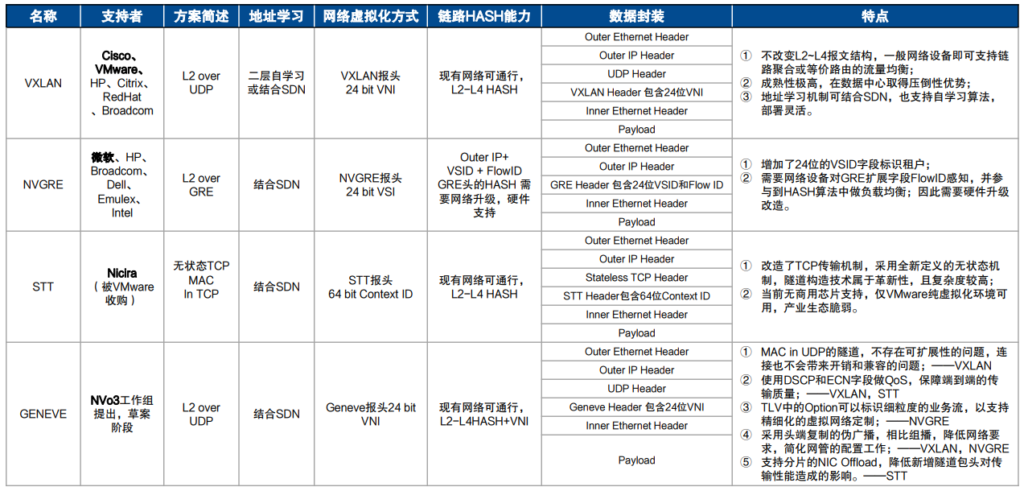
什么是分布式机框DDC?
DDC,Disaggregated Distributed Chassis的概念指使用若干个低功耗盒式设备组成的集群替换框式设备业务线卡和网板等硬件单元,盒式设备间通过线缆互联形成集群。整个集群通过集中式或者分布式的NOS(网络操作系统)管理,以期突破DCI单框设备性能和功耗瓶颈的问题。
-图1.png)
分布式机框方案的优势和劣势?
降低单点功耗:多台低功耗的盒式设备分散部署,解决了功耗集中的问题
传统的机框式交换机随着交换芯片技术的不断提升,交换容量越来越大,端口从 100G 逐步过渡到400G。但随之而来的是交换机功耗的大幅提升,16 槽位的机框交换机,全400G 端口需要4-5 万瓦的电力供应,这对老机房的设备选代升级带来巨大挑战,部分机房机柜电力无法满足需求。
突破框式设备扩容限制:通过多设备集群实现扩容,不受机框尺寸限制;
降低单点功耗:多台低功耗的盒式设备分散部署,解决了功耗集中的问题,降低机柜电力和散热的要求;
提升带宽利用率:与传统的ETH网Hash交换相比,DDC采用信元(Cell)交换,基于Cell进行负载均衡,有助于提升带宽利用率;
缓解丢包:使用设备大缓存能力满足DCI场景高收敛比要求。先通过VOQ(Virtual Output Queue)技术先将网络中接收到的报文分配到不同的虚拟出队列中,再通过Credit通信机制确定接收端有足够的缓存空间后再发送这些报文,从而减少由于出口拥塞带来的丢包。
当然,以上只是有关厂家对外宣称的说法,对此也有业内人士提出了质疑,总结了DDC方案的四大缺陷。
缺陷一:不可靠的设备管控平面
框式设备各部件通过硬件高度集成、可靠性极高的PCIe总线实现控制管理面互联,并设备都使用双主控板设计,确保设备的管控平面高可靠。DDC则使用“坏了就换”的易损模块线缆互联,构筑多设备集群并支撑集群管控平面运行。虽突破了框式设备的规模,但这种不可靠的互联方式给管控面带来了极大风险。两台设备堆叠,异常时会出现脑裂、表项不同步等问题。对于DDC这不可靠的管控平面而言,这种问题更容易发生。
缺陷二:高度复杂的设备NOS
SONiC社区已有基于VOQ架构下的分布式转发机框设计,并持续迭代补充和修改以便于满足对DDC的支持。虽然白盒确实已经有很多落地案例,但“白框”却少有人挑战。构筑一个拉远的“白框”,不仅仅需要考虑集群内多设备的状态、表项信息的同步和管理,还需要考虑到版本升级、回滚、热补丁等多个实际场景在多设备下的系统化实现。DDC对集群的NOS复杂度要求指数级提升,目前业界没有成熟商用案例,存在很大的开发风险。
缺陷三:可维护方案缺失
网络是不可靠的,因此ETH网络做了大量可维护和可定位的特性或工具,比如耳熟能详的INT、MOD。这些工具可以对具体的流进行监控,识别丢包的流特征,从而进行定位排障。但DDC使用的信元仅是报文的一个切片,没有相关IP等五元组信息,无法关联到具体的业务流。DDC一旦出现丢包问题,当前的运维手段无法定位到丢包点,维护方案严重缺失。
缺陷四:成本提升
DDC为突破机框尺寸限制,需要将集群的各设备通过高速的线缆/模块互联;互联成本是远高于框式设备线卡和网板之间通过PCB走线和高速链接器互联,且规模越大互联成本越高。
同时为降低单点功耗集中,通过线缆/模块互联的DDC集群整体功耗高于框式设备。相同一代的芯片,假设DDC集群设备之间用模块互联,集群功耗较框式设备高30%。
AI场景下,DDC方案能否应对?
AI网络支撑的业务其特征是流数量少,单条流的带宽大;同时流量不均匀,经常出现多打一或者多打多的情况(All-to-All和All-Reduce)。所以极易出现流量负载不均、链路利用率低、频繁的流量拥塞导致的丢包等问题,无法充分释放算力。
根据上文,DDC使用信元交换将报文切片成Cells,并根据可达信息采用轮询机制发送,流量负载会较为均衡的分配到每一条链路,实现带宽的充分利用,这可以解决DCN中大小流的问题,仍然存在相当多的缺陷。
-图2.png)
缺陷一:硬件要求特定设备,封闭专网不通用
DDC架构中的信元交换和VOQ技术,均依赖特定硬件芯片实现。DCC依赖硬件并通过私有的交换协议构建了一张封闭的专网并不通用,给后续运维以及升级扩容造成困难。
缺陷二:大缓存设计增加网络成本,不适合大规模DCN组网
DDC方案除去高昂的互联成本外,还背负着芯片大缓存的成本负担。DCN网络当前均使用小缓存设备,最大仅64M;而源于DCI场景的DDC方案通常芯片的HBM达到GB以上。
缺陷三:静态时延增加
DDC的大缓存能力将报文缓存,势必增加硬件转发静态时延。同时信元交换,对报文的切片、封装和重组,同样增加网络转发时延。通过测试数据比较,DDC较传统ETH网转发时延增大1.4倍。显然不适应AI计算网络的需求。
缺陷四:DC规模增大,可靠性下降
DDC进入DCN需要满足更大的一个集群,至少要满足一个网络POD。这意味着这个拉远的“框“,各个部件距离更远。那么对于这个集群的管控平面的可靠性、设备网络NOS的同步管理、网络POD级的运维管理要求更高。
全盒式的分布式组网方案
-图3.png)
-图4.png)
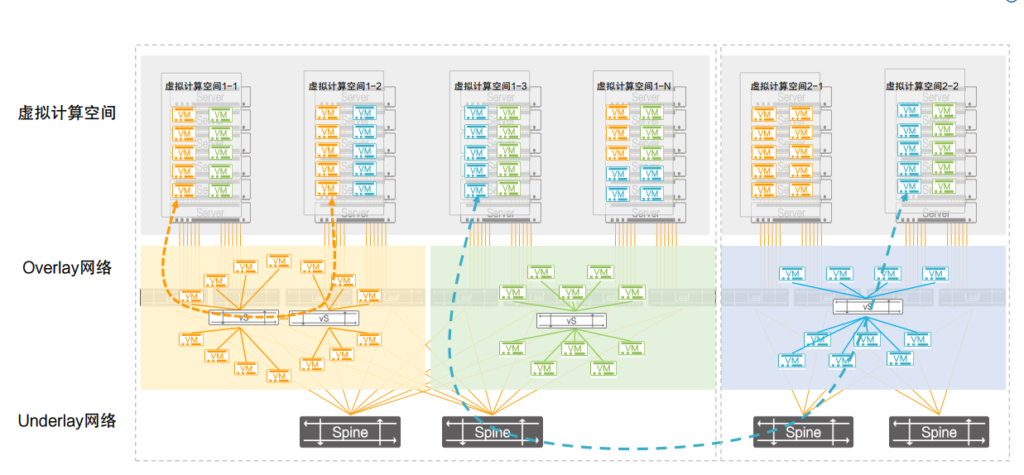
区别于DDC方案本质上仍是一个被拆解的”机框”,星融元的分布式组网则将解耦这件事做得更彻底——依靠高密度、大容量的盒式设备+专利的分布式算法,将禁锢在机箱内的CLOS架构分布到网络中,将网络的规划、部署、调整、优化,这些的主动权交还给用户,大幅降低建设成本,提升可扩展性,轻松实现千万级虚机规模的网络部署
数据面:支持专利的分布式路由算法PICFA,所有交换机能力整合为一个超级的“分布式虚拟路由表”,支持大规模组网扩展
在部署了PICFA的云网络中,所有租户的所有虚拟网络信息被动态、智能、均衡地分布在全网的所有Spine和Leaf交换机上,充分利用所有交换机的所有表项空间,由此,单台网络设备的FIB容量不再成为云的容量限制,虚拟机数量获得量级的提升,服务器计算力被充分利用。
控制面:采用ARP转主机路由的去堆叠方案,将路由分布到全网,Leaf仅保留直接接入VM的MAC表项,降低表项空间要求
Leaf交换机以上均采用L3路由,Leaf交换机仅需保存直接接入的虚机的MAC表项,有效的降低了Leaf交换机上的表项空间要求,也从另一个角度解决了Leaf交换机表项空间不足的问题
管理面:全网统一配置模板,支持ZTP零配置上线,即插即用,提高运维效率,全网分层简化配置,只需两个配置模板(Spine、Leaf)上线即插即用。
星融元全盒式组网在时延敏感网络场景的应用(以AIGC网络为例)
1、接入能力:网络架构横向扩展与存算分离
由于GPU资源本身稀缺的特性,尽可能多的把GPU资源集中在一个统一的资源池里面,将有利于任务的灵活调度,减少AI任务的排队、减少资源碎片的产生、提升GPU的利用率。要组成大规模GPU集群,网络的组网方式需要进行优化
-图11.png)
-图10-300x145.png)
-图14-300x222.png)
ToR交换机用于和GPU Server直接连接,构成一个Block;ToR交换机向上一层是Leaf交换机,一组ToR交换机和一组Leaf交换机之间实现无阻塞全连接架构,构成一个Pod;不同Pod之间使用Spine交换机连接。
- Block是最小单元,包括256个GPU
- Pod是典型集群规模,包括8个Block,2048个GPU
- 超过2048个GPU,通过Fabric-Pod模式进行扩展
2、高可用设计
可用性问题在GPU集群中要求不高,因为大规模分布式的AI任务基本都是离线的训练任务,网络中断不会对主业务造成直接影响。但是这不意味着网络可用性无需关注,因为一个AI训练持续的时间可能会很长,如果没有中间状态保存的话,网络中断就意味着前面花费时间训练出来的成果全部失效,所使用的GPU资源也全部被浪费。
考虑到AI训练任务对网络拓扑的高度敏感性,某一处网络的中断会导致其他节点网络的非对称,无限增加上层处理的复杂度,因此在设计集群的时候需要考虑中断容忍的网络架构。
-图15.png)
存储双上联
由于网络中断,导致一个存储节点下线,可能会在网络内触发大量数据恢复流量,增加网络负载,因此,建议采用双上联设计,确保某个交换机或上联链路中断不会影响存储节点的可用性。
计算单上行
如上文提及,综合性能与成本考虑,计算网暂不考虑双上联设计。
GPU网卡连接方式:同一个GPU Server上的8块卡连接到8个ToR,可以节省机间网络的流量,大部分都聚合在轨道内传输(只经过一级ToR),机间网络的流量大幅减少,冲击概率也明显下降,从而提供了整网性能。但是上面的方案,GPU Server上任何一个网卡或链接中断都会导致网络的非对称,整个GPU Server都会受到影响。所以干脆让所有网卡共享同一个交换机,好处是如果ToR交换机故障,影响到的GPU Server会尽可能少,从整个系统的角度出发,可用性反而提高了。
更多相关资讯:
客户案例:高性能、大规模、高可靠的AIGC承载网络
全以太网超低时延HPC网络方案 – 星融元Asterfusion
全闪分布式存储网络解决方案 – 星融元Asterfusion
本文参考:
http://www.cww.net.cn/article?id=577516
https://www.odcc.org.cn/download/24 DDC 技术白皮书2021
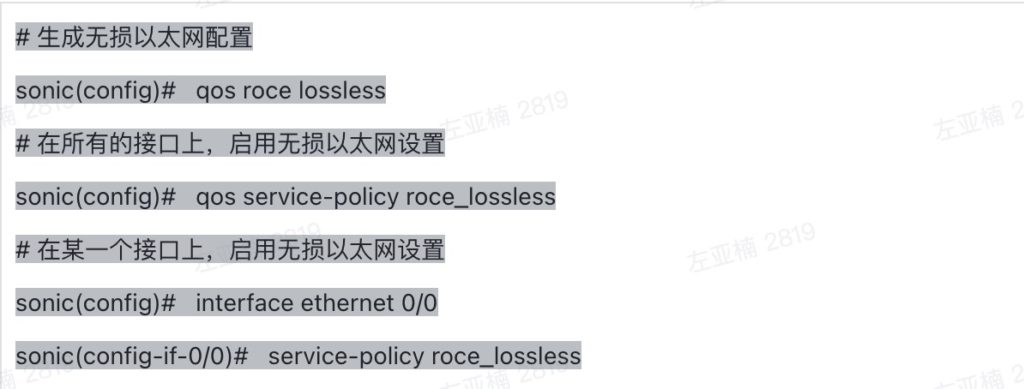

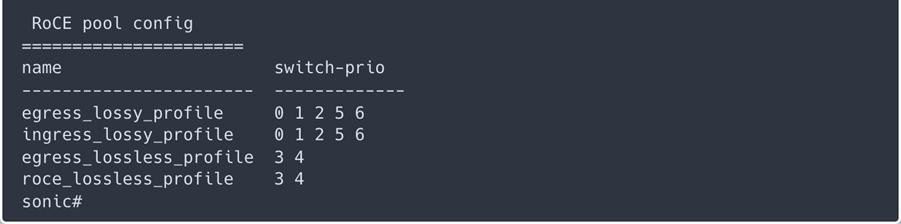
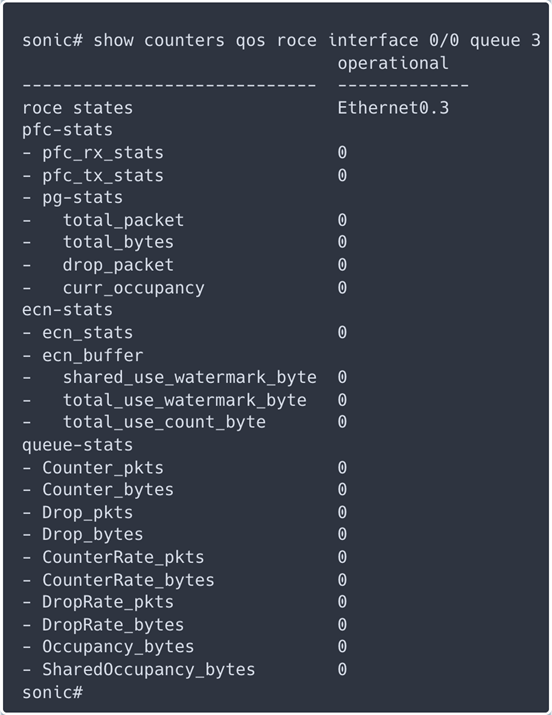



 如何计算公有云方案和与本地私有云的总体拥有成本(TCO)?
如何计算公有云方案和与本地私有云的总体拥有成本(TCO)? 洞察成本构成
洞察成本构成
-图1-1024x507.png)
-图2.png)

-图3-1024x220.png)
