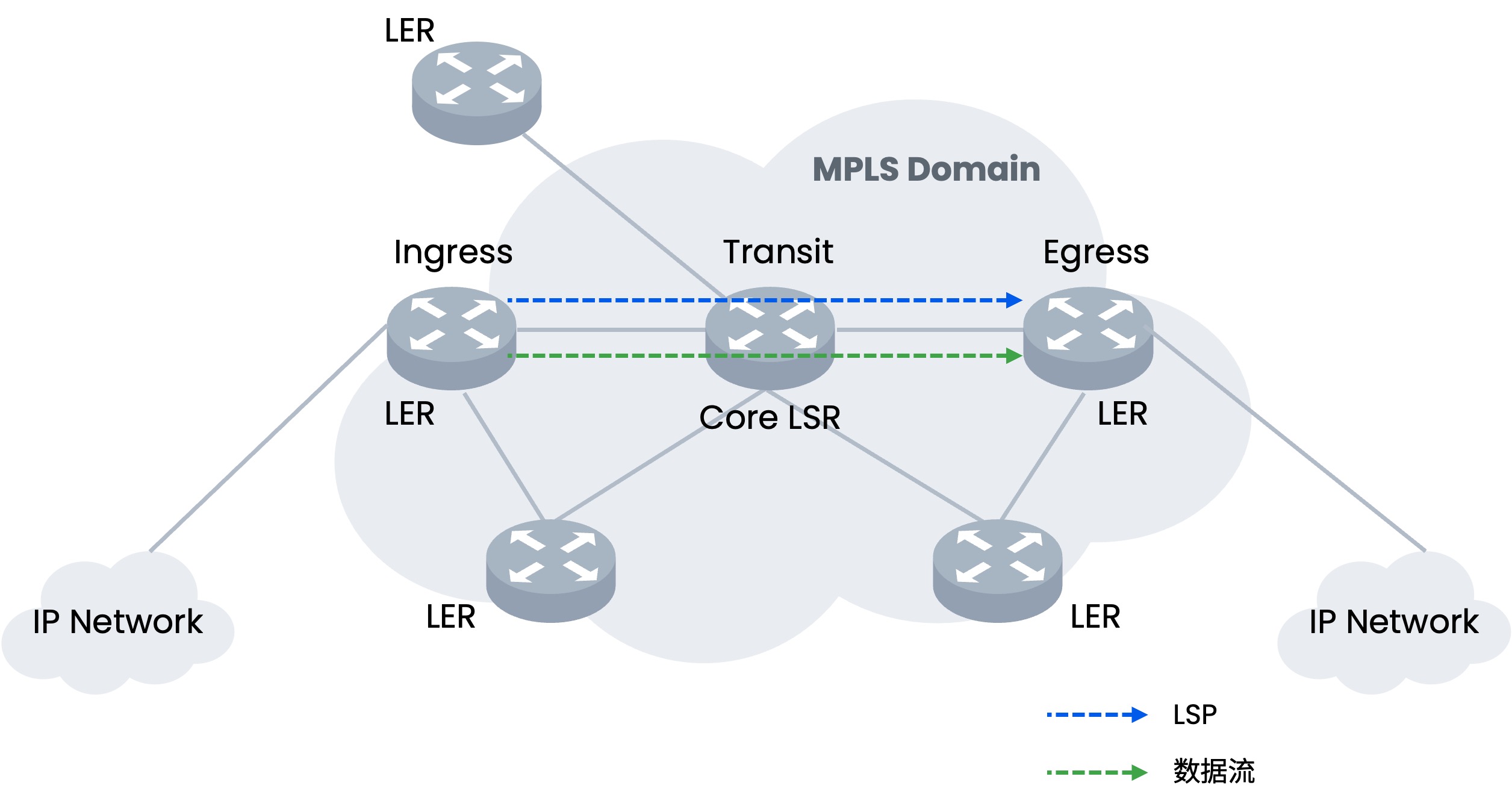
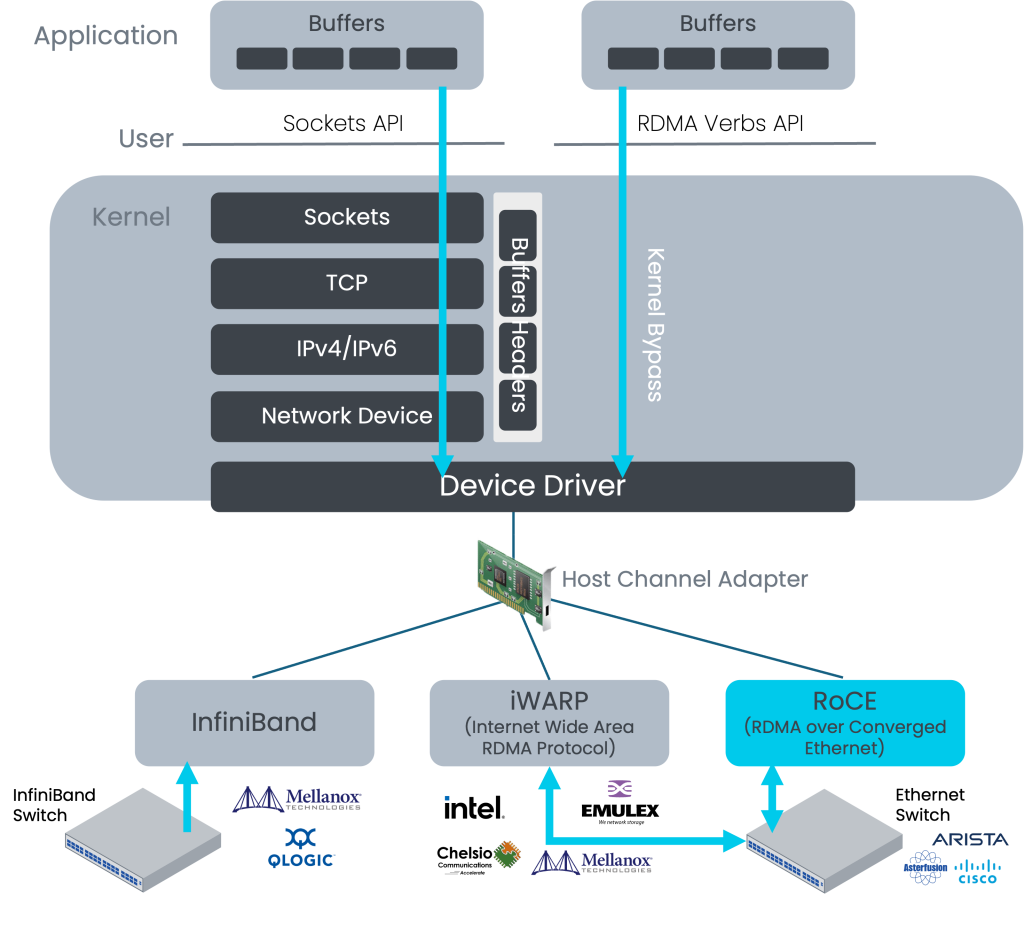
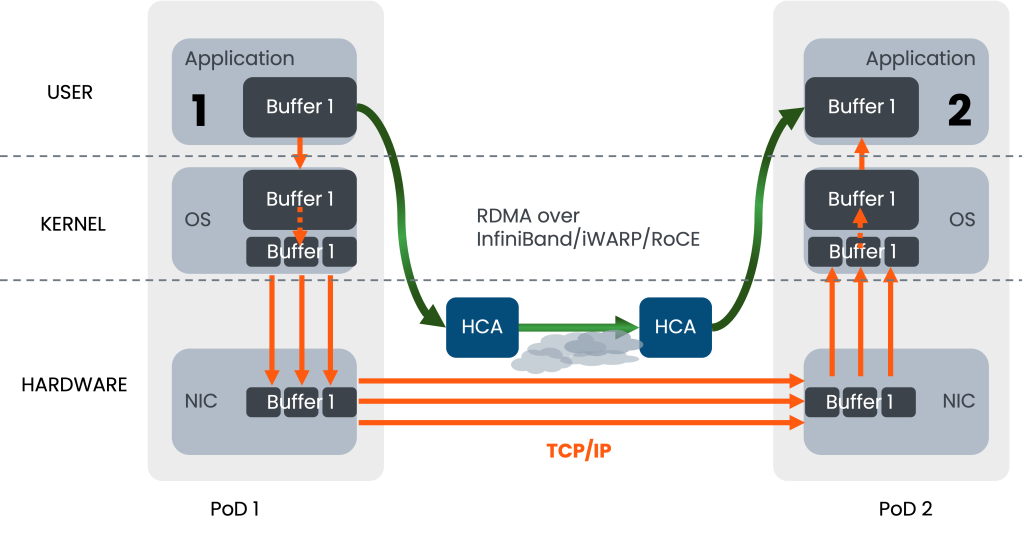
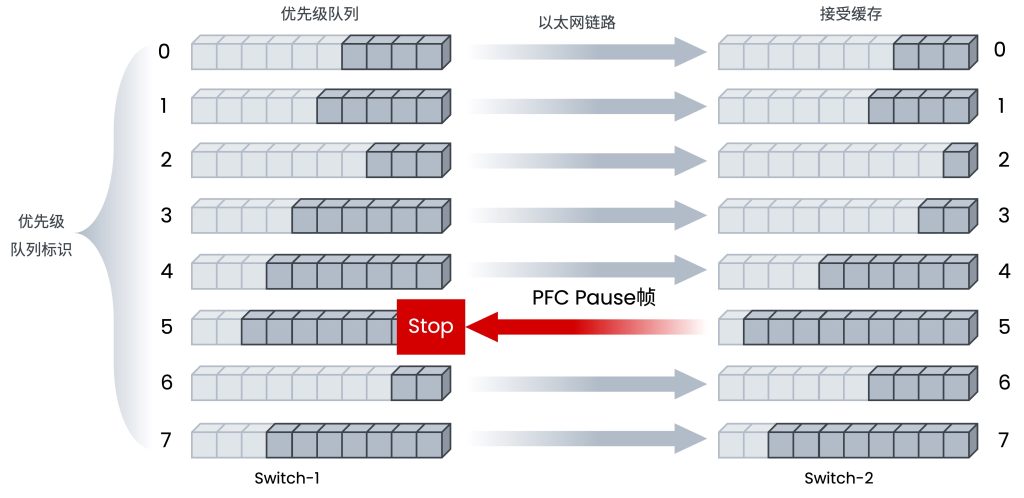
无论是在AI智算还是HPC,或是二者的融合,业界已普遍采用RDMA技术的内核旁路机制大幅降低了服务器侧的I/O时延。而为了切实提高集群生产效率,应用RDMA需同时建立端到端的超低时延无损网络,目前两大主流路线是Infiniband与RoCEv2。前者为专有协议,需要专用硬件搭建专网,后者则在IB基础上改进了报文格式,使其支持在以太网上传输,关于两种协议栈的详细对比可参考(RoCE与IB对比分析(一):协议栈层级篇 )
选择IB还是RoCEv2已是老生常谈的话题了,IB因其属于是RDMA原生的协议,由Mellanox/NVIDIA独家供应的IB交换机可提供极致性能,但RoCEv2在互操作性和带宽成本上优势明显,且随着开放网络技术的快速迭代,基于SONiC的高性能以太网交换机的端到端通信效率也可做到IB相当,甚至局部超越。
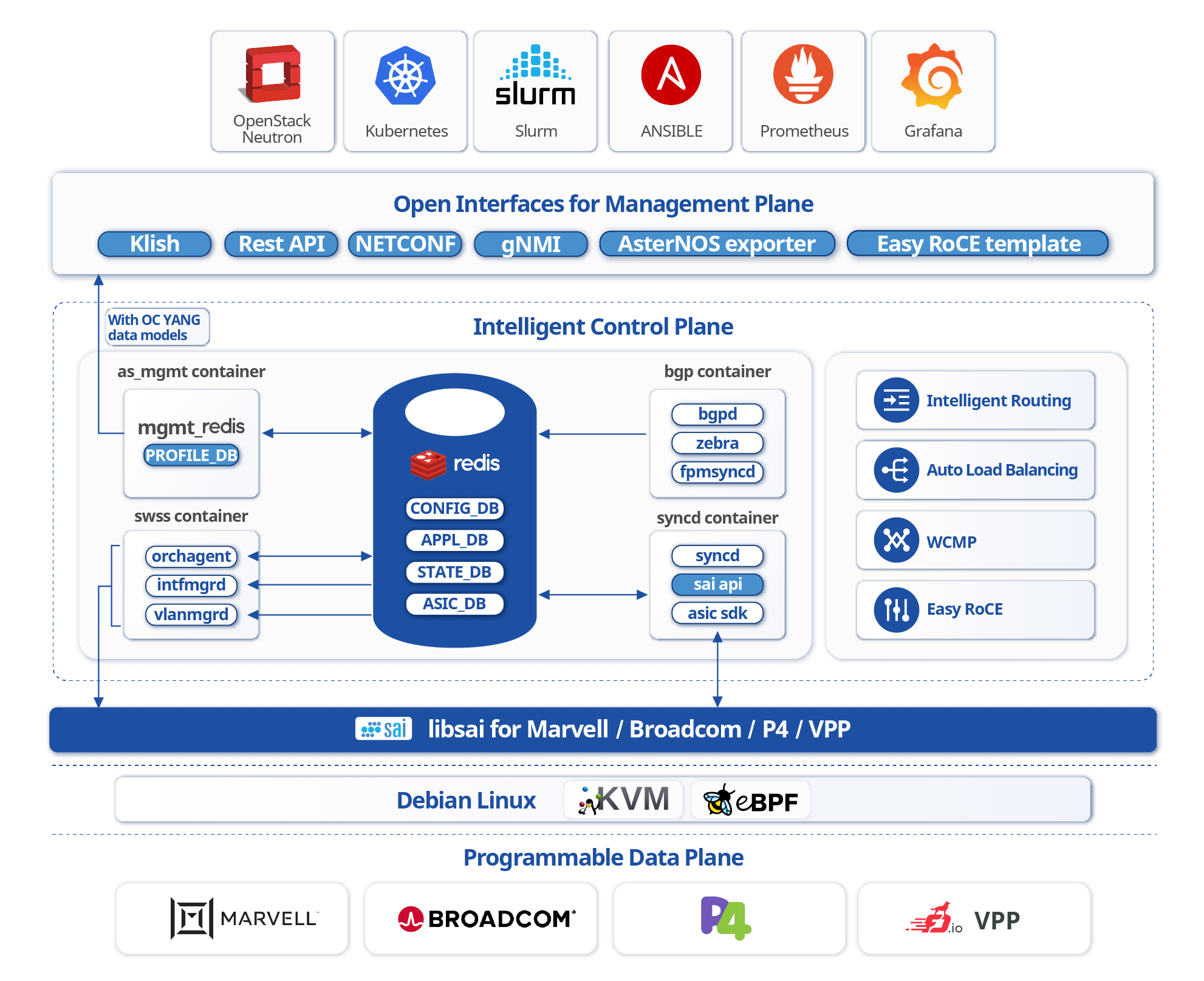
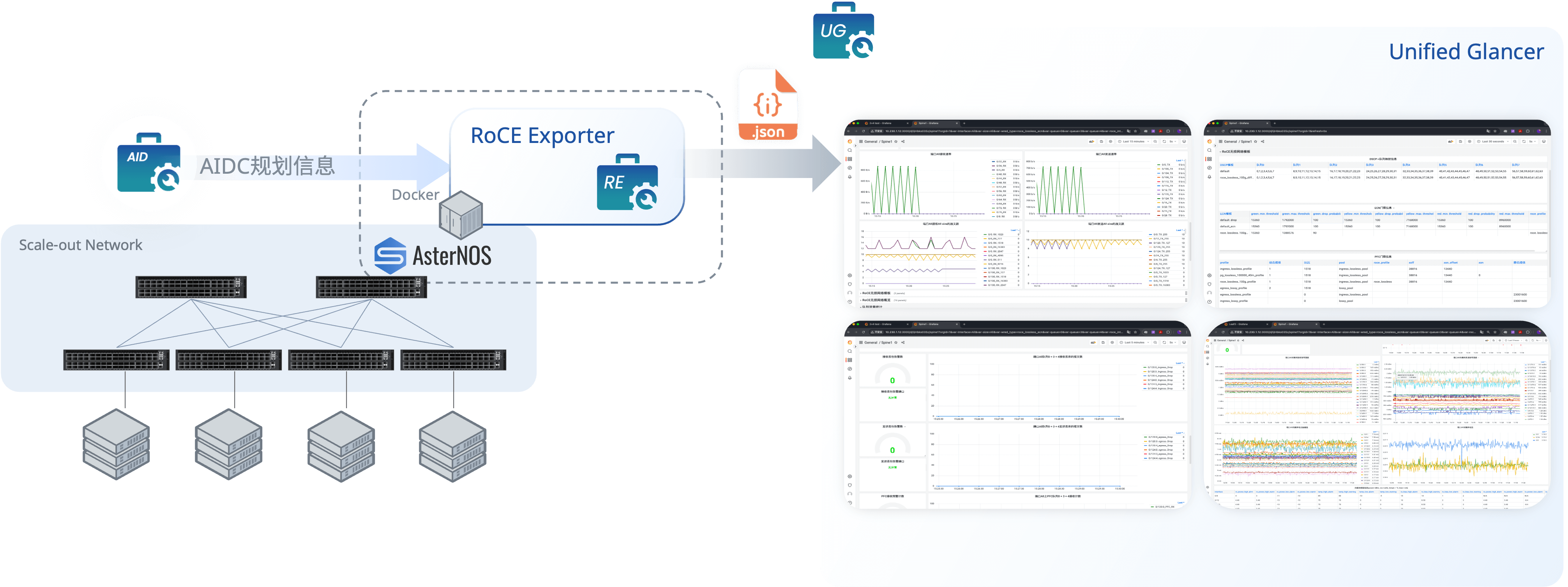
星融元CX-N系列超低时延交换机
HPC网络性能测试方案设计
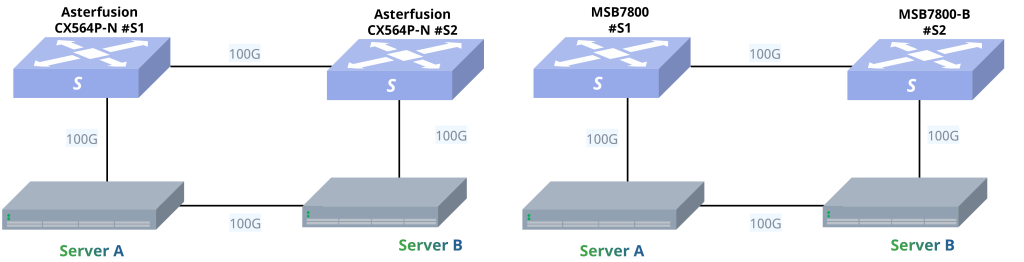
围绕HPC业务的实际要求和当前市场关注的IB替代问题,我们构建了面向典型HPC场景的网络测试,在同一测试环境下,部署同等规格速率的Mellanox IB和星融元的RoCE交换机 (32 x 100G)互为对照。测试项目包括转发测试、MPI基准测试、Linpack基准测试和HPC应用测试。
完成基础环境部署后(步骤见附录),我们在服务器Centos7.8系统下切换Mellanox InfiniBand卡的工作模式,确保两台服务器上的网卡工作模式正确对应被测交换机(IB或RoCE)
端到端转发时延测试
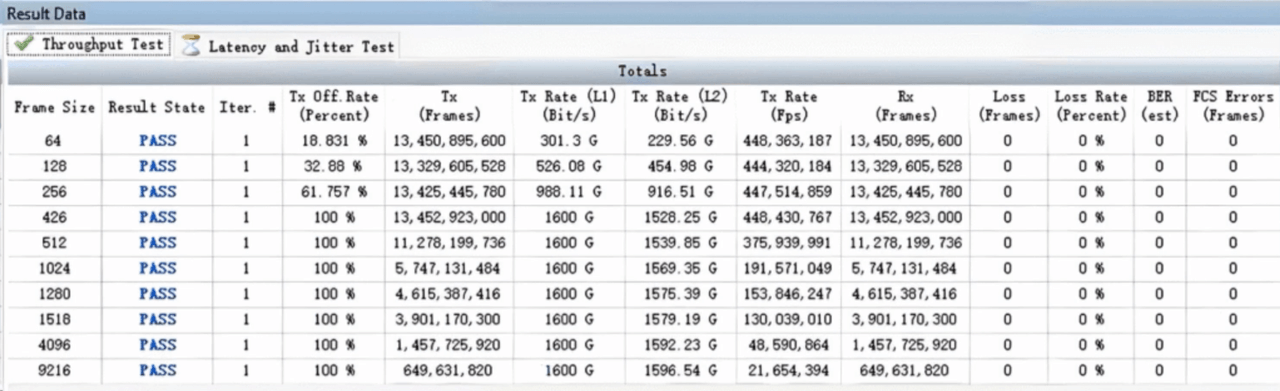
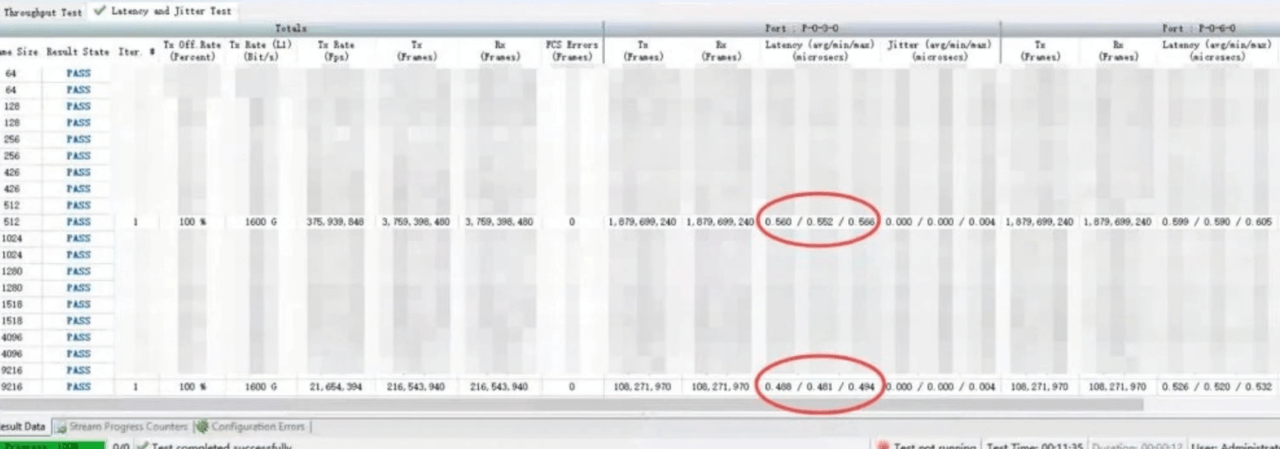
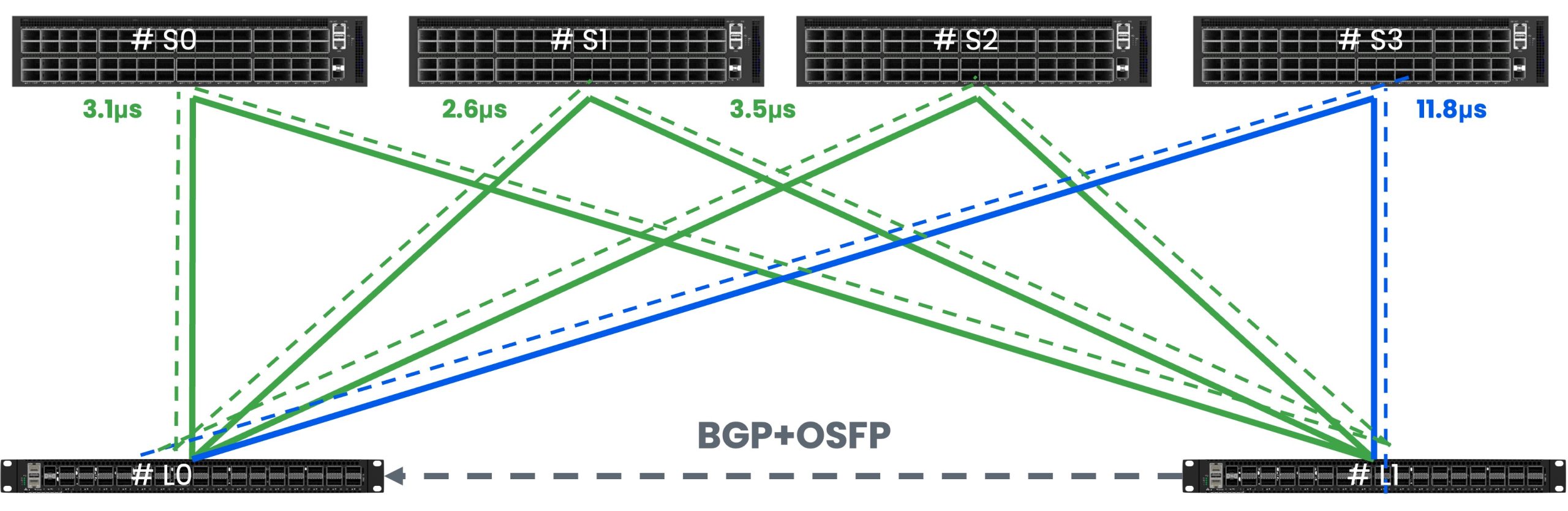
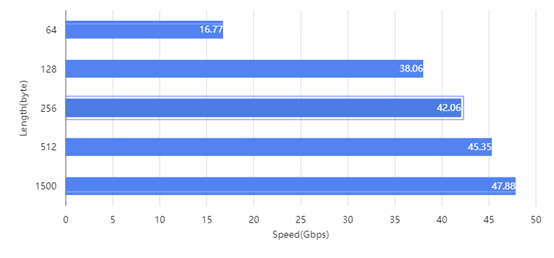
测试两款交换机在相同拓扑E2E(End to End)场景下的转发时延和带宽。采用Mellanox IB发包工具进行发包,测试遍历2~8388608字节。星融元交换机的E2E表现与IB交换机基本持平,带宽利用率与IB同为96%左右,两者时延差异保持在纳秒级。
MPI基准测试
MPI是一种消息传递接口,用于实现在多个计算节点之间进行并行计算和数据通信。MPI的核心思想是通过发送和接收消息进行节点间的数据交换,实现分布式计算的目标。
MPI提供了一系列的并行计算函数,如任务分发、结果收集和同步操作等,以及消息传递函数,如发送消息、接收消息和广播以实现高效的数据通信。通过合理地设计数据通信模式,可以避免数据冗余和通信瓶颈,提高计算效率。此外,MPI还提供进程管理函数来控制进程的创建、销毁、通信等。
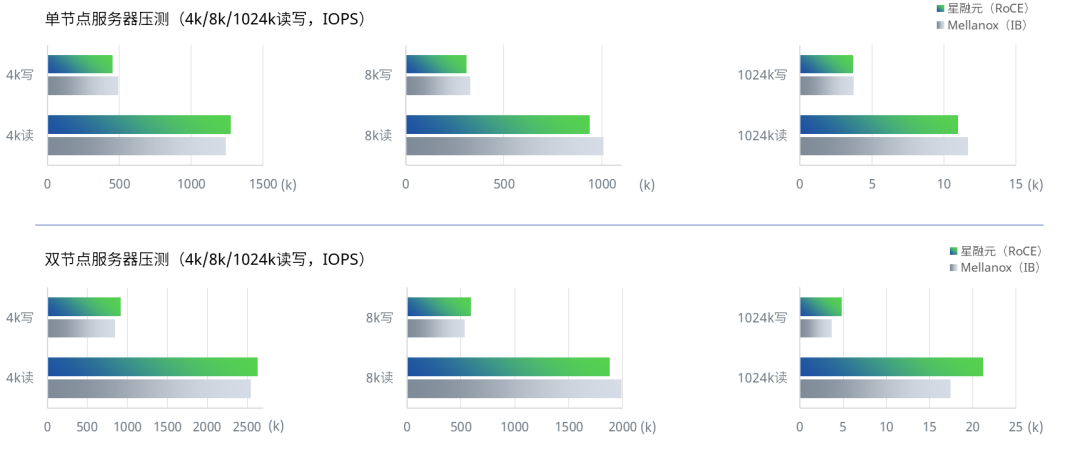
MPI基准测试使用OSU Micro-Benchmark工具MPI run方式测试网卡直连和通过两台交换机的端到端时延。星融元RoCE交换机与IB交换机的 端到端性能基本一致,时延差异保持在纳秒级 。
LinPack基准测试
Linpack现在在国际上已经成为最流行的用于测试高性能计算机系统浮点性能的Benchmark,通过高斯消元法求解N元一次稠密线性代数方程组,评价HPC的浮点运算性能。算力使用效率=实际峰值/理论峰值*100%,其中理论峰值来自于服务器的规格参数,即主频率*核心数*每周期浮点运算次数。在测试环境下,星融元RoCE交换机与IB交换机的LinPack效率基本一致 。
HPC 应用测试
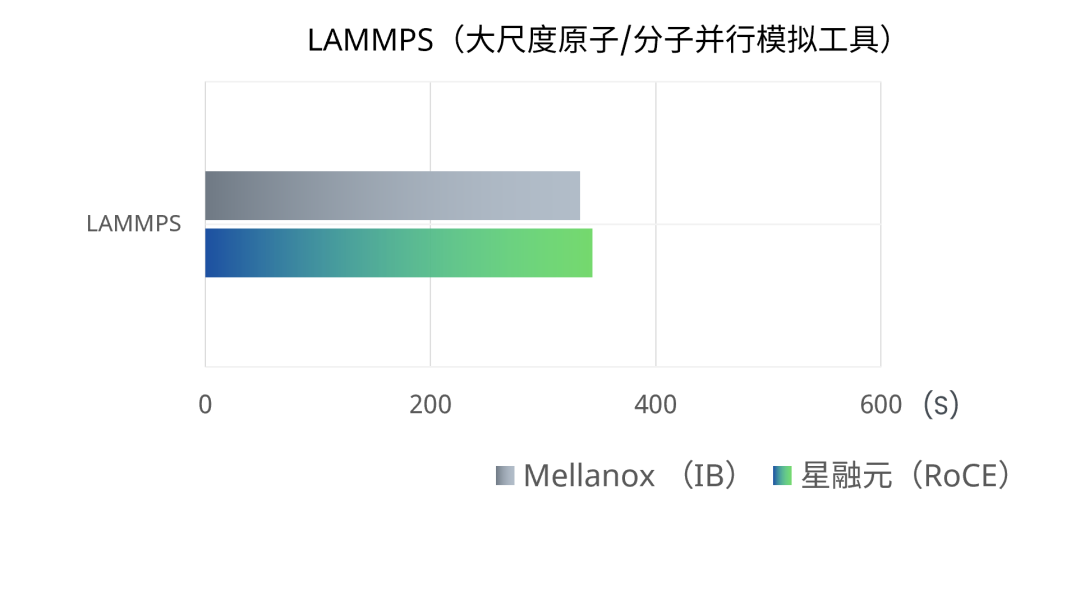
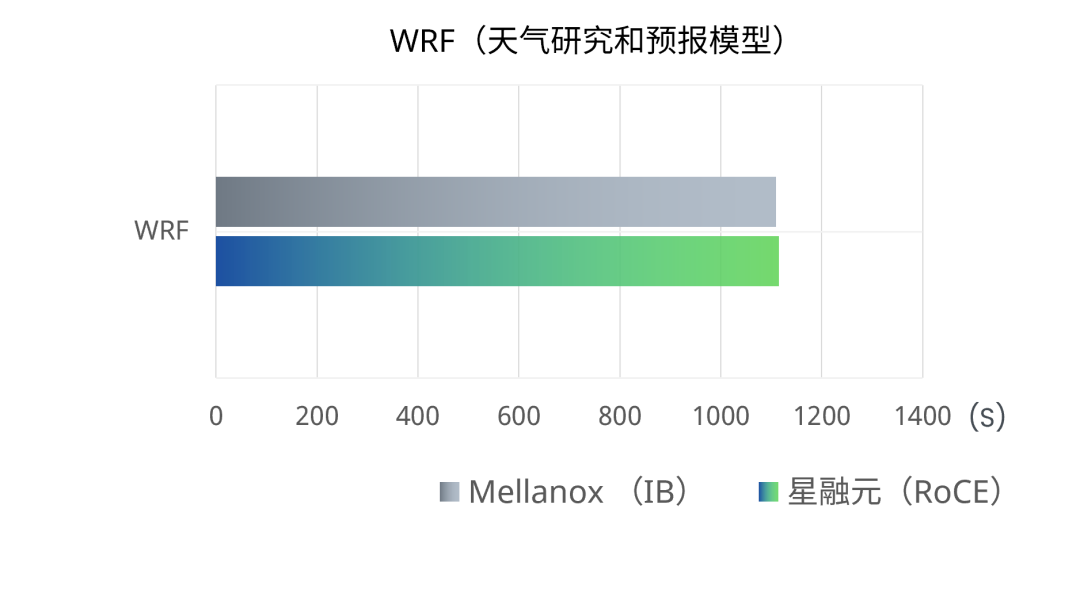
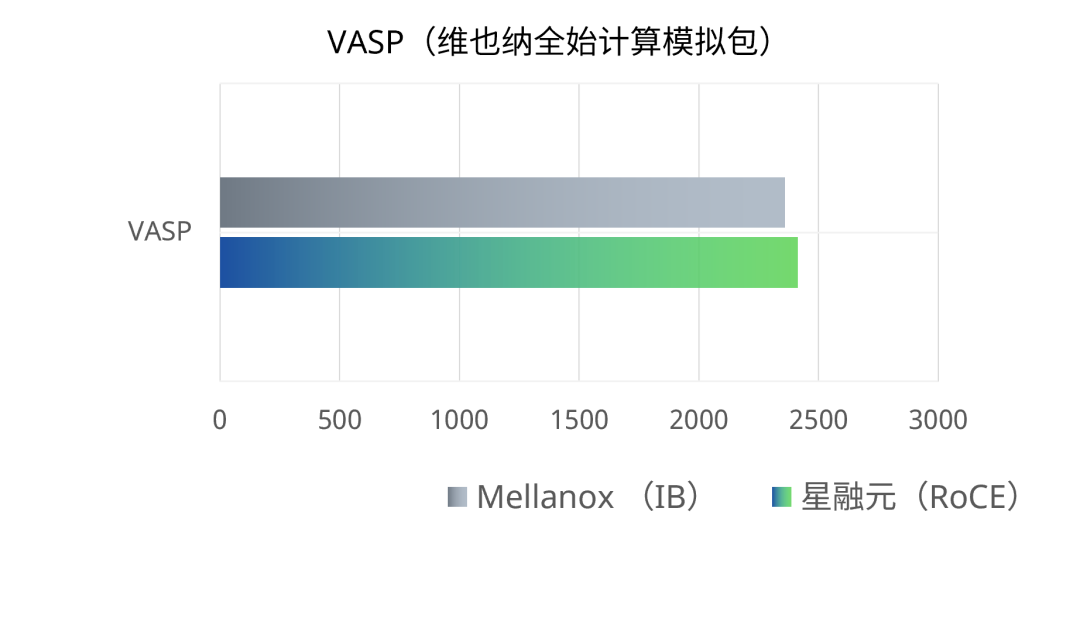
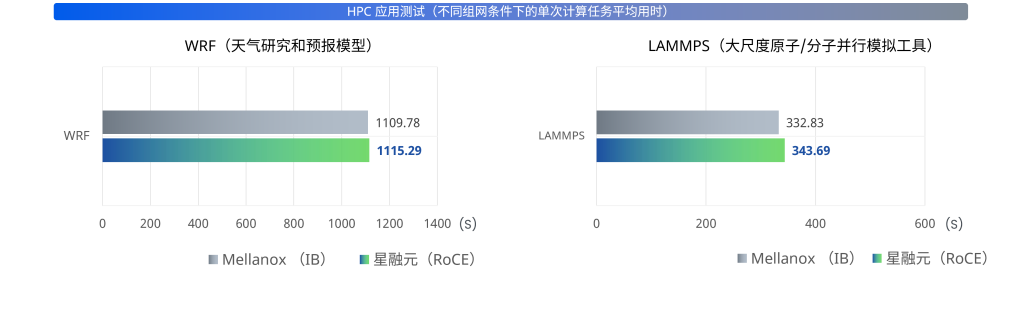
WRF(天气研究和预报模型)、LAMMPS(大尺度原子/分子并行模拟工具)和VASP(维也纳全始计算模拟包)分别是气象预报、分子动力学、量子化学领域的专用工具。测试结果为被测设备和对照组完成一次相同计算任务所需时间,最终结果取连续进行三次测试的平均用时。
星融元RoCE交换机组网条件下完成一次相同计算任务的平均用时与使用IB交换机组网的用时基本相当,两者差异在0.5%~3%之内。
附录:基础环境配置
网卡MLNX_OFED驱动程序安装
[root@Server ~]# wget \
https://content.mellanox.com/ofed/MLNX_OFED-5.0-1.0.0.0/MLNX_OFED_LINUX-5.0-1.0.0.0-rhel7.8-x86_64.tgz
[root@Server ~]# tar -zxvf \
MLNX_OFED_LINUX-5.0-1.0.0.0-rhel7.8-x86_64.tgz
[root@Server ~]# cd MLNX_OFED_LINUX-5.0-1.0.0.0-rhel7.8-x86_64
[root@Server ~]# ./mlnx_add_kernel_support.sh -m \
/root/MLNX_OFED_LINUX-5.0-1.0.0.0-rhel7.8-x86_64 -v
[root@Server ~]# tar xzvf \
MLNX_OFED_LINUX-5.0-1.0.0.0-rhel7.8-x86_64-ext.tgz
[root@Server ~]# cd MLNX_OFED_LINUX-5.0-1.0.0.0-rhel7.8-x86_64-ext
[root@Server ~]# ./mlnxofedinstall
检查网卡及网卡驱动状态
[root@Server ~]# /etc/init.d/openibd start
[root@Server ~]# ibstatus
[root@Server ~]# systemctl start mst
[root@Server ~]# mst statusHPC基础环境
[root@Server ~]# cat /etc/hosts
[root@Server ~]# systemctl stop firewalld && systemctl disable firewalld
[root@Server ~]# iptables -F
[root@Server ~]# setenforce 0
[root@Server ~]# ssh-keygen
[root@Server1 ~]# ssh-copy-id -i id_rsa.pub root@192.168.4.145
[root@Server2 ~]# ssh-copy-id -i id_rsa.pub root@192.168.4.144
[root@Server1 ~]# yum -y install rpcbind nfs-utils
[root@Server1 ~]# mkdir -p /data/share/
[root@Server1 ~]# chmod 755 -R /data/share/
[root@Server1 ~]# cat /etc/exports
/data/share/ *(rw,no_root_squash,no_all_squash,sync)
[root@Server1 ~]# systemctl start rpcbind
[root@Server1 ~]# systemctl start nfs
[root@Server2 ~]# yum -y install rpcbind
[root@Server2 ~]# showmount -e Server1
[root@Server2 ~]# mkdir /data/share
[root@Server2 ~]# mount -t nfs Server1:/data/share /data/share
MPI Benchamarks工具安装
[root@Server ~]# yum -y install openmpi3 openmpi3-devel -y
[root@Server ~]# wget \
http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.6.3.tar.gz
[root@Server ~]# tar zxvf osu-micro-benchmarks-5.6.3.tar.gz
[root@Server ~]# cd osu-micro-benchmarks-5.6.3
[root@Server ~]# ./configure
[root@Server ~]# make -j
[root@Server ~]# make install
[root@Server ~]# mkdir /osu
[root@Server ~]# cp -rf \
/usr/mpi/gcc/openmpi-4.0.3rc4/tests/osu-micro-benchmarks-5.3.2/* /osu
HPC 应用测试的基础环境需要在Server服务器上完成编译器的安装以及基础环境变量的配置,在Server服务器上安装第三方库以及完成zlib、libpng、mpich、jasper和netcdf软件的编译,并对依赖库进行测试。具体参考各类工具官方文档。
交换机和服务器上的配置参考
# 星融元CX-N交换机A
admin@sonic:~$sudo config vlan add 100
admin@sonic:~$sudo config vlan add 100
admin@sonic:~$sudo config vlan member add 100 Ethernet8
admin@sonic:~$sudo config interface ip add Vlan100 1.1.3.1/24
admin@sonic:~$sudo config interface ip add Ethernet0 1.1.1.1/24
admin@sonic:~$sudo config route add prefix 1.1.2.0/24 nexthop 1.1.1.2
# 星融元CX-N交换机B
admin@sonic:~$sudo config vlan add 100
admin@sonic:~$sudo config vlan member add 100 Ethernet8
admin@sonic:~$sudo config interface ip add Vlan100 1.1.2.1/24
admin@sonic:~$sudo config interface ip add Ethernet0 1.1.1.2/24
admin@sonic:~$sudo config route add prefix 1.1.3.0/24 nexthop 1.1.1.1
# Server1
[root@Server1 ~]# modprobe 8021q
[root@Server1 ~]# vconfig add ens1f0 100
[root@Server1 ~]# ifconfig ens1f0.100 1.1.3.2/24 up
[root@Server1 ~]# ifconfig ens1f1 1.1.9.9/24 up
[root@Server1 ~]# route add -net 1.1.0.0 netmask 255.255.0.0 \
gw 1.1.3.1
# Server2
[root@Server1 ~]# modprobe 8021q
[root@Server1 ~]# vconfig add ens1f0 100
[root@Server1 ~]# ifconfig ens1f0.100 1.1.3.2/24 up
[root@Server1 ~]# ifconfig ens1f1 1.1.9.9/24 up
[root@Server1 ~]# route add -net 1.1.0.0 netmask 255.255.0.0 \
gw 1.1.3.1