标签: 解决方案

数据库一体机场景下的RoCE组网方案实测报告
关注星融元

数据库一体机是一个集成了硬件和软件的设备,专门为数据库场景设计。
以下是数据库一体机的主要优势:
- 简化部署:由于硬件和软件都已经预先集成在一体机中,部署过程变得更加简单快捷。一体机通常会包括预安装的操作系统、数据库软件,以及存储和网络的软硬件。
- 优化性能:数据库一体机的硬件和软件都针对数据库管理进行了优化,组件之间的高度集成,让一体机可以实现更高的吞吐、更低的响应时延。
- 降低维护成本:数据库一体机的硬件和软件都经过了严格的测试和验证,确保各种场景下的稳定性,降低了故障发生的可能性,从而减少了维护成本。另外,还会提供统一的管理界面,使管理和维护变得更加简便。
过去,数据库一体机通常采用X86服务器和InfiniBand网络的硬件环境。然而,InfiniBand网络的部署和维护成本高昂,需要专门的硬件和管理技能。现在,RoCE网络可以提供与InfiniBand网络相当的性能。因此使用RoCE网络替代InfiniBand网络,可以降低成本、提高组网的灵活性和可扩展性,更容易地进行部署和运维。
星融元CX-N系列云交换机可谓是这个场景下所寻找的“梦中情机”,可以帮助用户构建不同规模、灵活、可靠、高品质的低时延RoCE网络,为数据库一体机业务提供卓越的网络服务。
组网方案
01、硬件信息
| 硬件项目 | 描述 | 数量 |
|---|---|---|
| 计算节点 | Dell PowerEdge R7525 CPU:2 x 18Cores 内存:8 x 32GB 网卡:2 x Mellanox ConnectX®-5 100GE | 2台 |
| 存储节点 | H3C UniServer R4900 G3 CPU:2 x 12Cores 内存:4 x 32GB 网卡:2 x Mellanox ConnectX®-5 100GE 数据盘:4 x 3.84TB NVMe SSD | 3台 |
| 管理节点 | Linux 虚拟机 | 1台 |
| 交换机 | Asterfusion CX532P-N(32 * 100GE) | 2台 |
02、组网拓扑
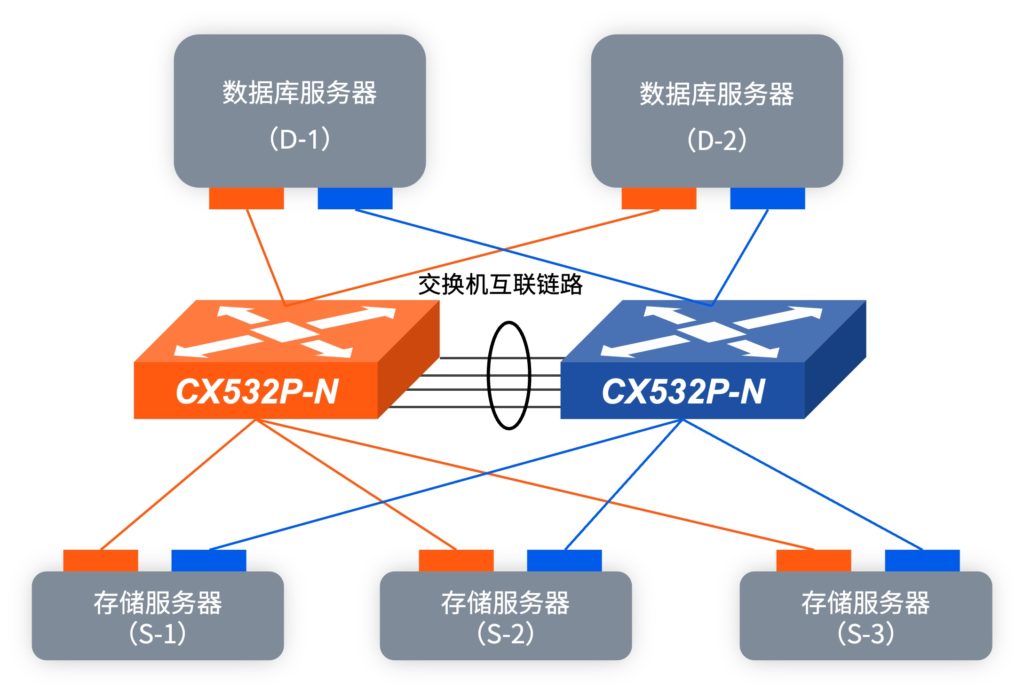
测试用例
01、RoCE组网与功能测试
RoCE组网测试
| 前提条件 | 1. 软硬件环境已准备完成 |
| 测试步骤 | 1. 业务网段1内RDMA流量互通 2. 业务网段2内RDMA流量互通 3. 两个网段跨网段RDMA流量互通 4. 管理网段流量互通 |
| 测试结果 | 所有测试均通过 |
数据库一体机功能测试
| 前提条件 | RoCE组网已完成 |
| 测试步骤 | 通过数据库一体机管理平台完成如下步骤: 1. 配置管理计算和存储节点 2. 创建存储资源 3. 给计算节点分配存储 4. 创建Oracle RAC数据库 |
| 测试结果 | 数据库创建成功,数据库实例运行正常 |
02、存储性能测试
| 前提条件 | 卷已映射至计算节点 |
| 测试步骤 | 通过FIO工具测试存储性能 |
| 测试结果 | 使用FIO完成存储性能测试,性能达到预期 |
存储性能测试结果
| 测试项 | 带宽(MB/s) | IOPS(万) | 延迟(毫秒) | IO深度 | 单卷JOB数 |
|---|---|---|---|---|---|
| 8k随机读 | 14271 | 182.7 | 0.4 | 8 | 2 |
| 1M顺序读 | 17767 | 17.7 | / | / | / |
03、高可用测试
| 前提条件 | 卷已映射至计算节点 |
| 测试步骤 | 1. 使用FIO对计算节点上挂载的存储卷进行压测 2. 拔掉任意节点上其中一个网口的线缆 3. 拔掉交换机互联链路的任意一根线缆 4. 重启一台交换机 5. 断电一台交换机 |
| 测试结果 | 分别进行2~5步骤操作,IO恢复的时间不超过10s,高可用测试通过。 |
测试结论
本次测试完成了组网方案的可用性测试、存储性能测试,以及高可用测试,经过多场景验证,结论如下:
- 数据库一体机通过使用星融元CX532P-N超低时延云交换机,成功实现了从IB组网方案向RoCE方案的切换
- 同样的配置下,性能与IB媲美 ,实测存储性能为IOPS:8K随机读189万,带宽:18GB/s
- 数据库一体机系统各项功能正常,测试通过
- 高可用场景测试通过
更多关于CX-N产品的测试报告,请持续关注星融元官方网站。
相关文章
私有云网络的进化之路:与开放网络技术的完美融合
关注星融元
随着整个社会数字化转型的持续推进 ,金融、政府、新能源、电信、科研为代表的行业对私有云服务的需求不断增加。然而传统数据中心网络在承载当今规模不断增长、业务模型不断变化的云计算业务时,不可避免会遇到以下挑战:
- 转发性能瓶颈:传统数据中心网络无法为分布式系统架构、HPC或存储业务提供扁平收敛、无损转发等高性能网络服务
- 功能扩展受限:面对新开发需求时,设备功能拓展往往受到网络设备产品封闭架构的限制,开发难度大
- 部署运维低效:网络开局部署周期长、日常监控手段粗糙,难以对网络进行实时、全面、精细的运维
如何应对业务对网络需求的不断变化,私有云网络解决方案需要不断进化。星融元作为国内专业的开放网络提供商,将开放网络技术融合到私有云网络中推出了全新一代的私有云网络解决方案,以帮助企业更好地应对这些变化。

星融元私有云承载网络解决方案
私有云网络方案架构
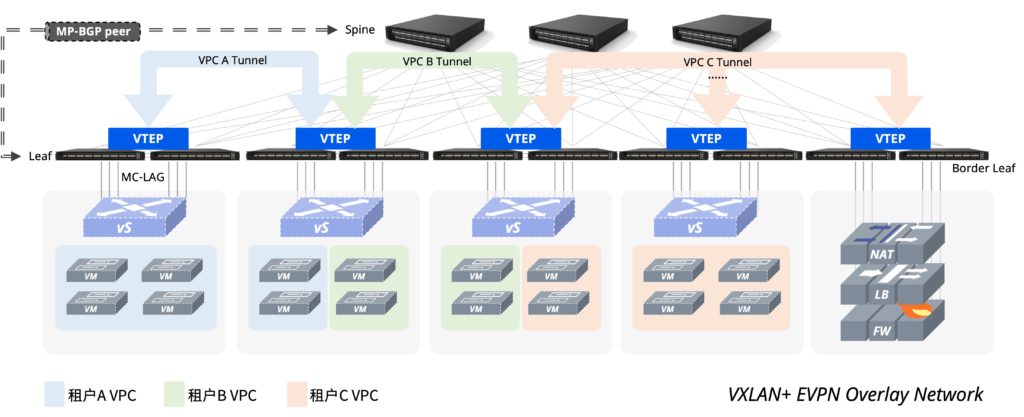
- Leaf层采用MC-LAG(Multi-Chassis Link Aggregation Group,跨设备链路聚合组)、ARP转主机路由等技术实现去堆叠主机双上行接入
- Spine-Leaf设备在Underlay层面EBGP互联并开启ECMP(Equal-cost multi-path,等价多路径路由)对流量进行负载
- Spine-Leaf之间创建MP-BGP peer,传递EVPN路由信息,采用VXLAN/EVPN技术实现网络Overlay承载方案
- VXLAN隧道通过EVPN路由自动完成建立并关联相同的VNI(VXLAN Network Identifier,VXLAN网络标识符),VPC(Virtual Private Cloud,虚拟私有云)内部的VLAN与本VPC的VNI在Leaf设备上建立映射,虚机的MAC和主机路由信息由EVPN在整个Pod内自动完成同步
- 单个Pod最大可支持10W+虚机条目
私有云方案特点
全盒式设备CLOS组网
星融元私有云网络解决方案采用星融元CX-N系列全盒式设备构建CLOS架构网络,单Pod采用CX308P-48Y-N与CX532P-N或CX564P-N型号组合可以支持大多数中小规模的私有云场景;同时还可以利用CX-N系列交换机构建二级正交CLOS网络进行多Pod扩展,以实现更大规模的网络接入能力;结合BGP等价路由负载、MC-LAG、Monitor-Link联动等技术实现接入层和汇聚层的高可靠保护机制。

Underlay网络零配置开局
CX-N系列交换机支持ZTP(Zero Touch Provisioning,零配置部署)功能,可以通过DHCP可选字段获取配置文件路径信息,从文件服务器获取配置文件,并自动加载,实现私有云网络方案中Underlay网络的零配置开局,降低方案开局配置操作的工作量,缩短业务上线时间。
DCB流控技术实现低时延无损网络
星融元私有云网络解决方案支持在CX-N系列低时延交换机上开启DCB(Data Center Bridge,数据中心桥接)流控功能,包括:PFC(Priority-based Flow Control,基于队列的流量控制)、ECN(Explicit Congestion Notification,显式拥塞通知)、ETS(Enhanced Transmission Selection,增强型传输选择)等技术,可构建“低时延、零丢包、高性能、低成本”的CEE(Converged Enhanced Ethernet,融合增强型以太网)来满足分布式存储、高性能计算等不同业务场景对数据中心网络提出的不同需求。

开放REST API对接云管、业务智能调度
星融元私有云网络解决方案中的CX-N系列交换机通过REST API将自身的网络能力全部开放出来,与用户的第三方控制器进行无缝对接,实现私有云网络在用户云管平台上的软件定义、弹性调度、按需扩展,实现业务的自动化开通部署,帮助用户减少了设备配置的复杂度,提高业务的上线、变更效率。
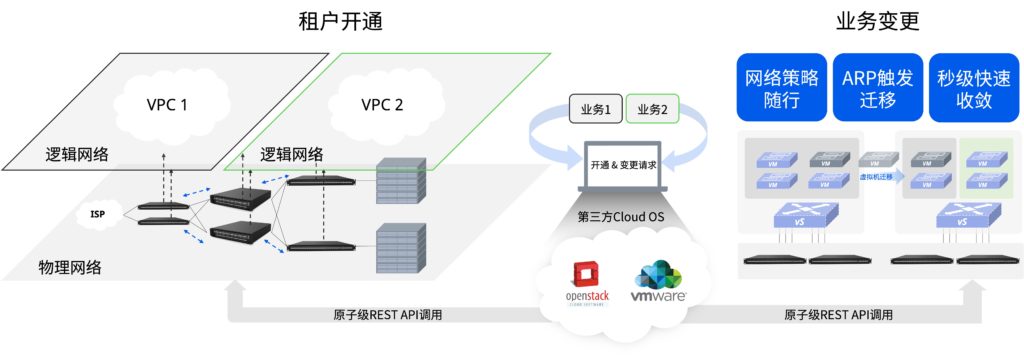
CX-N全开放NOS支持组件灵活开发与集成
CX-N系列交换机搭载的AsterNOS是星融元为云计算业务场景设计开发的一款全开放、高性能、高可靠、功能易扩展的云网操作系统。
采用了标准的Linux内核、开放的容器化架构,并向最终用户提供系统集成环境与开发套件,支持用户将运营经验工具化的插件、新业务功能模块集成部署在AsterNOS之上,提升最终用户网络管控的效率以及满足新业务场景对网络功能的需求。

INT带内遥测实时监控网络健康
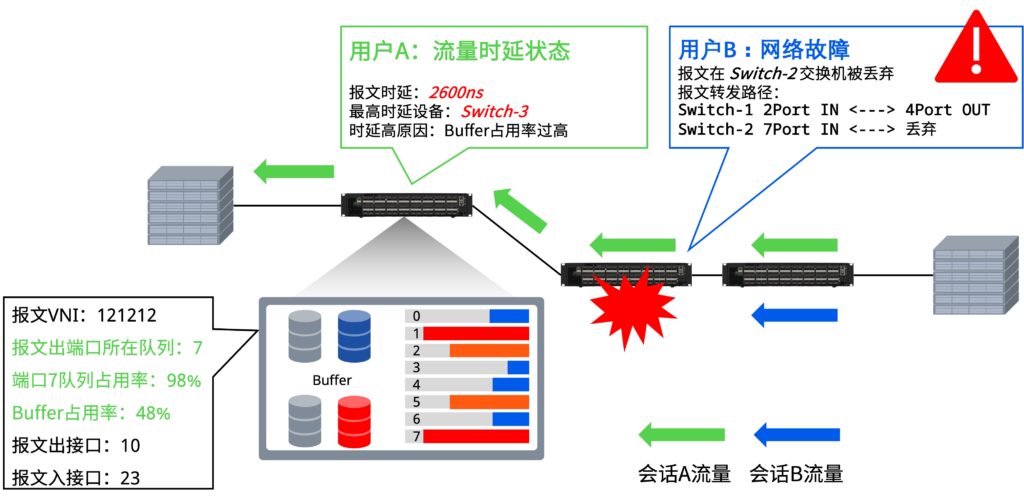
CX-N系列交换机提供了INT(In-band Network Telemetry,带内网络遥测)功能,为网络分析平台提供实时、精细、准确和全面的网络遥测数据(包括出入接口、时间戳、延迟、队列长度等),并且全部由交换芯片实现,无需管理CPU参与。
基于INT技术的主动推送特性,可将数据转发至网络分析平台,能够精准感知到网络设备纳秒级别的故障信息,网络路径健康状态清晰可视,可以为用户打造一个全网健康状态可见的智能网络,减少因传统监控手段不足而发生的网络故障,降低网络运维难度和运营成本。
相关文章
讲座精华 | 深度分享星融元开源DPU技术与应用场景
关注星融元
DPU(数据处理单元)作为继CPU和GPU之后的的第三颗主力芯片,所解决的核心问题是帮助数据中心基础设施“降本增效”——将“CPU处理效率低下、GPU处理不了”的负载卸载到DPU上。DPU不仅可以作为运算的加速引擎,还具备控制平面的功能,能够运行Hypervisor,更高效地完成网络虚拟化、IO虚拟化、存储虚拟化等任务,彻底将CPU的算力释放给应用程序,提升数据中心的有效算力。
近日,星融元数据联合智东西推出了主题为“开源DPU技术与应用场景”的技术公开课。星融元DPU技术负责人张敏以线上直播的形式,面向DPU开发从业者以及对相关技术感兴趣的各界人士,介绍了 Helium DPU产品开源的目的和进展、软硬件架构以及几大典型应用场景。现将直播要点整理如下,欢迎更多同仁与我们交流。

主讲人介绍
张敏 星融元DPU技术负责人
北京理工大学硕士,拥有10多年的多核开发经验,平台包括Marvell,Cavium、NPS、intel等;同时,在DPI、探针、2G/3G/4G/5G移动信令分析、NPB等领域也有着丰富的开发经验,曾主导过多个面向金融、运营商、安全等行业的千万级开发项目。
01 开源的目的与进展
构建开放网络是星融元一直坚持的理念,我们深知开源的力量。
开源模式有助于以市场自然选择的方式实现最优的发展路径:一方面广大社区里的广大开发者可以帮助检查软件代码漏洞,另一方面我们也能借助平台帮助DPU行业的技术人员快速地解决问题。
更重要的是,在创意的碰撞和交流过程中共同进步,一同探索新场景实现产品快速迭代。
目前星融元已将所有DPU产品开源到Github上,提供已验证的应用场景以及对应的软硬件技术实现,接下来也将不断更新提交,预计将于2023年11月推出下一代DPU产品。
相关阅读:这款国产高性能DPU智能网卡,即将开源!

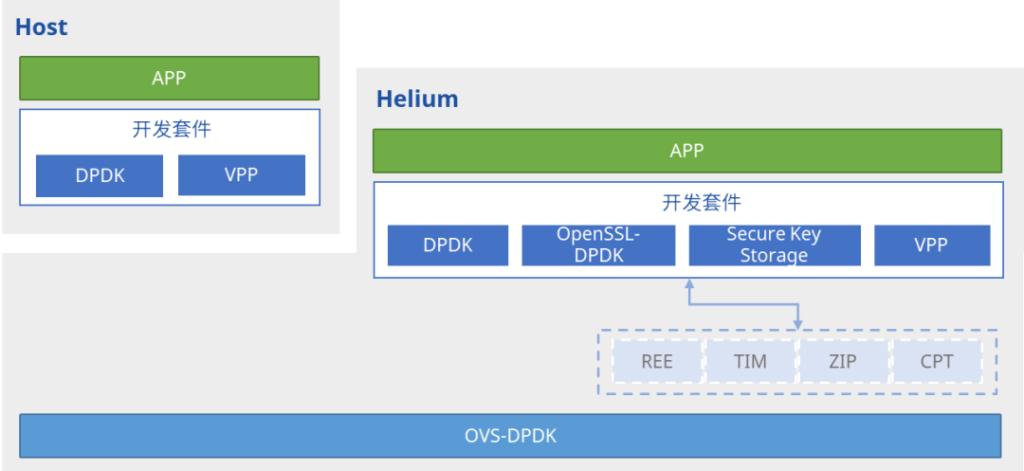
02 Helium DPU卡的硬件架构
我们可以结合下图来了解Helium的硬件架构,整个DPU卡是由24个ARM核和一些用于网络处理的重要硬件模块组成的。因公开课时间有限,张敏重点介绍了用于流量解析和分类的Network Parser和用于流量调度的Scheduler模块。
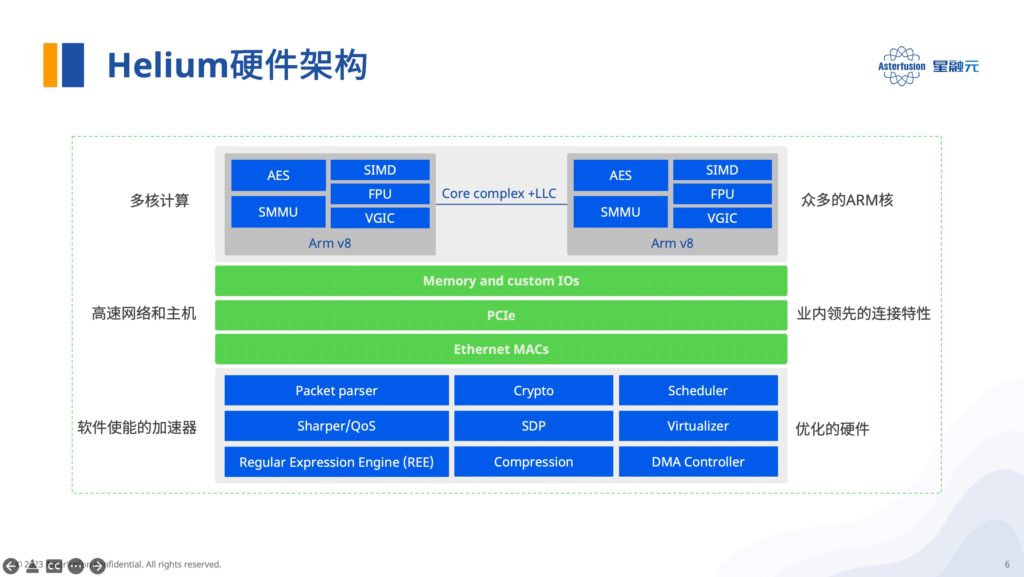
Network Parser主要实现自定义报文的快速解析和对内层复杂报文的深度解析(参考下图),而Scheduler模块的报文调度处理能力,可以将接收到的报文分配到不同的工作队列,对应到DPDK里,即是将报文分配到不同的RX queues与各个核心绑定。

值得一提的是,Scheduler可以支持将一条五元组相同流的不同报文分发到多个核心,这种特性十分适合应对数据中心常见的”大象流”和”老鼠流”问题——在网络突发大流量情况下,”大象流”的数据仍然可以负载均衡到多核心处理,由此避免了因单核处理导致的性能瓶颈,以及”老鼠流”的丢包现象。
此外,Helium DPU 还有用于DPI(深度报文检测)和加速虚拟化管理的模块等等,感兴趣的读者可自行前往产品的开源页面查看。
开源地址:https://github.com/asterfusion/Helium_DPU
03 一站式的综合开发环境——FusionNOS-Framework
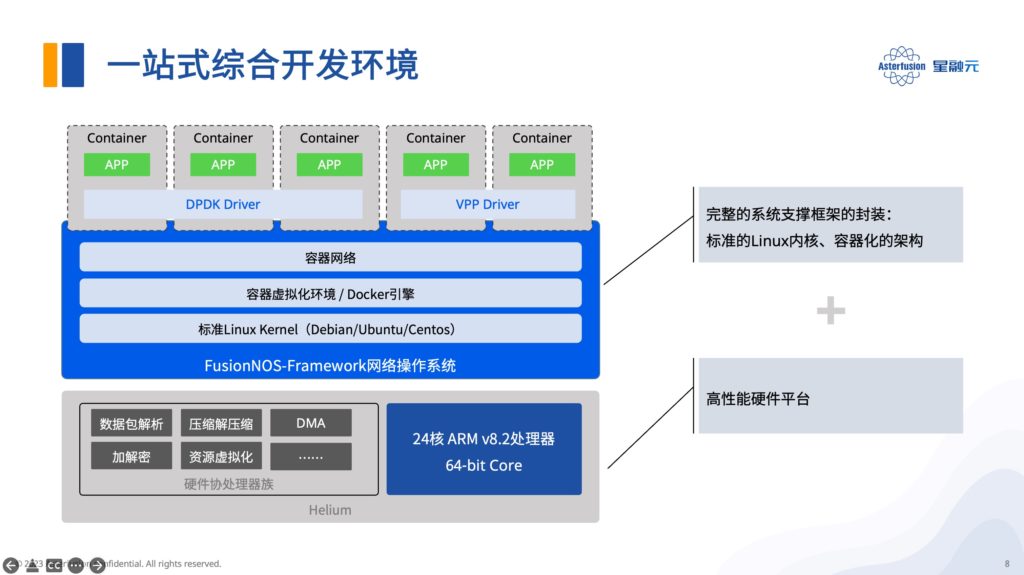
Helium 所提供的软件开发套件(FusionNOS-Framework)包括三大部分。
- 一、标准的Linux内核,方便开发者安装应用相关的各种依赖,并且有大量可选的软件源。
- 二、容器化的架构。我们可以打包运行环境和依赖到一个可移植的镜像中,实现轻量的资源隔离,做到一次编译,随处运行,并且每个实例的初始状态皆是一致的。
- 三、额外提供的DPDK和VPP开发套件,加速软件快速移植,用户也可以很方便去拓展自己的应用。
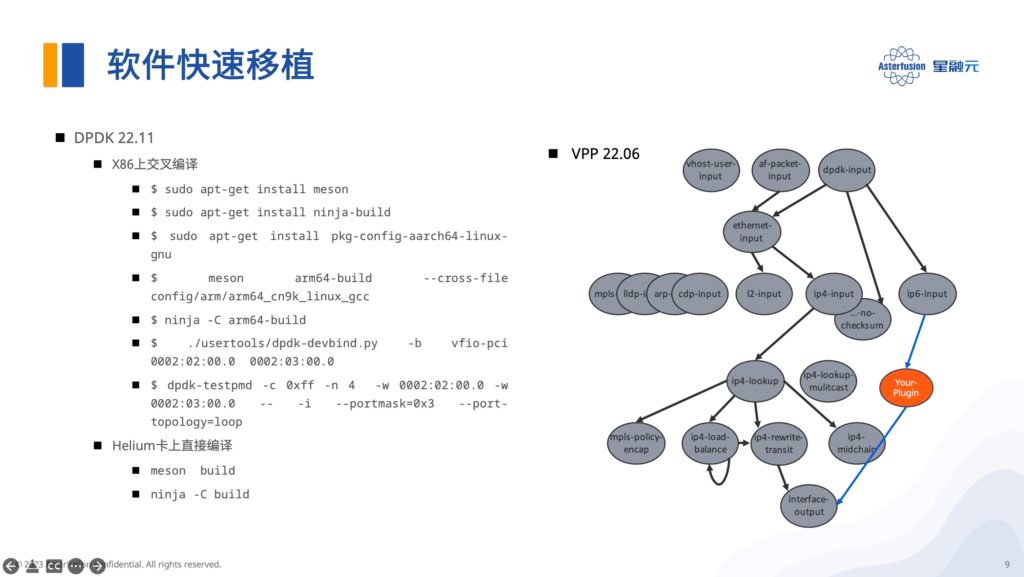
DPDK开发套件
目前星融元DPU开发团队上传在Github的是DPDK 22.11版本,它既可以在x86平台上交叉编译,也可以直接在DPU卡上编译;编译完成,只需配置大页内存并绑定接口,启动DPDK应用程序后即可开始收发包处理。
22.11以后的版本已支持P4 DPDK,这意味着Helium上完全可以运行P4程序,让交换机的流水线在DPU上跑起来。
VPP开发套件
VPP开发套件主要有以下三大特性:
- 矢量运算:单个指令,多个数据并行处理
- plugins机制:支持启动时动态加载自己开发的plugins
- node机制:支持图形化展示各个节点的处理关系
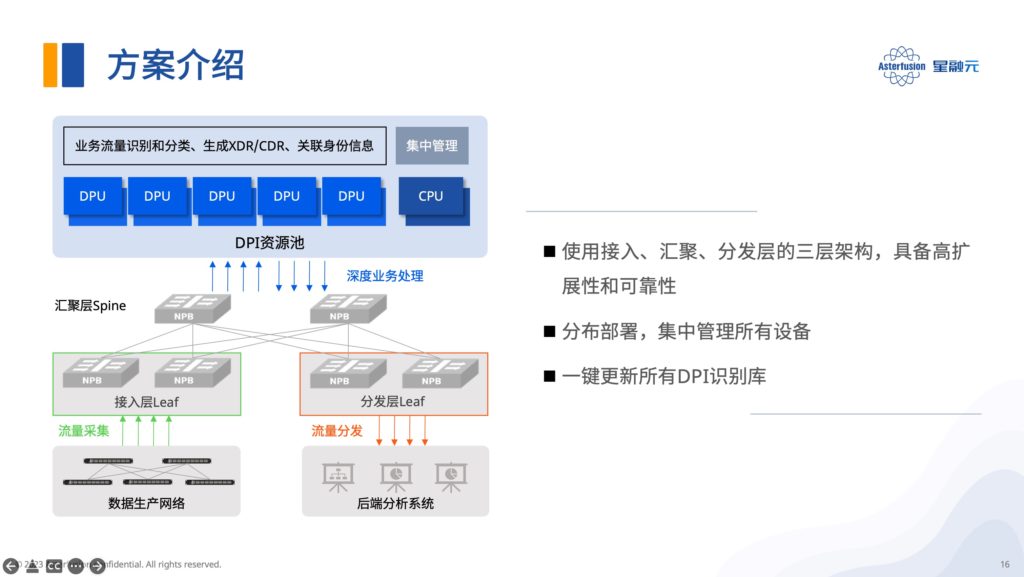
04 基于DPU池化方案的典型应用场景
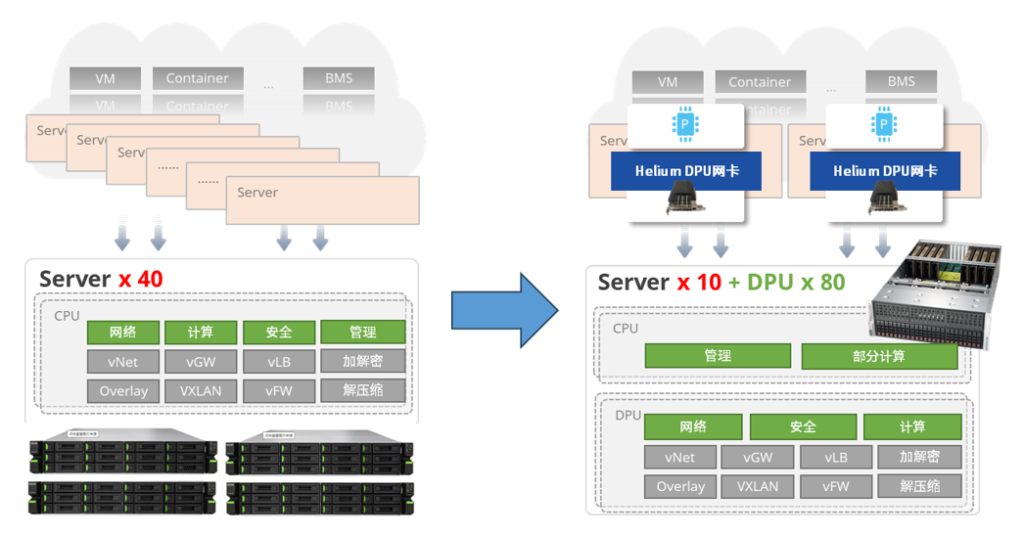
星融元DPU的算力池方案的核心思想是采用标准服务器+多块Helium DPU卡的形式,将原本独立部署在各个服务器的网络功能池化到各块DPU卡上,进而实现优化资源分配,简化运维管理的目标。
以DPI(深度报文检测)为例,通过Helium DPU资源池可以加速对业务报文的深度解析,识别出不同类型的流(视频、音频、网页流…);借助复杂的特征提取和匹配模块,这种分类可以精确到具体的应用类型(比如某平台的视频流等等)。该方案支持分布部署、集中管理,一键更新所有DPI识别库。
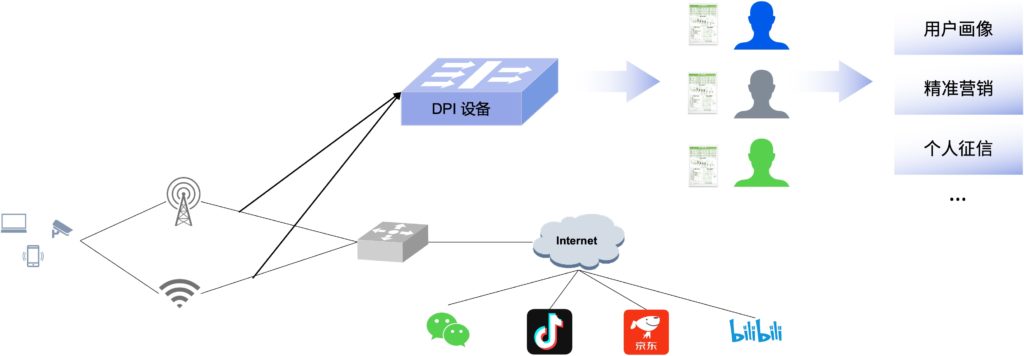
到了边缘云场景,DPU池化方案亦可帮助节约机架空间,便于机房电源管理,降低机房建设和能耗成本超50%。
相关文章
MC-LAG还是Multi-Homing?探讨网络通信高可用性的新选择
关注星融元
随着人工智能、大语言模型、AI学习等热点应用程序的不断涌现,对网络通信的可靠性、性能和灵活性提出了更高的要求。在这个背景下,EVPN Multi-homing技术备受关注,因为它可以提供更高效、更可靠的网络通信解决方案,满足这些热点应用程序的要求。
EVPN Multi-Homing是指在使用以太网VPN(Ethernet VPN,EVPN)技术构建的数据中心网络中,使用多个物理链路和IP地址来实现冗余和负载均衡的技术。在EVPN Multi-Homing中,每个用户可以使用多个物理链路来与数据中心网络进行连接,这些链路可以来自不同的交换机。当一个链路或设备发生故障时,可以自动切换到备用链路或设备,保证数据中心网络的可用性。也可以通过负载均衡的方式,将网络流量分配到多个链路或地址中,提高网络性能和效率。
从堆叠到MC-LAG再到Multi-Homing,网络高可用性演进之路
在网络通信发展的早期,服务器和其他网络设备通常会直接连接到单个接入交换机。然而,如果该交换机或端口发生故障,将导致设备无法连接到网络,从而影响业务。此外,如果该链路或端口的性能达到极限,将无法处理更多的流量,这会导致网络性能下降。为了提高网络的可靠性和可用性,出现了堆叠,即将多个网络设备堆叠在一起,一台服务器或其他网络设备可以连接到多台堆叠设备。堆叠设备能够通过单一的管理平面进行管理和控制,从而增强了网络容量和可扩展性,并简化了网络部署和管理。然而,堆叠设备的控制平面是单一的,因此如果出现故障,可能会影响整个堆叠系统,扩散到连接的所有设备。此外,升级和替换可能会对业务产生影响,因此在容错性和灵活性方面具有一定的局限性。
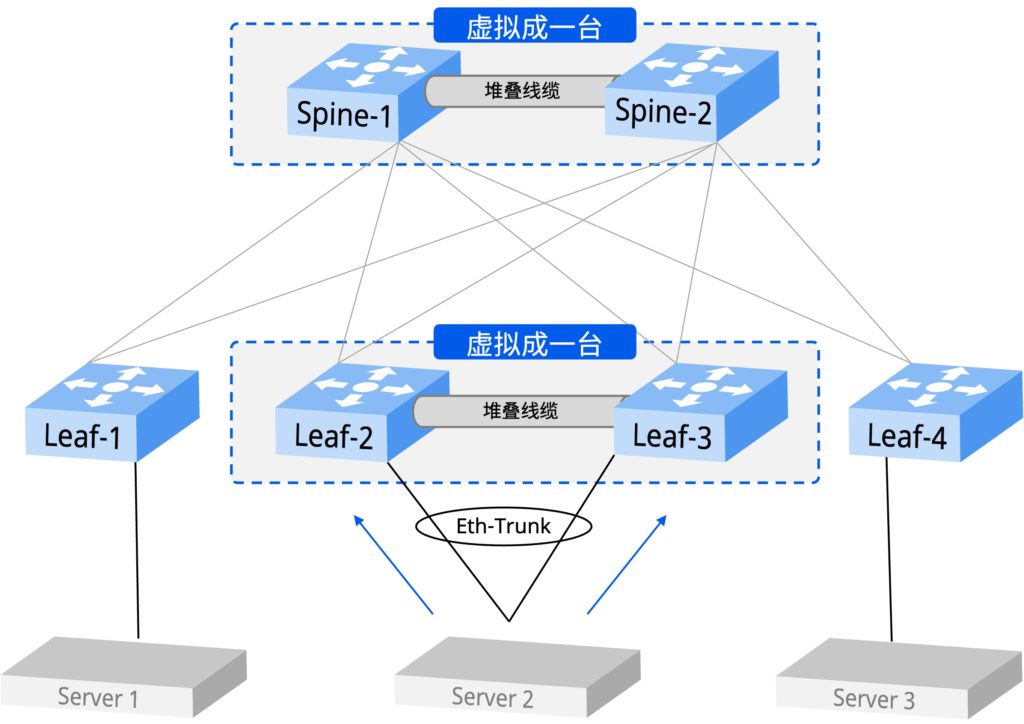
图1:堆叠方案
为了满足用户网络对灵活性以及更高可靠性的需求,堆叠逐渐被MC-LAG所取代。
MC-LAG同样支持一台服务器或其他网络设备连接到两台MC-LAG设备。区别于堆叠,MC-LAG在提供统一转发面的同时控制面板是独立的,因此,能够轻松地添加或删除物理连接,与堆叠相比,它具备了更高的可靠性以及灵活性,能够更好地满足用户需求。
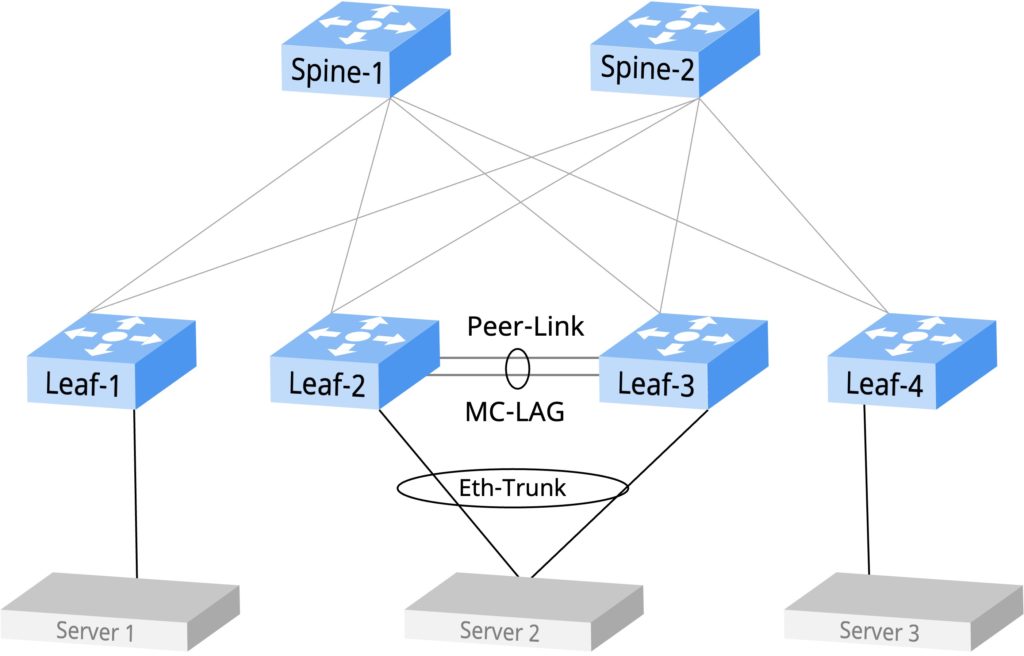
图2:MC-LAG方案
但是随着业务的不断发展,用户对网络需求不断增加,在VXLAN 网络Overlay场景中,MC-LAG不足也逐渐出现:
- ✘ MC-LAG设备之间需要互联链路来占用端口,这导致了端口/链路资源的浪费。同时,这种互联链路的存在也增加了网络的复杂性,使得网络管理和维护变得更加困难。
- ✘ 在一些应用场景中,需要保证两台以上的Leaf设备的冗余性。然而,MC-LAG双归接入可靠性方案只支持双归,无法满足多归的需求,因此其可扩展性存在一定的局限性,无法满足这些应用场景的需要。
- ✘ MC-LAG协议没有统一标准,不同厂商设备之间可能存在实现差异,可能会导致不同设备之间无法互相兼容,从而限制了网络的可扩展性和互操作性。
相较于MC-LAG双归接入可靠性方案,EVPN Multi-Homing是一种按照RFC标准定义的VXLAN网关多归方案。
它通过多台VTEP组成冗余备份组来实现对VTEP单点故障的容错和流量负载分担。与MC-LAG方案相比,EVPN Multi-Homing不仅可以更好地解决MC-LAG方案在可扩展性和流量负载均衡方面的局限性,还能够提高VXLAN接入侧的可靠性。
因此,在需要高可靠性和高可扩展性的场景下,EVPN Multi-Homing可能是更为优秀的选择。
EVPN Multi-Homing的特点:
- 无需在TOR交换机之间建立Peer link链路或交换机间链路,这是因为EVPN Multi-Homing方案可以通过多台VTEP组成冗余备份组来实现对TOR交换机的冗余支持,从而避免了在TOR交换机之间建立额外的链路所带来的复杂性和成本。
- 允许两个以上TOR交换机成为一个冗余组,从而可以更好地适应不同规模和复杂度的网络环境。同时,通过EVPN Multi-Homing方案的流量负载分担机制,可以实现更加均衡的网络流量分配,提高网络的性能和稳定性。
- 允许多供应商互操作性,EVPN Multi-Homing是按照RFC标准定义的一种VXLAN网关多归方案,具有良好的标准化程度和兼容性。用户可以在不同厂商之间自由选择,并且不需要担心不同厂商设备之间的兼容性问题,从而在降低部署和维护成本。
星融元Multi-Homing方案
EVPN Multi-Homing设计思路
- 配置多个物理VM和物理链路:在物理网络中配置多个物理VM和物理链路,每个物理VM都连接到不同的物理链路上。
- 配置VXLAN隧道和VLAN:在物理网络中配置VXLAN隧道和VLAN,将不同的虚拟机隔离开来。每个虚拟机都分配一个独立的VLAN和IP地址,可以在隧道中传输自己的数据和服务,并保证虚拟机之间的隔离性和安全性。
- 配置BGP EVPN协议:在物理网络中配置BGP EVPN协议,将每个虚拟机的MAC地址和IP地址信息作为一个独立的BGP EVPN路由广播出去。每个物理VM都会学习到虚拟机的路由信息,并将其用于网络的转发和路由。
- 监测链路故障:EVPN Multi-Homing会定期监测每个物理链路的状态,一旦某个链路故障,即可进行链路/设备切换。
- 自动更新路由信息:当虚拟机迁移到其他物理VM上时,EVPN Multi-Homing会自动更新虚拟机的MAC地址和IP地址信息,并将其作为一个新的BGP EVPN路由广播到所有物理链路上。这可以保证网络设备自动更新路由表和ARP表,实现虚拟机的自动故障转移。
EVPN Multi-Homing方案介绍
星融元 EVPN Multi-Homing方案,采用Spine-Leaf弹性易扩展架构,通过BGP EVPN、VXLAN等技术,将云中租户的虚拟网络和分布式网络功能网关被从计算空间中卸载出来,直接承载在CX-N交换机之上,让这部分被释放的VM计算力可以用于创建/承载更多业务的虚拟计算节点,从而提高CPU计算力的使用效率。
区别于MC-LAG方案,EVPN Multi-Homing使用EVPN消息与宿主机进行通信,利用主机连接信息动态建立与VM的关系,从而提供多归VM冗余支持。并且,冗余设备之间无需互连线,节省了端口和线缆的同时简化了网络结构。
此外,EVPN底层采用了开放标准协议BGP实现冗余,这意味着任何遵循RFC规范实现EVPN Multi-Homing的供应商都可以成为以太网段的一部分,提高了网络的互通性和灵活性。
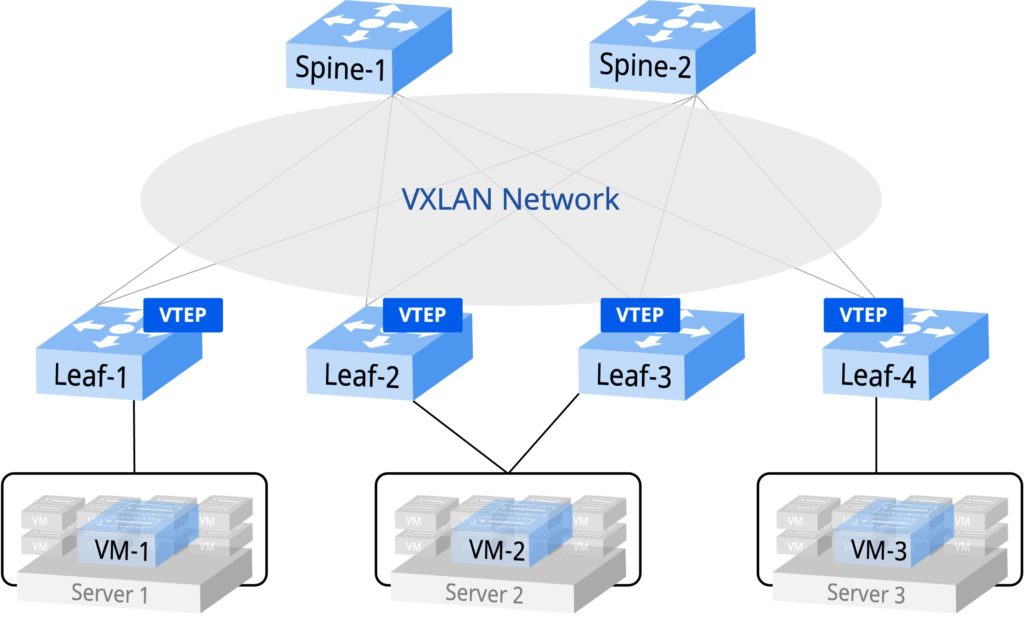
图3:多归接入
方案价值
EVPN Multi-Homing技术在网络架构设计中可以提高网络可靠性和容错能力、优化网络负载均衡、简化网络设计和管理、支持业务的高可用性和可用性SLA、以及支持虚拟化和云计算等方面作用:
提高网络可靠性和容错能力
EVPN Multi-Homing技术可以实现网络的多路径备份,从而提高网络的可靠性和容错能力。在网络出现故障或者链路故障时,EVPN Multi-Homing技术可以迅速切换到备用路径,保证网络的正常运行。
优化网络负载均衡
EVPN Multi-Homing技术可以实现流量的负载均衡,将流量均匀地分布到多个路径上,避免单一路径负载过重,从而提高网络的性能和吞吐量。
简化网络设计和管理
EVPN Multi-Homing技术可以简化网络架构和管理,冗余设备之间无需多余的端口和链路,可以简化架构,降低网络的成本和维护难度。
支持业务的高可用性和可用性SLA
EVPN Multi-Homing技术可以提供更高的业务可用性和可用性SLA,确保关键应用的高可用性,从而保证业务的平稳运行。
支持虚拟化和云计算
EVPN Multi-Homing技术可以支持虚拟化和云计算环境下的网络架构,可以提供虚拟机的多路径备份和负载均衡,保证虚拟机的高可用性和性能。
请注册/登录后获取完整Multi-homing验证方案:https://asterfusion.com/d-multi-homing-verification-scheme/
相关文章
基于开源DPU资源池,破解边缘云算力扩展难题
关注星融元
边缘云计算面临的困境
5G时代下基础网络设施的现代化改造势在必行,这包括简化运维,提高网络灵活性、可用性、可靠性和扩展性,减少延迟和优化应用响应时间等等。其中,边缘云计算的部署是一大重点——结合网络虚拟化技术把工作负载和服务从核心网络(位于数据中心内)移向网络边缘,一方面可以利用延迟降低的优势,改善现有应用的体验,对于网络运营方而言也便于新业务的灵活部署和统一管理。
随着业务规模快速增长,边缘场景下有限空间资源内的算力扩展成为了不可忽视的问题。边缘机房的CPU开销暴增,但机房的供电和散热能力有限,无法像数据中心一样通过大量新增服务器提升算力。
如何扩展边缘云算力?
星融元的Helium DPU智能网卡为边缘云算力扩展难题提供了一个解决思路:提高单位空间的算力上限。
通过给X86服务器加装DPU智能网卡,将服务器上的网络应用功能卸载到DPU网卡上,并结合网卡的硬件加速引擎进行业务加速(例如深度解析业务报文,对音视频、网页数据进行流分类),在有限的机架空间内低成本地灵活扩展算力。

并且,多块DPU网卡存储的数据可通过PCIe共享到同一台服务器,以标准服务器+DPU的 “算力资源池” 形式接受云管平台纳管,实现”从云到边”的资源统一管理和分配。
当前,星融元已将Helium DPU智能网卡的软件和场景开源,欢迎各位行业伙伴与我们共创生态。
相关阅读:这款国产高性能DPU智能网卡,即将开源!
开源地址:https://github.com/asterfusion/Helium_DPU

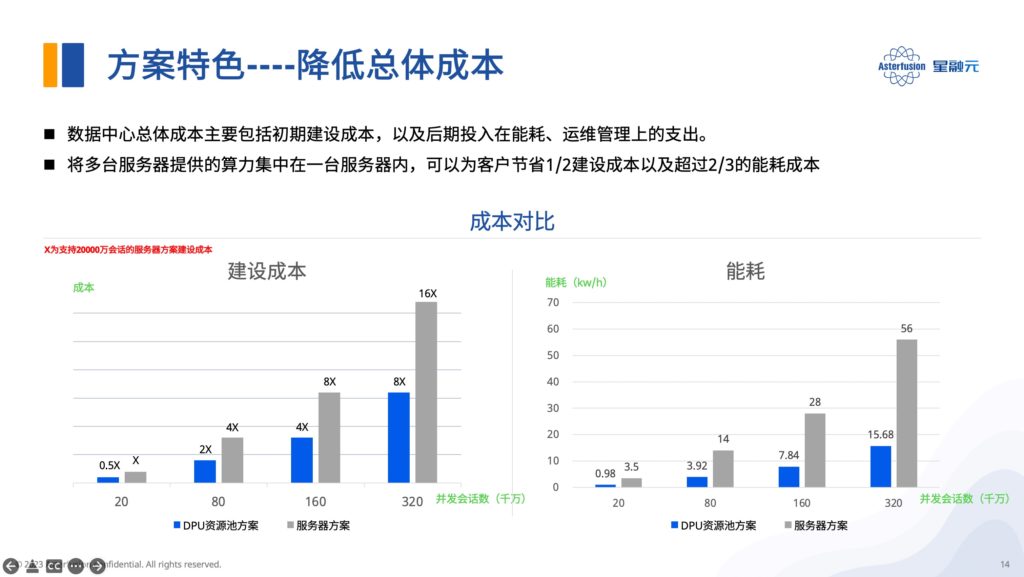
提高单位设备算力,节约2/3机架空间
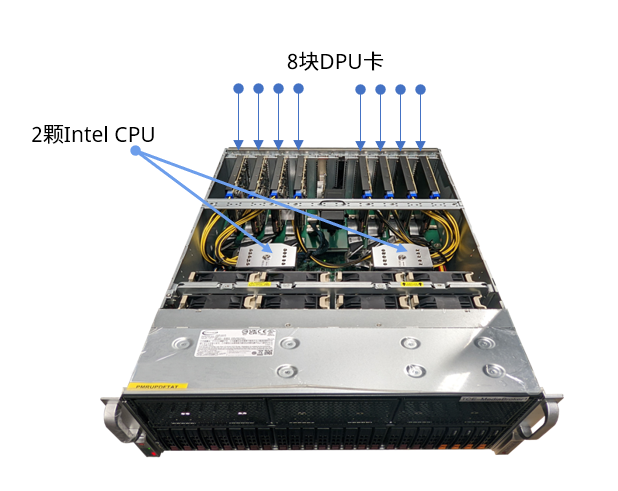
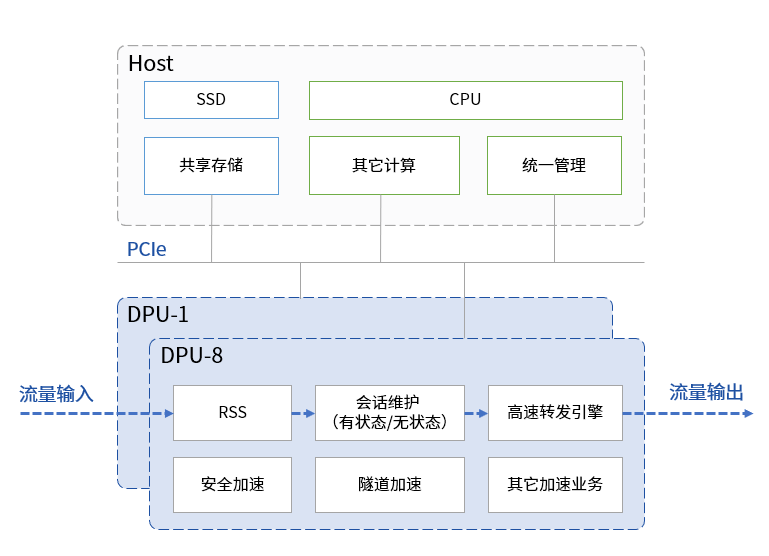
如下图所示,一台4U服务器最多可插8块DPU卡。
每块星融元Helium DPU卡集成24核ARMv8处理器(1.8Ghz),单卡可维护2500万在线会话,每秒新建会话40万,最高处理80Gbps。如此,加装Helium DPU智能网卡以后,单台4U服务器的高并发业务处理能力便可扩展640Gbps。
相比纯2U服务器方案,DPU资源池方案在提供同等接入能力的前提下仅占用原本1/3的机架空间。
机房整体建设和拥有成本降低50%
同样对比纯2U服务器方案,采用DPU资源池方案(4U服务器+8块DPU卡)同等接入规模下每年可节约50%以上的建设和能耗成本。
*服务器方案中,单2U服务器功耗约350W/h;DPU资源池方案,一台4U服务器+8块DPU卡总功耗约980W/h。
加速网络应用开发和移植
Helium DPU智能网卡提供全套的开发套件,客户无需关注底层开发环境,即可进行上层应用的开发及移植。
保证可编程性和性能的同时,无需像FPGA架构的智能网卡一样需要专业的开发团队支持,新版本交付周期小于1天。
算力扩展,不仅是在边缘云…
基于Helium的DPU资源池方案还可应用于云计算、5G UPF、网络可视等多种场景。
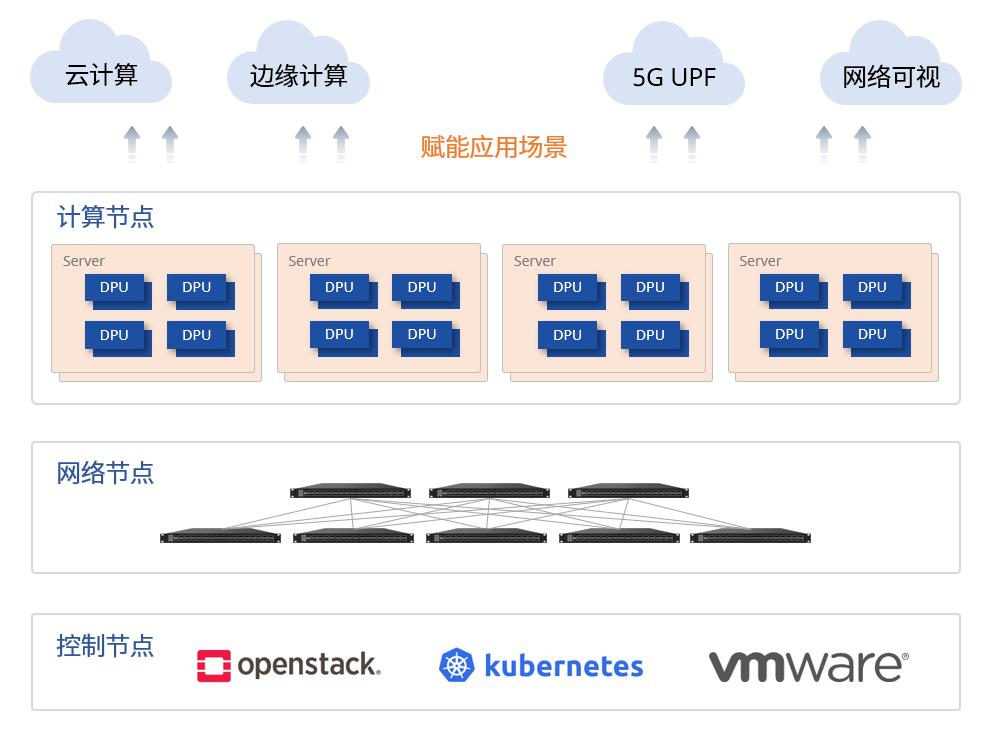
- 服务器CPU负责管理面业务及部分实时性要求不高的复杂计算业务
- Helium DPU卡负责网络数据转发面和控制面业务,并通过硬件加速协处理器进行应用加速
- 多块Helium DPU存储的数据通过PCIe共享到同一台服务器,实现资源共享
- 所有资源由云管平台纳管,完成计算、网络资源的统一管理和分配
相关文章

下一代园区网络,“接线上电”级别的极简运维
关注星融元
过去的几周里,我们已从多个方面介绍了星融元云化园区网络方案的创新亮点,例如在园区去除STP/堆叠等复杂技术、根除广播风暴、无AC隧道的无线漫游等等…
下一代园区网络,何必再有“堆叠”?
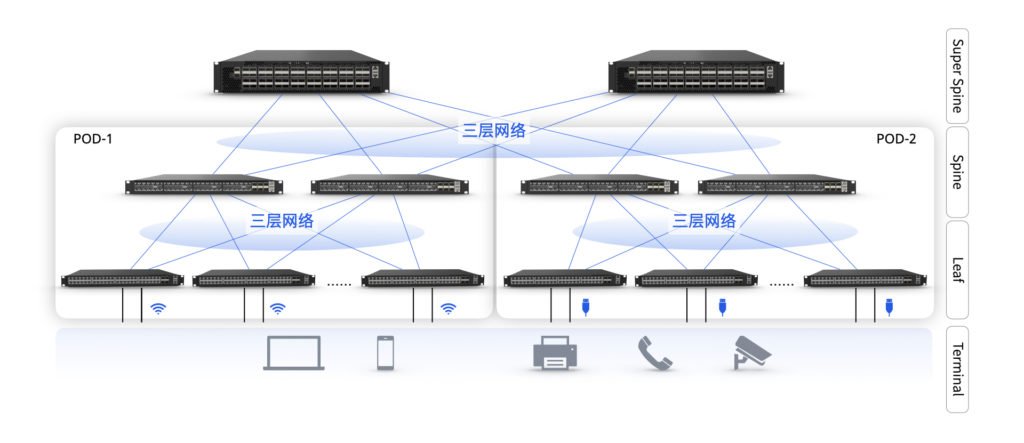
下一代园区网络,用Leaf/Spine架构替代传统三层拓扑
下一代园区网络,“分布式网关”实现更高效的无线漫游!
几乎所有的网络技术创新都是为降本增效而生,其中网络运维的优化改进无疑是个绕不开的话题。在运维层面,星融元的云化园区网络方案还有哪些对策呢?
客官别急,马上为您一一介绍!
零配置极简部署,设备上线即插即用
星融元的云化园区网络解决方案引入了在服务器和云网络运维体系中广泛使用的零配置部署机制。

网络管理员在管理服务器上部署文件传输系统的服务器端,并将网络操作系统镜像和按照规划生成的网络配置管理文件存放在指定目录下;
交换机上电启动后向管理服务器申请相关配置,并通过DHCP协议Option字段获取到配置、升级文件的地址和路径;
管理服务器将系统镜像和配置文件传送到交换机后,交换机将自动加载新获得的网络操作系统镜像,并根据配置文件完成系统的初始配置;
以上申请、加载、配置的过程完全自动化地完成,无需网络管理员介入。
对于一个有着成百上千台交换机的网络来说,零配置部署机制对网络升级、变更所带来的效率提升是非常可观的。
分层简化部署,三个配置搞定全网!
传统园区网络中,每一台网络设备的配置网络都是不同的。面对较大规模、结构复杂的网络,多个版本的网络配置文件维护和变更,运维人员稍有不慎就会因为错配引发网络故障。
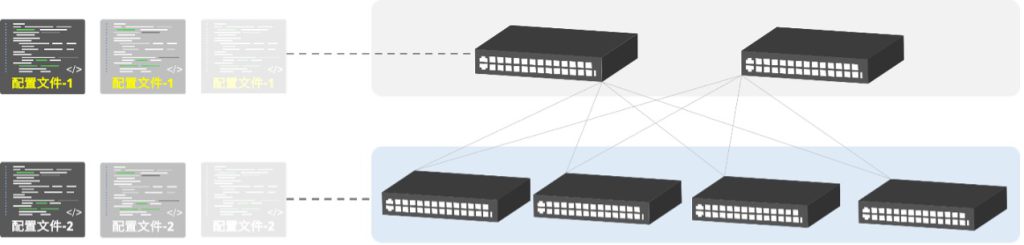
云化园区网络架构中,我们将网络设备的配置改进为 “一层设备、一个配置”。网络配置的数量不再被网络设备的总数量所决定,而是只跟网络的层数相关。
借助软件设计上的创新和初始配置的自动化,在一个二级三层的云化园区网络中,无论是几十台还是上百台网络设备,都只需要维护三个网络配置。这一来,配置管理工作带给网络运维的复杂度下降了2-3个数量级,综合成本得到大幅降低。
轻量灵活的带内管理网,更适合中/小规模园区
传统情况下,我们的运维工程师需要接console线或者ssh分别登录单台设备执行操作,配其他设备时,又得把流程再执行一遍。这无疑是繁琐低效的,为此有些园区网络方案便会引入一个复杂的SDN控制器实现全网统一管理。但在某些场景下控制器则显得过于笨重了,一旦这种集中控制器出现问题,定位排障又陷入了死局。
星融元云化园区解决方案为中小规模的园区网络提供了一种轻量、灵活的带内网络管理方式——通过集成在交换机操作系统内部的软件模块,建立设备集群。
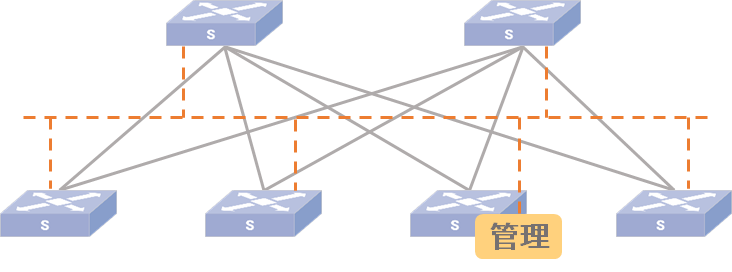
- 简化跨设备运维:登录到集群中任何一台设备, 就能管理和配置集群内的所有成员,完成配置备份、跨设备导出,批量升级等操作,无需关注物理连接和IP地址
- 低成本部署:不用额外布线,不依赖带外网络和管理平台,对拓扑结构无要求
- 随时启用:可在组网服务任何阶段安装/启用,成员加入和退出不影响控制面和转发面运行
- 不改变使用习惯: 思科风格CLI,保持广大运维工程师熟悉的命令行体验
进阶必备!丰富的可编程接口,面向未来的NetDevOps
星融元CX-M系列云园区交换机搭载以开源开放的SONiC为内核的自研网络操作系统AsterNOS,其中AsterNOS SDK提供了软件编程接口——使用者除了使用传统的命令行、WebUI进行基础运维之外,还可以通过REST API、System API自动化地、高效地运维网络,甚至开发新应用。让“应用定义网络”成为现实!
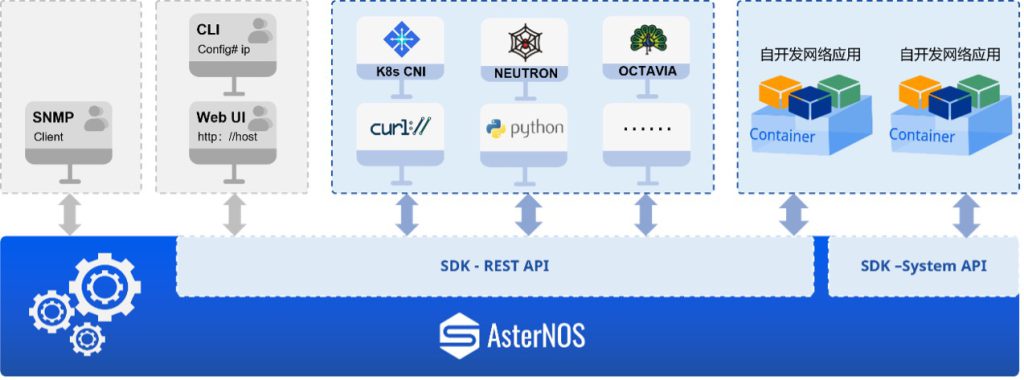
DevOps(Development and Operations,开发运营)是一种新型的产品交付与运营模型,它将与产品生命周期和业务运营过程中的研发、测试、部署、运营等环节,以一种空前的方法连接了起来。DevOps对应到网络世界中,就是NetDevOps。
星融元云化园区网络架构天然地支持NetDevOps。下图我们围绕一个安全运维场景简单举例说明:AsterNOS SDK所提供的REST API中,包含对ACL各个字段和统计数据的访问接口,通过调用这些接口,即可直接获得ACL的这些信息用以分析。
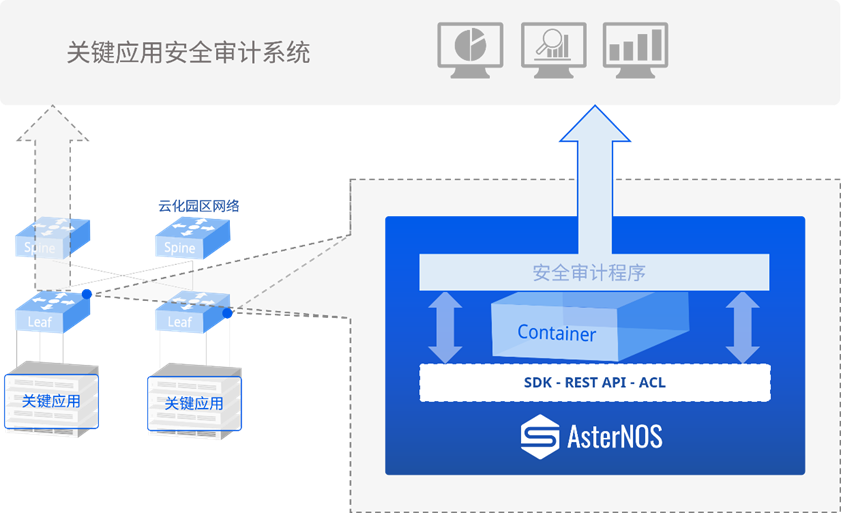
示意性伪代码:
运行着AsterNOS的网络设备的管理接口IP地址和端口为192.168.1.200:4430

相关文章

下一代园区网络,“分布式网关”实现更高效的无线漫游!
关注星融元
移动化办公时代下WiFi漫游已经成为了日常,你有没有遇到过网络断连导致业务中断的情况?这往往是因为我们在移动过程中,所属的IP子网发生了变化,终端不得不获取新的IP地址以适应新的网关,甚至我们还需要为此重新进行繁琐的安全认证…
为提升用户体验,实现WiFi无缝漫游,市面有以下两种常见的方案思路:
- 尽可能将需要漫游的区域规划在一个二层网络里,但是二层网络越大越不安全;
- 在新旧网关之间建立隧道,通过集中的网关控制器把漫游后的终端流量传输到原来的网关来转发,而这又导致复杂的配置和低效的流量转发路径,影响了漫游性能。
借鉴云网”分布式网关”概念,提升园区网络体验
早期的数据中心也多是采用集中式的网关,即:整个数据中心由几个大交换容量的设备作为网关来实现跨三层的流量转发。
随着市场需求变化以及各种新兴网络技术不断涌现,分布式网关的实现方式逐渐兴起——将三层网关分散部署到更靠近终端的接入层/边缘层。这种优化后的架构天然适应SDN(软件定义网络)的先进技术理念,在转发路径、网络运维、表项容量和网络安全等方面优势明显,成为了未来数据中心发展的主要方向。
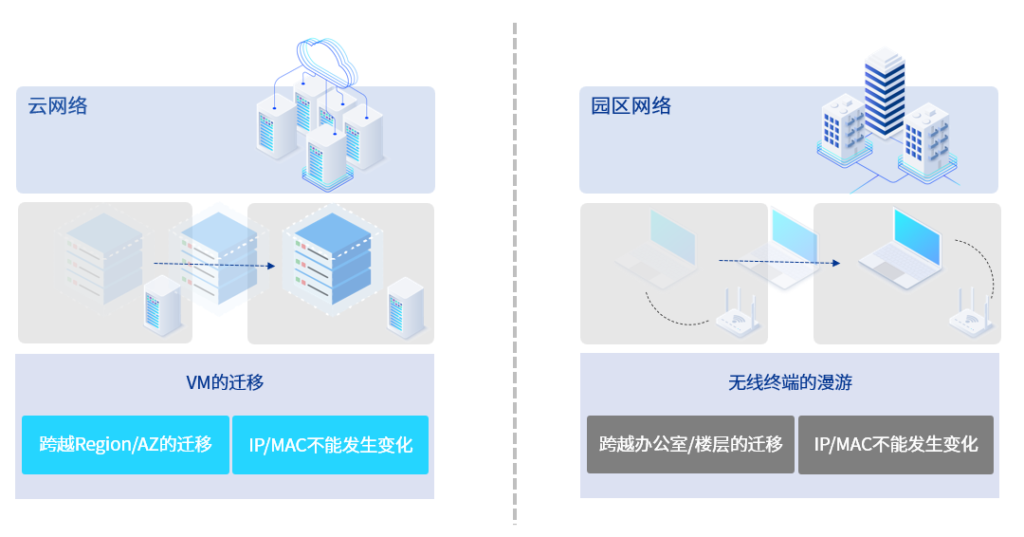
当我们对比云和园区的网络模型可以发现:尽管迁移/移动的规模和速度等方面有一定差异,但云中的虚拟机和容器的迁移过程与园区内的无线终端漫游高度相似,都同样要求移动后的终端的IP/MAC不能发生变化。
云网中的分布式网关设计为传统园区网络架构创新提供了一个很好的思路。
星融元新一代云化园区网络:分布式网关设计
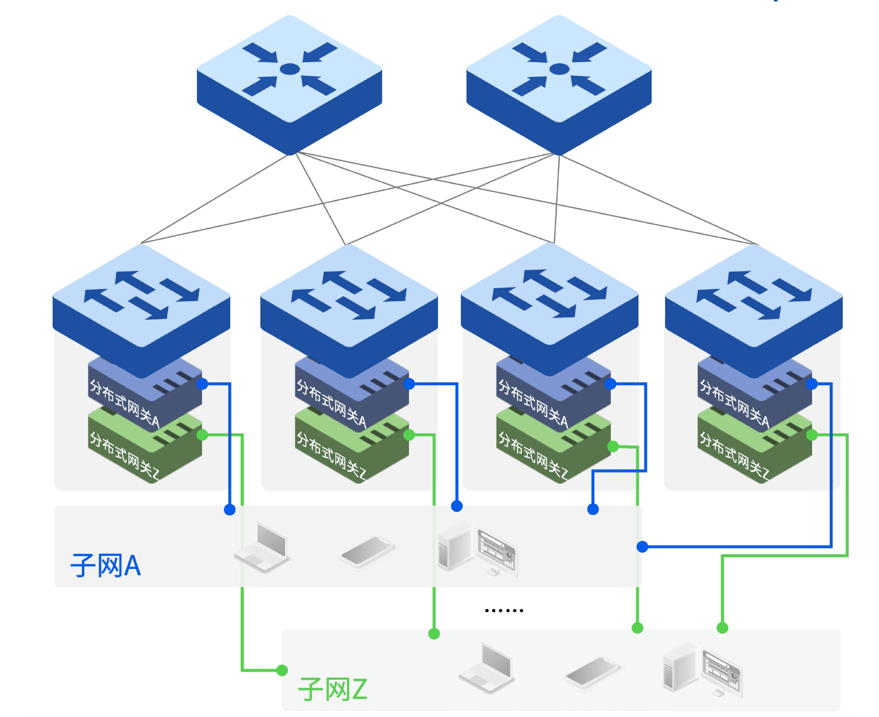
星融元云化园区网络在全三层IP路由组网的基础上借鉴了云网中分布式网关的概念:一个子网的网关以分布式的形式存在于每一个接入交换机上。这可以充分利用每一个接入交换机的能力,让所有的跨子网转发动作在最近的交换机上完成,网关功能不再成为压垮网络中某一台设备的潜在风险,同时大幅度提升整网的转发效率。
园区漫游的集中式网关方案对比分布式网关方案:
| 集中式网关(隧道转发) | 分布式网关 | |
|---|---|---|
| 转发路径 | 业务报文经过隧道封装,经由集中式网关统一转发 | 业务报文在本地接入交换机上转发 |
| 运维部署 | 部署时需要大量手动配置(例如AP分组规划,单独的SSID/VLAN等)较为复杂,日后维护起来难度大 | 开局一次性配置分布式网关信息即可,无需其他额外操作 |
| 可靠性 | 过于集中的网关功能有压垮设备的风险,一旦出现故障,影响面大 | 网关功能分散到所有接入交换机上;但设备发生故障对业务影响小 |
| 扩展性 | 承载着关键性的网关业务,需要高性能大容量的设备,也容易成为限制网络规模迅速扩展的瓶颈 | 接入层交换机仅需存储本地表项,对设备容量要求不高,更容易扩展接入规模 |
高效转发路径,流量”不兜圈子”
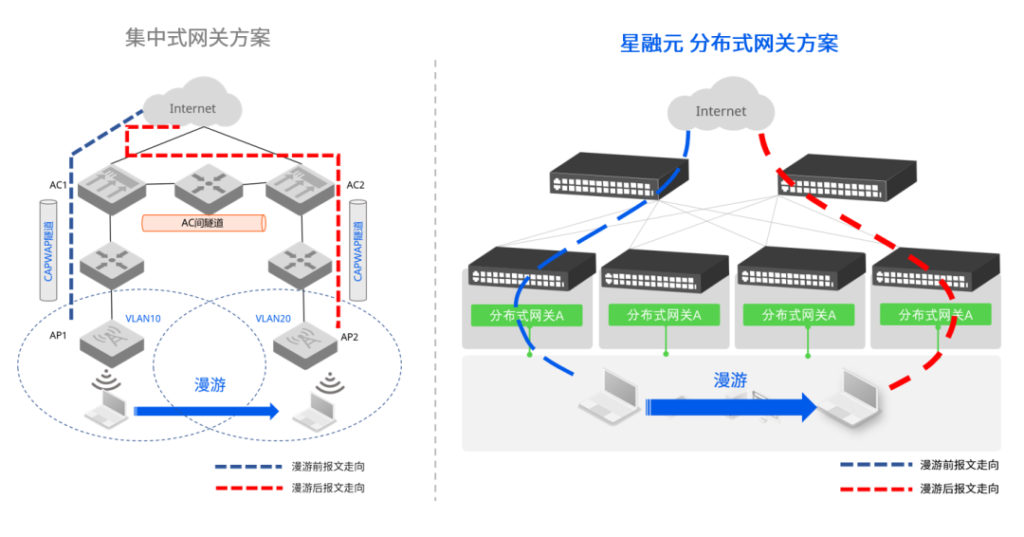
传统的集中式网关方案中,终端发生跨VLAN的AP漫游后需建立隧道,将漫游后的业务报文发回原先的网关处理,导致转发路径长,效率较低。(图仅作流量示意,实际AC多为旁路部署)
在星融元的分布式网关方案中,每个接入交换机上都同时运行着相同的多个子网的网关,终端无论漫游到哪个AP,业务报文都可直接在本地接入交换机以最短路径完成漫游后的转发,无需到某个集中式网关上“兜圈子”,效率更高。并且,这种毫秒级的网络切换对于正在运行的上层业务不会有任何影响。
极简网络配置,开局”一步到位”
终端IP地址始终不变是实现无缝漫游的必要条件之一。星融元的园区方案中全网采用了统一的分布式网关,终端上线后,接入层的分布式网关会将它的IP/MAC信息以及安全控制策略在全网同步。
正因为终端漫游后接入的交换机上已经预先配置了网关信息,并且自动学习和同步了终端的IP/MAC信息,所以一旦感知到发生终端漫游便可快速响应,并将漫游后产生的表项变化在全网自动更新。
网络管理员所要做的,仅仅是在网络初始化时一次性配置好所有分布式网关的信息,运行过程中无需再有任何动态调整。
附:无线漫游数据参考,来自客户现场实测(采用上述分布式网关方案),网络切换时延约10ms,丢包0
原文地址:小于10ms!基于SONiC+白盒AP的WiFi无缝漫游实测

更多关于星融元云化园区网络解决方案的创新亮点,请持续关注星融元官方公众号:星融元Asterfusion
