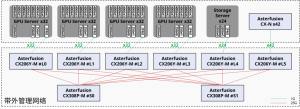
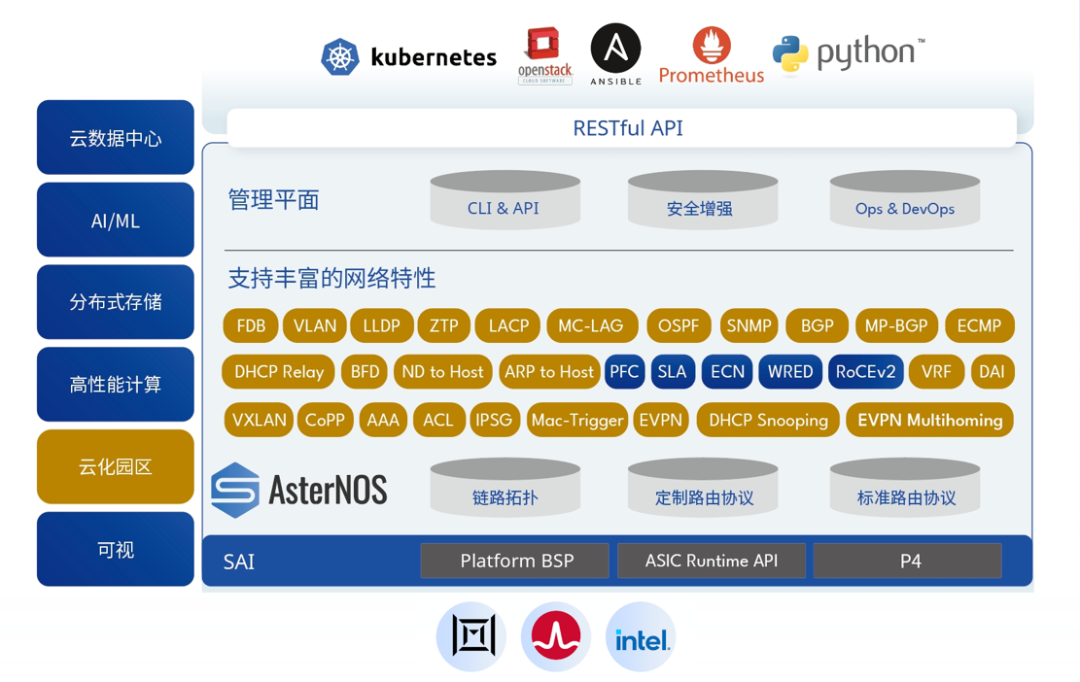
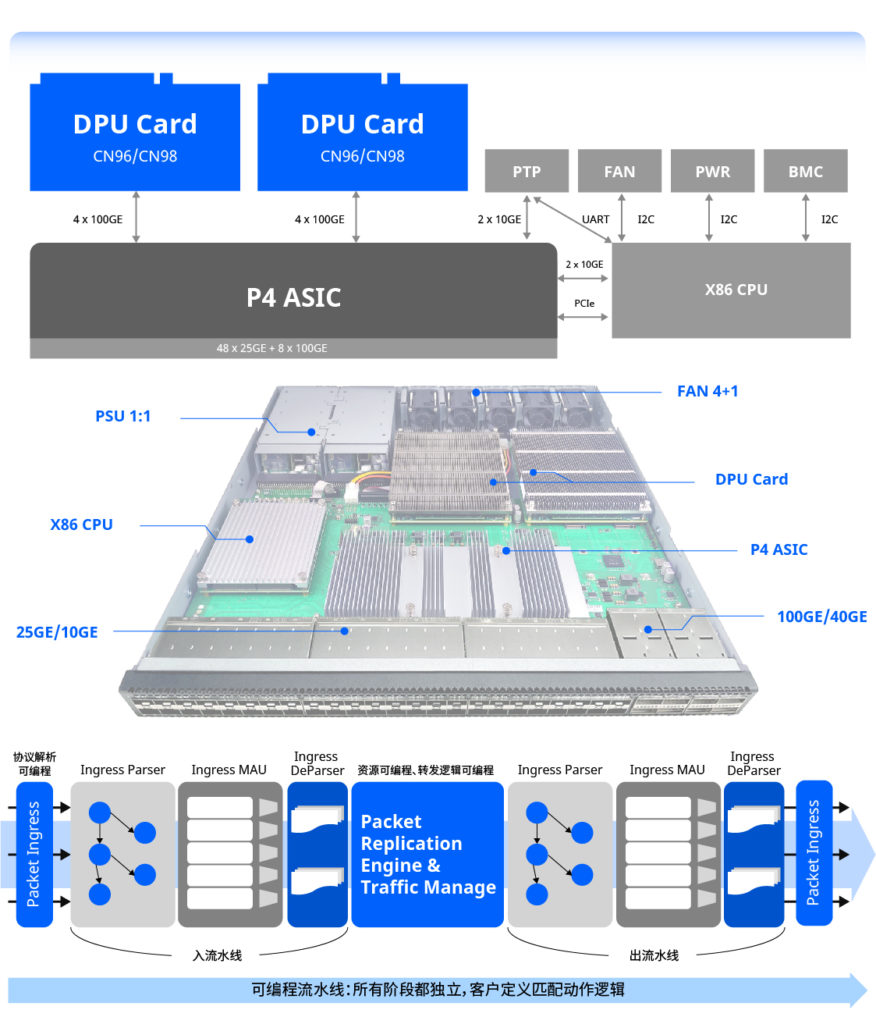
48 x 25GE,8 x 100GE/40GE 32 x 100GE/40GE, 2 x 25GE 64 x 100GE/40GE, 2 x 25GE 32 x 400GE, 2 x 25GE X-T 部分款型支持搭载2块DPU架构的ARM算力扣卡,从而实现x86(SONiC/ONIE/ONL)+P4(可编程高性能硬转发)+ DPU(自定义软转发)的全栈可编程硬件架构,满足高校、科研院所和产业界承载各类创新应用所需。
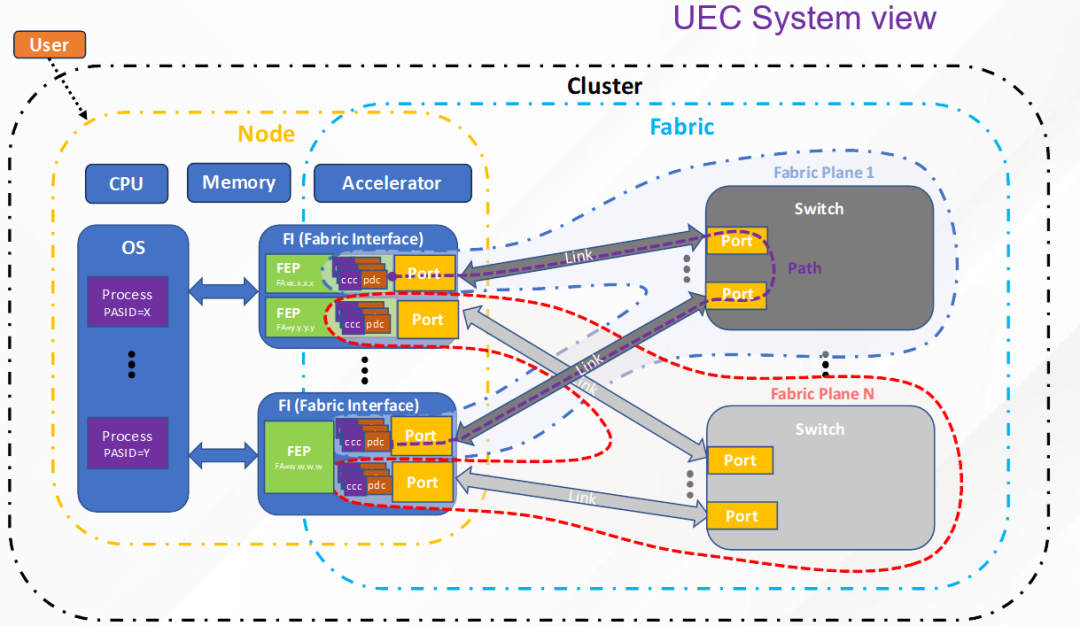
一个超级以太网系统的组成如下。一个集群(Cluster)由节点(Node)和网络(Fabric)组成,节点通过网卡(Fabric Interface)连接到网卡,一个网卡中可以有多个逻辑的网络端点(Fabric End Point,FEP)。网络由若干平面(Plane)组成,每个平面是多个FEP的集合,通常通过交换机互联。
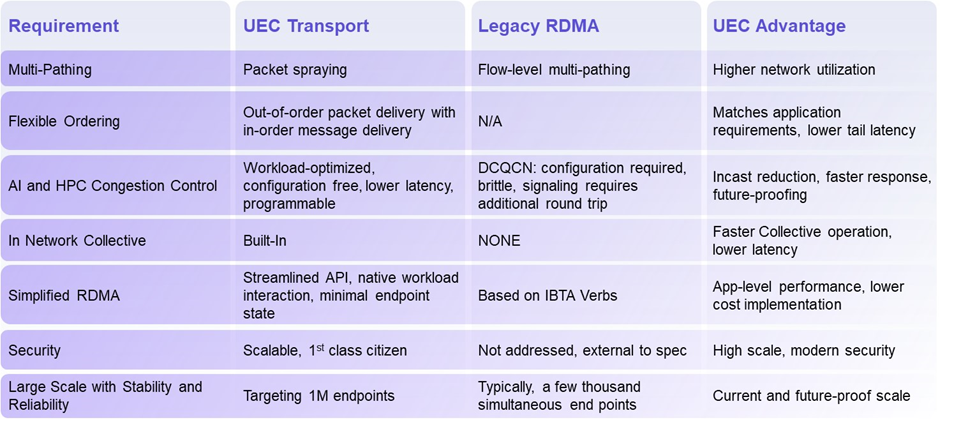
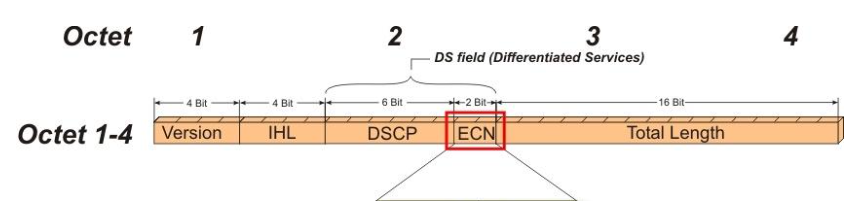
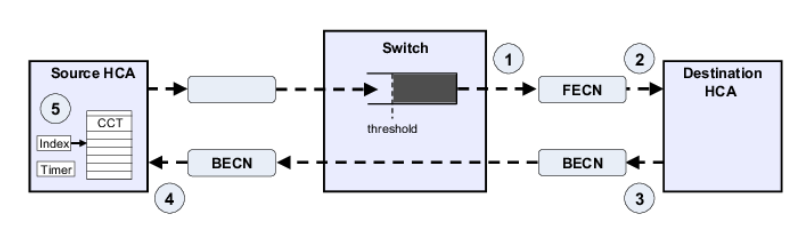
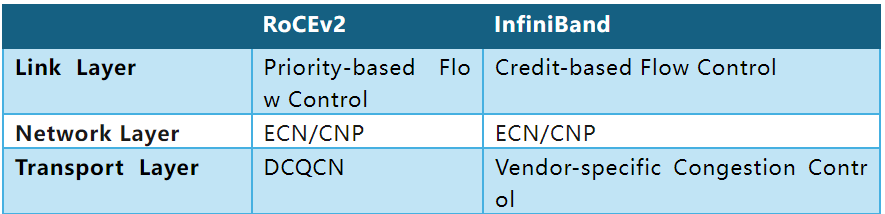
DCQCN(Data Center Quantized Congestion Notification)是一种适用于RoCEv2的拥塞控制算法,是数据中心TCP(DCTCP)和量化通知算法的结合,最初在SIGCOMM’15论文”Congestion control for large scale RDMA deployments”中提出。DC-QCN算法依赖于交换机端的ECN标记。结合了ECN和速率限制机制,工作在传输层。当接收方检测到ECN标记时,触发CNP发送给发送方,发送方根据反馈调整发送速率,从而缓解拥塞。
LLM 训练是一项 GPU 高度密集型工作负载,对 CPU 工作负载要求低。CPU 运行是一些简单任务,例如 PyTorch ,控制 GPU 的其他进程、初始化网络和存储调用,或者运行虚拟机管理程序等。Intel CPU 相对更容易实现正确的 NCCL 性能和虚拟化,而且整体错误更少。如果是采用AMD CPU ,则要用 NCCL_IB_PCI_RELAXED_ORDERING 并尝试不同的 NUMA NPS 设置来调优。
2、 RAM 降级到 1 TB
RAM 同样是计算节点中相对昂贵的部分。许多标准产品都具有 2TB 的 CPU DDR 5 RAM,但常规的AI工作负载根本不受 CPU RAM 限制,可以考虑减配。
3、删除 Bluefield-3 或选择平替
Bluefield-3 DPU最初是为传统 CPU 云开发的,卖点在于卸载CPU负载,让CPU用于业务出租,而不是运行网络虚拟化。结合实际,奔着GPU算力而来的客户无论如何都不会需要太多 CPU 算力,使用部分 CPU 核心进行网络虚拟化是可以接受的。此外Bluefield-3 DPU 相当昂贵,使用标准 ConnectX 作为前端或采用平替的DPU智能网卡完全可满足所需。
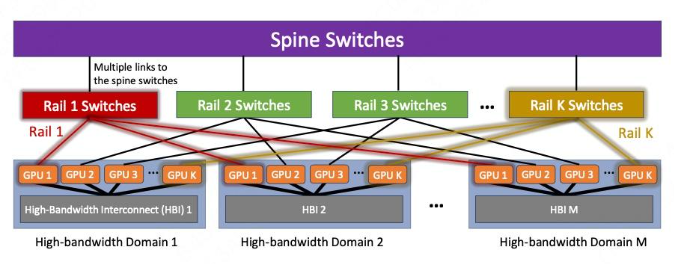
轨道优化拓扑的另一个好处可以超额订阅(Oversubscription)。在网络架构设计的语境下,超额订阅指的是提供更多的下行容量;超额订阅率即下行容量(到服务器/存储)和上行带宽(到上层Spine交换机)的比值,在 Meta 的 24k H100 集群里这个比率甚至已经来到夸张的7:1。
通过设计超额订阅,我们可以通过突破无阻塞网络的限制进一步优化成本。这点之所以可行是因为 8 轨的轨道优化拓扑里,大多数流量传输发生在 pod 内部,跨 pod 流量的带宽要求相对较低。结合足够好的自适应路由能力和具备较大缓冲空间的交换机,我们可以规划一个合适的超额订阅率以减少上层Spine交换机的数量。
但值得注意的是,无论是IB还是RoCEv2,当前还没有一个完美的方案规避拥塞风险,两者应对大规模集合通信流量时均有所不足,故超额订阅不宜过于激进。(而且最好给Leaf交换机留有足够端口,以便未来 pod 间流量较大时增加spine交换机)
在 TWT 中,客户端和 AP 之间会商定一个时间表,该时间表由时间段组成。它通常包含一个或多个信标(例如几分钟、几小时,甚至长达几天)。当时间到了,客户端被唤醒,等待 AP 发送的触发帧并交换数据,然后重新进入休眠状态。AP 和终端设备会独立协商特定时间,或者 AP 可以将终端进行分组,一次连接到多个设备。
Wi-Fi 6E 及其他
在 Wi-Fi 6 标准发布一年后,由于频谱短缺,Wi-Fi 6e 应运而生,将现有技术扩展到 6GHz 频段。Wi-Fi 6E 使用 WPA3 代替传统的 WPA2 来增强安全性,但它仍然使用 802.11ax,因此它算作 WiFi 6 的附加增强功能,而不是下一代标准。
Mesh组网在难以或无法布线的情况下特别有用,例如临时的室内或室外区域、老旧历史建筑内等。目前已有不少厂商提供了面向企业和家庭的Mesh网络解决方案,不过一般来说无线 Mesh AP 不兼容多供应商。
在为较小的区域设计无线Mesh网络时,我们可能只需要将一两个Mesh AP连接到有线网络,如果范围扩大,我们仍然需要将多个Mesh AP 插入有线网络以确保网络可用性。部署Mesh AP 时,应综合考虑数量、传输距离和电源位置,并且应将它们放置得更近以获得更好的信号,因此往往需要更多的 AP 来覆盖给定的区域,成本随之上升(甚至会抵消其他方面节省的费用)。


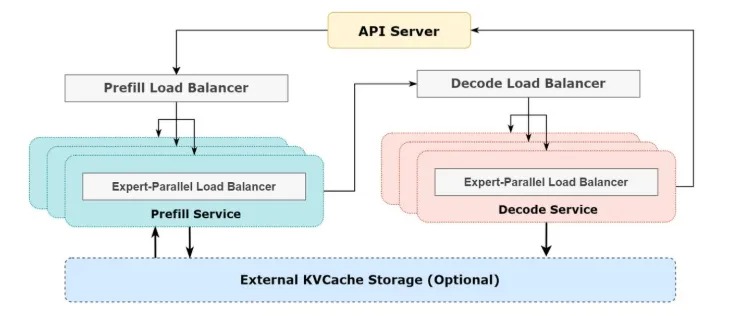

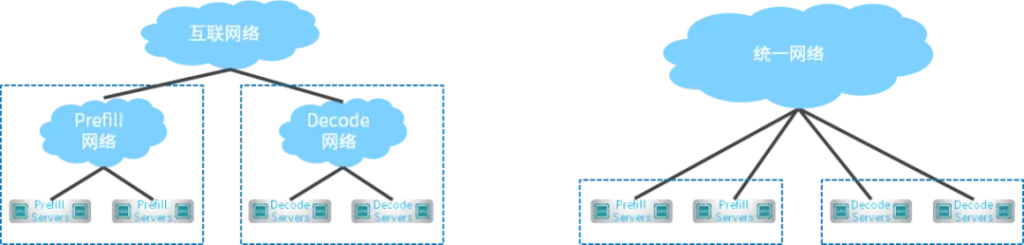
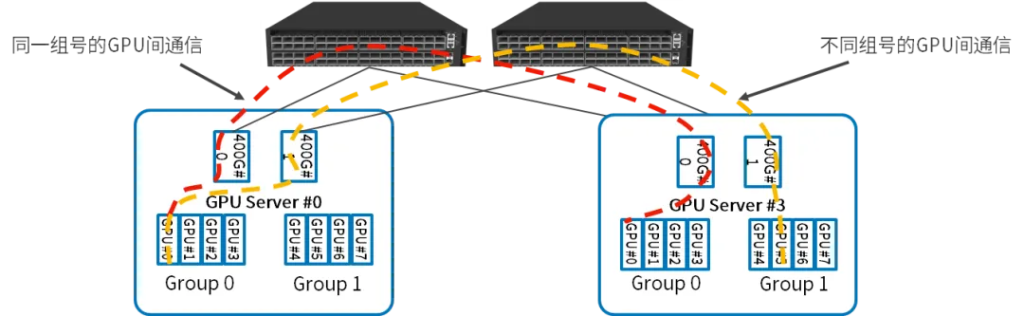
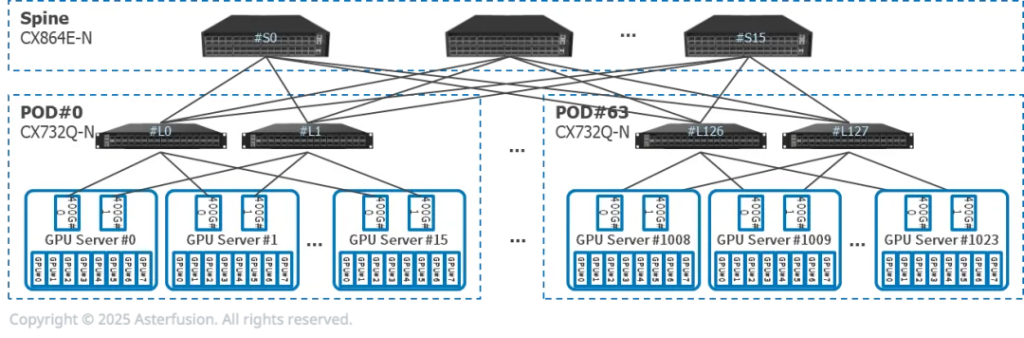
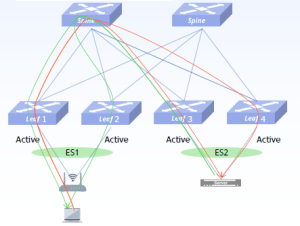
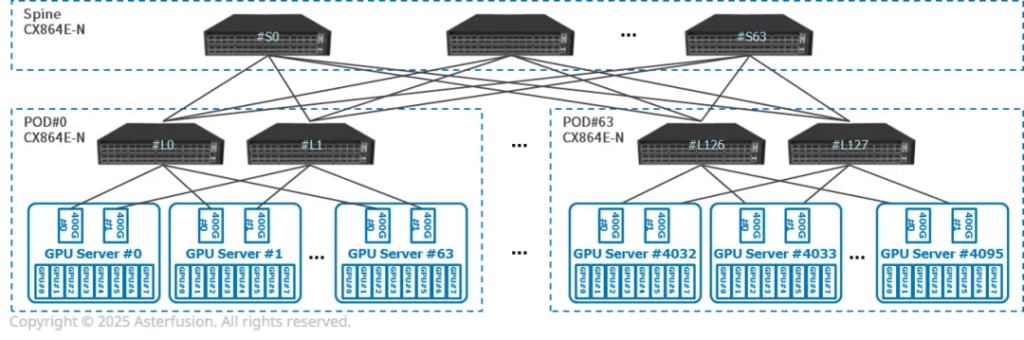 每台推理服务器有8张GPU,2张400G网卡,双归连接到两台CX864E-N
每台推理服务器有8张GPU,2张400G网卡,双归连接到两台CX864E-N
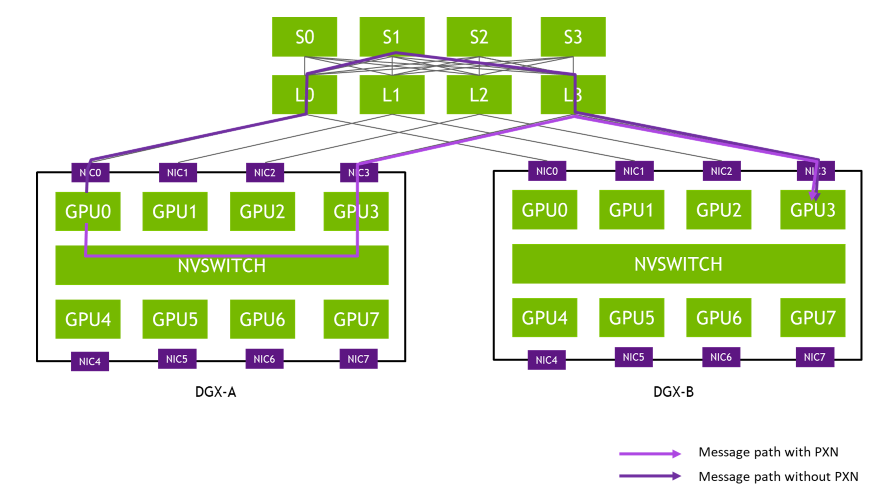








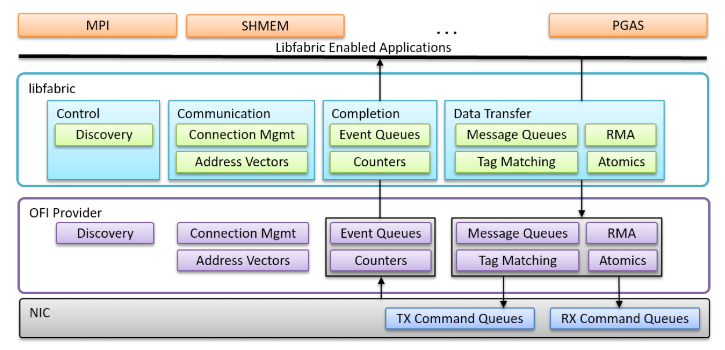
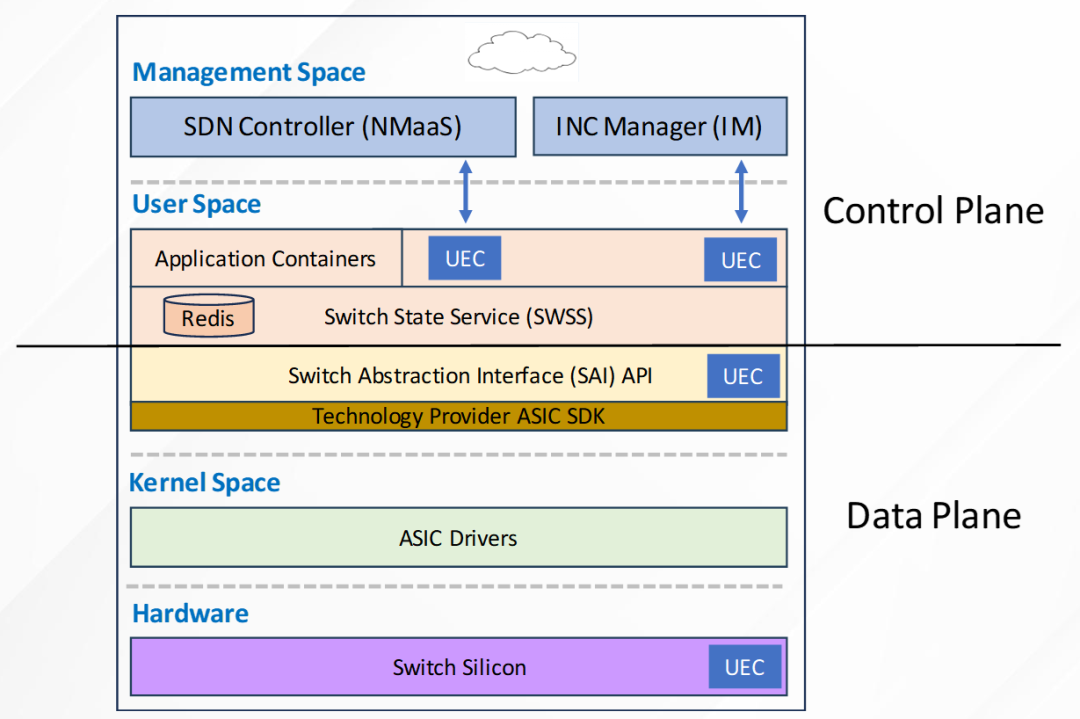
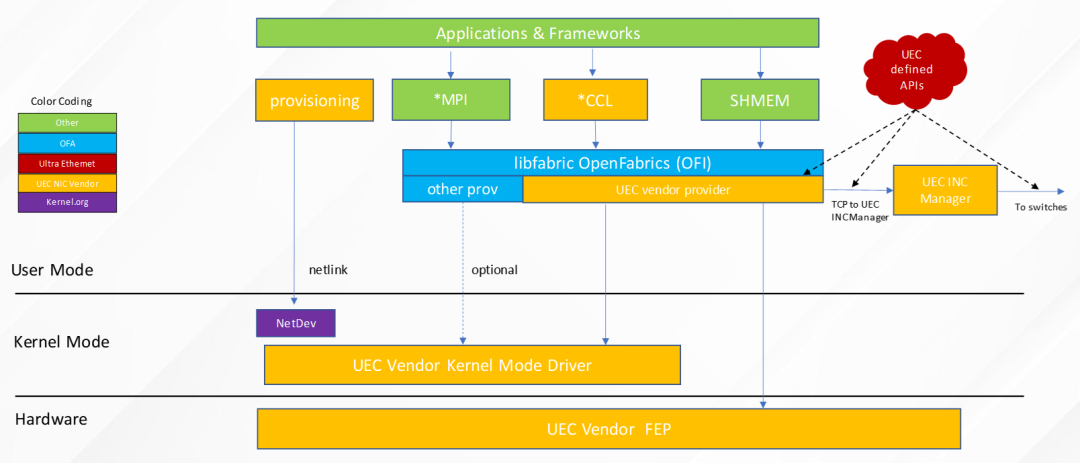

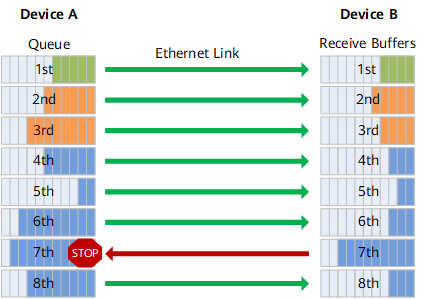










架构-300x137.png)
CX864E-N交换机1-300x159.png)
CX864E-N交换机2-300x106.png)
星智AI网络解决方案-300x109.png)

2-300x109.png)
1-300x87.png)
2-300x106.png)