测试报告-HPC高性能计算测试方案(CX-N系列云交换机)
关注星融元

一位来自金融行业的客户,他们希望可以实时地模拟和响应风险,以实现企业金融风险管理能力的提升。事实上,不管是金融行业还是其他行业,要想加快步伐满足快速数字化世界中的客户需求,就必须能够比标准计算机更快地处理大量数据。高性能计算(HPC)解决方案,正在受到企业们的青睐。
HPC通用架构主要由计算、存储、网络组成,而HPC之所以能够提高计算速度,更多是采用了“并行技术”,使用多个计算机协同工作,采用十台、百台,甚至成千上万台计算机“并行工作”。各个计算机之间需要互相通信,并对任务进行协同处理,这就需要建立一套对时延、带宽等有着严格要求的高速网络。
高带宽、低时延和低资源使用率的RDMA模式(主要体系架构:InfiniBand协议和以太网协议),往往是HPC网络的最佳选择。而星融元CX-N 超低时延交换机(简称CX-N)采用了标准以太网协议和开放软硬件技术,支持无损以太网技术和网络无损防拥塞技术,充分满足用户HPC应用下对网络带宽、时延等的高要求。为验证这一事实,我们选用Mellanox的InfiniBand交换机,与其进行了相同HPC应用下的运行速度的对比测试。
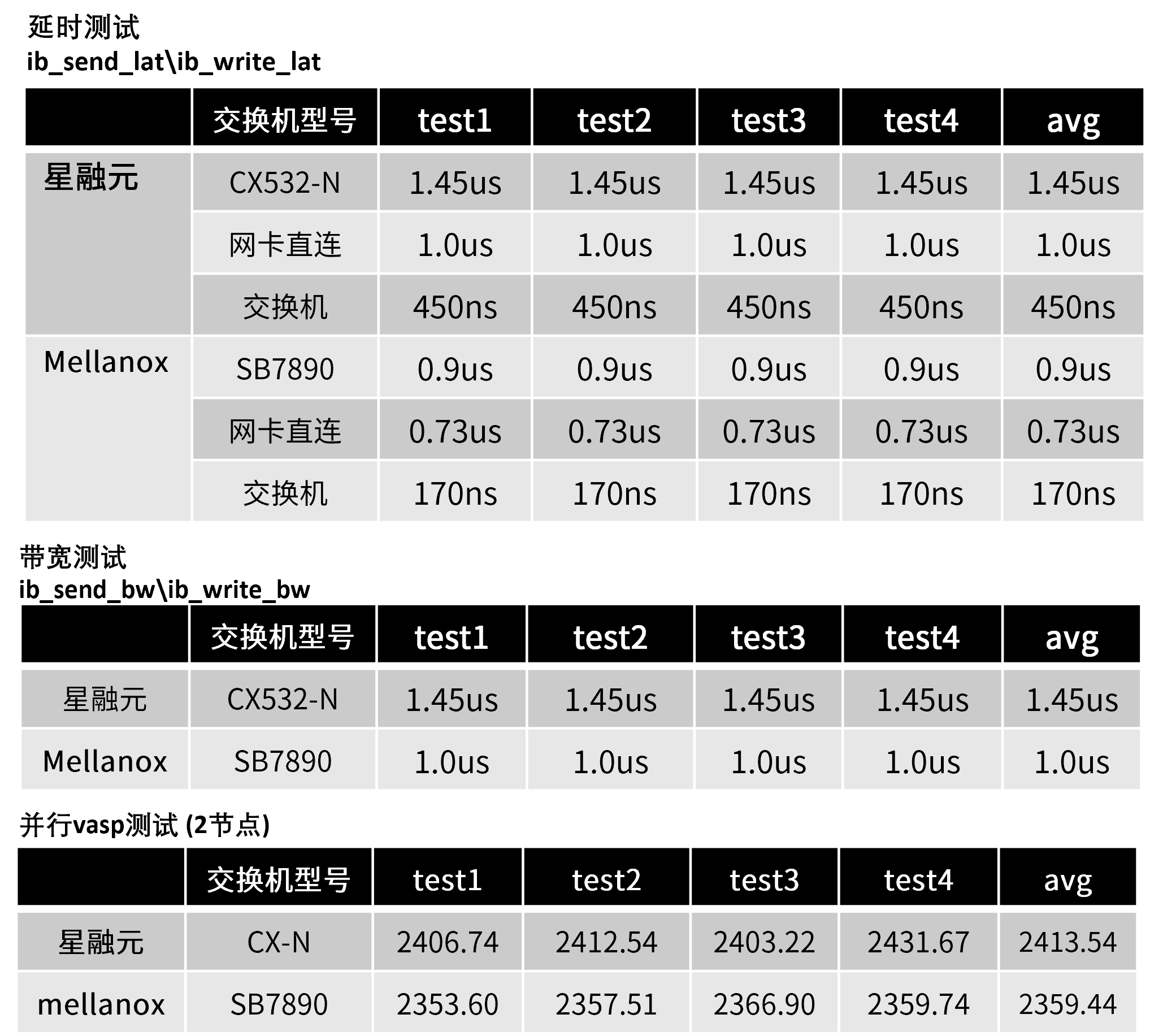
我们在CX-N和Mellanox的MSB7800交换机(简称IB交换机)分别搭建的网络上,进行了E2E转发测试、MPI基准测试和HPC应用测试。结果证明:CX-N 的时延和对方达到了同一个量级,运行速率较对方仅低3%左右,产品性能与对方交换机不相上下,能够满足绝大多数的HPC应用场景。而有必要补充一点的是,星融元更加注重产品成本的把控,星融元HPC解决方案在性价比方面有显著的优势。
HPC场景测试方案全过程:
1、目标与物理网络拓扑
- E2E转发测试
测试两款交换机在相同拓扑下E2E(End to End)的转发时延和带宽,本次方案测试点采用Mellanox IB发包工具进行发包,测试过程遍历2~8388608字节。 - MPI基准测试
MPI基准测试常用于评估高性能计算性能。本次方案测试点采用OSU Micro-Benchmarks来评估CX-N和IB两款交换机的性能。 - HPC应用测试
本次测试方案在每个HPC应用中运行相同任务,并比较CX-N和IB两款交换机的运行速度(时间更短)。
1.1 IB交换机物理拓扑
如上解决方案的IB交换机物理拓扑,如图1所示:
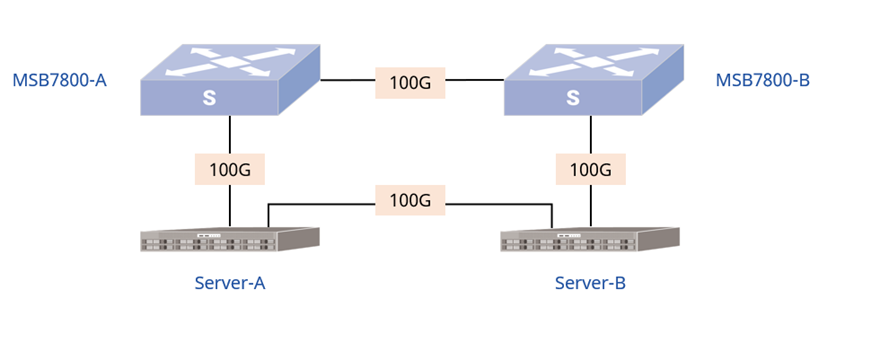
图1:IB交换机物理网络拓扑
1.2 CX-N物理拓扑
如上解决方案的CX-N物理拓扑,如图2所示:
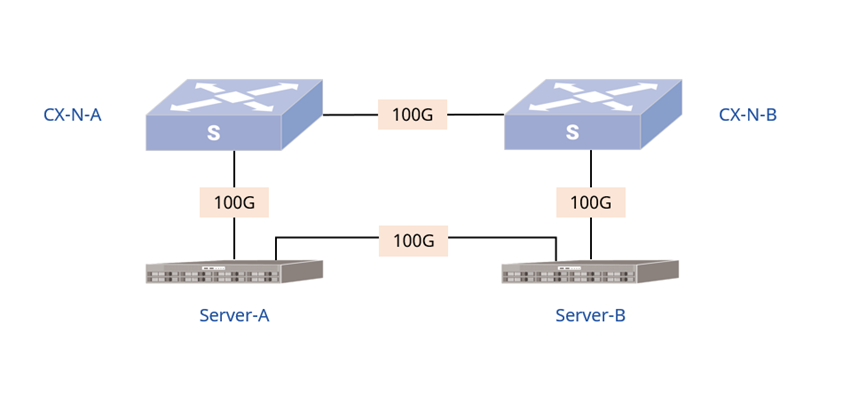
图2:CX-N物理网络拓扑
1.3 管理网口IP规划
部署过程中所涉及到的设备、接口及管理网口的IP地址如下表1所示:
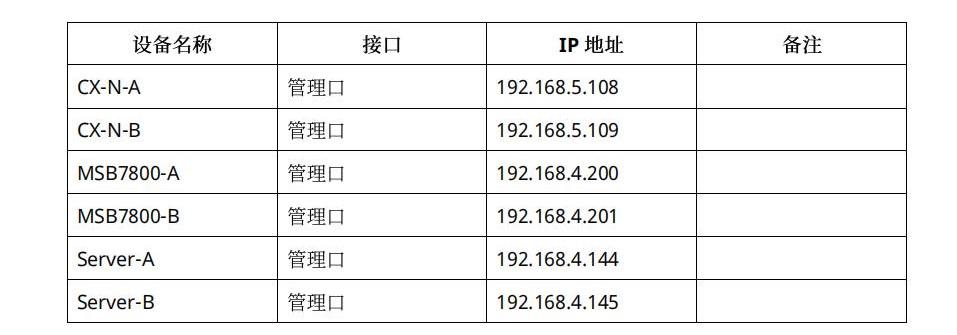
表1:设备管理口列表
2、 硬件和软件环境
部署环境中涉及到的硬件和软件如表2和表3所示:
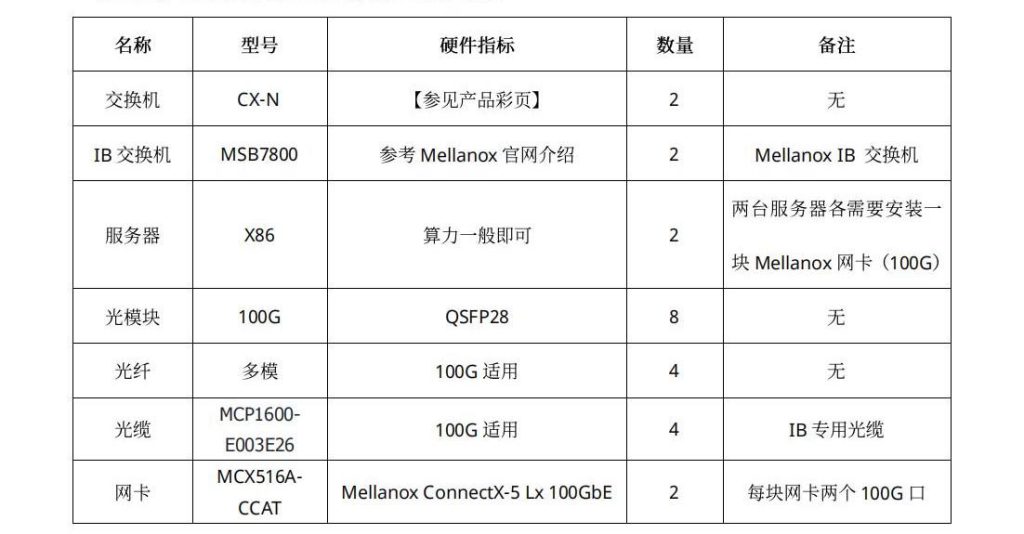
表2:硬件环境
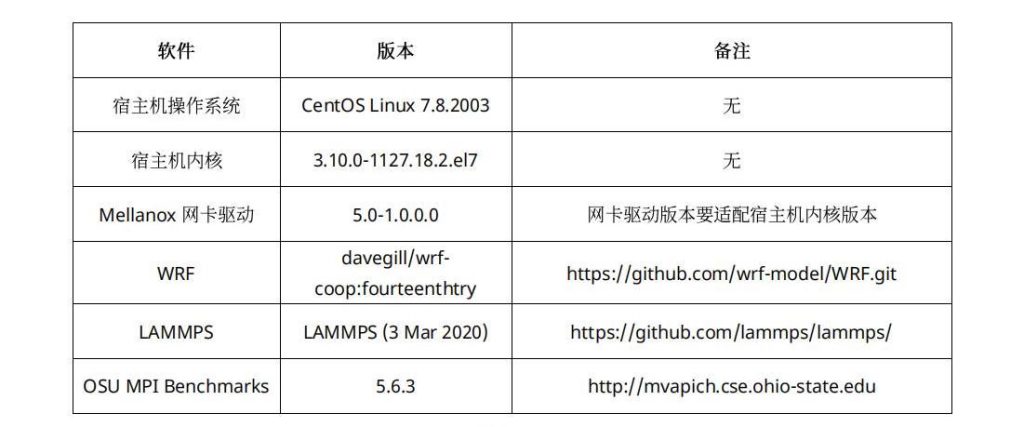
表3:软件环境
3、测试环境部署
在两台Server服务器上,安装部署HPC三种测试场景所需的基础环境。
补充说明:以”[root@server ~]#”为开头的命令表示两台服务器都要执行。
3.1 E2E转发测试环境部署
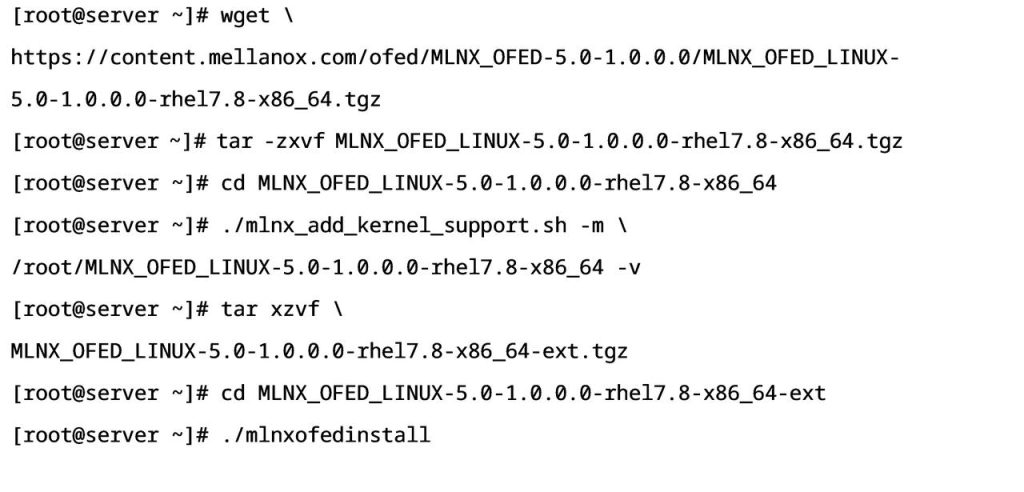
在两台Server服务器上安装Mellanox网卡的MLNX_OFED驱动程序,网卡驱动安装完成之后检查网卡及驱动状态,确保网卡可以正常使用。
- 网卡MLNX_OFED驱动程序安装:
- 检查网卡及网卡驱动状态:
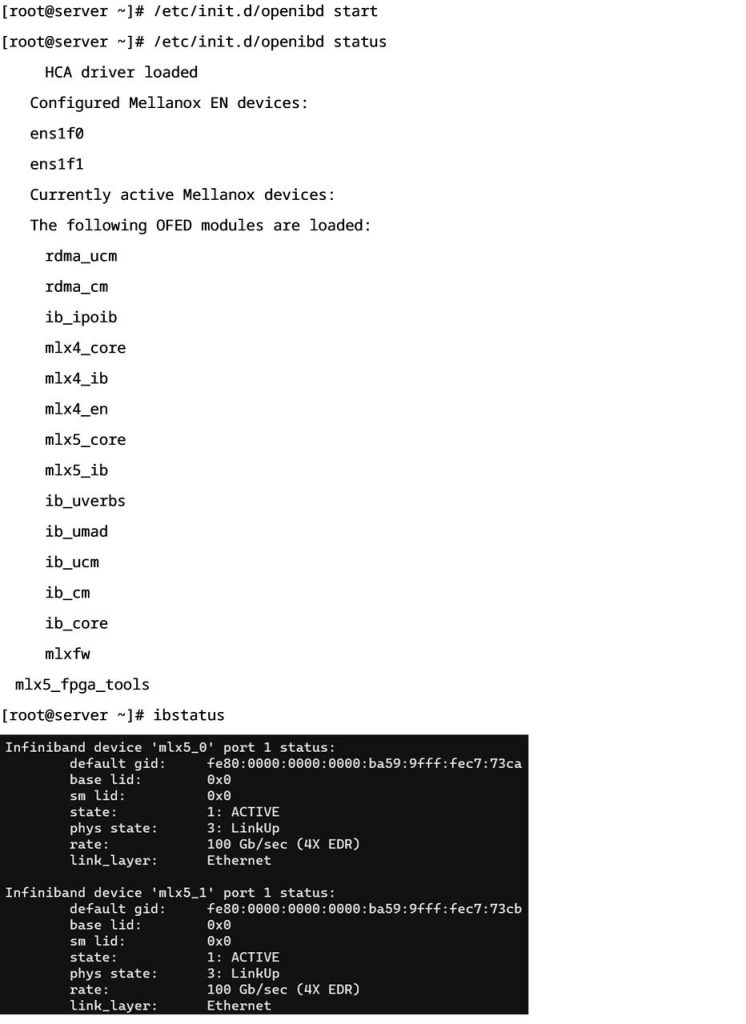
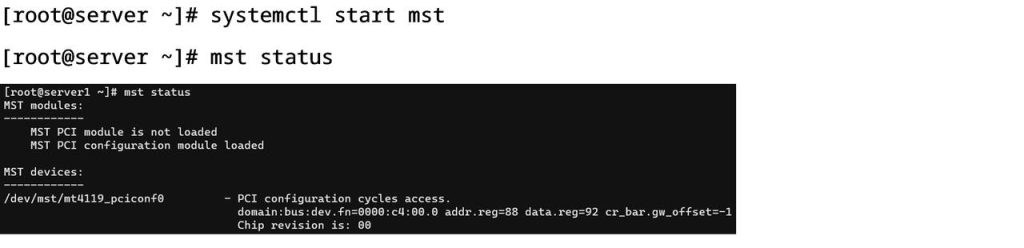
3.2 MPI基准测试环境部署
在两台Server服务器上安装HPC高性能集群基础环境,安装OSU MPI Benchmarks MPI通信效率测评工具,测试方式分为点对点通信和组网通信两种方式,通过执行各种不同模式的MPI,来测试带宽和时延。
- HPC集群高性能基础环境:
- OSU MPI Benchamarks工具安装

3.3 HPC应用测试环境部署
在两台Server服务器上安装HPC测试应用。本次方案部署WRF开源气象模拟软件和LAMMPS原子分子并行模拟器来进行数据测试。
WRF安装部署:
WRF全称Weather Research and Forecasting Model, 是一个天气研究与预报模型的软件。
- 修改Docker网络配置
本方案两台Server服务器WRF部署采用Docker容器部署,需要修改Docker配置文件,将虚拟网桥绑定到Mellanox网卡上,通过直接路由方式实现跨主机Docker容器通信。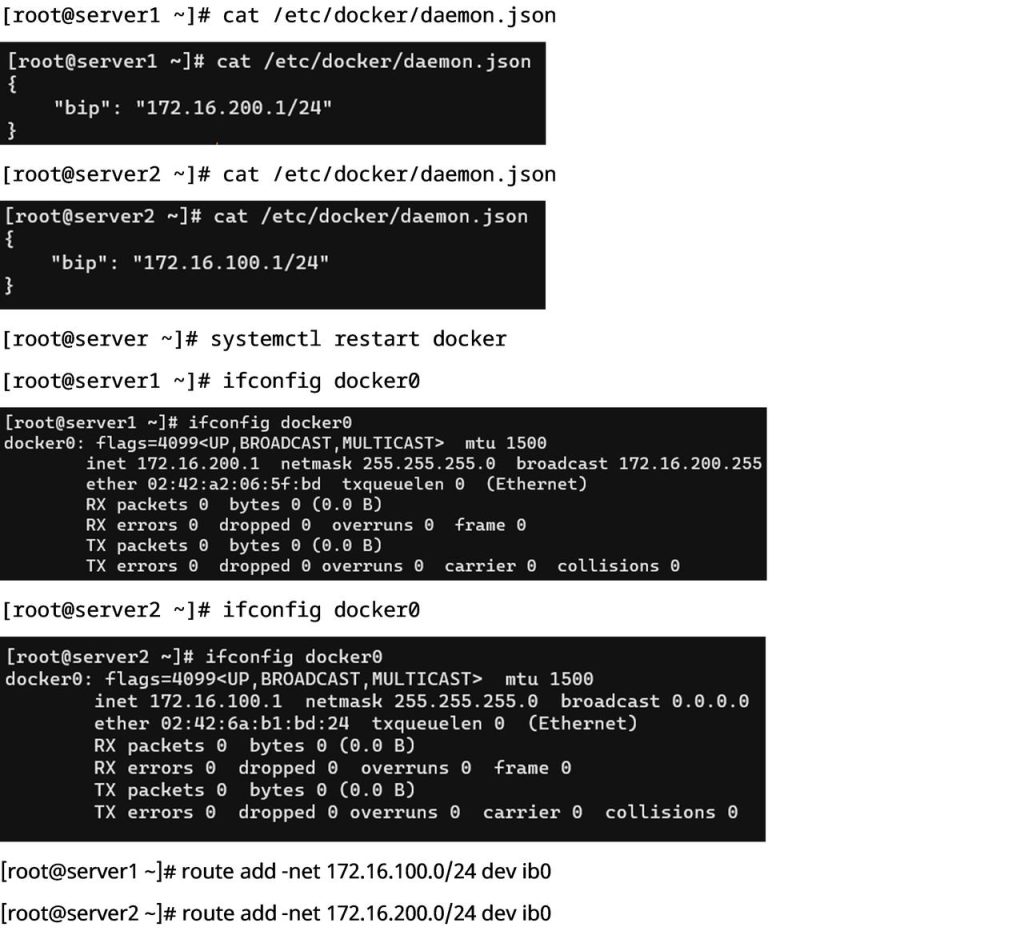
- WRF应用部署

- LAMMPS安装部署:LAMMPS即Large-scale Atomic/Molecular MassivelyParallel Simulator,大规模原子分子并行模拟器,主要用于分子动力学相关的一些计算和模拟工作。
- 安装GCC-7.3
- 安装OpenMPI
- 安装FFTW
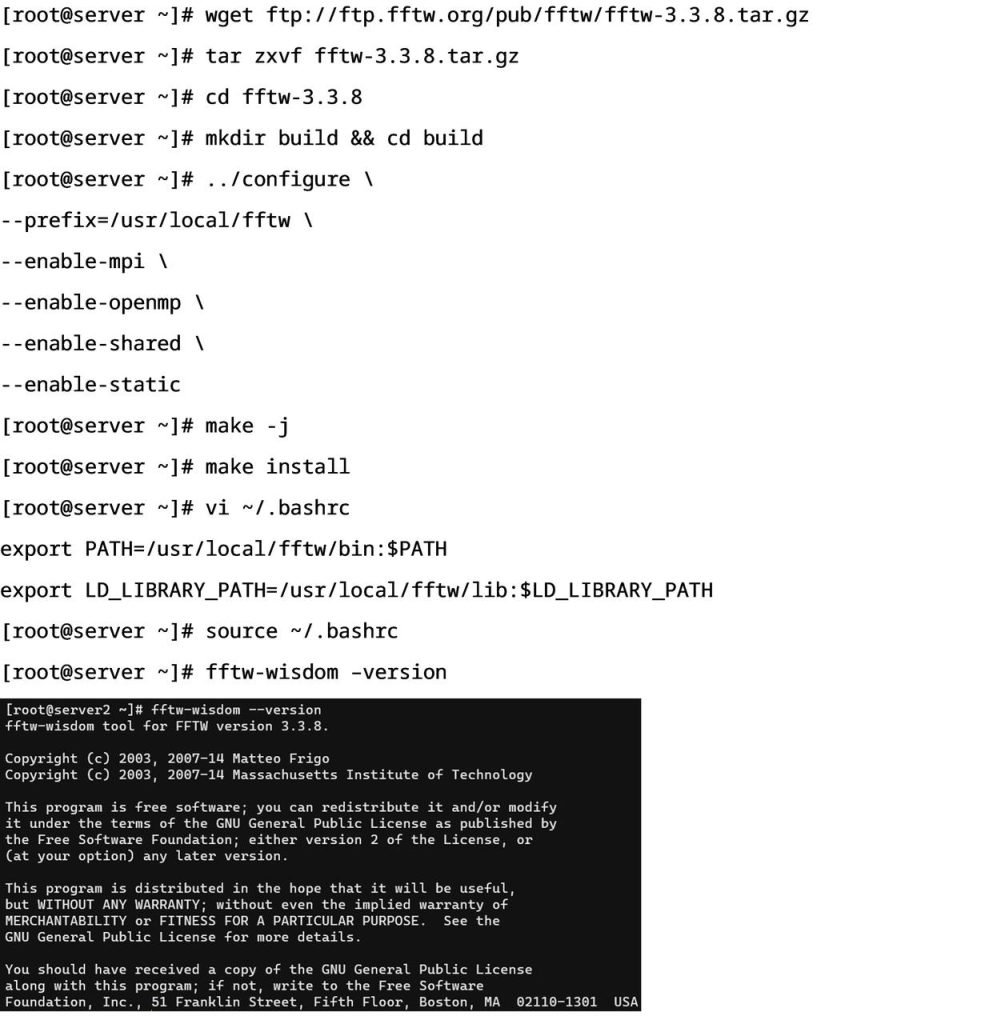
- 安装LAMMPS
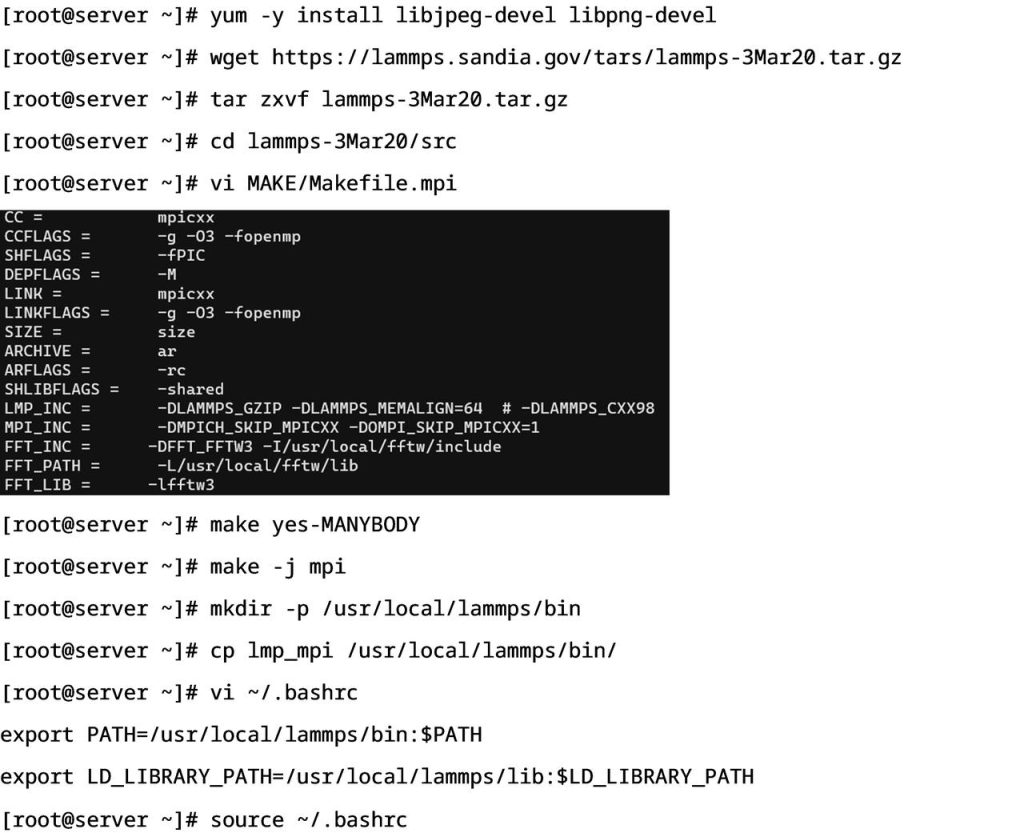
随着云计算技术的成熟,HPC正在从应用于大规模科学计算场景,转变为适用各种科学和商业计算场景。《星融元HPC解决方案》将重磅发布,敬请期待!
全文请注册/登录后获取:https://asterfusion.com/d-20220527/