ECN:显式拥塞通知机制原理解析
近期文章
在网络通信中,拥塞是一个常见的问题,尤其是在高负载时期或网络拓扑结构不完善的情况下。传统的拥塞控制方法主要通过丢包来指示网络拥塞,当路由器的缓冲区满时,会丢弃数据包,发送方通过检测丢失的数据包来进行拥塞控制。然而,丢包会导致重传,增加网络负担,降低网络性能。
ECN(Explicit Congestion Notification)是一种改进后的拥塞控制方法,它不依赖于丢包来指示拥塞,而是在数据包的头部标记拥塞发生的信号。ECN通过向数据包的 IP 头部添加一个特殊的标记位告知发送方网络发生了拥塞。
ECN的工作原理
ECN 的工作原理可以分为三个主要阶段:标记、回传、响应。
- 标记(第一阶段):当路由器的缓冲区开始出现拥塞时,它会检查传入的数据包。如果缓冲区超过了某个阈值,路由器会修改数据包的 IP 头部,在其中设置 ECN 位,表示网络出现了拥塞。
- 回传(第二阶段):标记了 ECN 位的数据包继续在网络中传输,它们不会被丢弃。这使得接收方能够收到所有数据包,无需等待重传。
- 响应(第三阶段):接收方收到带有 ECN 标记的数据包后,会向发送方发送一条特殊的通知(CNP),告知发送方网络发生了拥塞。发送方收到通知后,会根据接收方的指示适当调整发送速率,以降低网络拥塞的程度。
通过这种方式,ECN 可以更及时地指示网络拥塞,并且避免了丢包带来的额外开销,从而提高了网络的性能和效率。
ECN在网络层的实现
ECN在IP头部中需要2个比特位来承载信息,它在IPv4位于IP头部TOS字段中,示意图如下:
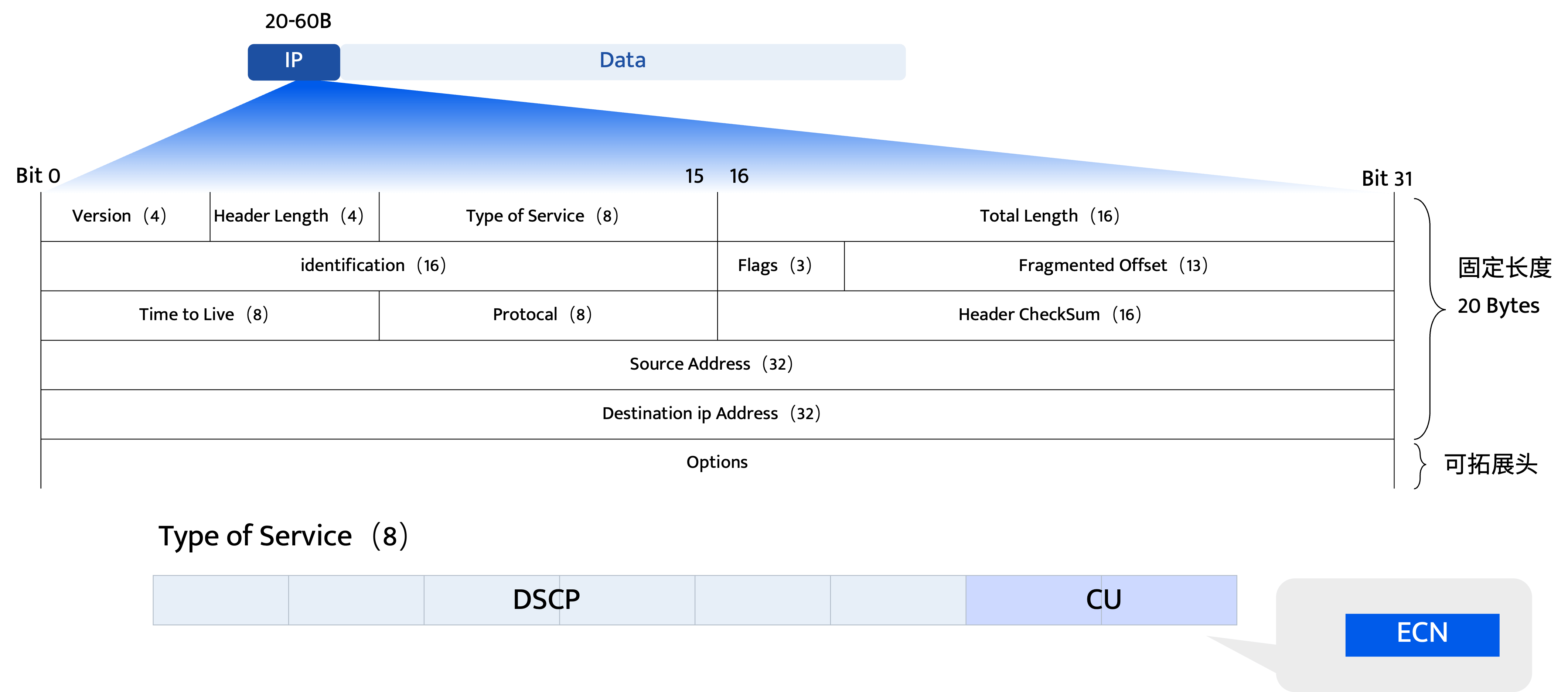
(Differentiated Services Field (区分服务领域):DS Field的两个部分DSCP和CU组合成一个可扩展性相对较强的方法以此来保证IP的服务质量。)
ECN在 IPv4 和 IPv6 头部中的位置和功能是类似的,但由于两者头部结构不同,其具体位置也存在差异。如下表:
| 特性维度 | IPv4 | IPv6 |
|---|---|---|
| 头部结构 | 可变长度头部(通常20字节,可带选项) | 固定40字节基本头部,扩展功能通过扩展头部实现 |
| ECN字段位置 | 重新定义的 ToS(服务类型)字节的后2位(第7-8位) | Traffic Class(流量类别)字节的后2位(第7-8位) |
| ECN字段大小 | 2比特 | 2比特 |
| ECN码点含义 | 00: Non-ECT (不支持ECN) 01: ECT(1) (支持ECN) 10: ECT(0) (支持ECN) 11: CE (经历拥塞) | 00: Non-ECT (不支持ECN) 01: ECT(1) (支持ECN) 10: ECT(0) (支持ECN) 11: CE (经历拥塞) |
| 所属字段 | 该8位字段前6位为DS(差分服务)字段,后2位为ECN字段(如图) | 该8位字段前6位为Traffic Class字段,后2位为ECN字段 |
支持ECN的标识
支持ECN的发送端(如服务器)在发出IP数据包时,会将其IP头部的ECN字段设置为 ECT(0)或 ECT(1)。这相当于向网络宣告:“我这个数据包是可以被ECN标记的,如果遇到拥塞,请标记我,不要丢弃我。”
拥塞标记
当支持ECN的网络设备(如路由器、交换机)检测到其缓冲区队列开始出现拥塞(但尚未满到需要丢包的程度)时,它会检查正在通过的数据包的ECN字段。如果该字段是 ECT(0)或 ECT(1),设备就会将其修改成 CE (11)。这个动作是ECN的核心—显式拥塞通知。
信息回传
接收端收到带有 CE 标记的数据包后,会通过其传输层协议(如 TCP ACK 包中的 ECN-Echo 标志位)通知发送端。发送端接到通知后,便会像检测到丢包一样降低发送速率,从而缓解拥塞。
ECN在传输层的实现
TCP
ECN在传输层的实现,是其发挥“端到端”拥塞控制作用的关键一环。在数据传输前,发送方和接收方必须通过三次握手 (Three-Way Handshake) 建立一个稳定的连接。TCP协议负责接收来自网络层(IP)的拥塞信号,并将其反馈给发送方,最终触发发送方的速率调整。
TCP 通过其首部中的两个标志位来实现 ECN 功能。
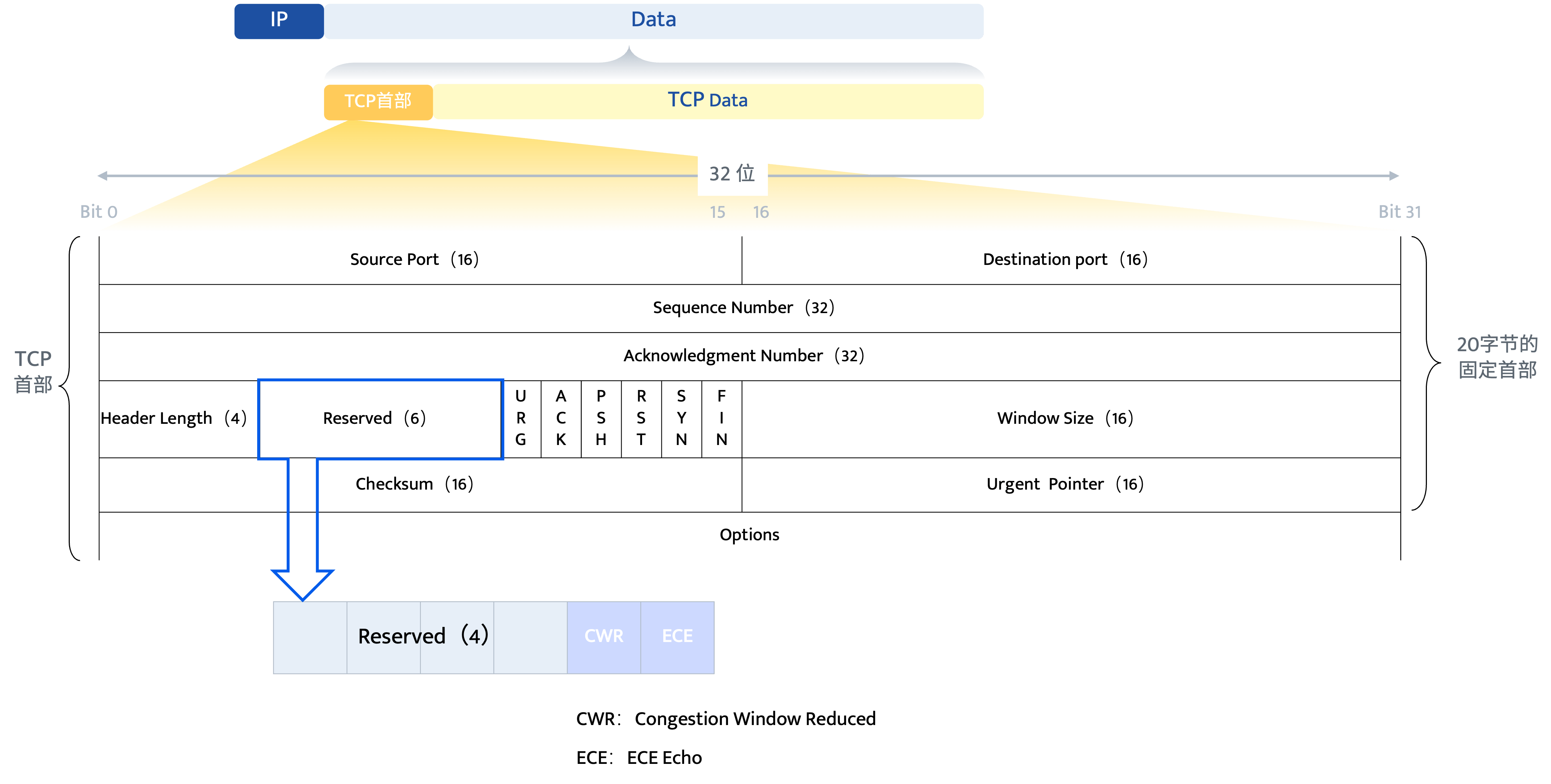
这2位有4种可能组合,每种组合被称为码点
| CWR | ECE | 码点 | 发送自 | 目标 | |
|---|---|---|---|---|---|
| 1 | 0 | 0 | Non-ECN set up | 任意 | 任意 |
| 2 | 0 | 1 | ECN Echo | 接收方 | 发送方 |
| 3 | 1 | 0 | Congestion window reduced | 发送方 | 接收方 |
| 4 | 1 | 1 | ECN Setup | 发送方 | 接收方 |
- ECE (ECN-Echo):用于接收方向发送方回显拥塞通知。当接收方收到一个被网络设备标记为拥塞体验(CE)的数据包时(接上一节内容),它会在后续返回的 ACK 包中设置 ECE=1,以此通知发送方网络发生了拥塞•
- CWR (Congestion Window Reduced):用于发送方向接收方确认已降低发送速率。当发送方收到一个 ECE=1 的 ACK 包并做出降速响应后,它会在下一个数据包中设置 CWR=1,以此告知接收方:“我已收到拥塞通知并已采取行动”。
UDP
UDP也是网络中传输层的一个核心协议,那么它和TCP的区别又是什么呢?
| 特性 | UDP (用户数据报协议) | TCP (传输控制协议) |
|---|---|---|
| 连接性 | 无连接 发送数据前无需建立连接,直接发送。 | 面向连接 通信前需通过“三次握手”建立可靠连接。 |
| 可靠性 | 不可靠 不保证数据包顺序、不重传丢失或出错包。 | 可靠 通过确认、重传等机制确保数据正确有序送达。 |
| 控制机制 | 无流量控制、无拥塞控制。 | 有复杂的流量控制和拥塞控制机制(如滑动窗口)。 |
| 数据单元 | 面向报文 应用层交给UDP多长的报文,UDP就发送多长。 | 面向字节流 将数据视为无结构的字节流进行传输。 |
| 速度开销 | 传输速度快 头部开销小(固定8字节),延迟低。 | 相对较慢 头部开销大(最小20字节),延迟较高。 |
| 适用场景 | 实时应用:音视频通话、直播、在线游戏、DNS查询等。 | 可靠性要求高的应用:文件传输、网页浏览、邮件等。 |

UDP 本身是无连接、无状态的协议,不像 TCP 那样有复杂的确认和重传机制。因此,ECN 在 UDP 中的实现方式与 TCP 不同,通常需要应用程序的更多参与或依赖配套的反馈协议。
发送方(应用程序)需要通过特定的 API(如 IP_ECNsocket 选项)来检测路径是否支持 ECN,并在发出的 UDP 数据包的 IP 头部设置 ECT 码点(ECT(0) 或 ECT(1)),表明该数据包支持 ECN。
当支持 ECN 的网络设备将 UDP 数据包标记为 CE 后,接收方需要检测到这一标记。由于 UDP 没有类似 TCP 的 ACK 机制,接收方需要生成一个专门的 CNP (Congestion Notification Packet, 拥塞通知报文),CNP报文内部会携带引发拥塞的原始数据流的关键信息(源和目标IP地址、传输层端口号、拥塞程度信息、QP(Queue Pair)信息),并将其发送回源发送方。发送方在收到 CNP 后,需要主动降低数据发送速率。
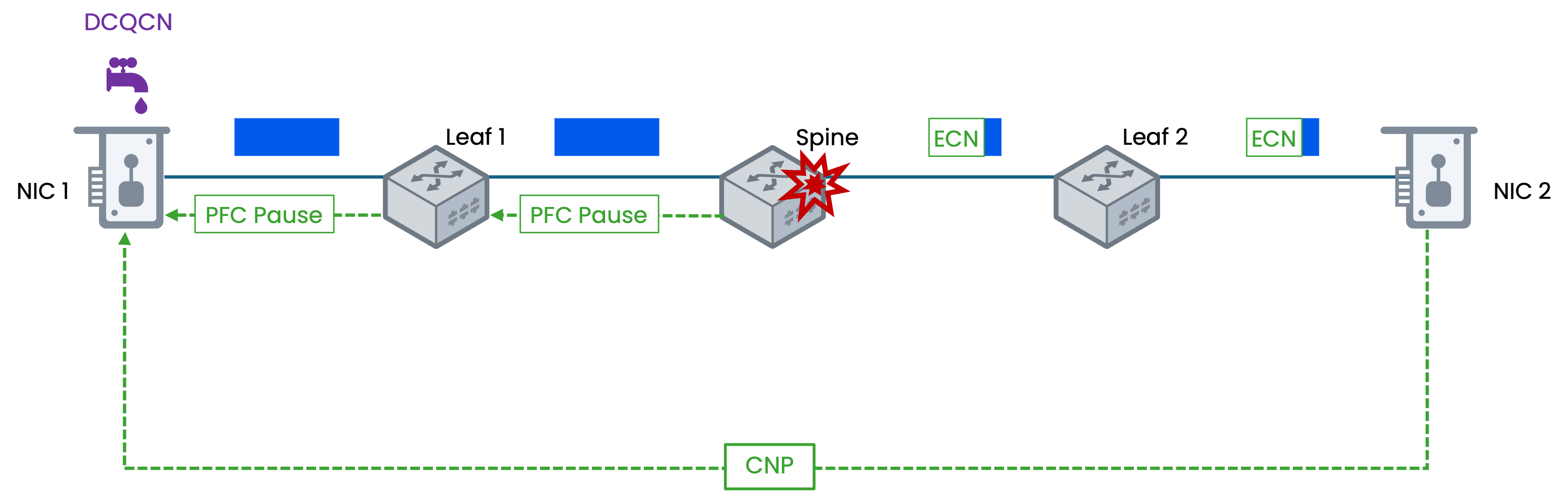
ECN在RDMA中的实现方式
在高性能计算和数据中心环境中,RoCEv2 也广泛使用 ECN。其实现方式与 UDP 类似,因为 RoCEv2 运行在 UDP 之上。
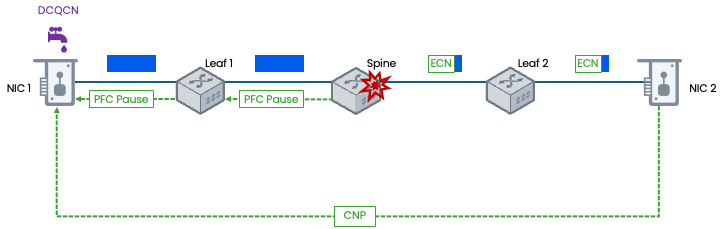
支持 ECN 的交换机在检测到拥塞时,会标记 RoCEv2 数据包的 IP 头 ECN 字段为 CE。接收端网卡生成专门的 CNP(拥塞通知报文),其中包含导致拥塞的流量源信息,CNP 被发送回引发拥塞的发送端主机,发送端主机收到 CNP 后,会根据DCQCN(数据中心量化拥塞通知) 等算法调整相应数据流的发送速率。
智算中心的硬件核心在于为 RoCEv2提供稳定、高性能的无损网络环境。这不仅需要网卡支持,更需要交换机的深度配合。CX-N系列数据中心交换机通过其超低时延、无损网络技术、对大容量缓存的优化、高级遥测功能以及对自动化运维的支持,为DCQCN协议在AI计算、高性能计算等场景中的高效、稳定运行提供了坚实的硬件基础。
参阅文献:
https://developer.aliyun.com/article/1494789
https://blog.csdn.net/yuff100/article/details/134858611
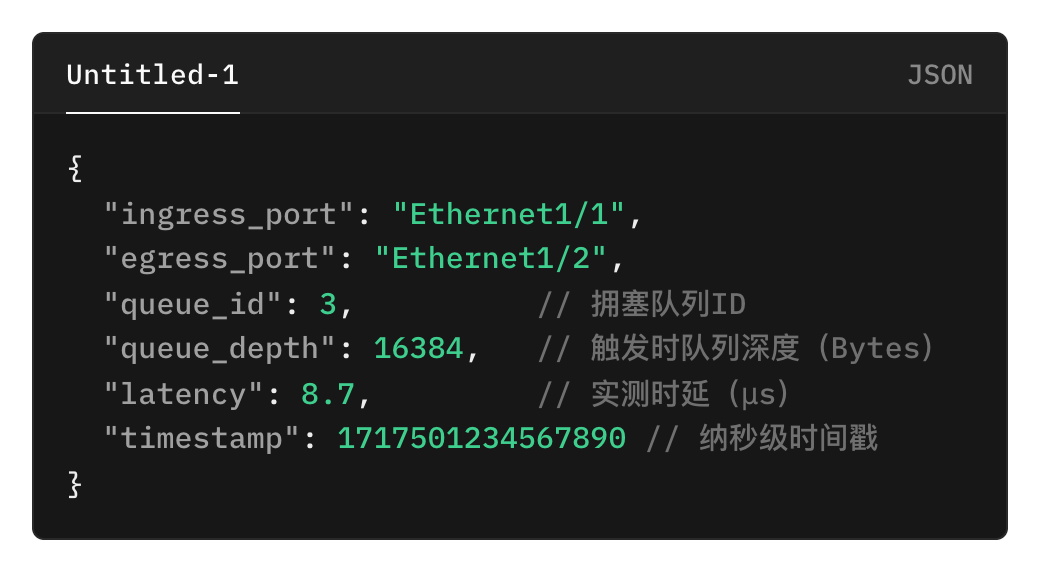







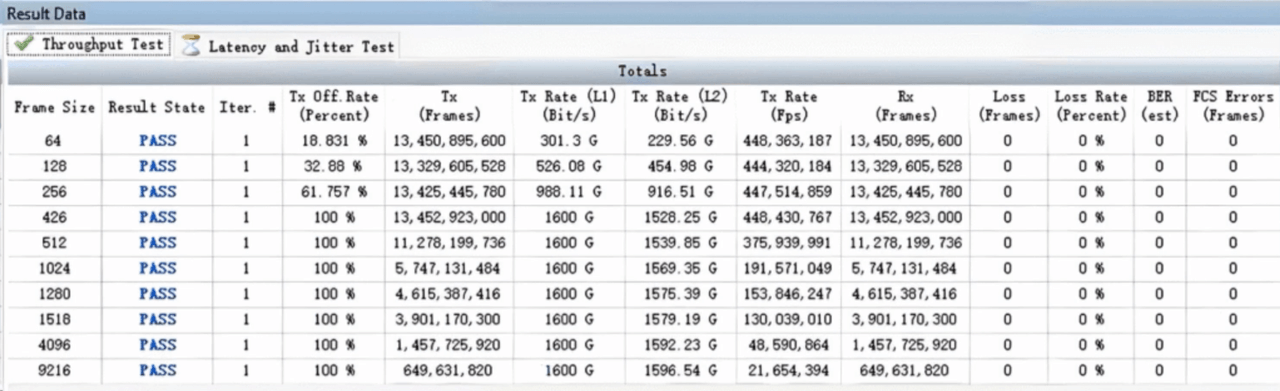
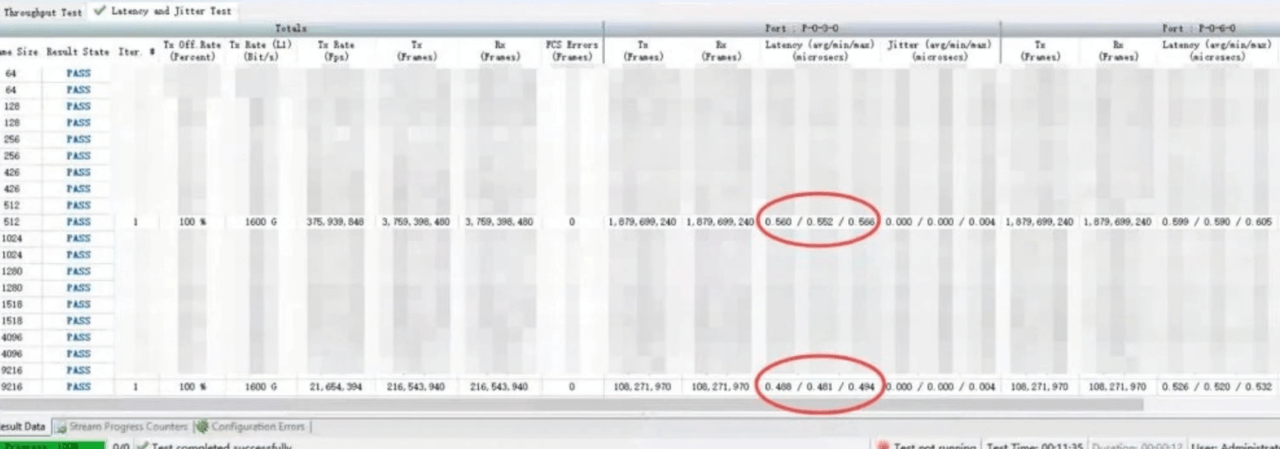
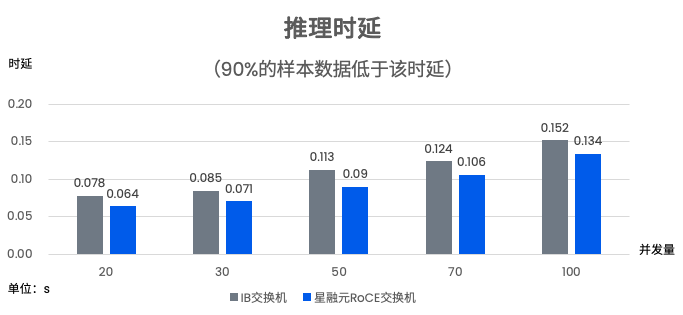
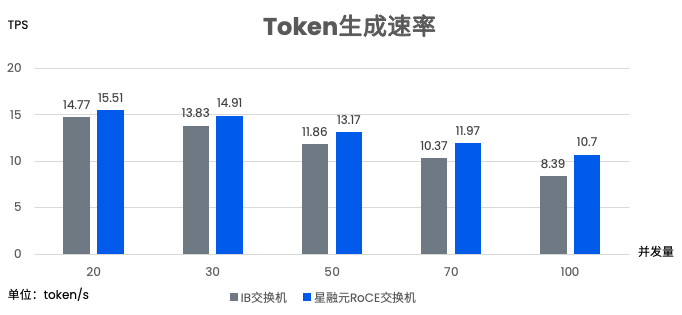

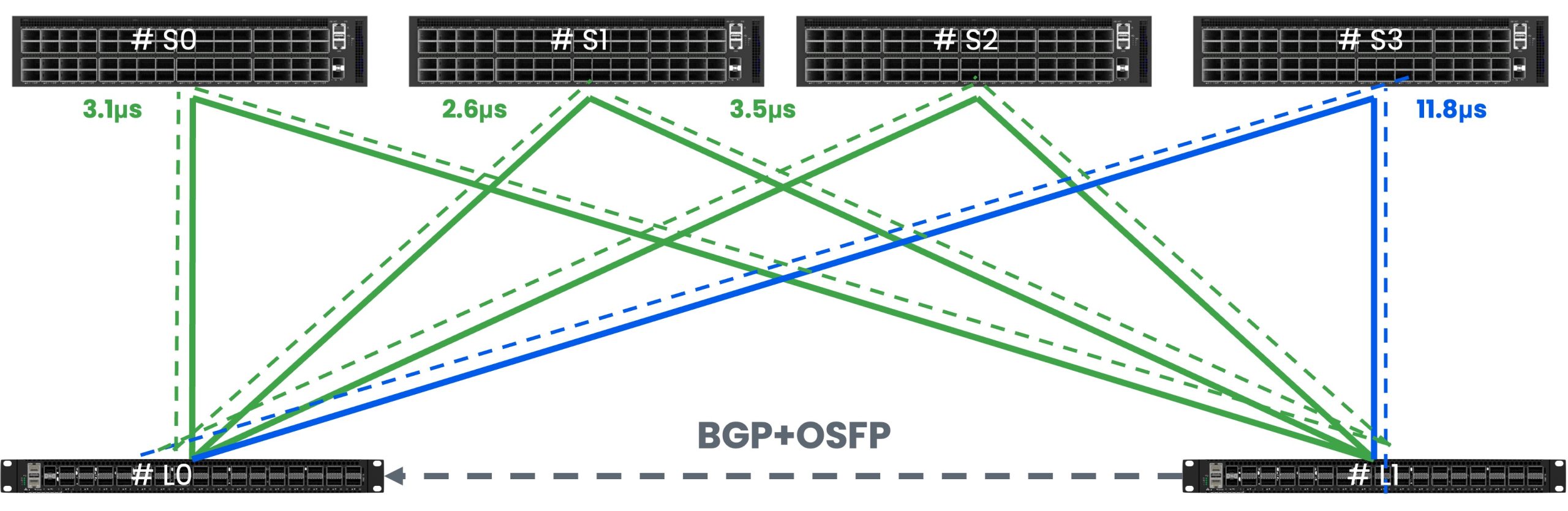




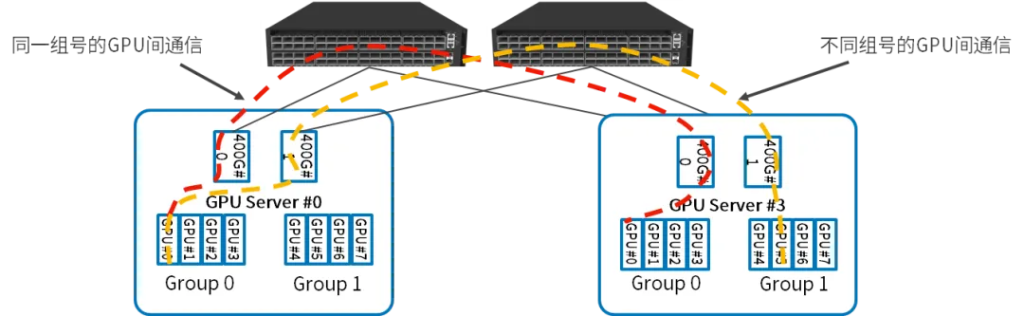
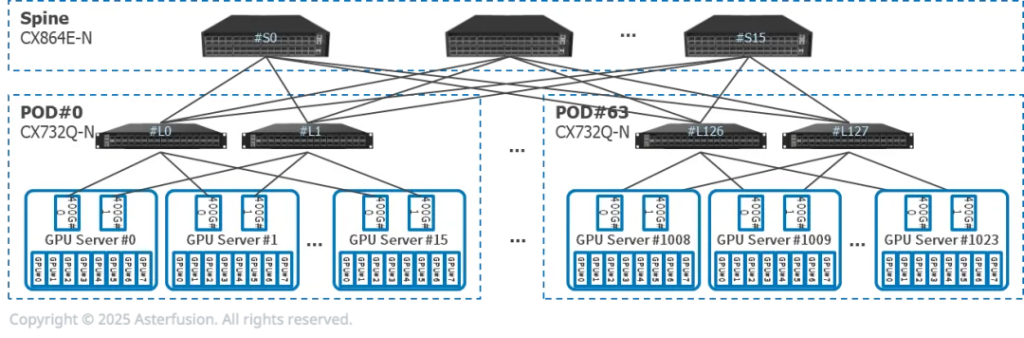
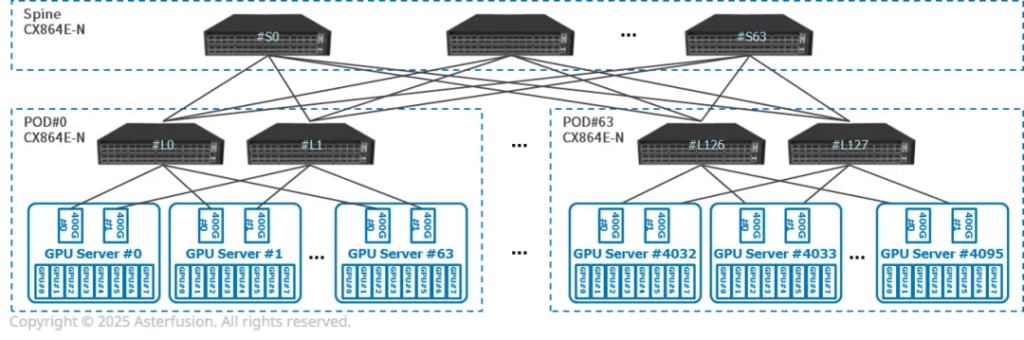 每台推理服务器有8张GPU,2张400G网卡,双归连接到两台CX864E-N
每台推理服务器有8张GPU,2张400G网卡,双归连接到两台CX864E-N