构建无损网络:DCQCN与FastECN协同下的拥塞控制策略
近期文章
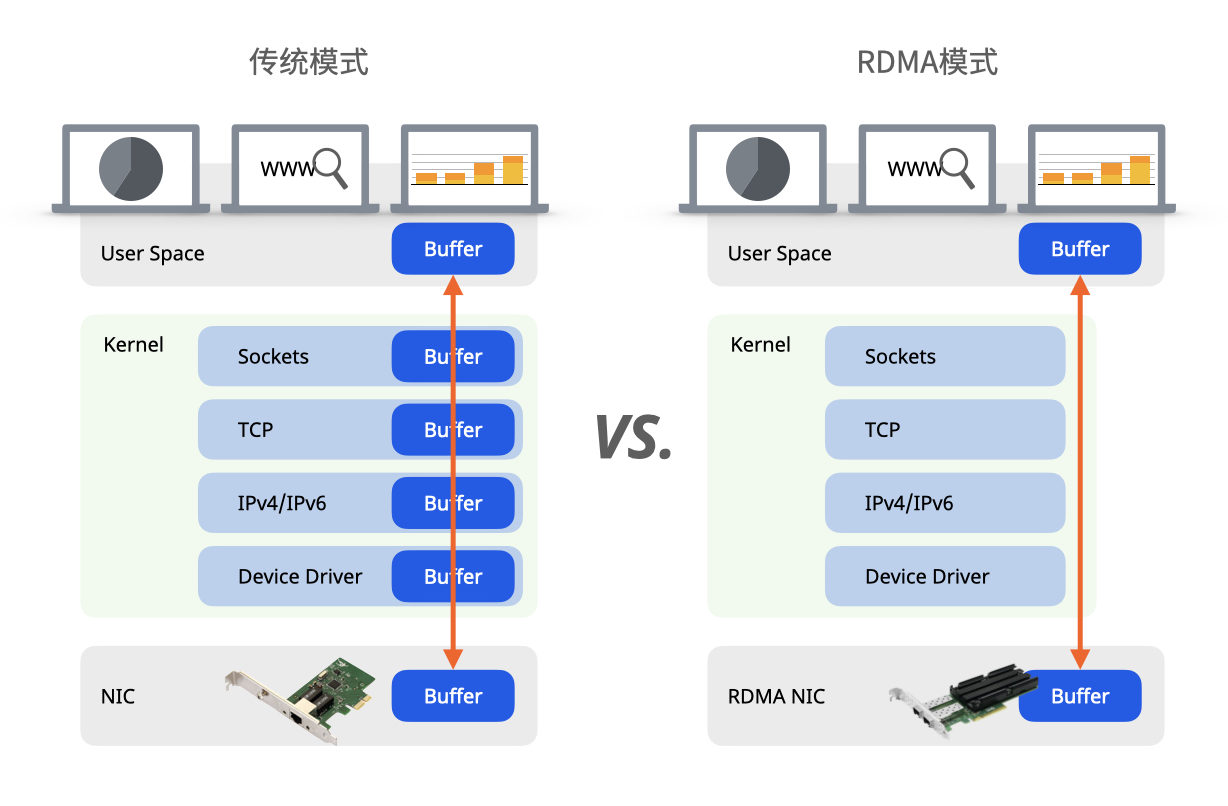
在传统的 TCP 网络中,当网络发生拥塞时,路由器会直接丢弃(Drop)数据包。发送端通过检测到丢包(超时或重复ACK)来推断网络发生了拥塞,从而降低发送速率。这是一种隐式的、通过“丢包”来传递的拥塞信号。
ECN 则是一种“显式”的拥塞通知机制,它的目标是避免丢包、减少延迟。【详情参见 ……】
我们知道,ECN的拥塞信号需要一个完整的往返时间才能到达发送端,这个延迟在高速或长距离网络中会成为性能瓶颈。
发送端发送数据 -> 路由器标记 -> 接收端接收 -> 接收端发送ACK -> 发送端处理ACK
什么是FastECN?
FastECN(或常被称为基于AI的ECN,如AI-ECN)是一种用于智算中心高性能无损网络的智能拥塞控制技术。它通过人工智能算法动态调整显式拥塞通知(ECN)的门限,以在实现零丢包的同时,保障网络的低时延和高吞吐量,从而满足AI大模型训练等场景对网络性能的苛刻要求。
FastECN的工作原理
FastECN解决了传统ECN机制中拥塞通知延迟过高的问题,它通过让网络设备(如交换机、路由器)直接向发送端发送拥塞信号,避免了接收端中转的延迟(主要应用于对延迟极其敏感的数据中心等网络环境)。
FastECN 在 ECN 的基础上增加了一种新的反馈机制
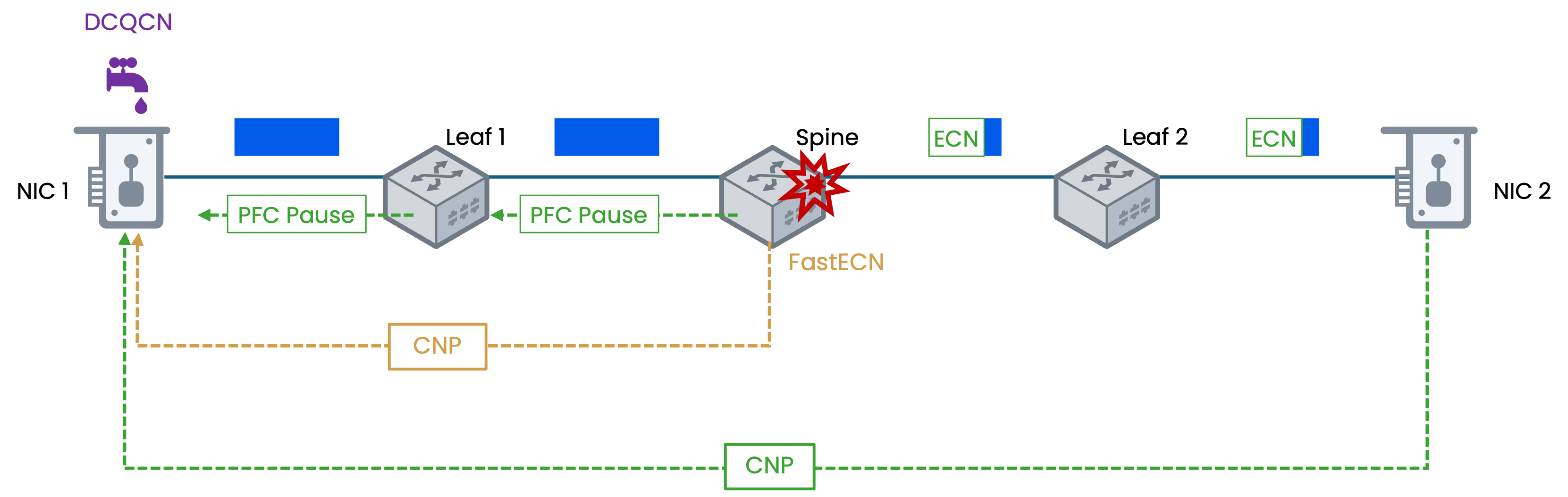
1、数据包标记(与ECN相同)
发送端发出支持 ECN 的数据包(IP 头中 ECN 字段设置为 10 或 01,即 ECT(0) 或 ECT(1))。当网络设备发生拥塞时,它会将数据包的 ECN 字段标记为 CE (11)。
2、生成并发送拥塞通知包 (CNP – Congestion Notification Packet)
这是 FastECN 的关键创新。检测到拥塞的网络设备(或与其相连的智能网卡)自己会生成一个特殊的控制包,即 CNP。这个 CNP 是一个非常小的数据包(通常只有几十字节),其中CNP包含以下关键信息:
- 拥塞流的信息:例如,被标记的数据包的 五元组(源/目的 IP、源/目的端口、协议)的一部分,用于标识哪个流经历了拥塞。
- 拥塞程度信息(可选):例如,该数据包被标记时的队列长度,可以提供更精细的拥塞控制。
3、直接反馈。
网络设备会直接通过网络将这个 CNP 发送回该数据流的源发送端。这个过程是立即的、直接的,不再需要经过接收端。
4、发送端立即反应。
发送端收到 CNP 后,立即执行拥塞控制算法,降低发送速率。因为 CNP 是直接从拥塞点发回的,其延迟远低于通过接收端再返回的 ACK 路径。
FastECN 的核心优势在于它让网络设备直接向发送端发送拥塞通知包(CNP),绕过了接收端中转,避免了至少一个 RTT 的延迟,这使得发送端能够即时地对拥塞做出反应,从而更高效地抑制队列增长、避免丢包,维持高吞吐量与低延迟;同时,CNP 中还可携带诸如队列深度等丰富的拥塞信息,为发送端实施更精细、高效的拥塞控制算法提供了基础。
相较ECN,FastECN都做了哪些升级?
FastECN 的思想(以及类似的技术,如 Intel 的 DCQCN)是现代数据中心RDMA(远程直接数据存取)技术的基石。RDMA 要求极低的延迟和零丢包,传统 ECN 的延迟无法满足要求,而 FastECN 机制正好解决了这个问题。
| 特性 | 传统 ECN | FastECN |
|---|---|---|
| 反馈路径 | 间接:拥塞点 -> 接收端 -> 发送端 | 直接:拥塞点 -> 发送端 |
| 通知机制 | 通过接收端的 ACK 包中的标志位 | 由网络设备生成专用的 CNP 包 |
| 延迟 | 至少 1 个 RTT | 极低,近乎单向延迟 |
| 主要目标 | 普通互联网,避免丢包 | 超低延迟网络(如数据中心),实现零丢包和超低延迟 |
DCQCN 和 FastECN
数据中心网络中,DCQCN和 FastECN都是RDMA网络常用的拥塞控制机制,它们都旨在实现低延迟、高吞吐和无损传输,但设计理念和实现方式有显著差异,可以从运维、行业特性及业务需求等来选择流量控制和拥塞管理方案。
| 特性维度 | DCQCN (数据中心量化拥塞通知) | FastECN (或AI-ECN等智能ECN) |
|---|---|---|
| 核心机制 | 端到端拥塞控制协议,结合ECN和PFC | 通常指利用AI/机器学习动态优化ECN阈值的行为 |
| 工作原理 | 交换机标记ECN → 接收端发送CNP → 发送端降速 | 嵌入式AI实时分析网络流量(队列长度、吞吐等),智能计算并动态调整ECN阈值 |
| 拥塞反馈路径 | 较长(交换机→接收端→发送端) | 更直接(设备本地智能决策或快速响应) |
| 关键依赖 | 依赖PFC实现无损,但需谨慎配置避免PFC缺陷(如HOL阻塞) | 依赖AI模型训练数据的质量和代表性 |
| 配置复杂度 | 高,有超过16个可调参数,需端网协同调优 | 低,旨在自动化调优,减少人工干预 |
| 灵活性 | 相对静态,参数设定后对流量变化适应性有限 | 高,能自适应不同流量模式和应用场景 |
| 主要优势 | 成熟、广泛应用、在RoCEv2网络中经过大量实践检验 | 自适应、智能化、有望降低运维复杂度、提升网络效率 |
| 潜在挑战 | 参数调优复杂、PFC可能引发全局暂停、对突发流适应性有时不足 | 依赖训练数据、AI模型可靠性需验证、初期部署成本可能较高 |

-图01.png)
-图02-1024x399.png)
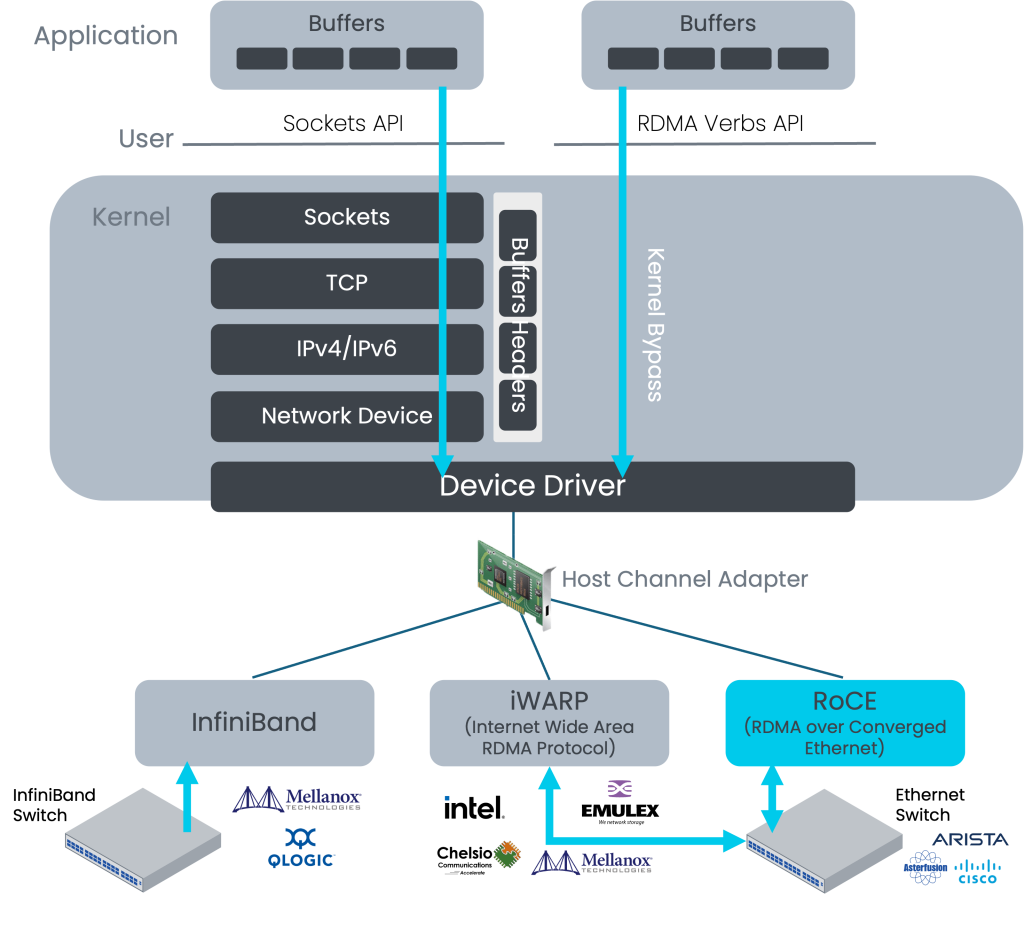
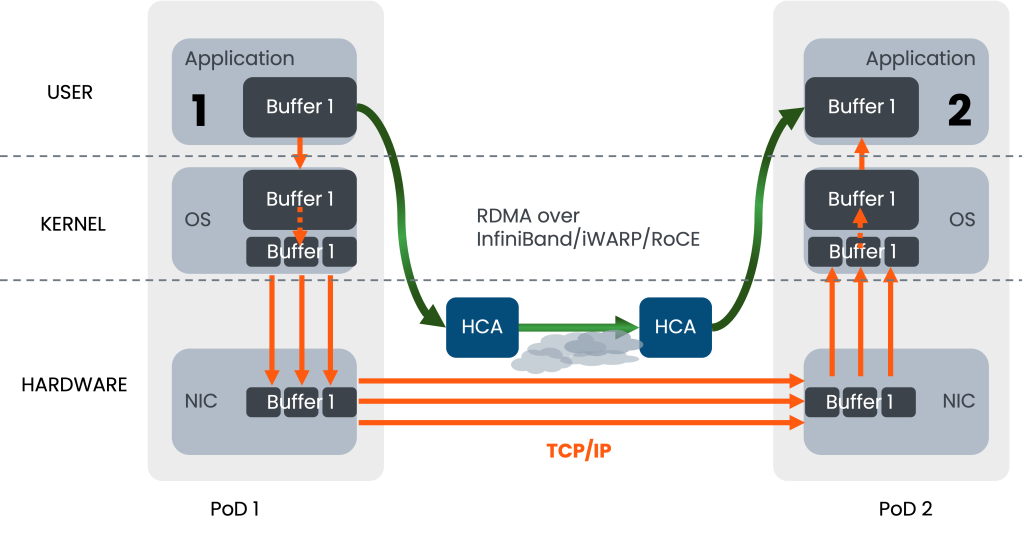
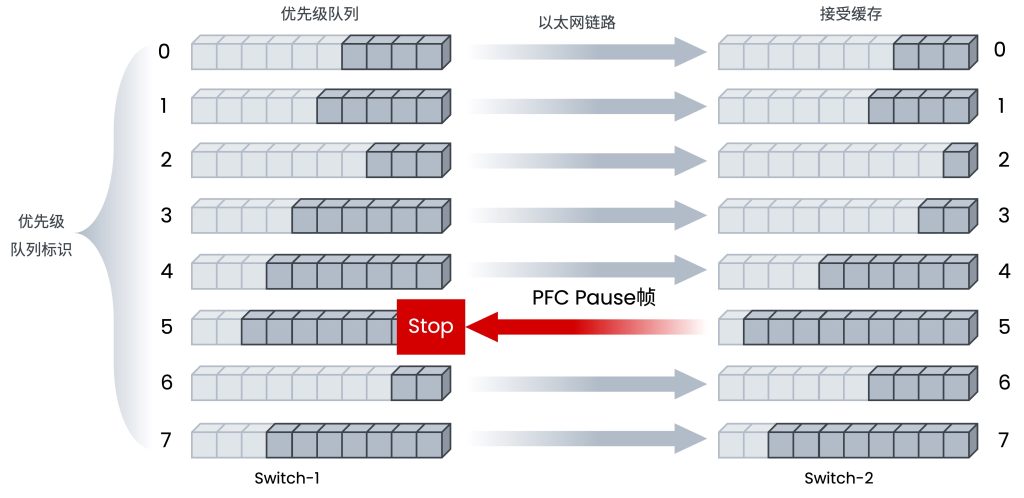
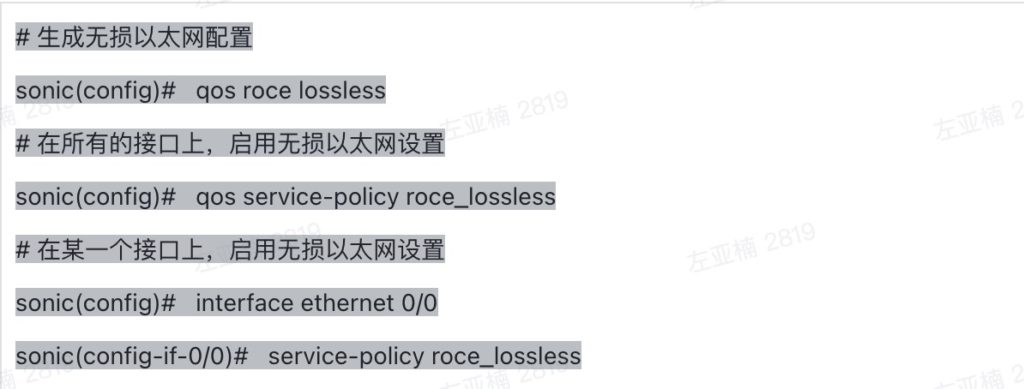
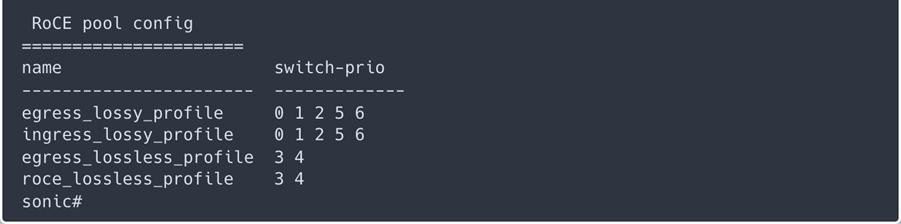
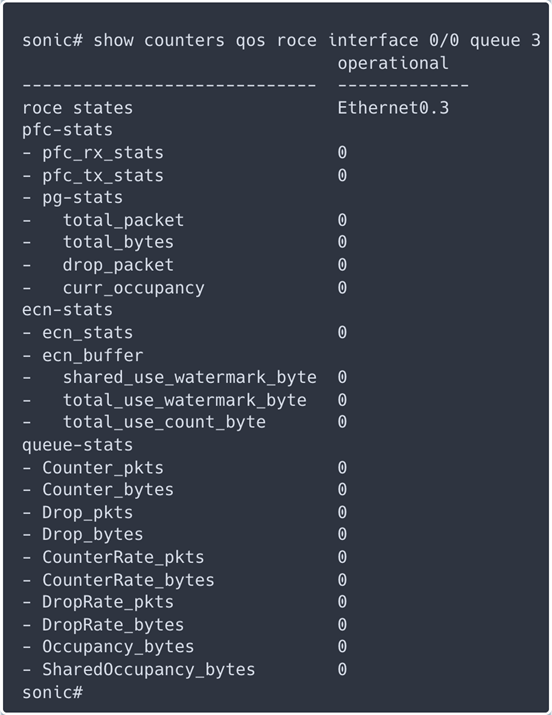
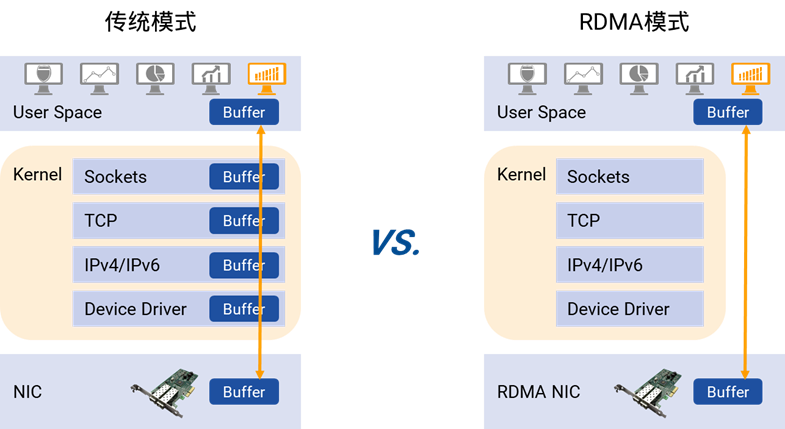
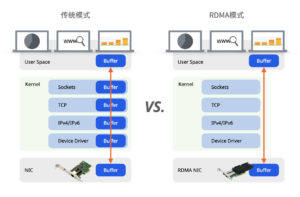 通过上述对比得出,RoCE相对于iWARP有着明显的优势,因此RoCE被很多主流厂商的方案所支持,成为该领域的发展方向。而在RoCE流量的传输中,网络的传输性能和质量直接影响了RDMA应用的体验,承载RoCE流量的以太网的建设就变得非常重要。
通过上述对比得出,RoCE相对于iWARP有着明显的优势,因此RoCE被很多主流厂商的方案所支持,成为该领域的发展方向。而在RoCE流量的传输中,网络的传输性能和质量直接影响了RDMA应用的体验,承载RoCE流量的以太网的建设就变得非常重要。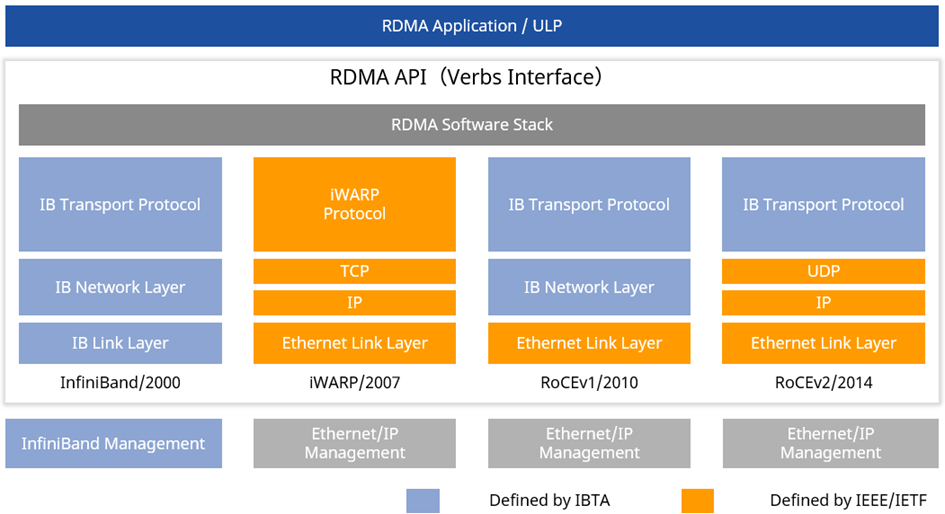
-图02-1.png)
-图01.png)
-图02.png)