一文梳理新一代云化园区网络建设方案-架构篇(2023版)
关注星融元

从传统的园区网络架构说起
顾名思义,园区网络指的是部署在一个园区范围内的网络,这个网络被用来连接其所在园区内的所有固定终端(台式机、服务器、打印机等)、移动终端(笔记本电脑、平板电脑、智能手机、服务机器人等)和IoT终端(门禁、考勤机、摄像头、烟雾传感器等);园区网络需要支持所有这些终端之间的互联互通,还需要按需将其中的一部分终端接入到互联网。
一个典型的园区网络往往由有线网络和无线网络两部分构成,无线网络负责通过WiFi接入各种移动终端和具备无线接入能力的IoT终端,有线网络负责接入各种固定终端和只具备有线接入能力的IoT终端;当然,无线网络最终也需要接入到有线网络中去,从而完成所有终端之间的互联互通。
在现实世界中,园区的规模或大或小,小到可能是一个容纳三五人的办公室,大到可以是同时容纳上万人、覆盖若干个大楼、甚至分布在多个城市的集团型的办公园区;相应的,园区网络的规模也可大可小,小到只需要接入个位数的各种终端,大到需要同时接入几十万数量的各种终端。
我们的讨论从一个典型的基于传统架构的园区网络模型开始。

图1:一个典型的基于传统架构的园区网络模型
在图1所示的模型中:
- 一个三层网络连接着若干二层网络,不同的区域往往划归到不同的二层网络,所有终端连接到不同的二层网络;
- 同一区域终端间的通信在本地二层网络内部完成,跨区域的终端间的通信由连接各个二层网络的三层网络完成;
- 所采用的网络设备(自下而上)一般包括:盒式的二层接入交换机、中等规模的框式汇聚层交换机和中/大规模的框式核心层交换机;
- 网络的扩展能力主要基于框式设备的纵向扩展能力;
- 网络的运维主要依赖于人工运维。
什么是开放网络架构的云网络?
在云计算发展的起步期,云的网络架构是参考传统园区网络搭建起来的。但云计算工程师很快便发现,这样的架构并不能满足云计算的业务所需,于是广大云计算工程师开始对云网络进行持续的改进和优化。
在市场需求与科技进步的双驱动之下,云网络经历了二十年的蜕变和升华。时至今日,尽管云网络架构诞生于园区网架构,但其发展早已远超后者——无论是整体的网络架构还是在硬件设备、扩展能力、运维能力等维度,云网络相比起传统园区网络都有了长足进步。

图2:一个主流的基于开放网络架构的云网络模型
在图2所示的模型中:
- 根据所连接服务器所处物理位置的不同,网络被分成了若干个POD,所有POD则通过一个更大的网络连接起来;
- 与传统园区网络架构不同的是,任何一个POD内的网络、连接所有POD的网络都是三层网络,网络的总体规模从连接几十台到几十万台服务器不等,这个网络往往被称为Underlay Network;
- 在同一个Underlay Network之上,管理员创建出不同的虚拟网络为云上的不同租户和不同业务提供连接服务,租户和业务并不感知Underlay Network的存在,只感知有一个(虚拟)网络为自己在服务,这个虚拟网络往往被称为Overlay Network;
- 云网络的搭建一般不再采用或大或小的框式网络设备,而是根据需求选择不同规格、性能的盒式设备,从而避免单设备的复杂度给整体网络运营和运维带来更高的成本和难度;
- 基于Clos架构,这些盒式网络设备可以组成从连接几十台服务器到几十万台服务器的不同规模的网络,并且网络规模可以按需横向扩展;
- 云网络的运维往往通过云管平台、网络控制器等实现自动化运维。
经过这些年的发展,为了区别于传统的网络架构,业界往往采用“开放网络架构”这样的术语来指代云网络架构。
随之而来的问题就是:如果将开放网络的架构及其技术推广到更广泛的网络世界,譬如园区网络,将给这些“更广泛的网络世界”带来什么样的改变?这些改变将会带来什么样的好处?
开放网络架构与技术将从哪些方面改变园区网络?
接下来,从网络的规划、建设、运维三个维度,我们分别探讨开放网络架构与技术有可能带给园区网络的改变,以及这些改变能够带来的好处。为了便于论述,我们将“基于开放网络架构和技术的园区网络”简称为“云化园区网络”,一来便于与“传统园区网络”方案进行区别,二来便于描述其本质(即“沿袭自云网络架构的新一代园区网络架构”)。
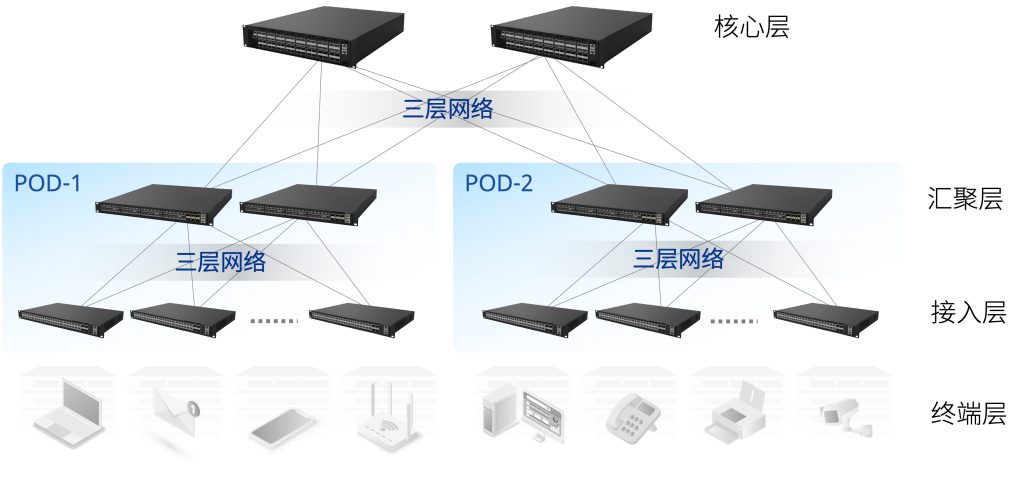
1. 多级CLOS结构的网络
如下图所示,在采用了开放网络架构的云化园区网络中,全部采用CLOS结构的组网模型。

多级CLOS结构的网络
以一个园区为例:
- 从楼层到整个园区,是个三级/四层的CLOS网络(Leaf-Spine结构的网络):
- 在楼层范围内,接入层交换机作为Leaf(也可称为接入Leaf),楼层汇聚交换机作为Spine(也可称为楼层Spine),构成第一级的CLOS网络;
- 在楼栋范围内,楼层汇聚交换机作为Leaf,楼栋汇聚交换机作为Spine(也可称为楼栋Spine),构成第二级的CLOS网络;
- 在园区范围内,楼栋汇聚交换机作为Leaf,园区汇聚交换机作为Spine(也可称为园区Spine),构成第三级的CLOS网络;
- 随着园区规模的从小到大,这个多级的CLOS网络能够从一级横向扩展至多级,使得网络能够接入的终端数量从几十个到几十万个不等,并且,扩展的过程中,原有的网络架构完全保持不变,新扩展的模块与原有模块架构完全一致,从而最大限度地降低了维护的复杂度;
- 基于其横向扩展能力,这个多级CLOS网络完全采用盒式的单芯片交换机来搭建,彻底抛弃了传统网络架构中各种规模的框式设备,从而在最大限度上避免了框式网络硬件带来的高昂成本;
- 在图中所示的三级CLOS网络中,任意两个终端之间的通信可保证在1跳(最优情况)到7跳(最坏情况)之内完成,并且因为路由结构的设计,所有的网络通信会充分利用所有的物理线路,因此网络通信质量是高性能、高可靠且可以预测的,从而在最大限度上确保了网络提供服务的质量。
2. 数据中心级的交换机设计
基于开放网络架构的云网络在过往十几年的发展过程中,在交换机设计方面逐渐形成了其独有的特点,我们将这些特点称之为数据中心级的交换机设计。
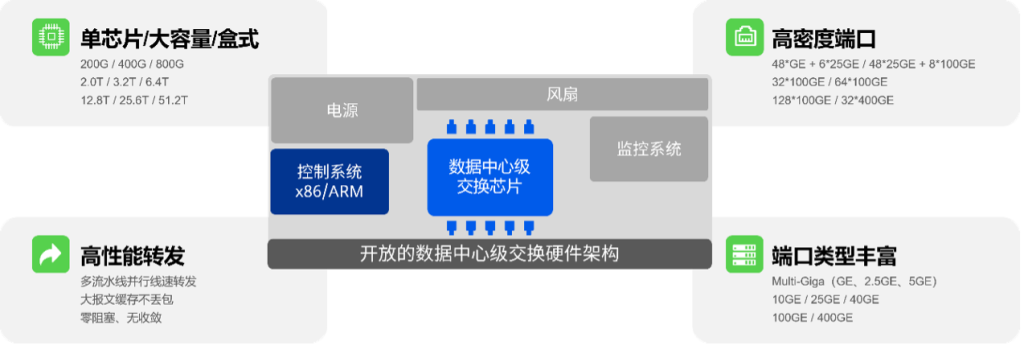
数据中心级的交换机设计
将这些特点运用于云化园区网络会极大地提升园区网络的架构先进性、整体性能和可持续发展性:
- 开放的硬件架构:由控制系统、数据中心级交换芯片、监控系统、电源、风扇等标准化模块构成,设计理念不再追求传统厂商主导的大规模、复杂的框式结构,而是追求标准化、单芯片、简单的结构,并且通过Clos架构来提升网络的横向扩展能力和整体接入能力;
- 数据中心级交换芯片:交换容量从2Tbps开始,依次向上增长到3.2Tbps、6.4Tbps、12.8Tbps、25.6Tbps,甚至51.2Tbps,基于这样容量芯片的单芯片、盒式交换机部署在园区网络的核心位置上足以承载大规模网络的流量;
- 超高端口密度:无论是接入Leaf还是各级Spine交换机,均可以提供超高密度的端口,譬如,在1U的空间内,接入Leaf可以提供48个千兆PoE接入端口和6个25GE上行端口,楼层Spine可以提供48个25GE接入端口和8个100GE上行端口,楼栋Spine则可以采用具备32个或者64个100GE端口的交换机,对于超大规模的园区,则可以采用具备128个甚至256个100GE端口的交换机作为园区Spine;
- 超高转发性能:所有数据中心级交换机均支持多流水线、全线速转发,从而保障云化园区网络支持零阻塞、无收敛的性能,这一点在今天大规模的园区网络中非常有价值,能够确保大量的访问数据中心的流量(业务系统访问等)和终端之间的P2P流量(音视频交流、文件传送等)无损的传送,提升园区网络用户的使用体验;
- 丰富的端口类型:25GE、100GE接口已经数据中心普遍使用,400GE接口也正在规模部署阶段,这些高速接口能够将网络传送每比特的成本降低至传统方案的20%~50%,并且能够有效地在未来五到八年之内保护用户的投资,因此,在云化园区网络中广泛部署此类高速接口将大幅度降低园区网络的TCO,更值得一提的是,在接入Leaf上支持Multi-Giga接口(2.5Gbps/5Gbps)可以为即将规模部署的Wi-Fi 6提前做好物理接入带宽的准备。
3. 开放的网络操作系统
开放的网络操作系统是开放网络架构的灵魂,它使得网络管理员能够以SDN(Software Defined Network,软件定义网络)、IBN(Intention-Based Network,基于意图的网络)和NetDevOps的方式运维开放的网络。
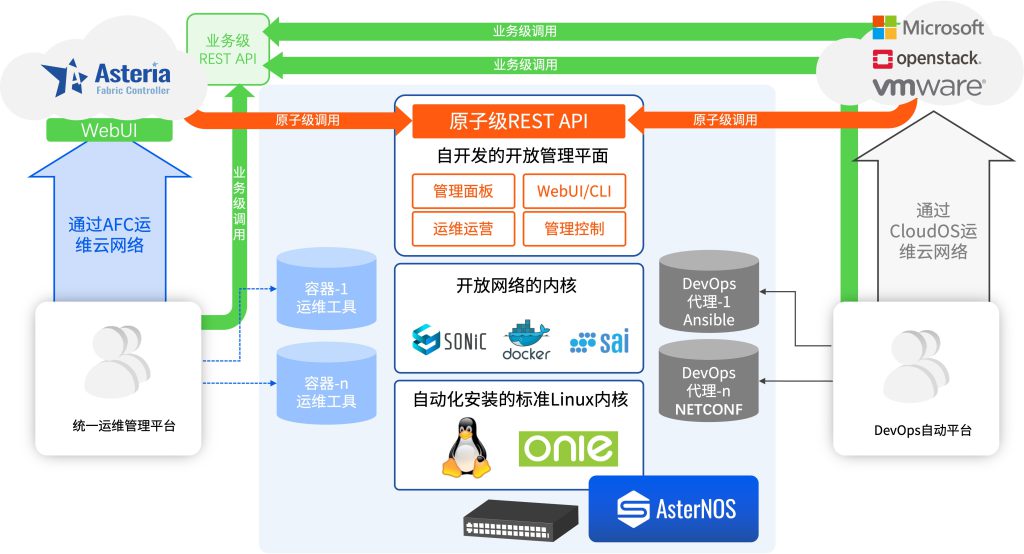
开放的网络操作系统
上图以星融元的开放网络操作系统AsterNOS为例,描述了一个基于SONiC的网络操作系统在整个云网络中的位置、功能以及与周边系统、角色的关系。可以类比的是,当我们将同样的操作系统引入到云化园区网络后,网络管理员将能够:
- 通过图形化界面将网络部署、变更的意图提交给网络控制器,即可自动化完成对所有网络设备的配置,即避免了繁琐的逐设备的命令行配置,又能够有效避免人工操作引入的人为错误,从而提升网络的整体健壮性;
- 网络管理员无需再在每台网络设备上维护纷繁复杂的配置文件,而是好像维护代码一样在服务器上完成对网络配置文件的变更管理、版本管理、模拟上线运行等工作,并且网络启动时配置文件自动完成加载,无需管理员手工干预;
- 将日常运维网络的各种软件工具,以容器化的形式运行到开放网络操作系统中去,既提升了网络运维效率,又节省了网络运维的成本(不再需要部署软件工具的物理服务器);
- 将开源世界中的各种软件集成到现有的网络运维体系中去,并且将它们与网络操作系统紧密的融合在一起,创造出前所未有的网络运维方法;
- 甚至,网络管理员能够通过调用开放网络操作系统提供的各类API,在各种基础网络功能之上编制出符合自身业务需求的“新”网络功能/设备来,从而真正让“应用定义网络”;
- 更为重要的是,当园区网络与数据中心网络使用同一个网络操作系统时,将对网络运维带来运维效率提升、运维人员减少、设备备件统一等诸多便利之处。
4. 一网多用
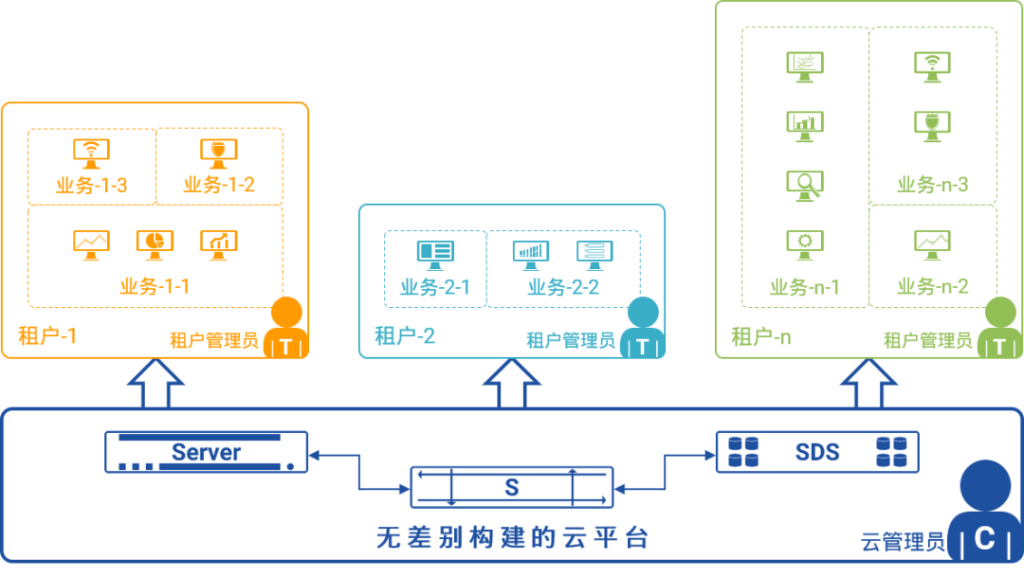
在同一张云网络的物理网络(Underlay)之上可以为不同的租户创建不同的虚拟网络(Overlay),从而实现“一张网络为多个租户服务、并且彼此隔离”的目的。在云化园区网络上,亦是如此,可以为不同的业务、不同的用户群创建彼此隔离的“逻辑网络”。

一网多用
在上图中,三种不同的业务(办公系统、业务系统和物联网)承载在同一张云化园区网络之上,云化园区网络提供了三张彼此隔离的逻辑网络为不同的业务服务,每种业务都认为自己被承载在一张专用的网络之上,无需感知其他逻辑网络的存在。
在云化园区网络之上创建这些彼此隔离的逻辑网络时,可以采用以下不同的方法:
- 完全复制云网络基于VXLAN(Virtual eXtensible Local Area Network,虚拟扩展局域网)的隔离方案,适用于超大规模、网络空间复杂且重叠的园区网络,是一种比较重的方案;
- 如果园区网络是扁平的地址空间,但是对路由隔离的要求比较严格,则可以利用VRF(Virtual Routing and Forwarding,虚拟路由与转发)的隔离性,将不同的逻辑网络隔离到多个不同的VRF中;相较于VXLAN方案,多VRF方案复杂度较低、开销较小;
- 如果园区网络是扁平的地址空间,并且规模较小、对隔离的要求仅限于对不同业务之间互通的访问控制,则可采用IP子网规划和ACL(Accessing Control List,访问控制列表)的组合,即可达成目标;相较于前两种方案,该方案基本不会带来额外的复杂度、开销约等于零,是最轻量的隔离方案。
- 因此,云化园区网络对多业务的支持采用的是“从大到小、越来越轻”的设计思路,可以支持接入从几十万终端到几十个终端不同规模的网络,并且采用越来越简单的逻辑隔离方案,降低部署与维护的复杂度。
下一篇我们将从园区网络的建设层面(路由、网关、广播风暴、园区网络安全、高可靠部署、园区漫游……)来继续探讨。
借鉴云数据中心网络的发展经验,星融元Asterfusion创新性地提出了新一代精简高效的云化园区网络架构。其中,型号丰富的CX-M系列主要作为接入或汇聚交换机,而高速率、高密度的CX-N系列作为汇聚和核心交换机。

-图-1-1024x201.jpg)
-图-2-1024x56.jpg)




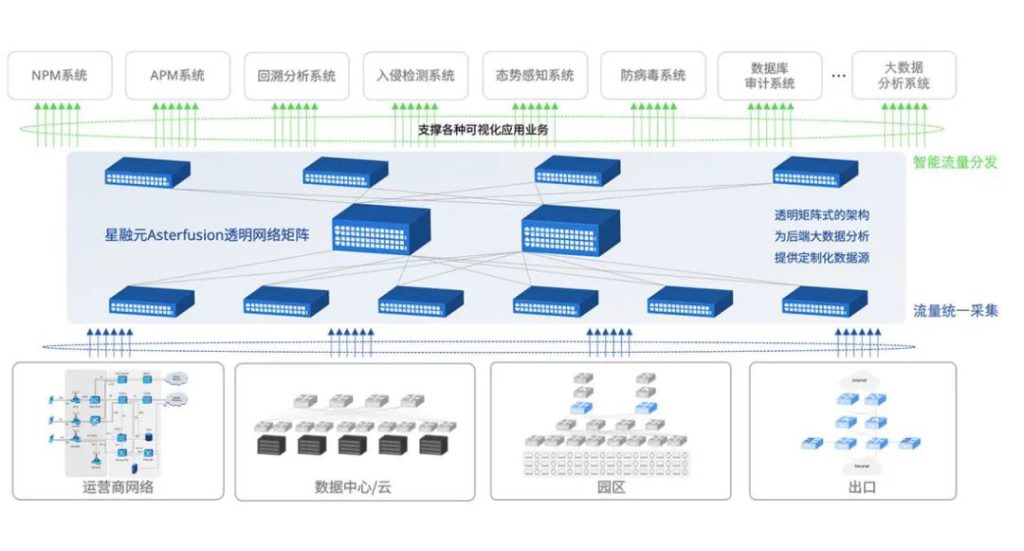
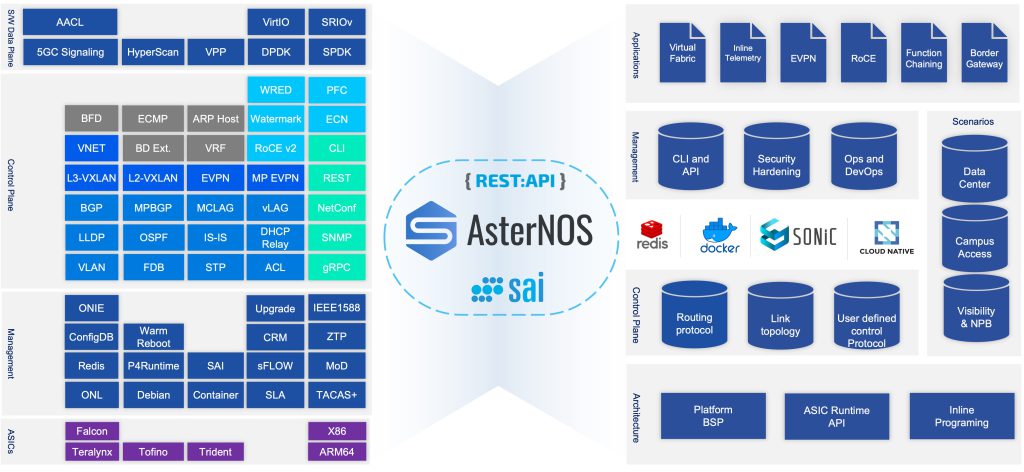

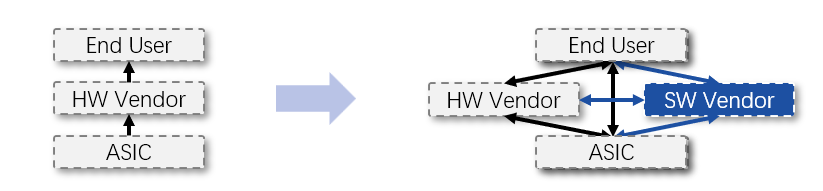



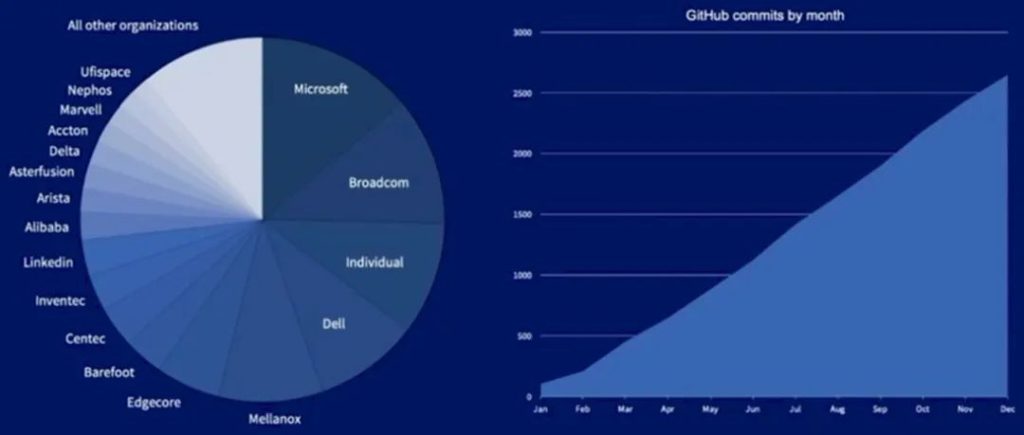

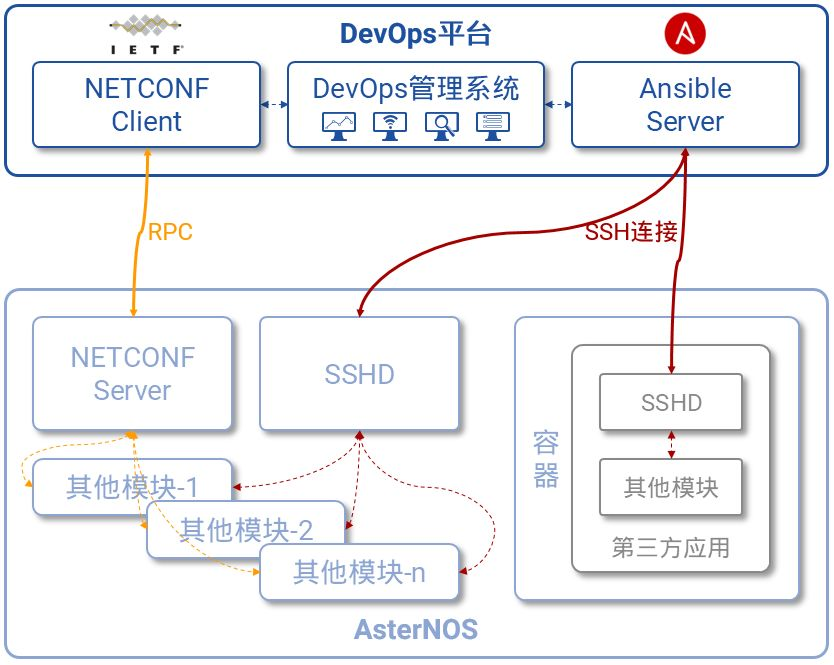
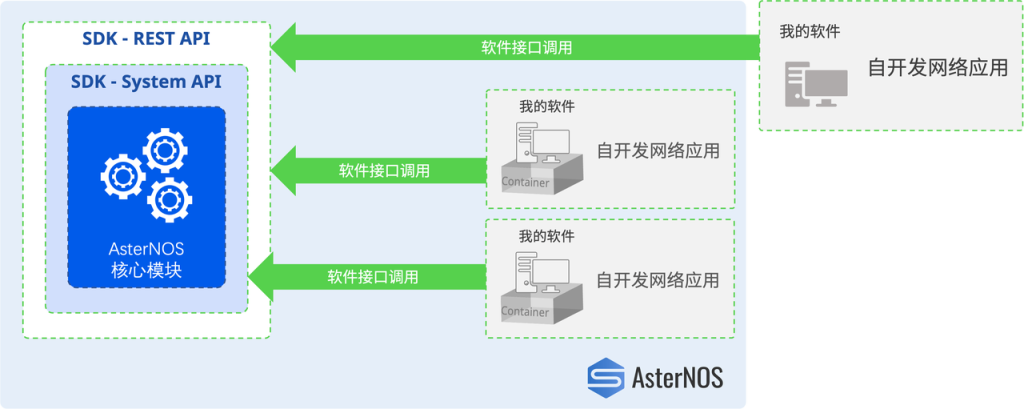




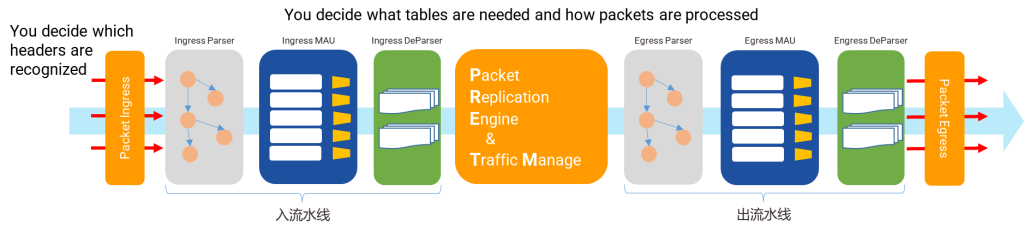
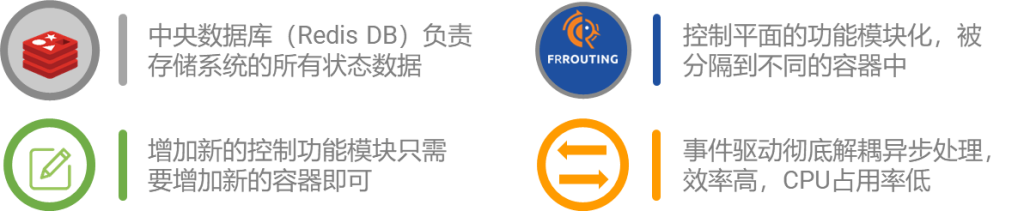
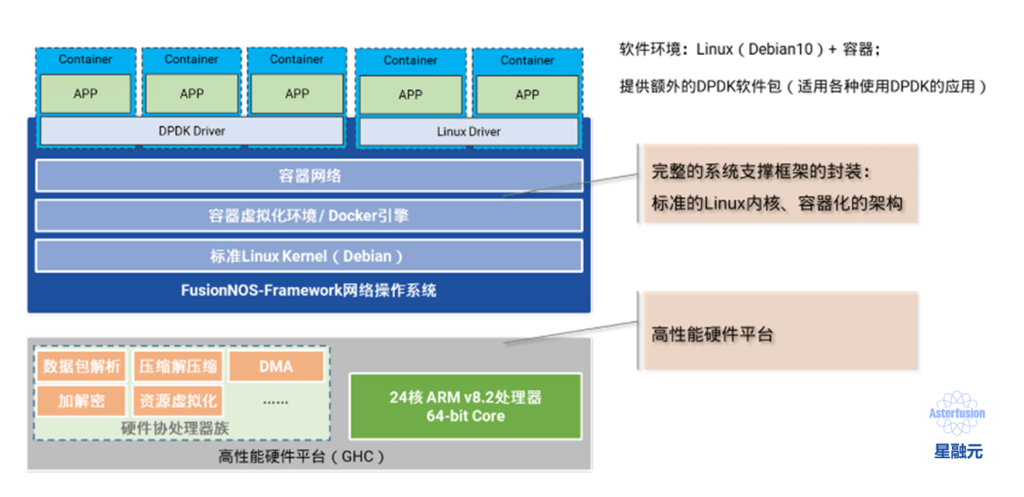








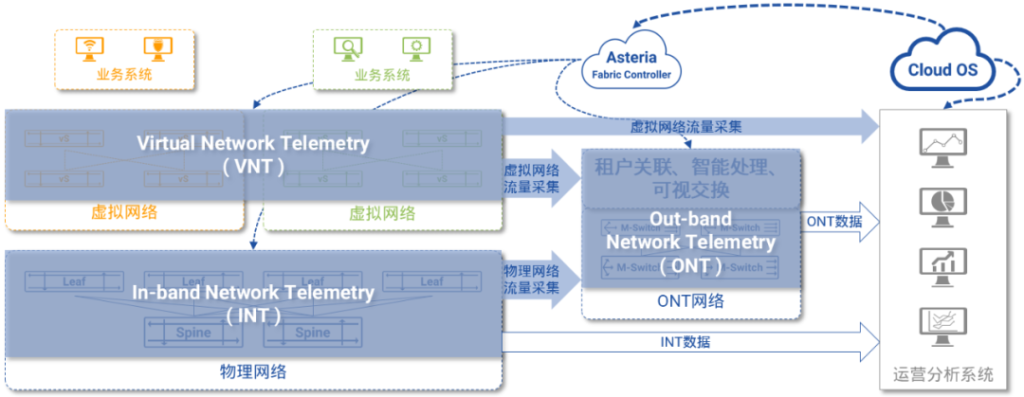
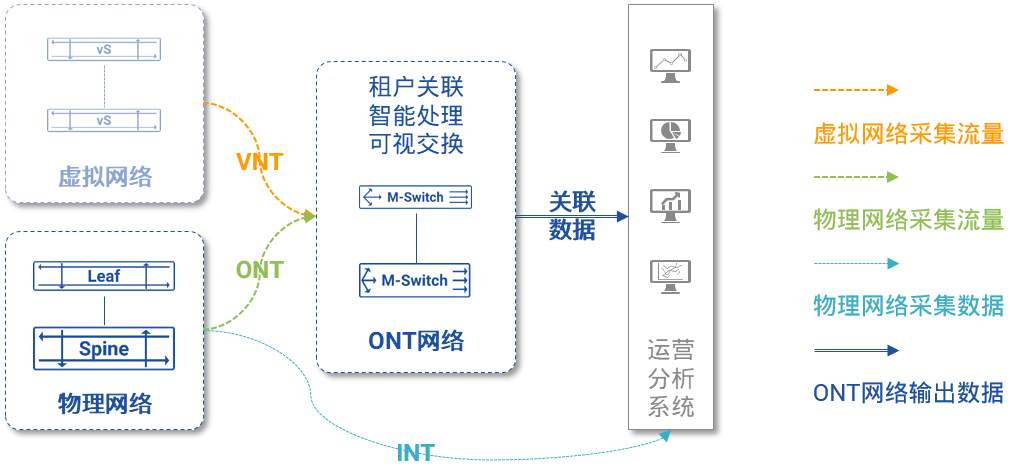
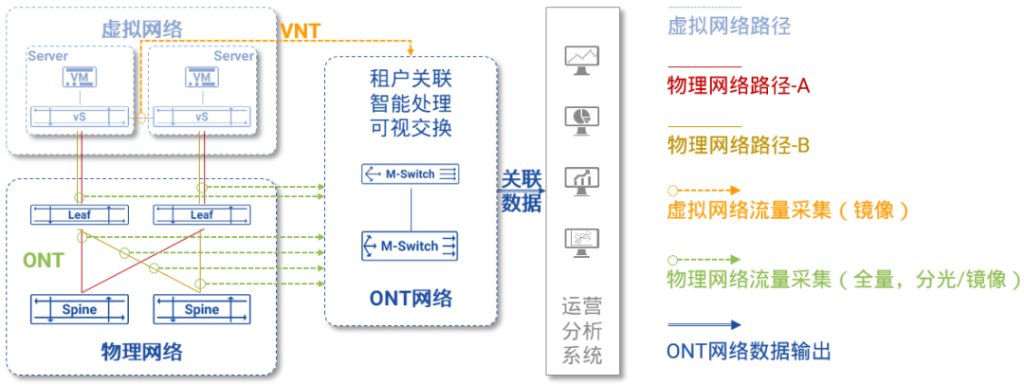
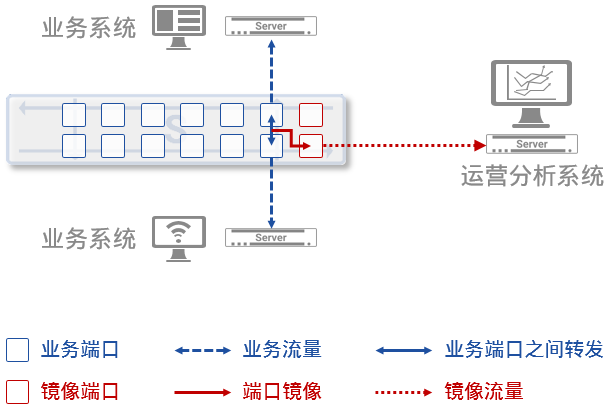
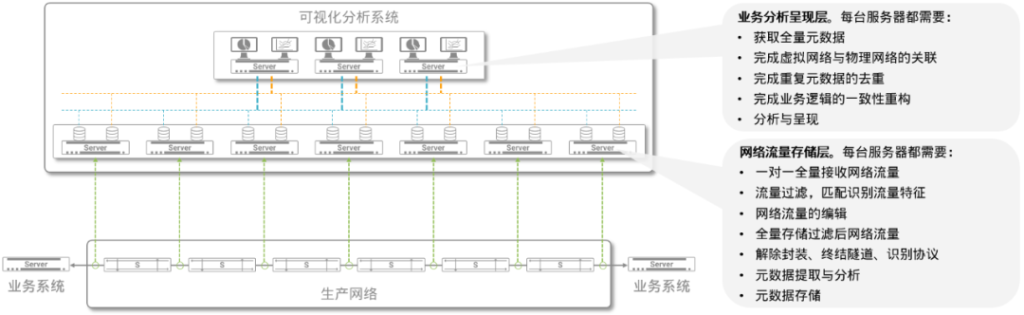
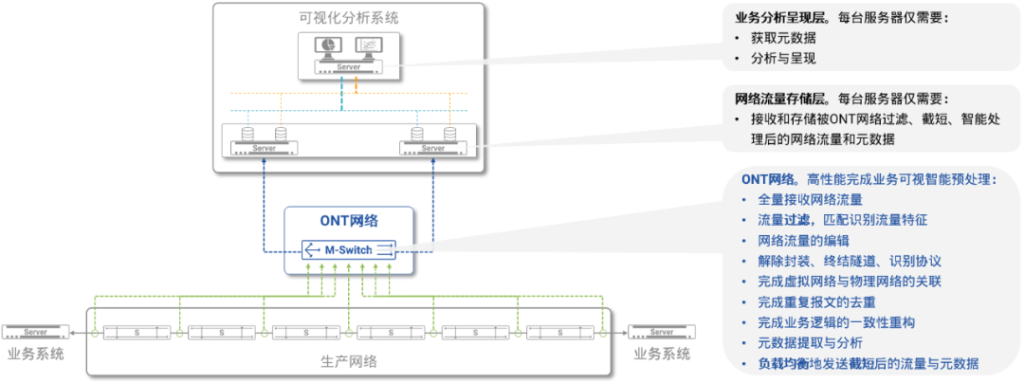
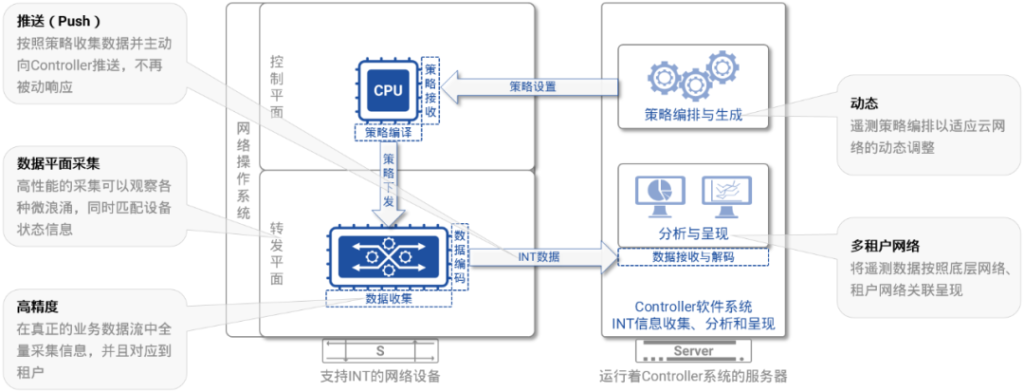 图5:INT的整体架构
图5:INT的整体架构