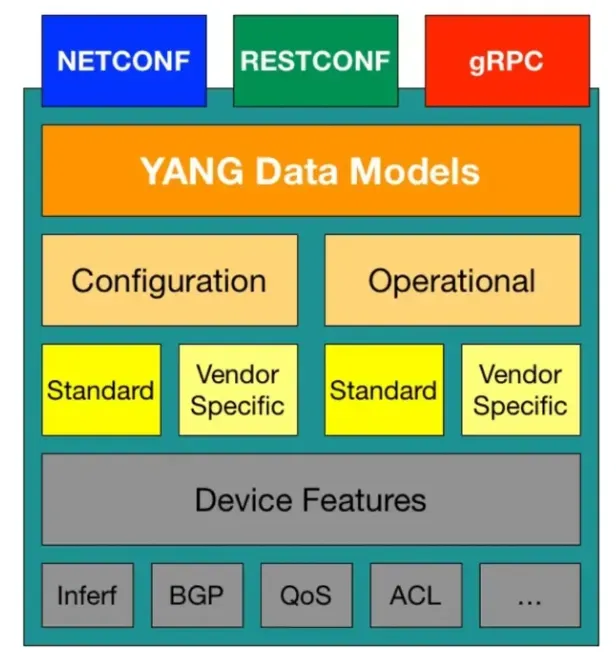
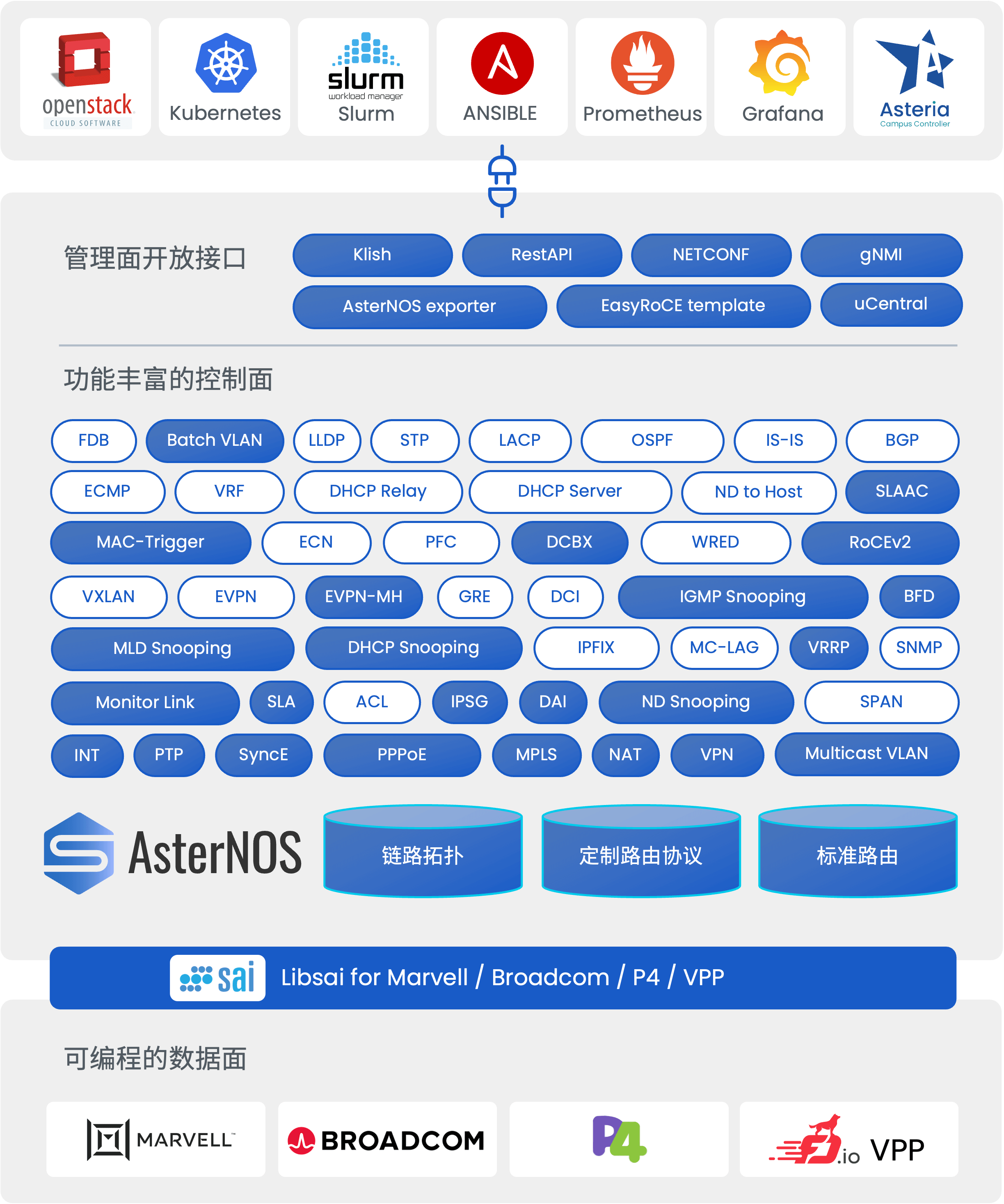
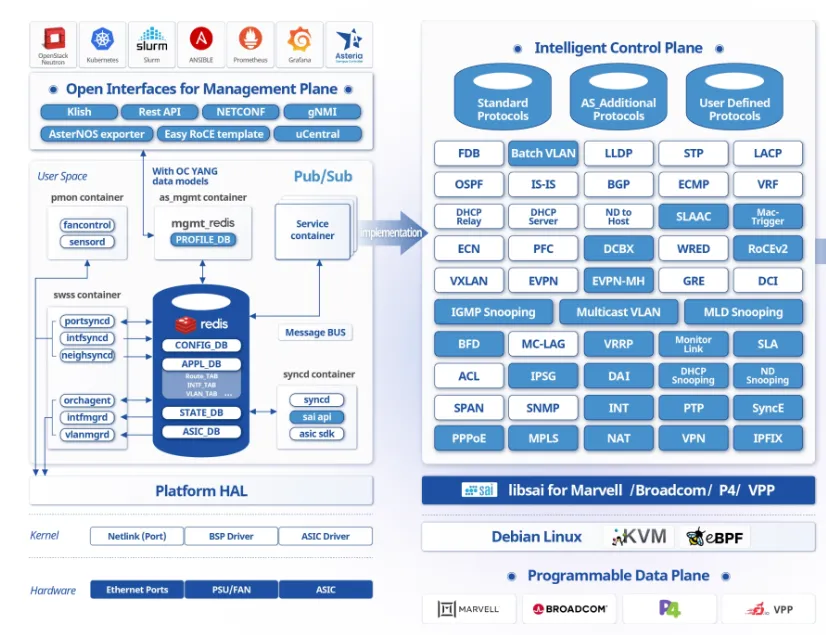
EasyRoCE 工具上新:基于INT的流量路径预览
关注星融元

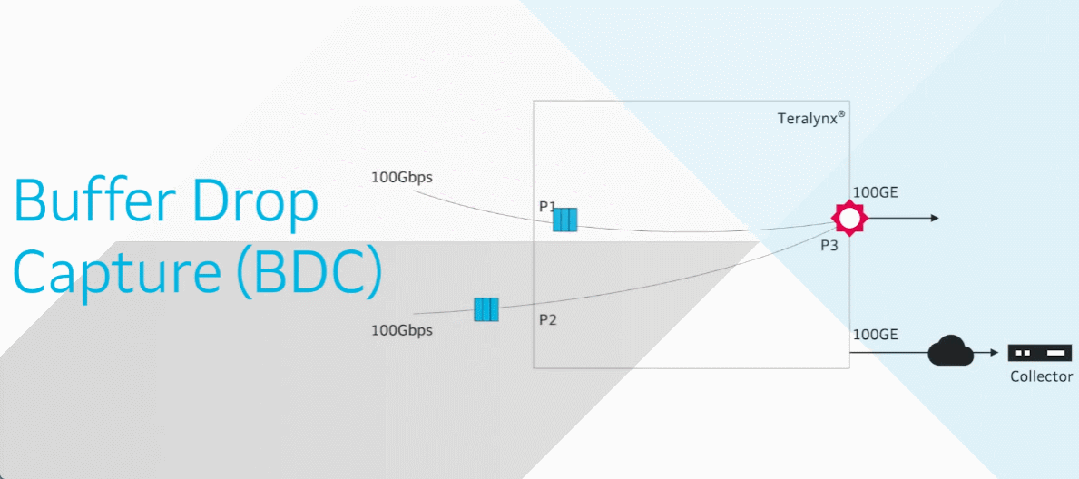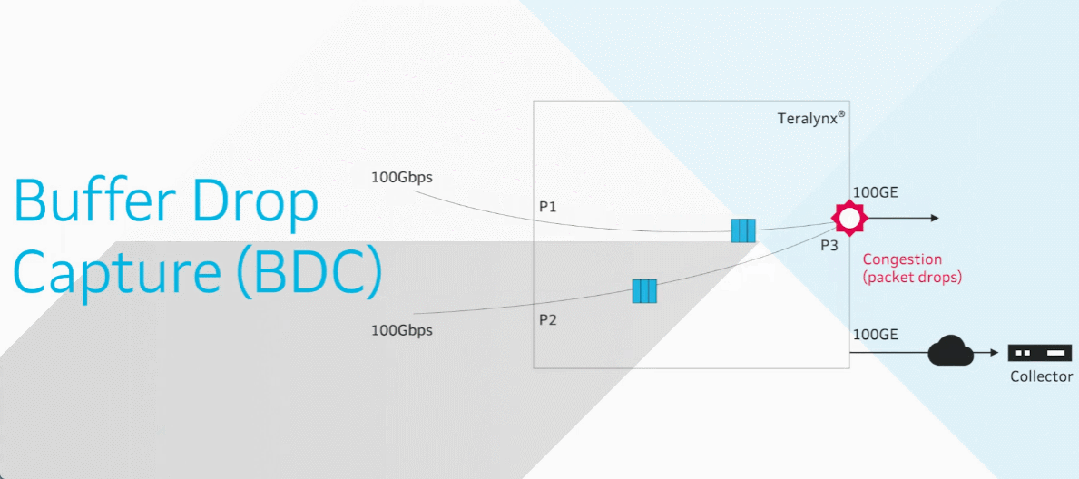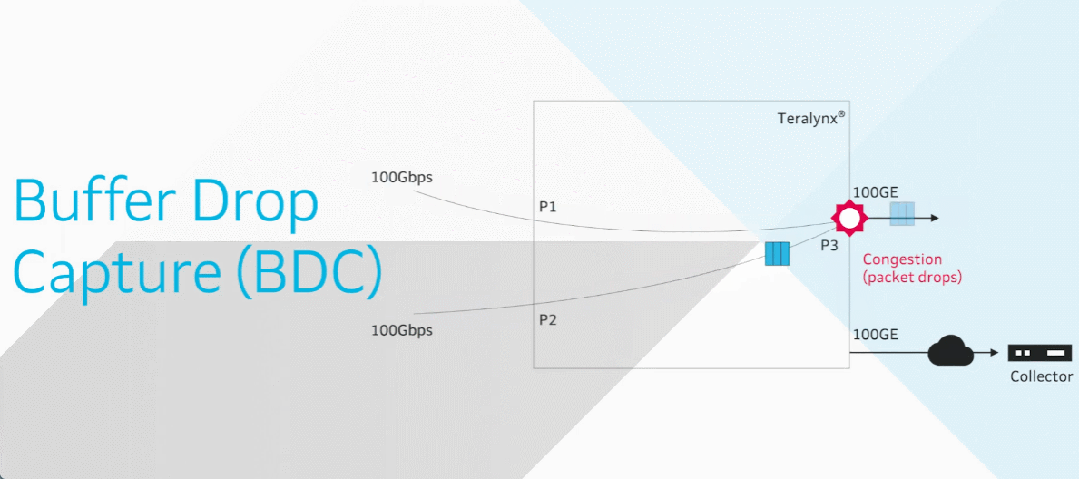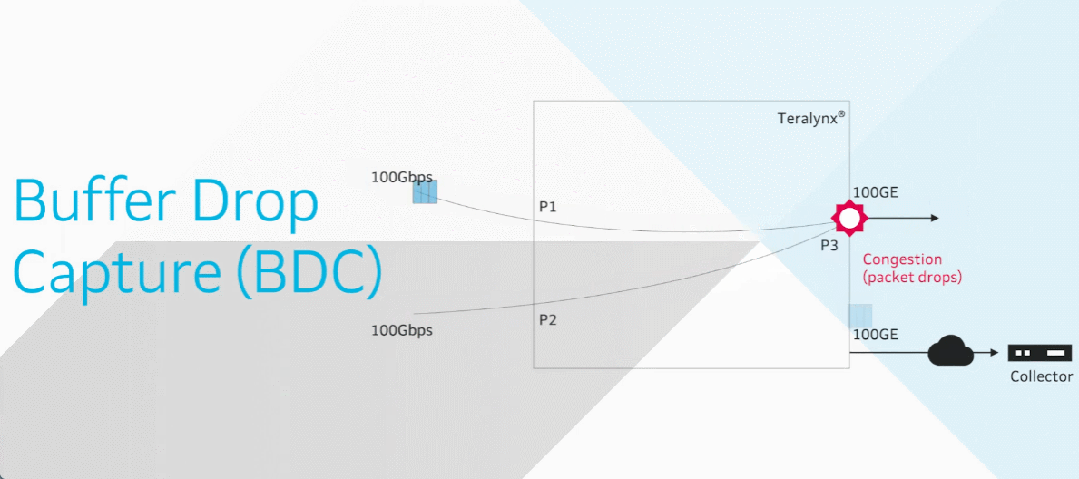
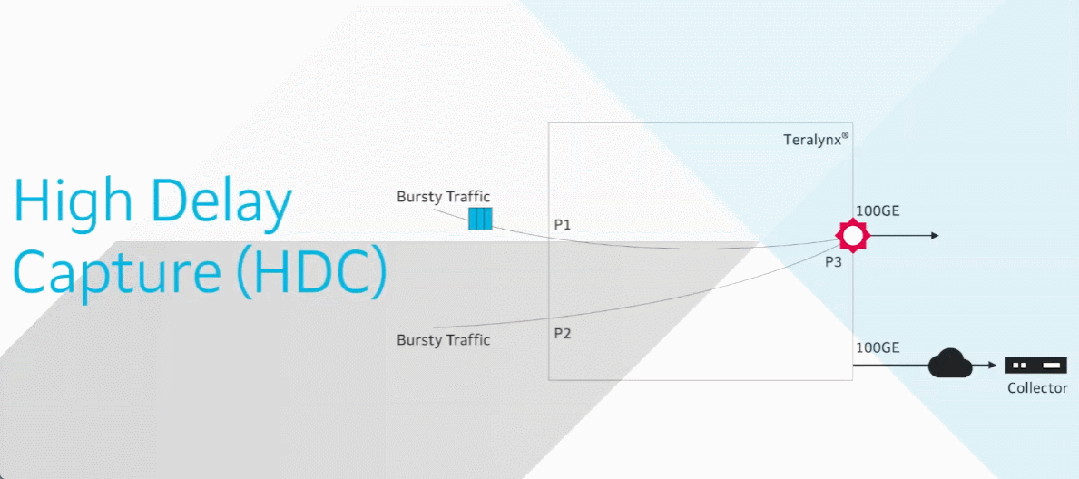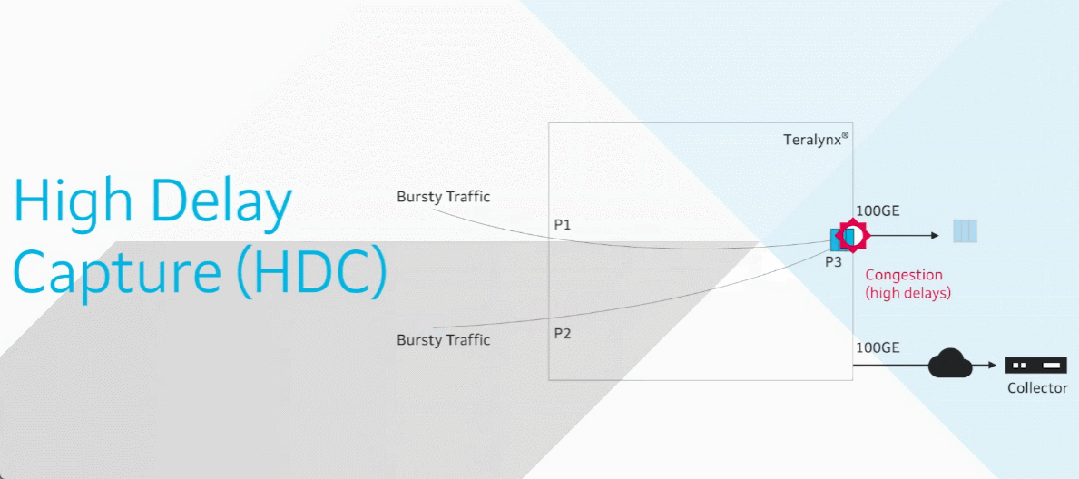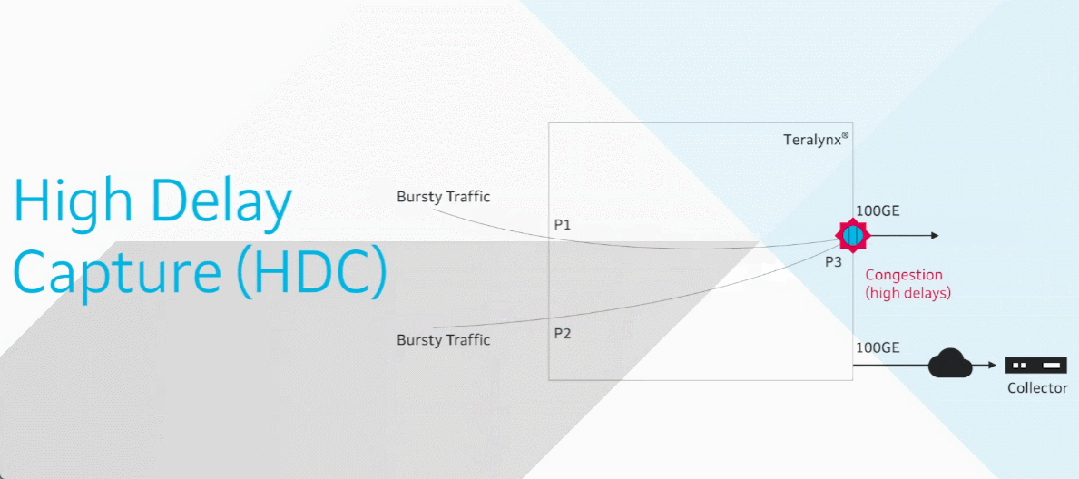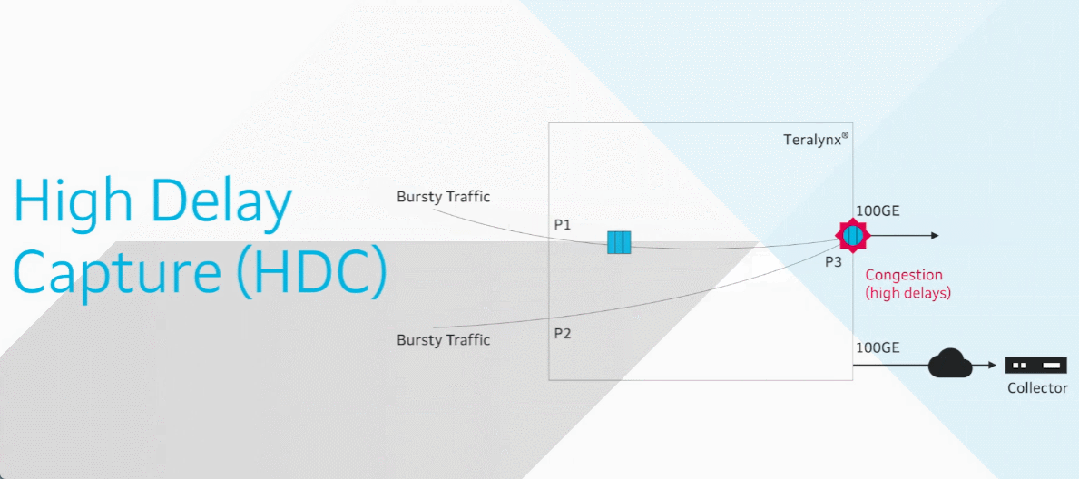
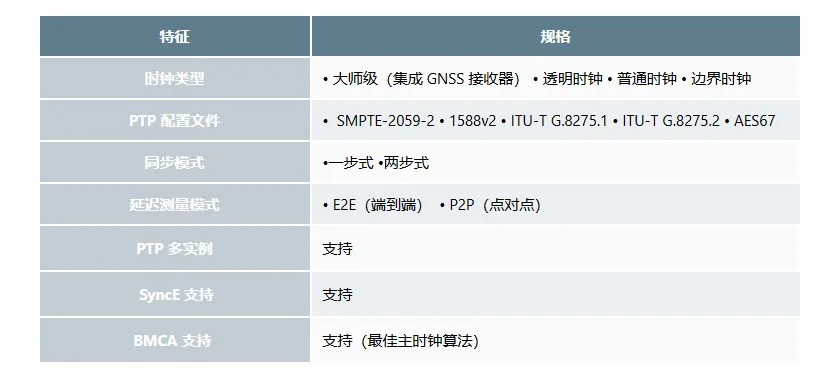
目前智算中心场景中的网络成为了影响模型训练效率的关键制约因素。在 RDMA 网络里,微小丢包或拥塞即可导致系统整体通信性能的显著下降,而传统网络运维方式无法感知微秒级延迟变化。
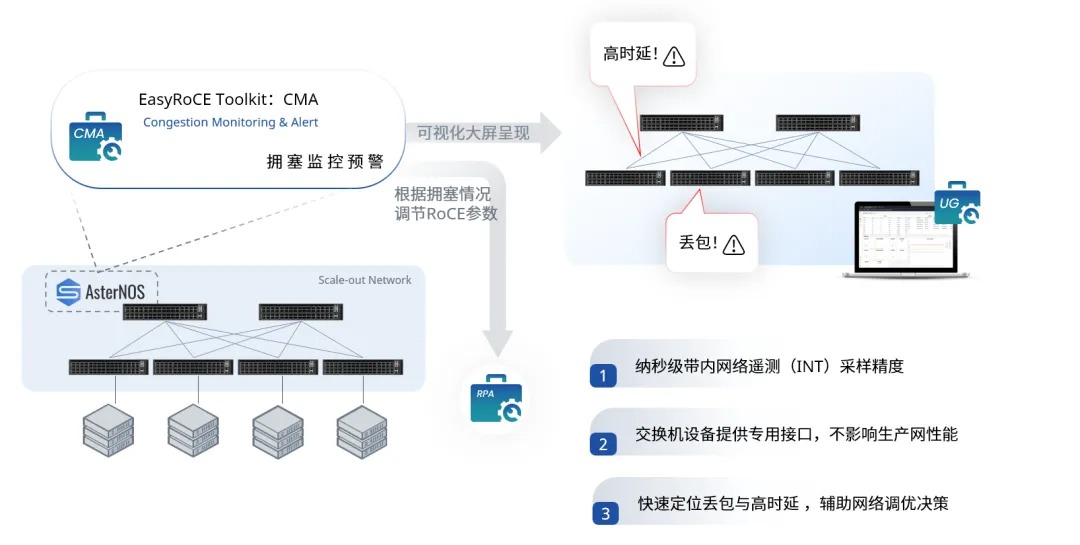
由此,基于交换机的软硬件能力,星融元设计并实现了一款基于带内网络遥测(INT)技术的网络运维与监控工具 —— EasyRoCE – TPE,旨在为一线网络运维工程师提供决策优化的实用信息。
什么是 TPE?
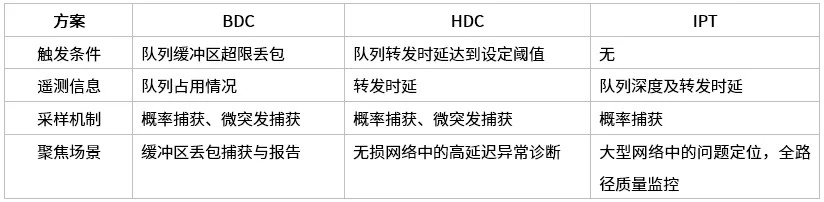
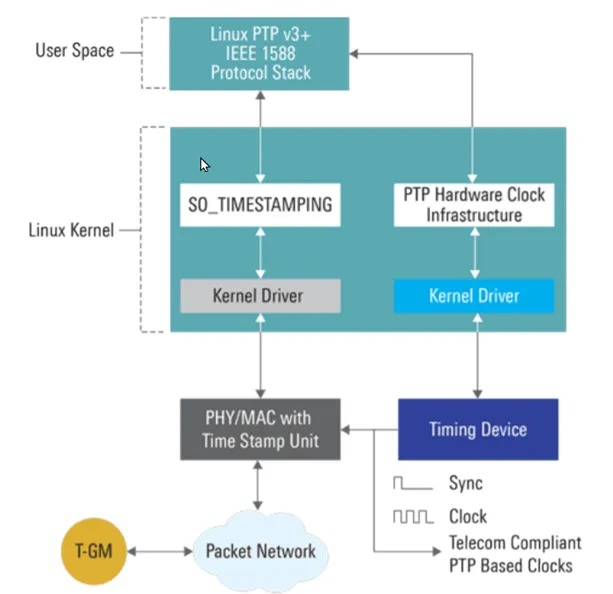
EasyRoCE-TPE(流量路径预览,Traffic Path Explorer)的实现基础来自于星融元交换机具备的一种名为 IPT(Inband Path Telemetry)带内网络监控技术:
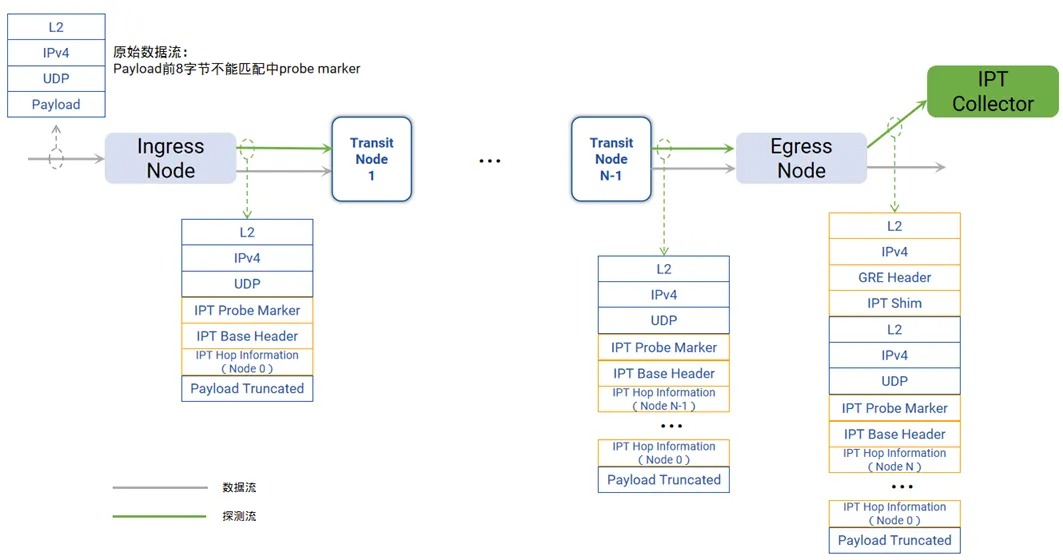
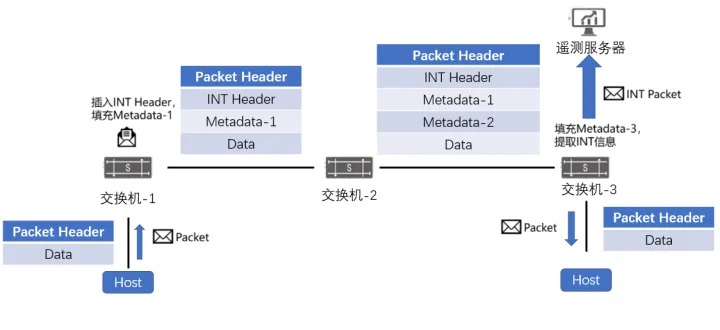
IPT技术通过复制特定业务流量的报文并携带流量经过的每一跳交换机的相关信息,从而获取端到端转发的统计信息。
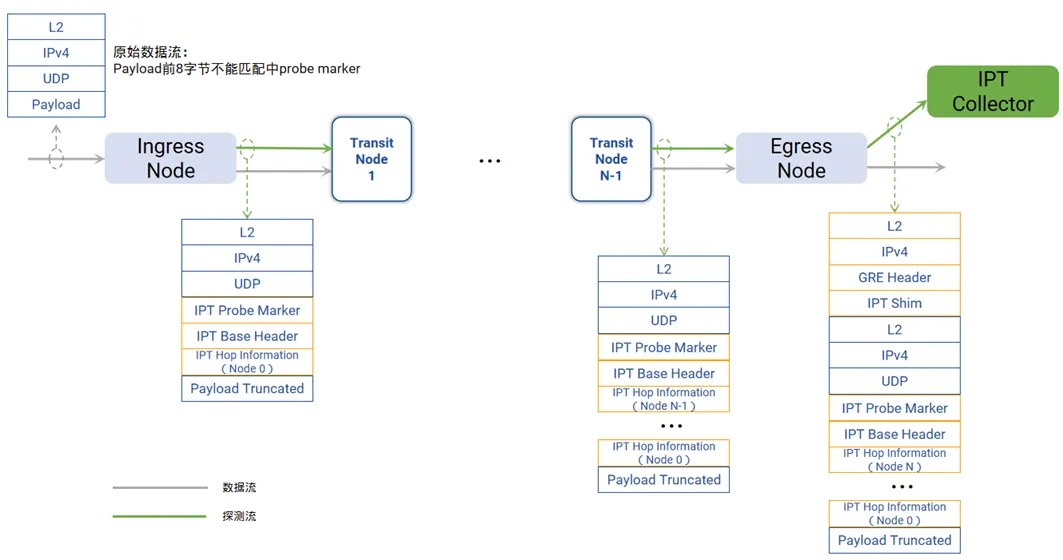
IPT相关技术原理参阅:一文读懂!INT技术之IPT如何实现端到端路径质量的精准监控
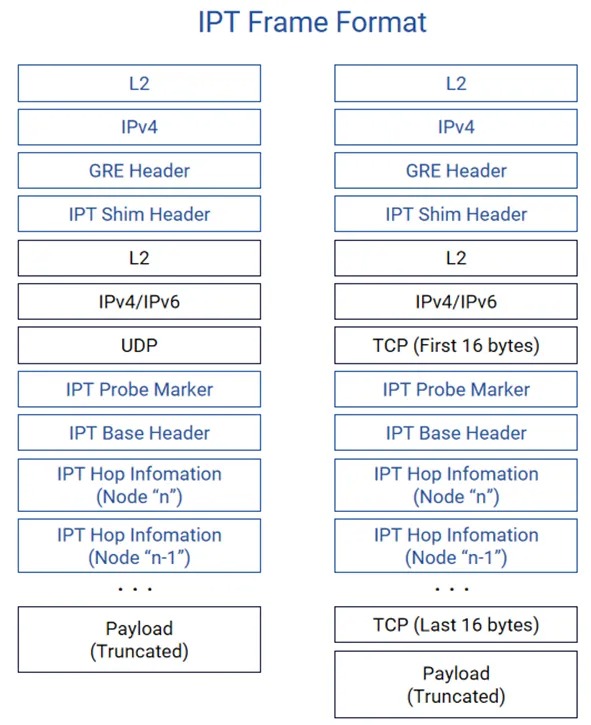
交换机启⽤IPT功能后,对于到达入口节点(Ingress Node)的每个特定流量原始数据包,交换机都会⽣成⼀个探测数据包,这个探测数据包是原始数据包的克隆(payload部分被截断),携带探针标记(probe marker)。
- 无侵入:不会影响既有业务,且整个TPE独立部署于单独的机器不会影响集群网络交换机;
- 容器化部署:整个TPE以容器方式部署,不影响监控服务器的其他服务;
- 可视化界面:用户全程在图形化界面操作,并且网络信息以图形化方式呈现;操作简单,直观查看交换机状态。
TPE 由两部分组成:IPT 控制页面和 IPT 可视化页面。
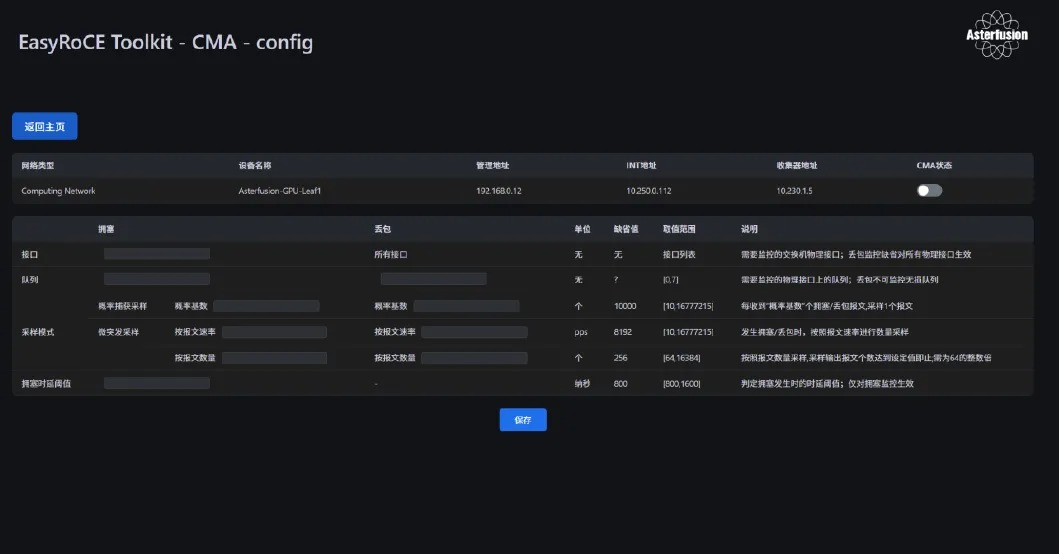
TPE 控制页面
TPE提供了一个可视化界面来配置IPT的规则,用户完成交换机的规则配置后,打开IPT开关即可通过SSH完成相关配置的下发工作。
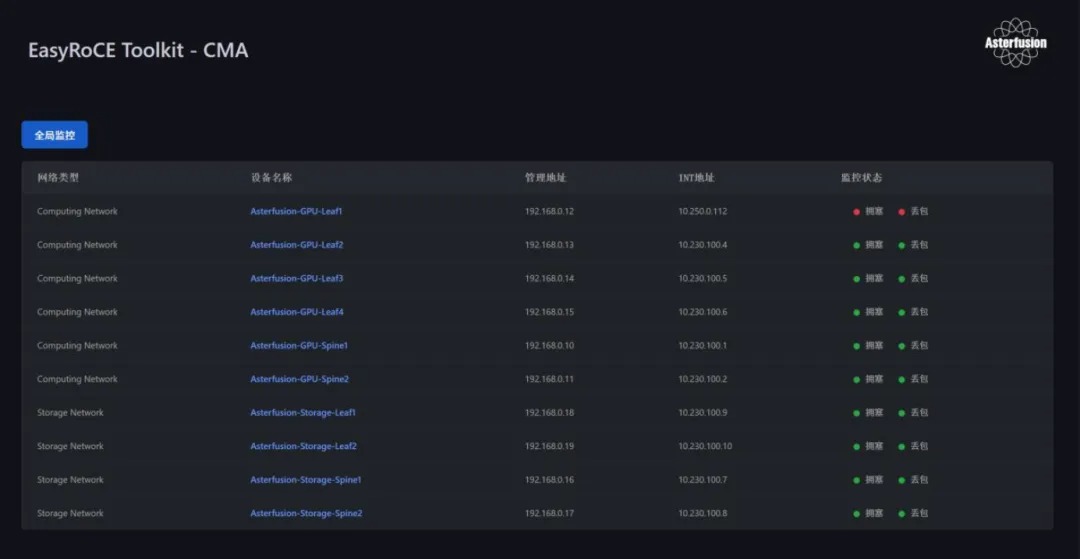
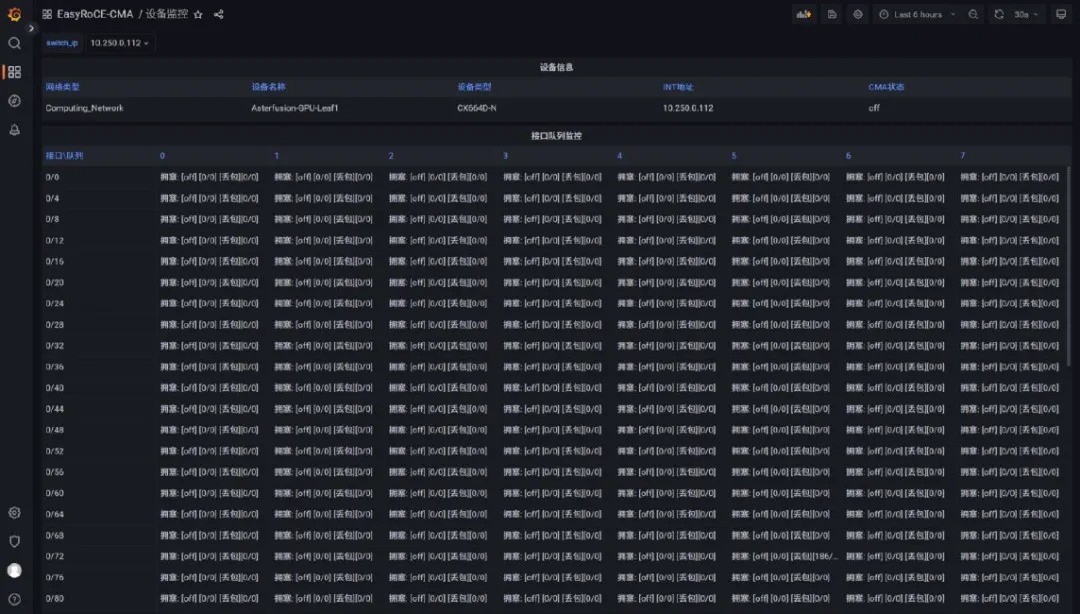
TPE 可视化界面
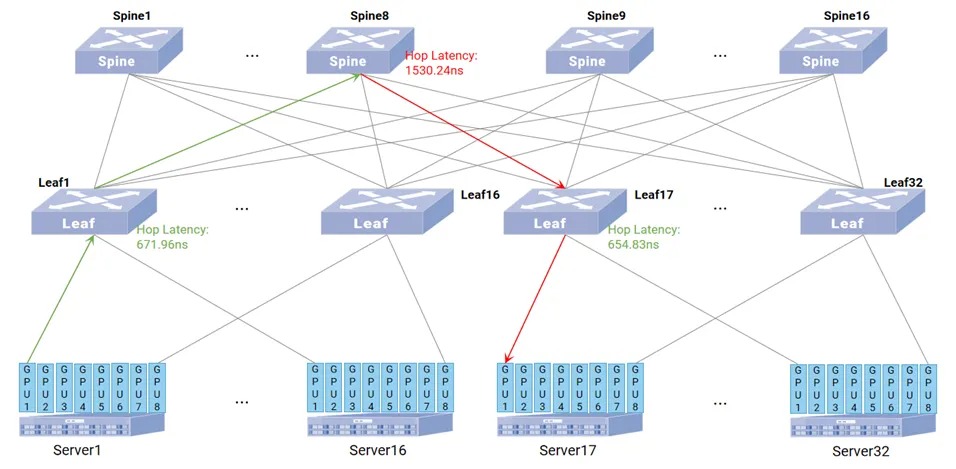
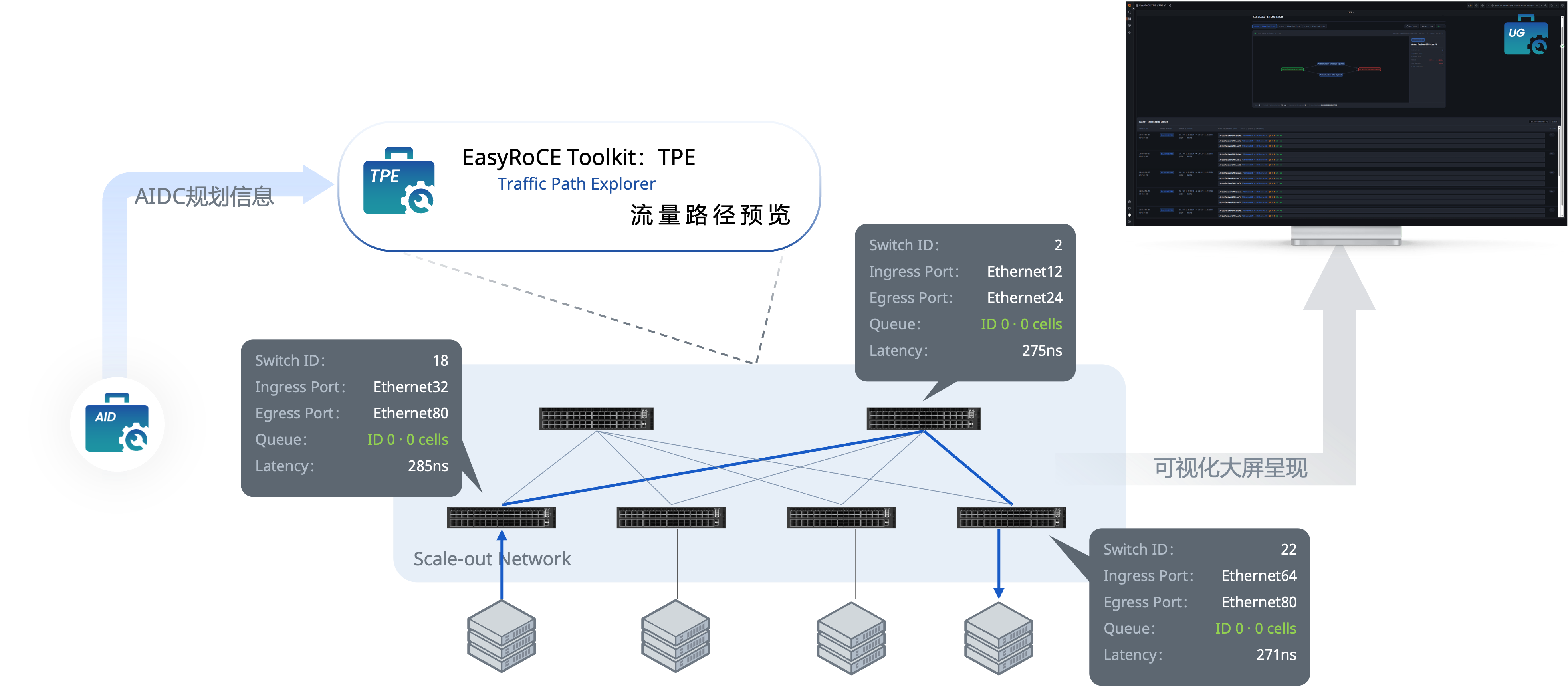
完成交换机的配置后,可视化界面将基于之前配置的规则生成拓扑,并同时检测服务器的网络接口。
当使能了 IPT 功能的交换机发送 IPT 报文给 TPE 时,TPE会解析并在可视化界面进行展示,此时在拓扑上可呈现每个交换机节点的最新的状态信息。
部署与使用
最新版本的TPE工具请联系项目销售/售前人员获取;部署TPE工具的服务器必须接入管理网络和交换机的INT网络中。
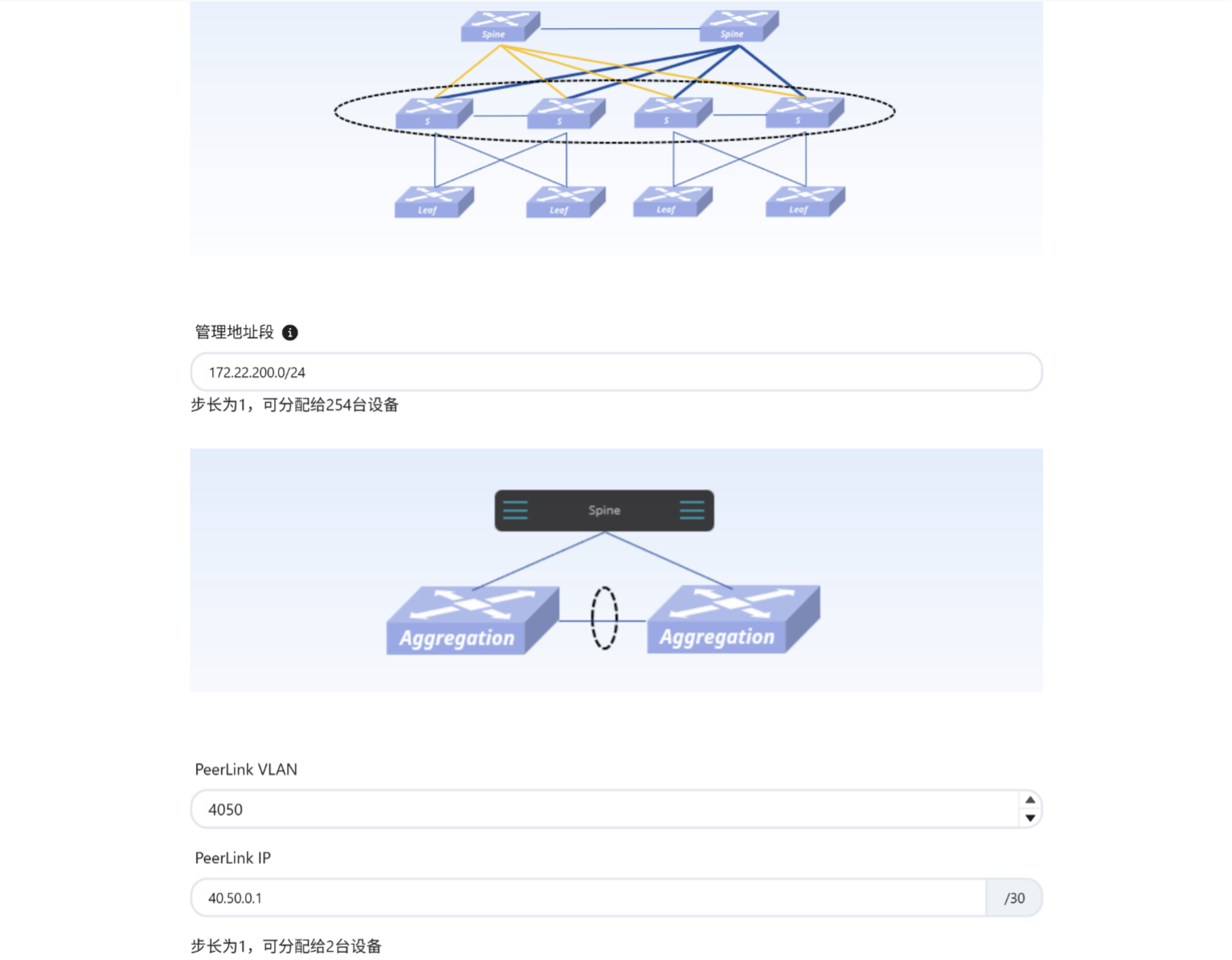
编辑AID,添加交换机的INT信息
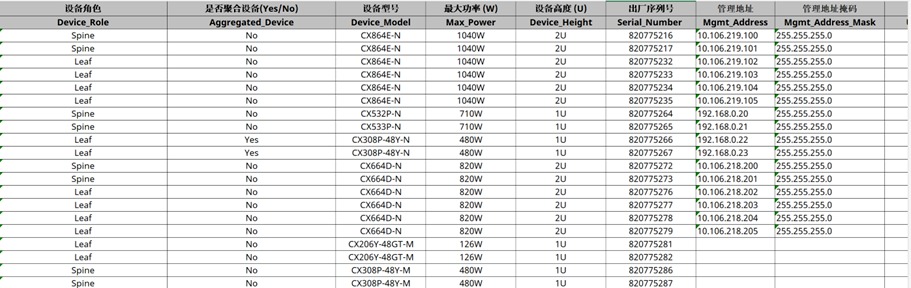
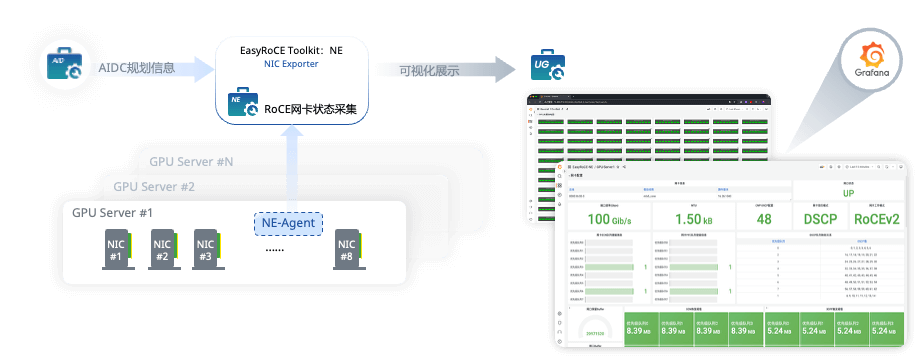
我们需要在EasyRoCE-AID(基础设施蓝图规划)工具里按照真实的网络拓扑规划添加交换机信息,以便 TPE 能够在运行时自动获取到正确的设备信息。
- 设备名称:交换机的hostname,全局唯一
- 网络类型:按现网真实拓扑来划分交换机类型,分计算网络、存储网以及管理网
- 设备角色:Spine、Leaf类型,按设备真实角色填写即可
- 设备型号:设备的真实类型,须如实填写以确保工具解析正确
- 管理地址:用于配置下发
在服务器上安装 TPE 工具
#上传TPE的容器镜像到服务器中scp tpe-v1.0.1.tgz root@10.240.3.5:/tmp/
# 导入镜像docker load -i tpe-v1.0.1.tgz
# 运行容器docker run -d --name=tpe --network host --privileged -v /tmp/tpe/data:/app/data tpe:v1.0.1
现在可以通过Grafana面板URL:http://10.240.3.5:3000/d/xxxxxx (示例) 来访问操作TPE。
访问和操作 TPE 工具
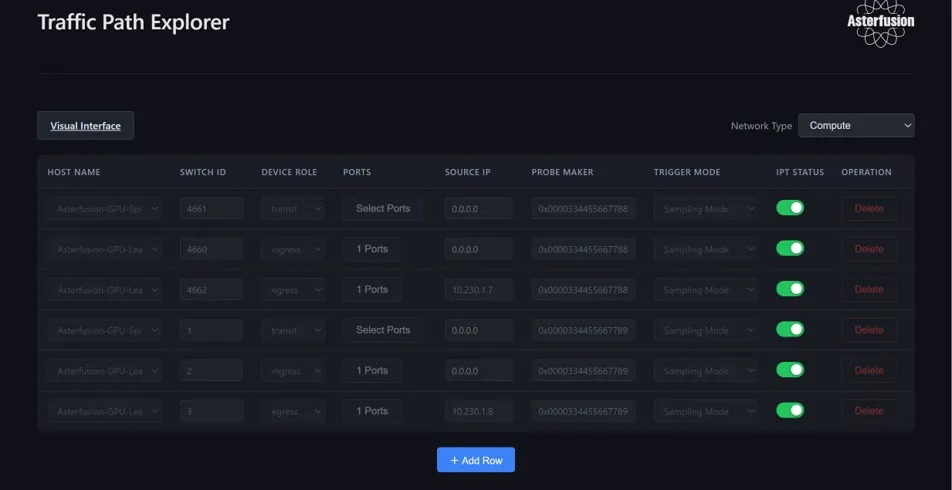
以上 TPE 配置页所呈现的效果,便于演示,此处我们已预先添加了一些交换机的 IPT 规则,实际使用时用户可在配置界面自行添加所需规则。
手动配置IPT规则
手动添加IPT规则需要遵循如下要求:
- 一条完整的业务路线需要按照实际拓扑添加入节点、传输节点以及出节点;
- 入节点需要添加业务进入的设备端口,出节点需要添加业务进入的端口以及INT地址;
- 所有设备的Switch ID唯一且同一链路的Probe Marker必须保持相同。
配置交换机角色:Ingress/Egress/Transit
主要配置项:
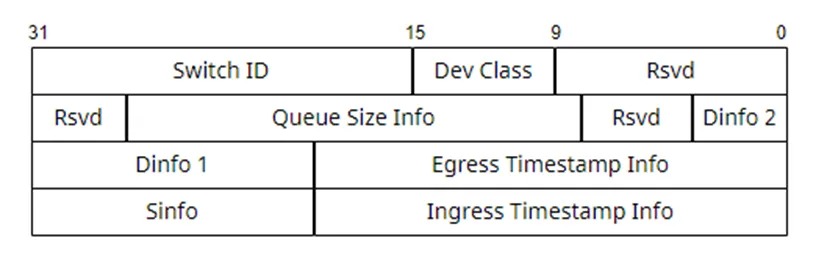
Switch ID:纯数字,全局唯一,与AID一致Ports:交换机仅对已配置接口的报文进行监控采样Probe Marker:为64位配置值,同一链路的ProbeM arker必须保持相同,最⾼2字节必须为0Trigger Mode:分为 Sampling Mode (全量报文概率采样)和按照 DSCP 过滤采样两种Source IP:对于Egress角色,需填写交换机Source IP(INT接口地址),该IP作为源IP地址用于IPT报文最外层IPT头封装,目的IP为TPE所在服务器IP。egress 节点会按照三层路由将 IPT 报文发送给 TPE 服务器用于最终的解析呈现
完成每个节点的配置,打开行末的开关即可完成配置下发工作。
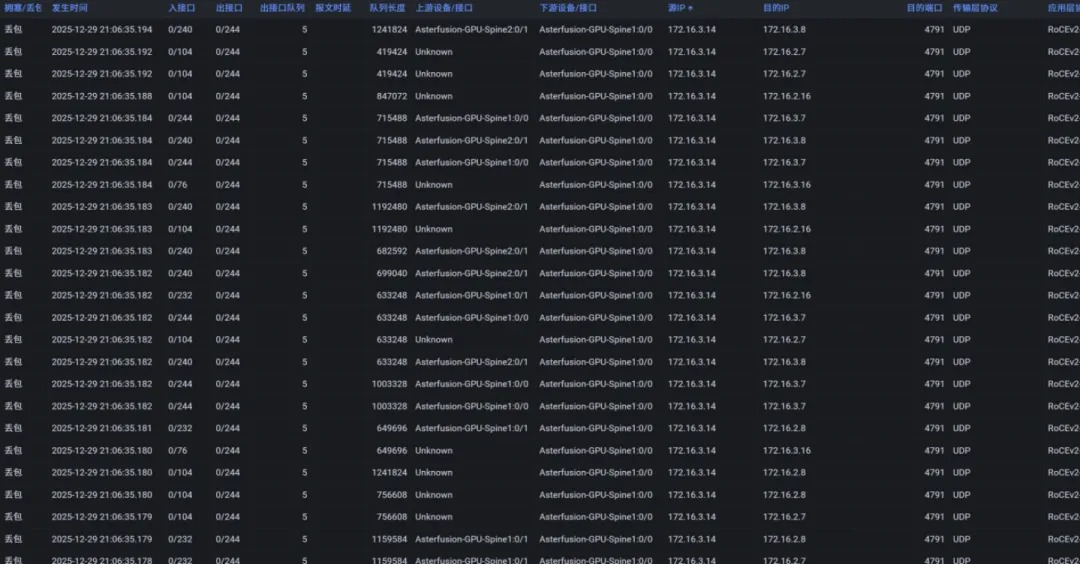
查看 TPE 可视化界面
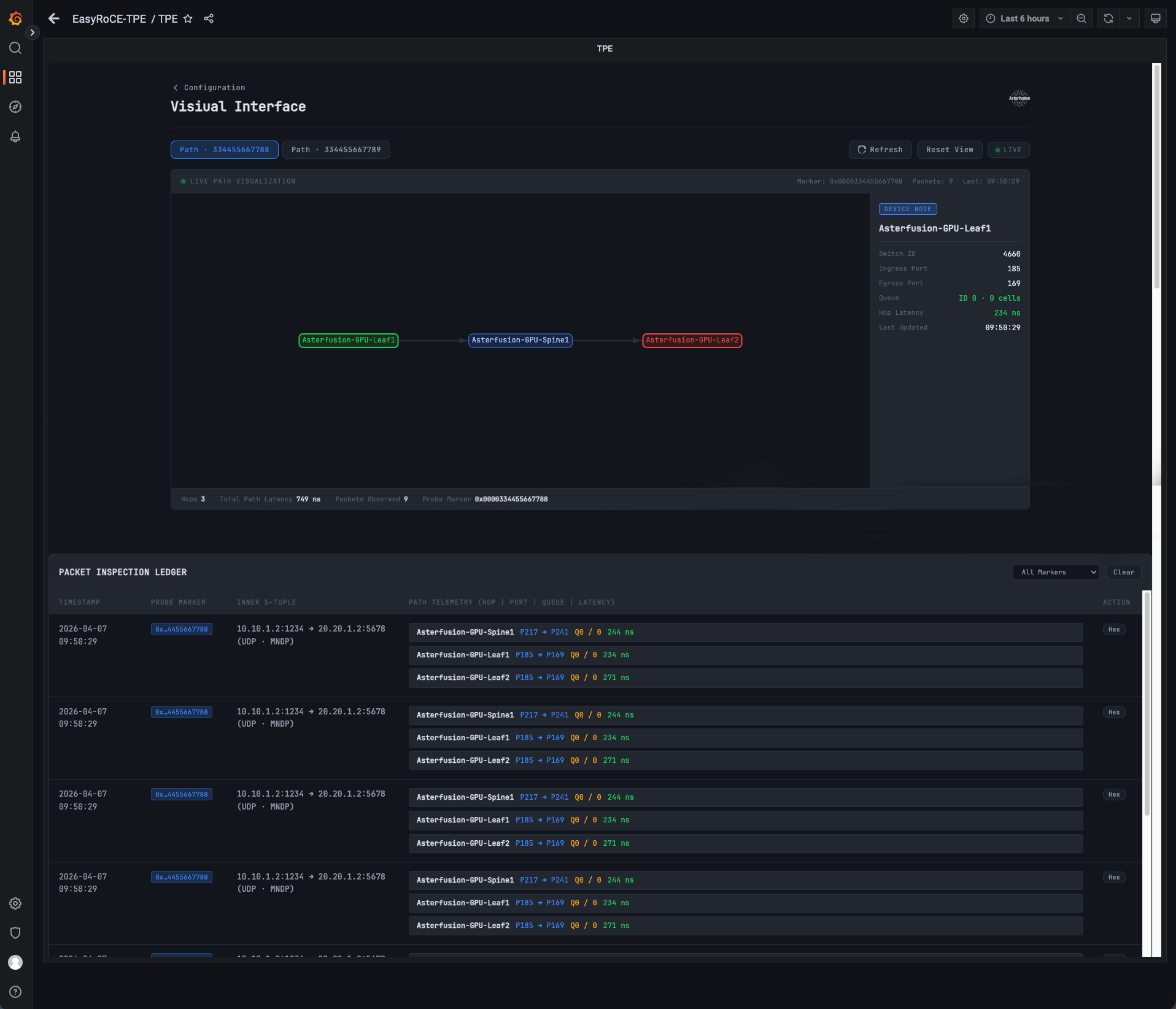
完成配置后点击可视化按钮 Visual Interface 即可跳转报文解析页面。
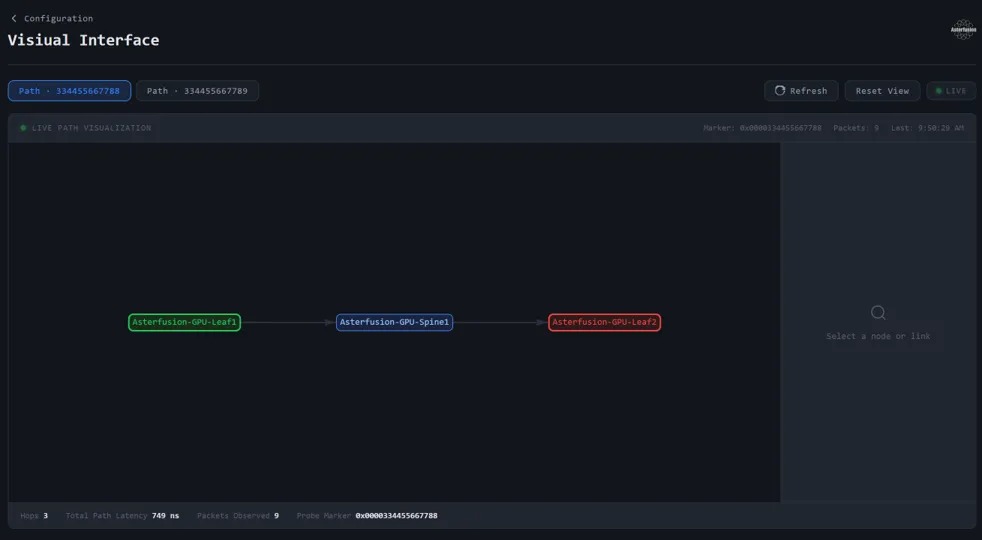
此时可以看到根据之前配置的信息生成的一条IPT路径。
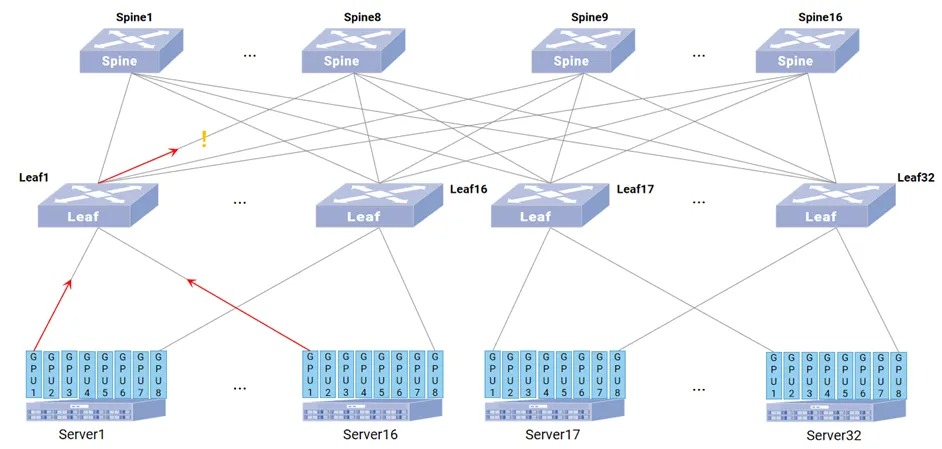
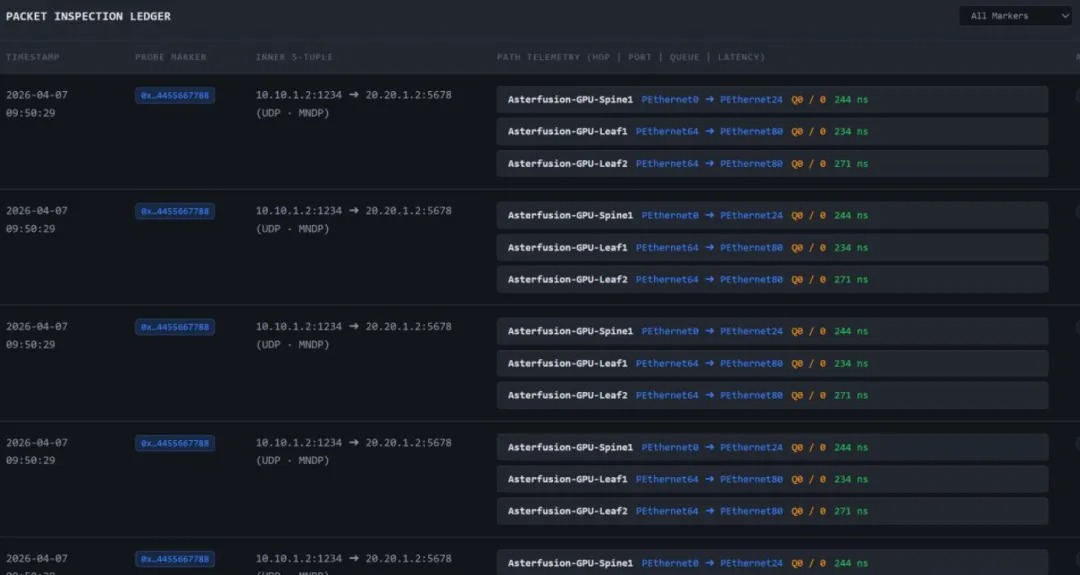
点击图上设备或者线路则能显示最新的IPT报文所展示的交换机的状态信息,下方则是 TPE 所解析的最新的 IPT 报文详情。