从 SNMP 到 gRPC:详解网络遥测的技术演进与工作原理
近期文章
gRPC的背景
由于GPU、HPC等这类业务容易出现微突发的现象,运维人员需要快速检测到微突发的情况并且进行定位、调整。而传统的CLI、SNMP等网管手段不能很好满足自动化运维需求,这时需要有一种技术在不影响设备的性能和功能的情况下实现更高精度的数据监控。通过INT技术可以实现流量端到端转发路径的可视化,但无法对交换机的Buffer进行更全面的管理,包括出、入端口/队列缓存等实时监控。
什么是gRPC?
gRPC(Google Remote Procedure Call) 是一个高性能、开源且与语言无关的远程过程调用(RPC)框架,最初由 Google 开发并基于 HTTP/2作为传输协议、Protocol Buffers(protobuf) 作为接口描述语言(IDL)和消息交换格式。若是采用基于gRPC + Protocol Buffers的运维接口设计,可以很好地满足运维对单个网络网元全面的可视化和实时性要求。解决了传统 SNMP 协议“跑不快、看不清、管不了”的痛点。
传统的 SNMP 采用“轮询(Pull)”模式,网管系统就像个查水表的,每间隔5分钟就去敲一次交换机的门“请问1号端口流量是多少?”。如果交换机正在忙,或者监控的项目太多,这种方式会导致数据不准且响应滞后。
在现代网络操作系统(如 SONiC)中,gPRC在网络监控中的应用(gRPC Telemetry)采用“推送(Push)”模式。可以实现毫秒级的数据采集,交换机能主动推送结构化数据,极大地降低了 CPU 占用。
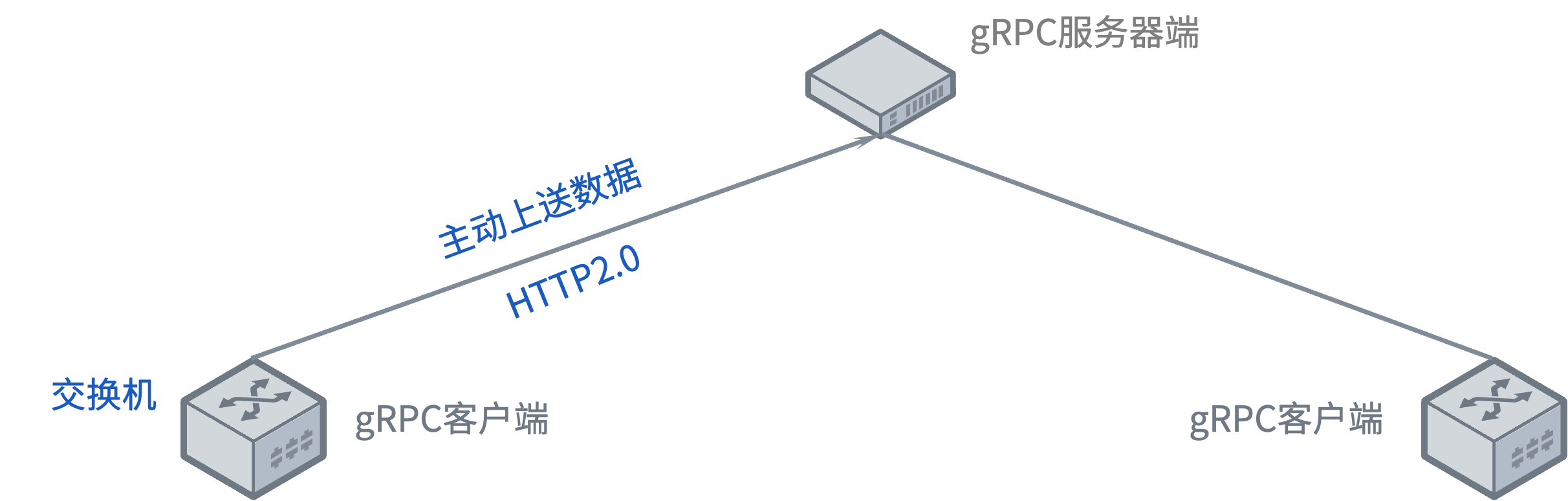
gRPC的交互方式
- 一次订阅,持续推送: 监控服务器只要向交换机发送一次订阅请求,交换机就会按照预设的时间间隔(比如每 100 毫秒)或在状态发生变化时,主动把数据塞给服务器。
- 极高的精细度: SNMP 很难做到秒级监控,而 gRPC 可以轻松实现毫秒级。这让你能捕捉到所谓的“微突发(Micro-burst)”流量,这在金融交易或高性能计算场景中至关重要。
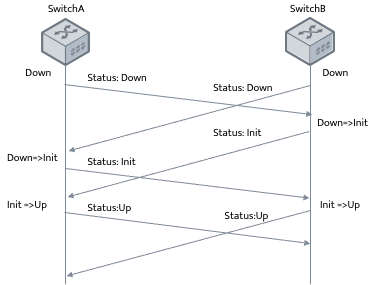
交换机在开启gRPC功能后充当gRPC客户端的角色,采集服务器充当gRPC服务器角色;交换机会根据订阅的事件构建对应数据的格式(GPB/JSON),通过Protocol Buffers进行编写proto文件,交换机与服务器建立gRPC通道,通过gRPC协议向服务器发送请求消息;服务器收到请求消息后,会通过Protocol Buffers解译proto文件,还原出最先定义好格式的数据结构,进行业务处理;数据梳理完后,服务器需要使用Protocol Buffers重编译应答数据,通过gRPC协议向交换机发送应答消息;交换机收到应答消息后,结束本次的gRPC交互。
上图展示的是gRPC交互过程的具体流程,也是Telemetry触发方式其中之一,称为Dial-out模式。
gRPC的工作原理
gRPC Telemetry 之所以快且准,是因为它解决了“语言不通”的问题。
1、Protobuf(数据压缩)
传统的网络管理数据(如 JSON 或 XML)包含大量冗余的标签。Protobuf 将数据转换为二进制流,体积通常只有 JSON 的 20%-50%。
通过 .proto 文件定义数据结构,交换机和控制器在“对话”前已经知道了数据的格式,解析速度非常快。
2、HTTP/2
gRPC 跑在 HTTP/2 之上,带来了几个关键特性,第一个多路复用,在同一个 TCP 连接上同时发送多个请求和响应,不再需要排队。第二双向流,交换机可以保持一个长连接,实时将接口流量、温度等数据源源不断地推送到监控平台。
3、交互流程
使用 YANG 模型(IDL)定义网络功能,并转换为 .proto 文件,服务器端运行gRPC Server,监听特定端口。客户端发起连接,订阅特定的数据路径(如/interfaces/interface/state/counters),交换机根据配置,一旦数据发生变化或达到时间间隔,立即封装成Portobuf并通过HTTP/2推送给客户端。
YANG 模型(数据建模) 它是网络设备的“说明书”。它规定了数据的层级结构(例如:接口名称 > 状态 > 输入字节数)。有了 YANG,开发者不再需要去查晦涩的 MIB 库。
SNMP vs gRPC(Telemetry)
| 特性 | SNMP | gRPC (Telemetry) |
|---|---|---|
| 模式 | Pull (轮询) | Push (主动推送) |
| 性能 | 消耗 CPU,延迟高 | 高效二进制,极低延迟 |
| 数据模型 | MIB (闭塞且难以维护) | YANG (结构化、标准化) |
| 安全性 | 弱 (即使是 v3 也复杂) | 强 (原生支持 TLS 加密) |
gRPC 与 YANG 模型驱动的自动化基石
在拥有数万节点、承载秒级万亿次请求的超大规模数据中心内,网络的容错空间几乎为零。面对万兆乃至 800G 的极速网络环境,传统 SNMP 协议频繁的请求/响应开销已成为交换机 CPU 不堪重负的枷锁。
gRPC 的引入彻底重构了监控范式:它依托 Protobuf 极高压缩率的二进制序列化技术,结合 HTTP/2 的多路复用能力,将网络遥测(Telemetry)的系统损耗降至微秒级,确保交换机算力能全量聚焦于线速转发。然而,单纯的“快”并不够,YANG 模型 为这些海量数据赋予了标准化的“灵魂”。只有当采集频率跨入毫秒级,且数据通过 YANG 实现高度结构化的语义定义时,自动化编排引擎才能在瞬息之间精准识别微突发拥塞,并在几毫秒内下发动态策略调整路由。
这种“高性能传输 + 标准化建模语言”的组合,不仅是效率的飞跃,更是实现自愈网络(Self-healing Network)的技术底座。