更多相关内容
RDMA为什么出现,它有什么好处
科技发展催生RDMA诞生
随着AI、5G网络的兴起,大数据分析、边缘计算的飞速发展,以及“唤醒万物,万物互联”时代的到来,各种应用、各种行业对高效通信的需求越来越强烈,在这一风口浪尖上,英特尔、NVIDIA、AMD、亚马逊、微软、联想、阿里巴巴、百度、Dell、EMC、阿托斯、华为、曙光、浪潮、Cray、Fujitsu、HP和NEC等众多公有云厂商推出了解决方案“为用户提供灵活、强弹性和高可扩展的基础通讯设施以及几乎无限的存储容量”,吸引了越来越多的新兴业务应用和企业将数据中心建设于公有云之上。当客户将数据中心建设于公有云上时,数据中心网络中的东西向流量剧增,占据了80%的网络带宽,于是出现了大量的远程内存访问需求。
一个应用的访问会在数据中心产生一系列的连锁反应,举例说明,如图1所示,在大数据分析的数据中心应用场景中,某终端用户访问某一业务,首先访问的是Web应用区中的业务链接;然后返回访问结果,于此同时,还需要根据终端用户的访问行为推送与该行为相关的其他业务链接,此时需要依赖大数据分析系统对该用户终端的一系列行为进行分析,在分析过程中会调用存储区中终端的其他相关行为数据,再进行深入的综合分析;
最后将终端用户行为和大数据分析结果存储到存储区,并作为用户行为分析的结论传输给应用显示系统进行排列组合,最终将呈现结果推送至用户终端,并通过Web界面显示。Web应用服务器、大数据分析服务器、存储服务器以及显示系统之间存在大量的内存访问需求。
-图01.png)
远程内存访问的低效直接导致业务应用的低效
由于在数据中心领域中人们总是将目光集中在云计算、100G/400G单端口带宽的提升等技术的发展上,而忽略了如何提升计算节点接收到数据后的数据处理性能和内存带宽的利用率。当AI、5G、AR/VR/MR、大数据分析、IoT等高性能计算应用大量兴起时,面对网络带宽、处理器速度与内存带宽三者的严重“不匹配性”,就造成了网络延迟效应的加剧。远程内存访问这一常态性业务处理性能的低效就直接导致了业务应用的低效。
如图2所示,在典型的IP数据传输过程中(包括数据接收和发送两个过程),其数据处理原理是:
数据发送
Server-A上的应用程序APP-A向Server-B上的应用程序APP-B发送数据。作为传输的一部分,需要将数据从用户应用空间的Buffer中复制到Sever-A的内核空间的Socket Buffer中,然后在内核空间中添加数据包头、封装数据包,再通过一系列网络协议的数据包处理工作,诸如传输控制协议(TCP)或用户数据报协议(UDP)、互联网协议(IP)以及互联网控制消息协议(ICMP)等,最后被Push到NIC网卡的Buffer中进行网络传输。
数据接收
消息接受方Sever-B接收从远程服务器Sever-A发送的数据包后会进行应答,当Sever-A收到应答数据包时,首先将数据包从NIC Buffer中复制数据到内核Socket Buffer中,然后经过协议栈进行数据包的解析,解析后的数据会被复制到相应位置的用户应用空间的Buffer中,最后唤醒应用程序APP-A,等待应用程序A执行读操作。
-图02.png)
当网络流量以很高的速率交互时,发送和接收的数据处理性能非常的低效,这种低效表现在:
- 处理延时过大,达数十微妙。在数据发送和接收的过程中,大多数网络流量必须至少两次跨系统内存总线进行数据复制,一次是在主机适配器使用DMA将数据放入内核提供的内存缓冲区中,另一次是从内核将数据移至应用程序的内存缓冲区中。这意味着计算机必须执行两次中断,才能在内核上下文和应用程序上下文之间进行切换。因此服务器收到数据后的处理过程需要经过多次内存拷贝、中断处理、上下文切换、复杂的TCP/IP协议处理等,造成流量传输时延加剧;
- 单位时间内收到的报文越多,处理报文消耗的CPU和内存资源越高。交换机往往做三层解析就足够,而且是由专门的芯片来完成,不消耗CPU资源。而服务器要将收到的每个报文的内容都解析出来,网络层和传输层的解析都需要消耗CPU资源和占用内存资源,由CPU来查询内存地址、检验CRC、还原TCP/UDP包并送到应用空间。单位时间内进来的报文数量越多,消耗CPU和内存资源就越多;
- 较低的灵活性。主要原因是所有网络通信协议通过内核传递,而这种方式很难去支持新的网络协议、新的消息通信协议及发送和接收接口,使用传统的IP数据传输在后期网络的演进过程中,想要跳脱这种“困局”就变得非常的困难。
低时延、超低CPU和内存资源占用率的RDMA技术,变低效为高效
为了解决远程内存访问过程中“服务器端数据处理延迟大、资源消耗大”的问题,IBM和HP在2003年提出了RDMA(Remote Direct Memory Access,远程直接内存存取),通过使用支持该技术的网络适配器能够将数据从线路直接传输到应用程序内存或从应用程序内存直接传输到线路,从而支持零拷贝网络,无需在应用程序内存和操作系统中的数据缓冲区之间复制数据。这样的传输不需要CPU、缓存或上下文切换器完成任何工作,大幅度降低了消息传输中的处理延迟,同时传输与其他系统操作并行进行,提高了交换机的性能。
在具体的远程内存读写过程中,用于RDMA读写操作的远程虚拟内存地址包含在RDMA消息中传送,所以远程应用程序要做的只是在其本地网卡中注册相应的内存缓冲区,而远程节点的CPU除在连接建立、注册调用等之外,在整个RDMA数据传输过程中并不提供服务,因此没有给CPU带来资源消耗。举例说明,假设应用和远程应用之间已经建立了连接,并注册了远端的内存缓存区,当该应用执行RDMA读操作,其工作过程如下:
- 当一个应用执行RDMA读操作时,不执行任何数据复制。在不需要任何内核参与的条件下,RDMA请求从运行在用户空间的应用中发送到本地NIC;
- 本地NIC读取缓存的内容,并通过网络传送到远程NIC;
- 在网络上传输的RDMA信息包含目标虚拟内存地址、内存钥匙和数据本身;
- 目标NIC确认内存钥匙,并直接读取应用缓存中的数据,其中用于操作的远程虚拟内存地址包含在RDMA信息中。
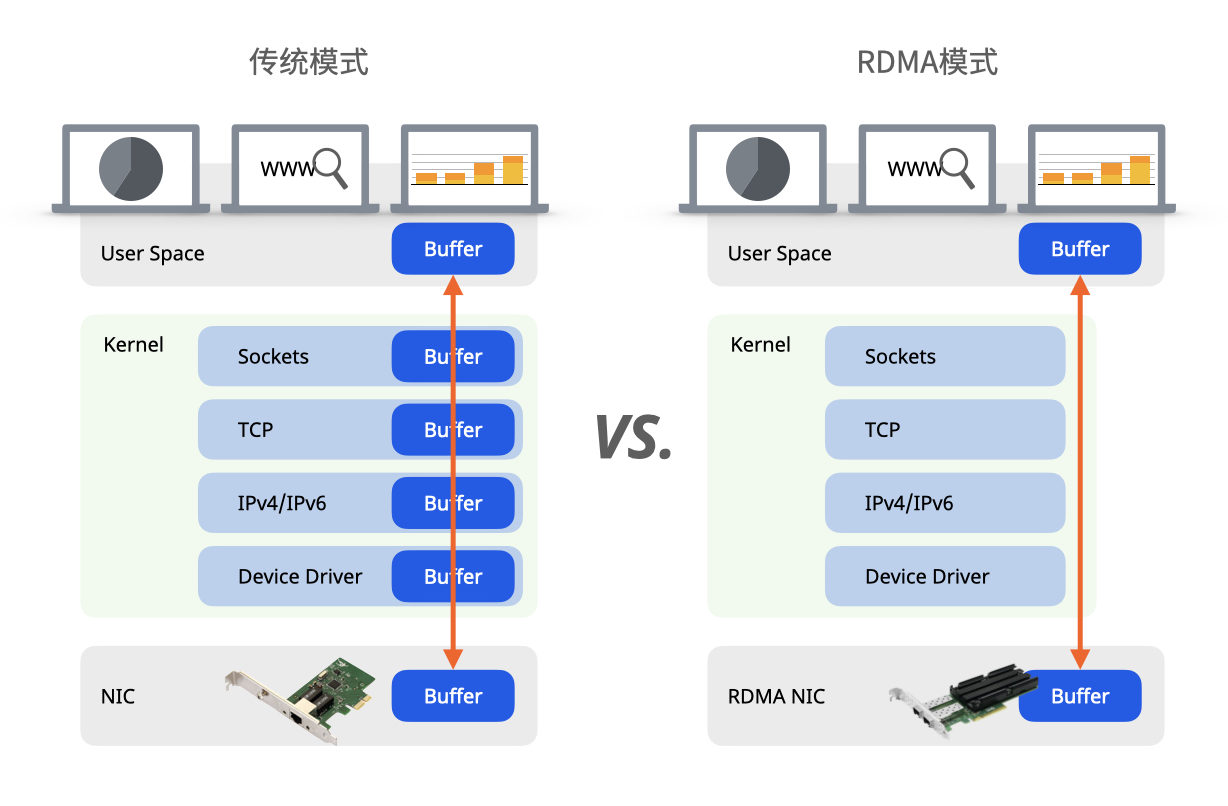
如图3所示,通过对比传统模式和RDMA模式对发送和接收数据的处理过程,RDMA技术最大的突破在于给数据中心通信架构带来了低时延、超低的CPU和内存资源占用率等特性。
低延时体现在:
- 在网卡上将RDMA协议固化于硬件。在网卡硬件上就完成四层解析,然后直接将解析后的数据上送到应用层软件,硬件的处理速率远高于软件,降低了报文的处理延时;
- 零拷贝网络。网卡可以直接与应用内存相互传输数据,消除了在应用内存与内核内存之间的数据复制操作,使传输延迟显著降低;
- 内核内存旁路。应用程序无需执行内核内存调用就可向网卡发送命令。在不需要任何内核内存参与的条件下,RDMA请求从User Space发送到本地NIC,再通过网络发送给远程网卡,这就减少了在处理网络传输流时内核内存空间与用户空间之间环境切换的次数,降低了时延;
- 消息基于事务。数据被处理为离散消息而不是流,消除了应用程序将流切割为不同消息/事务的需求;
- 支持分散/聚合条目。RDMA原生态支持分散/聚合,也就是说,读取多个内存缓冲区然后作为一个流发出去或者接收一个流然后写入到多个内存缓冲区里去。
超低CPU和内存资源占用率体现在:
应用程序可以直接访问远程内存,而不占用远程服务器中的任何CPU资源,远程CPU中的缓存资源也不会被访问的内容填满,服务器可以将几乎100%的CPU资源和内存资源提供给计算或其他的服务,节省了服务器资源占用的同时,提高了服务器数据处理带宽。
